жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
вҖғеңЁеүҚж®өж—¶й—ҙзңӢдәҶжқ°жҳҶиҸІе°је…Ӣж–Ҝзҡ„е°Ҹдё‘з”өеҪұпјҢеҝғйҮҢеҫҲеҘҪеҘҮеӨ§йғЁеҲҶи§Ӯдј—зңӢе®ҢиҝҷйғЁз”өеҪұд№ӢеҗҺеҜ№жӯӨжңүд»Җд№ҲиҜ„д»·пјҢ然еҗҺзңӢдәҶзңӢиұҶз“ЈзҹӯиҜ„д№ӢеҗҺпјҢи§үеҫ—йҖҡиҝҮpythonжҠҠзҹӯиҜ„дёӯеҮәзҺ°жңҖеӨҡзҡ„еҚ•иҜҚжҸҗеҸ–еҮәжқҘпјҢеҒҡжҲҗдёҖеј иҜҚдә‘пјҢзңӢзңӢиҝҷйғЁз”өеҪұз»ҷи§Ӯ众们з•ҷдёӢзҡ„е…ій”®иҜҚжҳҜд»Җд№ҲгҖӮ
вҖғйҰ–е…ҲеҲҡејҖе§Ӣзҡ„ж—¶еҖҷ пјҢжҳҜйҖҡиҝҮrequestsеҺ»жЁЎжӢҹжҠ“еҸ–ж•°жҚ®пјҢеҸ‘зҺ°зҹӯиҜ„зҝ»йЎөзҝ»еҲ°20йЎөд№ӢеҗҺе°ұйңҖиҰҒзҷ»еҪ•иұҶз“Јз”ЁжҲ·жүҚжңүжқғйҷҗжҹҘзңӢпјҢжүҖд»Ҙжү“з®—йҖҡиҝҮдҪҝз”ЁseleniumжЁЎжӢҹжөҸи§ҲеҷЁеҠЁдҪңиҮӘеҠЁеҢ–е°ҶйЎөйқўдёӯзҡ„ж•°жҚ®зҲ¬еҸ–дёӢжқҘпјҢ然еҗҺеӯҳеӮЁеҲ°зү№е®ҡзҡ„txtж–Ү件пјҢз”ұдәҺжІЎжү“з®—еҒҡе…¶д»–зҡ„еҲҶжһҗпјҢе°ұдёҚжү“з®—еӯҳж”ҫеҲ°ж•°жҚ®еә“дёӯгҖӮ
вҖғе…ідәҺжөҒиЎҢзҡ„иҮӘеҠЁеҢ–жөӢиҜ•жЎҶжһ¶seleniumзҡ„е·ҘдҪңеҺҹзҗҶпјҢд»ҘеҸҠseleniumе’ҢchromdriverеҜ№еә”зҡ„зүҲжң¬е®үиЈ…е°ұдёҚиҜҰз»Ҷиөҳиҝ°пјҢжңүе…ҙи¶Јзҡ„еҗҢеӯҰеҸҜд»ҘеҸӮиҖғпјҡ
вҖғhttps://blog.csdn.net/weixin_43241295/article/details/83784692
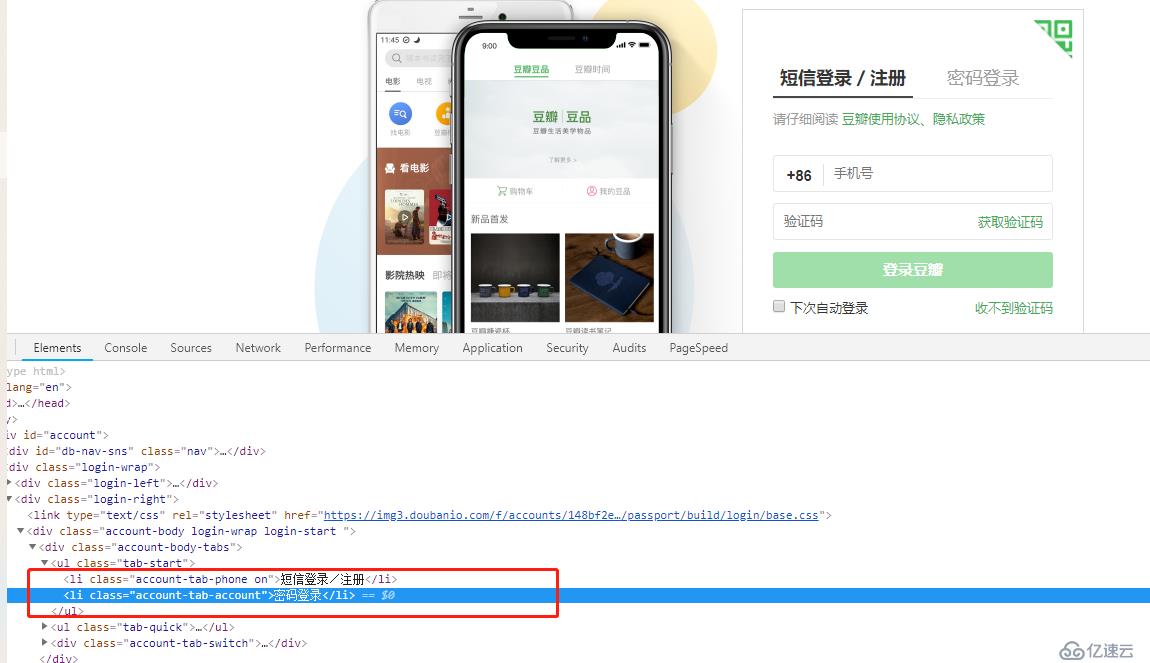
