жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
еҗҢж—¶еҒҡжҹҗдәӣдәӢпјҢеҸҜд»Ҙдә’дёҚе№Іжү°зҡ„еҗҢдёҖж—¶еҲ»еҒҡеҮ 件дәӢ
еҰӮй«ҳйҖҹе…¬и·ҜдёҠзҡ„иҪҰйҒ“пјҢеҗҢдёҖж—¶еҲ»пјҢеҸҜд»ҘжңүеӨҡдёӘдә’дёҚе№Іжү°зҡ„иҪҰиҝҗиЎҢ
еңЁеҗҢдёҖж—¶еҲ»пјҢжҜҸжқЎиҪҰйҒ“дёҠеҸҜиғҪеҗҢж—¶жңүиҪҰиҫҶеңЁи·‘пјҢжҳҜеҗҢж—¶еҸ‘з”ҹзҡ„жҰӮеҝө
д№ҹжҳҜеҗҢж—¶еҒҡжҹҗдәӢпјҢдҪҶејәи°ғзҡ„жҳҜеҗҢдёҖж—¶ж®өеҒҡдәҶеҮ 件дәӢгҖӮ
并иЎҢжҳҜеҸҜд»Ҙи§ЈеҶіе№¶еҸ‘й—®йўҳзҡ„гҖӮ
йҳҹеҲ—пјҡжҺ’йҳҹе°ұжҳҜйҳҹеҲ—пјҢе…Ҳиҝӣе…ҲеҮәпјҢи§ЈеҶідәҶиө„жәҗдҪҝз”Ёзҡ„й—®йўҳгҖӮ
зј“еҶІеҢәпјҡжҺ’зЁӢзҡ„йҳҹеҲ—пјҢе…¶е®һе°ұжҳҜдёҖдёӘзј“еҶІең°еёҰпјҢе°ұжҳҜзј“еҶІеҢә
дјҳе…ҲйҳҹеҲ—пјҡеҜ№жҜ”иҫғйҮҚиҰҒзҡ„дәӢиҝӣиЎҢеҸҠж—¶зҡ„еӨ„зҗҶпјҢжӯӨеӨ„е°ұжҳҜдјҳе…ҲйҳҹеҲ—
еҸӘејҖдёҖдёӘзӘ—еҸЈпјҢжңүеҸҜиғҪ没秩еәҸпјҢд№ҹе°ұжҳҜи°ҒжҢӨиҝӣеҺ»е°ұз»ҷи°Ғжү“йҘӯ
жҢӨеҲ°зӘ—еҸЈзҡ„дәәеҚ жҚ®зӘ—еҸЈпјҢзӣҙеҲ°иҫҫеҲ°йҘӯиҸңзҰ»ејҖпјҢе…¶д»–дәә继з»ӯдәүжҠўпјҢдјҡжңүдёҖдёӘдәәеҚ жҚ®зӘ—еҸЈпјҢеҸҜд»Ҙи§Ҷдёәй”Ғе®ҡзӘ—еҸЈпјҢзӘ—еҸЈе°ұдёҚиғҪдёәе…¶д»–дәәжҸҗдҫӣжңҚеҠЎдәҶпјҢиҝҷжҳҜдёҖз§Қй”ҒжңәеҲ¶пјҢжҠўеҲ°иө„жәҗе°ұдёҠй”ҒпјҢжҺ’д»–жҖ§й”ҒпјҢе…¶д»–дәәеҸӘиғҪзӯүеҖҷдәүжҠўд№ҹжҳҜдёҖз§Қй«ҳ并еҸ‘и§ЈеҶіж–№жЎҲпјҢдҪҶжҳҜпјҢдёҚеҘҪпјҢеӣ дёәжңүдәәеҸҜиғҪй•ҝж—¶й—ҙжҠўдёҚеҲ°гҖӮ
дёҖз§ҚжҸҗеүҚеҠ иҪҪз”ЁжҲ·йңҖиҰҒзҡ„ж•°жҚ®зҡ„жҖқи·ҜпјҢеҰӮйў„зғӯпјҢйў„еҠ иҪҪзӯүпјҢзј“еӯҳдёӯеёёз”Ё
зј“еӯҳзҡ„жҖқжғіе°ұжҳҜе°Ҷж•°жҚ®зӣҙжҺҘжӢҝеҲ°пјҢиҝӣиЎҢеӨ„зҗҶгҖӮ
еҸҜйҖҡиҝҮиҙӯд№°жӣҙеӨҡзҡ„жңҚеҠЎеҷЁпјҢжҲ–ејҖеӨҡзәҝзЁӢпјҢиҝӣиЎҢе®һзҺ°е№¶иЎҢеӨ„зҗҶпјҢжқҘи§ЈеҶіе№¶еҸ‘й—®йўҳпјҢиҝҷдәӣйғҪжҳҜж°ҙе№іжү©еұ•пјҢ
жҸҗй«ҳеҚ•дёӘCPUжҖ§иғҪпјҢжҲ–иҖ…еҚ•дёӘжңҚеҠЎеҷЁе®үиЈ…жӣҙеӨҡзҡ„CPUпјҢдҪҶжӯӨе’ҢеӨҡдёӘжңҚеҠЎеҷЁзӣёжҜ”жҲҗжң¬иҫғй«ҳ
йҖҡиҝҮдёӯй—ҙзҡ„зј“еҶІеҷЁжқҘи§ЈеҶіе№¶еҸ‘й—®йўҳпјҢеҰӮrabbitmqпјҢactivemq,rocketmqпјҢkafka зӯүпјҢCDNд№ҹз®—жҳҜдёҖз§Қ
еңЁе®һзҺ°дәҶзәҝзЁӢзҡ„ж“ҚдҪңзі»з»ҹдёӯпјҢзәҝзЁӢжҳҜж“ҚдҪңзі»з»ҹиғҪеӨҹиҝҗз®—и°ғеәҰзҡ„жңҖе°ҸеҚ•дҪҚпјҢд»–иў«еҢ…еҗ«еңЁиҝӣзЁӢдёӯпјҢжҳҜиҝӣзЁӢдёӯзҡ„е®һйҷ…иҝҗдҪңеҚ•дҪҚпјҢдёҖдёӘзЁӢеәҸзҡ„жү§иЎҢе®һдҫӢе°ұжҳҜдёҖдёӘиҝӣзЁӢ
иҝӣзЁӢ(process)жҳҜи®Ўз®—жңәдёӯзҡ„зЁӢеәҸе…ідәҺжҹҗж•°жҚ®йӣҶеҗҲдёҠзҡ„дёҖж¬ЎиҝҗиЎҢжҙ»еҠЁпјҢжҳҜзі»з»ҹиҝӣиЎҢиө„жәҗеҲҶй…Қе’Ңи°ғеәҰзҡ„еҹәжң¬еҚ•дҪҚпјҢжҳҜж“ҚдҪңзі»з»ҹз»“жһ„зҡ„еҹәзЎҖ
зЁӢеәҸжҳҜжәҗд»Јз Ғзј–иҜ‘еҗҺзҡ„ж–Ү件пјҢиҖҢиҝҷдәӣж–Ү件еӯҳж”ҫеңЁзЈҒзӣҳдёҠпјҢеҪ“зЁӢеәҸиў«ж“ҚдҪңзі»з»ҹеҠ иҪҪеҲ°еҶ…еӯҳдёӯпјҢе°ұжҳҜиҝӣзЁӢпјҢиҝӣзЁӢдёӯеӯҳж”ҫзқҖжҢҮд»Өе’Ңж•°жҚ®(иө„жәҗ)пјҢе®ғд№ҹжҳҜзәҝзЁӢзҡ„е®№еҷЁгҖӮ
LinuxиҝӣзЁӢжңүзҲ¶иҝӣзЁӢпјҢеӯҗиҝӣзЁӢпјҢwindowsдёӯиҝӣзЁӢд№Ӣй—ҙжҳҜе№ізӯүе…ізі»
зәҝзЁӢжңүж—¶еҖҷиў«з§°дёәиҪ»йҮҸзә§иҝӣзЁӢ(LWP)пјҢжҳҜзЁӢеәҸжү§иЎҢзҡ„жңҖе°ҸеҚ•е…ғпјҢдёҖдёӘж ҮеҮҶзҡ„зәҝзЁӢз”ұзәҝзЁӢIDпјҢеҪ“еүҚжҢҮд»ӨжҢҮй’Ҳ(PC)пјҢеҜ„еӯҳеҷЁйӣҶеҗҲе’Ңе Ҷж Ҳз»„жҲҗ
зҺ°д»Јж“ҚдҪңзі»з»ҹжҸҗеҮәиҝӣзЁӢзҡ„жҰӮеҝөпјҢжҜҸдёҖдёӘиҝӣзЁӢйғҪи®ӨдёәиҮӘе·ұзӢ¬еҚ жүҖжңүи®Ўз®—жңә硬件иө„жәҗпјҢиҝӣзЁӢе°ұжҳҜзӢ¬з«ӢзҺӢеӣҪпјҢиҝӣзЁӢй—ҙдёҚиғҪйҡҸдҫҝе…ұдә«ж•°жҚ®
зәҝзЁӢе°ұжҳҜзңҒд»ҪпјҢеҗҢдёҖдёӘиҝӣзЁӢеҶ…зҡ„зәҝзЁӢеҸҜд»Ҙе…ұдә«иҝӣзЁӢзҡ„иө„жәҗпјҢжҜҸдёҖдёӘзәҝзЁӢжӢҘжңүиҮӘе·ұзӢ¬з«Ӣзҡ„е Ҷж ҲгҖӮ
иҝӣзЁӢдјҡеҗҜеҠЁдёҖдёӘи§ЈйҮҠеҷЁиҝӣзЁӢпјҢзәҝзЁӢе…ұдә«дёҖдёӘи§ЈйҮҠеҷЁиҝӣзЁӢ
дёӨдёӘи§ЈйҮҠеҷЁиҝӣзЁӢд№Ӣй—ҙжҳҜжІЎжңүд»»дҪ•е…ізі»зҡ„пјҢдёҚеҗҢиҝӣзЁӢд№Ӣй—ҙжҳҜдёҚиғҪйҡҸдҫҝдәӨдә’ж•°жҚ®зҡ„
еӨ§еӨҡж•°ж•°жҚ®йғҪжҳҜи·‘еңЁдё»зәҝзЁӢдёҠзҡ„
1 иҝҗиЎҢжҖҒпјҡ иҜҘж—¶еҲ»пјҢиҜҘзәҝзЁӢжӯЈеңЁеҚ з”ЁCPUиө„жәҗ
2 е°ұз»ӘжҖҒпјҡеҸҜйҡҸж—¶иҪ¬жҚўжҲҗиҝҗиЎҢжҖҒпјҢеӣ дёәе…¶д»–зәҝзЁӢжӯЈеңЁиҝҗиЎҢиҖҢжҡӮеҒңпјҢиҜҘзәҝзЁӢдёҚеҚ CPU
3 йҳ»еЎһжҖҒпјҡ йҷӨйқһеӨ–йғЁжҹҗдәӣдәӢжғ…еҸ‘з”ҹпјҢеҗҰеҲҷзәҝзЁӢдёҚиғҪиҝҗиЎҢ
4 з»Ҳжӯўпјҡ зәҝзЁӢе®ҢжҲҗпјҢжҲ–йҖҖеҮәпјҢжҲ–иў«еҸ–ж¶Ҳ
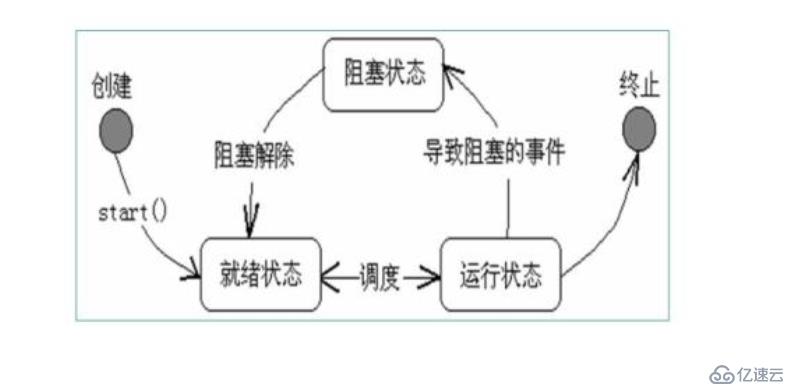
е…ҲеҲӣе»әиҝӣзЁӢпјҢ然еҗҺеҶҚеҲӣе»әдёҖдёӘзәҝзЁӢ
зӯүеҫ…иө„жәҗзҡ„иҝҗиЎҢ
йҳ»еЎһдёҚиғҪзӣҙжҺҘиҝӣе…ҘиҝҗиЎҢзҠ¶жҖҒпјҢеҝ…йЎ»е…Ҳиҝӣе…Ҙе°ұз»ӘзҠ¶жҖҒ
иҝҗиЎҢдёӯзҡ„зәҝзЁӢжҳҜеҸҜд»Ҙиў«еҸ–ж¶Ҳзҡ„
зӯҫеҗҚ
def __init__(self, group=None, target=None, name=None,
args=(), kwargs=None, *, daemon=None):еҸӮж•°еҗҚеҸҠеҗ«д№үпјҡ
target:зәҝзЁӢи°ғз”Ёзҡ„еҜ№иұЎпјҢе°ұжҳҜзӣ®ж ҮеҮҪж•°
name:дёәзәҝзЁӢиө·еҗҚеӯ—(дёҚеҗҢзәҝзЁӢзҡ„еҗҚеӯ—еҸҜд»ҘйҮҚеӨҚпјҢдё»иҰҒжҳҜйҖҡиҝҮзәҝзЁӢTIDиҝӣиЎҢеҢәеҲҶзҡ„)
argsпјҡдёәзӣ®ж ҮеҮҪж•°дј йҖ’еҸӮж•°пјҢе…ғзҘ–
kwargs: дёәзӣ®ж ҮеҮҪж•°е…ій”®еӯ—дј еҸӮпјҢеӯ—е…ё
е®һдҫӢеҰӮдёӢ
#!/usr/bin/poython3.6
#conding:utf-8
import threading
def test():
for i in range(5):
print (i)
print ('Thread over')
# е®һдҫӢеҢ–дёҖдёӘзәҝзЁӢ
t=threading.Thread(target=test)
t.start() # еҗҜеҠЁдёҖдёӘзәҝзЁӢ
йҡҸзқҖеҮҪж•°зҡ„жү§иЎҢе®ҢжҲҗпјҢзәҝзЁӢд№ҹе°ұз»“жқҹдәҶпјҢеӯҗзәҝзЁӢдёҚз»“жқҹпјҢеҲҷдё»зәҝзЁӢдёҖзӣҙеӯҳеңЁпјҢжӯӨж—¶зҡ„дё»зәҝзЁӢжҳҜзӯүеҫ…зҠ¶жҖҒ
йҖҡиҝҮthreading.ThreadеҲӣе»әдёҖдёӘзәҝзЁӢеҜ№иұЎпјҢtargetжҳҜзӣ®ж ҮеҮҪж•°пјҢnameеҸҜд»ҘжҢҮе®ҡеҗҚз§°пјҢдҪҶжҳҜзәҝзЁӢжІЎжңүеҗҜеҠЁпјҢйңҖиҰҒи°ғз”Ёstartж–№жі•гҖӮ
зәҝзЁӢд№ӢжүҖд»ҘиғҪжү§иЎҢеҮҪж•°пјҢжҳҜеӣ дёәзәҝзЁӢдёӯе°ұжҳҜжү§иЎҢд»Јз ҒпјҢиҖҢжңҖз®ҖеҚ•зҡ„е°ҒиЈ…е°ұжҳҜе“ҲеҮҪж•°пјҢжүҖд»ҘиҝҳжҳҜеҮҪж•°и°ғз”ЁгҖӮ
еҮҪж•°жү§иЎҢе®ҢжҲҗпјҢзәҝзЁӢе°ұйҖҖеҮәдәҶпјҢеҰӮжһңдёҚи®©зәҝзЁӢйҖҖеҮәпјҢеҲҷйңҖиҰҒдҪҝз”Ёжӯ»еҫӘзҺҜ
#!/usr/bin/poython3.6
#conding:utf-8
import threading
def test():
for i in range(5):
print (i)
print ('Thread over')
# е®һдҫӢеҢ–дёҖдёӘзәҝзЁӢ
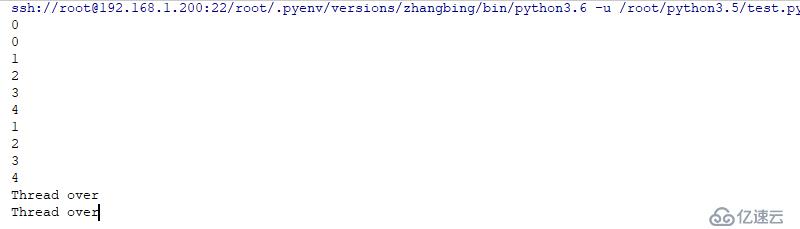
t=threading.Thread(target=test,name='test1')
t.start() # еҗҜеҠЁдёҖдёӘзәҝзЁӢ
t=threading.Thread(target=test,name='test2')
t.start() # еҗҜеҠЁдёҖдёӘзәҝзЁӢ
# дёҠиҝ°дёӨдёӘзәҝзЁӢжҳҜ并иЎҢеӨ„зҗҶпјҢеҰӮжһңжҳҜдёҖдёӘCPUпјҢеҲҷжҳҜеҒҮзҡ„е№іиЎЎз»“жһңеҰӮдёӢ
pythonдёӯжІЎжңүжҸҗдҫӣзәҝзЁӢйҖҖеҮәзҡ„ж–№ејҸпјҢзәҝзЁӢеңЁдёӢйқўжғ…еҶөж—¶йҖҖеҮәгҖҒ
1 зәҝзЁӢеҮҪж•°еҶ…иҜӯеҸҘжү§иЎҢе®ҢжҜ•
2 зәҝзЁӢеҮҪж•°дёӯжҠӣеҮәжңӘеӨ„зҗҶзҡ„ејӮеёё
#!/usr/bin/poython3.6
#conding:utf-8
import threading
def test():
count=0
while True:
count+=1
if count==3:
raise Exception('NUMBER')
print (count)
# е®һдҫӢеҢ–дёҖдёӘзәҝзЁӢ
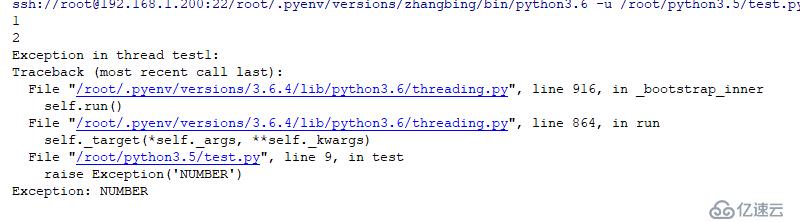
t=threading.Thread(target=test,name='test1')
t.start() # еҗҜеҠЁдёҖдёӘзәҝзЁӢејӮеёёеҜјиҮҙзҡ„зәҝзЁӢйҖҖеҮә
#!/usr/bin/poython3.6
#conding:utf-8
import threading
import time
def test():
count=0
while True:
count+=1
if count==3:
raise Exception('NUMBER')
print (count)
def test1():
for i in range(5):
time.sleep(0.1)
print ('test1',i)
# е®һдҫӢеҢ–дёҖдёӘзәҝзЁӢ
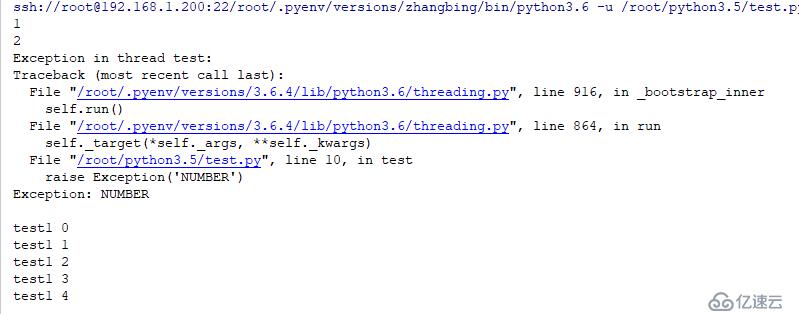
t=threading.Thread(target=test,name='test')
t.start() # еҗҜеҠЁдёҖдёӘзәҝзЁӢ
t=threading.Thread(target=test1,name='test1') #жӯӨеӨ„еҗҜз”ЁдёҖдёӘзәҝзЁӢпјҢзңӢдёҠиҝ°зәҝзЁӢиғҪеҗҰеҪұе“ҚиҜҘзәҝзЁӢзҡ„иҝҗиЎҢжғ…еҶө
t.start()з»“жһңеҰӮдёӢ
pythonдёӯзәҝзЁӢжІЎжңүдјҳе…Ҳзә§пјҢжІЎжңүзәҝзЁӢз»„зҡ„жҰӮеҝөпјҢд№ҹдёҚиғҪиў«й”ҖжҜҒпјҢеҒңжӯўпјҢжҢӮиө·пјҢд№ҹе°ұжІЎжңүжҒўеӨҚпјҢдёӯж–ӯдәҶпјҢдёҠиҝ°зҡ„дёҖдёӘзәҝзЁӢзҡ„ејӮеёёдёҚиғҪеҪұе“ҚеҸҰдёҖдёӘзәҝзЁӢзҡ„иҝҗиЎҢпјҢеҸҰдёҖдёӘзәҝзЁӢзҡ„иҝҗиЎҢжҳҜеӣ дёәе…¶еҮҪж•°иҝҗиЎҢе®ҢжҲҗдәҶ
#!/usr/bin/poython3.6
#conding:utf-8
import threading
import time
def test(count):
while True:
count+=1
if count==5:
raise Exception('NUMBER')
print (count)
# е®һдҫӢеҢ–дёҖдёӘзәҝзЁӢ
t=threading.Thread(target=test,name='test',args=(0,)) #жӯӨеӨ„еҝ…йЎ»жҳҜе…ғзҘ–зұ»еһӢпјҢеҗҰеҲҷдјҡжҠҘй”ҷ
t.start() # еҗҜеҠЁдёҖдёӘзәҝзЁӢ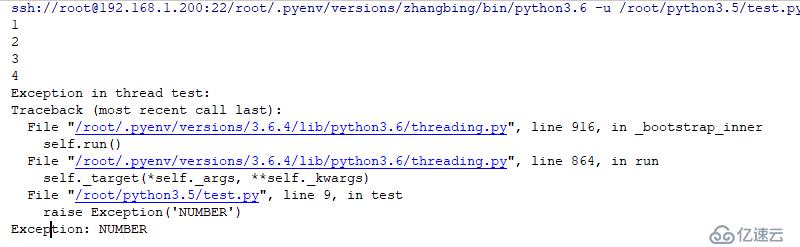
current_thread() иҝ”еӣһеҪ“еүҚзәҝзЁӢеҜ№иұЎ
main_thread() иҝ”еӣһдё»зәҝзЁӢеҜ№иұЎ
active_count() еҪ“еүҚеӨ„дәҺaliveзҠ¶жҖҒзҡ„зәҝзЁӢдёӘж•°
enumerate() иҝ”еӣһжүҖжңүжҙ»зқҖзҡ„зәҝзЁӢзҡ„еҲ—иЎЁпјҢдёҚеҢ…жӢ¬е·Із»Ҹз»Ҳжӯўзҡ„зәҝзЁӢе’ҢжңӘејҖе§Ӣзҡ„зәҝзЁӢ
get_ident() иҝ”еӣһеҪ“еүҚзәҝзЁӢзҡ„IDпјҢйқһ0ж•ҙж•°
#!/usr/bin/poython3.6
#conding:utf-8
import threading
import time
def test(count):
while True:
print ("еҪ“еүҚзәҝзЁӢеҜ№иұЎдёә{}еҪ“еүҚеӨ„дәҺжҙ»еҠЁзҡ„зәҝзЁӢдёӘж•°дёә{}".format(threading.current_thread(),threading.active_count()))
count+=1
if count==5:
break
print (count)
print('еҪ“еүҚжҙ»зқҖзҡ„зәҝзЁӢеҲ—иЎЁдёә:', threading.enumerate())
# е®һдҫӢеҢ–дёҖдёӘзәҝзЁӢ
t=threading.Thread(target=test,name='test',args=(0,)) #жӯӨеӨ„еҝ…йЎ»жҳҜе…ғзҘ–зұ»еһӢпјҢеҗҰеҲҷдјҡжҠҘй”ҷ
t.start() # еҗҜеҠЁдёҖдёӘзәҝзЁӢ
print ('еҪ“еүҚжҙ»зқҖзҡ„зәҝзЁӢеҲ—иЎЁдёә:',threading.enumerate())
print ('еҪ“еүҚеӨ„дәҺжҙ»еҠЁзҡ„зәҝзЁӢдёӘж•°дёә{} ,еҪ“еүҚдё»зәҝзЁӢдёә{},еҪ“еүҚзәҝзЁӢIDдёә{}'.format(threading.active_count(),threading.main_thread(),threading.get_ident()))
з»“жһңеҰӮдёӢ

