жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
еҰӮжһңжғіиҰҒеӨ§и§„жЁЎжҠ“еҸ–ж•°жҚ®пјҢйӮЈд№ҲдёҖе®ҡдјҡз”ЁеҲ°еҲҶеёғејҸзҲ¬иҷ«пјҢеҜ№дәҺеҲҶеёғејҸзҲ¬иҷ«жқҘиҜҙпјҢжҲ‘们дёҖе®ҡйңҖиҰҒеӨҡеҸ°дё»жңәпјҢжҜҸеҸ°дё»жңәеӨҡдёӘзҲ¬иҷ«д»»еҠЎпјҢдҪҶжҳҜжәҗд»Јз Ғе…¶е®һеҸӘжңүдёҖд»ҪгҖӮйӮЈд№ҲжҲ‘们йңҖиҰҒеҒҡзҡ„е°ұжҳҜе°ҶдёҖд»Ҫд»Јз ҒеҗҢж—¶йғЁзҪІеҲ°еӨҡеҸ°дё»жңәдёҠжқҘеҚҸеҗҢиҝҗиЎҢпјҢйӮЈд№ҲжҖҺд№ҲеҺ»йғЁзҪІе°ұеҸҲжҳҜдёҖдёӘеҖјеҫ—жҖқиҖғзҡ„й—®йўҳгҖӮ
еҜ№дәҺ Scrapy жқҘиҜҙпјҢе®ғжңүдёҖдёӘжү©еұ•з»„件еҸ«еҒҡ ScrapydпјҢжҲ‘们еҸӘйңҖиҰҒе®үиЈ… Scrapyd еҚіеҸҜиҝңзЁӢз®ЎзҗҶ Scrapy д»»еҠЎпјҢеҢ…жӢ¬йғЁзҪІжәҗз ҒгҖҒеҗҜеҠЁд»»еҠЎгҖҒзӣ‘еҗ¬д»»еҠЎзӯүж“ҚдҪңгҖӮеҸҰеӨ–иҝҳжңү ScrapydClient е’Ң ScrapydAPI жқҘеё®еҠ©жҲ‘们жӣҙж–№дҫҝең°е®ҢжҲҗйғЁзҪІе’Ңзӣ‘еҗ¬ж“ҚдҪңгҖӮ
еҸҰеӨ–иҝҳжңүдёҖз§ҚйғЁзҪІж–№ејҸе°ұжҳҜ Docker йӣҶзҫӨйғЁзҪІпјҢжҲ‘们еҸӘйңҖиҰҒе°ҶзҲ¬иҷ«еҲ¶дҪңдёә Docker й•ңеғҸпјҢеҸӘиҰҒдё»жңәе®үиЈ…дәҶ DockerпјҢе°ұеҸҜд»ҘзӣҙжҺҘиҝҗиЎҢзҲ¬иҷ«пјҢиҖҢж— йңҖеҶҚеҺ»жӢ…еҝғзҺҜеўғй…ҚзҪ®гҖҒзүҲжң¬й—®йўҳгҖӮ
жң¬иҠӮжҲ‘们е°ұжқҘд»Ӣз»ҚдёҖдёӢзӣёе…ізҺҜеўғзҡ„й…ҚзҪ®иҝҮзЁӢгҖӮ
Docker жҳҜдёҖз§Қе®№еҷЁжҠҖжңҜпјҢе®ғеҸҜд»Ҙе°Ҷеә”з”Ёе’ҢзҺҜеўғзӯүиҝӣиЎҢжү“еҢ…пјҢеҪўжҲҗдёҖдёӘзӢ¬з«Ӣзҡ„пјҢзұ»дјјдәҺ iOS зҡ„ APP еҪўејҸзҡ„гҖҢеә”з”ЁгҖҚпјҢиҝҷдёӘеә”з”ЁеҸҜд»ҘзӣҙжҺҘиў«еҲҶеҸ‘еҲ°д»»ж„ҸдёҖдёӘж”ҜжҢҒ Docker зҡ„зҺҜеўғдёӯпјҢйҖҡиҝҮз®ҖеҚ•зҡ„е‘Ҫд»ӨеҚіеҸҜеҗҜеҠЁиҝҗиЎҢгҖӮDocker