жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
10 HiveдҪ“зі»жһ¶жһ„
10.1 жҰӮеҝө
з”ЁжҲ·жҺҘеҸЈпјҡз”ЁжҲ·и®ҝй—®Hiveзҡ„е…ҘеҸЈ
е…ғж•°жҚ®пјҡHiveзҡ„з”ЁжҲ·дҝЎжҒҜдёҺиЎЁзҡ„MetaData
и§ЈйҮҠеҷЁпјҡеҲҶжһҗзҝ»иҜ‘HQLзҡ„组件
зј–иҜ‘еҷЁпјҡзј–иҜ‘HQLзҡ„组件
дјҳеҢ–еҷЁпјҡдјҳеҢ–HQLзҡ„组件
10.2 Hiveжһ¶жһ„дёҺеҹәжң¬з»„жҲҗ
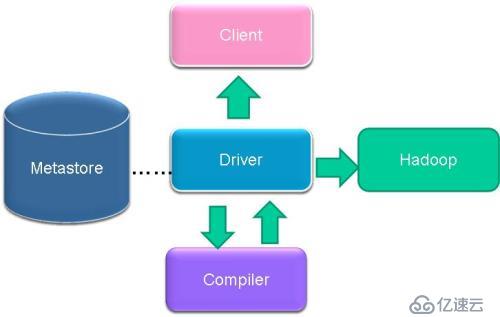
1гҖҒжһ¶жһ„еӣҫ
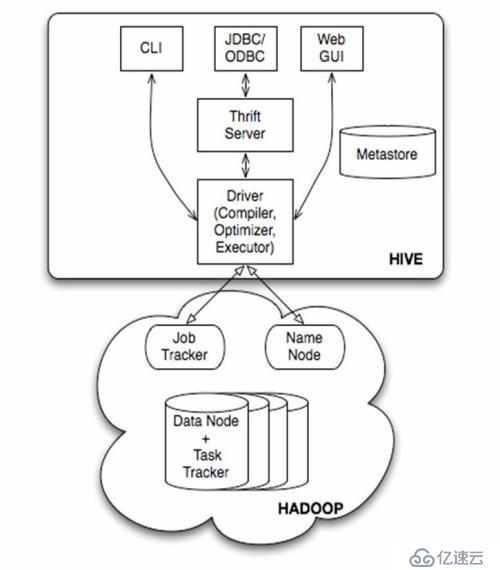
2гҖҒеҹәжң¬з»„жҲҗ
з”ЁжҲ·жҺҘеҸЈпјҢеҢ…жӢ¬ CLIпјҢJDBC/ODBCпјҢWebUI
е…ғж•°жҚ®еӯҳеӮЁпјҢйҖҡеёёжҳҜеӯҳеӮЁеңЁе…ізі»ж•°жҚ®еә“еҰӮ mysql, derby дёӯ
и§ЈйҮҠеҷЁгҖҒзј–иҜ‘еҷЁгҖҒдјҳеҢ–еҷЁгҖҒжү§иЎҢеҷЁ
Hadoopпјҡз”ЁHDFS иҝӣиЎҢеӯҳеӮЁпјҢеҲ©з”Ё MapReduce иҝӣиЎҢи®Ўз®—
3гҖҒеҗ„组件зҡ„еҹәжң¬еҠҹиғҪ
з”ЁжҲ·жҺҘеҸЈдё»иҰҒжңүдёүдёӘпјҡCLIпјҢJDBC/ODBCе’Ң WebUI
CLIпјҢеҚіShellе‘Ҫд»ӨиЎҢ
JDBC/ODBC жҳҜHive зҡ„JAVAпјҢдёҺдҪҝз”Ёдј з»ҹж•°жҚ®еә“JDBCзҡ„ж–№ејҸзұ»дјј
WebGUIжҳҜйҖҡиҝҮжөҸи§ҲеҷЁи®ҝй—® Hive
Hive е°Ҷе…ғж•°жҚ®еӯҳеӮЁеңЁж•°жҚ®еә“дёӯпјҢзӣ®еүҚеҸӘж”ҜжҢҒ mysqlгҖҒderbyпјҢдёӢдёҖзүҲжң¬дјҡж”ҜжҢҒжӣҙеӨҡзҡ„ж•°жҚ®еә“гҖӮHive дёӯзҡ„е…ғж•°жҚ®еҢ…жӢ¬иЎЁзҡ„еҗҚеӯ—пјҢиЎЁзҡ„еҲ—е’ҢеҲҶеҢәеҸҠе…¶еұһжҖ§пјҢиЎЁзҡ„еұһжҖ§пјҲжҳҜеҗҰдёәеӨ–йғЁиЎЁзӯүпјүпјҢиЎЁзҡ„ж•°жҚ®жүҖеңЁзӣ®еҪ•зӯү
и§ЈйҮҠеҷЁгҖҒзј–иҜ‘еҷЁгҖҒдјҳеҢ–еҷЁе®ҢжҲҗ HQL жҹҘиҜўиҜӯеҸҘд»ҺиҜҚжі•еҲҶжһҗгҖҒиҜӯжі•еҲҶжһҗгҖҒзј–иҜ‘гҖҒдјҳеҢ–д»ҘеҸҠжҹҘиҜўи®ЎеҲ’зҡ„з”ҹжҲҗгҖӮз”ҹжҲҗзҡ„жҹҘиҜўи®ЎеҲ’еӯҳеӮЁеңЁ HDFS дёӯпјҢ并еңЁйҡҸеҗҺжңү MapReduce и°ғз”Ёжү§иЎҢ