е…¶зәҝзЁӢзҡ„жү§иЎҢдёҚжҳҜйЎәеәҸзҡ„пјҢе…¶и°ғз”ЁеҸ–еҶідәҺCPUзҡ„и°ғеәҰ规еҲҷпјҢиҖҢдё»зәҝзЁӢеңЁеӯҗзәҝзЁӢжүҖжңүеӯҗзәҝзЁӢйҖҖеҮәд№ӢеүҚйғҪжҳҜactiveзҠ¶жҖҒгҖӮ
name : зәҝзЁӢзҡ„еҗҚеӯ—пјҢеҸӘжҳҜдёҖдёӘж ҮиҜҶпјҢе…¶еҸҜд»ҘйҮҚеҗҚпјҢgetname() иҺ·еҸ–пјҢsetname()и®ҫзҪ®иҝҷдёӘеҗҚиҜҚ
identпјҡзәҝзЁӢIDпјҢе…¶жҳҜйқһ0ж•ҙж•°пјҢзәҝзЁӢеҗҜеҠЁеҗҺжүҚдјҡжңүIDпјҢеҗҰеҲҷдёәNone,зәҝзЁӢйҖҖеҮәпјҢжӯӨIDдҫқж—§еҸҜд»Ҙи®ҝй—®пјҢжӯӨIDеҸҜд»ҘйҮҚеӨҚдҪҝз”Ё
is_alive() иҝ”еӣһзәҝзЁӢжҳҜеҗҰжҙ»зқҖ
#!/usr/bin/poython3.6
#conding:utf-8
import threading
import time
def test(count):
while True:
count+=1
if count==5:
break
print (count)
print ('еҪ“еүҚзәҝзЁӢname дёә{},ID дёә{}'.format(threading.current_thread().name,threading.current_thread().ident))
# е®һдҫӢеҢ–дёҖдёӘзәҝзЁӢ
t=threading.Thread(target=test,name='test',args=(0,)) #жӯӨеӨ„еҝ…йЎ»жҳҜе…ғзҘ–зұ»еһӢпјҢеҗҰеҲҷдјҡжҠҘй”ҷ
t.start() # еҗҜеҠЁдёҖдёӘзәҝзЁӢ
print ('дё»зәҝзЁӢзҠ¶жҖҒ',threading.main_thread().is_alive())
print ('зәҝзЁӢзҠ¶жҖҒ',threading.current_thread().is_alive())з»“жһңеҰӮдёӢ

