您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
mha的工作原理
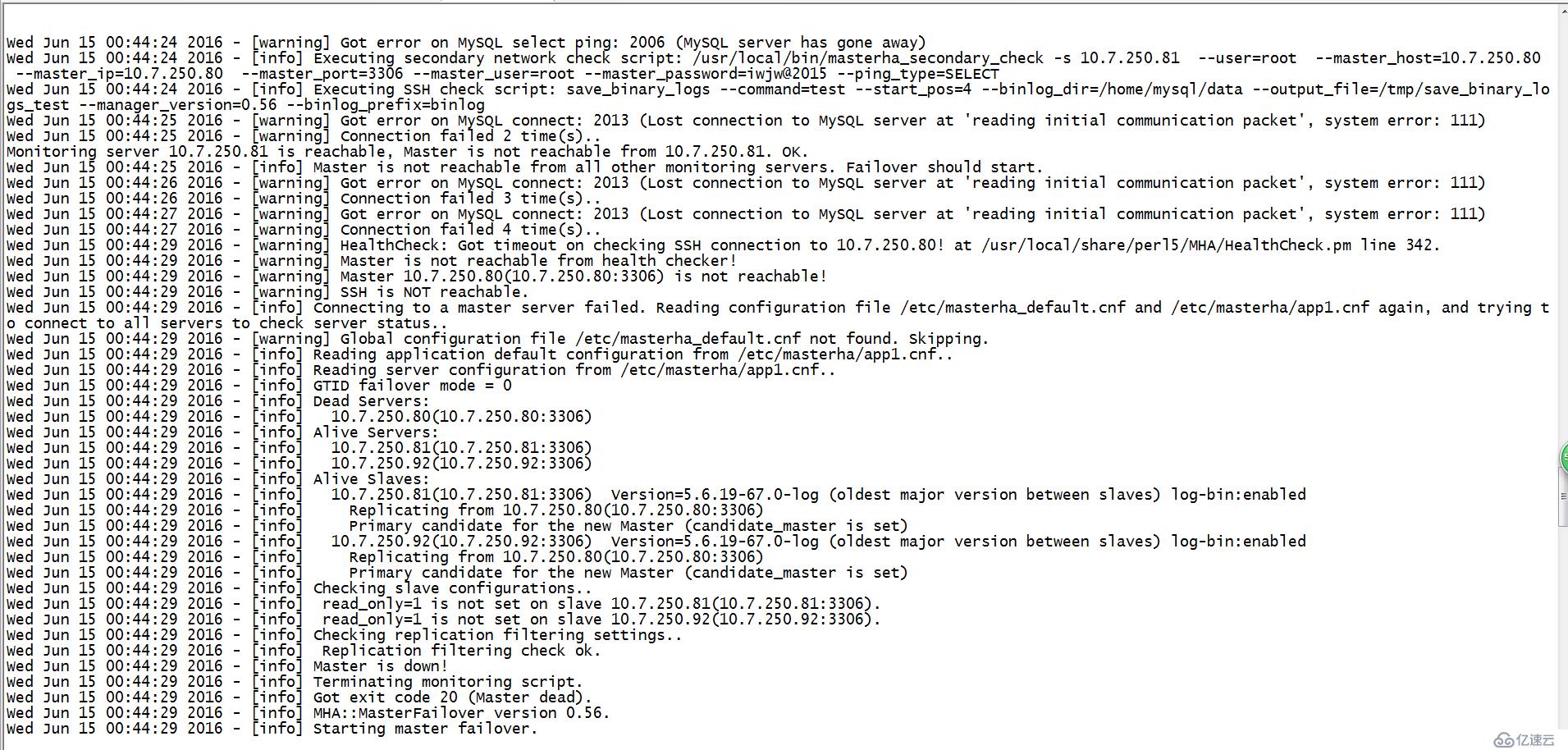
1.检查阶段
<1>.监测到maser goway
<2>.多路由检测
<3>.重复检测4次(这个次数固定的,无法修改)
<4>.检测ssh是否正常
<5>.检测配置(主要检测集群中有哪些机器,哪些机器可以正常访问,哪些机器已经dead,binlog,
候选master,relay_log_purge,read_only)
<6>.再一次检测master状态
2.关闭服务阶段