Hive зҡ„ж•°жҚ®еӯҳеӮЁеңЁHDFS дёӯпјҢеӨ§йғЁеҲҶзҡ„жҹҘиҜўз”ұ MapReduce е®ҢжҲҗпјҲеҢ…еҗ«* зҡ„жҹҘиҜўпјҢжҜ”еҰӮ select * from table дёҚдјҡз”ҹжҲҗ MapRedcue д»»еҠЎпјү
4гҖҒMetastore
MetastoreжҳҜзі»з»ҹзӣ®еҪ•(catalog)з”ЁдәҺдҝқеӯҳHiveдёӯжүҖеӯҳеӮЁзҡ„иЎЁзҡ„е…ғж•°жҚ®пјҲmetadataпјүдҝЎжҒҜ
MetastoreжҳҜHiveиў«з”ЁдҪңдј з»ҹж•°жҚ®еә“и§ЈеҶіж–№жЎҲпјҲеҰӮoracleе’Ңdb2пјүж—¶еҢәеҲ«е…¶е®ғзұ»дјјзі»з»ҹзҡ„дёҖдёӘзү№еҫҒ
MetastoreеҢ…еҗ«еҰӮдёӢзҡ„йғЁеҲҶпјҡ
Database жҳҜиЎЁпјҲtableпјүзҡ„еҗҚеӯ—з©әй—ҙгҖӮй»ҳи®Өзҡ„ж•°жҚ®еә“пјҲdatabaseпјүеҗҚдёәвҖҳdefaultвҖҷ
Table иЎЁпјҲtableпјүзҡ„еҺҹж•°жҚ®еҢ…еҗ«дҝЎжҒҜжңүпјҡеҲ—пјҲlist of columnsпјүе’Ңе®ғ们зҡ„зұ»еһӢпјҲtypesпјүпјҢжӢҘжңүиҖ…пјҲownerпјүпјҢеӯҳеӮЁз©әй—ҙпјҲstorageпјүе’ҢSerDeiдҝЎжҒҜ
Partition жҜҸдёӘеҲҶеҢәпјҲpartitionпјүйғҪжңүиҮӘе·ұзҡ„еҲ—пјҲcolumnsпјүпјҢSerDeе’ҢеӯҳеӮЁз©әй—ҙпјҲstorageпјүгҖӮиҝҷдёҖзү№еҫҒе°Ҷиў«з”ЁжқҘж”ҜжҢҒHiveдёӯзҡ„жЁЎејҸжј”еҸҳпјҲschema evolutionпјү
5гҖҒCompiler
Driverи°ғз”Ёзј–иҜ‘еҷЁпјҲcompilerпјүеӨ„зҗҶHiveQLеӯ—дёІпјҢиҝҷдәӣеӯ—дёІеҸҜиғҪжҳҜдёҖжқЎDDLгҖҒDMLжҲ–жҹҘиҜўиҜӯеҸҘ
зј–иҜ‘еҷЁе°Ҷеӯ—з¬ҰдёІиҪ¬еҢ–дёәзӯ–з•ҘпјҲplanпјү
зӯ–з•Ҙд»…з”ұе…ғж•°жҚ®ж“ҚдҪңе’ҢHDFSж“ҚдҪңз»„жҲҗпјҢе…ғж•°жҚ®ж“ҚдҪңеҸӘеҢ…еҗ«DDLиҜӯеҸҘпјҢHDFSж“ҚдҪңеҸӘеҢ…еҗ«LOADиҜӯеҸҘ
еҜ№жҸ’е…Ҙе’ҢжҹҘиҜўиҖҢиЁҖпјҢзӯ–з•Ҙз”ұmap-reduceд»»еҠЎдёӯзҡ„е…·жңүж–№еҗ‘зҡ„йқһеҫӘзҺҜеӣҫпјҲdirectedacyclic graphпјҢDAGпјүз»„жҲҗ
10.3 HiveиҝҗиЎҢжЁЎејҸ
Hiveзҡ„иҝҗиЎҢжЁЎејҸеҚід»»еҠЎзҡ„жү§иЎҢзҺҜеўғ
еҲҶдёәжң¬ең°дёҺйӣҶзҫӨдёӨз§Қ
жҲ‘们еҸҜд»ҘйҖҡиҝҮmapred.job.tracker жқҘжҢҮжҳҺ
