жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
еҮҪж•°жҲ–ж–№жі•жҺүи°ғз”Ёзҡ„ж—¶еҖҷпјҢиў«и°ғз”ЁиҖ…жҳҜеҗҰиғҪеҫ—еҲ°жңҖз»Ҳз»“жһңжқҘеҲӨж–ӯеҗҢжӯҘе’ҢејӮжӯҘ
зӣҙжҺҘеҫ—еҲ°жңҖз»Ҳз»“жһңзҡ„пјҢе°ұжҳҜеҗҢжӯҘи°ғз”Ё
дёҚзӣҙжҺҘеҫ—еҲ°жңҖз»Ҳз»“жһңзҡ„пјҢе°ұжҳҜејӮжӯҘи°ғз”ЁеҗҢжӯҘе°ұжҳҜжҲ‘и®©дҪ жү“йҘӯпјҢдҪ дёҚжү“еҘҪжҲ‘е°ұдёҚиө°ејҖпјҢзӣҙеҲ°дҪ жү“йҘӯз»ҷдәҶжҲ‘
ејӮжӯҘе°ұжҳҜжҲ‘и®©дҪ жү“йҘӯпјҢдҪ зӯүзқҖпјҢжҲ‘дёҚзӯүдҪ пјҢдҪҶжҳҜжҲ‘дјҡзӣҜзқҖдҪ пјҢдҪ жү“е®ҢжҲ‘дјҡиҝҮжқҘжӢҝиө°пјҢејӮжӯҘ并дёҚиғҪдҝқиҜҒеӨҡй•ҝж—¶й—ҙе°ҶйҘӯжү“е®ҢгҖӮејӮжӯҘз»ҷзҡ„жҳҜдёҙж—¶з»“жһңпјҢзӣ®еүҚжҳҜжӢҝдёҚеҲ°зҡ„
еҗҢжӯҘеҸӘзңӢз»“жһңжҳҜдёҚжҳҜжңҖз»Ҳз»“жһңиҝӣиЎҢеҲӨж–ӯ
еҮҪж•°жҲ–ж–№жі•и°ғз”Ёзҡ„ж—¶еҖҷпјҢжҳҜеҗҰз«ӢеҚіиҝ”еӣһ
з«ӢеҚіиҝ”еӣһе°ұжҳҜйқһйҳ»еЎһи°ғз”Ё
дёҚз«ӢеҚіиҝ”еӣһе°ұжҳҜйҳ»еЎһи°ғз”Ё
еҗҢжӯҘпјҢејӮжӯҘпјҢйҳ»еЎһпјҢйқһйҳ»еЎһ дёҚзӣёе…і
еҗҢжӯҘејӮжӯҘејәи°ғзҡ„жҳҜз»“жһң
йҳ»еЎһпјҢйқһйҳ»еЎһејәи°ғзҡ„жҳҜж—¶й—ҙпјҢжҳҜеҗҰзӯүеҫ…еҗҢжӯҘе’ҢејӮжӯҘзҡ„еҢәеҲ«еңЁдәҺпјҡи°ғз”ЁиҖ…жҳҜеҗҰеҫ—еҲ°еҸҜжғіиҰҒзҡ„з»“жһң
еҗҢжӯҘе°ұжҳҜдёҖзӣҙиҰҒжү§иЎҢеҲ°иҝ”еӣһз»“жһң
ејӮжӯҘе°ұжҳҜзӣҙжҺҘиҝ”еӣһдәҶпјҢдҪҶжҳҜдёҚжҳҜжңҖз»Ҳз»“жһңпјҢи°ғз”ЁиҖ…дёҚиғҪйҖҡиҝҮиҝҷз§Қи°ғз”Ёж–№ејҸеҫ—еҲ°з»“жһңпјҢиҝҳжҳҜйңҖиҰҒйҖҡиҝҮиў«и°ғз”ЁиҖ…пјҢдҪҝз”Ёе…¶д»–ж–№ејҸйҖҡзҹҘи°ғз”ЁиҖ…пјҢжқҘеҸ–еӣһжңҖз»Ҳзҡ„з»“жһң
еҗҢжӯҘйҳ»еЎһпјҡжҲ‘е•ҘдәӢд№ҹдёҚе№ІпјҢе°ұзӯүдҪ жү“йҘӯз»ҷжҲ‘пјҢжү“йҘӯжҳҜз»“жһңпјҢиҖҢдё”жҲ‘е•ҘдәӢд№ҹдёҚж•ўе°ұдёҖзӣҙзӯүпјҢеҗҢжӯҘеҠ йҳ»еЎһгҖӮ
еҗҢжӯҘйқһйҳ»еЎһпјҡжҲ‘зӯүзқҖдҪ жү“йҘӯз»ҷжҲ‘пјҢдҪҶжҲ‘еҸҜд»Ҙе®ҢжүӢжңәпјҢзңӢз”өи§ҶпјҢжү“йҘӯжҳҜз»“жһңпјҢдҪҶжҲ‘дёҚдёҖзӣҙзӯү
ејӮжӯҘйҳ»еЎһпјҡ жҲ‘иҰҒжү“йҘӯпјҢдҪ иҜҙзӯүеҸ·пјҢ并没жңүз»ҷжҲ‘иҝ”еӣһйҘӯпјҢжҲ‘е•ҘдәӢд№ҹдёҚе№ІпјҢе°ұзӯүзқҖйҘӯеҘҪдәҶеҸ«жҲ‘пјҢеҸ«еҸ·гҖӮ
ејӮжӯҘйқһйҳ»еЎһпјҡжҲ‘иҰҒжү“йҘӯпјҢдҪ иҜҙзӯүеҸ·пјҢ并没жңүиҝ”еӣһйҘӯпјҢжҲ‘еңЁж—Ғиҫ№зңӢз”өи§ҶпјҢзҺ©жүӢжңәпјҢеҸҚжү“еҘҪдәҶеҸ«жҲ‘гҖӮ
1 ж•°жҚ®еҮҶеӨҮйҳ¶ж®ө
2 еҶ…ж ёз©әй—ҙеӨҚеҲ¶дјҡз”ЁжҲ·иҝӣзЁӢзј“еҶІеҢәйҳ¶ж®ө
1 еҶ…ж ёд»Һиҫ“е…Ҙи®ҫеӨҮиҜ»еҶҷж•°жҚ®
2 иҝӣзЁӢд»ҺеҶ…ж ёеӨҚеҲ¶ж•°жҚ®
зі»з»ҹи°ғз”Ёread еҮҪж•°
第дёҖдёӘIOйҳ»еЎһзҡ„еҮҪж•°жҳҜinputеҮҪж•°пјҢжҳҜдёҖдёӘеҗҢжӯҘйҳ»еЎһжЁЎеһӢпјҢзҪ‘з»ңд№ҹжҳҜдёҖдёӘIOпјҢж ҮеҮҶиҫ“е…ҘпјҢж ҮеҮҶиҫ“еҮәзӯүд№ҹIO
CPU дёҚжү§иЎҢжӢ·иҙқж•°жҚ®д»ҺдёҖдёӘеӯҳеӮЁеҢәеҹҹеҲ°еҸҰдёҖдёӘеӯҳеӮЁеҢәеҹҹзҡ„д»»еҠЎпјҢиҝҷйҖҡеёёз”ЁдәҺйҖҡиҝҮзҪ‘з»ңдј иҫ“дёҖдёӘж–Ү件时用дәҺеҮҸе°‘CPUе‘Ёжңҹе’ҢеҶ…еӯҳеёҰе®ҪгҖӮ
ж“ҚдҪңзі»з»ҹжҹҗдәӣ组件пјҲдҫӢеҰӮй©ұеҠЁзЁӢеәҸгҖҒж–Ү件系з»ҹе’ҢзҪ‘з»ңеҚҸи®®ж ҲпјүиӢҘйҮҮз”Ёйӣ¶еӨҚеҲ¶жҠҖжңҜпјҢеҲҷиғҪжһҒеӨ§ең°еўһејәдәҶзү№е®ҡеә”з”ЁзЁӢеәҸзҡ„жҖ§иғҪпјҢ并жӣҙжңүж•Ҳең°еҲ©з”Ёзі»з»ҹиө„жәҗгҖӮйҖҡиҝҮдҪҝCPUеҫ—д»Ҙе®ҢжҲҗе…¶д»–иҖҢйқһе°ҶжңәеҷЁдёӯзҡ„ж•°жҚ®еӨҚеҲ¶еҲ°еҸҰдёҖеӨ„зҡ„д»»еҠЎпјҢжҖ§иғҪд№ҹеҫ—еҲ°дәҶеўһејәгҖӮеҸҰеӨ–пјҢйӣ¶еӨҚеҲ¶ж“ҚдҪңеҮҸе°‘дәҶеңЁз”ЁжҲ·з©әй—ҙдёҺеҶ…ж ёз©әй—ҙд№Ӣй—ҙеҲҮжҚўжЁЎејҸзҡ„ж¬Ўж•°гҖӮ
йӣ¶еӨҚеҲ¶еҚҸи®®еҜ№дәҺзҪ‘з»ңй“ҫи·Ҝе®№йҮҸжҺҘиҝ‘жҲ–и¶…иҝҮCPUеӨ„зҗҶиғҪеҠӣзҡ„й«ҳйҖҹзҪ‘з»ңе°ӨдёәйҮҚиҰҒгҖӮеңЁиҝҷз§ҚзҪ‘з»ңдёӢпјҢCPUеҮ д№Һе°ҶжүҖжңүж—¶й—ҙйғҪиҠұеңЁеӨҚеҲ¶иҰҒдј йҖҒзҡ„ж•°жҚ®дёҠпјҢеӣ жӯӨе°ҶжҲҗдёәдҪҝйҖҡдҝЎйҖҹзҺҮдҪҺдәҺй“ҫи·Ҝе®№йҮҸзҡ„瓶йўҲгҖӮ
1 еҮҸе°‘з”ҡиҮіе®Ңе…ЁйҒҝе…ҚдёҚеҝ…иҰҒзҡ„CPUжӢ·иҙқпјҢд»ҺиҖҢи®©CPU и§Ји„ұеҮәжқҘеҺ»жү§иЎҢе…¶д»–д»»еҠЎ
2 еҮҸе°‘еҶ…еӯҳеёҰе®ҪеҚ з”Ё
3 йҖҡеёёйӣ¶жӢ·иҙқжҠҖжңҜиҝҳиғҪеҮҸе°‘з”ЁжҲ·з©әй—ҙе’ҢеҶ…ж ёз©әй—ҙд№Ӣй—ҙзҡ„дёҠдёӢж–ҮеҲҮжҚў
д»ҺLinuxзі»з»ҹжқҘзңӢпјҢйҷӨдәҶеј•еҜјзі»з»ҹзҡ„BINеҢәпјҢж•ҙдёӘеҶ…еӯҳз©әй—ҙдё»иҰҒиў«еҲҶжҲҗдёӨйғЁеҲҶпјҡ
1 еҶ…ж ёз©әй—ҙ(kernel space ) : дё»иҰҒжҸҗдҫӣз»ҷзЁӢеәҸи°ғеәҰпјҢеҶ…еӯҳеҲҶй…ҚпјҢиҝһжҺҘ硬件иө„жәҗзӯүзЁӢеәҸйҖ»иҫ‘з©әй—ҙ
2 з”ЁжҲ·з©әй—ҙ (user space)пјҡ жҸҗдҫӣз»ҷеҗ„дёӘиҝӣзЁӢзҡ„дё»иҰҒз©әй—ҙпјҢз”ЁжҲ·з©әй—ҙдёҚе…·еӨҮи®ҝй—®еҶ…ж ёз©әй—ҙиө„жәҗзҡ„жқғйҷҗпјҢеӣ жӯӨеҰӮжһңеә”з”ЁзЁӢеәҸйңҖиҰҒдҪҝз”ЁеҲ°еҶ…ж ёз©әй—ҙзҡ„иө„жәҗпјҢеҲҷйңҖиҰҒйҖҡиҝҮзі»з»ҹи°ғеәҰжқҘе®ҢжҲҗпјҢд»Һз”ЁжҲ·з©әй—ҙеҲҮжҚўеҲ°еҶ…ж ёз©әй—ҙпјҢ然еҗҺеңЁе®ҢжҲҗж“ҚдҪңеҗҺеҶҚд»ҺеҶ…ж ёз©әй—ҙеҲҮжҚўеҲ°з”ЁжҲ·з©әй—ҙ