start() еҗҜеҠЁзәҝзЁӢпјҢжҜҸдёҖдёӘзәҝзЁӢеҝ…йЎ»дё”еҸӘиғҪиў«жү§иЎҢдёҖж¬Ў
run() иҝҗиЎҢзәҝзЁӢеҮҪж•°
#!/usr/bin/poython3.6
#conding:utf-8
import threading
import time
class MyThread(threading.Thread): # иҮӘе®ҡд№үдёҖдёӘзұ»пјҢ其继жүҝThreadзҡ„зӣёе…іstartе’ҢrunеұһжҖ§
def start(self) -> None:
print ('start',self)
super().start()
def run(self) -> None:
print ('run',self)
super().run()
def work():
print ('жң¬зәҝзЁӢIDдёә{}пјҢдё»зәҝзЁӢIDдёә{}'.format(threading.current_thread().ident,threading.main_thread().ident))
print ('test')
t=MyThread(target=work,name='w')
t.start()з»“жһңеҰӮдёӢ

#!/usr/bin/poython3.6
#conding:utf-8
import threading
import time
class MyThread(threading.Thread): # иҮӘе®ҡд№үдёҖдёӘзұ»пјҢ其继жүҝThreadзҡ„зӣёе…іstartе’ҢrunеұһжҖ§
def start(self) -> None:
print ('start',self)
super().start()
def run(self) -> None:
print ('run',self)
super().run()
def work():
print ('жң¬зәҝзЁӢIDдёә{}пјҢдё»зәҝзЁӢIDдёә{}'.format(threading.current_thread().ident,threading.main_thread().ident))
print ('test')
t=MyThread(target=work,name='w')
t.run()
з»“жһңеҰӮдёӢ

з»“и®әеҰӮдёӢпјҡstart ж–№жі•зҡ„и°ғз”Ёдјҡдә§з”ҹж–°зҡ„зәҝзЁӢпјҢиҖҢrunзҡ„и°ғз”ЁжҳҜеңЁдё»зәҝзЁӢдёӯиҝҗиЎҢзҡ„пјҢдё”runзҡ„и°ғз”ЁеҸӘдјҡи°ғз”ЁиҮӘе·ұзҡ„ж–№жі•пјҢиҖҢstart дјҡи°ғз”ЁиҮӘе·ұе’Ңrunж–№жі•
#!/usr/bin/poython3.6
#conding:utf-8
import threading
import time
class MyThread(threading.Thread): # иҮӘе®ҡд№үдёҖдёӘзұ»пјҢ其继жүҝThreadзҡ„зӣёе…іstartе’ҢrunеұһжҖ§
def start(self) -> None:
print ('start',self)
super().start()
def run(self) -> None:
print ('run',self)
super().run()
def work():
print ('test')
t=MyThread(target=work,name='w')
t.start()
time.sleep(3)
t.start() #еҶҚж¬ЎеҗҜз”ЁзәҝзЁӢ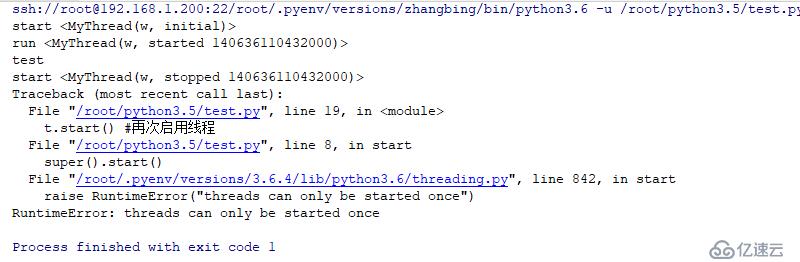
дёҠиҝ°еҸҜзҹҘпјҢзәҝзЁӢеңЁstartжҳҜдјҡи°ғз”Ёstartе’ҢrunеұһжҖ§иҝҗиЎҢпјҢдё”е…¶дёҚиғҪеҶҚж¬ЎеҗҜеҠЁзәҝзЁӢдёҖж¬ЎгҖӮ
и°ғз”Ёrunж–№жі•
#!/usr/bin/poython3.6
#conding:utf-8
import threading
import time
class MyThread(threading.Thread): # иҮӘе®ҡд№үдёҖдёӘзұ»пјҢ其继жүҝThreadзҡ„зӣёе…іstartе’ҢrunеұһжҖ§
def start(self) -> None:
print ('start',self)
super().start()
def run(self) -> None:
print ('run',self)
super().run()
def work():
print ('test')
t=MyThread(target=work,name='w')
t.run()
time.sleep(3)
t.run()з»“жһңеҰӮдёӢ

run ж–№жі•д№ҹеҸӘиғҪи°ғз”ЁдёҖж¬Ў
#!/usr/bin/poython3.6
#conding:utf-8
import threading
import time
class MyThread(threading.Thread): # иҮӘе®ҡд№үдёҖдёӘзұ»пјҢ其继жүҝThreadзҡ„зӣёе…іstartе’ҢrunеұһжҖ§
def start(self) -> None:
print ('start',self)
super().start()
def run(self) -> None:
print ('run',self)
super().run()
def work():
print ('test')
t=MyThread(target=work,name='w')
t.run()
time.sleep(3)
t.start()з»“жһңеҰӮдёӢ
дёҠиҝ°з»“жһңиЎЁжҳҺпјҢrunе’Ңstartзҡ„и°ғз”ЁдёҚиғҪеҮәзҺ°еңЁеҗҢдёҖдёӘзәҝзЁӢдёӯ
йҮҚж–°жһ„е»әдёҖдёӘж–°зәҝзЁӢ并еҗҜеҠЁ
#!/usr/bin/poython3.6
#conding:utf-8
import threading
import time
class MyThread(threading.Thread): # иҮӘе®ҡд№үдёҖдёӘзұ»пјҢ其继жүҝThreadзҡ„зӣёе…іstartе’ҢrunеұһжҖ§
def start(self) -> None:
print ('start',self)
super().start()
def run(self) -> None:
print ('run',self)
super().run()
def work():
print ('test')
t=MyThread(target=work,name='w')
t.start()
t=MyThread(target=work,name='w1')
t.start()з»“жһңеҰӮдёӢ