и®ҫзҪ®ж–№ејҸпјҡhive > SET mapred.job.tracker=local
10.4 ж•°жҚ®зұ»еһӢ
1гҖҒеҺҹе§Ӣж•°жҚ®зұ»еһӢ
IntegersпјҡTINYINT - 1 byteгҖҒSMALLINT - 2 byteгҖҒINT - 4 byteгҖҒBIGINT - 8 byte
Boolean typeпјҡBOOLEAN - TRUE/FALSE
Floating point numbersпјҡFLOAT вҖ“еҚ•зІҫеәҰгҖҒDOUBLE вҖ“ еҸҢзІҫеәҰ
String typeпјҡSTRING - sequence of charactersin a specified character set
2гҖҒеӨҚжқӮж•°жҚ®зұ»еһӢ
Structs: дҫӢеӯҗ {c INT; d INT}
Maps (key-value tuples):. дҫӢеӯҗ'group' ->gid M['group']
Arrays (indexable lists): дҫӢеӯҗ[вҖҳ1', вҖҳ2', вҖҳ3']
TIMESTAMP 0.8зүҲжң¬ж–°еҠ еұһжҖ§
10.5 Hiveзҡ„е…ғж•°жҚ®еӯҳеӮЁ
1гҖҒеӯҳеӮЁж–№ејҸдёҺжЁЎејҸ
Hiveе°Ҷе…ғж•°жҚ®еӯҳеӮЁеңЁж•°жҚ®еә“дёӯ
иҝһжҺҘеҲ°ж•°жҚ®еә“жЁЎејҸжңүдёүз§Қ
еҚ•з”ЁжҲ·жЁЎејҸ
еӨҡз”ЁжҲ·жЁЎејҸ
иҝңзЁӢжңҚеҠЎеҷЁжЁЎејҸ
2гҖҒеҚ•з”ЁжҲ·жЁЎејҸ
жӯӨжЁЎејҸиҝһжҺҘеҲ°дёҖдёӘ In-memory зҡ„ж•°жҚ®еә“ Derby пјҢдёҖиҲ¬з”ЁдәҺ Unit Test
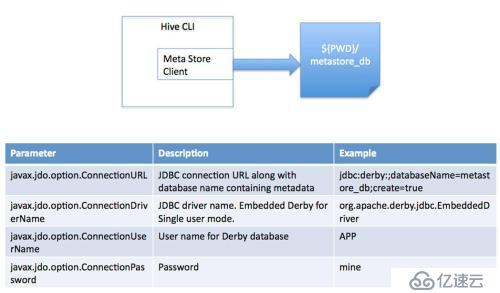
3гҖҒеӨҡз”ЁжҲ·жЁЎејҸ
йҖҡиҝҮзҪ‘з»ңиҝһжҺҘеҲ°дёҖдёӘж•°жҚ®еә“дёӯпјҢжҳҜжңҖз»ҸеёёдҪҝз”ЁеҲ°зҡ„жЁЎејҸ
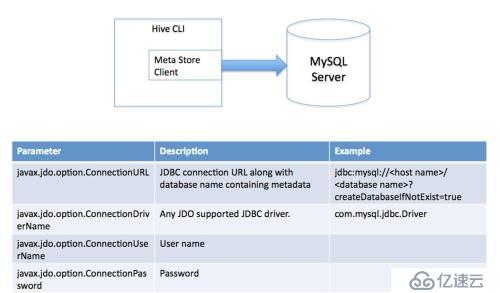
4гҖҒиҝңзЁӢжңҚеҠЎеҷЁжЁЎејҸ
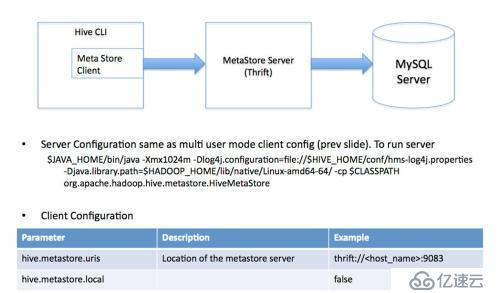 з”ЁдәҺйқһ Java е®ўжҲ·з«Ҝи®ҝй—®е…ғж•°жҚ®еә“пјҢеңЁжңҚеҠЎеҷЁз«ҜеҗҜеҠЁMetaStoreServerпјҢе®ўжҲ·з«ҜеҲ©з”Ё Thrift еҚҸи®®йҖҡиҝҮMetaStoreServer и®ҝй—®е…ғж•°жҚ®еә“гҖӮ
з”ЁдәҺйқһ Java е®ўжҲ·з«Ҝи®ҝй—®е…ғж•°жҚ®еә“пјҢеңЁжңҚеҠЎеҷЁз«ҜеҗҜеҠЁMetaStoreServerпјҢе®ўжҲ·з«ҜеҲ©з”Ё Thrift еҚҸи®®йҖҡиҝҮMetaStoreServer и®ҝй—®е…ғж•°жҚ®еә“гҖӮ
