жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
иҝҷзҜҮж–Үз« е°ҶдёәеӨ§е®¶иҜҰз»Ҷи®Іи§Јжңүе…іеҰӮдҪ•дјҳеҢ–Shellи„ҡжң¬ж•ҲзҺҮпјҢе°Ҹзј–и§үеҫ—жҢәе®һз”Ёзҡ„пјҢеӣ жӯӨеҲҶдә«з»ҷеӨ§е®¶еҒҡдёӘеҸӮиҖғпјҢеёҢжңӣеӨ§е®¶йҳ…иҜ»е®ҢиҝҷзҜҮж–Үз« еҗҺеҸҜд»ҘжңүжүҖ收иҺ·гҖӮ
дёҖгҖҒе…ҲиҜҙдёҖдёӢShellи„ҡжң¬иҜӯиЁҖиҮӘиә«зҡ„еұҖйҷҗжҖ§
дҪңдёәи§ЈйҮҠеһӢзҡ„и„ҡжң¬иҜӯиЁҖпјҢеӨ©з”ҹе°ұжңүж•ҲзҺҮдёҠиҫ№зҡ„зјәйҷ·гҖӮе°Ҫз®Ўе®ғи°ғз”Ёзҡ„е…¶д»–е‘Ҫд»ӨеҸҜиғҪж•ҲзҺҮдёҠжҳҜдёҚй”ҷзҡ„гҖӮ
Shellи„ҡжң¬зЁӢеәҸзҡ„жү§иЎҢжҳҜйЎәеәҸжү§иЎҢпјҢиҖҢйқһ并иЎҢжү§иЎҢзҡ„гҖӮиҝҷеҫҲеӨ§зЁӢеәҰдёҠжөӘиҙ№дәҶеҸҜиғҪиғҪеҲ©з”ЁдёҠзҡ„зі»з»ҹиө„жәҗгҖӮ
ShellжҜҸжү§иЎҢдёҖдёӘе‘Ҫд»Өе°ұеҲӣе»әдёҖдёӘж–°зҡ„иҝӣзЁӢпјҢеҰӮжһңи„ҡжң¬зј–еҶҷиҖ…жІЎжңүиҝҷж–№йқўж„ҸиҜҶпјҢзј–еҶҷи„ҡжң¬дёҚеҪ“зҡ„иҜқпјҢжҳҜйқһеёёжөӘиҙ№зі»з»ҹиө„жәҗзҡ„гҖӮ
дәҢгҖҒжҲ‘们еңЁShellи„ҡжң¬иҜӯиЁҖзҡ„еұҖйҷҗжҖ§дёҠе°ҪеҸҜиғҪзҡ„йҖҡиҝҮжҲ‘们жңүз»ҸйӘҢзҡ„зј–з ҒжқҘжҸҗй«ҳи„ҡжң¬зҡ„ж•ҲзҺҮгҖӮ
1гҖҒжҜ”еҰӮжҲ‘жғіеҒҡдёҖдёӘеҫӘзҺҜеӨ„зҗҶж•°жҚ®пјҢеҸҜиғҪжҳҜз®ҖеҚ•зҡ„еӨ„зҗҶдёҖдёӢж•°жҚ®пјҢиҝҷж ·дјҡи®©дәәжҜ”иҫғе®№жҳ“е°ұжғіеҲ°ShellйҮҢзҡ„еҫӘзҺҜзұ»дјјиҝҷж ·пјҡ
д»Јз ҒеҰӮдёӢ:
sum=0
for((i=0;i<100000;i++))
do
sum=$(($sum+$i))
done
echo $sum
жҲ‘们еҸҜд»ҘдҪҝз”ЁtimeиҝҷдёӘи„ҡжң¬жқҘжөӢиҜ•дёҖдёӢеҚҒдёҮж¬ЎеҫӘзҺҜзҡ„дёүж¬Ўжү§иЎҢиҖ—ж—¶пјҡ
real 0m2.115s
user 0m1.975s
sys 0m0.138s
real 0m2.493s
user 0m2.173s
sys 0m0.254s
real 0m2.085s
user 0m1.886s
sys 0m0.195s
е№іеқҮиҖ—ж—¶2.2sпјҢеҰӮжһңдҪ зҹҘйҒ“awkе‘Ҫд»ӨйҮҢзҡ„еҫӘзҺҜзҡ„иҜқпјҢйӮЈжӣҙеҘҪдәҶпјҢжҲ‘们жқҘжөӢиҜ•дёҖдёӢеҗҢж•°жҚ®и§„жЁЎзҡ„еҫӘзҺҜдёүж¬Ўжү§иЎҢиҖ—ж—¶пјҡ
д»Јз ҒеҰӮдёӢ:
awk 'BEGIN{
sum=0;
for(i=0;i<100000;i++)
sum=sum+i;
print sum;
}'
real 0m0.023s
user 0m0.018s
sys 0m0.005s
real 0m0.020s
user 0m0.018s
sys 0m0.002s
real 0m0.021s
user 0m0.019s
sys 0m0.003s
