жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
жң¬зҜҮж–Үз« з»ҷеӨ§е®¶еҲҶдә«зҡ„жҳҜжңүе…іжҖҺд№ҲеңЁRиҜӯиЁҖдёӯе®һзҺ°ж•°жҚ®йў„еӨ„зҗҶж“ҚдҪңпјҢе°Ҹзј–и§үеҫ—жҢәе®һз”Ёзҡ„пјҢеӣ жӯӨеҲҶдә«з»ҷеӨ§е®¶еӯҰд№ пјҢеёҢжңӣеӨ§е®¶йҳ…иҜ»е®ҢиҝҷзҜҮж–Үз« еҗҺеҸҜд»ҘжңүжүҖ收иҺ·пјҢиҜқдёҚеӨҡиҜҙпјҢи·ҹзқҖе°Ҹзј–дёҖиө·жқҘзңӢзңӢеҗ§гҖӮ
ејҖеҸ‘е·Ҙе…·пјҡRStudio
Rпјҡ3.5.2
зӣёе…іеҢ…пјҡinfotheoпјҢdiscretizationпјҢsmbinningпјҢdplyrпјҢsqldf
# иҝҷйҮҢжҲ‘们дҪҝз”Ёзҡ„жҳҜйёўе°ҫиҠұж•°жҚ®йӣҶпјҲirisпјү data(iris) head(iris)
| Sepal.Length | Sepal.Width | Petal.Length | Petal.Width | Species | |
|---|---|---|---|---|---|
| 1 | 5.1 | 3.5 | 1.4 | 0.2 | setosa |
| 2 | 4.9 | 3.0 | 1.4 | 0.2 | setosa |
| 3 | 4.7 | 3.2 | 1.3 | 0.2 | setosa |
| 4 | 4.6 | 3.1 | 1.5 | 0.2 | setosa |
| 5 | 5.0 | 3.6 | 1.4 | 0.2 | setosa |
| 6 | 5.4 | 3.9 | 1.7 | 0.4 | setosa |
зӣёе…іж•°жҚ®и§ЈйҮҠпјҡ
Sepal.LengthпјҡиҗјзүҮй•ҝеәҰ
Sepal.WidthпјҡиҗјзүҮе®ҪеәҰ
Petal.LengthпјҡиҠұз“Јй•ҝеәҰ
Petal.WidthпјҡиҠұз“Је®ҪеәҰ
Speciesпјҡйёўе°ҫиҠұе“Ғз§Қ
library(dplyr)
library(sqldf)
# дёәж•°жҚ®йӣҶеўһеҠ еәҸеҸ·еҲ—пјҲidпјү
iris$id <- c(1:nrow(iris))
# е°Ҷйёўе°ҫиҠұж•°жҚ®йӣҶдёӯ70%зҡ„ж•°жҚ®еҲ’еҲҶдёәи®ӯз»ғйӣҶ
iris_train <- sample_frac(iris, 0.7, replace = TRUE)
# дҪҝз”ЁsqlиҜӯеҸҘе°Ҷеү©дёӢзҡ„30%иҠұиҙ№дёәжөӢиҜ•йӣҶ
iris_test <- sqldf("
select *
from iris
where id not in (
select id
from iris_train
)
")
# еҺ»йҷӨеәҸеҸ·еҲ—пјҲidпјү
iris_train <- iris_train[,-6]