10.6 Hiveзҡ„ж•°жҚ®еӯҳеӮЁ
1гҖҒHiveж•°жҚ®еӯҳеӮЁзҡ„еҹәжң¬жҰӮеҝө
Hiveзҡ„ж•°жҚ®еӯҳеӮЁжҳҜе»әз«ӢеңЁHadoop HDFSд№ӢдёҠзҡ„
HiveжІЎжңүдё“й—Ёзҡ„ж•°жҚ®еӯҳеӮЁж јејҸ
еӯҳеӮЁз»“жһ„дё»иҰҒеҢ…жӢ¬пјҡж•°жҚ®еә“гҖҒж–Ү件гҖҒиЎЁгҖҒи§Ҷеӣҫ
Hiveй»ҳи®ӨеҸҜд»ҘзӣҙжҺҘеҠ иҪҪж–Үжң¬ж–Ү件пјҢиҝҳж”ҜжҢҒsequence file гҖҒRCFile
еҲӣе»әиЎЁж—¶пјҢжҲ‘们зӣҙжҺҘе‘ҠиҜүHiveж•°жҚ®зҡ„еҲ—еҲҶйҡ”з¬ҰдёҺиЎҢеҲҶйҡ”з¬ҰпјҢHiveеҚіеҸҜи§Јжһҗж•°жҚ®
2гҖҒHiveзҡ„ж•°жҚ®жЁЎеһӢ-ж•°жҚ®еә“
зұ»дјјдј з»ҹж•°жҚ®еә“зҡ„DataBase
еңЁз¬¬дёүж–№ж•°жҚ®еә“йҮҢе®һйҷ…жҳҜдёҖеј иЎЁ
з®ҖеҚ•зӨәдҫӢпјҡе‘Ҫд»ӨиЎҢhive > create database test_database;
3гҖҒеҶ…йғЁиЎЁ
дёҺж•°жҚ®еә“дёӯзҡ„ Table еңЁжҰӮеҝөдёҠжҳҜзұ»дјј
жҜҸдёҖдёӘ Table еңЁ Hive дёӯйғҪжңүдёҖдёӘзӣёеә”зҡ„зӣ®еҪ•еӯҳеӮЁж•°жҚ®
дҫӢеҰӮпјҢдёҖдёӘиЎЁ testпјҢе®ғеңЁ HDFS дёӯзҡ„и·Ҝеҫ„дёәпјҡ/warehouse /test
warehouseжҳҜеңЁ hive-site.xml дёӯз”ұ
${hive.metastore.warehouse.dir}жҢҮе®ҡзҡ„ж•°жҚ®д»“еә“зҡ„зӣ®еҪ•
жүҖжңүзҡ„ Table ж•°жҚ®пјҲдёҚеҢ…жӢ¬ External TableпјүйғҪдҝқеӯҳеңЁиҝҷдёӘзӣ®еҪ•дёӯгҖӮ
еҲ йҷӨиЎЁж—¶пјҢе…ғж•°жҚ®дёҺж•°жҚ®йғҪдјҡиў«еҲ йҷӨ
4гҖҒеҶ…йғЁиЎЁз®ҖеҚ•зӨәдҫӢ
еҲӣе»әж•°жҚ®ж–Ү件test_inner_table.txt
еҲӣе»әиЎЁ
create table test_inner_table (key string)
еҠ иҪҪж•°жҚ®
LOAD DATA LOCAL INPATH вҖҳfilepathвҖҷ INTO TABLE test_inner_table
жҹҘзңӢж•°жҚ®
select * from test_inner_table select count(*) from test_inner_table
еҲ йҷӨиЎЁ
drop table test_inner_table
5гҖҒеҲҶеҢәиЎЁ