дҪ йғҪдёҚж•ўжғіиұЎе№іеқҮж—¶й—ҙд»…0.022sпјҢеҹәжң¬дёҠзәҜеҫӘзҺҜзҡ„ж•ҲзҺҮе·Із»ҸжҜ”Shellй«ҳеҮәдёӨдҪҚж•°йҮҸзә§дәҶгҖӮдәӢе®һдёҠдҪ еҶҚи·‘зҷҫдёҮж¬Ўзҡ„еҫӘзҺҜдҪ дјҡеҸ‘зҺ°Shellе·Із»ҸжҜ”иҫғеҗғеҠӣдәҶпјҢеҚғдёҮзә§зҡ„жӣҙжҳҜиү°йҡҫгҖӮжүҖд»ҘдҪ еә”иҜҘжіЁж„ҸдҪ зҡ„зЁӢеәҸе°ҪйҮҸдҪҝз”ЁawkжқҘеҒҡеҫӘзҺҜж“ҚдҪңгҖӮ
2гҖҒе…ідәҺжӯЈеҲҷпјҢз»ҸеёёеҶҷShellзҡ„еҗҢеӯҰйғҪжҳҺзҷҪе®ғзҡ„йҮҚиҰҒжҖ§пјҢдҪҶжҳҜдҪ зңҹзҡ„иғҪй«ҳж•ҲдҪҝз”Ёе®ғеҗ—пјҹ
дёӢиҫ№дёҫдёӘдҫӢеӯҗпјҡзҺ°еңЁжҲ‘жңүдёҖдёӘ1694617иЎҢзҡ„ж—Ҙеҝ—ж–Ү件 action.logпјҢе®ғзҡ„еҶ…е®№зұ»дјјпјҡ
2012_02_07 00:00:04 1977575701 183.10.69.47 login 500004 1977575701 old /***/port/***.php?вҖҰ
жҲ‘зҺ°еңЁжғіиҺ·еҸ–//д№Ӣй—ҙзҡ„portзҡ„еӯ—з¬ҰдёІпјҢжҲ‘еҸҜд»Ҙиҝҷж ·пјҡ
awk -F'/' вҖҳ{print $3}' < 7action.log > /dev/null
дҪҶжҳҜдҪ дёҚдјҡжғізҹҘйҒ“е®ғзҡ„ж•ҲзҺҮпјҡ
real 0m12.296s
user 0m12.033s
sys 0m0.262s
зӣёдҝЎжҲ‘пјҢжҲ‘дёҚдјҡеҶҚжғізңӢзқҖе…үж Үй—Ә12з§’зҡ„гҖӮдҪҶжҳҜеҰӮжһңиҝҷж ·жү§иЎҢпјҡ
awk вҖҳ{print $9}' < 7action.log | awk -F'/' '{print $3}' > /dev/null
иҝҷеҸҘзҡ„ж•ҲзҺҮдёүж¬ЎеҲҶеҲ«жҳҜпјҡ
real 0m3.691s
user 0m5.219s
sys 0m0.630s
real 0m3.660s
user 0m5.169s
sys 0m0.618s
real 0m3.660s
user 0m5.150s
sys 0m0.612s
е№іеқҮж—¶й—ҙеӨ§жҰӮ3.6з§’пјҢиҝҷеүҚеҗҺж•ҲзҺҮеӨ§жҰӮжңү4еҖҚзҡ„е·®и·қпјҢиҷҪ然дёҚеғҸдёҠдёҖдёӘжңүзҷҫеҖҚзҡ„е·®и·қпјҢдҪҶжҳҜд№ҹи¶іеӨҹи®©4е°Ҹж—¶еҸҳжҲҗ1е°Ҹж—¶дәҶгҖӮжҲ‘жғідҪ жҮӮиҝҷдёӘе·®и·қзҡ„гҖӮ
е…¶е®һиҝҷдёӘжӯЈеҲҷе®һдҫӢдҪ еҸҜд»Ҙе°қиҜ•жҺЁжөӢе…¶д»–зҡ„жғ…еҶөпјҢеӣ дёәжӯЈеҲҷжҜҸж¬ЎиҝҗиЎҢйғҪжҳҜйңҖиҰҒеҗҜеҠЁеӯ—з¬ҰдёІеҢ№й…Қзҡ„пјҢиҖҢдё”й»ҳи®Өзҡ„еҲҶйҡ”з¬Ұдјҡиҫғеҝ«зҡ„жҢүеӯ—ж®өеҢәеҲҶеҮәгҖӮжүҖд»ҘжҲ‘们еңЁзҹҘйҒ“дёҖдәӣж•°жҚ®и§„еҫӢд№ӢеҗҺеҸҜд»Ҙе°қиҜ•еӨ§е№…еәҰзҡ„зј©зҹӯжҲ‘们е°ҶиҰҒиҝӣиЎҢеӨҚжқӮжӯЈеҲҷеҢ№й…Қзҡ„еӯ—з¬ҰдёІпјҢиҝҷж ·дјҡж №жҚ®дҪ зј©еҮҸж•°жҚ®и§„жЁЎжңүдёҖдёӘйқһеёёжҳҺжҳҫзҡ„ж•ҲзҺҮжҸҗеҚҮпјҢдёҠиҫ№иҝҳжҳҜйӘҢиҜҒзҡ„жҜ”иҫғз®ҖеҚ•зҡ„жӯЈеҲҷеҢ№й…Қжғ…еҶөпјҢеҸӘжңүдёҖдёӘеҚ•еӯ—з¬ҰвҖң\вҖқ,дҪ еҸҜд»ҘиҜ•жғіеҰӮжһңжӯЈеҲҷиЎЁиҫҫејҸжҳҜиҝҷж ·пјҡ