iris_test <- iris_test[,-6]гҖҗжіЁгҖ‘пјҡиҝҷйҮҢдҪҝз”ЁеҲ°sqldfеҢ…зҡ„еҮҪж•°sqldfеҮҪж•°жқҘж—¶й—ҙеңЁRиҜӯиЁҖдёӯдҪҝз”ЁSQLиҜӯеҸҘ
еёёи§Ғзҡ„еҮ з§Қж— зӣ‘зқЈеҲҶз®ұж–№жі•
зӯүе®ҪеҲҶз®ұжі•
зӯүйў‘еҲҶз®ұжі•
kmeansеҲҶз®ұжі•
# еҜје…Ҙж— зӣ‘зқЈеҲҶз®ұеҢ…вҖ”вҖ”infotheo library(infotheo) # еҲҶжҲҗеҮ дёӘеҢәеҹҹ nbins <- 3
### зӯүе®ҪеҲҶз®ұзҡ„еҺҹзҗҶйқһеёёз®ҖеҚ•пјҢе°ұжҳҜжҢүз…§зӣёеҗҢзҡ„й—ҙи·қе°Ҷж•°жҚ®еҲҶжҲҗзӣёеә”зҡ„зӯүеҲҶ # е°Ҷиҝһз»ӯеһӢж•°жҚ®еҲҶжҲҗдёүд»ҪпјҢ并д»Ҙ1гҖҒ2гҖҒ3иөӢеҖј equal_width <- discretize(iris_train$Sepal.Width,"equalwidth",nbins) ### жҹҘзңӢеҲҶз®ұжғ…еҶө # жҹҘзңӢеҗ„еҲҶзұ»ж•°йҮҸ table(equal_width) # з”ЁйўңиүІиЎЁжҳҺжҳҜзӯүе®ҪеҲҶз®ұ plot(iris_train$Sepal.Width, col = equal_width$X) ### дҝқеӯҳжҜҸдёӘзӯүеҲҶеҲҮеүІзӮ№зҡ„еҖјпјҲйҳҷеҖјпјү # и®Ўз®—еҗ„дёӘеҲҶзұ»зӣёеә”зҡ„еҲҮеүІзӮ№ width <- (max(iris_train$Sepal.Width)-min(iris_train$Sepal.Width))/nbins # дҝқеӯҳйҳҷеҖј depreciation <- width * c(1:nbins) + min(iris_train$Sepal.Width)

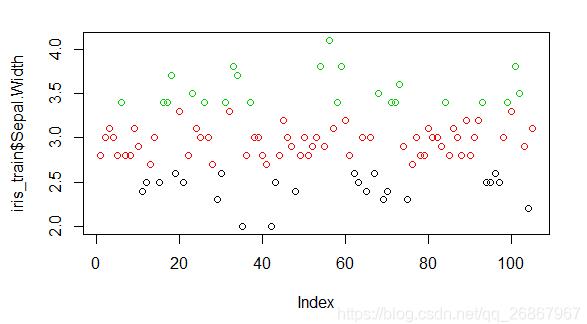
### зӯүйў‘еҲҶз®ұжҳҜе°Ҷж•°жҚ®еқҮеҢҖзҡ„еҲҶжҲҗзӣёеә”зҡ„зӯүеҲҶпјҲж•°йҮҸдёҚдёҖе®ҡжҳҜе®Ңе…ЁзӣёеҗҢзҡ„пјү # е°Ҷиҝһз»ӯеһӢж•°жҚ®еҲҶжҲҗдёүд»ҪпјҢ并д»Ҙ1гҖҒ2гҖҒ3иөӢеҖј equal_freq <- discretize(iris_train$Sepal.Width,"equalfreq",nbins) ### жҹҘзңӢеҲҶз®ұжғ…еҶө # жҹҘзңӢеҗ„еҲҶзұ»ж•°йҮҸ table(equal_width) # з”ЁйўңиүІиЎЁжҳҺжҳҜзӯүйў‘еҲҶз®ұ plot(iris_train$Sepal.Width, col = equal_freq$X) ### дҝқеӯҳжҜҸдёӘзӯүеҲҶеҲҮеүІзӮ№зҡ„еҖјпјҲйҳҷеҖјпјү data <- iris_train$Sepal.Width[order(iris_train$Sepal.Width)] depreciation <- as.data.frame(table(equal_freq))$Freq

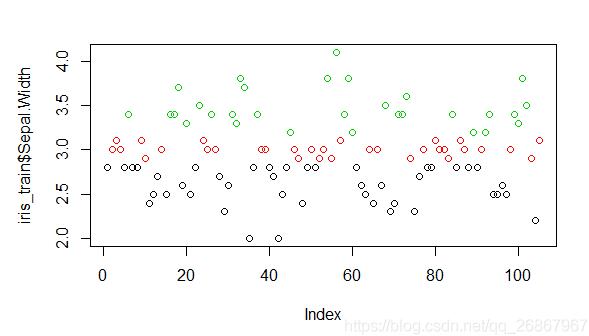