Partition еҜ№еә”дәҺж•°жҚ®еә“дёӯзҡ„ Partition еҲ—зҡ„еҜҶйӣҶзҙўеј•
еңЁ Hive дёӯпјҢиЎЁдёӯзҡ„дёҖдёӘ Partition еҜ№еә”дәҺиЎЁдёӢзҡ„дёҖдёӘзӣ®еҪ•пјҢжүҖжңүзҡ„ Partition зҡ„ж•°жҚ®йғҪеӯҳеӮЁеңЁеҜ№еә”зҡ„зӣ®еҪ•дёӯ
дҫӢеҰӮпјҡtestиЎЁдёӯеҢ…еҗ« date е’Ңposition дёӨдёӘ PartitionпјҢеҲҷеҜ№еә”дәҺ date= 20120801, position = zh зҡ„ HDFS еӯҗзӣ®еҪ•дёәпјҡ/ warehouse /test/date=20120801/ position =zh
еҜ№еә”дәҺ = 20100801, position = US зҡ„HDFS еӯҗзӣ®еҪ•дёәпјӣ/ warehouse/xiaojun/date=20120801/ position =US
6гҖҒеҲҶеҢәиЎЁз®ҖеҚ•зӨәдҫӢ
еҲӣе»әж•°жҚ®ж–Ү件test_partition_table.txt
еҲӣе»әиЎЁ
create table test_partition_table (key string) partitioned by (dtstring)
еҠ иҪҪж•°жҚ®
LOAD DATA INPATH вҖҳfilepathвҖҷ INTO TABLE test_partition_tablepartition (dt=вҖҳ2006вҖҷ)
жҹҘзңӢж•°жҚ®
select * from test_partition_table select count(*) from test_partition_table
еҲ йҷӨиЎЁ
drop table test_partition_table
7гҖҒеӨ–йғЁиЎЁ
жҢҮеҗ‘е·Із»ҸеңЁ HDFS дёӯеӯҳеңЁзҡ„ж•°жҚ®пјҢеҸҜд»ҘеҲӣе»ә Partition
е®ғе’Ң еҶ…йғЁиЎЁ еңЁе…ғж•°жҚ®зҡ„з»„з»ҮдёҠжҳҜзӣёеҗҢзҡ„пјҢиҖҢе®һйҷ…ж•°жҚ®зҡ„еӯҳеӮЁеҲҷжңүиҫғеӨ§зҡ„е·®ејӮ
еҶ…йғЁиЎЁ зҡ„еҲӣе»әиҝҮзЁӢе’Ңж•°жҚ®еҠ иҪҪиҝҮзЁӢпјҲиҝҷдёӨдёӘиҝҮзЁӢеҸҜд»ҘеңЁеҗҢдёҖдёӘиҜӯеҸҘдёӯе®ҢжҲҗпјүпјҢеңЁеҠ иҪҪж•°жҚ®зҡ„иҝҮзЁӢдёӯпјҢе®һйҷ…ж•°жҚ®дјҡ被移еҠЁеҲ°ж•°жҚ®д»“еә“зӣ®еҪ•дёӯпјӣд№ӢеҗҺеҜ№ж•°жҚ®еҜ№и®ҝй—®е°ҶдјҡзӣҙжҺҘеңЁж•°жҚ®д»“еә“зӣ®еҪ•дёӯе®ҢжҲҗгҖӮеҲ йҷӨиЎЁж—¶пјҢиЎЁдёӯзҡ„ж•°жҚ®е’Ңе…ғж•°жҚ®е°Ҷдјҡиў«еҗҢж—¶еҲ йҷӨ