#!/usr/bin/poython3.6
#conding:utf-8
import threading
import time
class MyThread(threading.Thread): # иҮӘе®ҡд№үдёҖдёӘзұ»пјҢ其继жүҝThreadзҡ„зӣёе…іstartе’ҢrunеұһжҖ§
def start(self) -> None:
print ('start',self)
super().start()
def run(self) -> None:
print ('run',self)
super().run()
def work():
print ('test')
t=MyThread(target=work,name='w')
t.run()
t=MyThread(target=work,name='w1')
t.run()з»“жһңеҰӮдёӢ

жіЁйҮҠ继жүҝзҡ„runж–№жі•
#!/usr/bin/poython3.6
#conding:utf-8
import threading
import time
class MyThread(threading.Thread): # иҮӘе®ҡд№үдёҖдёӘзұ»пјҢ其继жүҝThreadзҡ„зӣёе…іstartе’ҢrunеұһжҖ§
def start(self) -> None:
print ('start',self)
super().start()
def run(self) -> None:
print ('run',self)
# super().run()
def work():
print ('test')
t=MyThread(target=work,name='w')
t.start()
t=MyThread(target=work,name='w1')
t.start()з»“жһңеҰӮдёӢ

зҰҒз”Ёstartж–№жі•
#!/usr/bin/poython3.6
#conding:utf-8
import threading
import time
class MyThread(threading.Thread): # иҮӘе®ҡд№үдёҖдёӘзұ»пјҢ其继жүҝThreadзҡ„зӣёе…іstartе’ҢrunеұһжҖ§
def start(self) -> None:
print ('start',self)
#super().start()
def run(self) -> None:
print ('run',self)
super().run()
def work():
print ('test')
t=MyThread(target=work,name='w')
t.start()
t=MyThread(target=work,name='w1')
t.start()
з»“и®әпјҡstart()еҮҪж•°дјҡи°ғз”ЁrunеҮҪж•°пјҢиҖҢrun()еҮҪж•°жҳҜз”ЁжқҘиҝҗиЎҢеҮҪж•°зҡ„пјҢstartжҳҜеҲӣе»әзәҝзЁӢзҡ„пјҢеңЁжү§иЎҢstart()ж—¶run()еҝ…дёҚеҸҜе°‘пјҢиҖҢеңЁиҝҗиЎҢrun()ж—¶еӣ дёәдёҚйңҖиҰҒи°ғз”Ёstart(),еӣ жӯӨе…¶жҳҜйқһеҝ…йЎ»зҡ„гҖӮ
start дјҡеҗҜз”Ёж–°зҡ„зәҝзЁӢпјҢе…¶дҪҝз”ЁеҸҜд»ҘеҪўжҲҗеӨҡзәҝзЁӢпјҢиҖҢrun()жҳҜеңЁеҪ“еүҚзәҝзЁӢдёӯи°ғз”ЁеҮҪж•°пјҢдёҚдјҡдә§з”ҹж–°зҡ„зәҝзЁӢпјҢе…¶еқҮдёҚиғҪеӨҡж¬Ўи°ғз”Ё
дёҖдёӘиҝӣзЁӢдёӯеҰӮжһңжңүеӨҡдёӘзәҝзЁӢпјҢе°ұжҳҜеӨҡзәҝзЁӢпјҢе®һзҺ°дёҖз§Қ并еҸ‘
зәҝзЁӢзҡ„и°ғеәҰд»»еҠЎжҳҜж“ҚдҪңзі»з»ҹе®ҢжҲҗзҡ„
жІЎжңүејҖж–°зҡ„зәҝзЁӢпјҢиҝҷе°ұжҳҜжҷ®йҖҡзҡ„еҮҪж•°и°ғз”ЁпјҢжүҖд»Ҙжү§иЎҢе®Ңt1.run()пјҢ然еҗҺжү§иЎҢt2.run()пјҢиҝҷдёҚжҳҜеӨҡзәҝзЁӢ
еҪ“дҪҝз”Ёstartж–№жі•еҗҜеҠЁзәҝзЁӢж—¶пјҢиҝӣзЁӢеҶ…жңүеӨҡдёӘжҙ»еҠЁзҡ„зәҝзЁӢ并иЎҢе·ҘдҪңпјҢе°ұжҳҜеӨҡзәҝзЁӢ
дёҖдёӘиҝӣзЁӢдёӯиҮіе°‘жңүдёҖдёӘзәҝзЁӢпјҢдҪңдёәзЁӢеәҸзҡ„е…ҘеҸЈпјҢиҝҷдёӘзәҝзЁӢе°ұжҳҜдё»зәҝзЁӢпјҢдёҖдёӘиҝӣзЁӢиҮіе°‘жңүдёҖдёӘдё»зәҝзЁӢ
е…¶д»–зәҝзЁӢз§°дёәе·ҘдҪңзәҝзЁӢ
pythonдёӯзҡ„зәҝзЁӢжІЎжңүдјҳе…Ҳзә§зҡ„жҰӮеҝө
жӯӨе®һдҫӢйңҖиҰҒеңЁipython дёӯиҝҗиЎҢ
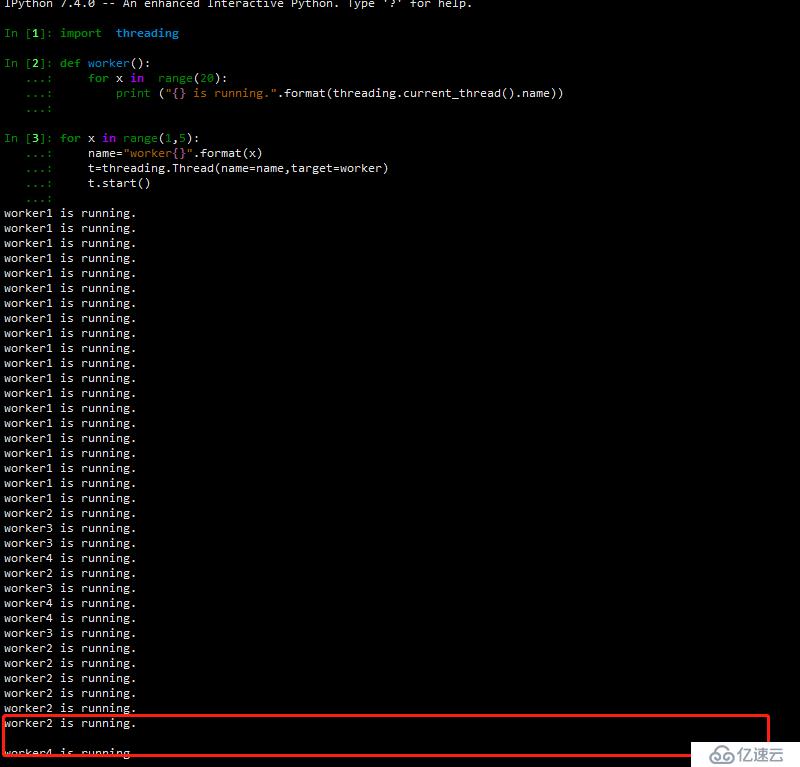
жӯӨеӨ„зҡ„print дјҡиў«жү“ж–ӯпјҢе…¶дёӯй—ҙжңүз©әж јпјҢжӯӨз§Қжғ…еҶөз§°дёәзәҝзЁӢдёҚе®үе…ЁгҖӮ
print еҮҪж•°зҡ„жү§иЎҢеҲҶдёәдёӨжӯҘпјҡ
1 жү“еҚ°еӯ—з¬ҰдёІ
2 жҚўиЎҢпјҢе°ұеңЁиҝҷд№Ӣй—ҙеҸ‘з”ҹдәҶзәҝзЁӢеҲҮжҚўпјҢе…¶дёҚе®үе…Ё
1 йҖҡиҝҮеӯ—з¬ҰдёІзҡ„жӢјжҺҘжқҘе®ҢжҲҗ
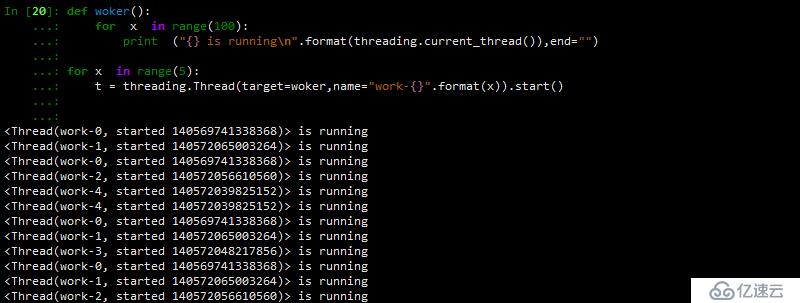
2 йҖҡиҝҮloggingжЁЎеқ—жқҘеӨ„зҗҶпјҢе…¶иҫ“еҮәиҝҮзЁӢдёӯжҳҜдёҚиў«жү“ж–ӯзҡ„
#!/usr/bin/poython3.6
#conding:utf-8
import threading
import logging # еҜје…Ҙж—Ҙеҝ—жү“еҚ°жЁЎеқ—
logging.basicConfig(level=logging.INFO) #е®ҡд№үеҹәжң¬зә§еҲ«пјҢй»ҳи®ӨжҳҜWARNINGпјҢжӯӨеӨ„дҝ®ж”№дёәINFO
def woker():
for x in range(10):
msg="{} is running".format(threading.current_thread())
logging.info(msg) # ж—Ҙеҝ—жү“еҚ°
for x in range(5):
t = threading.Thread(target=woker,name="work-{}".format(x)).start()з»“жһңеҰӮдёӢ
з®ҖеҚ•жөӢиҜ•зҡ„ж—¶еҖҷдҪҝз”ЁprintпјҢеңЁе…¶д»–еә”з”Ёзҡ„ж—¶еҖҷеҝ…йЎ»дҪҝз”ЁloggingпјҢе…¶жҳҜй’ҲеҜ№ж—Ҙеҝ—жү“еҚ°дҪҝз”Ёзҡ„жҠҖжңҜпјҢж—Ҙеҝ—жү“еҚ°иҝҮзЁӢдёӯжҳҜдёҚиғҪиў«дёӯж–ӯзҡ„пјҢ
иҝҷйҮҢзҡ„daemonзәҝзЁӢдёҚжҳҜLinuxдёӯзҡ„е®ҲжҠӨиҝӣзЁӢ
иҝӣзЁӢйқ зәҝзЁӢжү§иЎҢд»Јз ҒпјҢиҮіе°‘дёҖдёӘдё»зәҝзЁӢпјҢе…¶д»–зәҝзЁӢжҳҜе·ҘдҪңзәҝзЁӢ
дё»зәҝзЁӢжҳҜ第дёҖдёӘеҗҜеҠЁзҡ„зәҝзЁӢ
зҲ¶зәҝзЁӢпјҡ еҰӮжһңзәҝзЁӢAдёӯеҗҜеҠЁдәҶдёҖдёӘзәҝзЁӢBпјҢAе°ұжҳҜBзҡ„зҲ¶зәҝзЁӢ
еӯҗзәҝзЁӢ: Bе°ұжҳҜAзҡ„еӯҗзәҝзЁӢеңЁpythonдёӯпјҢжһ„е»әзәҝзЁӢзҡ„ж—¶еҖҷпјҢеҸҜд»Ҙи®ҫзҪ®daemonеұһжҖ§пјҢиҝҷдёӘеұһжҖ§еҝ…йЎ»еңЁstartж–№жі•д№ӢеүҚи®ҫзҪ®еҘҪпјҢ
зӣёе…іжәҗз Ғ