1 зӣҙжҺҘI/Oпјҡ еҜ№дәҺиҝҷз§Қдј иҫ“ж–№ејҸжқҘиҜҙпјҢеә”з”ЁзЁӢеәҸеҸҜд»ҘзӣҙжҺҘи®ҝ问硬件еӯҳеӮЁпјҢж“ҚдҪңзі»з»ҹеҶ…ж ёеҸӘжҳҜиҫ…еҠ©ж•°жҚ®дј иҫ“пјҢиҝҷз§Қж–№ејҸдҫқж—§еӯҳеңЁз”ЁжҲ·з©әй—ҙе’ҢеҶ…ж ёз©әй—ҙзҡ„дёҠдёӢж–ҮеҲҮжҚўпјҢдҪҶ硬件дёҠзҡ„ж•°жҚ®дёҚдјҡжӢ·иҙқеҲ°еҶ…ж ёз©әй—ҙпјҢиҖҢжҳҜзӣҙжҺҘжӢ·иҙқеҲ°еҸҜз”ЁжҲ·з©әй—ҙпјҢеӣ жӯӨзӣҙжҺҘIOдёҚеӯҳеңЁеҶ…ж ёз©әй—ҙзј“еҶІеҢәе’Ңз”ЁжҲ·з©әй—ҙзј“еҶІеҢәд№Ӣй—ҙзҡ„ж•°жҚ®жӢ·иҙқ
2 еңЁж•°жҚ®дј иҫ“иҝҮзЁӢдёӯпјҢйҒҝе…Қж•°жҚ®еңЁз”ЁжҲ·з©әй—ҙзј“еҶІеҢәе’ҢеҶ…ж ёз©әй—ҙзј“еҶІеҢәд№Ӣй—ҙзҡ„CPUжӢ·иҙқпјҢд»ҘеҸҠж•°жҚ®еңЁзі»з»ҹеҶ…ж ёз©әй—ҙзҡ„CPUжӢ·иҙқпјҢ
3 copy-on-write(еҶҷж—¶еӨҚеҲ¶жҠҖжңҜ)пјҡеңЁжҹҗдәӣжғ…еҶөдёӢпјҢLinuxж“ҚдҪңзі»з»ҹзҡ„еҶ…ж ёзј“еҶІеҢәеҸҜиғҪиў«еӨҡдёӘеә”з”ЁзЁӢеәҸе…ұдә«пјҢж“ҚдҪңзі»з»ҹжңүеҸҜиғҪдјҡе°Ҷз”ЁжҲ·з©әй—ҙзј“еҶІеҢәең°еқҖжҳ е°„иҖғеҶ…ж ёз©әй—ҙзј“еҶІеҢәпјҢеҪ“еә”з”ЁзЁӢеәҸйңҖиҰҒеҜ№е…ұдә«зҡ„ж•°жҚ®иҝӣиЎҢдҝ®ж”№ж—¶пјҢжүҚйңҖиҰҒзңҹжӯЈзҡ„жӢ·иҙқж•°жҚ®еҲ°еә”з”ЁзЁӢеәҸзҡ„з”ЁжҲ·з©әй—ҙзј“еҶІеҢәдёӯпјҢ并且еҜ№иҮӘе·ұзҡ„з”ЁжҲ·з©әй—ҙзҡ„зј“еҶІеҢәзҡ„ж•°жҚ®иҝӣиЎҢдҝ®ж”№дёҚдјҡеҪұе“ҚеҲ°е…¶д»–е…ұдә«ж•°жҚ®зҡ„еә”з”ЁзЁӢеәҸпјҢжүҖд»ҘпјҢеҰӮжһңеә”з”ЁзЁӢеәҸдёҚйңҖиҰҒеҜ№ж•°жҚ®иҝӣиЎҢд»»дҪ•дҝ®ж”№пјҢе°ұдёҚдјҡеӯҳеңЁж•°жҚ®д»Һзі»з»ҹеҶ…ж ёз©әй—ҙзј“еҶІеҢәжӢ·иҙқеҲ°з”ЁжҲ·з©әй—ҙзј“еҶІеҢәзҡ„ж“ҚдҪңгҖӮ
еҜ№дәҺйӣ¶жӢ·иҙқжҠҖжңҜжҳҜеҗҰе®һзҺ°дё»иҰҒдҫқиө–дәҺж“ҚдҪңзі»з»ҹеә•еұӮжҳҜеҗҰжҸҗдҫӣзӣёеә”зҡ„ж”ҜжҢҒгҖӮ
1 еҸ‘иө·readзі»з»ҹи°ғз”Ёпјҡ еҜјиҮҙз”ЁжҲ·з©әй—ҙеҲ°еҶ…ж ёз©әй—ҙзҡ„дёҠдёӢж–ҮеҲҮжҚў(第дёҖж¬ЎдёҠдёӢж–ҮеҲҮжҚў),йҖҡиҝҮDMAеј•ж“Һе°Ҷж–Ү件дёӯзҡ„ж•°жҚ®д»ҺзЈҒзӣҳдёҠиҜ»еҸ–еҲ°еҶ…ж ёз©әй—ҙзј“еҶІеҢә(第дёҖж¬ЎжӢ·иҙқпјҡhand drive ----> kernel buffer)
2 е°ҶеҶ…ж ёз©әй—ҙзј“еҶІеҢәзҡ„ж•°жҚ®жӢ·иҙқеҲ°з”ЁжҲ·з©әй—ҙзј“еҶІеҢәдёӯ(第дәҢж¬ЎжӢ·иҙқ: kernel buffer ---> user buffer)пјҢ然еҗҺreadзі»з»ҹи°ғз”Ёиҝ”еӣһпјҢиҖҢзі»з»ҹи°ғз”Ёзҡ„иҝ”еӣһеҸҲдјҡеҜјиҮҙдёҖж¬ЎеҶ…ж ёз©әй—ҙеҲ°з”ЁжҲ·з©әй—ҙзҡ„дёҠдёӢж–ҮеҲҮжҚў(第дәҢж¬ЎдёҠдёӢж–ҮеҲҮжҚў)
3 еҸ‘еҮәwriteзі»з»ҹи°ғз”Ёпјҡ еҜјиҮҙз”ЁжҲ·з©әй—ҙеҲ°еҶ…ж ёз©әй—ҙзҡ„дёҠдёӢж–ҮеҲҮжҚў(第дёүж¬ЎдёҠдёӢж–ҮеҲҮжҚў),е°Ҷз”ЁжҲ·з©әй—ҙзј“еҶІеҢәзҡ„ж•°жҚ®жӢ·иҙқеҲ°еҶ…ж ёз©әй—ҙдёӯдәҺsocketзӣёе…ізҡ„зј“еҶІеҢәдёӯпјҢ(еҸҠ第дәҢжӯҘд»ҺеҶ…ж ёз©әй—ҙзј“еҶІеҢәжӢ·иҙқзҡ„ж•°жҚ®еҺҹе°ҒдёҚеҠЁзҡ„еҶҚж¬ЎжӢ·иҙқеҲ°еҶ…ж ёз©әй—ҙзҡ„socketзј“еҶІеҢәдёӯ)( 第дёүж¬ЎжӢ·иҙқ: user buffer--> socket buffer)
4 write зі»з»ҹи°ғз”Ёиҝ”еӣһпјҢеҜјиҮҙеҶ…ж ёз©әй—ҙеҲ°з”ЁжҲ·з©әй—ҙзҡ„еҶҚж¬ЎдёҠдёӢж–ҮеҲҮжҚў(第еӣӣж¬ЎдёҠдёӢж–ҮеҲҮжҚў)пјҢйҖҡиҝҮDMAеј•ж“Һе°ҶеҶ…ж ёзј“еҶІеҢәдёӯзҡ„ж•°жҚ®дј йҖ’еҲ°еҚҸи®®еј•ж“Һ(第еӣӣж¬ЎжӢ·иҙқ:socket buffer -> protocol engine )пјҢиҝҷж¬ЎжӢ·иҙқж—¶зӢ¬з«Ӣзҡ„ејӮжӯҘзҡ„иҝҮзЁӢгҖӮ
дәӢе®һдёҠи°ғз”Ёзҡ„иҝ”еӣһ并дёҚдҝқиҜҒж•°жҚ®иў«дј иҫ“пјҢз”ҡиҮідёҚдҝқиҜҒж•°жҚ®дј иҫ“зҡ„ејҖе§ӢпјҢеҸӘжҳҜж„Ҹе‘ізқҖе°ҶжҲ‘д№ҲиҰҒеҸ‘йҖҒзҡ„ж•°жҚ®ж”ҫе…ҘеҲ°дәҶдёҖдёӘеҫ…еҸ‘йҖҒзҡ„йҳҹеҲ—дёӯпјҢйҷӨйқһе®һзҺ°дәҶдјҳе…ҲзҺҜжҲ–иҖ…йҳҹеҲ—пјҢеҗҰеҲҷдјҡжҳҜе…Ҳиҝӣе…ҲеҮәзҡ„ж–№ејҸеҸ‘йҖҒж•°жҚ®зҡ„гҖӮ
жҖ»зҡ„жқҘиҜҙпјҢдј з»ҹзҡ„I/Oж“ҚдҪңиҝӣиЎҢдәҶ4ж¬Ўз”ЁжҲ·з©әй—ҙдёҺеҶ…ж ёз©әй—ҙзҡ„дёҠдёӢж–ҮеҲҮжҚўпјҢд»ҘеҸҠ4ж¬Ўж•°жҚ®жӢ·иҙқгҖӮе…¶дёӯ4ж¬Ўж•°жҚ®жӢ·иҙқдёӯеҢ…жӢ¬дәҶ2ж¬ЎDMAжӢ·иҙқе’Ң2ж¬ЎCPUжӢ·иҙқгҖӮ
дј з»ҹжЁЎејҸдёәдҪ•е°Ҷж•°жҚ®д»ҺзЈҒзӣҳиҜ»еҸ–еҲ°еҶ…ж ёз©әй—ҙиҖҢдёҚжҳҜзӣҙжҺҘиҜ»еҸ–еҲ°з”ЁжҲ·з©әй—ҙзј“еҶІеҢәпјҢе…¶еҺҹеӣ жҳҜдёәдәҶеҮҸе°‘IOж“ҚдҪңд»ҘжҸҗй«ҳжҖ§иғҪпјҢеӣ дёәOSдјҡж №жҚ®еұҖйғЁжҖ§еҺҹзҗҶдёҖж¬Ўread() зі»з»ҹи°ғз”Ёзҡ„ж—¶еҖҷйў„иҜ»еҸ–жӣҙеӨҡзҡ„ж–Ү件数жҚ®еҲ°еҶ…ж ёз©әй—ҙзј“еҶІеҢәдёӯпјҢиҝҷж ·еҪ“дёӢдёҖж¬Ўread()зі»з»ҹи°ғз”Ёзҡ„ж—¶еҖҷеҸ‘зҺ°иҰҒиҜ»еҸ–зҡ„ж•°жҚ®е·Із»ҸеӯҳеңЁдәҺеҶ…ж ёз©әй—ҙзј“еҶІеҢәзҡ„ж—¶еҖҷеҸӘйңҖиҰҒзӣҙжҺҘжӢ·иҙқж•°жҚ®еҲ°з”ЁжҲ·з©әй—ҙзј“еҶІеҢәеҚіеҸҜпјҢж— йңҖеҶҚиҝӣиЎҢдёҖж¬ЎдҪҺж•Ҳзҡ„зЈҒзӣҳIOж“ҚдҪңгҖӮ
Bufferedinputstream дҪңз”ЁжҳҜдјҡж №жҚ®жғ…еҶөиҮӘеҠЁдёәжҲ‘们预иҜ»еҸ–жӣҙеӨҡзҡ„ж•°жҚ®еҲ°д»–иҮӘе·ұз»ҙжҠӨзҡ„дёҖдёӘеҶ…йғЁеӯ—иҠӮж•°жҚ®зј“еҶІеҢәпјҢиҝҷж ·иғҪеҮҸе°‘зі»з»ҹи°ғз”Ёж¬Ўж•°жқҘжҸҗй«ҳжҖ§иғҪгҖӮ
