您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
今天就跟大家聊聊有关使用shell脚本怎么备份数据库,可能很多人都不太了解,为了让大家更加了解,小编给大家总结了以下内容,希望大家根据这篇文章可以有所收获。
Shell 脚本
Shell 脚本(shell script),是一种为 shell 编写的脚本程序。 业界所说的 shell 通常都是指 shell 脚本,但读者朋友要知道,shell 和 shell script 是两个不同的概念。
场景:
一台MySQL服务器,跑着5个数据库,在没有做主从的情况下,需要对这5个库进行备份
需求:
1)每天备份一次,需要备份所有的库
2)把备份数据存放到/data/backup/下
3)备份文件名称格式示例:dbname-2019-11-23.sql
4)需要对1天以前的所有sql文件压缩,格式为gzip
5)本地数据保留1周
6)需要把备份的数据同步到远程备份中心,假如本机可以直接通过rsync命令同步,同步目标地址为192.168.234.125,数据存放目录:/data/mysqlbak/
7)远程备份数据要求保留1个月
脚本:
#!/bin/bash mysqldump="/usr/local/mysql/bin/mysqldump" bakdir="/data/backup" bakuser="backup" passwd="backup123" d1=`date +%F` d2=`date +%d` #将后面所有的输出都写入到日志 exec &> tmp/bak.log echo "mysql bakup begin at `date`" #循环遍历数据库并导出 for db in db1 db2 db3 db4 db5 do $mysqldump -u$bakuser -p$passwd $db > $bakdir/$db-$d1.sql done #压缩一天前的备份文件 find $bakdir -type f -name "*.sql" -mtime +1 |xargs gzip #删除一周前的被封文件 find $bakdir -type f -mtime +7 |xargs rm #把当天的备份文件同步到远程机器 for db in db1 db2 db3 db4 db5 do rsync -a $bakdir/$db-$d1.sql rsuser@192.168.234.125::/data/mysqlbak/$db-$d2.sql done echo "mysql bakup end at `date`"
补充:
1.远程机器存放的备份文件以库名-日期的具体日命名,就实现了自动保留30天(比如15号备份的文件db1-15.sql下个月1号的备份文件将会覆盖该文件)
2.当数据库较大时,使用mysqldump备份速度会非常慢,这时该使用xtarbackup工具备份或mysql主从复制
生产环境中一个业务通常跑在多台服务器上,也就是所谓的负载均衡,那么这些机器上运行的代码必须要保持一致,如何实现一致呢?有两种方案
1.通过共享的方式
如果机器量不多,可以使用NFS实现,当然如果要求稳定性最好是使用专业的存储设备(NAS、SAN等),这种方式架构如下:
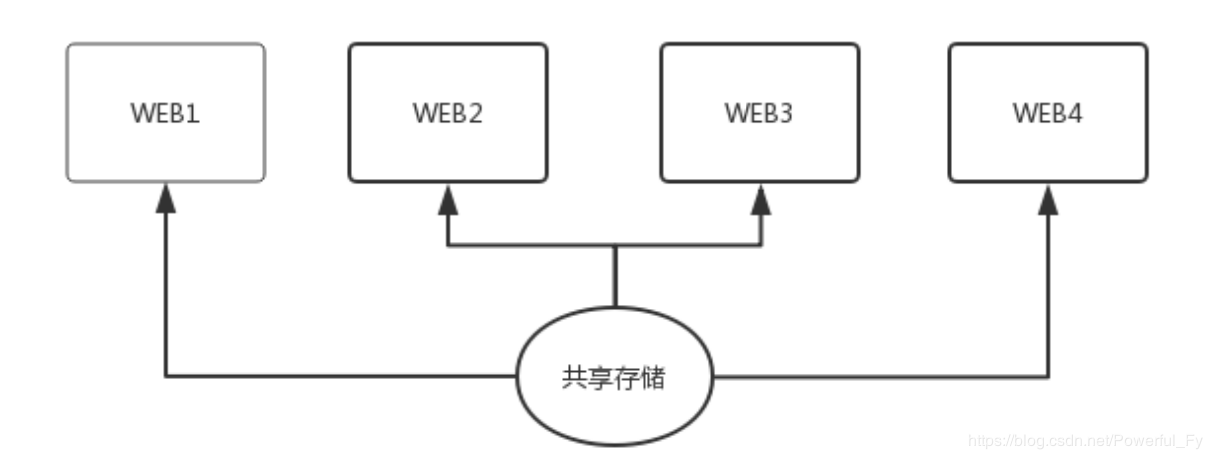
