жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
гҖҖгҖҖе…ҲжқҘиҜҰз»Ҷзҡ„и®ІдёҖдёӢEMз®—жі•гҖӮ
гҖҖгҖҖеүҚжҸҗеҮҶеӨҮ
гҖҖгҖҖJupyter notebook жҲ– Pycharm
гҖҖгҖҖзҒ«зӢҗжөҸи§ҲеҷЁжҲ–ChromeжөҸи§ҲеҷЁ
гҖҖгҖҖwin7жҲ–win10з”өи„‘дёҖеҸ°
гҖҖгҖҖзҪ‘зӣҳжҸҗеҸ–csvж•°жҚ®
гҖҖгҖҖйңҖжұӮеҲҶжһҗ
гҖҖгҖҖе®һзҺ°й«ҳж–Ҝж··еҗҲжЁЎеһӢзҡ„ EM з®—жі•(GMM_EM)
гҖҖгҖҖй«ҳж–Ҝж··еҗҲжЁЎеһӢжҳҜеӨҡдёӘй«ҳж–ҜжЁЎеһӢзҡ„зәҝжҖ§еҸ еҠ иҖҢжҲҗзҡ„пјҢй«ҳж–Ҝж··еҗҲжЁЎеһӢзҡ„жҰӮзҺҮеҲҶеёғиЎЁзӨәеҰӮдёӢпјҡ
гҖҖгҖҖ
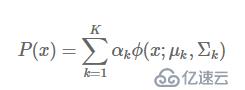
гҖҖгҖҖе…¶дёӯпјҢkиЎЁзӨәжЁЎеһӢзҡ„дёӘж•°пјҢОұkОұ_kОұk жҳҜ第 k дёӘжЁЎеһӢзҡ„зі»ж•°пјҢиЎЁзӨәеҮәзҺ°иҜҘжЁЎеһӢзҡ„жҰӮзҺҮпјҢП•(x;Ојk,ОЈk) жҳҜ第 k дёӘй«ҳж–ҜжЁЎеһӢзҡ„жҰӮзҺҮеҲҶеёғгҖӮ
гҖҖгҖҖEжӯҘпјҡж ·жң¬ xix_ixiжқҘиҮӘдәҺ第 k дёӘжЁЎеһӢзҡ„жҰӮзҺҮпјҢжҲ‘们жҠҠиҝҷдёӘжҰӮзҺҮз§°дёәжЁЎеһӢ k еҜ№ж ·жң¬ xix_ixi зҡ„вҖңиҙЈд»»вҖқпјҢд№ҹеҸ«вҖңе“Қеә”еәҰвҖқпјҢи®°дҪң Оі(ik)Оі_(ik)Оі(ik)пјҢи®Ўз®—е…¬ејҸеҰӮдёӢпјҡ
гҖҖгҖҖ
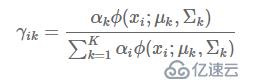
гҖҖгҖҖMжӯҘпјҡж №жҚ®ж ·жң¬е’ҢеҪ“еүҚ Оі зҹ©йҳөйҮҚж–°дј°и®ЎеҸӮж•°пјҢжіЁж„ҸиҝҷйҮҢ x дёәеҲ—еҗ‘йҮҸ
гҖҖгҖҖгҖҗзӣ®ж ҮгҖ‘з»ҷе®ҡдёҖе ҶжІЎжңүж Үзӯҫзҡ„ж ·жң¬е’ҢжЁЎеһӢдёӘж•° KпјҢд»ҘжӯӨжұӮеҫ—ж··еҗҲжЁЎеһӢзҡ„еҸӮж•°пјҢ然еҗҺе°ұеҸҜд»Ҙз”ЁиҝҷдёӘжЁЎеһӢжқҘеҜ№ж ·жң¬иҝӣиЎҢиҒҡзұ»гҖӮ
гҖҖгҖҖpythonд»Јз ҒеҰӮдёӢпјҡ
гҖҖгҖҖimport numpy as np
гҖҖгҖҖimport matplotlib.pyplot as plt
гҖҖгҖҖfrom scipy.stats import multivariate_normal #жң¬й—®йўҳиҖғиҷ‘зҡ„жҳҜй«ҳж–Ҝж··еҗҲжЁЎеһӢпјҢжүҖд»ҘеҜје…ҘеӨҡе…ғй«ҳж–ҜеҲҶеёғmultivariate_normal
гҖҖгҖҖdef prob_Y_k(Y,mu_k,cov_k): #Yдёәж ·жң¬зҹ©йҳө