# kmeansеҲҶз®ұжі•пјҢе…Ҳз»ҷе®ҡдёӯеҝғж•°пјҢе°Ҷи§ӮеҜҹзӮ№еҲ©з”Ёж¬§ејҸи·қзҰ»и®Ўз®—дёҺдёӯеҝғзӮ№зҡ„и·қзҰ»иҝӣиЎҢеҪ’зұ»пјҢеҶҚйҮҚж–°и®Ўз®—дёӯеҝғзӮ№пјҢзӣҙеҲ°дёӯеҝғзӮ№# дёҚеҶҚеҸ‘з”ҹеҸҳеҢ–пјҢд»ҘеҪ’зұ»зҡ„з»“жһңеҒҡдёәеҲҶз®ұзҡ„з»“жһңгҖӮ # е°Ҷиҝһз»ӯеһӢж•°жҚ®еҲҶжҲҗдёүд»ҪпјҢ并д»Ҙ1гҖҒ2гҖҒ3иөӢеҖј k_means <- kmeans(iris_train$Sepal.Width, nbins) # жҹҘзңӢеҗ„еҲҶзұ»ж•°йҮҸ table(k_means$cluster) # жҹҘзңӢе®һйҷ…еҲҶз®ұзҠ¶еҶө k_means$cluster # дҝқеӯҳйҳҷеҖј # rev() зҡ„дҪңз”ЁжҳҜеҖ’зҪ®ж•°жҚ®жЎҶ # з»ҹдёҖд»Һе·ҰеҫҖеҸіпјҢд»ҺеӨ§еҲ°е°Ҹ depreciation <- rev(k_means$centers)

discretizationжҸҗдҫӣдәҶеҮ дёӘдё»иҰҒзҡ„зҰ»ж•ЈеҢ–зҡ„е·Ҙе…·еҮҪж•°пјҡ
chiMпјҢChiMз®—жі•иҝӣиЎҢзҰ»ж•ЈеҢ–
chi2, Chi2з®—жі•иҝӣиЎҢзҰ»ж•ЈеҢ–
mdlpпјҢжңҖе°ҸжҸҸиҝ°й•ҝеәҰеҺҹзҗҶ(MDLP)иҝӣиЎҢзҰ»ж•ЈеҢ–
modChi2пјҢж”№иҝӣзҡ„Chi2ж–№жі•зҰ»ж•Јж•°еҖјеұһжҖ§
disc.TopdownпјҢиҮӘдёҠиҖҢдёӢзҡ„зҰ»ж•ЈеҢ–
extendChi2пјҢжү©еұ•Chi2з®—жі•зҰ»ж•Јж•°еҖјеұһжҖ§
smbinningжҸҗдҫӣзҡ„е·Ҙе…·еҮҪж•°пјҡ
smbinning пјҢеҹәдәҺжһ„йҖ жқЎд»¶жҺЁж–ӯж ‘ctreeзҡ„зӣ‘зқЈејҸеҲҶз®ұ
### жңүзӣ‘зқЈзҡ„ж•°жҚ®зҰ»ж•ЈеҢ– library(discretization)# жңүзӣ‘зқЈеҲҶз®ұ # дҪҝз”ЁChiMergeз®—жі•еҹәдәҺеҚЎж–№жЈҖйӘҢиҝӣиЎҢиҮӘдёӢиҖҢдёҠзҡ„еҗҲ并 chi1 <- chiM(iris_train, alpha = 0.05) # alpha дёәжҳҫи‘—жҖ§жҢҮж Ү apply(chi1$Disc.data,2,table) # дҝқеӯҳйҳҷеҖј depreciation <- chi1$cutp[[2]] ## е…¶д»–жңүзӣ‘зқЈеҲҶдә«з®—жі• # chi2 <- chi2(iris,alp=0.5,del=0.05) # chi2()з®—жі• # chi3 <- modChi2(iris,alp=0.5) # modChi2()з®—жі• # chi4 <- extendChi2(iris,alp = 0.5) # extendChi2()з®—жі• # m1 <- mdlp(iris) # дҪҝз”ЁзҶөеҮҶеҲҷе°ҶжңҖе°ҸжҸҸиҝ°й•ҝеәҰдҪңдёәеҒңжӯўи§„еҲҷжқҘзҰ»ж•ЈеҢ– # d1 <- disc.Topdown(iris,method=1) # иҜҘеҠҹиғҪе®һзҺ°дәҶдёүз§ҚиҮӘдёҠиҖҢдёӢзҡ„зҰ»ж•ЈеҢ–з®—жі•пјҲCAIMпјҢCACCпјҢAmevaпјү

# еҲҶз®ұеүҚж•°жҚ®еҮҶеӨҮ library(smbinning) # жҹҘзңӢжөӢиҜ•з”ЁдҫӢ head(smbsimdf1)
| fgood | cbs1 | cbs2 | cbinq | cbline | cbterm | cblineut | cbtob | cbdpd | cbnew | pmt | tob | dpd | dep | dc | od | home | inc | dd | online | rnd | period |
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 1 | 60.11 | NA | 02 | 2 | 00 | 47.51361 | 5 | No | No | M | 2 | 00No | 10481.40 | 20 | 01 | No | W06 | 00 | Yes | 0.46641029 | 2018-03-31 |
| 1 | 45.62 | 66.72 | 02 | 2 | 02 | 52.36222 | 4 | No | No | A | 1 | 02Hi | 10182.43 | 17 | 01 | No | W10 | 00 | Yes | 0.91980286 | 2018-05-31 |
| 1 | 30.86 | 66.94 | 02 | 2 | 00 | 35.89640 | 5 | No | Yes | M | 2 | 02Hi | 9645.37 | 23 | 00 | No | W05 | 00 | Yes | 0.33804009 | 2018-07-31 |
| 1 | 62.38 | 49.12 | 02 | 3 | 01 | 41.93578 | 6 | No | No | P | 4 | 00No | 13702.76 | 31 | 01 | No | 00 | Yes | 0.76475600 | 2017-12-31 | |
| 1 | 54.36 | 41.22 | 00 | 1 | 00 | 44.23662 | 5 | No | No | P | 4 | 00No | 18720.09 | 26 | 02 | Yes | W08 | 01 | Yes | 0.58563795 | 2018-02-28 |