为了防止造成数据异常,关闭服务器阶段。可以调用 master_ip_failover_scripts 脚本关闭服务器
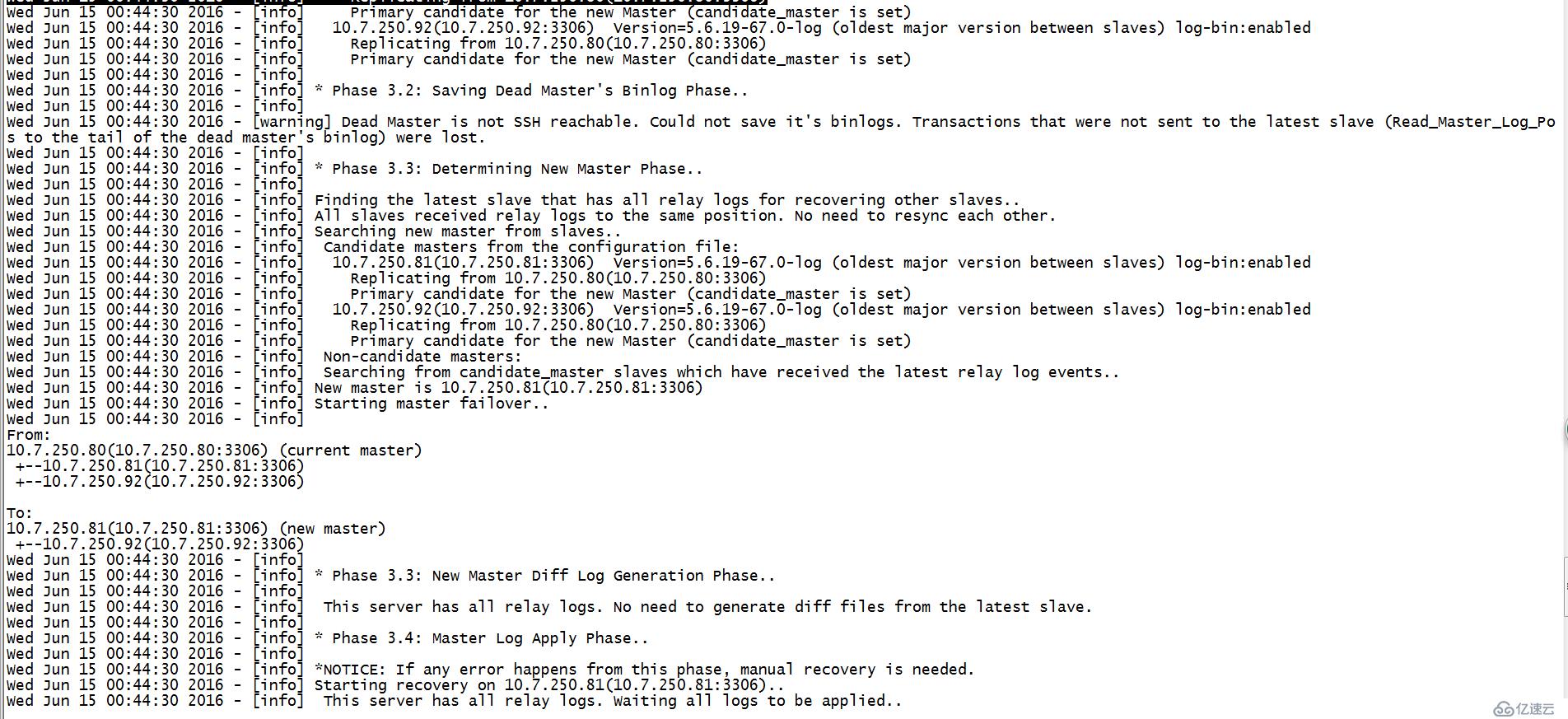
3.恢复阶段
(1).master恢复阶段
<1>.找出最近的slave和最旧的slave.
<2>.复制未发送出去的binlog并保存在manager上(T1).
<3>.使用最新的slave恢复其他的slave,使所有的slave处于同一个时间点
<4>.选取新的master
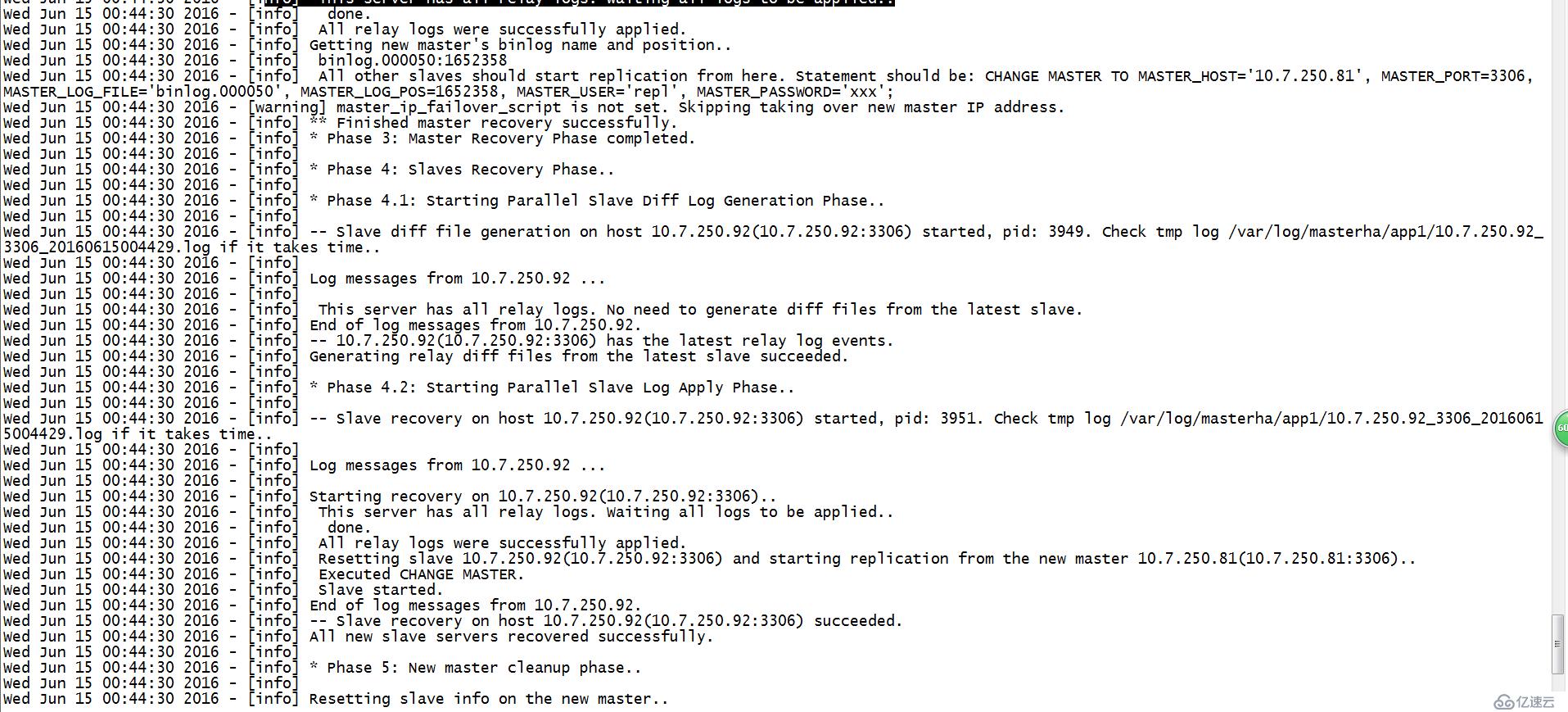
<5>.将T1和master进行对比,生成差异binlog,并重做,保存此时的binlog和pos(T2)