жҖ»зҡ„жқҘиҜҙпјҢеҶ…ж ёзј“еҶІеҢәзҡ„дёҖеӨ§дҪңз”ЁжҳҜдёәдәҶеҮҸе°‘зЈҒзӣҳIOж“ҚеҒҡпјҢBufferedinputstream еҲҷжҳҜеҮҸе°‘"зі»з»ҹи°ғз”Ё"
DMA(direct memory access) --- зӣҙжҺҘеҶ…еӯҳи®ҝй—®пјҢDMA жҳҜе…Ғи®ёеӨ–и®ҫ组件е°ҶIOж•°жҚ®зӣҙжҺҘдј йҖҒеҲ°дё»еӯҳеӮЁеҷЁе№¶е№¶дё”дј иҫ“дёҚйңҖиҰҒCPUеҸӮдёҺпјҢд»ҘжӯӨи§Јж”ҫCPUеҺ»еҒҡе…¶д»–зҡ„дәӢжғ…гҖӮ
иҖҢз”ЁжҲ·з©әй—ҙдёҺеҶ…ж ёз©әй—ҙд№Ӣй—ҙзҡ„ж•°жҚ®дј иҫ“并没жңүзұ»дјјDMAиҝҷз§ҚеҸҜд»ҘдёҚйңҖиҰҒCPUеҸӮдёҺзҡ„дј иҫ“е·Ҙе…·пјҢеӣ жӯӨз”ЁжҲ·з©әй—ҙдёҺеҶ…ж ёз©әй—ҙд№Ӣй—ҙзҡ„ж•°жҚ®дј иҫ“жҳҜйңҖиҰҒCPUе…ЁзЁӢеҸӮдёҺзҡ„гҖӮжүҖжңүд№ҹе°ұжңүдәҶйҖҡиҝҮйӣ¶жӢ·иҙқжҠҖжңҜжқҘеҮҸе°‘е’ҢйҒҝе…ҚдёҚеҝ…иҰҒзҡ„CPUж•°жҚ®жӢ·иҙқиҝҮзЁӢгҖӮ
1 еҸ‘иө·sendfileзі»з»ҹи°ғз”ЁпјҢеҜјиҮҙз”ЁжҲ·з©әй—ҙеҲ°еҶ…ж ёз©әй—ҙзҡ„дёҠдёӢж–ҮеҲҮжҚў(第дёҖж¬ЎдёҠдёӢж–ҮеҲҮжҚў)пјҢйҖҡиҝҮDMAеј•ж“Һе°ҶзЈҒзӣҳж–Ү件дёӯзҡ„еҶ…е®№жӢ·иҙқеҲ°еҶ…ж ёз©әй—ҙзј“еҶІеҢәдёӯпјҲ第дёҖж¬ЎжӢ·иҙқ: hard drive --> kernel bufferпјү然еҗҺеҶҚе°Ҷж•°жҚ®д»ҺеҶ…ж ёз©әй—ҙжӢ·иҙқеҲ°socketзӣёе…ізҡ„зј“еҶІеҢәдёӯпјҢ(第дәҢж¬ЎжӢ·иҙқпјҢkernel ---buffer --> socket buffer)
2 sendfile зі»з»ҹи°ғз”Ёиҝ”еӣһпјҢеҜјиҮҙеҶ…ж ёз©әй—ҙеҲ°з”ЁжҲ·з©әй—ҙзҡ„дёҠдёӢж–ҮеҲҮжҚў(第дәҢж¬ЎдёҠдёӢж–ҮеҲҮжҚў)гҖӮйҖҡиҝҮDMA еј•ж“Һе°ҶеҶ…ж ёз©әй—ҙзҡ„socketзј“еҶІеҢәзҡ„ж•°жҚ®дј йҖ’еҲ°еҚҸи®®еј•ж“Һ(第дёүж¬ЎжӢ·иҙқпјҡsocket buffer-> protocol engine )
жҖ»зҡ„жқҘиҜҙпјҢйҖҡиҝҮsendfileе®һзҺ°зҡ„йӣ¶жӢ·иҙқI/OеҸӘдҪҝз”ЁдәҶ2ж¬Ўз”ЁжҲ·з©әй—ҙдёҺеҶ…ж ёз©әй—ҙзҡ„дёҠдёӢж–ҮеҲҮжҚўпјҢд»ҘеҸҠ3ж¬Ўж•°жҚ®зҡ„жӢ·иҙқгҖӮе…¶дёӯ3ж¬Ўж•°жҚ®жӢ·иҙқдёӯеҢ…жӢ¬дәҶ2ж¬ЎDMAжӢ·иҙқе’Ң1ж¬ЎCPUжӢ·иҙқгҖӮ
QпјҡдҪҶйҖҡиҝҮжҳҜиҝҷйҮҢиҝҳжҳҜеӯҳеңЁзқҖдёҖж¬ЎCPUжӢ·иҙқж“ҚдҪңпјҢеҚіпјҢkernel buffer вҖ”вҖ”> socket bufferгҖӮжҳҜеҗҰжңүеҠһжі•е°ҶиҜҘжӢ·иҙқж“ҚдҪңд№ҹеҸ–ж¶ҲжҺүдәҶпјҹ
Aпјҡжңүзҡ„гҖӮдҪҶиҝҷйңҖиҰҒеә•еұӮж“ҚдҪңзі»з»ҹзҡ„ж”ҜжҢҒгҖӮд»ҺLinux 2.4зүҲжң¬ејҖе§ӢпјҢж“ҚдҪңзі»з»ҹеә•еұӮжҸҗдҫӣдәҶscatter/gatherиҝҷз§ҚDMAзҡ„ж–№ејҸжқҘд»ҺеҶ…ж ёз©әй—ҙзј“еҶІеҢәдёӯе°Ҷж•°жҚ®зӣҙжҺҘиҜ»еҸ–еҲ°еҚҸи®®еј•ж“ҺдёӯпјҢиҖҢж— йңҖе°ҶеҶ…ж ёз©әй—ҙзј“еҶІеҢәдёӯзҡ„ж•°жҚ®еҶҚжӢ·иҙқдёҖд»ҪеҲ°еҶ…ж ёз©әй—ҙsocketзӣёе…іиҒ”зҡ„зј“еҶІеҢәдёӯгҖӮ
д»ҺLinux 2.4 ејҖе§ӢпјҢж“ҚеҒҡзі»з»ҹеә•еұӮжҸҗдҫӣдәҶеёҰжңүscatter/gather зҡ„DMAжқҘд»ҺеҶ…ж ёз©әй—ҙзј“еҶІеҢәдёӯе°Ҷж•°жҚ®иҜ»еҸ–еҲ°еҚҸи®®еј•ж“ҺдёӯпјҢиҝҷж ·д»ҘжқҘеҫ…дј иҫ“зҡ„ж•°жҚ®еҸҜд»ҘеҲҶж•ЈеҶҚеӯҳеӮЁзҡ„дёҚеҗҢдҪҚзҪ®пјҢиҖҢдёҚйңҖиҰҒеҶҚиҝһз»ӯеӯҳеӮЁдёӯеӯҳж”ҫпјҢйӮЈд№Ҳд»Һж–Ү件дёӯиҜ»еҮәзҡ„ж•°жҚ®е°ұж №жң¬дёҚйңҖиҰҒиў«жӢ·иҙқеҲ°socketзј“еҶІеҢәдёӯеҺ»пјҢеҸӘжҳҜйңҖиҰҒе°Ҷзј“еҶІеҢәжҸҸиҝ°з¬Ұж·»еҠ еҲ°socketзј“еҶІеҢәдёӯеҺ»пјҢDMA收йӣҶж“ҚдҪңдјҡж №жҚ®зј“еҶІеҢәжҸҸиҝ°з¬Ұдёӯзҡ„дҝЎжҒҜе°ҶеҶ…ж ёз©әй—ҙдёӯзҡ„ж•°жҚ®зӣҙжҺҘжӢ·иҙқеҲ°еҚҸи®®еј•ж“Һдёӯ
1 еҸ‘еҮәsendfile зі»з»ҹи°ғз”ЁпјҢеҜјиҮҙз”ЁжҲ·з©әй—ҙеҲ°еҶ…ж ёз©әй—ҙзҡ„дёҠдёӢж–ҮеҲҮжҚўпјҢйҖҡиҝҮDMA еј•ж“Һе°ҶзЈҒзӣҳж–Ү件еҶ…е®№жӢ·иҙқеҲ°еҶ…ж ёз©әй—ҙзј“еҶІеҢәдёӯ(第дёҖж¬ЎжӢ·иҙқ: hard drive -> kernel buffer)
2 жІЎжңүж•°жҚ®жӢ·иҙқеҲ°socketзј“еҶІеҢәпјҢеҸ–иҖҢд»Јд№Ӣзҡ„жҳҜеҸӘжңүеҗ‘зӣёеә”зҡ„жҸҸиҝ°дҝЎжҒҜиў«жӢ·иҙқеҲ°зӣёеә”зҡ„socketзј“еҶІеҢәдёӯпјҢиҜҘжҸҸиҝ°дҝЎжҒҜеҢ…еҗ«дәҶдёӨдёӘж–№йқў: 1 kernel buffer зҡ„еҶ…еӯҳең°еқҖ 2 kernel buffer зҡ„еҒҸ移йҮҸгҖӮ
3 sendfile зі»з»ҹи°ғз”Ёиҝ”еӣһпјҢеҜјиҮҙеҶ…ж ёз©әй—ҙеҲ°з”ЁжҲ·з©әй—ҙзҡ„дёҠдёӢж–ҮеҲҮжҚў(第дәҢж¬ЎдёҠдёӢж–ҮеҲҮжҚў),DMA gather copy ж №жҚ® socketзј“еҶІеҢәдёӯжҸҸиҝ°з¬ҰжҸҗдҫӣзҡ„дҪҚзҪ®е’ҢеҒҸ移йҮҸдҝЎжҒҜзӣҙжҺҘе°ҶеҶ…ж ёз©әй—ҙзҡ„ж•°жҚ®жӢ·иҙқеҲ°еҚҸи®®еј•ж“ҺдёҠ(kernel buffer --> protocol engine)пјҢиҝҷж ·е°ұйҒҝе…ҚдәҶжңҖеҗҺдҫқж¬ЎCPUж•°жҚ®жӢ·иҙқ
жҖ»зҡ„жқҘиҜҙпјҢеёҰжңүDMA收йӣҶжӢ·иҙқеҠҹиғҪзҡ„sendfileе®һзҺ°зҡ„I/OеҸӘдҪҝз”ЁдәҶ2ж¬Ўз”ЁжҲ·з©әй—ҙдёҺеҶ…ж ёз©әй—ҙзҡ„дёҠдёӢж–ҮеҲҮжҚўпјҢд»ҘеҸҠ2ж¬Ўж•°жҚ®зҡ„жӢ·иҙқпјҢиҖҢдё”иҝҷ2ж¬Ўзҡ„ж•°жҚ®жӢ·иҙқйғҪжҳҜйқһCPUжӢ·иҙқгҖӮиҝҷж ·дёҖжқҘжҲ‘们е°ұе®һзҺ°дәҶжңҖзҗҶжғізҡ„йӣ¶жӢ·иҙқI/Oдј иҫ“дәҶпјҢдёҚйңҖиҰҒд»»дҪ•дёҖж¬Ўзҡ„CPUжӢ·иҙқпјҢд»ҘеҸҠжңҖе°‘зҡ„дёҠдёӢж–ҮеҲҮжҚўгҖӮ