| 1 | 68.78 | 50.80 | 00 | 0 | 00 | 43.59248 | 7 | Yes | Yes | A | 4 | 01Lo | 10217.07 | 31 | 00 | No | W09 | 00 | Yes | 0.05756396 | 2018-03-31 |
гҖҗжіЁгҖ‘пјҡиҝҷйҮҢд№ӢжүҖд»ҘдёҚйҖӮз”Ёйёўе°ҫиҠұж•°жҚ®йӣҶзҡ„еҺҹеӣ еңЁдәҺпјҢиҝҷдёӘеҮҪж•°зҡ„дҪҝз”ЁжқЎд»¶иҫғдёәиӢӣеҲ»гҖӮйҰ–е…Ҳе®ғдёҚе…Ғи®ёж•°жҚ®йӣҶзҡ„еҲ—еҗҚдёӯеҗ«жңү вҖң.вҖқ ,жҜ”еҰӮ йёўе°ҫиҠұж•°жҚ®йӣҶдёӯзҡ„вҖңSepal.WidthвҖқе°ұдёҚеҸҜд»ҘгҖӮ
е…¶ж¬Ўе®ғиҰҒжұӮз”ЁдәҺеӯҰд№ зҡ„еҲ—еҝ…йЎ»жҳҜдәҢеҲҶзұ»пјҢдё”ж•°жҚ®зұ»еһӢеҝ…йЎ»жҳҜnumericпјҢдәҢеҲҶзұ»зҡ„еҖјд№ҹеҝ…йЎ»жҳҜпјҲ0пјҢ 1пјү гҖӮд№ҹжҳҜеӣ дёәиҝҷдәӣеҺҹеӣ пјҢдёәдәҶж–№дҫҝеңЁиҝҷйҮҢдҪҝз”ЁеҢ…дёӯиҮӘеёҰзҡ„ж•°жҚ®йӣҶгҖӮ
# дҪҝз”ЁsmbinningеҮҪж•°иҝӣиЎҢеҲҶз®ұпјҢdf дёәеҺҹе§Ӣж•°жҚ®пјҢyиЎЁзӨәзӣ®ж Үж ҮзӯҫпјҢxиЎЁзӨәйңҖиҰҒеҲҶз®ұзҡ„ж Үзӯҫresult <- smbinning(df = smbsimdf1,y = "fgood",x = "cbs1") # жҹҘзңӢеҲҶз®ұз»“жһңзҡ„еҲҶеёғжғ…еҶөпјҢдёҚиүҜзҺҮе’ҢиҜҒжҚ®жқғйҮҚ par(mfrow=c(2,2)) boxplot(smbsimdf1$cbs1~smbsimdf1$fgood,horizontal=T, frame=F, col="lightgray",main="Distribution") smbinning.plot(result,option="dist") smbinning.plot(result,option="badrate") smbinning.plot(result,option="WoE")
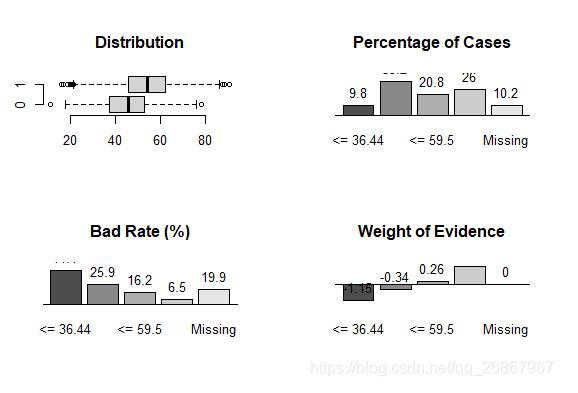
result$ivtable # зӣёе…ійҮҚиҰҒдҝЎжҒҜ result$ctree # еҶізӯ–ж ‘ result$cuts # йҳҷеҖј smbinning.sql(result) # иҫ“еҮәзӣёеә”зҡ„sqlиҜӯеҸҘ

# дҪҝз”Ёи®ӯз»ғеҘҪзҡ„еҮҪж•°еҜ№ж•°жҚ®иҝӣиЎҢеҲҶз®ұпјҲи®ӯз»ғйӣҶе’ҢжөӢиҜ•йӣҶйғҪйңҖиҰҒпјү smbsimdf1 <- smbinning.gen(smbsimdf1, result, chrname = "gcbs1") # жҹҘзңӢеҲҶз®ұжғ…еҶө table(smbsimdf1$gcbs1)
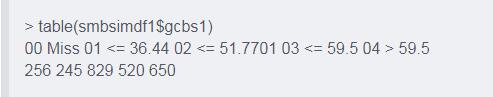