$7!~/\.jpg$/&&$7~/\.[s]?html|\.php|\.xml|\/$/&&($9==200||$9==304)&&$1!~/^103\.108|^224\.215|^127\.0|^122\.110\.5/
жҲ‘жғідҪ еҸҜд»ҘжғіиұЎзҡ„еҮәдёҖдёӘзӣ®ж ҮеҢ№й…Қеӯ—з¬ҰдёІд»Һ500дёӘеӯ—з¬Ұзј©еҮҸеҲ°50дёӘеӯ—з¬Ұзҡ„ж—¶еҖҷзҡ„е·ЁеӨ§ж„Ҹд№үпјҒ
psпјҡеҸҰеӨ–иҜҰз»Ҷзҡ„жӯЈеҲҷдјҳеҢ–иҜ·зңӢиҝҷдёӘж—Ҙжңҹд№ӢеҗҺеҸ‘зҡ„дёҖзҜҮеҚҡж–ҮгҖӮ
3гҖҒеҶҚиҜҙдёҖдёӢshellзҡ„йҮҚе®ҡеҗ‘е’Ңз®ЎйҒ“гҖӮиҝҷдёӘжқЎзӣ®жҲ‘дёҚдјҡеҶҚдёҫдҫӢеӯҗпјҢеҸӘжҳҜиҜҙдёҖдёӢжҲ‘дёӘдәәзҡ„зҗҶи§ЈгҖӮ
е‘ЁжүҖе‘ЁзҹҘпјҢеҫҲеӨҡзЁӢеәҸжҲ–иҖ…иҜӯиЁҖйғҪжңүдёҖдёӘжҜ”иҫғзӘҒеҮәзҡ„ж•ҲзҺҮ瓶йўҲе°ұжҳҜIOпјҢShellд№ҹдёҚдҫӢеӨ–пјҲдёӘдәәиҝҷд№ҲиҖғиҷ‘пјүгҖӮжүҖд»Ҙе»әи®®е°ҪеҸҜиғҪзҡ„е°‘з”ЁйҮҚе®ҡеҗ‘жқҘиҝӣиЎҢиҫ“е…Ҙиҫ“еҮәиҝҷж ·зҡ„ж“ҚдҪңжҲ–иҖ…еҲӣе»әдёҙж—¶ж–Ү件жқҘдҫӣеҗҺз»ӯдҪҝз”ЁпјҢеҪ“然пјҢеҰӮжһңеҝ…йЎ»иҝҷд№Ҳе№Ізҡ„ж—¶еҖҷйӮЈе°ұиҝҷд№Ҳе№Іеҗ§пјҢжҲ‘еҸӘжҳҜи®ІдёҖдёӘе°ҪйҮҸзҡ„иҝҮзЁӢгҖӮ
жҲ‘们еҸҜд»Ҙз”ЁShellжҸҗдҫӣзҡ„з®ЎйҒ“жқҘе®һзҺ°е‘Ҫд»Өй—ҙж•°жҚ®зҡ„дј йҖ’гҖӮеҰӮжһңиҝӣиЎҢиҝһз»ӯзҡ„еҜ№ж•°жҚ®иҝӣиЎҢиҝҮж»ӨжҖ§е‘Ҫд»Өзҡ„ж—¶еҖҷпјҢе°ҪйҮҸжҠҠдёҖж¬ЎжҖ§иҝҮж»ӨиҫғеӨҡзҡ„е‘Ҫд»Өж”ҫеңЁеүҚиҫ№пјҢиҝҷдёӘеҺҹеӣ йғҪжҮӮеҗ§пјҹеҮҸе°‘ж•°жҚ®дј йҖ’规模гҖӮ
жңҖеҗҺжҲ‘жғіиҜҙзҡ„иҝһз®ЎйҒ“д№ҹе°ҪйҮҸзҡ„е°‘з”Ёзҡ„пјҢиҷҪ然管йҒ“жҜ”жӯЈеёёзҡ„еҗҢе®ҡеҗ‘IOеҝ«еҮ дёӘж•°йҮҸзә§зҡ„ж ·еӯҗпјҢдҪҶжҳҜйӮЈд№ҹжҳҜйңҖиҰҒж¶ҲиҖ—йўқеӨ–зҡ„иө„жәҗзҡ„пјҢеҘҪеҘҪи®ҫи®ЎдҪ зҡ„д»Јз ҒжқҘеҮҸе°‘иҝҷдёӘејҖй”Җеҗ§гҖӮжҜ”еҰӮsort | uniq е‘Ҫд»ӨпјҢе®Ңе…ЁеҸҜд»ҘдҪҝз”Ё sort -u жқҘе®һзҺ°гҖӮ
4гҖҒеҶҚиҜҙдёҖдёӢShellи„ҡжң¬зЁӢеәҸзҡ„йЎәеәҸжү§иЎҢгҖӮиҝҷеқ—зҡ„дјҳеҢ–еҸ–еҶідәҺдҪ зҡ„зі»з»ҹиҙҹиҪҪжҳҜеҗҰиҫҫеҲ°дәҶжһҒйҷҗпјҢеҰӮжһңдҪ зҡ„зі»з»ҹиҝһе‘Ҫд»Өзҡ„йЎәеәҸжү§иЎҢиҙҹиҪҪйғҪеҲ°дәҶдёҖдёӘиҫғй«ҳзҡ„зәҝзҡ„иҜқпјҢдҪ е°ұжІЎжңүеҝ…иҰҒиҝӣиЎҢShellи„ҡжң¬зЁӢеәҸзҡ„并иЎҢж”№йҖ дәҶгҖӮдёӢиҫ№з»ҷеҮәдёҖдёӘдҫӢеӯҗпјҢеҰӮжһңдҪ иҰҒжЁЎд»ҝиҝҷдёӘдјҳеҢ–пјҢиҜ·дҝқиҜҒдҪ зҡ„зі»з»ҹиҝҳиғҪжңүиҙҹиҪҪз©әй—ҙгҖӮжҜ”еҰӮзҺ°еңЁжңүиҝҷж ·дёҖдёӘзЁӢеәҸпјҡ