жӯӨеӨ„иЎЁжҳҺгҖӮиӢҘдј е…Ҙзҡ„daemon дёҚжҳҜNone,еҲҷе…¶иЎЁзӨәй»ҳи®Өдј е…Ҙзҡ„еҖјпјҢеҗҰеҲҷпјҢеҸҠиӢҘдёҚдј е…ҘпјҢеҲҷиЎЁзӨәдҪҝз”ЁеҪ“еүҚзәҝзЁӢзҡ„daemon
дё»зәҝзЁӢжҳҜnon-daemonзәҝзЁӢпјҢеҸҠdaemon=False
жҙ»зқҖзәҝзЁӢзҡ„еҲ—иЎЁзҡ„жәҗз Ғ

жӯӨеӨ„иЎЁзӨәжҙ»зқҖзҡ„зәҝзЁӢеҲ—иЎЁдёӯдёҖе®ҡдјҡеҢ…еҗ«дё»зәҝзЁӢпјҢ
#!/usr/bin/poython3.6
#conding:utf-8
import threading
import logging # еҜје…Ҙж—Ҙеҝ—жү“еҚ°жЁЎеқ—
logging.basicConfig(level=logging.INFO) #е®ҡд№үеҹәжң¬зә§еҲ«пјҢй»ҳи®ӨжҳҜWARNINGпјҢжӯӨеӨ„дҝ®ж”№дёәINFO
def woker():
for x in range(10):
msg="{} is running".format(threading.current_thread())
logging.info(msg) # ж—Ҙеҝ—жү“еҚ°
threading.Thread(target=woker,name="work-{}".format(0)).start()
print ('ending')
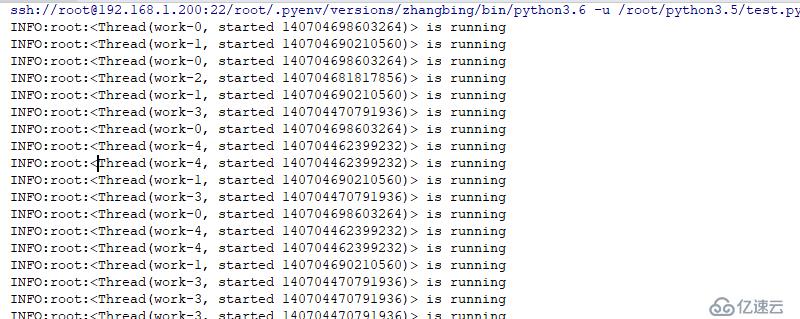
print (threading.enumerate()) #дё»зәҝзЁӢеӣ дёәе…¶д»–зәҝзЁӢзҡ„жү§иЎҢпјҢеӣ жӯӨе…¶еӨ„дәҺзӯүеҫ…зҠ¶жҖҒз»“жһңеҰӮдёӢ
#!/usr/bin/poython3.6
#conding:utf-8
import threading
import logging # еҜје…Ҙж—Ҙеҝ—жү“еҚ°жЁЎеқ—
logging.basicConfig(level=logging.INFO) #е®ҡд№үеҹәжң¬зә§еҲ«пјҢй»ҳи®ӨжҳҜWARNINGпјҢжӯӨеӨ„дҝ®ж”№дёәINFO
def woker():
for x in range(10):
msg="{} is running".format(threading.current_thread())
logging.info(msg) # ж—Ҙеҝ—жү“еҚ°
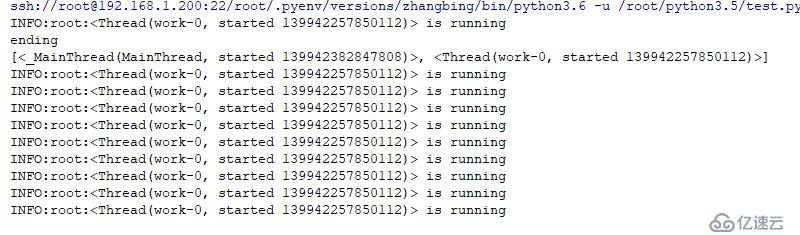
threading.Thread(target=woker,name="work-{}".format(0),daemon=True).start() #дё»зәҝзЁӢдёҖиҲ¬дјҡеңЁдёҖе®ҡж—¶й—ҙеҶ…жү«жҸҸеұһжҖ§еҲ—иЎЁпјҢиӢҘе…¶дёӯжңүnon-daemonзұ»еһӢ
# зҡ„зәҝзЁӢпјҢеҲҷдјҡзӯүеҫ…е…¶жү§иЎҢе®ҢжҲҗеҶҚйҖҖеҮәпјҢиӢҘжҳҜйҒҮи§ҒйғҪжҳҜdaemonзұ»еһӢзәҝзЁӢпјҢеҲҷзӣҙжҺҘйҖҖеҮәпјҢ
print ('ending')
print (threading.enumerate()) #дё»зәҝзЁӢеӣ дёәе…¶д»–зәҝзЁӢзҡ„жү§иЎҢпјҢеӣ жӯӨе…¶еӨ„дәҺзӯүеҫ…зҠ¶жҖҒз»“жһңеҰӮдёӢ

дёҠиҝ°зәҝзЁӢжҳҜdaemonзәҝзЁӢпјҢеӣ жӯӨдё»зәҝзЁӢдёҚдјҡзӯүеҫ…е…¶е®ҢжҲҗеҗҺеҶҚе…ій—ӯ
#!/usr/bin/poython3.6
#conding:utf-8
import threading
import logging # еҜје…Ҙж—Ҙеҝ—жү“еҚ°жЁЎеқ—
import time
logging.basicConfig(level=logging.INFO) #е®ҡд№үеҹәжң¬зә§еҲ«пјҢй»ҳи®ӨжҳҜWARNINGпјҢжӯӨеӨ„дҝ®ж”№дёәINFO
def woker():
for x in range(10):
msg="{} {} is running".format(x,threading.current_thread())
logging.info(msg) # ж—Ҙеҝ—жү“еҚ°
time.sleep(0.5) #жӯӨеӨ„й…ҚзҪ®е»¶иҝҹпјҢжЈҖйӘҢжҳҜеҗҰеңЁnon-daemonзәҝзЁӢжү§иЎҢе®ҢжҲҗеҗҺеҸҠдјҡзӣҙжҺҘе…ій—ӯзҡ„жғ…еҶө
threading.Thread(target=woker,name="work-{}".format(0),daemon=True).start() #дё»зәҝзЁӢдёҖиҲ¬дјҡеңЁдёҖе®ҡж—¶й—ҙеҶ…жү«жҸҸеұһжҖ§еҲ—иЎЁпјҢиӢҘе…¶дёӯжңүnon-daemonзұ»еһӢ
# зҡ„зәҝзЁӢпјҢеҲҷдјҡзӯүеҫ…е…¶жү§иЎҢе®ҢжҲҗеҶҚйҖҖеҮәпјҢиӢҘжҳҜйҒҮи§ҒйғҪжҳҜdaemonзұ»еһӢзәҝзЁӢпјҢеҲҷзӣҙжҺҘйҖҖеҮәпјҢгҖҒ
def woker1():
for x in ['a','b','c','d']:
msg="{} {} is running".format(x,threading.current_thread())
logging.info(msg) # ж—Ҙеҝ—жү“еҚ°
threading.Thread(target=woker1,name="work-{}".format(0)).start() #дё»зәҝзЁӢдёҖиҲ¬дјҡеңЁдёҖе®ҡж—¶й—ҙеҶ…жү«жҸҸеұһжҖ§еҲ—иЎЁпјҢиӢҘе…¶дёӯжңүnon-daemonзұ»еһӢ,еҲҷдёҚдјҡз»ҲжӯўпјҢ
# жӯӨеӨ„й»ҳи®Өд»ҺзҲ¶зәҝзЁӢдёӯиҺ·еҸ–еұһжҖ§пјҢзҲ¶зәҝзЁӢдёӯжҳҜnon-daemonпјҢеӣ жӯӨжӯӨеұһжҖ§дјҡдёҖзӣҙиҝҗиЎҢпјҢдёҠйқўзҡ„дјҡе…ій—ӯпјҢдҪҶдёҚдјҡеҪұе“ҚиҝҷдёӘ
print ('ending')
print (threading.enumerate()) #дё»зәҝзЁӢеӣ дёәе…¶д»–зәҝзЁӢзҡ„жү§иЎҢпјҢеӣ жӯӨе…¶еӨ„дәҺзӯүеҫ…зҠ¶жҖҒз»“жһңеҰӮдёӢ

з»“жһңиЎЁзӨәпјҢеҪ“non-daemonзәҝзЁӢжү§иЎҢе®ҢжҲҗеҗҺпјҢдёҚз®ЎdamonжҳҜеҗҰжү§иЎҢе®ҢжҲҗпјҢдё»зәҝзЁӢе°ҶзӣҙжҺҘз»ҲжӯўпјҢдёҚдјҡеҶҚж¬ЎиҝҗиЎҢгҖӮ
#!/usr/bin/poython3.6
#conding:utf-8
import threading
import logging # еҜје…Ҙж—Ҙеҝ—жү“еҚ°жЁЎеқ—
import time
def woker1():
for x in ['a','b','c','d']:
msg="{} {} is running".format(x,threading.current_thread())
logging.info(msg) # ж—Ҙеҝ—жү“еҚ°
logging.basicConfig(level=logging.INFO) #е®ҡд№үеҹәжң¬зә§еҲ«пјҢй»ҳи®ӨжҳҜWARNINGпјҢжӯӨеӨ„дҝ®ж”№дёәINFO
def woker():
for x in range(10):
msg="{} {} is running".format(x,threading.current_thread())
logging.info(msg) # ж—Ҙеҝ—жү“еҚ°
time.sleep(1) # жӯӨеӨ„й…ҚзҪ®1秒延时пјҢдҪҝеҫ—дё»зәҝзЁӢзңӢдёҚеҲ°еӯҷеӯҗзәҝзЁӢзҡ„non-daemonе°ұе…ій—ӯ
T3=threading.Thread(target=woker1,name="woker{}".format(10),daemon=False) #жӯӨеӨ„еҗҜеҠЁзҡ„зәҝзЁӢй»ҳи®ӨжҳҜnon-daemonзәҝзЁӢпјҢдҪҶз”ұдәҺе…¶зҲ¶зәҝзЁӢжҳҜdaemon
# еҸҠе°ұжҳҜдёӢйқўзҡ„T1зәҝзЁӢпјҢеҪ“T2зәҝзЁӢжү§иЎҢе®ҢжҜ•еҗҺзәҝзЁӢжү«жҸҸпјҢеҸ‘зҺ°жІЎnon-daemonзәҝзЁӢпјҢеҲҷзӣҙжҺҘйҖҖеҮәпјҢжӯӨж—¶е°ҶдёҚдјҡ继з»ӯжү§иЎҢT1 зҡ„еӯҗзәҝзЁӢT3пјҢиҷҪ然T3жҳҜnon-daemonгҖӮеӣ дёәе…¶жңӘеҗҜеҠЁ
T3.start()
T1=threading.Thread(target=woker,name="work-{}".format(0),daemon=True)#дё»зәҝзЁӢдёҖиҲ¬дјҡеңЁдёҖе®ҡж—¶й—ҙеҶ…жү«жҸҸеұһжҖ§еҲ—иЎЁпјҢиӢҘе…¶дёӯжңүnon-daemonзұ»еһӢ
T1.start()
# зҡ„зәҝзЁӢпјҢеҲҷдјҡзӯүеҫ…е…¶жү§иЎҢе®ҢжҲҗеҶҚйҖҖеҮәпјҢиӢҘжҳҜйҒҮи§ҒйғҪжҳҜdaemonзұ»еһӢзәҝзЁӢпјҢеҲҷзӣҙжҺҘйҖҖеҮәпјҢ
T2=threading.Thread(target=woker1,name="work-{}".format(0)) #дё»зәҝзЁӢдёҖиҲ¬дјҡеңЁдёҖе®ҡж—¶й—ҙеҶ…жү«жҸҸеұһжҖ§еҲ—иЎЁпјҢиӢҘе…¶дёӯжңүnon-daemonзұ»еһӢ,еҲҷдёҚдјҡз»ҲжӯўпјҢ
# жӯӨеӨ„й»ҳи®Өд»ҺзҲ¶зәҝзЁӢдёӯиҺ·еҸ–еұһжҖ§пјҢзҲ¶зәҝзЁӢдёӯжҳҜnon-daemonпјҢеӣ жӯӨжӯӨеұһжҖ§дјҡдёҖзӣҙиҝҗиЎҢпјҢдёҠйқўзҡ„дјҡе…ій—ӯпјҢдҪҶдёҚдјҡеҪұе“ҚиҝҷдёӘ
T2.start()
print ('ending')
print (threading.enumerate()) #дё»зәҝзЁӢеӣ дёәе…¶д»–зәҝзЁӢзҡ„жү§иЎҢпјҢеӣ жӯӨе…¶еӨ„дәҺзӯүеҫ…зҠ¶жҖҒ
з»“жһңеҰӮдёӢ