гҖҗжіЁгҖ‘пјҡйҷӨжӯӨд№ӢеӨ–д№ҹеҸҜд»Ҙз”Ёsmbinning.sql(result) з”ҹжҲҗзҡ„sqlиҜӯеҸҘпјҢй…ҚеҗҲsqldfеҢ…иҝӣиЎҢж•°жҚ®еҲҶз®ұж“ҚдҪңгҖӮ
дёҠиҝ°ж–№жі•дёӯпјҢйҷӨдәҶжңҖеҗҺдёҖз§Қж–№жі•пјҢжҲ‘们йғҪжІЎжңүе°Ҷи®ӯз»ғеҘҪзҡ„еҮҪж•°з”ЁдәҺжөӢиҜ•йӣҶгҖӮдҪҶжҳҜеңЁе®һйҷ…зҡ„еҲҶжһҗпјҢжҲ‘们让数жҚ®зҰ»ж•ЈеҢ–жңҖдё»иҰҒзҡ„зӣ®зҡ„жӣҙеӨҡзҡ„жҳҜдёәдәҶйҷҚдҪҺжңәеҷЁеӯҰд№ зҡ„иҙҹжӢ…гҖӮ
еӣ жӯӨжҲ‘们йҷӨдәҶйңҖиҰҒеҜ№и®ӯз»ғйӣҶиҝӣиЎҢеҲҶз®ұж“ҚдҪңд№ӢеӨ–пјҢе°ҶеҗҢж ·зҡ„еҲҶз®ұж–№жі•дҪңз”ЁдёҺжөӢиҜ•йӣҶгҖӮйӮЈд№ҲдёӢйқўжҲ‘们е°ұе°ҶдҪҝз”Ёд№ӢеүҚеҫ—еҲ°зҡ„йҳҷеҖјпјҢеҜ№жөӢиҜ•йӣҶиҝӣиЎҢеҲҶдә«ж“ҚдҪңгҖӮ
### еҜ№жөӢиҜ•йӣҶиҝӣиЎҢеҲҶз®ұж“ҚдҪң
# дҪҝз”Ёд№ӢеүҚдҝқеӯҳзҡ„йҳҷеҖј
# иҝҷйҮҢд№ӢжүҖд»ҘиҰҒеүҚеҗҺеҠ дёҠInfпјҢжҳҜдёәдәҶи®©е®ғзҡ„иҢғеӣҙиғҪеӨҹеҗ‘жӯЈиҙҹж— з©·е»¶дјё
# (-Inf, a],[b, Inf)
break1<-c(-Inf,depreciation,Inf)
labels = c("е·®", "дёӯ", "иүҜ", "дјҳ")
# 第дёҖдёӘеҖјжҳҜж•°жҚ®
# 第дёҖдёӘеҖјжҳҜеҲҶз®ұзҡ„еҢәй—ҙ
# 第дёүдёӘеҖјжҳҜжӣҝжҚўжҲҗзҡ„ж•°
# ordered_resultиЎЁзӨәиў«жӣҝжҚўжҲҗзҡ„ж•°жҳҜеҗҰжңүеүҚеҗҺйЎәеәҸ
iris_test$Sepal.Width <- cut(iris_test$Sepal.Width,break1,labels,ordered_result = T)
iris_test$Sepal.Width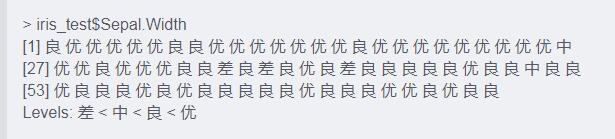
д»ҘдёҠе°ұжҳҜжҖҺд№ҲеңЁRиҜӯиЁҖдёӯе®һзҺ°ж•°жҚ®йў„еӨ„зҗҶж“ҚдҪңпјҢе°Ҹзј–зӣёдҝЎжңүйғЁеҲҶзҹҘиҜҶзӮ№еҸҜиғҪжҳҜжҲ‘们ж—Ҙеёёе·ҘдҪңдјҡи§ҒеҲ°жҲ–з”ЁеҲ°зҡ„гҖӮеёҢжңӣдҪ иғҪйҖҡиҝҮиҝҷзҜҮж–Үз« еӯҰеҲ°жӣҙеӨҡзҹҘиҜҶгҖӮжӣҙеӨҡиҜҰжғ…敬иҜ·е…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“гҖӮ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