supportdatacommand1
supportdatacommand2
supportdatacommand3
supportdatacommand4
supportdatacommand5
supportdatacommand6
need13datacommand
need24datacommand
need56datacommand
еӨ§ж„Ҹе°ұжҳҜжңү6дёӘжҸҗдҫӣж•°жҚ®зҡ„е‘Ҫд»ӨеңЁеүҚиҫ№пјҢеҗҺйқўжңү3дёӘйңҖиҰҒж•°жҚ®зҡ„е‘Ҫд»ӨпјҢ第дёҖдёӘйңҖиҰҒж•°жҚ®зҡ„е‘Ҫд»ӨйңҖиҰҒж•°жҚ®13пјҢ第дәҢдёӘйңҖиҰҒ24пјҢ第дёүдёӘйңҖиҰҒ56гҖӮдҪҶжҳҜжӯЈеёёжғ…еҶөдёӢShellдјҡйЎәеәҸзҡ„жү§иЎҢиҝҷдәӣе‘Ҫд»ӨпјҢд»Һsupportdatacommand1,дёҖжқЎдёҖжқЎжү§иЎҢеҲ°need56datacommandгҖӮиҝҷж ·зҡ„иҝҮзЁӢдҪ зңӢзқҖжҳҜдёҚжҳҜд№ҹеҫҲиӣӢз–јпјҹжҳҺжҳҺеҸҜд»ҘжӣҙеҘҪзҡ„еҒҡиҝҷдёҖеқ—зҡ„пјҢиӣӢз–јзҡ„зЁӢеәҸеҸҜд»Ҙиҝҷж ·ж”№йҖ пјҡ
д»Јз ҒеҰӮдёӢ:
supportdatacommand1 &
supportdatacommand2 &
supportdatacommand3 &
supportdatacommand4 &
supportdatacommand5 &
supportdatacommand6 &
#2012-02-22 psпјҡиҝҷйҮҢзҡ„еҫӘзҺҜеҲӨж–ӯеҗҺеҸ°е‘Ҫд»ӨжҳҜеҗҰжү§иЎҢе®ҢжҜ•жҳҜжңүй—®йўҳзҡ„пјҢpidnumеҫӘ#зҺҜеҮҸеҲ°жңҖеҗҺд№ҹиҝҳжҳҜ1дёҚдјҡеҫ—еҲ°0еҖјпјҢе…·дҪ“и§ЈеҶіеҠһжі•зңӢйҷ„еҪ•пјҢеӣ дёәиҝҳжңүи§ЈйҮҠпјҢе°ұдёҚеңЁиҝҷ#йҮҢж·»еҠ е’Ңдҝ®ж”№дәҶгҖӮ
while true
do
sleep 10s
pidnum=`jobs -p | wc -l`
if [ $pidnum -le 0 ]
then
echo "run over"
break
fi
done
need13datacommand &
need24datacommand &
need56datacommand &
wait
...
еҸҜд»Ҙзұ»дјјдёҠиҫ№зҡ„ж”№йҖ гҖӮиҝҷж ·ж”№йҖ д№ӢеҗҺиӣӢз–јд№Ӣж„ҹе°ұзәҫи§Јзҡ„еӨҡдәҶгҖӮдҪҶиҝҳжҳҜж„ҹи§үдёҚжҳҜеҫҲз•…еҝ«пјҢйӮЈеҘҪеҗ§пјҢжҲ‘们еҸҜд»ҘеҶҚз•…еҝ«дёҖзӮ№пјҲжҲ‘жҳҜжҢҮзЁӢеәҸгҖӮгҖӮгҖӮпјүпјҢеҸҜд»Ҙзұ»дјјиҝҷж ·пјҡ
д»Јз ҒеҰӮдёӢ:
for((i=0;i<1;i++));do
{
command1
command2
}&
done
for((i=0;i<1;i++));do
{
command3&
command4&
}&
done
for((i=0;i<1;i++));do
{
command5 &
command6 &
if 5 6жү§иЎҢе®ҢжҜ•...