еҸҜиғҪеӯҷеӯҗзәҝзЁӢиҝҳжІЎиө·жқҘпјҢдё»зәҝзЁӢеҸӘзңӢеҲ°дәҶdaemonзәҝзЁӢгҖӮеҲҷзӣҙжҺҘиҝӣиЎҢе…ій—ӯпјҢ
#!/usr/bin/poython3.6
#conding:utf-8
import threading
import logging # еҜје…Ҙж—Ҙеҝ—жү“еҚ°жЁЎеқ—
import time
def woker1():
for x in ['a','b','c','d']:
msg="{} {} is running".format(x,threading.current_thread())
logging.info(msg) # ж—Ҙеҝ—жү“еҚ°
logging.basicConfig(level=logging.INFO) #е®ҡд№үеҹәжң¬зә§еҲ«пјҢй»ҳи®ӨжҳҜWARNINGпјҢжӯӨеӨ„дҝ®ж”№дёәINFO
def woker():
for x in range(10):
msg="{} {} is running".format(x,threading.current_thread())
logging.info(msg) # ж—Ҙеҝ—жү“еҚ°
# time.sleep(1) # жӯӨеӨ„й…ҚзҪ®1秒延时пјҢдҪҝеҫ—дё»зәҝзЁӢзңӢдёҚеҲ°еӯҷеӯҗзәҝзЁӢзҡ„non-daemonе°ұе…ій—ӯ
T3=threading.Thread(target=woker1,name="woker{}".format(10),daemon=False) #жӯӨеӨ„еҗҜеҠЁзҡ„зәҝзЁӢй»ҳи®ӨжҳҜnon-daemonзәҝзЁӢпјҢдҪҶз”ұдәҺе…¶зҲ¶зәҝзЁӢжҳҜdaemon
# еҸҠе°ұжҳҜдёӢйқўзҡ„T1зәҝзЁӢпјҢеҪ“T2зәҝзЁӢжү§иЎҢе®ҢжҜ•еҗҺзәҝзЁӢжү«жҸҸпјҢеҸ‘зҺ°жІЎnon-daemonзәҝзЁӢпјҢеҲҷзӣҙжҺҘйҖҖеҮәпјҢжӯӨж—¶е°ҶдёҚдјҡ继з»ӯжү§иЎҢT1 зҡ„еӯҗзәҝзЁӢT3пјҢиҷҪ然T3жҳҜnon-daemonгҖӮеӣ дёәе…¶жңӘеҗҜеҠЁ
T3.start()
T1=threading.Thread(target=woker,name="work-{}".format(0),daemon=True)#дё»зәҝзЁӢдёҖиҲ¬дјҡеңЁдёҖе®ҡж—¶й—ҙеҶ…жү«жҸҸеұһжҖ§еҲ—иЎЁпјҢиӢҘе…¶дёӯжңүnon-daemonзұ»еһӢ
T1.start()
# зҡ„зәҝзЁӢпјҢеҲҷдјҡзӯүеҫ…е…¶жү§иЎҢе®ҢжҲҗеҶҚйҖҖеҮәпјҢиӢҘжҳҜйҒҮи§ҒйғҪжҳҜdaemonзұ»еһӢзәҝзЁӢпјҢеҲҷзӣҙжҺҘйҖҖеҮәпјҢз»“жһңеҰӮдёӢ
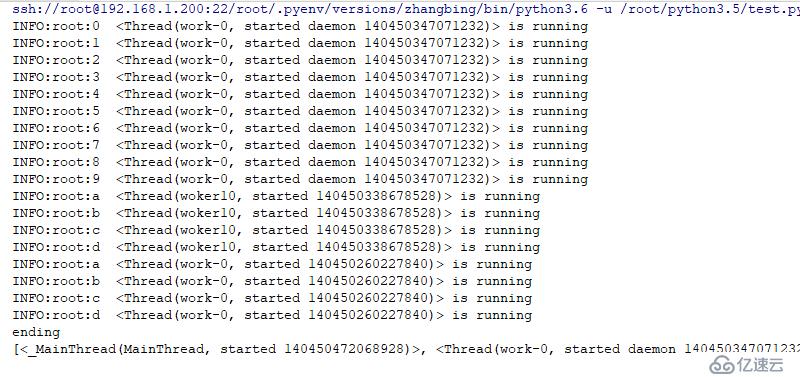
д№ҹеҸҜиғҪжҳҜеӯҷеӯҗзәҝзЁӢе·Із»Ҹиө·жқҘдәҶпјҢдё»зәҝзЁӢзңӢеҲ°дәҶnon-daemonзәҝзЁӢпјҢеӣ жӯӨжңӘзӣҙжҺҘе…ій—ӯпјҢиҖҢжҳҜзӯүеҫ…еӯҷеӯҗзәҝзЁӢжү§иЎҢе®ҢжҲҗеҗҺжүҚиҝӣиЎҢе…ій—ӯж“ҚдҪң
зӣёе…іеұһжҖ§
daemon еұһжҖ§ иЎЁзӨәзәҝзЁӢжҳҜеҗҰжҳҜdaemonзәҝзЁӢпјҢиҝҷдёӘеҖјеҝ…йЎ»еңЁstart()д№ӢеүҚи®ҫзҪ®пјҢеҗҰеҲҷдјҡеј•еҸ‘ејӮеёё
isDaemon() жҳҜеҗҰжҳҜdaemonзәҝзЁӢ
setDaemon() и®ҫзҪ®дёәdaemonзәҝзЁӢпјҢеҝ…йЎ»еңЁstartж–№жі•д№ӢеүҚи®ҫзҪ®
жҖ»з»“пјҡ
pythonдёӯзҲ¶зәҝзЁӢе’ҢеӯҗзәҝзЁӢжІЎжңүзӣҙжҺҘзҡ„з®ЎзҗҶе…ізі»
pythonдё»зәҝзЁӢжҳҜеҗҰжқҖжҺүзәҝзЁӢпјҢзңӢзҡ„жҳҜdaemon,иӢҘеҸӘжңүdaemonпјҢеҲҷзӣҙжҺҘеҲ жҺүжүҖжңүзәҝзЁӢпјҢиҮӘе·ұз»“жқҹпјҢиӢҘиҝҳжңүеӯҗзәҝзЁӢжҳҜnon-daemonпјҢеҲҷдјҡзӯүеҫ…
еҰӮжһңжғіи®©дёҖдёӘзәҝзЁӢе®Ңж•ҙжү§иЎҢпјҢеҲҷйңҖиҰҒе®ҡд№үnon-daemonеұһжҖ§
daemon еұһжҖ§пјҢеҝ…йЎ»еңЁstart д№ӢеүҚи®ҫзҪ®пјҢеҗҰеҲҷдјҡеј•еҸ‘runtimeErrorејӮеёё
зәҝзЁӢе…·жңүdaemonеұһжҖ§пјҢеҸҜд»ҘжҳҫзӨәи®ҫзҪ®дёәTrueжҲ–False,д№ҹеҸҜд»ҘдёҚи®ҫзҪ®пјҢеҲҷеҺ»й»ҳи®ӨеҖјNone
еҰӮжһңдёҚи®ҫзҪ®daemon,е°ұеҢәеҪ“еүҚзәҝзЁӢзҡ„daemonжқҘи®ҫзҪ®е®ғдё»зәҝзЁӢжҳҜnon-daemonзәҝзЁӢпјҢеҸҠdaemon=False
д»Һдё»зәҝзЁӢеҲӣе»әзҡ„жүҖжңүзәҝзЁӢдёҚи®ҫзҪ®daemonеұһжҖ§пјҢеҲҷй»ҳи®ӨйғҪжҳҜdaemon=FalseпјҢд№ҹе°ұжҳҜnon-daemonзәҝзЁӢ
pythonзЁӢеәҸеңЁжІЎжңүжҙ»зқҖзҡ„non-daemonзәҝзЁӢиҝҗиЎҢж—¶жҺЁеҮәпјҢд№ҹе°ұжҳҜеү©дёӢзҡ„еҸӘжңүdaemonзәҝзЁӢпјҢдё»зәҝзЁӢжүҚиғҪйҖҖеҮәпјҢеҗҰеҲҷдё»зәҝзЁӢе°ұеҸӘиғҪзӯүеҫ…гҖӮ
еә”з”ЁеңәжҷҜпјҡ
дёҚе…іеҝғд»Җд№Ҳж—¶еҖҷејҖе§ӢпјҢд»Җд№Ҳж—¶еҖҷз»“жқҹзҡ„ж—¶еҖҷдҪҝз”Ёdaemon,еҗҰеҲҷеҸҜд»ҘдҪҝз”Ёnon-daemonLinuxзҡ„daemonжҳҜиҝӣзЁӢзә§еҲ«зҡ„пјҢиҖҢpythonзҡ„daemonжҳҜзәҝзЁӢзә§еҲ«зҡ„пјҢе…¶д№Ӣй—ҙжІЎжңүеҸҜжҜ”жҖ§зҡ„
daemonе’Ңnon-daemon еҗҜеҠЁзҡ„ж—¶еҖҷпјҢйңҖиҰҒжіЁж„ҸеҗҜеҠЁзҡ„ж—¶жңәгҖӮ
з®ҖеҚ•жқҘиҜҙпјҢжң¬жқҘ并没жңүdaemon threadпјҢдёәдәҶз®ҖеҢ–зЁӢеәҸе‘ҳе·ҘдҪңпјҢ让他们дёҚеҺ»и®°еҪ•е’Ңз®ЎзҗҶйӮЈдәӣеҗҺеҸ°зәҝзЁӢпјҢеҲӣйҖ дәҶdaemon thread зҡ„жҰӮеҝөпјҢиҝҷдёӘжҰӮеҝөе”ҜдёҖзҡ„дҪңз”Ёе°ұжҳҜпјҢеҪ“дҪ жҠҠдёҖдёӘзәҝзЁӢи®ҫзҪ®дёәdaemonж—¶пјҢе®ғдјҡйҡҸзқҖдё»зәҝзЁӢзҡ„йҖҖеҮәиҖҢйҖҖеҮәгҖӮ
дё»иҰҒеә”з”ЁеңәжҷҜпјҡ
1 еҗҺеҸ°д»»еҠЎпјҢеҸ‘йҖҒеҝғи·іеҢ…пјҢзӣ‘жҺ§пјҢиҝҷз§ҚеңәжҷҜиҫғеӨҡгҖӮ
2 дё»зәҝзЁӢе·ҘдҪңжүҚжңүз”Ёзҡ„зәҝзЁӢпјҢеҰӮдё»зәҝзЁӢдёӯз»ҙжҠӨдәҶе…¬е…ұиө„жәҗпјҢдё»зәҝзЁӢе·Із»Ҹжё…зҗҶдәҶпјҢеҮҶеӨҮйҖҖеҮәпјҢиҖҢе·ҘдҪңзәҝзЁӢдҪҝз”Ёиҝҷдәӣиө„жәҗе·ҘдҪңд№ҹжІЎж„Ҹд№үдәҶпјҢдёҖиө·йҖҖеҮәжңҖеҗҲйҖӮ
3 йҡҸж—¶еҸҜд»Ҙиў«з»Ҳжӯўзҡ„зәҝзЁӢ
joinжҳҜж ҮеҮҶзҡ„зәҝзЁӢеҮҪж•°д№ӢдёҖпјҢе…¶еҗ«д№үжҳҜзӯүеҫ…пјҢи°Ғи°ғз”ЁjoinпјҢи°Ғзӯүеҫ…
#!/usr/bin/poython3.6
#conding:utf-8
import threading
import logging # еҜје…Ҙж—Ҙеҝ—жү“еҚ°жЁЎеқ—
import time
def foo(n):
for i in range(n):
print (i)
time.sleep(0.5)
t1=threading.Thread(target=foo,args=(10,),daemon=True)
t1.start() # й»ҳи®Өжғ…еҶөдёӢпјҢжӯӨзәҝзЁӢеҸӘиғҪжү§иЎҢе°‘йҮҸжӯӨпјҢдёҖиҲ¬дёҚиғҪе…ЁйғЁжү§иЎҢ
t1.join() # йҖҡиҝҮjoinж–№жі•е°ҶеҺҹжң¬дёҚиғҪжү§иЎҢе®ҢжҲҗзҡ„зәҝзЁӢжү§иЎҢе®ҢжҲҗдәҶз»“жһңеҰӮдёӢ
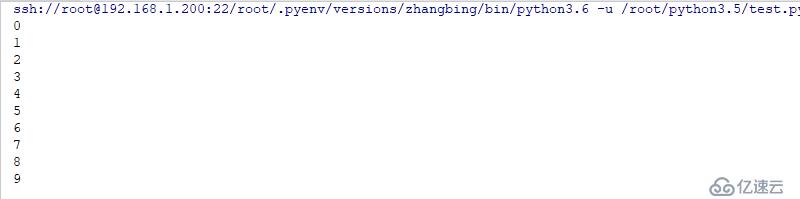
дҪҝз”Ёjoinж–№жі•пјҢdaemonзәҝзЁӢжү§иЎҢе®ҢжҲҗеҗҺпјҢдё»зәҝзЁӢжүҚйҖҖеҮәпјҢ
join(timeout=None)пјҢжҳҜзәҝзЁӢзҡ„ж ҮеҮҶж–№жі•д№ӢдёҖгҖӮ
timeoutеҸӮж•°жҢҮе®ҡи°ғз”ЁиҖ…зӯүеҫ…еӨҡд№…пјҢжІЎжңүи®ҫзҪ®и¶…ж—¶пјҢеҲҷе°ұдёҖзӣҙзӯүеҲ°иў«и°ғз”ЁзәҝзЁӢз»“жқҹпјҢи°ғз”Ёи°Ғзҡ„joinж–№жі•пјҢе°ұжҳҜjoinи°ҒпјҢи°Ғе°ұиҰҒзӯүеҫ…гҖӮдёҖдёӘзәҝзЁӢдёӯи°ғз”ЁеҸҰдёҖдёӘзәҝзЁӢзҡ„joinж–№жі•пјҢи°ғз”ЁиҖ…е°Ҷиў«йҳ»еЎһпјҢзӣҙеҲ°иў«и°ғз”ЁиҖ…зәҝзЁӢз»ҲжӯўпјҢдёҖдёӘзәҝзЁӢеҸҜд»Ҙиў«joinеӨҡж¬Ў
еҰӮжһңеңЁдёҖдёӘdaemon C зәҝзЁӢдёӯпјҢеҜ№еҸҰдёҖдёӘdaemonзәҝзЁӢD дҪҝз”ЁдәҶjoinж–№жі•пјҢеҸӘиғҪиҜҙжҳҺCиҰҒзӯүеҫ…DпјҢдё»зәҝзЁӢйҖҖеҮәпјҢCе’ҢDжҳҜеҗҰз»“жқҹпјҢд№ҹдёҚ管他们и°Ғзӯүеҫ…и°ҒпјҢйғҪиҰҒиў«жқҖжҺүгҖӮ
join ж–№жі•пјҢж”ҜжҢҒдҪҝз”Ёзӯүеҫ…пјҢдҪҶе…¶дјҡеҜјиҮҙеӨҡзәҝзЁӢеҸҳжҲҗеҚ•зәҝзЁӢпјҢе…¶дјҡеҪұе“ҚжӯЈеёёзҡ„иҝҗиЎҢпјҢеӣ жӯӨдёҖиҲ¬дјҡе°Ҷз”ҹжҲҗзҡ„зәҝзЁӢеҠ е…ҘеҲ°еҲ—иЎЁдёӯпјҢиҝӣиЎҢйҒҚеҺҶеҫ—еҲ°еҜ№еә”зәҝзЁӢиҝӣиЎҢи®Ўз®—гҖӮ
python жҸҗдҫӣдәҶthreading.local зұ»пјҢе°ҶиҝҷдёӘе®һдҫӢеҢ–еҫ—еҲ°дёҖдёӘе…ЁеұҖеҜ№иұЎпјҢдҪҶжҳҜдёҚеҗҢзҡ„зәҝзЁӢпјҢиҝҷдёӘеҜ№иұЎеӯҳеӮЁзҡ„ж•°жҚ®е…¶д»–зәҝзЁӢзңӢдёҚеҲ°
#!/usr/bin/poython3.6
#conding:utf-8
import threading
import time
def worker():
x=0 # жӯӨеӨ„жҳҜеұҖйғЁеҸҳйҮҸ
for i in range(10):
time.sleep(0.0001)
x+=1
print (threading.current_thread(),x)
for i in range(10):
threading.Thread(target=worker).start()з»“жһңеҰӮдёӢ