гҖҖгҖҖnorm = multivariate_normal(mean = mu_k , cov = cov_k) #з”ҹжҲҗеӨҡе…ғжӯЈеӨӘеҲҶеёғпјҢmuдёә第kдёӘжЁЎеһӢзҡ„еқҮеҖјпјҢcovдёә第kдёӘжЁЎеһӢзҡ„еҚҸж–№е·®зҹ©йҳө(еҚҸж–№е·®зҹ©йҳөеҝ…йЎ»жҳҜе®һеҜ№з§°зҹ©йҳө)
гҖҖгҖҖreturn norm.pdf(Y) #иҝ”еӣһж ·жң¬YжқҘиҮӘдәҺ第kдёӘжЁЎеһӢзҡ„жҰӮзҺҮ
гҖҖгҖҖdef Estep(Y,mu,cov,alpha): #Yдёәж ·жң¬зҹ©йҳөпјҢalphaдёәжқғйҮҚ
гҖҖгҖҖN = Y.shape[0] #ж ·жң¬ж•°
гҖҖгҖҖK = alpha.shape[0] #жЁЎеһӢж•°
гҖҖгҖҖassert N>1 , "There must be more than one sample!" #дёәйҒҝе…ҚеҚ•дёӘж ·жң¬еҜјиҮҙиҝ”еӣһзҡ„з»“жһңзҡ„зұ»еһӢдёҚдёҖиҮҙпјҢеӣ жӯӨиҰҒжұӮж ·жң¬ж•°еҝ…йЎ»еӨ§дәҺдёҖ
гҖҖгҖҖassert K>1 , "There must be more than one gaussian model!" #дёәйҒҝе…ҚеҚ•дёӘжЁЎеһӢз»“жһңзҡ„зұ»еһӢдёҚдёҖиҮҙпјҢеӣ жӯӨиҰҒжұӮжЁЎеһӢйЎ»еӨ§дәҺдёҖ
гҖҖгҖҖgamma = np.mat(np.zeros((N,K))) #еҲқе§ӢеҢ–е“Қеә”еәҰзҹ©йҳөпјҢиЎҢеҜ№еә”ж ·жң¬ж•°пјҢеҲ—еҜ№еә”жЁЎеһӢж•°
гҖҖгҖҖprob = np.zeros((N,K)) #еҲқе§ӢеҢ–жүҖжңүж ·жң¬еҮәзҺ°зҡ„жҰӮзҺҮзҹ©йҳөпјҢиЎҢеҜ№еә”ж ·жң¬ж•°пјҢеҲ—еҜ№еә”е“Қеә”еәҰ
гҖҖгҖҖfor k in range(K):
гҖҖгҖҖprob[:,k] = prob_Y_k(Y,mu[k],cov[k]) #第kдёӘжЁЎеһӢзҡ„жҰӮзҺҮprob_Y_k
гҖҖгҖҖprob = np.mat(prob) #KдёӘprobж”ҫе…Ҙж•°з»„дёӯ
гҖҖгҖҖfor k in range(K):
гҖҖгҖҖgamma[:,k] = alpha[k] * prob[:,k] #и®Ўз®—жЁЎеһӢkеҜ№ж ·жң¬iзҡ„е“Қеә”еәҰ
гҖҖгҖҖfor i in range(N):
гҖҖгҖҖgamma[i,:] /= np.sum(gamma[i,:]) #第iдёӘж ·жң¬зҡ„еҚ жҖ»ж ·жң¬зҡ„е“Қеә”зЁӢеәҰ
гҖҖгҖҖreturn gamma #gammaдёәе“Қеә”еәҰзҹ©йҳө
гҖҖгҖҖdef Mstep(Y,gamma): #дј е…Ҙж ·жң¬зҹ©йҳөYе’ҢEstepеҫ—еҲ°зҡ„gammaе“Қеә”еәҰзҹ©йҳө
гҖҖгҖҖN, D = Y.shape #Nдёәж ·жң¬ж•°пјҢDдёәзү№еҫҒж•°
гҖҖгҖҖK = gamma.shape[1] #жЁЎеһӢж•°