command7
}&
done
иҝҷж ·зұ»дјјиҝҷж ·зҡ„ж”№йҖ пјҢи®©жңүеүҚеҗҺе…ізі»зҡ„е‘Ҫд»Өж”ҫеңЁдёҖдёӘforеҫӘзҺҜйҮҢ让他们дёҖиө·жү§иЎҢеҺ»пјҢиҝҷж ·дёүдёӘforеҫӘзҺҜе…¶е®һжҳҜ并иЎҢжү§иЎҢдәҶгҖӮ然еҗҺforеҫӘзҺҜеҶ…йғЁзҡ„е‘Ҫд»ӨдҪ иҝҳеҸҜд»Ҙзұ»дјјж”№йҖ 1зҡ„йӮЈз§Қж–№ејҸж”№йҖ жҲ–иҖ…еҶ…еөҢж”№йҖ 2иҝҷдёӘзҡ„并иЎҢforеҫӘзҺҜпјҢйғҪжҳҜеҸҜд»Ҙзҡ„пјҢе…ій”®зңӢдҪ жғіиұЎеҠӣдәҶгҖӮжҒ©пјҹе“ҰпјҢдёҚеҜ№пјҢе…ій”®жҳҜзңӢиҝҷдәӣдёӘе‘Ҫд»Өд№Ӣй—ҙжҳҜдёҖз§Қд»Җд№Ҳж ·зҡ„еҹәеҸӢе…ізі»дәҶгҖӮжңүе…іиҒ”зҡ„ж”ҫдёҖдёӘеұӢйҮҢе°ұиЎҢдәҶпјҢеү©дёӢзҡ„дҪ е°ұдёҚз”Ёж“ҚеҝғдәҶгҖӮеҳҝеҳҝ~~
е…¶е®һиҝҷдёӘдјҳеҢ–зңҹзҡ„йңҖиҰҒзңӢзі»з»ҹиҙҹиҪҪгҖӮ
5гҖҒе…ідәҺеҜ№shellе‘Ҫд»Өзҡ„зҗҶи§ЈгҖӮиҝҷдёӘжқЎзӣ®е°ұйқ з»ҸйӘҢдәҶпјҢеӣ дёәиІҢдјјжІЎжңүзӣёе…ізҡ„д№ҰзұҚеҸҜзңӢпјҢеҰӮжһңи°ҒзҹҘйҒ“жңүпјҢиҜ·жҺЁиҚҗз»ҷжҲ‘пјҢжҲ‘дјҡзҒ°еёёж„ҹи°ўзҡ„е•ҠгҖӮ
жҜ”еҰӮпјҡsed -n '45,50p' е’Ң sed -n '51q;45,50p' пјҢеүҚиҖ…д№ҹжҳҜиҜ»еҸ–45еҲ°50иЎҢпјҢеҗҺиҖ…д№ҹжҳҜпјҢдҪҶжҳҜеҗҺиҖ…еҲ°51иЎҢе°ұжү§иЎҢдәҶйҖҖеҮәsedе‘Ҫд»ӨпјҢйҒҝе…ҚдәҶеҗҺз»ӯзҡ„ж“ҚдҪңиҜ»еҸ–гҖӮеҰӮжһңиҝҷдёӘзӣ®ж Үж–Ү件зҡ„规模巨еӨ§зҡ„иҜқпјҢеү©дёӢзҡ„дҪ жҮӮзҡ„гҖӮ
иҝҳжңүзұ»дјјsed вҖҳs/foo/bar/g' е’Ңsed вҖҳ/foo/ s/foo/bar/g'
sedж”ҜжҢҒйҮҮз”ЁжӯЈеҲҷиҝӣиЎҢеҢ№й…Қе’ҢжӣҝжҚўпјҢиҖғиҷ‘еӯ—з¬ҰдёІжӣҝжҚўзҡ„йңҖжұӮдёӯпјҢдёҚйҳІеҠ дёҠең°еқҖд»ҘжҸҗй«ҳйҖҹеәҰгҖӮе®һдҫӢдёӯйҖҡиҝҮеўһеҠ дёҖдёӘеҲӨж–ӯйҖ»иҫ‘пјҢйҮҮз”ЁвҖңдәӢе…ҲеҢ№й…ҚвҖқд»ЈжӣҝвҖңзӣҙжҺҘжӣҝжҚўвҖқпјҢз”ұдәҺsedдјҡдҝқз•ҷеүҚдёҖж¬Ўзҡ„жӯЈеҲҷеҢ№й…ҚзҺҜеўғпјҢдёҚдјҡдә§з”ҹеҶ—дҪҷзҡ„жӯЈеҲҷеҢ№й…ҚпјҢеӣ жӯӨеҗҺиҖ…е…·жңүжӣҙй«ҳзҡ„ж•ҲзҺҮгҖӮе…ідәҺsedе‘Ҫд»Өзҡ„иҝҷдёӨзӮ№дјҳеҢ–пјҢжҲ‘д№ҹеңЁsedе‘Ҫд»ӨиҜҰи§ЈйҮҢжңүжҸҗеҲ°гҖӮ