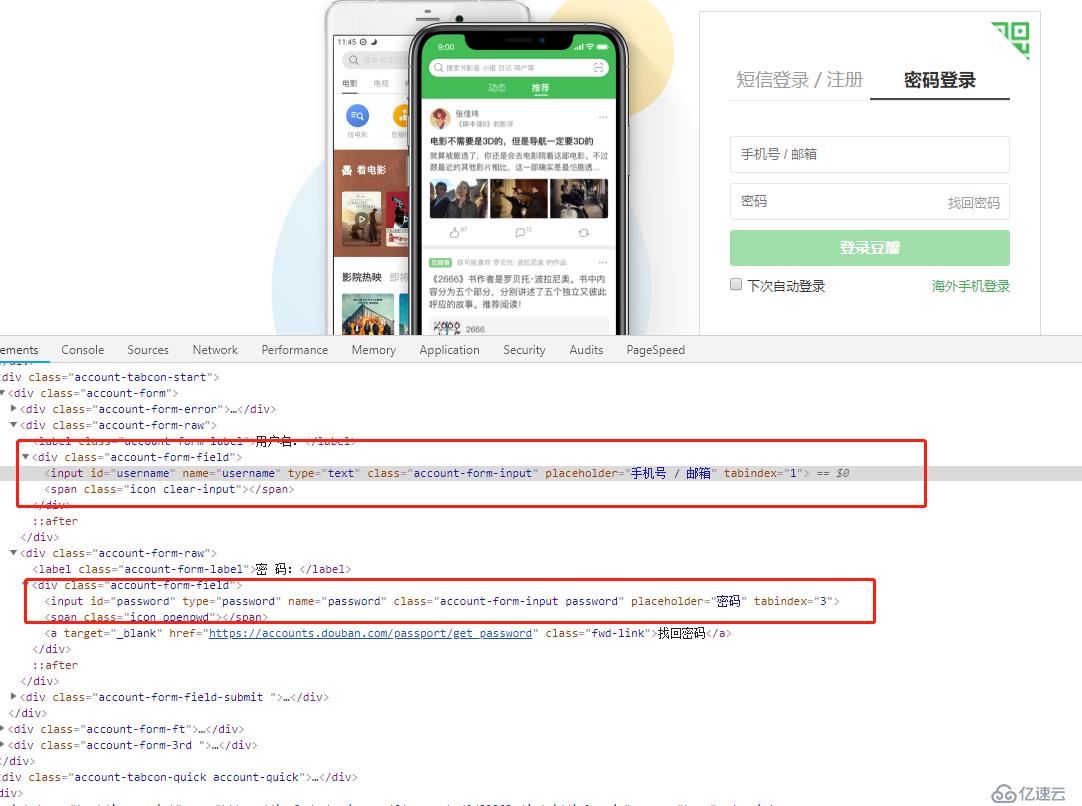
вҖғд»ҺйЎөйқўдёҠзңӢжқҘпјҢеӨ§жҰӮжөҒзЁӢе°ұжҳҜзӮ№еҮ»еҜјиҲӘж Ҹдёӯзҡ„еҜҶз Ғзҷ»еҪ•пјҢ然еҗҺиҫ“е…Ҙз”ЁжҲ·еҗҚе’ҢеҜҶз ҒпјҢзӮ№еҮ»зҷ»еҪ•жҢүй’®пјҢиҮідәҺзңӢзҪ‘дёҠдёҖдәӣиұҶз“ЈзҲ¬иҷ«ж—¶дјҡеҮәзҺ°зҡ„йӘҢиҜҒеӣҫзүҮпјҢжҲ‘жІЎжңүйҒҮеҲ°иҝҮпјҢжҲ‘зӣҙжҺҘзҷ»еҪ•е°ұOKдәҶпјҢжүҖд»ҘжҺҘдёӢжқҘе°ұйңҖиҰҒйҖҡиҝҮseleniumжЁЎжӢҹж•ҙдёӘзҷ»еҪ•иҝҮзЁӢгҖӮ
from selenium import webdriver
from selenium.webdriver.chrome.options import Options
import time
def crawldouban():
name = "дҪ зҡ„з”ЁжҲ·еҗҚ"
passw = "дҪ зҡ„еҜҶз Ғ"
# еҗҜеҠЁchrome
options = Options()
options.add_argument('--headless')
options.add_argument('--no-sandbox')
browser = webdriver.Chrome(executable_path="/usr/bin/chromedriver", options=options)
# иҺ·еҸ–зҷ»еҪ•зҪ‘еқҖ
browser.get("https://accounts.douban.com/passport/login")
time.sleep(3)
# зҷ»еҪ•иҮӘеҠЁеҢ–ж“ҚдҪңжөҒзЁӢ
browser.find_element_by_class_name("account-tab-account").click()
form = browser.find_element_by_class_name("account-tabcon-start")
username = form.find_element_by_id("username")
password = form.find_element_by_id("password")