这种架构的优点是方便维护,比如有代码更新时,只需要更新一台机器上的代码,则其他机器上都会跟着更新。缺点是,机器量大了的话,共享存储会成为瓶颈,甚至由于对文件的争抢造成性能问题。还有一点,共享存储这里是一个很大的单点隐患,不出故障一切都OK,一旦出了故障,则整个业务都挂掉,影响非常大。
2.分布式
既然通过共享的方式有不少缺点,那么就选择另外一种方式,即把代码存到每一台WEB服务器本地磁盘上,如下图所示:
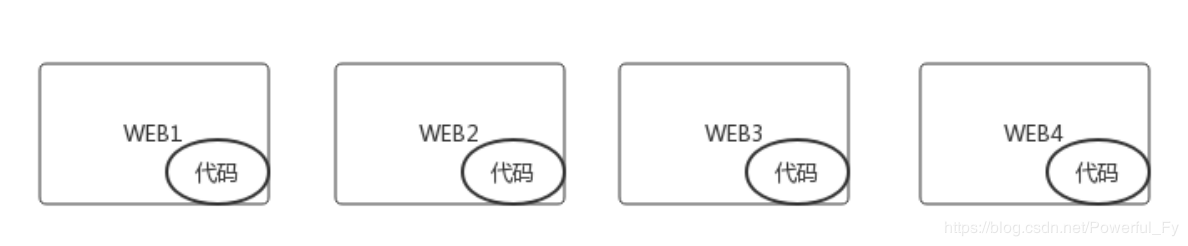
这样做的好处是,没有存储性能问题,没有资源争抢冲突,也没有单点故障的隐患。缺点是,每次代码更新需要对所有web机器进行更新,比较繁琐。虽然步骤繁琐,但大多数企业都会选择该方式。
通过shell脚本+expect批量发布代码到多台web服务器:
前提:
1)提供一个存放所有web服务器的IP列表文件ip.list
2)假设所有web服务器上有一个普通用户user,密码为user123,该用户为同步代码用户
3)每次代码上线会提供一个文件列表file.list(即要更改的文件的列表)
脚本:
#/bin/bash
#提醒用户,是否更新了要上线的代码列表文件
read -p "你是否已经更新了文件列表./file.list?确认请输入y或者Y,否则按其他任意键退出脚本。" c
#如果直接按回车,也会退出脚本
if [ -z "$c" ]
then
exit 1
fi
if [ $c == "y" -o $c == "Y" ]
then
echo "脚本将在2秒后,继续执行。"
#每秒输出一个.共输出两个.
for i in 1 2
do
echo -n "."
sleep 1
done
echo
else
exit 1
fi
#判断有无./rsync.exp文件
[ -f ./rsync.exp ] && rm -f ./rsync.exp
#定义rsync.exp
cat >./rsync.exp <<EOF
#!/usr/bin/expect
set passwd "user123"
set host [lindex \$argv 0]
set file [lindex \$argv 1]
spawn rsync -avR --files-from=\$file / user@\$host:/
expect {
"yes/no" {send "yes\r"}
"password:" {send \$passwd\r}
}
expect eof
EOF
chmod a+x ./rsync.exp
#定义检测文件是否存在的函数
if_file_exist()
{
if [ ! -f $1 ]
then
echo "文件$1不存在,请检查。"
exit 1
}
#ip.list为所有WEB机器的ip列表
#file.list为要同步的文件列表
if_file_exist ./ip.list
if_file_exist ./file.list
for ip in `cat ./ip.list`
do
./rsync.exp $ip ./file.list
done
#善后处理
rm -f ./rsync.exp注意:在每台web服务器上创建的代码同步用户需要有代码所在目录的写入权限
看完上述内容,你们对使用shell脚本怎么备份数据库有进一步的了解吗?如果还想了解更多知识或者相关内容,请关注亿速云行业资讯频道,感谢大家的支持。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。