жҳҜдёҖз§ҚжңҖжөҒиЎҢзҡ„е®№еҷЁеҢ–е®һзҺ°ж–№жЎҲгҖӮе’ҢиҷҡжӢҹеҢ–жҠҖжңҜзұ»дјјпјҢе®ғжһҒеӨ§зҡ„ж–№дҫҝдәҶеә”з”ЁжңҚеҠЎзҡ„йғЁзҪІпјӣеҸҲдёҺиҷҡжӢҹеҢ–жҠҖжңҜдёҚеҗҢпјҢе®ғд»ҘдёҖз§ҚжӣҙиҪ»йҮҸзҡ„ж–№ејҸе®һзҺ°дәҶеә”з”ЁжңҚеҠЎзҡ„жү“еҢ…гҖӮдҪҝз”Ё Docker еҸҜд»Ҙи®©жҜҸдёӘеә”з”ЁеҪјжӯӨзӣёдә’йҡ”зҰ»пјҢеңЁеҗҢдёҖеҸ°жңәеҷЁдёҠеҗҢж—¶иҝҗиЎҢеӨҡдёӘеә”з”ЁпјҢдёҚиҝҮ他们еҪјжӯӨд№Ӣй—ҙе…ұдә«еҗҢдёҖдёӘж“ҚдҪңзі»з»ҹгҖӮDocker зҡ„дјҳеҠҝеңЁдәҺпјҢе®ғеҸҜд»ҘеңЁжӣҙз»Ҷзҡ„зІ’еәҰдёҠиҝӣиЎҢиө„жәҗзҡ„з®ЎзҗҶпјҢд№ҹжҜ”иҷҡжӢҹеҢ–жҠҖжңҜжӣҙеҠ иҠӮзәҰиө„жәҗгҖӮPythonиө„жәҗеҲҶдә«qun 784758214 ,еҶ…жңүе®үиЈ…еҢ…пјҢPDFпјҢеӯҰд№ и§Ҷйў‘пјҢиҝҷйҮҢжҳҜPythonеӯҰд№ иҖ…зҡ„иҒҡйӣҶең°пјҢйӣ¶еҹәзЎҖпјҢиҝӣйҳ¶пјҢйғҪж¬ўиҝҺ
жң¬ж®өеҸӮиҖғпјҡDaoCloudе®ҳж–№ж–ҮжЎЈ
еҜ№дәҺзҲ¬иҷ«жқҘиҜҙпјҢеҰӮжһңжҲ‘们йңҖиҰҒеӨ§и§„жЁЎйғЁзҪІзҲ¬иҷ«зі»з»ҹзҡ„иҜқпјҢз”Ё Docker дјҡеӨ§еӨ§жҸҗй«ҳж•ҲзҺҮпјҢе·Ҙж¬Іе–„е…¶дәӢпјҢеҝ…е…ҲеҲ©е…¶еҷЁгҖӮ
жң¬иҠӮжқҘд»Ӣз»ҚдёҖдёӢдёүеӨ§е№іеҸ°дёӢ Docker зҡ„е®үиЈ…ж–№ејҸгҖӮ
иҜҰз»Ҷзҡ„еҲҶжӯҘйӘӨзҡ„е®үиЈ…иҜҙжҳҺеҸҜд»ҘеҸӮи§Ғе®ҳж–№ж–ҮжЎЈпјҡhttps://docs.docker.com/engin...гҖӮ
еңЁе®ҳж–№ж–ҮжЎЈдёӯиҜҰз»ҶиҜҙжҳҺдәҶдёҚеҗҢ Linux зі»з»ҹзҡ„е®үиЈ…ж–№жі•пјҢе®үиЈ…жөҒзЁӢж №жҚ®ж–ҮжЎЈдёҖжӯҘжӯҘжү§иЎҢеҚіеҸҜе®үиЈ…жҲҗеҠҹгҖӮ
дҪҶжҳҜдёәдәҶдҪҝеҫ—е®үиЈ…жӣҙеҠ ж–№дҫҝпјҢDocker е®ҳж–№иҝҳжҸҗдҫӣдәҶдёҖй”®е®үиЈ…и„ҡжң¬пјҢдҪҝз”Ёе®ғдјҡдҪҝеҫ—е®үиЈ…жӣҙеҠ дҫҝжҚ·пјҢдёҚз”ЁеҶҚеҺ»дёҖжӯҘжӯҘжү§иЎҢе‘Ҫд»Өе®үиЈ…дәҶпјҢеңЁжӯӨд»Ӣз»ҚдёҖдёӢдёҖй”®и„ҡжң¬е®үиЈ…ж–№ејҸгҖӮ