гҖҖгҖҖmu = np.zeros((K,D)) #еҲқе§ӢеҢ–еҸӮж•°еқҮеҖјmuпјҢжҜҸдёӘжЁЎеһӢзҡ„Dз»ҙеҗ„жңүеқҮеҖјж•…muзҡ„зҹ©йҳөдёәKиЎҢDеҲ—
гҖҖгҖҖcov = [] #еҲқе§ӢеҢ–еҸӮж•°еҚҸж–№е·®зҹ©йҳө
гҖҖгҖҖalpha = np.zeros(K) # еҲқе§ӢеҢ–жқғйҮҚж•°з»„пјҢжҜҸдёӘжЁЎеһӢйғҪжңүжқғеҖј
гҖҖгҖҖ#жҺҘдёӢжқҘжҳҜжӣҙж–°жҜҸдёӘжЁЎеһӢзҡ„еҸӮж•°
гҖҖгҖҖfor k in range(K):
гҖҖгҖҖNk = np.sum(gamma[:,k]) #第kдёӘжЁЎеһӢжүҖжңүж ·жң¬зҡ„е“Қеә”еәҰд№Ӣе’Ң
гҖҖгҖҖmu[k,:] = np.sum(np.multiply(Y, gamma[:,k]),axis=0)/Nk #жӣҙж–°еҸӮж•°еқҮеҖјmuпјҢеҜ№жҜҸдёӘзү№еҫҒжұӮеқҮеҖј
гҖҖгҖҖcov_k = (Y - mu[k]).T * np.multiply((Y - mu[k]), gamma[:,k]) / Nk #жӣҙж–°cov
гҖҖгҖҖcov = np.append(cov_k)
гҖҖгҖҖalpha[k] = Nk / N
гҖҖгҖҖcov = np.array(cov)
гҖҖгҖҖreturn mu, cov, alpha
гҖҖгҖҖdef normalize_data(Y): #е°ҶжүҖжңүж•°жҚ®иҝӣиЎҢеҪ’дёҖеҢ–еӨ„зҗҶпјҢ
гҖҖгҖҖfor i in range(Y.shape[1]):
гҖҖгҖҖmax_data = Y[:,i].max()
гҖҖгҖҖmin_data = Y[:,i].min()
гҖҖгҖҖY[:,i] = (Y[:,i] - min_data)/(max_data - min_data) #жӯӨеӨ„з”ЁеҲ°min-maxеҪ’дёҖеҢ–
гҖҖгҖҖdebug("Data Normalized")
гҖҖгҖҖreturn Y
гҖҖгҖҖdef init_params(shape,K): #еңЁжү§иЎҢиҜҘз®—жі•д№ӢеүҚпјҢйңҖиҰҒе…Ҳз»ҷеҮәдёҖдёӘеҲқе§ӢеҢ–зҡ„жЁЎеһӢеҸӮж•°гҖӮжҲ‘们让жҜҸдёӘжЁЎеһӢзҡ„ОјдёәйҡҸжңәеҖј,ОЈ дёәеҚ•дҪҚзҹ©йҳөпјҢОұ дёә 1/KпјҢеҚіжҜҸдёӘжЁЎеһӢеҲқе§Ӣж—¶йғҪжҳҜзӯүжҰӮзҺҮеҮәзҺ°зҡ„гҖӮ
гҖҖгҖҖN, D = shape
гҖҖгҖҖmu = np.random.rand(K, D) #з”ҹжҲҗдёҖдёӘKиЎҢDеҲ—зҡ„[0,1)д№Ӣй—ҙзҡ„ж•°з»„
гҖҖгҖҖcov = np.array([np.eye(D)] * K) #з”ҹжҲҗKдёӘDз»ҙзҡ„еҜ№и§’зҹ©йҳө
гҖҖгҖҖalpha = np.array([1.0 / K] * K) #з”ҹжҲҗKдёӘжқғйҮҚ
гҖҖгҖҖdebug("Parameters initialized.")