username.send_keys(name)
password.send_keys(passw)
browser.find_element_by_class_name("account-form-field-submit").click()
time.sleep(3)вҖғжҺҘдёӢжқҘе°ұжҳҜпјҢиҺ·еҸ–йЎөйқўдёӯзҡ„иҜ„и®әпјҢ然еҗҺе°ҶиҜ„и®әеӯҳеӮЁеҲ°жҢҮе®ҡзҡ„ж–Үжң¬ж–Ү件дёӯпјҢ(жҲ‘е°ұдёҚжЁЎжӢҹжҹҘиҜўз”өеҪұ然еҗҺпјҢи·іиҪ¬еҲ°зҹӯиҜ„зҡ„ж•ҙдёӘиҝҮзЁӢдәҶ)пјҢзӣҙжҺҘд»ҺжӢҝеҲ°зҡ„зҹӯиҜ„йЎөйқўең°еқҖеҮәеҸ‘пјҢдёҚж–ӯзӮ№еҮ»дёӢдёҖйЎө然еҗҺдёҚж–ӯйҮҚеӨҚжҸҗеҸ–иҜ„и®әпјҢеҶҷе…Ҙзҡ„ж“ҚдҪңгҖӮ
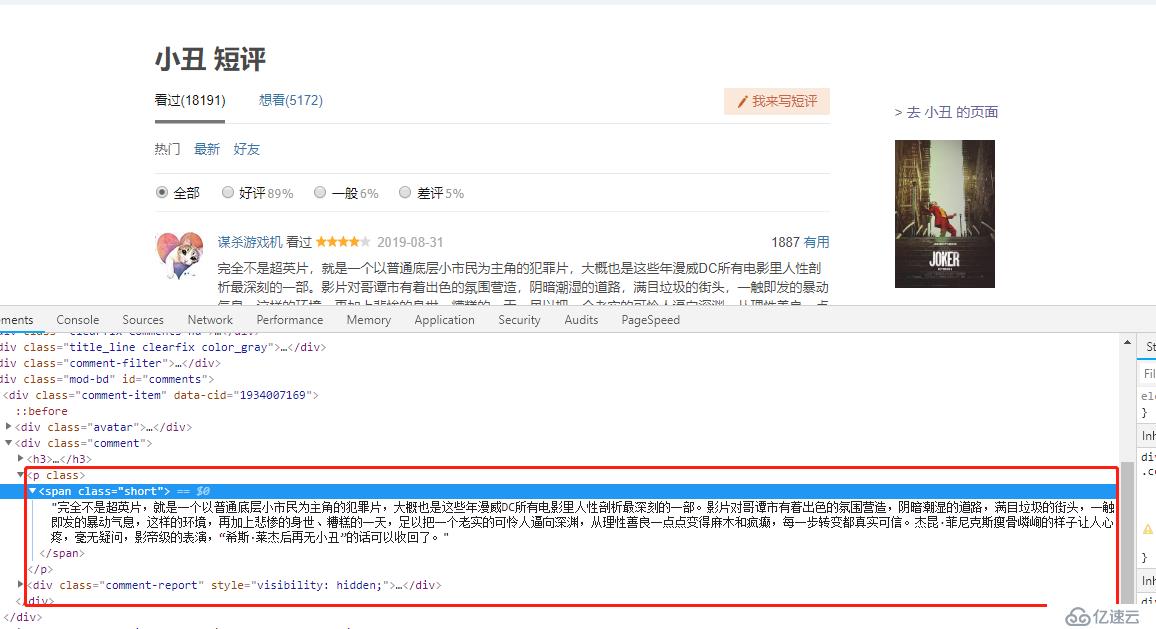
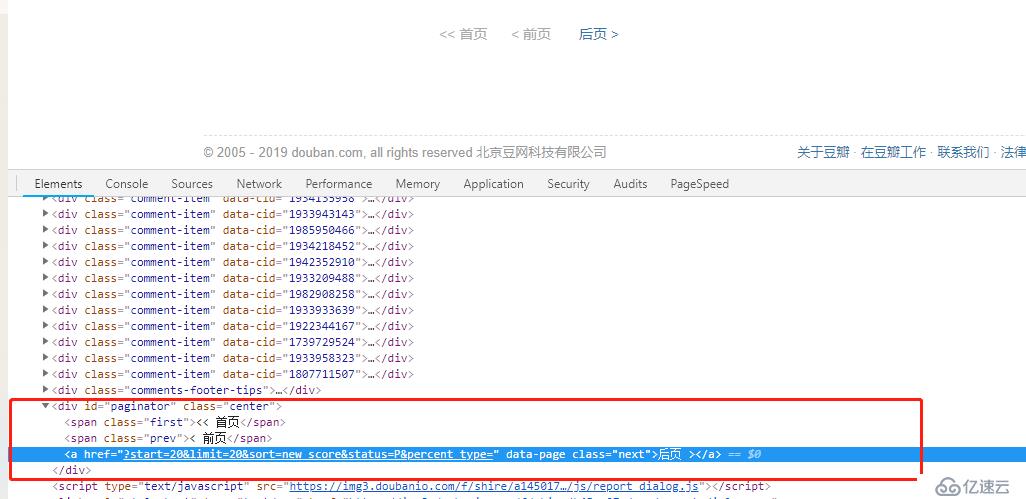
browser.get("https://movie.douban.com/subject/27119724/comments?status=P")
comments = browser.find_elements_by_class_name("short")
WriteComment(comments)
while True:
link = browser.find_element_by_class_name("next")
path = link.get_attribute('href')
if not path:
break
# print(path)
link.click()
time.sleep(3)
comments = browser.find_elements_by_class_name("short")
WriteComment(comments)
browser.quit()
# е°ҶиҜ„и®әеҶҷе…ҘеҲ°жҢҮе®ҡзҡ„ж–Үжң¬ж–Ү件
def WriteComment(comments):
with open("comments.txt", "a+") as f:
for comment in comments:
f.write(comment.text+" \n") вҖғд»Јз Ғи§ЈжһҗпјҡжҠ“еҸ–зҡ„д»Јз ҒжІЎе•ҘеҘҪи®Ізҡ„пјҢе°ұжҳҜжүҫеҲ°classnameжҳҜ'shortвҖҳзҡ„е…ғзҙ пјҢиҺ·еҸ–йҮҢйқўзҡ„ж–Үжң¬еҶ…е®№еҶҷеҲ°жҢҮе®ҡж–Үжң¬ж–Ү件еҚіеҸҜпјҢйҮҢйқўдё»иҰҒжңүдёӘеҫӘзҺҜеҲӨж–ӯжҳҜеҗҰиҝҳжңүдёӢдёҖйЎөпјҢйҖҡиҝҮиҺ·еҸ–дёӢдёҖйЎөзҡ„и¶…й“ҫжҺҘпјҢеҪ“иҺ·еҸ–дёҚеҲ°ж—¶иҜҒжҳҺе·Із»ҸеңЁжңҖеҗҺдёҖйЎөдәҶгҖӮ
вҖғеӨ§жҰӮи®Іи®ІжҖқи·Ҝеҗ§пјҢжҲ‘иҝҷйҮҢзҡ„ж•°жҚ®еӨ„зҗҶжҜ”иҫғзІ—зіҷпјҢжІЎжңүз»“еҗҲpandas+numpyпјҢжҲ‘е°ҶзҲ¬еҸ–дёӢжқҘзҡ„ж•°жҚ®пјҢз®ҖеҚ•зҡ„е°ҶжҚўиЎҢз¬ҰеҲҮеүІз„¶еҗҺз»„жҲҗж–°зҡ„ж•°жҚ®пјҢ然еҗҺйҖҡиҝҮjiebaеҲҶиҜҚпјҢе°Ҷж–°зҡ„ж•°жҚ®иҝӣиЎҢеҲҶиҜҚпјҢжңҖеҗҺеҶҚиҜ»еҸ–жң¬ең°зҡ„дёҖдёӘеҒңйЎҝиҜҚж–Ү件пјҢиҺ·еҸ–дёҖдёӘеҒңйЎҝиҜҚеҲ—иЎЁгҖӮз”ҹжҲҗиҜҚдә‘жҢҮе®ҡеҒңйЎҝиҜҚпјҢд»ҘеҸҠеӯ—дҪ“ж–Ү件пјҢиғҢжҷҜйўңиүІзӯүпјҢеҶҚжҠҠиҜҚдә‘еӣҫзүҮдҝқеӯҳеҲ°жң¬ең°гҖӮ
from wordcloud import WordCloud
from scipy.misc import imread
import jieba
# еӨ„зҗҶд»Һж–Үжң¬дёӯиҜ»еҸ–зҡ„еҶ…е®№
def text_read(file_path):
filename = open(file_path, 'r', encoding='utf-8')
texts = filename.read()
texts_split = texts.split("\n")
filename.close()