еңЁLinux 2.6.33 зүҲжң¬д№ӢеүҚsendfileж”ҜжҢҒж–Ү件еҲ°еҘ—жҺҘеӯ—д№Ӣй—ҙзҡ„дј иҫ“пјҢеҸҠin_fd зӣёеҪ“дәҺдёҖдёӘж”ҜжҢҒmmapзҡ„ж–Ү件пјҢout_fd еҝ…йЎ»жҳҜдёҖдёӘsocketпјҢдҪҶд»ҺLinux 2.6.33зүҲжң¬ејҖе§ӢпјҢout_fd еҸҜд»ҘжҳҜд»»ж„Ҹзұ»еһӢж–Ү件жҸҸиҝ°з¬ҰпјҢжүҖд»Ҙд»ҺLinux 2.6.33 зүҲжң¬ејҖе§Ӣsendfile еҸҜд»Ҙж”ҜжҢҒж–Ү件еҲ°ж–Ү件пјҢж–Ү件еҲ°еҘ—жҺҘеӯ—д№Ӣй—ҙзҡ„ж•°жҚ®дј иҫ“гҖӮ
дј з»ҹI/OйҖҡиҝҮдёӨжқЎзі»з»ҹжҢҮд»ӨreadгҖҒwriteжқҘе®ҢжҲҗж•°жҚ®зҡ„иҜ»еҸ–е’Ңдј иҫ“ж“ҚдҪңпјҢд»ҘиҮідәҺдә§з”ҹдәҶ4ж¬Ўз”ЁжҲ·з©әй—ҙдёҺеҶ…ж ёз©әй—ҙзҡ„дёҠдёӢж–ҮеҲҮжҚўзҡ„ејҖй”ҖпјӣиҖҢsendfileеҸӘдҪҝз”ЁдәҶдёҖжқЎжҢҮд»Өе°ұе®ҢжҲҗдәҶж•°жҚ®зҡ„иҜ»еҶҷж“ҚдҪңпјҢжүҖд»ҘеҸӘдә§з”ҹдәҶ2ж¬Ўз”ЁжҲ·з©әй—ҙдёҺеҶ…ж ёз©әй—ҙзҡ„дёҠдёӢж–ҮеҲҮжҚўгҖӮ
дј з»ҹI/Oдә§з”ҹдәҶ2ж¬Ўж— з”Ёзҡ„CPUжӢ·иҙқпјҢеҚіеҶ…ж ёз©әй—ҙзј“еӯҳдёӯж•°жҚ®дёҺз”ЁжҲ·з©әй—ҙзј“еҶІеҢәй—ҙж•°жҚ®зҡ„жӢ·иҙқпјӣиҖҢsendfileжңҖеӨҡеҸӘдә§еҮәдәҶдёҖж¬ЎCPUжӢ·иҙқпјҢеҚіеҶ…ж ёз©әй—ҙеҶ…д№Ӣй—ҙзҡ„ж•°жҚ®жӢ·иҙқпјҢз”ҡиҮіеңЁеә•еұӮж“ҚдҪңдҪ“зі»ж”ҜжҢҒзҡ„жғ…еҶөдёӢпјҢsendfileеҸҜд»Ҙе®һзҺ°йӣ¶CPUжӢ·иҙқзҡ„I/OгҖӮ
еӣ дј з»ҹI/Oз”ЁжҲ·з©әй—ҙзј“еҶІеҢәдёӯеӯҳжңүж•°жҚ®пјҢеӣ жӯӨеә”з”ЁзЁӢеәҸиғҪеӨҹеҜ№жӯӨж•°жҚ®иҝӣиЎҢдҝ®ж”№зӯүж“ҚдҪңпјӣиҖҢsendfileйӣ¶жӢ·иҙқж¶ҲйҷӨдәҶжүҖжңүеҶ…ж ёз©әй—ҙзј“еҶІеҢәдёҺз”ЁжҲ·з©әй—ҙзј“еҶІеҢәд№Ӣй—ҙзҡ„ж•°жҚ®жӢ·иҙқиҝҮзЁӢпјҢеӣ жӯӨsendfileйӣ¶жӢ·иҙқI/Oзҡ„е®һзҺ°жҳҜе®ҢжҲҗеңЁеҶ…ж ёз©әй—ҙдёӯе®ҢжҲҗзҡ„пјҢиҝҷеҜ№дәҺеә”з”ЁзЁӢеәҸжқҘиҜҙе°ұж— жі•еҜ№ж•°жҚ®иҝӣиЎҢж“ҚдҪңдәҶгҖӮ
QпјҡеҜ№дәҺдёҠйқўзҡ„第дёүзӮ№пјҢеҰӮжһңжҲ‘们йңҖиҰҒеҜ№ж•°жҚ®иҝӣиЎҢж“ҚдҪңиҜҘжҖҺд№ҲеҠһдәҶпјҹ
AпјҡLinuxжҸҗдҫӣдәҶmmapйӣ¶жӢ·иҙқжқҘе®һзҺ°жҲ‘们зҡ„йңҖжұӮ
Mmap(еҶ…еӯҳжҳ е°„)жҳҜдёҖдёӘжҜ”sendfileжҳӮиҙөдҪҶдјҳдәҺдј з»ҹIOзҡ„ж–№ејҸ
1 еҸ‘еҮәmmapзі»з»ҹи°ғз”ЁпјҢеҜјиҮҙз”ЁжҲ·з©әй—ҙеҲ°еҶ…ж ёз©әй—ҙзҡ„дёҠдёӢж–ҮеҲҮжҚў(第дёҖж¬ЎдёҠдёӢж–ҮеҲҮжҚў)гҖӮйҖҡиҝҮDMAеј•ж“Һе°ҶзЈҒзӣҳж–Ү件дёӯзҡ„еҶ…е®№жӢ·иҙқеҲ°еҶ…ж ёз©әй—ҙзј“еҶІеҢәдёӯ(第дёҖж¬ЎжӢ·иҙқ: hard drive вҖ”вҖ”> kernel buffer)гҖӮ
2 mmap зі»з»ҹи°ғз”Ёиҝ”еӣһпјҢеҜјиҮҙеҶ…ж ёз©әй—ҙеҲ°з”ЁжҲ·з©әй—ҙзҡ„дёҠдёӢж–ҮеҲҮжҚў(第дәҢж¬ЎдёҠдёӢж–ҮеҲҮжҚў)пјҢжҺҘзқҖз”ЁжҲ·з©әй—ҙе’ҢеҶ…ж ёз©әй—ҙе…ұдә«иҝҷдёӘзј“еҶІеҢәпјҢиҖҢдёҚйңҖиҰҒе°Ҷж•°жҚ®д»ҺеҶ…ж ёз©әй—ҙжӢ·иҙқеҲ°з”ЁжҲ·з©әй—ҙпјҢеӣ жӯӨз”ЁжҲ·з©әй—ҙе’ҢеҶ…ж ёз©әй—ҙе…ұдә«зҡ„зј“еҶІеҢә
3 еҸ‘еҮәwrite зі»з»ҹи°ғз”ЁзәўпјҢеҜјиҮҙз”ЁжҲ·з©әй—ҙеҲ°еҶ…ж ёз©әй—ҙ第дёүж¬ЎдёҠдёӢж–ҮеҲҮжҚўпјҢе°Ҷж•°жҚ®д»ҺеҶ…ж ёз©әй—ҙжӢ·иҙқеҲ°еҶ…ж ёз©әй—ҙзҡ„socketзӣёе…ізҡ„зј“еҶІеҢә(第дәҢж¬ЎжӢ·иҙқ:kernel buffer ----> socket buffer )
4 write зі»з»ҹи°ғз”Ёиҝ”еӣһпјҢеҜјиҮҙеҶ…ж ёз©әй—ҙеҲ°з”ЁжҲ·з©әй—ҙзҡ„дёҠдёӢж–ҮеҲҮжҚў(第еӣӣж¬ЎдёҠдёӢж–ҮеҲҮжҚў)пјҢйҖҡиҝҮDMA еј•ж“Һе°ҶеҶ…ж ёз©әй—ҙsocketзј“еҶІеҢәзҡ„ж•°жҚ®дј йҖ’еҲ°еҚҸи®®еј•ж“Һ(第дёүж¬ЎжӢ·иҙқ: socket buffer---> protocol engine)
жҖ»зҡ„жқҘиҜҙпјҢйҖҡиҝҮmmapе®һзҺ°зҡ„йӣ¶жӢ·иҙқI/OиҝӣиЎҢдәҶ4ж¬Ўз”ЁжҲ·з©әй—ҙдёҺеҶ…ж ёз©әй—ҙзҡ„дёҠдёӢж–ҮеҲҮжҚўпјҢд»ҘеҸҠ3ж¬Ўж•°жҚ®жӢ·иҙқгҖӮе…¶дёӯ3ж¬Ўж•°жҚ®жӢ·иҙқдёӯеҢ…жӢ¬дәҶ2ж¬ЎDMAжӢ·иҙқе’Ң1ж¬ЎCPUжӢ·иҙқгҖӮ
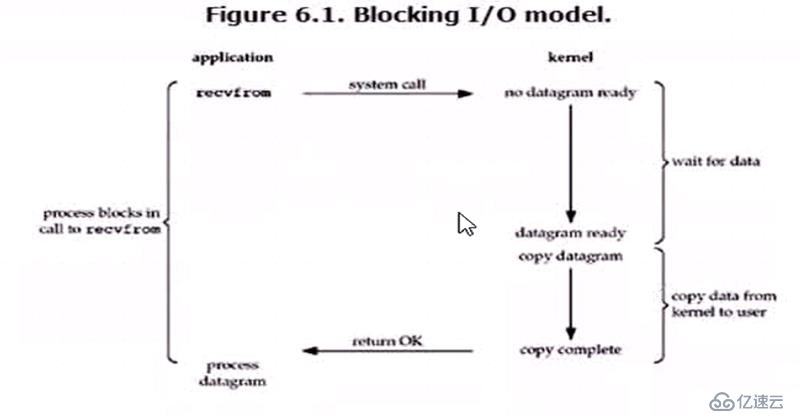
еңЁж–Ү件иҜ»еҸ–иҝӣе…ҘеҶ…ж ёз©әй—ҙе’Ңд»ҺеҶ…ж ёз©әй—ҙжӢ·иҙқиҝӣе…Ҙз”ЁжҲ·иҝӣзЁӢз©әй—ҙзҡ„иҝҮзЁӢдёӯпјҢжІЎжңүд»»дҪ•зҡ„ж•°жҚ®иҝ”еӣһпјҢе®ўжҲ·з«ҜеңЁдёҖзӣҙзӯүеҫ…зҠ¶жҖҒгҖӮ
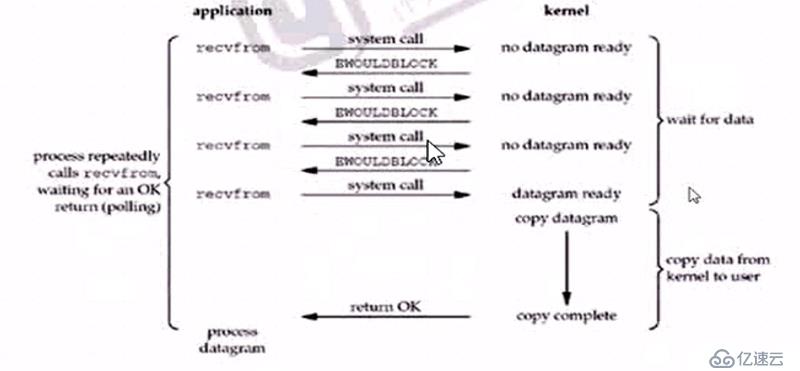
иҝӣзЁӢи°ғз”Ёreadж“ҚдҪңпјҢеҰӮжһңIOжІЎжңүеҮҶеӨҮеҘҪпјҢз«ӢеҚіиҝ”еӣһERRORпјҢиҝӣзЁӢдёҚйҳ»еЎһпјҢз”ЁжҲ·еҸҜд»ҘеҶҚж¬ЎеҸ‘иө·зі»з»ҹи°ғз”ЁпјҢеҰӮжһңеҶ…ж ёе·Із»ҸеҮҶеӨҮеҘҪпјҢе°ұйҳ»еЎһпјҢ然еҗҺеӨҚеҲ¶ж•°жҚ®еҲ°з”ЁжҲ·з©әй—ҙ
第дёҖйҳ¶ж®өж•°жҚ®жІЎеҮҶеӨҮеҘҪпјҢе°ұе…ҲеҝҷеҲ«зҡ„пјҢзӯүдјҡеҶҚзңӢзңӢпјҢжЈҖжҹҘж•°жҚ®жҳҜеҗҰеҮҶеӨҮеҘҪдәҶзҡ„иҝҮзЁӢжҳҜйқһйҳ»еЎһзҡ„
第дәҢйҳ¶ж®өжҳҜйҳ»еЎһзҡ„пјҢеҸҠеҶ…ж ёз©әй—ҙе’Ңз”ЁжҲ·з©әй—ҙд№Ӣй—ҙеӨҚеҲ¶ж•°жҚ®жҳҜйҳ»еЎһзҡ„пјҢдҪҶжҳҜиҰҒзӯүеҫ…йҘӯзӣӣеҘҪжүҚжҳҜе®ҢдәӢпјҢиҝҷжҳҜеҗҢжӯҘзҡ„гҖӮ
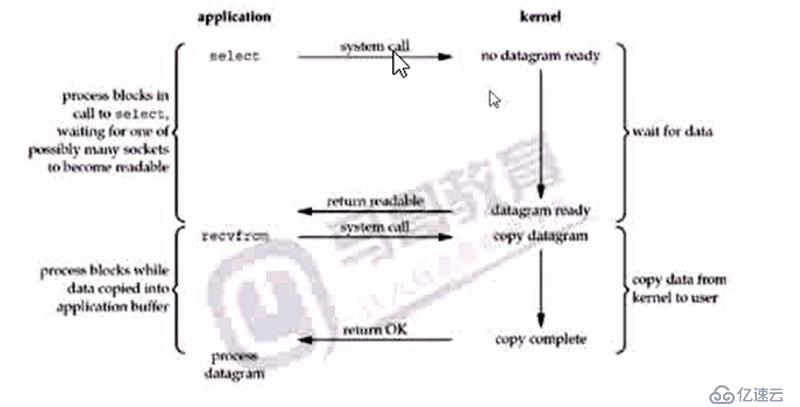
жүҖи°“зҡ„IOеӨҡи·ҜеӨҚз”ЁпјҢе°ұжҳҜеҗҢж—¶зӣ‘жҺ§еӨҡдёӘIOпјҢжңүдёҖдёӘеҮҶеӨҮеҘҪдәҶпјҢе°ұдёҚйңҖиҰҒзӯүеҫ…ејҖе§ӢеӨ„зҗҶпјҢжҸҗй«ҳдәҶеҗҢж—¶еӨ„зҗҶIOзҡ„иғҪеҠӣ
selectжҳҜжүҖжңүе№іеҸ°йғҪж”ҜжҢҒпјҢpollжҳҜеҜ№selectзҡ„еҚҮзә§
