您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
Elasticsearch的数据就存储在硬盘中。当我们的访问日志非常大时,kabana绘制图形的时候会非常缓慢。而且硬盘空间有限,不可能保存所有的日志文件。如果我们想获取站点每天的重要数据信息,比如每天的访问量并希望能图像化的形式显示该如何做呢?
一、具体操作方法
获取数据之前你要知道你想要什么样的数据。比如我想获取每小时网站访问的PV,在kibana中肯定能获取到
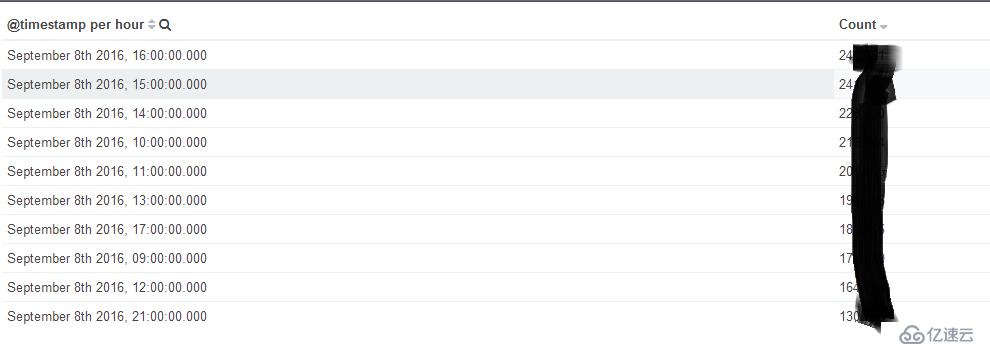
这是在kibana中查询的每小时的pv,然后我们把他的查询json复制出来
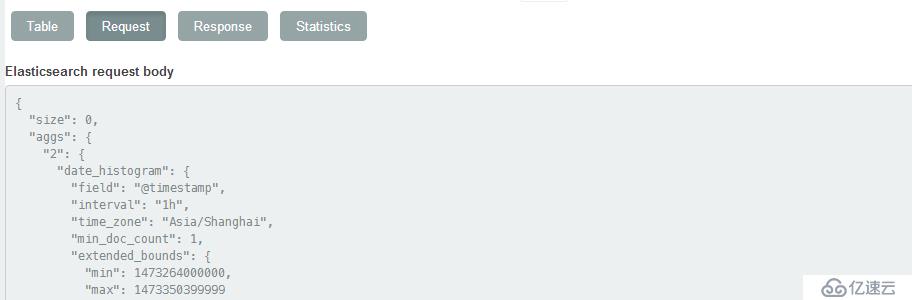
把上述json粘贴到test文件中 然后使用如下语句即可查询上图显示的查询结果
curl -POST 'http://192.168.10.49:9200/_search' -d '@test'
{"took":940,"timed_out":false,"_shards":{"total":211,"successful":211,"failed":0},"hits"......
然后把返回的结果中的数据获取存入data数组中,这是你可以存入数据库也可以转换成json直接插入es
这种方法主要是通过elasticsearch的查询语句把数据查询出来在传参给其他地方。你输入固定的查询json它返回的json数据也是固定格式的,这样很方面就能从中挖掘出我们想要的数据!