return texts_split
def data_handle(picture_name):
# иҜ»еҸ–д»ҺзҪ‘з«ҷдёҠзҲ¬еҸ–дёӢжқҘзҡ„ж•°жҚ®
comments = text_read("comments.txt")
comments = "".join(comments)
# еҲҶиҜҚ, иҜ»еҸ–еҒңйЎҝиҜҚ
lcut = jieba.lcut(comments)
cut_text = "/".join(lcut)
stopwords = text_read("chineseStopWords.txt")
# з”ҹжҲҗиҜҚдә‘еӣҫ
bmask = imread("backgrounds.jpg")
wordcloud = WordCloud(font_path='/usr/share/fonts/chinese/simhei.ttf', mask=bmask, background_color='white', max_font_size=250, width=1300, height=800, stopwords=stopwords)
wordcloud.generate(cut_text)
wordcloud.to_file(picture_name)
if __name__ == "__main__":
data_handle("joker6.jpg")иҝҷжҳҜжҲ‘иҮӘе·ұжүЈзҡ„дёҖеј еӣҫзүҮдҪңдёәиғҢжҷҜпјҡ

жңҖз»Ҳж•Ҳжһңеӣҫпјҡ

вҖғеҶҷзҲ¬иҷ«еҲ°ж•°жҚ®еҲҶжһҗпјҢеӨ§жҰӮжңүжҖқи·Ҝд»ҘеҸҠж•ҙзҗҶйңҖиҰҒз”ЁеҲ°зҡ„е·Ҙе…·еӨ§жҰӮиҠұдәҶдёӨдёӘжҷҡдёҠгҖӮж•ҙдҪ“жқҘиҜҙпјҢиҝҳжҳҜдёҖдәӣжҜ”иҫғжө…жҳҫжҳ“жҮӮзҡ„дёңиҘҝпјҢеҜ№дәҺжңүе…ізҲ¬иҷ«еӨ§и§„模并еҸ‘йҮҮйӣҶ д»ҘеҸҠж•°жҚ®еҲҶжһҗзӯүеҶ…е®№иҝҳеңЁеӯҰд№ пјҢи®°еҪ•дёӢиҮӘе·ұеӯҰд№ иҝҮзЁӢиҝҳжҳҜиӣ®жңүи¶Јзҡ„гҖӮ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