йҰ–е…ҲжҳҜ Docker е®ҳж–№жҸҗдҫӣзҡ„е®үиЈ…и„ҡжң¬пјҢзӣёжҜ”е…¶д»–и„ҡжң¬пјҢе®ҳж–№жҸҗдҫӣзҡ„дёҖе®ҡжӣҙйқ и°ұпјҢе®үиЈ…е‘Ҫд»ӨеҰӮдёӢпјҡ
curl -sSL https://get.docker.com/ | shеҸӘиҰҒжү§иЎҢеҰӮдёҠдёҖжқЎе‘Ҫд»ӨпјҢзӯүеҫ…дёҖдјҡе„ҝ Docker дҫҝдјҡе®үиЈ…е®ҢжҲҗпјҢйқһеёёж–№дҫҝгҖӮ
дҪҶжҳҜе®ҳж–№и„ҡжң¬е®үиЈ…жңүдёҖдёӘзјәзӮ№пјҢйӮЈе°ұжҳҜж…ўпјҢд№ҹеҸҜиғҪдёӢиҪҪи¶…ж—¶пјҢжүҖд»ҘдёәдәҶеҠ еҝ«дёӢиҪҪйҖҹеәҰпјҢжҲ‘们еҸҜд»ҘдҪҝз”ЁеӣҪеҶ…зҡ„й•ңеғҸжқҘе®үиЈ…пјҢжүҖд»ҘеңЁиҝҷйҮҢиҝҳжңүйҳҝйҮҢдә‘е’Ң DaoCloud зҡ„е®үиЈ…и„ҡжң¬гҖӮ
йҳҝйҮҢдә‘е®үиЈ…и„ҡжң¬пјҡ
curl -sSL http://acs-public-mirror.oss-cn-hangzhou.aliyuncs.com/docker-engine/internet | sh -DaoCloud е®үиЈ…и„ҡжң¬пјҡ
curl -sSL https://get.daocloud.io/docker | shдёӨдёӘи„ҡжң¬еҸҜд»Ҙд»»йҖүе…¶дёҖпјҢйҖҹеәҰйғҪйқһеёёдёҚй”ҷгҖӮ
зӯүеҫ…и„ҡжң¬жү§иЎҢе®ҢжҜ•д№ӢеҗҺпјҢе°ұеҸҜд»ҘдҪҝз”Ё Docker зӣёе…іе‘Ҫд»ӨдәҶпјҢеҰӮиҝҗиЎҢжөӢиҜ• Hello World й•ңеғҸпјҡ
docker run hello-worldиҝҗиЎҢз»“жһңпјҡ
Unable to find image 'hello-world:latest' locally
latest: Pulling from library/hello-world
78445dd45222: Pull complete
Digest: sha256:c5515758d4c5e1e838e9cd307f6c6a0d620b5e07e6f927b07d05f6d12a1ac8d7
Status: Downloaded newer image for hello-world:latest
Hello from Docker!
