您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
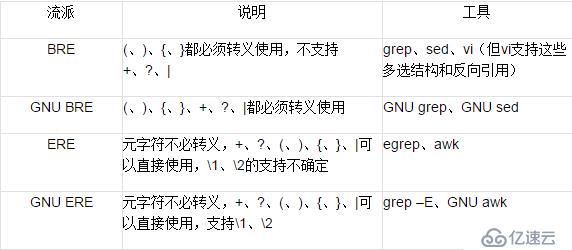
对正则表达式有基本了解的读者,一定不会陌生『\d』、『[a-z]+』之类的表达式,前者匹配一个数字字符,后者匹配一个以上的小写英文字母。但是如果你用过vi、grep、awk、sed之类Linux/Unix下的工具或许会发现,这些工具虽然支持正则表达式,语法却很不一样,照通常习惯的办法写的『\d』、『[a-z]+』之类的正则表达式,往往不是无法识别就是匹配错误。而且,这些工具自身之间也存在差异,同样的结构,有时需要转义有时不需要转义。这,究竟是为什么呢? 原因在于,Unix/Linux下的工具大多采用POSIX规范,同时,POSIX规范又可分为两种流派(flavor)。所以,首先有必要了解一下POSIX规范。
常见的正则表达式记法,其实都源于Perl,实际上,正则表达式从Perl衍生出一个显赫的流派,叫做PCRE(Perl Compatible Regular Expression),『\d』、『\w』、『\s』之类的记法,就是这个流派的特征。但是在PCRE之外,正则表达式还有其它流派,比如下面要介绍的POSIX规范的正则表达式。 POSIX的全称是Portable Operating System Interface for uniX,它由一系列规范构成,定义了UNIX操作系统应当支持的功能,所以“POSIX规范的正则表达式”其实只是“关于正则表达式的POSIX规范”,它定义了BRE(Basic Regular Expression,基本型正则表达式)和ERE(Extended Regular Express,扩展型正则表达式)两大流派。在兼容POSIX的UNIX系统上,grep和egrep之类的工具都遵循POSIX规范,一些数据库系统中的正则表达式也符合POSIX规范。
1.1 BRE
在Linux/Unix常用工具中,grep、vi、sed都属于BRE这一派,它的语法看起来比较奇怪,元字符『(』、『)』、『{』、『}』必须转义之后才具有特殊含义,所以正则表达式『(a)b』只能匹配字符串 (a)b而不是字符串ab;正则表达式『a{1,2}』只能匹配字符串a{1,2},正则表达式『a\{1,2\}』才能匹配字符串a或者aa。 之所以这么麻烦,是因为这些工具的诞生时间很早,正则表达式的许多功能却是逐步发展演化出来的,之前这些元字符可能并没有特殊的含义;为保证向后兼容,就只能使用转义。而且有些功能甚至根本就不支持,比如BRE就不支持『+』和『?』量词,也不支持多选结构『(…|…)』和反向引用『\1』、『\2』…。 不过今天,纯粹的BRE已经很少见了,毕竟大家已经认为正则表达式“理所应当”支持多选结构和反向引用等功能,没有确实太不方便。所以虽然vi属于BRE流派,但提供了这些功能。GNU也对BRE做了扩展,支持『+』、『?』、『|』,只是使用时必须写成『\+』、『\?』、『\|』,而且也支持『\1』、『\2』之类反向引用。这样,GNU的grep等工具虽然名义上属于BRE流,但更确切的名称是GNU BRE。
1.2 ERE
在Linux/Unix常用工具中,egrep、awk则属于ERE这一派,。虽然BRE名为“基本”而ERE名为“扩展”,但ERE并不要求兼容BRE的语法,而是自成一体。因此其中的元字符不用转义(在元字符之前添加反斜线会取消其特殊含义),所以『(ab|cd)』就可以匹配字符串ab或者cd,量词『+』、『?』、『{n,m}』可以直接使用。ERE并没有明确规定支持反向引用,但是不少工具都支持『\1』、『\2』之类的反向引用。 GNU出品的egrep等工具就属于ERE流(更准确的名字是GNU ERE),但因为GNU已经对BRE做了不少扩展,所谓的GNU ERE其实只是个说法而已,它有的功能GNU BRE都有了,只是元字符不需要转义而已。 下面的表格简要说明了几种POSIX流派的区别[1](其实,现在的BRE和ERE在功能上并没有什么区别,主要的差异是在元字符的转义上)。 几种POSIX流派的说明
为了方便查阅,下面再用一张表格列出基本的正则功能在常用工具中的表示法,其中的工具GNU的版本为准。 常用Linux/Unix工具中的表示法
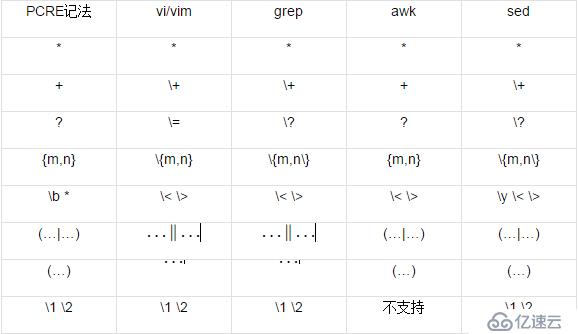