#!/usr/bin/poython3.6
#conding:utf-8
import threading
import time
x = 0 # жӯӨеӨ„жҳҜдёҖдёӘе…ЁеұҖеҸҳйҮҸ
def worker():
for i in range(10):
global x
time.sleep(0.0001)
x+=1
print (threading.current_thread(),x)
for i in range(10):
threading.Thread(target=worker).start()з»“жһңеҰӮдёӢ
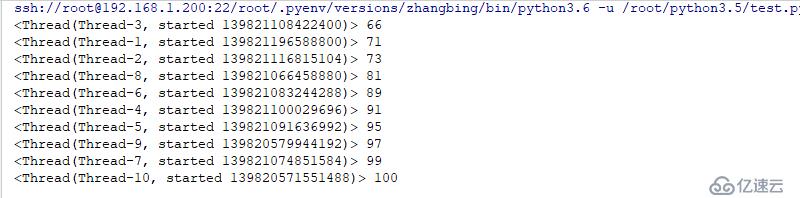
еұҖйғЁеҸҳйҮҸжң¬иә«е…·жңүйҡ”зҰ»ж•ҲжһңпјҢдёҖж—ҰеҸҳжҲҗе…ЁеұҖеҸҳйҮҸпјҢеҲҷжүҖжңүзҡ„зәҝзЁӢйғҪе°ҶиғҪеӨҹи®ҝй—®е’Ңдҝ®ж”№гҖӮ
#!/usr/bin/poython3.6
#conding:utf-8
import threading
import time
class A:
def __init__(self,x):
self.x=x
a=A(0)
def worker():
for i in range(100):
a.x=0
time.sleep(0.0001)
a.x+=1
print (threading.current_thread(),a.x)
for i in range(10):
threading.Thread(target=worker).start()з»“жһңеҰӮдёӢ
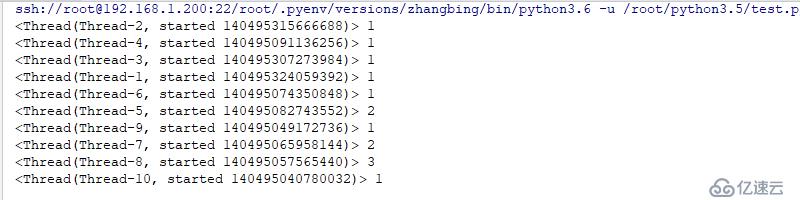
е…¶дёҚеҗҢзәҝзЁӢзҡ„TIDжҳҜдёҚеҗҢзҡ„пјҢеҸҜйҖҡиҝҮдёҚеҗҢзәҝзЁӢзҡ„TIDиҝӣиЎҢдёәй”®пјҢе…¶з»“жһңдёәеҖјпјҢдҫҝеҸҜи§ЈеҶіжӯӨз§Қд№ұиұЎ
#!/usr/bin/poython3.6
#conding:utf-8
import threading
import time
a=threading.local() # еҒҡеҲ°йҡ”зҰ»пјҢйҖҡиҝҮTIDиҝӣиЎҢж•°жҚ®зҡ„йҡ”зҰ»еӨ„зҗҶдёҚеҗҢзәҝзЁӢзҡ„дёҚеҗҢж•°еҖјй—®йўҳ
def worker():
a.x = 0
for i in range(100):
time.sleep(0.0001)
a.x+=1
print (threading.current_thread(),a.x)
for i in range(10):
threading.Thread(target=worker).start()з»“жһңеҰӮдёӢ
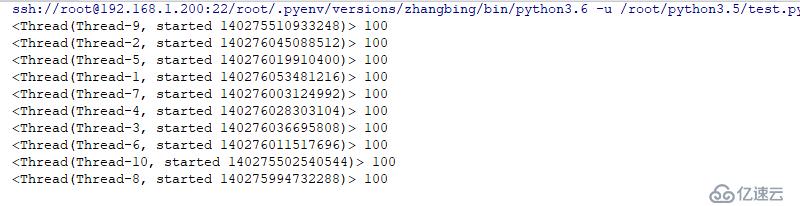
#!/usr/bin/poython3.6
#conding:utf-8
import threading
import time
a=threading.local() # еҒҡеҲ°йҡ”зҰ»пјҢйҖҡиҝҮTIDиҝӣиЎҢж•°жҚ®зҡ„йҡ”зҰ»еӨ„зҗҶдёҚеҗҢзәҝзЁӢзҡ„дёҚеҗҢж•°еҖјй—®йўҳ
def worker():
a.x = 0
for i in range(100):
time.sleep(0.0001)
a.x+=1
print (threading.current_thread(),a.x)
print (threading.get_ident(),a.__dict__) #жӯӨеӨ„жү“еҚ°зәҝзЁӢTIDе’Ңеӯ—е…ё
for i in range(10):
threading.Thread(target=worker).start()з»“жһңеҰӮдёӢ