еӨ–йғЁиЎЁ еҸӘжңүдёҖдёӘиҝҮзЁӢпјҢеҠ иҪҪж•°жҚ®е’ҢеҲӣе»әиЎЁеҗҢж—¶е®ҢжҲҗпјҢ并дёҚдјҡ移еҠЁеҲ°ж•°жҚ®д»“еә“зӣ®еҪ•дёӯпјҢеҸӘжҳҜдёҺеӨ–йғЁж•°жҚ®е»әз«ӢдёҖдёӘй“ҫжҺҘгҖӮеҪ“еҲ йҷӨдёҖдёӘеӨ–йғЁиЎЁ ж—¶пјҢд»…еҲ йҷӨиҜҘй“ҫжҺҘ
8гҖҒеӨ–йғЁиЎЁз®ҖеҚ•зӨәдҫӢ
еҲӣе»әж•°жҚ®ж–Ү件test_external_table.txt
еҲӣе»әиЎЁ
create external table test_external_table (key string)
еҠ иҪҪж•°жҚ®
LOAD DATA INPATH вҖҳfilepathвҖҷ INTO TABLE test_inner_table
жҹҘзңӢж•°жҚ®
select * from test_external_table select count(*) from test_external_table
еҲ йҷӨиЎЁ
drop table test_external_table
9гҖҒBucket TableпјҲжЎ¶иЎЁпјү
еҸҜд»Ҙе°ҶиЎЁзҡ„еҲ—йҖҡиҝҮHashз®—жі•иҝӣдёҖжӯҘеҲҶи§ЈжҲҗдёҚеҗҢзҡ„ж–Ү件еӯҳеӮЁ
дҫӢеҰӮпјҡе°ҶageеҲ—еҲҶж•ЈжҲҗ20дёӘж–Ү件пјҢйҰ–е…ҲиҰҒеҜ№AGEиҝӣиЎҢHashи®Ўз®—пјҢеҜ№еә”дёә0зҡ„еҶҷе…Ҙ/warehouse/test/date=20120801/postion=zh/part-00000,еҜ№еә”дёә1зҡ„еҶҷе…Ҙ/warehouse/test/date=20120801/postion=zh/part-00001
еҰӮжһңжғіеә”з”ЁеҫҲеӨҡзҡ„Mapд»»еҠЎиҝҷж ·жҳҜдёҚй”ҷзҡ„йҖүжӢ©
10гҖҒBucket Tableз®ҖеҚ•зӨәдҫӢ
еҲӣе»әж•°жҚ®ж–Ү件test_bucket_table.txt
еҲӣе»әиЎЁ
create table test_bucket_table (key string) clustered by (key)into 20 buckets
еҠ иҪҪж•°жҚ®
LOAD DATA INPATH вҖҳfilepathвҖҷ INTO TABLE test_bucket_table
жҹҘзңӢж•°жҚ®
select * from test_bucket_table set hive.enforce.bucketing = true;
11гҖҒHiveзҡ„ж•°жҚ®жЁЎеһӢ-и§Ҷеӣҫ
и§ҶеӣҫдёҺдј з»ҹж•°жҚ®еә“зҡ„и§Ҷеӣҫзұ»дјј
и§ҶеӣҫжҳҜеҸӘиҜ»зҡ„
и§ҶеӣҫеҹәдәҺзҡ„еҹәжң¬иЎЁпјҢеҰӮжһңж”№еҸҳпјҢжҢҮеўһеҠ дёҚдјҡеҪұе“Қи§Ҷеӣҫзҡ„е‘ҲзҺ°пјӣеҰӮжһңеҲ йҷӨпјҢдјҡеҮәзҺ°й—®йўҳ
