您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
如何在pandas中使用Series类型?针对这个问题,这篇文章详细介绍了相对应的分析和解答,希望可以帮助更多想解决这个问题的小伙伴找到更简单易行的方法。
线性的数据结构, series是一个一维数组
Pandas 会默然用0到n-1来作为series的index, 但也可以自己指定index( 可以把index理解为dict里面的key )
import pandas as pd import numpy as np s = pd.Series([9, 'zheng', 'beijing', 128]) print(s)
打印
0 9
1 zheng
2 beijing
3 128
dtype: object
访问其中某个数据
print(s[1:2]) # 打印 1 zheng dtype: object
Series类型的基本操作:
Series类型包括index和values两部分
In [14]: a = pd.Series({'a':1,'b':5})
In [15]: a.index
Out[15]: Index(['a', 'b'], dtype='object')
In [16]: a.values #返回一个多维数组numpy对象
Out[16]: array([1, 5], dtype=int64)Series类型的操作类似ndarray类型
#自动索引和自定义索引并存,但不能混用 In [17]: a[0] #自动索引 Out[17]: 1 #自定义索引 In [18]: a['a'] Out[18]: 1 #不能混用 In [20]: a[['a',1]] Out[20]: a 1.0 1 NaN dtype: float64
Series类型的操作类似Python字典类型
#通过自定义索引访问 #对索引保留字in操作,值不可以 In [21]: 'a' in a Out[21]: True In [22]: 1 in a Out[22]: False
Series类型在运算中会自动对齐不同索引的数据
In [29]: a = pd.Series([1,3,5],index = ['a','b','c']) In [30]: b = pd.Series([2,4,5,6],index = ['c,','d','e','b']) In [31]: a+b Out[31]: a NaN b 9.0 c NaN c, NaN d NaN e NaN dtype: float64
Series对象可以随时修改并即刻生效
In [32]: a.index = ['c','d','e'] In [33]: a Out[33]: c 1 d 3 e 5 dtype: int64 In [34]: a+b Out[34]: b NaN c NaN c, NaN d 7.0 e 10.0 dtype: float64
import pandas as pd import numpy as np s = pd.Series([9, 'zheng', 'beijing', 128, 'usa', 990], index=[1,2,3,'e','f','g']) print(s)
打印
1 9
2 zheng
3 beijing
e 128
f usa
g 990
dtype: object
根据索引找出值
print(s['f']) # usa
import pandas as pd
import numpy as np
s = {"ton": 20, "mary": 18, "jack": 19, "car": None}
sa = pd.Series(s, name="age")
print(sa)打印
car NaN
jack 19.0
mary 18.0
ton 20.0
Name: age, dtype: float64
检测类型
print(type(sa)) # <class 'pandas.core.series.Series'>
生成一个随机数
import pandas as pd
import numpy as np
num_abc = pd.Series(np.random.randn(5), index=list('abcde'))
num = pd.Series(np.random.randn(5))
print(num)
print(num_abc)
# 打印
0 -0.102860
1 -1.138242
2 1.408063
3 -0.893559
4 1.378845
dtype: float64
a -0.658398
b 1.568236
c 0.535451
d 0.103117
e -1.556231
dtype: float64import pandas as pd import numpy as np s = pd.Series([9, 'zheng', 'beijing', 128, 'usa', 990], index=[1,2,3,'e','f','g']) print(s[1:3]) # 选择第1到3个, 包左不包右 zheng beijing print(s[[1,3]]) # 选择第1个和第3个, zheng 128 print(s[:-1]) # 选择第1个到倒数第1个, 9 zheng beijing 128 usa