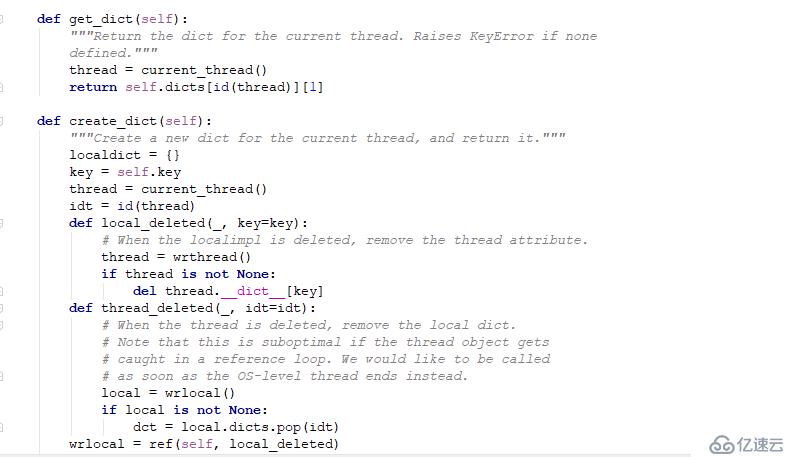
self.key жҳҜ еүҚйқўзҡ„еҠ дёҠid
йҖҡиҝҮеӯ—е…ёе®һзҺ°пјҢзәҝзЁӢIDзҡ„ең°еқҖжҳҜе”ҜдёҖзҡ„пјҢдҪҶи·ЁиҝӣзЁӢзҡ„зәҝзЁӢID дёҚдёҖе®ҡжҳҜзӣёеҗҢзҡ„иҝӣзЁӢдёӯзҡ„зәҝзЁӢең°еқҖеҸҜиғҪжҳҜдёҖж ·зҡ„гҖӮжҜҸдёҖдёӘиҝӣзЁӢйғҪи®ӨдёәиҮӘе·ұжҳҜзӢ¬еҚ иө„жәҗзҡ„пјҢдҪҶдёҚдёҖе®ҡе°ұжҳҜ гҖӮ
#!/usr/bin/poython3.6
#conding:utf-8
import threading
import time
X='abc'
ctx=threading.local()
ctx.x=123
def work():
print (X)
print (ctx)
print (ctx.x) #жӯӨж—¶зҡ„еӯ—е…ёдёӯctxжӯӨctx.xеұһжҖ§пјҢеӣ жӯӨе…¶дёҚиғҪжү“еҚ°пјҢе…¶жҳҜеңЁзәҝзЁӢеҶ…йғЁпјҢжҜҸдёӘdictеҜ№еә”зҡ„еҖјйғҪжҳҜзӢ¬з«Ӣзҡ„
print ('end')
threading.Thread(target=work).run() # жӯӨеӨ„жҳҜжң¬ең°зәҝзЁӢи°ғз”ЁпјҢеҲҷдёҚдјҡеҪұе“Қ
threading.Thread(target=work).start()з»“жһңеҰӮдёӢ

#!/usr/bin/poython3.6
#conding:utf-8
import threading
import time
X='abc'
ctx=threading.local()
ctx.x=123
def work():
print (X)
print (ctx)
ctx.x=100 #еҶ…йғЁзәҝзЁӢдёӯе®ҡд№үдёҖдёӘеұҖйғЁеҸҳйҮҸпјҢеҲҷеҸҜд»Ҙжү§иЎҢе’Ңиў«и°ғз”Ё
print (ctx.x) #жӯӨж—¶зҡ„ctx ж— жӯӨеұһжҖ§пјҢеӣ жӯӨе…¶дёҚиғҪжү“еҚ°пјҢе…¶жҳҜеңЁзәҝзЁӢеҶ…йғЁпјҢ
print ('end')
threading.Thread(target=work).run() # жӯӨеӨ„жҳҜжң¬ең°зәҝзЁӢи°ғз”ЁпјҢеҲҷдёҚдјҡеҪұе“Қ
threading.Thread(target=work).start()з»“жһңеҰӮдёӢ
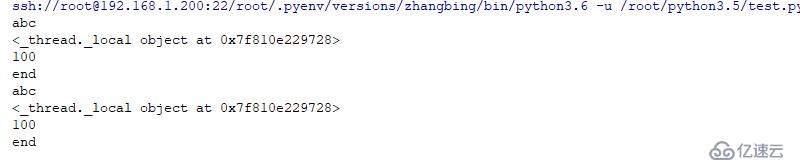
threading.localзұ»жһ„件дәҶдёҖдёӘеӨ§еӯ—е…ёпјҢе…¶е…ғзҙ зҡ„жҜҸдёҖзәҝзЁӢе®һдҫӢзҡ„ең°еқҖдёәKeyе’ҢзәҝзЁӢзҡ„еј•з”ЁзәҝзЁӢеҚ•зӢ¬зҡ„еӯ—е…ёзҡ„жҳ е°„(ж Ҳ)пјҢйҖҡиҝҮthreading.local е®һдҫӢе°ұеҸҜд»ҘеңЁдёҚеҗҢзҡ„зәҝзЁӢдёӯпјҢе®үе…Ёзҡ„дҪҝз”ЁзәҝзЁӢзӢ¬жңүзҡ„ж•°жҚ®пјҢеҒҡеҲ°дәҶзәҝзЁӢй—ҙж•°жҚ®зҡ„йҡ”зҰ»пјҢеҰӮеҗҢжң¬ең°еҸҳйҮҸдёҖж ·
дёҠиҝ°еҸҜзңӢеҲ°пјҢ其第дёҖдёӘеӯ—ж®өдҫҝжҳҜж—¶й—ҙ
#!/usr/bin/poython3.6
#conding:utf-8
import threading
import datetime
start_time=datetime.datetime.now()
def add(x,y):
print (x+y)
print("еҮҪж•°жү§иЎҢж—¶й—ҙдёә{}".format((datetime.datetime.now() - start_time).total_seconds()))
t=threading.Timer(3,add,args=(3,4))
t.start() #жӯӨеӨ„дјҡ延иҝҹ3з§’жү§иЎҢз»“жһңеҰӮдёӢ

жӯӨеӨ„жҳҜ延иҝҹжү§иЎҢзәҝзЁӢпјҢиҖҢдёҚжҳҜ延иҝҹжү§иЎҢеҮҪж•°пјҢжң¬иҙЁдёҠиҝҳжҳҜзәҝзЁӢ
#!/usr/bin/poython3.6
#conding:utf-8
import threading
import datetime
import time
def add(x,y):
print (x+y)
t=threading.Timer(6,add,args=(3,4)) # жӯӨеӨ„иЎЁзӨә6з§’еҗҺеҮәз»“жһң
t.start()
time.sleep(5)
t.cancel() #зәҝзЁӢиў«еҲ йҷӨеҸӘиҰҒжҳҜжІЎзңҹжӯЈжү§иЎҢзҡ„зәҝзЁӢпјҢйғҪиғҪеӨҹиў«cancelеҲ йҷӨ

#!/usr/bin/poython3.6
#conding:utf-8
import threading
import datetime
import time
def add(x,y):
time.sleep(5)
print (x+y)
t=threading.Timer(6,add,args=(3,4)) # жӯӨеӨ„иЎЁзӨә6з§’еҗҺеҮәз»“жһң
t.start()
time.sleep(10)
t.cancel()з»“жһңеҰӮдёӢ 
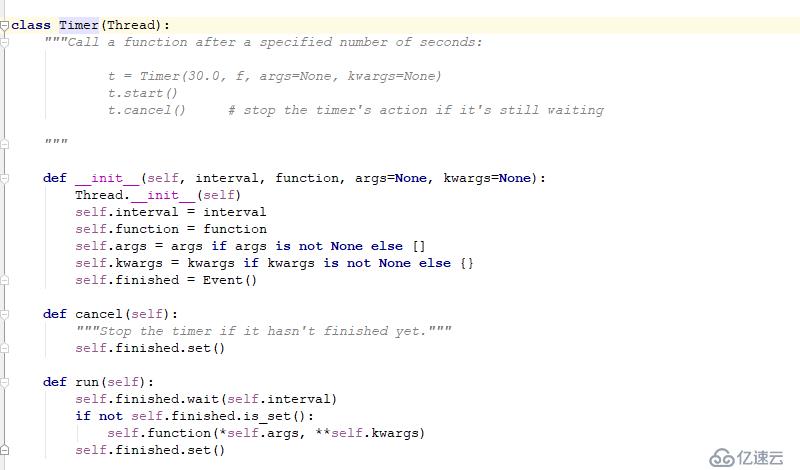
startж–№жі•еҗҺпјҢtimerеҜ№иұЎдјҡеӨ„дәҺзӯүеҫ…зҠ¶жҖҒпјҢзӯүеҫ…intervalд№ӢеҗҺпјҢејҖе§Ӣжү§иЎҢfunctionеҮҪж•°пјҢеҰӮжһңеңЁжү§иЎҢеҮҪж•°д№ӢеүҚзӯүеҫ…йҳ¶ж®өпјҢдҪҝз”ЁдәҶcancelж–№жі•пјҢе°ұдјҡи·іиҝҮжү§иЎҢеҮҪж•°з»“жқҹгҖӮ
еҰӮжһңзәҝзЁӢе·Із»ҸејҖе§Ӣжү§иЎҢдәҶпјҢеҲҷcancelе°ұжІЎжңүд»»дҪ•ж•ҲжһңдәҶ
TimerжҳҜзәҝзЁӢThreadзҡ„еӯҗзұ»пјҢе°ұжҳҜзәҝзЁӢзұ»пјҢе…·жңүзәҝзЁӢзҡ„иғҪеҠӣе’Ңзү№еҫҒ
е®ғзҡ„е®һдҫӢжҳҜиғҪеӨҹ延иҝҹжү§иЎҢзӣ®ж ҮеҮҪж•°зҡ„зәҝзЁӢпјҢеңЁзңҹжӯЈзҡ„жү§иЎҢзӣ®ж ҮеҮҪж•°д№ӢеүҚпјҢйғҪеҸҜд»Ҙcancelе®ғ гҖӮ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