иҝҳжңүзұ»дјјsort еҰӮжһңж•°еӯ—е°ҪйҮҸз”Ё -nйҖүйЎ№пјӣиҝҳжңүз»ҹи®Ўж–Ү件иЎҢж•°пјҢеҰӮжһңжҜҸиЎҢзҡ„ж•°жҚ®еңЁеҚ з”Ёеӯ—иҠӮж•°дёҖж ·зҡ„жғ…еҶөж—¶е°ұеҸҜд»ҘlsжҹҘж–Ү件еӨ§е°Ҹ然еҗҺйҷӨд»ҘжҜҸиЎҢзҡ„ж•°жҚ®еӨ§е°Ҹзҡ„еҮәиЎҢж•°пјҢиҖҢйҒҝе…ҚзӣҙжҺҘдҪҝз”Ёwc -lиҝҷж ·зҡ„е‘Ҫд»ӨпјӣиҝҳжңүfindеҮәжқҘзҡ„ж•°жҚ®пјҢеҲ«зӣҙжҺҘе°ұ-execйҖүйЎ№дәҶпјҢеҰӮжһңж•°жҚ®и§„жЁЎе°ҸеҫҲеҘҪпјҢдҪҶжҳҜеҰӮжһңдҪ findеҮәжқҘдёҠеҚғжқЎж•°жҚ®жҲ–жӣҙеӨҡпјҢдҪ дјҡз–ҜжҺүзҡ„пјҢдёҚпјҢзі»з»ҹдјҡз–ҜжҺүзҡ„пјҢеӣ дёәжҜҸиЎҢж•°жҚ®йғҪдјҡдә§з”ҹж–°зҡ„иҝӣзЁӢпјҢдҪ еҸҜд»Ҙиҝҷж ·find вҖҰ. | xargs вҖҰ.пјӣиҝҳжңүвҖҰ(еҰӮжһңдҪ д№ҹзҹҘйҒ“зұ»дјјзҡ„жҸҗж•ҲзҺҮжғ…еҶөиҜ·дҪ е‘ҠиҜүжҲ‘е…ұеҗҢиҝӣжӯҘпјҒ)
дёүгҖҒе…ідәҺдјҳеҢ–жӣҙеҘҪзҡ„дёҖдәӣйҖүжӢ©
дёҖдёӘжҜ”иҫғеҘҪзҡ„жҸҗеҚҮShellи„ҡжң¬зҡ„ж•ҲзҺҮж–№жі•е°ұжҳҜвҖҰвҖҰ е°ұжҳҜвҖҰвҖҰ е°ұжҳҜвҖҰвҖҰ еҘҪеҗ§пјҢе°ұжҳҜе°ҪйҮҸе°‘з”ЁShellпјҲеҲ«жү“жҲ‘е•ҠпјҒпјҒпјҒпјүдёӢиҫ№з»ҷеҮәдёҖдәӣdebianе®ҳж–№з»ҹи®Ўзҡ„дёҖдәӣеңЁlinuxзі»з»ҹдёҠиҫ№зҡ„еҗ„дёӘиҜӯиЁҖзҡ„ж•ҲзҺҮеӣҫпјҢе’ұйғҪд»ҘC++дёәжҜ”иҫғеҹәеҮҶпјҲзі»з»ҹи§„ж јпјҡx64 Ubuntuв„ў Intel® Q6600® quad-coreпјүпјҡ
иҝҷдәӣеӣҫзҡ„жҹҘзңӢж–№жі•пјҢжҜ”еҰӮ第дёҖдёӘеӣҫjavaе’Ңc++зҡ„зЁӢеәҸж•ҲзҺҮжҜ”иҫғеӣҫпјҢжҖ»е…ұеҲҶдёүдёӘйғЁеҲҶпјҢеҲҶеҲ«жҳҜtimeгҖҒmemoryгҖҒcodeзҡ„жҜ”иҫғпјҢеҰӮжһңжҳҜc++/java пјҢе°ұжҳҜиҜҙ c++еҒҡжҜ”иҫғзҡ„еҲҶеӯҗпјҢjavaеҒҡжҜ”иҫғзҡ„еҲҶжҜҚпјҢеҰӮжһңеӣҫдёҠзҡ„й•ҝжқЎеңЁе“Әиҫ№пјҢиҜҙжҳҺжүҖеңЁзҡ„йӮЈиҫ№зҡ„зЁӢеәҸдҪҝз”Ёзҡ„ж—¶й—ҙжҲ–иҖ…еҶ…еӯҳжҲ–иҖ…д»Јз ҒиҫғеӨҡпјҢе…·дҪ“еӨҡеӨҡе°‘е°ұзңӢй•ҝжқЎй•ҝдәҶеӨҡе°‘гҖӮжҜҸдёҖйғЁеҲҶжңүеӨҡдёӘй•ҝжқЎеӣҫеҪўпјҢжҜҸдёӘй•ҝжқЎеӣҫжЎҲиЎЁзӨәй’ҲеҜ№зЁӢеәҸеӨ„зҗҶдёҚеҗҢж–№йқўзҡ„д»»еҠЎж—¶иҝӣиЎҢзҡ„жөӢиҜ•гҖӮжҜ”еҰӮ第дёҖе№…пјҢc++е’ҢjavaеңЁиҜҘзҺҜеўғдёӢеӨ§йғЁеҲҶжғ…еҶөдёӢtimeдёҠжҳҜе·®дёҚеӨҡзҡ„пјҢз”ҡиҮіjava-serverиҝҳжңүзЁҚеҫ®зҡ„дјҳеҠҝпјҢеҶ…еӯҳж–№йқўc++е°ұжңүеҫҲеӨ§дјҳеҠҝпјҢиғҪеӨҹдҪҝз”ЁжҜ”javaе°‘зҡ„еӨҡзҡ„еҶ…е®№еҒҡзӣёеҗҢзҡ„дәӢжғ…пјҢдҪҶжҳҜзј–з ҒйҮҸc++е°ұзЁҚеҫ®еӨҡдёҖзӮ№зӮ№гҖӮд»ҘдёӢзҡ„еӣҫзұ»дјјгҖӮ 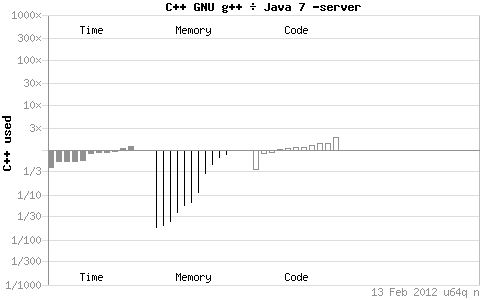