гҖҖгҖҖdebug("mu:",mu, "cov:",cov ,"alpha:",alpha,sep = "\n" )
гҖҖгҖҖreturn mu, cov, alpha
гҖҖгҖҖdef GMM_EM(Y, K, times): #й«ҳж–Ҝж··еҗҲEMз®—жі•,Yдёәз»ҷе®ҡж ·жң¬зҹ©йҳөпјҢKдёәжЁЎеһӢдёӘж•°пјҢtimesдёәиҝӯд»Јж¬Ўж•°пјҢзӣ®зҡ„жҳҜжұӮиҜҘжЁЎеһӢзҡ„еҸӮж•°
гҖҖгҖҖY = normalize_data(Y) #и°ғз”ЁеүҚйқўе®ҡд№үзҡ„normalize_dataеҮҪж•°пјҢеҪ’дёҖеҢ–ж ·жң¬зҹ©йҳөY
гҖҖгҖҖmu, cov, alpha = init_params(Y.shape, K) #и°ғз”Ёinit_paramsеҮҪж•°еҫ—еҲ°еҲқе§ӢеҢ–зҡ„еҸӮж•°mu,cov,alpha
гҖҖгҖҖfor i in range(times):йғ‘е·һеҰҮ科еҢ»йҷў http://m.zyfuke.com/
гҖҖгҖҖgamma = Estep(Y, mu, cov, alpha) #и°ғз”ЁEstepеҫ—еҲ°е“Қеә”еәҰзҹ©йҳө
гҖҖгҖҖmu, cov, alpha = Mstep(Y, gamma) #и°ғз”ЁMstepеҫ—еҲ°жӣҙж–°еҗҺзҡ„еҸӮж•°mu,cov,alpha
гҖҖгҖҖdebug("{sep} Result {sep}".format(sep="-"*20))
гҖҖгҖҖdebug("mu:", mu , "cov:",cov , "alpha:",alpha , sep="\n")
гҖҖгҖҖreturn mu,cov,alpha
гҖҖгҖҖimport matplotlib.pyplot as plt
гҖҖгҖҖfrom gmm import *
гҖҖгҖҖDEBUG = True
гҖҖгҖҖY = np.loadtxt("gmm.data") #иҪҪе…Ҙж•°жҚ®
гҖҖгҖҖmatY = np.matrix(Y ,copy = True)
гҖҖгҖҖK = 2 #жЁЎеһӢдёӘж•°(зӣёеҪ“дәҺиҒҡзұ»зҡ„зұ»еҲ«дёӘж•°)
гҖҖгҖҖmu, cov, alpha = GMM_EM(matY , K , 100) #и°ғз”ЁGMM_EMеҮҪж•°пјҢи®Ўз®—GMMжЁЎеһӢеҸӮж•°
гҖҖгҖҖN = Y.shape[0]
гҖҖгҖҖgamma = Estep(matY, mu, cov, alpha) #жұӮеҪ“еүҚжЁЎеһӢеҸӮж•°дёӢпјҢеҗ„жЁЎеһӢеҜ№ж ·жң¬зҡ„е“Қеә”зҹ©йҳө
гҖҖгҖҖcategory = gamma.argmax(axis = 1).flatten().tolist()[0] #еҜ№жҜҸдёӘж ·жң¬пјҢжұӮе“Қеә”еәҰжңҖеӨ§зҡ„жЁЎеһӢдёӢж ҮпјҢдҪңдёәе…¶зұ»еҲ«ж ҮиҜҶ
гҖҖгҖҖclass1 = np.array([Y[i] for i in range(N) if category[i] == 0]) #е°ҶжҜҸдёӘж ·жң¬ж”ҫе…ҘеҜ№еә”ж ·жң¬зҡ„еҲ—иЎЁдёӯ
гҖҖгҖҖclass2 = np.array([Y[i] for i in range(N) if category[i] == 1])
гҖҖгҖҖplt.plot(class1[:,0],class1[:,1], 'rs' ,label = "class1")
гҖҖгҖҖplt.plot(class2[:,0],class2[:,1], 'bo' ,label = "class2")
гҖҖгҖҖplt.legend(loc = "best")
гҖҖгҖҖplt.title("GMM Clustering By EM Algorithm")
гҖҖгҖҖplt.show()
гҖҖгҖҖimport numpy as np
гҖҖгҖҖimport matplotlib.pyplot as plt
гҖҖгҖҖcov1 = np.mat("0.3 0 ; 0 0.1") #2з»ҙеҚҸж–№е·®зҹ©йҳө(еҝ…йЎ»жҳҜеҜ№и§’зҹ©йҳө)
гҖҖгҖҖcov2 = np.mat("0.2 0 ; 0 0.3")
гҖҖгҖҖmu1 = np.array([0,1])
гҖҖгҖҖmu2 = np.array([2,1])
гҖҖгҖҖsample = np.zeros((100,2)) #еҲқе§ӢеҢ–100дёӘж ·жң¬пјҢж ·жң¬зү№еҫҒдёә2
гҖҖгҖҖsample[:30, :] = np.random.multivariate_normal(mean=mu1, cov=cov1, size=30) #з”ҹжҲҗеӨҡе…ғжӯЈжҖҒеҲҶеёғзҹ©йҳө
гҖҖгҖҖsample[30:, :] = np.random.multivariate_normal(mean=mu2, cov=cov2, size=70)
гҖҖгҖҖnp.savetxt("sample.data",sample) # е°ҶarrayдҝқеӯҳеҲ°txtж–Ү件дёӯ
гҖҖгҖҖplt.plot(sample[:30, 0], sample[:30, 1], "bo") #30дёӘж ·жң¬з”Ёи“қиүІеңҶеңҲж Үи®°
гҖҖгҖҖplt.plot(sample[30:, 0], sample[30:, 1], "rs") #70дёӘж ·жң¬з”ЁзәўиүІж–№еқ—ж Үи®°
гҖҖгҖҖplt.title("sample_data")
гҖҖгҖҖplt.show()
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