This message shows that your installation appears to be working correctly.еҰӮжһңеҮәзҺ°дёҠж–Үзұ»дјјжҸҗзӨәеҶ…е®№еҲҷиҜҒжҳҺ Docker еҸҜд»ҘжӯЈеёёдҪҝз”ЁдәҶгҖӮ
Mac е№іеҸ°еҗҢж ·жңүдёӨз§ҚйҖүжӢ©пјҢDocker for Mac е’Ң Docker ToolboxгҖӮ
Docker for Mac иҰҒжұӮзі»з»ҹдёә OS X EI Captain 10.11 жҲ–жӣҙж–°пјҢиҮіе°‘ 4GB еҶ…еӯҳпјҢеҰӮжһңдҪ зҡ„зі»з»ҹж»Ўи¶іжӯӨиҰҒжұӮпјҢеҲҷејәзғҲе»әи®®е®үиЈ… Docker for MacгҖӮ
еҸҜд»ҘдҪҝз”Ё HomeBrew е®үиЈ…пјҢе®үиЈ…е‘Ҫд»ӨеҰӮдёӢпјҡ
brew cask install docker
Pythonиө„жәҗеҲҶдә«qun 784758214 ,еҶ…жңүе®үиЈ…еҢ…пјҢPDFпјҢеӯҰд№ и§Ҷйў‘пјҢиҝҷйҮҢжҳҜPythonеӯҰд№ иҖ…зҡ„иҒҡйӣҶең°пјҢйӣ¶еҹәзЎҖпјҢиҝӣйҳ¶пјҢйғҪж¬ўиҝҺеҸҰеӨ–д№ҹеҸҜд»ҘжүӢеҠЁдёӢиҪҪе®үиЈ…еҢ…е®үиЈ…пјҢе®үиЈ…еҢ…дёӢиҪҪең°еқҖдёәпјҡhttps://download.docker.com/m...
дёӢиҪҪе®ҢжҲҗд№ӢеҗҺзӣҙжҺҘеҸҢеҮ»е®үиЈ…еҢ…пјҢ然еҗҺе°ҶзЁӢеәҸжӢ–еҠЁеҲ°еә”з”ЁзЁӢеәҸдёӯеҚіеҸҜгҖӮ
зӮ№еҮ»зЁӢеәҸеӣҫж ҮиҝҗиЎҢ DockerпјҢдјҡеҸ‘зҺ°еңЁиҸңеҚ•ж ҸдёӯеҮәзҺ°дәҶ Docker зҡ„еӣҫж ҮпјҢеҰӮеӣҫ 1-83 дёӯзҡ„第дёүдёӘе°ҸйІёйұјеӣҫж Үпјҡ

еӣҫ 1-83 иҸңеҚ•ж Ҹ
зӮ№еҮ»еӣҫж Үеұ•ејҖиҸңеҚ•д№ӢеҗҺпјҢеҶҚзӮ№еҮ» Start жҢүй’®еҚіеҸҜеҗҜеҠЁ DockerпјҢеҗҜеҠЁжҲҗеҠҹдҫҝдјҡжҸҗзӨә Docker is runningпјҢеҰӮеӣҫ 1-84 жүҖзӨәпјҡ