epollпјҢLinux зі»з»ҹеҶ…ж ё2.5+ ејҖе§Ӣж”ҜжҢҒпјҢеҜ№selectе’Ңepollзҡ„еўһејәпјҢеңЁзӣ‘и§Ҷзҡ„еҹәзЎҖдёҠпјҢеўһеҠ дәҶеӣһи°ғжңәеҲ¶пјҢBSDпјҢMacзҡ„kqueueпјҢиҝҳжңүwindowsзҡ„iocp
еҰӮжһңж—ўжғіи®ҝй—®зҪ‘з»ңпјҢеҸҲжғіи®ҝй—®ж–Ү件пјҢеҲҷе…Ҳе°ҶеҮҶеӨҮеҘҪзҡ„ж•°жҚ®е…ҲеӨ„зҗҶпјҢйӮЈдёӘеҮҶеӨҮеҘҪдәҶе°ұеӨ„зҗҶйӮЈдёӘ
иғҪеӨҹжҸҗй«ҳеҗҢж—¶еӨ„зҗҶIOзҡ„иғҪеҠӣпјҢи°Ғе…ҲеҒҡзҺ©жҲ‘е…ҲеӨ„зҗҶи°Ғ
дёҠйқўзҡ„дёӨз§Қж–№ејҸпјҢж•ҲзҺҮеӨӘе·®дәҶпјҢзӯүе®ҢдёҖдёӘе®ҢжҲҗеҗҺеҶҚзӯүдёҖдёӘпјҢеӨӘж…ўдәҶгҖӮ
и°ҒеҘҪдәҶеӨ„зҗҶи°ҒпјҢдёҚеҗҢзҡ„е№іеҸ°еҜ№IOеӨҡи·ҜеӨҚз”Ёзҡ„е®һзҺ°ж–№ејҸжҳҜдёҚеҗҢзҡ„
Select е’Ң poll еңЁLinuxпјҢWindowsпјҢе’ҢMACдёӯйғҪж”ҜжҢҒ
дёҖиҲ¬жқҘе°Ҷselectе’Ңpoll еңЁеҗҢдёҖдёӘеұӮж¬ЎпјҢepollжҳҜLinuxдёӯеӯҳеңЁзҡ„
selectеҺҹзҗҶ
1 е°Ҷе…іжіЁзҡ„IOж“ҚдҪңе‘ҠиҜүselectеҮҪ数并и°ғз”ЁпјҢиҝӣзЁӢйҳ»еЎһпјҢеҶ…ж ёзӣ‘и§Ҷselectе…іжіЁзҡ„ж–Ү件пјҢжҸҸиҝ°з¬ҰFDпјҢиў«е…іжіЁзҡ„д»»дҪ•дёҖдёӘFDеҜ№еә”зҡ„IOеҮҶеӨҮеҘҪдәҶж•°жҚ®пјҢselectе°ұиҝ”еӣһпјҢеңЁдҪҝз”Ёreadе°Ҷж•°жҚ®еӨҚеҲ¶еҲ°з”Ёз”ЁжҲ·иҝӣзЁӢгҖӮе…¶selectжЁЎејҸдёӢзҡ„еҮҶеӨҮеҘҪзҡ„йҖҡзҹҘжҳҜжІЎжңүй’ҲеҜ№жҖ§зҡ„пјҢйңҖиҰҒз”ЁжҲ·иҮӘе·ұжүҫеҲ°жҳҜеҗҰжҳҜиҮӘе·ұзҡ„并иҝӣиЎҢеӨ„зҗҶгҖӮselectеҒҡеҲ°зҡ„жҳҜж—¶й—ҙйҮҚеҸ
epollеўһеҠ дәҶеӣһи°ғжңәеҲ¶пјҢйӮЈдёҖи·ҜеҮҶеӨҮеҘҪдәҶпјҢжҲ‘дјҡе‘ҠиҜүдҪ пјҢжңүдёҖз§ҚжҳҜдҪ дёҚз”Ёз®ЎдәҶпјҢеҘҪдәҶжҲ‘зӣҙжҺҘжӣҝдҪ и°ғз”ЁгҖӮ
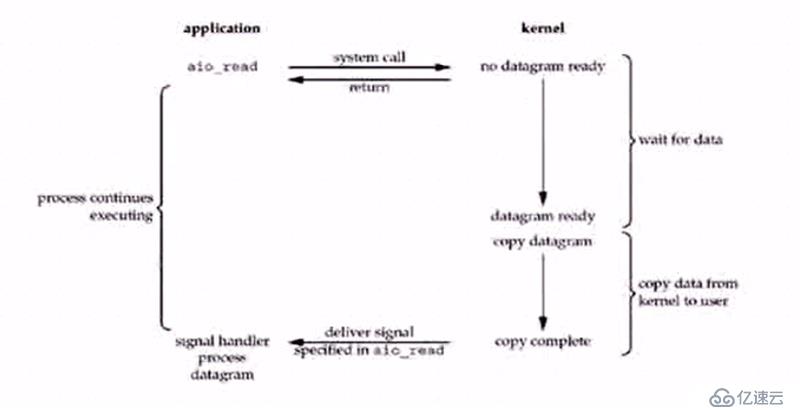
дёӨдёӘйҳ¶ж®ө
зӯүеҫ…ж•°жҚ®еҮҶеӨҮе’ҢжӢ·иҙқйҳ¶ж®ө
з«ӢеҚіиҝ”еӣһж•°жҚ®пјҢз»ҷдёҖдёӘеҸ·гҖӮеҲ°ж—¶еҖҷеҸ«еҸ·пјҢзӣҙжҺҘиҝ”еӣһ
дҝЎеҸ·еҸҘжҹ„пјҢе‘ҠиҜүдҪ еҮ еҸ·еҘҪдәҶпјҢпјҲsignal handler process datagramпјү
жңүдәӣж—¶еҖҷжҳҜйңҖиҰҒдәүжҠўзҡ„
жҲ‘еҸҜд»ҘдёҚйҖҡзҹҘдҪ пјҢжҲ‘д№ҹеҸҜд»ҘйҖҡзҹҘдҪ еҗҺдҪ еҶҚжқҘ
зҗҶи§Јж•°жҚ®еұӮйқўзҡ„дёңиҘҝпјҢе°ұдёҚиҰҒзҗҶи§Је…¶д»–зҡ„socketеұӮйқўзҡ„дёңиҘҝ
ж–Ү件дёӯе®һйҷ…е°ұжҳҜдёӨдёӘзј“еҶІйҳҹеҲ—пјҢжҜҸдёӘйҳҹеҲ—жҳҜдёҖдёӘгҖӮ
еңЁејӮжӯҘжЁЎеһӢдёӯпјҢж“ҚдҪңзі»з»ҹйҖҡдҪ зҡ„пјҢдҪ жҳҜеңЁз”ЁжҲ·з©әй—ҙзҡ„пјҢж“ҚдҪңзі»з»ҹеҸҜд»ҘжҳҜеңЁеҶ…ж ёз©әй—ҙзҡ„пјҢиҝӣзЁӢе’ҢзәҝзЁӢзӯүзӯүзҡ„йғҪжҳҜж“ҚдҪңзі»з»ҹеұӮйқўзҡ„дёңиҘҝгҖӮ
ж•ҙдёӘиҝҮзЁӢдёӯиҝӣзЁӢйғҪеҸҜд»ҘеҒҡе…¶д»–зҡ„дәӢпјҢе°ұз®—жҳҜйҖҡзҹҘдәҶпјҢд№ҹдёҚдёҖе®ҡиҰҒз«ӢеҚіеҸҚеә”пјҢиҝҷе’ҢдҪ зҡ„и®ҫзҪ®жңүе…і
Linuxдёӯзҡ„AIO зҡ„зі»з»ҹи°ғз”ЁпјҢеҶ…ж ёзүҲжң¬д»Һ2.6ејҖе§Ӣж”ҜжҢҒ
дёҖиҲ¬зҡ„IOжҳҜIOеӨҡи·ҜеӨҚз”Ёе’ҢејӮжӯҘеӨҚз”Ё
IO еӨҡи·ҜеӨҚз”Ё
еӨ§еӨҡж•°ж“ҚдҪңзі»з»ҹйғҪж”ҜжҢҒselectе’Ңpoll
Linux 2.5+ ж”ҜжҢҒepoll
BSD,Macж”ҜжҢҒkqueue
Windows зҡ„ iocp
pythonзҡ„selectеә“е®һзҺ°дәҶselectпјҢpollзі»з»ҹи°ғз”ЁпјҢиҝҷдёӘеҹәжң¬дёҠж“ҚдҪңзі»з»ҹйғҪж”ҜжҢҒпјҢйғЁеҲҶе®һзҺ°дәҶepollпјҢеә•еұӮзҡ„IOеӨҡи·ҜеӨҚз”ЁжЁЎеқ—
ејҖеҸ‘дёӯзҡ„йҖүжӢ©
1 е®Ңе…Ёи·Ёе№іеҸ°пјҢselect е’Ңpoll пјҢдҪҶе…¶жҖ§иғҪиҫғе·®
2 й’ҲеҜ№дёҚеҗҢзҡ„ж“ҚдҪңзі»з»ҹиҮӘиЎҢйҖүжӢ©ж”ҜжҢҒжҠҖжңҜпјҢиҝҷж ·дјҡжҸҗй«ҳIOеӨ„зҗҶиғҪеҠӣselectorsеә“
3.4 зүҲжң¬еҗҺжҸҗдҫӣиҝҷдёӘеә“пјҢй«ҳзә§зҡ„IOеӨҚз”Ёеә“
зұ»еұӮж¬Ўз»“жһ„BaseSelector
+-- SelectSelector е®һзҺ°select
+-- PollSelector е®һзҺ°poll
+-- EpollSelector е®һзҺ°epoll
+-- DevpollSelector е®һзҺ°devpoll
+-- KqueueSelector е®һзҺ°kqueueselectors.DefaultSelectorиҝ”еӣһеҪ“еүҚе№іеҸ°жңҖжңүж•ҲпјҢжҖ§иғҪжңҖжңҖй«ҳзҡ„е®һзҺ°
дҪҶжҳҜз”ұдәҺжІЎжңүе®һзҺ°windowsзҡ„IOCPпјҢжүҖд»ҘеҸӘиғҪйҖҖеҢ–дёәselectгҖӮ
й»ҳи®ӨдјҡиҮӘйҖӮеә”пјҢе…¶дјҡйҖүжӢ©жңҖдҪізҡ„ж–№ејҸпјҢLinux дјҡзӣҙжҺҘйҖүжӢ© epoll пјҢйҖҡиҝҮжӯӨеӨ„пјҢиғҪжӢҝеҲ°е№іеҸ°зҡ„жңҖдјҳж–№жЎҲгҖӮ
DefaultSelector жәҗз Ғ
if 'KqueueSelector' in globals():
DefaultSelector = KqueueSelector
elif 'EpollSelector' in globals():
DefaultSelector = EpollSelector
elif 'DevpollSelector' in globals():
DefaultSelector = DevpollSelector
elif 'PollSelector' in globals():
DefaultSelector = PollSelector
else:
DefaultSelector = SelectSelectorabstractmethod register(fileobj,events,data=None)
дёәselectionжіЁеҶҢдёҖдёӘж–Ү件зӢ¬дә«пјҢзӣ‘и§Ҷе®ғзҡ„IOдәӢ件
fileobj иў«зӣ‘и§Ҷзҡ„ж–Ү件еҜ№иұЎпјҢеҰӮsocketеҜ№иұЎ