此时可以调用master_ip_failover_scripts对外开启服务
(2).slave恢复阶段
并行将T1和slave对比生成差异binlog,并重做
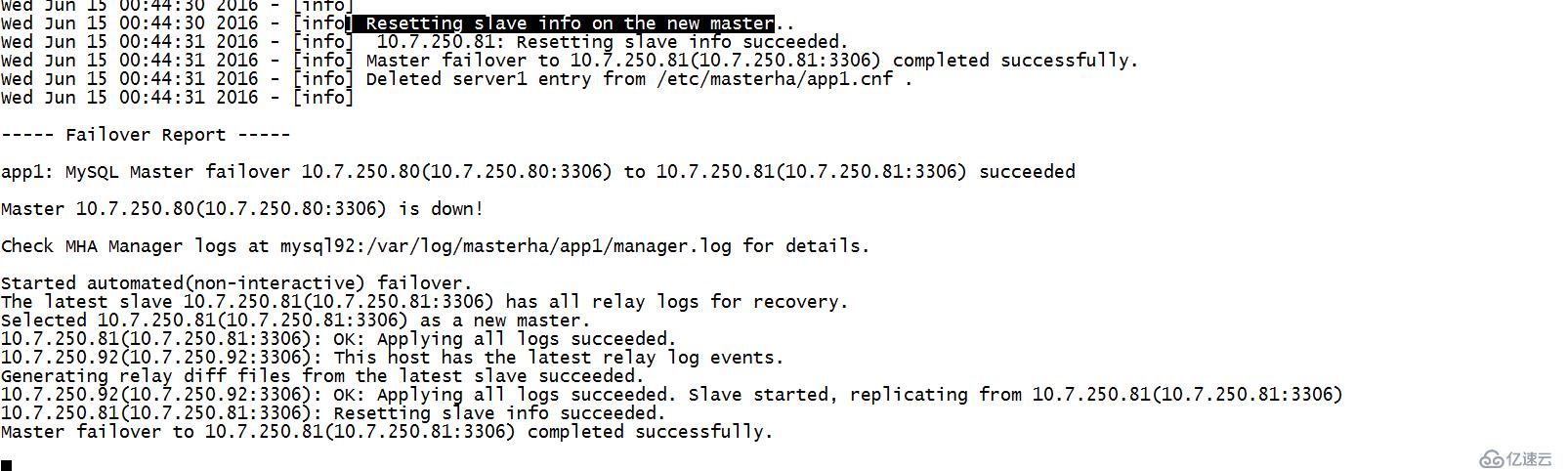
(3).slave信息修改阶段
(1).在newmaster上执行reset slave all
(2).在其他slave上执行change master binlog和pos在T2
(3).修改mha配置文件
4.检查阶段(报告阶段)
可以调用report_scripts脚本检查新的集群是否正常
具体日志如下:

免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。