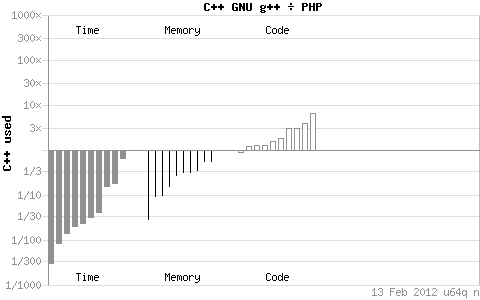

йҖҡиҝҮдёҠиҫ№зҡ„еӣҫжҲ‘зңӢеҸҜд»ҘзҹҘйҒ“C++еңЁж—¶й—ҙе’Ңз©әй—ҙдёҠеҜ№PythonгҖҒPerlгҖҒPHPжңүзқҖз»қеҜ№еҺӢеҖ’жҖ§зҡ„дјҳеҠҝпјҢдҪҶжҳҜзӣёеҜ№зҡ„зј–з ҒйҮҸиҫғй«ҳгҖӮеҗҢjavaжҜ”еҸӘжңүеҶ…еӯҳдҪҝз”ЁдёҠзҡ„дјҳеҠҝгҖӮдҪҶжҳҜжҲ‘们иҝҷзҜҮдё»иҰҒжҳҜй’ҲеҜ№Shellзҡ„пјҢдҪҶжҳҜпјҢеҸҲжҳҜдҪҶжҳҜпјҢdebianе®ҳзҪ‘жІЎжңүжҠҠshellи„ҡжң¬зәіе…Ҙж•ҲзҺҮжҜ”иҫғзҡ„з»ҹи®ЎиҢғеӣҙе•ҠпјҒпјҒпјҒиҝҳжҳҜдҪҶжҳҜпјҢжҲ‘们зҹҘйҒ“PythonгҖҒPerlгҖҒPHPйғҪжҳҜеҸ·з§°еҜ№ShellеңЁж•ҲзҺҮж–№йқўжңүзқҖжҳҺжҳҫзҡ„дјҳеҠҝпјҢжүҖд»ҘдҪ еҰӮжһңдёҚж»Ўж„ҸдҪ йҖҡиҝҮд»ҘдёҠжҸҗдҫӣзҡ„з§Қз§ҚдјҳеҢ–йҖ”еҫ„еҗҺзҡ„Shellи„ҡжң¬зЁӢеәҸзҡ„иҜқпјҢйӮЈдҪ е°ұеҸҜд»Ҙе°қиҜ•жҚўдёҖз§ҚиҜӯиЁҖдәҶгҖӮ
дҪҶжҳҜжҲ‘们еҫҖеҫҖдёҚйӮЈд№Ҳе®№жҳ“иҲҚејғиҝҷд№ҲеҘҪз”Ёж–№дҫҝиҖҢдё”з®ҖеҚ•зҡ„еӨ„зҗҶж•°жҚ®ж–№ејҸпјҢд№ҹеҸҜд»ҘжңүдёӘжҠҳдёӯзҡ„ж–№жі•пјҢдҪ е…Ҳз”ЁtimeжөӢиҜ•еҗ„дёӘShellи„ҡжң¬е‘Ҫд»Өзҡ„иҖ—ж—¶пјҢй’ҲеҜ№зү№еҲ«иҖ—ж—¶пјҢзү№еҲ«и®©дәәдёҚиғҪеҝҚеҸ—зҡ„е‘Ҫд»Өзҡ„ж•ҲзҺҮдҪҝз”ЁC++зЁӢеәҸеӨ„зҗҶпјҢи®©дҪ зҡ„Shellи„ҡжң¬жқҘи°ғз”ЁиҝҷдёӘй’ҲеҜ№еұҖйғЁж•°жҚ®еӨ„зҗҶзҡ„C++зЁӢеәҸпјҢиҝҷж ·жҠҳдёӯиІҢдјјиҝҳжҳҜиғҪи®©дәәжҺҘеҸ—еҗ§пјҹ
еӣӣгҖҒжңҖеҗҺиҜҙдёҖдёӢиҝҷзҜҮжҳҜдёҚж•ўз§°дёәе…ЁйқўжҲ–иҖ…иҜҰи§Јзҡ„ж–Үз« пјҢжҳҜжҲ‘еҜ№иҝҷдёҖж®өShellеӯҰд№ е’Ңе®һи·өзҡ„дёҖдәӣеҝғеҫ—пјҢеёҢжңӣиғҪжңүй«ҳжүӢжҢҮзӮ№гҖӮд№ҹеёҢжңӣиғҪеё®еҲ°ж–°иёҸе…ҘиҝҷдёҖйўҶеҹҹзҡ„ж–°еҗҢеӯҰгҖӮд»ҘеҗҺжңүж–°зҡ„еҝғеҫ—еҶҚж·»еҠ еҗ§гҖӮ
ж„ҹи°ўиҝҷзҜҮж–Үз« зҡ„дҪңиҖ…зҡ„еҚҡж–ҮжҢҮзӮ№гҖӮ