еӣҫ 1-84 иҝҗиЎҢйЎөйқў
йҡҸеҗҺжҲ‘们е°ұеҸҜд»ҘеңЁе‘Ҫд»ӨиЎҢдёӢдҪҝз”Ё Docker е‘Ҫд»ӨдәҶгҖӮ
еҸҜд»ҘдҪҝз”ЁеҰӮдёӢе‘Ҫд»ӨжөӢиҜ•иҝҗиЎҢпјҡ
sudo docker run hello-worldиҝҗиЎҢз»“жһңеҰӮеӣҫ 1-85 жүҖзӨәпјҡ
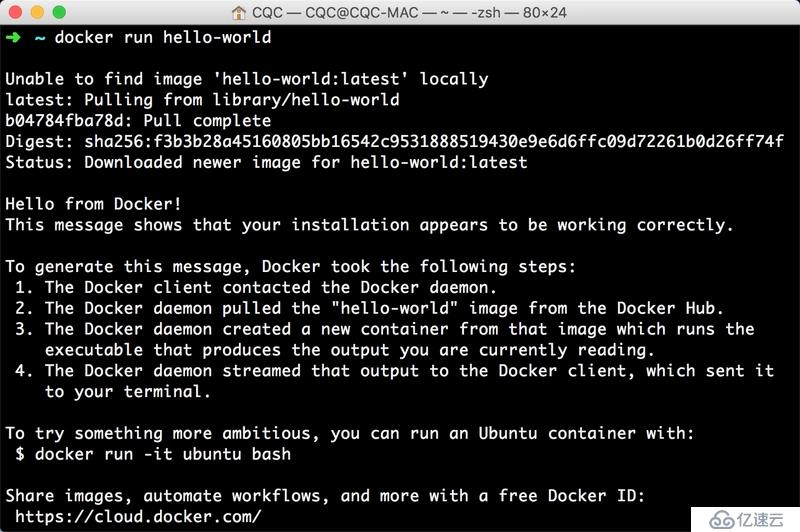
еӣҫ 1-85 иҝҗиЎҢз»“жһң
еҰӮжһңеҮәзҺ°зұ»дјјиҫ“еҮәеҲҷиҜҒжҳҺ Docker е·Із»ҸжҲҗеҠҹе®үиЈ…гҖӮ
еҰӮжһңзі»з»ҹдёҚж»Ўи¶іиҰҒжұӮпјҢеҸҜд»ҘдёӢиҪҪ Docker ToolboxпјҢе…¶е®үиЈ…иҜҙжҳҺдёәпјҡhttps://docs.docker.com/toolb...гҖӮ
е…ідәҺ Docker for Mac е’Ң Docker Toolbox зҡ„еҢәеҲ«пјҢеҸҜд»ҘеҸӮи§Ғпјҡhttps://docs.docker.com/docke...гҖӮ
е®үиЈ…еҘҪ Docker д№ӢеҗҺпјҢеңЁиҝҗиЎҢжөӢиҜ•е‘Ҫд»Өж—¶пјҢжҲ‘们дјҡеҸ‘зҺ°е®ғйҰ–е…ҲдјҡдёӢиҪҪдёҖдёӘ Hello World зҡ„й•ңеғҸпјҢ然еҗҺе°Ҷе…¶иҝҗиЎҢпјҢдҪҶжҳҜдёӢиҪҪйҖҹеәҰжңүж—¶еҖҷдјҡйқһеёёж…ўпјҢиҝҷжҳҜеӣ дёәе®ғй»ҳи®ӨиҝҳжҳҜд»ҺеӣҪеӨ–зҡ„ Docker Hub дёӢиҪҪзҡ„пјҢжүҖд»ҘдёәдәҶжҸҗй«ҳй•ңеғҸзҡ„дёӢиҪҪйҖҹеәҰпјҢжҲ‘们иҝҳеҸҜд»ҘдҪҝз”ЁеӣҪеҶ…й•ңеғҸжқҘеҠ йҖҹдёӢиҪҪпјҢжүҖд»Ҙиҝҷе°ұжңүдәҶ Docker еҠ йҖҹеҷЁдёҖиҜҙгҖӮ
жҺЁиҚҗзҡ„ Docker еҠ йҖҹеҷЁжңү DaoCloud е’ҢйҳҝйҮҢдә‘гҖӮ
DaoCloudпјҡhttps://www.daocloud.io/mirror
йҳҝйҮҢдә‘пјҡhttps://cr.console.aliyun.com...