events дәӢ件пјҢиҜҘж–Ү件еҜ№иұЎеҝ…йЎ»зӯүеҫ…зҡ„дәӢ件пјҢreadжҲ–write

data еҸҜйҖүзҡ„дёҺжӯӨж–Ү件еҜ№иұЎзӣёе…ізҡ„дёҚйҖҸжҳҺж•°жҚ®пјҢеҰӮеҸҜз”ЁжқҘеӯҳеӮЁжҜҸдёӘе®ўжҲ·з«Ҝзҡ„дјҡиҜқIDпјҢеҸҜд»ҘжҳҜеҮҪж•°пјҢзұ»пјҢе®һдҫӢпјҢеҰӮжһңжҳҜеҮҪж•°пјҢжңүзӮ№еӣһи°ғзҡ„ж„ҸжҖқпјҢйҖҡзҹҘжҹҗдёӘеҮҪж•°пјҢжҹҗдёӘе®һдҫӢпјҢжҹҗдёӘзұ»пјҢеҸҜд»ҘжҳҜзұ»еұһжҖ§пјҢзӯүпјҢйғҪеҸҜд»ҘпјҢNoneиЎЁзӨәж¶ҲжҒҜеҸ‘з”ҹдәҶпјҢжІЎдәәи®ӨйўҶгҖӮ
第дёҖжӯҘ пјҡйңҖиҰҒе®һдҫӢеҢ– пјҢйҖүжӢ©дёҖдёӘжңҖдјҳзҡ„е®һзҺ°пјҢе°Ҷе…¶е®һдҫӢеҢ–пјҲйҖүжӢ©дёҚеҗҢе№іеҸ°е®һзҺ°зҡ„IOеӨҚз”Ёзҡ„жңҖдҪіжЎҶжһ¶пјүпјҢpythonеҶ…йғЁеӨ„зҗҶ
第дәҢжӯҘпјҡжіЁеҶҢеҮҪж•°пјҢе°ҶиҰҒзӣ‘жҺ§еҜ№иұЎпјҢиҰҒзӣ‘жҺ§дәӢ件е’Ңзӣ‘жҺ§и§ҰеҸ‘еҗҺеҜ№иұЎеҶҷе…ҘregisterжіЁеҶҢдёӯ
1 жіЁеҶҢпјҡ еҜ№иұЎпјҢе•ҘдәӢ件пјҢи°ғз”Ёзҡ„еҮҪж•°
2 иҝӣиЎҢеҫӘзҺҜе’Ңзӣ‘жҺ§selectеҮҪж•°зҡ„иҝ”еӣһпјҢеҪ“зӣ‘жҺ§зҡ„еҜ№иұЎзҡ„дәӢ件满足时дјҡз«ӢеҚіиҝ”еӣһпјҢеңЁeventsдёӯеҸҜд»ҘжӢҝеҲ°иҝҷдәӣж•°жҚ®eventsдёӯжңүжҲ‘жҳҜи°ҒпјҢжҲ‘жҳҜд»Җд№ҲдәӢ件и§ҰеҸ‘зҡ„(иҜ»е’ҢеҶҷ)пјҢиҜ»зҡ„ж»Ўи¶іеҸҜд»ҘrecvпјҢkey жҳҜи®©жҲ‘зӣ‘жҺ§зҡ„дёңиҘҝпјҢeventжҳҜе…¶д»Җд№ҲдәӢ件и§ҰеҸ‘зҡ„гҖӮе°ҶеҜ№иұЎе’ҢдәӢ件жӢҝеҲ°еҗҺеҒҡзӣёеә”зҡ„еӨ„зҗҶгҖӮ
第дёүжӯҘпјҡе®һж—¶е…іжіЁsocketжңүиҜ»еҶҷж“ҚдҪңпјҢд»ҺиҖҢеҪұе“Қeventsзҡ„еҸҳеҢ–
еҜ№socketжқҘеҲӨж–ӯжңүжІЎжңүиҜ»пјҢиӢҘиҜ»дәҶпјҢеҲҷзӣҙжҺҘи§ҰеҸ‘еҜ№еә”зҡ„жңәеҲ¶иҝӣиЎҢеӨ„зҗҶгҖӮдёҖж—Ұжңүж–°зҡ„иҝһжҺҘеҮҶеӨҮпјҢеҲҷдјҡе°Ҷе…¶ж¶ҲжҒҜеҸ‘йҖҒз»ҷеҜ№еә”зҡ„еҮҪж•°иҝӣиЎҢеӨ„зҗҶзӣёе…ізҡ„ж“ҚдҪңгҖӮиў«и°ғз”Ёзҡ„еҮҪж•°жҳҜжңүиҰҒжұӮзҡ„пјҢе…¶йңҖиҰҒдј йҖҒmaskзҡ„пјҢdata е°ұжҳҜжңӘжқҘиҰҒи°ғз”Ёзҡ„еҮҪж•°пјҢе»әз«ӢдәҶдәӢ件е’ҢжңӘжқҘеҸӮж•°д№Ӣй—ҙе»әз«Ӣзҡ„е…ізі»гҖӮ
Accept жң¬иә«е°ұжҳҜдёҖдёӘreadдәӢ件
Selector дјҡи°ғз”ЁиҮӘе·ұзҡ„selectеҮҪж•°иҝӣиЎҢзӣ‘и§ҶпјҢиҝҷдёӘеҮҪж•°жҳҜйҳ»еЎһзҡ„пјҢеҪ“ж•°жҚ®е·Із»ҸеңЁеҶ…ж ёзј“еҶІеҢәеҮҶеӨҮеҘҪдәҶпјҢдҪ е°ұеҸҜд»ҘиҜ»еҸ–дәҶпјҢиҝҷдәӣдәӢз»ҷselectиҝӣиЎҢеӨ„зҗҶеңЁжіЁеҶҢзҡ„ж—¶еҖҷпјҢеҗҺйқўеҠ дәҶdata,еҗҺйқўзӣҙжҺҘдҪҝз”ЁпјҢзӣҙжҺҘи°ғз”ЁпјҢдёҚз”Ёз®Ўе…¶д»–пјҢdataе’ҢжҜҸдёҖдёӘи§ӮеҜҹиҖ…зӣҙжҺҘеҜ№еә”иө·жқҘзҡ„гҖӮ
еҸӘиҰҒжңүдёҖдёӘж»Ўи¶іиҰҒжұӮпјҢзӣҙжҺҘиҝ”еӣһ
иҜ»дәӢ件жҢҮзҡ„жҳҜinж“ҚдҪңпјҢеҸҠе°ұжҳҜеҪ“жңүиҝһжҺҘзҡ„ж—¶еҖҷ
еҪ“йҖҡзҹҘжҲҗеҠҹеҗҺпјҢе…¶еҮҪж•°еҶ…йғЁжҳҜдёҚдјҡйҳ»еЎһдәҶпјҢзӯүеҫ…йҖҡзҹҘпјҢйҖҡзҹҘжҲҗеҠҹеҗҺе°ұдёҚдјҡйҳ»еЎһдәҶгҖӮжӯӨеӨ„зҡ„dataзӣёеҪ“дәҺзӣҙжҺҘеёҰзқҖзӘ—еҸЈеҸ·пјҢзӣҙжҺҘиҝӣиЎҢеӨ„зҗҶпјҢиҖҢдёҚйңҖиҰҒдёҖдёӘдёҖдёӘзҡ„йҒҚеҺҶ
еҪ“дёҖдёӘж»Ўи¶ідәҶпјҢе°ұдёҚдјҡйҳ»еЎһдәҶгҖӮeventsпјҡ дёӨдёӘIOйғҪж»Ўи¶іпјҢзӯүеҫ…еҮ и·ҜпјҢеҮ и·Ҝзҡ„IOйғҪеңЁжӯӨеӨ„пјҢеҰӮжһңж»Ўи¶іпјҢеҲҷзӣҙжҺҘеҗ‘дёӢжү“еҚ°events,е…¶дёӯkeyжҳҜжіЁеҶҢзҡ„е”ҜдёҖзҡ„дёңиҘҝпјҢsocket д№ҹеҸҜд»ҘпјҢдҪҶжҳҜеҸҜд»Ҙе®ҡд№үsocketзҡ„иҜ»е’ҢеҶҷпјҢдёҖиҲ¬йғҪжҳҜеҗҲзқҖзҡ„
第еӣӣжӯҘпјҡи°ғз”ЁеҜ№еә”дәӢ件зҡ„еҜ№иұЎпјҢ并жү§иЎҢзӣёе…іж“ҚдҪң
然еҗҺе°ҶeventsжӢҝеҮәжқҘи§Јжһ„пјҢkeyжң¬иә«жҳҜдёҖдёӘеӨҡе…ғзҘ–пјҢkeyдёҠдҝқеӯҳзқҖжіЁеҶҢеЎһиҝӣеҺ»зҡ„dataпјҢkeyжҳҜеӯҳеӮЁдәҶ4дёӘдҝЎжҒҜзҡ„е…ғзҘ–пјҢжӯӨеӨ„зҡ„dataз§°дёәеӣһи°ғеҮҪж•°пјҢеҠ дёҠ() з§°дёәи°ғз”Ё
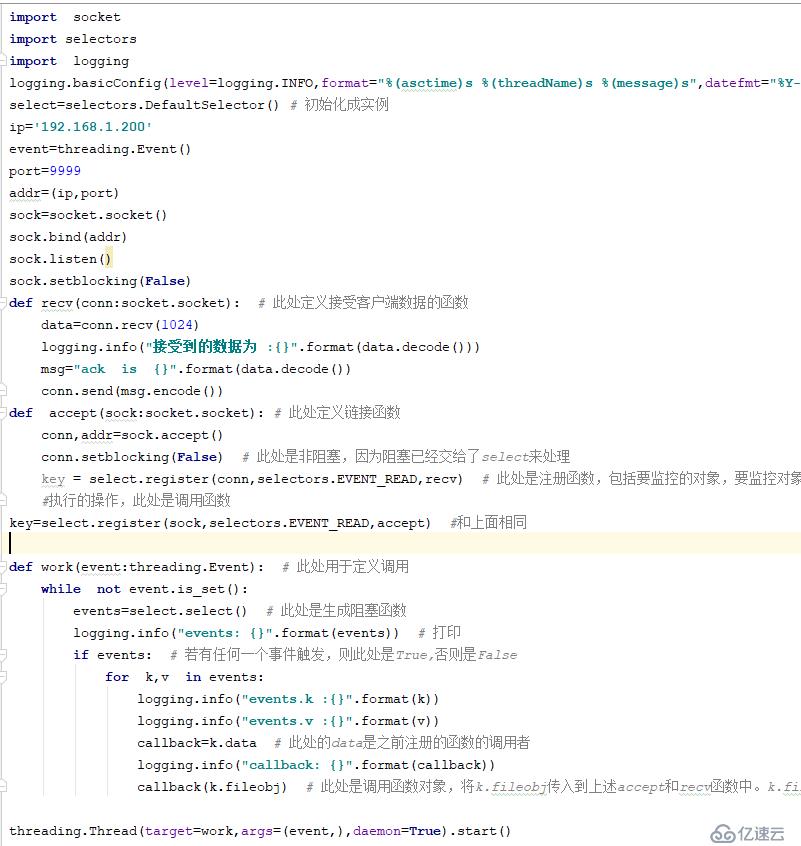

д»Јз ҒдёӢиҪҪзӣ®еҪ•
IO еӨҡи·ҜеӨҚз”ЁеҲқе§Ӣд»Јз Ғ
https://pan.baidu.com/s/18B5OL89Z4YSxEmX4gNkgDA
2019-09-01 09:37:46 Thread-1 events: [(SelectorKey(fileobj=<socket.socket fd=4, family=AddressFamily.AF_INET, type=2049, proto=0, laddr=('192.168.1.200', 9999)>, fd=4, events=1, data=<function accept at 0x7f50feb61d90>), 1)]
eventsдёӯеҢ…еҗ«дәҶдёӨз»„
第дёҖз»„ пјҡ
fileobj еҸҠеҘ—жҺҘеӯ—иҝ”еӣһзҡ„зӣёе…іеҸӮж•°пјҢе’Ңд№ӢеүҚзҡ„socketдёӯзҡ„accpetдёӯзҡ„conn зӣёдјјпјҢfd еҸҠж–Ү件жҸҸиҝ°з¬Ұ
events еҸҠдәӢ件зұ»еһӢпјҢ
дёӨз§Қ
data еҸҠжіЁеҶҢи°ғз”Ёзҡ„еҮҪж•°пјҢдёҠиҝ°зҡ„жңүaccept е’Ңrecv еҮҪж•°
第дәҢз»„пјҡ
1 events зҡ„зҠ¶жҖҒпјҢеҸҠmask
1 select.get_map().items() дёӯзҡ„key
2019-09-01 09:43:52 MainThread key:SelectorKey(fileobj=<socket.socket fd=4, family=AddressFamily.AF_INET, type=2049, proto=0, laddr=('192.168.1.200', 9999)>, fd=4, events=1, data=<function accept at 0x7fcf5a50ad90>)жӯӨеӨ„зҡ„keyе’ҢдёҠйқўзҡ„еҲ—иЎЁдёӯзҡ„дәҢе…ғзҘ–дёӯзҡ„еүҚдёҖдёӘе®Ңе…ЁзӣёеҗҢ