2012-02-22 psпјҡеҫӘзҺҜжЈҖжөӢеҗҺеҸ°е‘Ҫд»ӨжҳҜеҗҰз»“жқҹзҡ„еҲӨж–ӯдҝ®ж”№пјҡ
и§ЈеҶіж–№жі•жҡӮж—¶жңүдёӨдёӘпјҲе…·дҪ“жІЎжңүи§ЈйҮҠпјҢдёҚеӨӘжё…жҘҡеҺҹеӣ пјүпјҡ
1гҖҒ
д»Јз ҒеҰӮдёӢ:
sleep 8 &
sleep 16 &
while true
do
echo `jobs -p | wc -l`
jobs -l >> res
sleep 4
done
2гҖҒ жЈҖжҹҘеү©дҪҷдёӘж•°зҡ„иҜӯеҸҘж”№жҲҗ jobs -l |grep -v вҖңDoneвҖқ|wc -l
第дёҖдёӘж–№жЎҲзҡ„и§ЈеҶіжҳҜеӨҡжү§иЎҢдёҖж¬ЎjobsпјҢеҸҜд»Ҙи§ЈйҮҠжҲҗдёәдәҶж¶ҲйҷӨжңҖеҗҺзҡ„Doneз»“жһңпјҢдҪҶжҳҜиҝҷз§Қи§ЈйҮҠд№ҹжҳҜиЎҢдёҚйҖҡзҡ„пјҢеӣ дёәеҫӘзҺҜжҳҜдёҖзӣҙжү§иЎҢзҡ„пјҢеңЁechoйҮҢе·Із»Ҹжү§иЎҢеҫҲеӨҡж¬ЎjobsдәҶпјҢдҪ•жӯўдёҖж¬ЎгҖӮ
第дәҢдёӘж–№жЎҲжҳҜиҝҮж»ӨжҺүjobsжңҖеҗҺзҡ„иҫ“еҮәз»“жһңDoneиҝҷжқЎиҜӯеҸҘгҖӮз®—жҳҜз»•иҝҮй—®йўҳеҫ—еҲ°дәҶжңҹеҫ…зҡ„з»“жһңгҖӮ
дёӘдәәж„ҹи§үbashи§ЈйҮҠеҷЁдјҳеҢ–жҺүдәҶжІЎжңүеҗҺеҸ°е‘Ҫд»Өжү§иЎҢзҡ„jobsжҹҘиҜўе‘Ҫд»ӨпјҢеҰӮжһңжҳҜдјҳеҢ–жҺүдәҶйӮЈд№ҹеә”иҜҘжңүдёӘз©әзҡ„иҝ”еӣһпјҢwcдҫқ然еҸҜд»Ҙеҫ—еҲ°0зҡ„з»“жһңе•ҠгҖӮжүҖд»ҘиҝҷдёӘй—®йўҳжүҫдёҚеҲ°е…·дҪ“еҺҹеӣ пјҢеҰӮжһңдҪ зҹҘйҒ“иҜ·е‘ҠиҜүжҲ‘пјҢйқһеёёж„ҹи°ўгҖӮгҖӮгҖӮ иҝҷйҮҢе…Ҳж„ҹи°ўjust do shellзҫӨйҮҢзҡ„Eric жІүй»ҳзҡ„еңҹеҢӘ GS дёүдәәпјҢйқһеёёж„ҹи°ўдҪ 们зҡ„её®еҠ©гҖӮ
иҝҷйҮҢдёӨдёӘж–№жі•дёҚз®—еҘҪж–№жі•пјҢеҸӘжҳҜеҘҮжҖӘиҝҷж ·дёәд»Җд№ҲдёҚиЎҢпјҢиЎҢзҡ„еҸҲиҜҘеҰӮдҪ•и§ЈйҮҠгҖӮеҗҺжқҘзҹҘйҒ“з”Ёwaitе‘Ҫд»Өе°ұе…Ёи§ЈеҶідәҶпјҢиҖҪиҜҜйӮЈд№ҲеӨҡж—¶й—ҙиҝҳжҳҜз”Ёзҡ„дёҚжҳҺжҷәзҡ„ж–№жі•гҖӮ
е…ідәҺвҖңеҰӮдҪ•дјҳеҢ–Shellи„ҡжң¬ж•ҲзҺҮвҖқиҝҷзҜҮж–Үз« е°ұеҲҶдә«еҲ°иҝҷйҮҢдәҶпјҢеёҢжңӣд»ҘдёҠеҶ…е®№еҸҜд»ҘеҜ№еӨ§е®¶жңүдёҖе®ҡзҡ„её®еҠ©пјҢдҪҝеҗ„дҪҚеҸҜд»ҘеӯҰеҲ°жӣҙеӨҡзҹҘиҜҶпјҢеҰӮжһңи§үеҫ—ж–Үз« дёҚй”ҷпјҢиҜ·жҠҠе®ғеҲҶдә«еҮәеҺ»и®©жӣҙеӨҡзҡ„дәәзңӢеҲ°гҖӮ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