дёҚеҗҢе№іеҸ°зҡ„й•ңеғҸеҠ йҖҹж–№жі•й…ҚзҪ®еҸҜд»ҘеҸӮиҖғ DaoCloud зҡ„е®ҳж–№ж–ҮжЎЈпјҡhttp://guide.daocloud.io/dcs/...гҖӮ
й…ҚзҪ®е®ҢжҲҗд№ӢеҗҺпјҢеҸҜд»ҘеҸ‘зҺ°й•ңеғҸзҡ„дёӢиҪҪйҖҹеәҰдјҡеҝ«йқһеёёеӨҡгҖӮ
д»ҘдёҠдҫҝжҳҜ Docker зҡ„е®үиЈ…ж–№ејҸиҜҙжҳҺгҖӮ
Scrapyd жҳҜдёҖдёӘз”ЁдәҺйғЁзҪІе’ҢиҝҗиЎҢ Scrapy йЎ№зӣ®зҡ„е·Ҙе…·гҖӮжңүдәҶе®ғпјҢдҪ еҸҜд»Ҙе°ҶеҶҷеҘҪзҡ„ Scrapy йЎ№зӣ®дёҠдј еҲ°дә‘дё»жңә并йҖҡиҝҮ API жқҘжҺ§еҲ¶е®ғзҡ„иҝҗиЎҢгҖӮ
既然жҳҜ Scrapy йЎ№зӣ®йғЁзҪІпјҢжүҖд»Ҙеҹәжң¬дёҠйғҪдҪҝз”Ё Linux дё»жңәпјҢжүҖд»Ҙжң¬иҠӮзҡ„е®үиЈ…жҳҜй’ҲеҜ№дәҺ Linux дё»жңәзҡ„гҖӮ
жҺЁиҚҗдҪҝз”Ё Pip е®үиЈ…пјҢе‘Ҫд»ӨеҰӮдёӢпјҡ
pip3 install scrapydе®үиЈ…е®ҢжҜ•д№ӢеҗҺйңҖиҰҒж–°е»әдёҖдёӘй…ҚзҪ®ж–Ү件 /etc/scrapyd/scrapyd.confпјҢScrapyd еңЁиҝҗиЎҢзҡ„ж—¶еҖҷдјҡиҜ»еҸ–жӯӨй…ҚзҪ®ж–Ү件гҖӮ
еңЁ Scrapyd 1.2 зүҲжң¬д№ӢеҗҺдёҚдјҡиҮӘеҠЁеҲӣе»әиҜҘж–Ү件пјҢйңҖиҰҒжҲ‘们иҮӘиЎҢж·»еҠ гҖӮ
жү§иЎҢе‘Ҫд»Өж–°е»әж–Ү件пјҡ
sudo mkdir /etc/scrapyd
sudo vi /etc/scrapyd/scrapyd.confеҶҷе…ҘеҰӮдёӢеҶ…е®№пјҡ
[scrapyd]
eggs_dir = eggs
logs_dir = logs
items_dir =
jobs_to_keep = 5
dbs_dir = dbs
max_proc = 0
max_proc_per_cpu = 10
finished_to_keep = 100
poll_interval = 5.0
bind_address = 0.0.0.0
http_port = 6800
debug = off
runner = scrapyd.runner
application = scrapyd.app.application
launcher = scrapyd.launcher.Launcher
webroot = scrapyd.website.Root
[services]
schedule.json = scrapyd.webservice.Schedule
cancel.json = scrapyd.webservice.Cancel
addversion.json = scrapyd.webservice.AddVersion
listprojects.json = scrapyd.webservice.ListProjects