注:PCRE中常用『\b』来表示“单词的起始或结束位置”,但Linux/Unix的工具中,通常用『\<』来匹配“单词的起始位置”,用『\>』来匹配“单词的结束位置”,sed中的『\y』可以同时匹配这两个位置。
在某些文档中,你还会发现类似『[:digit:]』、『[:lower:]』之类的表示法,它们看起来不难理解(digit就是“数字”,lower就是“小写”),但又很奇怪,这就是POSIX字符组。不仅在Linux/Unix的常见工具中,甚至一些变成语言中都出现了这些字符组,为避免困惑,这里有必要简要介绍它们。
在POSIX规范中,『[a-z]』、『[aeiou]』之类的记法仍然是合法的,其意义与PCRE中的字符组也没有区别,只是这类记法的准确名称是POSIX方括号表达式(bracket expression),它主要用在Unix/Linux系统中。POSIX方括号表示法与PCRE字符组的最主要差别在于:POSIX字符组中,反斜线\不是用来转义的。所以POSIX方括号表示法『[\d]』只能匹配\和d两个字符,而不是『[0-9]』对应的数字字符。
为了解决字符组中特殊意义字符的转义问题,POSIX方括号表示法规定,如果要在字符组中表达字符](而不是作为字符组的结束标记),应当让它紧跟在字符组的开方括号之后,所以POSIX中,正则表达式『[]a]』能匹配的字符就是]和a;如果要在POSIX方括号表示法中表达字符-(而不是范围表示法),必须将它紧挨在闭方括号]之前,所以『[a-]』能匹配的字符就是a和-。
POSIX规范也定义了POSIX字符组,它近似等价于于PCRE的字符组简记法,用一个有直观意义的名字来表示某一组字符,比如digit表示“数字字符”,alpha表示“字母字符”。 不过,POSIX中还有一个值得注意的概念:locale(通常翻译为“语言环境”)。它是一组与语言和文化相关的设定,包括日期格式、货币币值、字符编码等等。POSIX字符组的意义会根据locale的变化而变化,下面的表格介绍了常见的POSIX字符组在ASCII语言环境与Unicode语言环境下的意义,供大家参考。
POSIX字符组
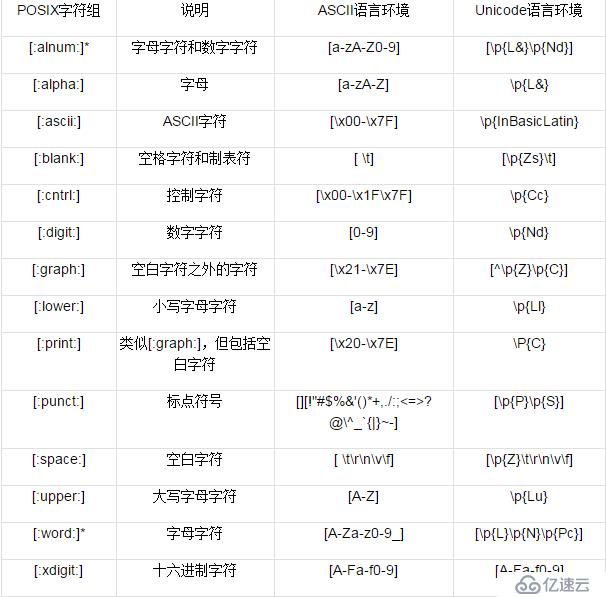
注1:标记*的字符组简记法并不是POSIX规范中的,但使用很多,一般语言中都提供,文档中也会出现。
注2:对应的Unicode属性请参考本系列文章已经刊发过的关于Unicode的部分。
POSIX字符组的使用有所不同。主要区别在于,PCRE字符组简记法可以脱离方括号直接出现,而POSIX字符组必须出现在方括号内,所以同样是匹配数字字符,单独出现时,PCRE中可以直接写『\d』,而POSIX字符组就必须写成『[[:digit:]]』。
Linux/Unix下的工具中,一般都可以直接使用POSIX字符组,而PCRE的字符组简记法『\w』、『\d』等则大多不支持,所以如果你看到『[[:space:]]』而不是『\s』,一定不要感到奇怪。 不过,在常用的编程语言中,Java、PHP、Ruby也支持使用POSIX字符组。其中Java和PHP中的POSIX字符组都是按照ASCII语言环境进行匹配;Ruby的情况则要复杂一点,Ruby 1.8按照ASCII语言环境进行匹配,而且不支持『[:word:]』和『[:alnum:]』,Ruby 1.9按照Unicode语言环境进行匹配,同时支持『[:word:]』和『[:alnum:]』。
说明:关于正则表达式的系列文章到此即告一段落,作者最近已经完成了一本关于正则表达式的书籍,其中更详细也更全面地讲解了正则表达式使用中的各种问题。该书暂定名《正则导引》,预计近期上市,有兴趣的读者敬请关注。
[1] 关于ERE和BRE的详细规范,可以参考http://pubs.opengroup.org/onlinepubs/009695399/basedefs/xbd_chap09.html。
关于作者
余晟,程序员,曾任抓虾网高级顾问,现就职于盛大创新院,感兴趣的方向包括搜索和分布式算法等。翻译爱好者,译有《精通正则表达式》(第三版)和《技术领导之路》,目前正在写作《正则表达式傻瓜书》(暂定名),希望为国内开发同行贡献一本实用的正则表达式教程。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。