二、php代码实现上述操作
class.php
<?php
#从ES中导出数据
#两个参数:
#url为从ES导出数据的访问路径,不同的数据路径不一样
#post_data为json格式,是request body。
function export($url,$post_data){
$ch = curl_init ();
curl_setopt ( $ch, CURLOPT_URL, $url );
curl_setopt ( $ch, CURLOPT_CUSTOMREQUEST,"POST");
curl_setopt ( $ch, CURLOPT_HEADER, 0 );
curl_setopt ( $ch, CURLOPT_RETURNTRANSFER, 1 );
curl_setopt ( $ch, CURLOPT_POSTFIELDS, $post_data);
$arr=curl_exec($ch);
curl_close($ch);
return json_decode($arr,'assoc');;
}
#把数组数据导入ES
#两个参数:
#$url为导入数据的具体位置 如:http://IP:9200/索引/类型/ID(ID最好根据时间确定,需要唯一ID)
#post_data 导入ES的数据数组
function import($url,$post_data)
{
$json=json_encode($post_data);
$ci = curl_init();
curl_setopt($ci, CURLOPT_PORT, 9200);
curl_setopt($ci, CURLOPT_TIMEOUT, 2000);
curl_setopt($ci, CURLOPT_RETURNTRANSFER, 1);
curl_setopt($ci, CURLOPT_FORBID_REUSE, 0);
curl_setopt($ci, CURLOPT_CUSTOMREQUEST, 'PUT');
curl_setopt($ci, CURLOPT_URL, $url);
curl_setopt($ci, CURLOPT_POSTFIELDS, $json);
$response = curl_exec($ci);
unset($post_data);//销毁数组
unset($json);//销毁数据
curl_close($ci);
}
?>vim access_info.php (index_name和type_name自己根据实际情况命名)
<?php
include("class.php");
#导出数据的ES路径
$url="http://192.168.10.49:9200/_search";
#查询数据的开始时间
$begin=date("Y-m-d",strtotime("-16 day"));
#开始时间的格式转换
$start_time=strtotime($begin." 00:00:00");
#查询数据的结束时间及当时时间,并转换时间格式
$end_time=strtotime(date("Y-m-d H:i:s",time()));
#替换查询json中开始及结束时间的,文件是./lib/下的同名txt文件
$post_data=str_replace('end_time',$end_time,str_replace('start_time',$start_time,file_get_contents('lib/'.str_replace('.php','.txt',basename($_SERVER['PHP_SELF'])).'')));
#查询ES中的数据,返回数组数据
$arr=export($url,$post_data);
#从数组中获取你想要的数据,然后在组合成一个新的数组
$array=$arr['aggregations']['2']['buckets'];
foreach($array as $key => $value){
$data['@timestamp']=$value['key_as_string'];
$data['request_PV']=$value['doc_count'];
$data['request_IP']=$value['3']['value'];
#Time为导入ES中的ID,具有唯一性。(不同tpye的可以相同)
$Time=strtotime($data['@timestamp']);
$urls="http://192.168.2.243:9200/index_name/tpye_name/$Time"
#调用函数import导入数据
import($urls,$data);
}
?>下面这个文件是存放./lib文件下的,和执行的php文件必须同名。
vim lib/access_info.txt
{
"size": 0,
"aggs": {
"2": {
"date_histogram": {
"field": "@timestamp",
"interval": "1h",
"time_zone": "Asia/Shanghai"
#保留时区获取的信息会准确但是在kibana或ganafa显示的时候会加8个小时
"min_doc_count": 1,
"extended_bounds": {
"min": start_time, #start_time会被换成具体的时间
"max": end_time
}
},
"aggs": {
"3": {
"cardinality": {
"field": "geoip.ip"
}
}
}
}
},
"highlight": {
"pre_tags": [
"@kibana-highlighted-field@"
],
"post_tags": [
"@/kibana-highlighted-field@"
],
"fields": {
"*": {}
},
"require_field_match": false,
"fragment_size": 2147483647
},
"query": {
"filtered": {
"query": {
"query_string": {
"query": "*",
"analyze_wildcard": true
}
},
"filter": {
"bool": {
"must": [
{
"range": {
"@timestamp": {
"gte": start_time,
"lte": end_time,
"format": "epoch_second" #由毫秒换成秒
}
}
}
],
"must_not": []
}
}
}
}
}根据上面的代码,我们可以定期获取ES中的重要数据。这样获取的数据只是结果数据,不是很精确,但能反应网站的趋势,而且查询非常快速!如果想要长时间保存重要的数据,可以使用这个方法。而且数据也可以存入数据库。
以上是个人对能长期保存ES结果数据的做法,如果有更好的方法,希望能一起讨论!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。