listversions.json = scrapyd.webservice.ListVersions
listspiders.json = scrapyd.webservice.ListSpiders
delproject.json = scrapyd.webservice.DeleteProject
delversion.json = scrapyd.webservice.DeleteVersion
listjobs.json = scrapyd.webservice.ListJobs
daemonstatus.json = scrapyd.webservice.DaemonStatusй…ҚзҪ®ж–Ү件зҡ„еҶ…е®№еҸҜд»ҘеҸӮи§Ғе®ҳж–№ж–ҮжЎЈпјҡhttps://scrapyd.readthedocs.i...пјҢеңЁиҝҷйҮҢзҡ„й…ҚзҪ®ж–Ү件жңүжүҖдҝ®ж”№пјҢе…¶дёӯд№ӢдёҖжҳҜ max_proc_per_cpu е®ҳж–№й»ҳи®Өдёә 4пјҢеҚідёҖеҸ°дё»жңәжҜҸдёӘ CPU жңҖеӨҡиҝҗиЎҢ 4 дёӘScrapy JobпјҢеңЁжӯӨжҸҗй«ҳдёә 10пјҢеҸҰеӨ–дёҖдёӘжҳҜ bind_addressпјҢй»ҳи®Өдёәжң¬ең° 127.0.0.1пјҢеңЁжӯӨдҝ®ж”№дёә 0.0.0.0пјҢд»ҘдҪҝеӨ–зҪ‘еҸҜд»Ҙи®ҝй—®гҖӮ
з”ұдәҺ Scrapyd жҳҜдёҖдёӘзәҜ Python йЎ№зӣ®пјҢеңЁиҝҷйҮҢеҸҜд»ҘзӣҙжҺҘи°ғз”Ё scrapyd жқҘиҝҗиЎҢпјҢдёәдәҶдҪҝзЁӢеәҸдёҖзӣҙеңЁеҗҺеҸ°иҝҗиЎҢпјҢLinux е’Ң Mac еҸҜд»ҘдҪҝз”ЁеҰӮдёӢе‘Ҫд»Өпјҡ
(scrapyd > /dev/null &)иҝҷж · Scrapyd е°ұдјҡеңЁеҗҺеҸ°жҢҒз»ӯиҝҗиЎҢдәҶпјҢжҺ§еҲ¶еҸ°иҫ“еҮәзӣҙжҺҘеҝҪз•ҘпјҢеҪ“然еҰӮжһңжғіи®°еҪ•иҫ“еҮәж—Ҙеҝ—еҸҜд»Ҙдҝ®ж”№иҫ“еҮәзӣ®ж ҮпјҢеҰӮпјҡ
(scrapyd > ~/scrapyd.log &)еҲҷдјҡиҫ“еҮә Scrapyd иҝҗиЎҢиҫ“еҮәеҲ° ~/scrapyd.log ж–Ү件дёӯгҖӮ
иҝҗиЎҢд№ӢеҗҺдҫҝеҸҜд»ҘеңЁжөҸи§ҲеҷЁзҡ„ 6800 и®ҝй—® WebUI дәҶпјҢеҸҜд»Ҙз®Җз•ҘзңӢеҲ°еҪ“еүҚ Scrapyd зҡ„иҝҗиЎҢ JobгҖҒLog зӯүеҶ…е®№пјҢеҰӮеӣҫ 1-86 жүҖзӨәпјҡ
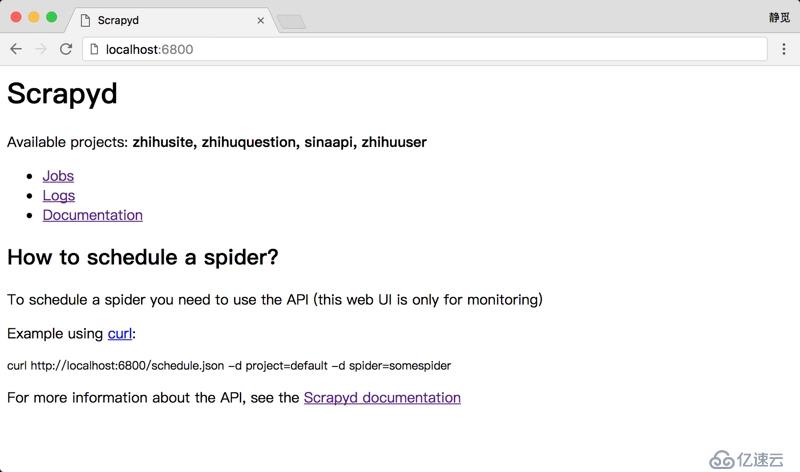
еӣҫ 1-86 Scrapyd йҰ–йЎө
еҪ“然иҝҗиЎҢ Scrapyd жӣҙдҪізҡ„ж–№ејҸжҳҜдҪҝз”Ё Supervisor е®ҲжҠӨиҝӣзЁӢиҝҗиЎҢпјҢеҰӮжһңж„ҹе…ҙи¶ЈеҸҜд»ҘеҸӮиҖғпјҡhttp://supervisord.org/гҖӮ