import pandas as pd import numpy as np s = pd.Series([9, 'zheng', 'beijing', 128, 'usa', 990], index=[1,2,3,'e','f','g']) sum = s[1:3] + s[1:3] sum1 = s[1:4] + s[1:4] sum2 = s[1:3] + s[1:4] sum3 = s[:3] + s[1:] print(sum) print(sum1) print(sum2) print(sum3)
打印
2 zhengzheng
3 beijingbeijing
dtype: object
2 zhengzheng
3 beijingbeijing
e 256
dtype: object
2 zhengzheng
3 beijingbeijing
e NaN
dtype: object
1 NaN
2 zhengzheng
3 beijingbeijing
e NaN
f NaN
g NaN
dtype: object
是否存在
USA in s # true
范围查找
import pandas as pd
import numpy as np
s = {"ton": 20, "mary": 18, "jack": 19, "jim": 22, "lj": 24, "car": None}
sa = pd.Series(s, name="age")
print(sa[sa>19])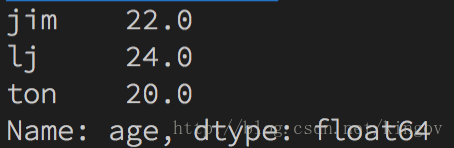
中位数
import pandas as pd
import numpy as np
s = {"ton": 20, "mary": 18, "jack": 19, "jim": 22, "lj": 24, "car": None}
sa = pd.Series(s, name="age")
print(sa.median()) # 20判断是否大于中位数
import pandas as pd
import numpy as np
s = {"ton": 20, "mary": 18, "jack": 19, "jim": 22, "lj": 24, "car": None}
sa = pd.Series(s, name="age")
print(sa>sa.median())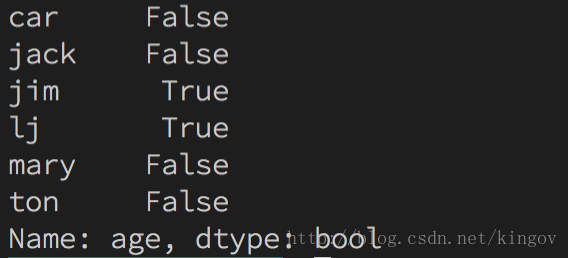
找出大于中位数的数
import pandas as pd
import numpy as np
s = {"ton": 20, "mary": 18, "jack": 19, "jim": 22, "lj": 24, "car": None}
sa = pd.Series(s, name="age")
print(sa[sa > sa.median()])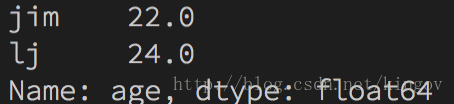
中位数
import pandas as pd
import numpy as np
s = {"ton": 20, "mary": 18, "jack": 19, "jim": 22, "lj": 24, "car": None}
sa = pd.Series(s, name="age")
more_than_midian = sa>sa.median()
print(more_than_midian)
print('---------------------')
print(sa[more_than_midian])
import pandas as pd
import numpy as np
s = {"ton": 20, "mary": 18, "jack": 19, "jim": 22, "lj": 24, "car": None}
sa = pd.Series(s, name="age")
print(s)
print('----------------')
sa['ton'] = 99
print(sa)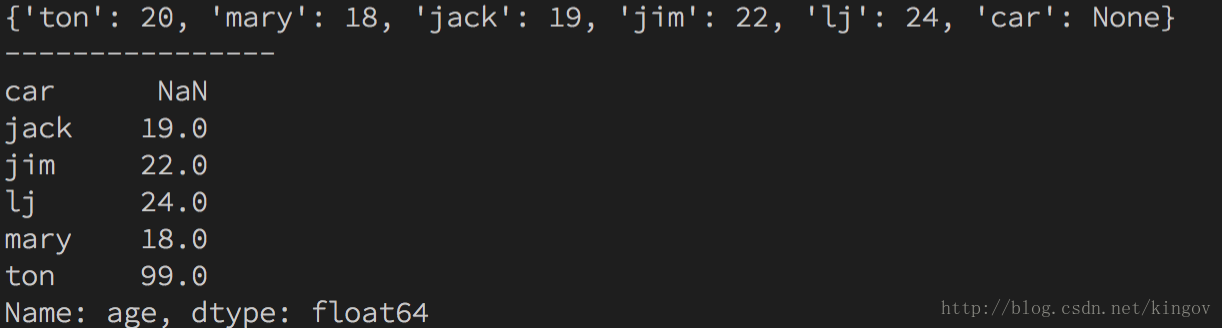
import pandas as pd
import numpy as np
s = {"ton": 20, "mary": 18, "jack": 19, "jim": 22, "lj": 24, "car": None}
sa = pd.Series(s, name="age")
print(s) # 打印原字典
print('---------------------') # 分割线
sa[sa>19] = 88 # 将所有大于19的同一改为88
print(sa) # 打印更改之后的数据
print('---------------------') # 分割线
print(sa / 2) # 将所有数据除以2
关于如何在pandas中使用Series类型问题的解答就分享到这里了,希望以上内容可以对大家有一定的帮助,如果你还有很多疑惑没有解开,可以关注亿速云行业资讯频道了解更多相关知识。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。