еҰӮжһңдёҚжҢҮе®ҡи§Ҷеӣҫзҡ„еҲ—пјҢдјҡж №жҚ®selectиҜӯеҸҘеҗҺзҡ„з”ҹжҲҗ
зӨәдҫӢ
create view test_view as select * from test
10.7 Hiveзҡ„ж•°жҚ®еӯҳеӮЁ
й…ҚзҪ®жӯҘйӘӨпјҡ
hive-site.xml ж·»еҠ
<property> <name>hive.hwi.war.file</name> <value>lib/hive-hwi-0.8.1.war</value> </property>
еҗҜеҠЁHiveзҡ„UI sh $HIVE_HOME/bin/hive --service hwi
11 HiveеҺҹзҗҶ
11.1 HiveеҺҹзҗҶ
1гҖҒд»Җд№ҲиҰҒеӯҰд№ Hiveзҡ„еҺҹзҗҶ
дёҖжқЎHive HQLе°ҶиҪ¬жҚўдёәеӨҡе°‘йҒ“MRдҪңдёҡ
жҖҺд№Ҳж ·еҠ еҝ«Hiveзҡ„жү§иЎҢйҖҹеәҰ
зј–еҶҷHive HQLзҡ„ж—¶еҖҷжҲ‘们еҸҜд»ҘеҒҡд»Җд№Ҳ
Hive жҖҺд№Ҳе°ҶHQLиҪ¬жҚўдёәMRдҪңдёҡ
HiveдјҡйҮҮз”Ёд»Җд№Ҳж ·зҡ„дјҳеҢ–ж–№ејҸ
2гҖҒHiveжһ¶жһ„&жү§иЎҢжөҒзЁӢеӣҫ
3гҖҒHiveжү§иЎҢжөҒзЁӢ
зј–иҜ‘еҷЁе°ҶдёҖдёӘHive QLиҪ¬жҚўж“ҚдҪңз¬Ұ
ж“ҚдҪңз¬ҰжҳҜHiveзҡ„жңҖе°Ҹзҡ„еӨ„зҗҶеҚ•е…ғ
жҜҸдёӘж“ҚдҪңз¬Ұд»ЈиЎЁHDFSзҡ„дёҖдёӘж“ҚдҪңжҲ–иҖ…дёҖйҒ“MapReduceдҪңдёҡ
4гҖҒOperator
OperatorйғҪжҳҜhiveе®ҡд№үзҡ„дёҖдёӘеӨ„зҗҶиҝҮзЁӢ
OperatorйғҪе®ҡд№үжңү:
protected List <Operator<? extends Serializable >> childOperators;
protected List <Operator<? extends Serializable >> parentOperators;
protected boolean done; // еҲқе§ӢеҢ–еҖјдёәfalse
жүҖжңүзҡ„ж“ҚдҪңжһ„жҲҗдәҶ OperatorеӣҫпјҢhiveжӯЈжҳҜеҹәдәҺиҝҷдәӣеӣҫе…ізі»жқҘеӨ„зҗҶиҜёеҰӮlimit, group by, joinзӯүж“ҚдҪңгҖӮ

5гҖҒHiveжү§иЎҢжөҒзЁӢ
ж“ҚдҪңз¬Ұ | жҸҸиҝ° |
TableScanOperator | жү«жҸҸhiveиЎЁж•°жҚ® |
ReduceSinkOperator | еҲӣе»әе°ҶеҸ‘йҖҒеҲ°Reducerз«Ҝзҡ„<Key,Value>еҜ№ |
JoinOperator | JoinдёӨд»Ҫж•°жҚ® |