еҸҰеӨ– Scrapyd д№ҹж”ҜжҢҒ DockerпјҢеңЁеҗҺж–ҮжҲ‘们дјҡд»Ӣз»Қ Scrapyd Docker й•ңеғҸзҡ„еҲ¶дҪңе’ҢиҝҗиЎҢж–№жі•гҖӮ
йҷҗеҲ¶й…ҚзҪ®е®ҢжҲҗд№ӢеҗҺ Scrapyd е’Ңе®ғзҡ„жҺҘеҸЈйғҪжҳҜеҸҜд»Ҙе…¬ејҖи®ҝй—®зҡ„пјҢеҰӮжһңиҰҒжғій…ҚзҪ®и®ҝй—®и®ӨиҜҒзҡ„иҜқеҸҜд»ҘеҖҹеҠ©дәҺ Nginx еҒҡеҸҚеҗ‘д»ЈзҗҶпјҢеңЁиҝҷйҮҢйңҖиҰҒе…Ҳе®үиЈ… Nginx жңҚеҠЎеҷЁгҖӮ
еңЁжӯӨд»Ҙ Ubuntu дёәдҫӢиҝӣиЎҢиҜҙжҳҺпјҢе®үиЈ…е‘Ҫд»ӨеҰӮдёӢпјҡ
sudo apt-get install nginx然еҗҺдҝ®ж”№ Nginx зҡ„й…ҚзҪ®ж–Ү件 nginx.confпјҢеўһеҠ еҰӮдёӢй…ҚзҪ®пјҡ
http {
server {
listen 6801;
location / {
proxy_pass http://127.0.0.1:6800/;
auth_basic "Restricted";
auth_basic_user_file /etc/nginx/conf.d/.htpasswd;
}
}
}еңЁиҝҷйҮҢдҪҝз”Ёзҡ„з”ЁжҲ·еҗҚеҜҶз Ғй…ҚзҪ®ж”ҫзҪ®еңЁ /etc/nginx/conf.d зӣ®еҪ•пјҢжҲ‘们йңҖиҰҒдҪҝз”Ё htpasswd е‘Ҫд»ӨеҲӣе»әпјҢдҫӢеҰӮеҲӣе»әдёҖдёӘз”ЁжҲ·еҗҚдёә admin зҡ„ж–Ү件пјҢе‘Ҫд»ӨеҰӮдёӢпјҡ
htpasswd -c .htpasswd adminжҺҘдёӢе°ұдјҡжҸҗзӨәжҲ‘们иҫ“е…ҘеҜҶз ҒпјҢиҫ“е…ҘдёӨж¬Ўд№ӢеҗҺпјҢе°ұдјҡз”ҹжҲҗеҜҶз Ғж–Ү件пјҢжҹҘзңӢдёҖдёӢеҶ…е®№пјҡ
cat .htpasswd
admin:5ZBxQr0rCqwbcй…ҚзҪ®е®ҢжҲҗд№ӢеҗҺжҲ‘们йҮҚеҗҜдёҖдёӢ Nginx жңҚеҠЎпјҢиҝҗиЎҢеҰӮдёӢе‘Ҫд»Өпјҡ
sudo nginx -s reload
Pythonиө„жәҗеҲҶдә«qun 784758214 ,еҶ…жңүе®үиЈ…еҢ…пјҢPDFпјҢеӯҰд№ и§Ҷйў‘пјҢиҝҷйҮҢжҳҜPythonеӯҰд№ иҖ…зҡ„иҒҡйӣҶең°пјҢйӣ¶еҹәзЎҖпјҢиҝӣйҳ¶пјҢйғҪж¬ўиҝҺиҝҷж ·е°ұжҲҗеҠҹй…ҚзҪ®дәҶ Scrapyd зҡ„и®ҝй—®и®ӨиҜҒдәҶгҖӮ
жң¬иҠӮд»Ӣз»ҚдәҶ Scrapyd зҡ„е®үиЈ…ж–№жі•пјҢеңЁеҗҺж–ҮжҲ‘们дјҡиҜҰз»ҶдәҶи§ЈеҲ° Scrapy йЎ№зӣ®зҡ„йғЁзҪІеҸҠйЎ№зӣ®иҝҗиЎҢзҠ¶жҖҒзӣ‘жҺ§ж–№жі•гҖӮ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