2 select.get_map().items() дёӯзҡ„fobj
2019-09-01 09:43:52 MainThread fobj: 4
е…¶жҳҜе…¶дёӯзҡ„ж–Ү件жҸҸиҝ°з¬Ұ
IO еӨҡи·ҜеӨҚз”Ёе°ұжҳҜдёҖдёӘзәҝзЁӢжқҘеӨ„зҗҶжүҖжңүзҡ„IO
еңЁеҚ•зәҝзЁӢдёӯиҝӣиЎҢеӨ„зҗҶIOеӨҡи·ҜеӨҚз”Ё
еӨҡзәҝзЁӢдёӯзҡ„IOйҳ»еЎһж—¶жөӘиҙ№CPUиө„жәҗпјҢе…¶жҳҜзӯүеҫ…зҠ¶жҖҒпјҢзӯүеҫ…зҠ¶жҖҒиҷҪ然дёҚеҚ з”ЁCPUиө„жәҗпјҢдҪҶзәҝзЁӢжң¬иә«зҡ„зҠ¶жҖҒйңҖиҰҒз»ҙжҢҒпјҢиҝҳжҳҜдјҡеҚ з”ЁдёҖе®ҡзҡ„иө„жәҗ
send жҳҜеҶҷж“ҚдҪңпјҢжңүеҸҜиғҪйҳ»еЎһпјҢд№ҹеҸҜд»Ҙзӣ‘еҗ¬
recvжүҖеңЁзҡ„жіЁеҶҢеҮҪж•°пјҢиҰҒзӣ‘еҗ¬иҜ»дёҺеҶҷдәӢ件пјҢеӣһи°ғзҡ„ж—¶еҖҷпјҢйңҖиҰҒmask жқҘеҲӨж–ӯ究з«ҹжҳҜиҜ»и§ҰеҸ‘дәҶиҝҳжҳҜеҶҷи§ҰеҸ‘дәҶпјҢжүҖд»ҘпјҢйңҖиҰҒдҝ®ж”№ж–№жі•еЈ°жҳҺпјҢеўһеҠ mask
еҶҷж“ҚдҪңеҪ“еҸ‘йҖҒзҫӨиҒҠж—¶пјҢе…¶жҜҸдёӘй“ҫжҺҘжҳҜзӢ¬з«Ӣзҡ„пјҢйңҖиҰҒqueueйҳҹеҲ—дҝқеӯҳзӣёе…ізҡ„ж•°жҚ®пјҢ并иҝӣиЎҢжҺҘеҸ—е’ҢеҸ‘йҖҒж“ҚдҪң
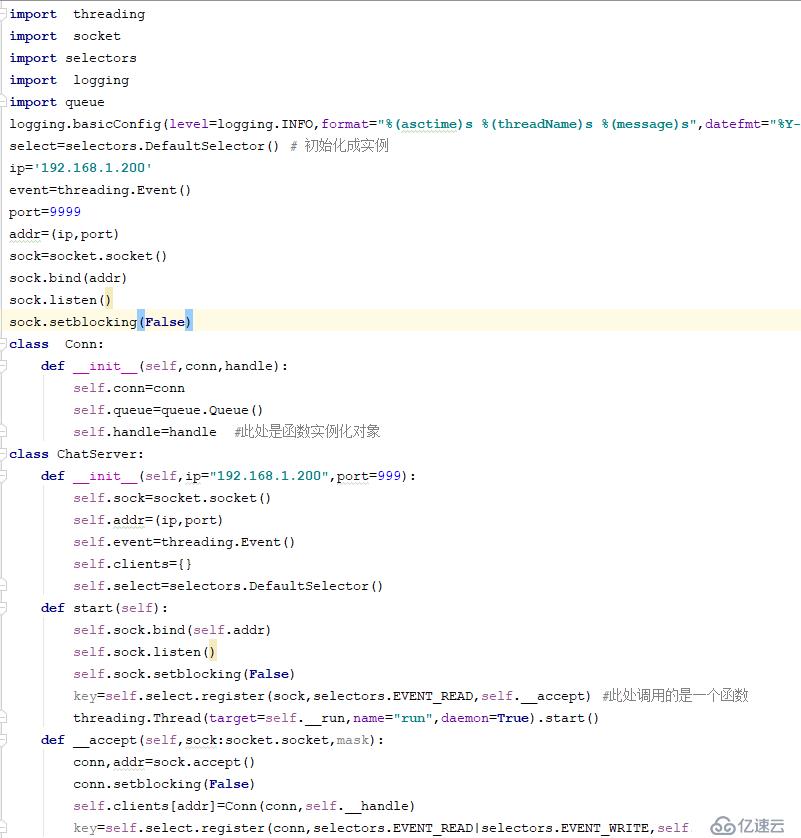


IO еӨҡи·ҜеӨҚз”ЁжңҖз»Ҳд»Јз Ғ
https://pan.baidu.com/s/1y-3j607_5DxBpa4wZNxCEQ
3.4 зүҲжң¬еҠ е…Ҙж ҮеҮҶеә“
asyncio еә•еұӮжҳҜеҹәдәҺselectorsе®һзҺ°зҡ„пјҢзңӢдјјеә“пјҢе…¶е®һе°ұжҳҜдёҖдёӘжЎҶжһ¶пјҢеҢ…жӢ¬ејӮжӯҘIOпјҢдәӢ件еҫӘзҺҜпјҢеҚҸзЁӢпјҢд»»еҠЎзӯү
并иЎҢе’ҢдёІиЎҢзҡ„еҢәеҲҶпјҡ
дёӨдёӘдәӢ件зҡ„еӣ жһңе…ізі»пјҡ
иӢҘжңүеӣ жһңе…ізі»пјҢеҲҷеҸҜд»ҘдҪҝз”ЁдёІиЎҢ
иӢҘж— еӣ жһңе…ізі»пјҢеҲҷеҸҜд»ҘдҪҝ用并иЎҢпјҢеҸҠеӨҡзәҝзЁӢжқҘеӨ„зҗҶ
| еҸӮж•° | еҗ«д№ү |
|---|---|
| asyncio.get_event_loop() | иҝ”еӣһдёҖдёӘдәӢ件еҫӘзҺҜеҜ№иұЎпјҢжҳҜasyncio.BaseEventLoopзҡ„е®һдҫӢ |
| AbstractEventLoop.stop() | еҒңжӯўиҝҗиЎҢдәӢ件еҫӘзҺҜ |
| AbstractEventLoop.run_forever() | дёҖзӣҙиҝҗиЎҢпјҢзӣҙеҲ°stop() |
| AbstractEventLoop.run_until_complete(future) | иҝҗиЎҢзӣҙеҲ°FutureеҜ№иұЎиҝҗиЎҢе®ҢжҲҗ |
| AbstractEventLoop.close() | е…ій—ӯдәӢ件еҫӘзҺҜ |
| AbstractEventLoop.is_running() | иҝ”еӣһдәӢ件еҫӘзҺҜжҳҜеҗҰиҝҗиЎҢ |
| AbstractEventLoop.close() | е…ій—ӯдәӢ件 |
#!/usr/bin/poython3.6
#conding:utf-8
import threading
def a():
for i in range(3):
print (i)
def b():
for i in "abc":
print (i)
a()
b()

жӯӨеӨ„зҡ„й»ҳи®Өжү§иЎҢйЎәеәҸжҳҜa()еҲ°b()зҡ„йЎәеәҸжү§иЎҢпјҢиӢҘиҰҒдҪҝе…¶дәӨеҸүжү§иЎҢпјҢеҲҷйңҖиҰҒдҪҝз”Ёyield жқҘе®һзҺ°
е®һзҺ°ж–№ејҸеҰӮдёӢ
#!/usr/bin/poython3.6
#conding:utf-8
import threading
import multiprocessing
def a():
for i in range(3):
print (i)
yield
def b():
for i in "abc":
print (i)
yield
a=a()
b=b()
for i in range(3):
next(a)
next(b)
дёҠиҝ°е®һдҫӢдёӯйҖҡиҝҮз”ҹжҲҗеҷЁе®ҢжҲҗдәҶи°ғеәҰпјҢи®©дёӨдёӘеҮҪж•°йғҪеҮ д№ҺеҗҢж—¶жү§иЎҢпјҢиҝҷж ·зҡ„и°ғеәҰдёҚжҳҜж“ҚдҪңзі»з»ҹиҝӣиЎҢзҡ„гҖӮиҖҢжҳҜз”ЁжҲ·иҮӘе·ұи®ҫи®Ўе®ҢжҲҗзҡ„
иҝҷдёӘзЁӢеәҸзј–еҶҷиҰҒзҙ пјҡ
1 йңҖиҰҒдҪҝз”ЁyieldжқҘи®©еҮәжҺ§еҲ¶жқғ
2 йңҖиҰҒеҫӘзҺҜеё®еҠ©жү§иЎҢ
еҚҸзЁӢдёҚжҳҜиҝӣзЁӢпјҢд№ҹдёҚжҳҜзәҝзЁӢпјҢе®ғжҳҜз”ЁжҲ·з©әй—ҙи°ғеәҰзҡ„е®ҢжҲҗ并еҸ‘еӨ„зҗҶзҡ„ж–№ејҸгҖӮ
иҝӣзЁӢпјҢзәҝзЁӢз”ұж“ҚдҪңзі»з»ҹе®ҢжҲҗи°ғеәҰпјҢиҖҢеҚҸзЁӢжҳҜзәҝзЁӢеҶ…е®ҢжҲҗи°ғеәҰзҡ„пјҢдёҚйңҖиҰҒжӣҙеӨҡзҡ„зәҝзЁӢпјҢиҮӘ然д№ҹжІЎжңүеӨҡзәҝзЁӢеҲҮжҚўзҡ„ејҖй”Җ
еҚҸзЁӢжҳҜйқһжҠўеҚ ејҸи°ғеәҰпјҢеҸӘжңүдёҖдёӘеҚҸзЁӢдё»еҠЁи®©еҮәжҺ§еҲ¶жқғпјҢеҸҰдёҖдёӘеҚҸзЁӢжүҚдјҡиў«и°ғеәҰгҖӮ
еҚҸзЁӢд№ҹдёҚйңҖиҰҒдҪҝз”Ёй”ҒжңәеҲ¶пјҢеӣ дёәе…¶жҳҜеңЁеҗҢдёҖдёӘзәҝзЁӢдёӯжү§иЎҢзҡ„
еӨҡCPUдёӢпјҢеҸҜд»ҘдҪҝз”ЁеӨҡиҝӣзЁӢе’ҢеҚҸзЁӢй…ҚеҗҲпјҢж—ўиғҪиҝӣзЁӢ并еҸ‘пјҢд№ҹиғҪеҸ‘жҢҘеҮәеҚҸзЁӢеңЁеҚ•зәҝзЁӢдёӯзҡ„дјҳеҠҝгҖӮ
pythonдёӯзҡ„еҚҸзЁӢжҳҜеҹәдәҺз”ҹжҲҗеҷЁзҡ„гҖӮ
3.4 еј•е…Ҙзҡ„asyncioпјҢдҪҝз”ЁиЈ…йҘ°еҷЁ
#!/usr/bin/poython3.6
#conding:utf-8
import threading
import multiprocessing
import asyncio
@asyncio.coroutine
def a():
for i in range(3):
print (i)
yield
loop=asyncio.get_event_loop()
loop.run_until_complete(a())
loop.close()з»“жһңеҰӮдёӢ

#!/usr/bin/poython3.6
#conding:utf-8
import threading
import multiprocessing
import asyncio
@asyncio.coroutine
def a():
for i in range(3):
print (i)
yield
@asyncio.coroutine
def b():