SelectOperator | йҖүжӢ©иҫ“еҮәеҲ— |
FileSinkOperator | е»әз«Ӣз»“жһңж•°жҚ®,иҫ“еҮәиҮіж–Ү件 |
FilterOperator | иҝҮж»Өиҫ“е…Ҙж•°жҚ® |
GroupByOperator | GroupByиҜӯеҸҘ |
MapJoinOperator | /*+mapjoin(t) */ |
LimitOperator | LimitиҜӯеҸҘ |
UnionOperator | UnionиҜӯеҸҘ |
HiveйҖҡиҝҮExecMapperе’ҢExecReducerжү§иЎҢMapReduceд»»еҠЎ
еңЁжү§иЎҢMapReduceж—¶жңүдёӨз§ҚжЁЎејҸ
жң¬ең°жЁЎејҸ
еҲҶеёғејҸжЁЎејҸ
6гҖҒANTLRиҜҚжі•иҜӯжі•еҲҶжһҗе·Ҙе…·
ANTLRвҖ”Another Tool for Language Recognition
ANTLR жҳҜејҖжәҗзҡ„
дёәеҢ…жӢ¬JavaпјҢC++пјҢC#еңЁеҶ…зҡ„иҜӯиЁҖжҸҗдҫӣдәҶдёҖдёӘйҖҡиҝҮиҜӯжі•жҸҸиҝ°жқҘиҮӘеҠЁжһ„йҖ иҮӘе®ҡд№үиҜӯиЁҖзҡ„иҜҶеҲ«еҷЁпјҲrecognizerпјүпјҢзј–иҜ‘еҷЁпјҲparserпјүе’Ңи§ЈйҮҠеҷЁпјҲtranslatorпјүзҡ„жЎҶжһ¶
Hibernateе°ұжҳҜдҪҝз”ЁдәҶиҜҘеҲҶжһҗе·Ҙе…·
11.2 дёҖжқЎHQLеј•еҸ‘зҡ„жҖқиҖғ
1гҖҒжЎҲдҫӢHQL
select key from test_limit limit 1
Stage-1
TableScan Operator>Select Operator-> Limit->File OutputOperator
Stage-0
Fetch Operator
иҜ»еҸ–ж–Ү件
2гҖҒMapperдёҺInputFormat
иҜҘhive MRдҪңдёҡдёӯжҢҮе®ҡзҡ„mapperжҳҜ:
mapred.mapper.class = org.apache.hadoop.hive.ql.exec.ExecMapper
input formatжҳҜ:
hive.input.format =
org.apache.hadoop.hive.ql.io.CombineHiveInputFormat
иҜҘhive MRдҪңдёҡдёӯжҢҮе®ҡзҡ„mapperжҳҜ:
mapred.mapper.class = org.apache.hadoop.hive.ql.exec.ExecMapper
input formatжҳҜ:
hive.input.format =
org.apache.hadoop.hive.ql.io.CombineHiveInputFormat
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