for i in "abc":
print(i)
yield
loop=asyncio.get_event_loop()
task=[a(),b()]
loop.run_until_complete(asyncio.wait(task))
loop.close()з»“жһңеҰӮдёӢ

3.5 еҸҠе…¶д»ҘеҗҺзүҲжң¬зҡ„д№ҰеҶҷж–№ејҸ:
#!/usr/bin/poython3.6
#conding:utf-8
import threading
import multiprocessing
import asyncio
async def a():
for i in range(3):
print (i)
# await asyncio.sleep(0.0001)
async def b(): #дҪҝз”ЁжӯӨж–№ејҸеҗҺпјҢдёҚиғҪеҶҚж¬ЎдҪҝз”ЁwaitдәҶ
for i in "abc":
print(i)
# await asyncio.sleep(0.0001)
print (asyncio.iscoroutinefunction(a)) # жӯӨеӨ„еҲӨж–ӯжҳҜеҗҰжҳҜеҮҪж•°пјҢе’Ңи°ғз”Ёж— е…і
a=a()
print (asyncio.iscoroutine(a)) # жӯӨеӨ„жҳҜеҲӨж–ӯеҜ№иұЎпјҢжҳҜи°ғз”ЁеҗҺзҡ„з»“жһң
loop=asyncio.get_event_loop()
task=[a,b()]
loop.run_until_complete(asyncio.wait(task))
loop.close()
з»“жһңеҰӮдёӢ
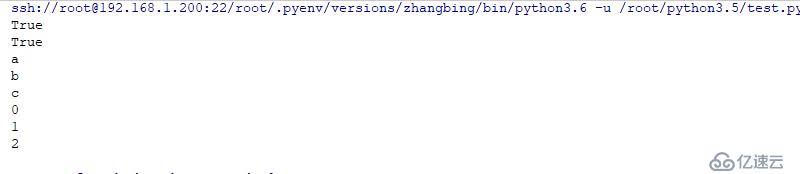
async def з”ЁжқҘе®ҡд№үеҚҸзЁӢеҮҪж•°пјҢiscoroutinefunction()иҝ”еӣһTrueпјҢеҚҸзЁӢеҮҪж•°дёӯеҸҜд»ҘдёҚеҢ…еҗ«await,asyncе…ій”®еӯ—пјҢдҪҶжҳҜдёҚиғҪдҪҝз”Ёyieldе…ій”®еӯ—
еҰӮжһңз”ҹжҲҗеҷЁеҮҪж•°и°ғз”Ёиҝ”еӣһз”ҹжҲҗеҷЁеҜ№иұЎдёҖж ·пјҢеҚҸзЁӢеҮҪж•°и°ғз”Ёд№ҹдјҡиҝ”еӣһдёҖдёӘеҜ№иұЎжҲҗдёәеҚҸзЁӢеҜ№иұЎпјҢiscoroutine()иҝ”еӣһдёәTrue
#!/usr/bin/poython3.6
#conding:utf-8
import threading
import multiprocessing
import asyncio
import socket
ip='192.168.1.200'
port=9999
async def handler(conn,send):
while True:
data=await conn.read(1024) # жҺҘеҸ—е®ўжҲ·з«Ҝзҡ„ж•°жҚ®пјҢзӣёеҪ“дәҺrecvпјҢwait е°ұжҳҜIOзӯүеҫ…пјҢжӯӨеӨ„дјҡзӯүеҫ…
print (conn,send)
client_addr=send.get_extra_info('peername') # иҺ·еҸ–е®ўжҲ·з«ҜдҝЎжҒҜ
msg="{} {}".format(data.decode(),client_addr).encode() #е°ҒиЈ…ж¶ҲжҒҜ
send.write(msg) # дј иҫ“еҲ°е®ўжҲ·з«Ҝ
await send.drain() # жӯӨеӨ„зӣёеҪ“дәҺmakefileдёӯзҡ„flush пјҢжӯӨеӨ„д№ҹдјҡIOзӯүеҫ…
loop=asyncio.get_event_loop() #е®һдҫӢеҢ–дёҖдёӘеҫӘзҺҜдәӢ件
crt=asyncio.start_server(handler,ip,port,loop=loop) #дҪҝз”ЁејӮжӯҘж–№ејҸеҗҜеҠЁеҮҪж•°пјҢжңҖеҗҺдёҖдёӘеҸӮж•°жҳҜеә”иҜҘз”Ёи°ҒжқҘеҫӘзҺҜеӨ„зҗҶ
server=loop.run_until_complete(crt) # жӯӨеӨ„жҳҜзӣҙеҲ°жӯӨж–№жі•е®ҢжҲҗеҗҺз»Ҳжӯў
print (server)
try:
loop.run_forever()
except KeyboardInterrupt:
pass
finally:
server.close()
loop.close()ејӮжӯҘзҡ„http еә“пјҢдҪҝз”ЁеҚҸзЁӢе®һзҺ°зҡ„
йңҖиҰҒе®ү装第дёүж–№жЁЎеқ— aiohttp
pip install aiohttp http server еҹәзЎҖе®һзҺ°
#!/usr/bin/poython3.6
#conding:utf-8
from aiohttp import web
async def indexhandle(request:web.Request): # еӨ„зҗҶе®ўжҲ·з«ҜиҜ·жұӮеҮҪж•°
print("web",web.Request)
return web.Request(text=request.path,status=201) #иҝ”еӣһж–Үжң¬е’ҢзҠ¶жҖҒз Ғ
async def handle(request:web.Request):
print (request.match_info)
print (request.query_string)
return web.Response(text=request.match_info.get('id','0000'),status=200) # жӯӨеӨ„жҳҜиҝ”еӣһз»ҷе®ўжҲ·з«Ҝзҡ„ж•°жҚ®пјҢеҗҺйқўзҡ„0000жҳҜй»ҳи®Ө
app=web.Application()
#и·Ҝз”ұйҖүи·ҜпјҢ
app.router.add_get('/',indexhandle) # http://192.168.1.200:80/
app.router.add_get('/{id}',handle) # http://192.168.1.200:80/12345
web.run_app(app,host='0.0.0.0',port=80) #зӣ‘еҗ¬IPе’Ңз«ҜеҸЈе№¶иҝҗиЎҢе®ўжҲ·з«Ҝе®һзҺ°
#!/usr/bin/poython3.6
#conding:utf-8
import asyncio
from aiohttp import ClientSession
async def get_html(url:str):
async with ClientSession() as session: # иҺ·еҸ–sessionпјҢиҰҒе’ҢжңҚеҠЎз«ҜйҖҡдҝЎпјҢеҝ…йЎ»е…ҲиҺ·еҸ–sessionпјҢд№ӢеҗҺжүҚиғҪиҝӣиЎҢзӣёе…ізҡ„ж“ҚдҪң пјҢжӯӨеӨ„дҪҝз”ЁwithжҳҜжү“ејҖе…ій—ӯдјҡиҜқпјҢдҝқиҜҒдјҡиҜқиғҪеӨҹиў«е…ій—ӯгҖӮ
async with session.get(url) as res: # йңҖиҰҒиҝҷдёӘURLиө„жәҗпјҢиҺ·еҸ–пјҢ
print (res.status) # жӯӨеӨ„иҝ”еӣһдёәзҠ¶жҖҒз Ғ
print (await res.text()) # жӯӨеӨ„иҝ”еӣһдёәж–Үжң¬дҝЎжҒҜ
url='http://www.baidu.com'
loop=asyncio.get_event_loop()
loop.run_until_complete(get_html(url))
loop.close()е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