您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
这篇文章主要介绍了pytorch动态神经网络的实现方法,具有一定借鉴价值,感兴趣的朋友可以参考下,希望大家阅读完这篇文章之后大有收获,下面让小编带着大家一起了解一下。
(1)首先要建立数据集
import torch #引用torch模块 import matplotlib.pyplot as plt #引用画图模块 x=torch.unsqueeze(torch.linspace(-1,1,100),dim=1)#产生(-1,1)的100个点横坐标,dim表示维度,表示在这里增加第二维 y=x.pow(2)+0.2*torch.rand(x,size()) #0.2*torch.rand(x,size())是为了产生噪点使数据更加真实
(2)建立神经网络
import torch imoort torch.nn.functional as F #激励函数在这个模块里 class Net (torch.nn.Module): #Net要继承torch中Module (1)首先有定义(建立)神经网络层 def __init__(self,n_feature,n_hidden,n_output): #__init__表示初始化数据 super(Net,self).__init__()#Net的对象self转换为类nn.module的对象,然后在用nn.Module的方法使用__init__初始化。 self.hidden=torch.nn.Linear(n_feature,n_hidden) #建立隐藏层线性输出 self.predict=torch.nn.Linear(n_hidden,n_output) #建立输出层线性输出
(2)建立层与层之间的关系
def forward (self,x): # 这同时也是 Module 中的 forward 功能 x=F.relu(self,hidden(x)) #使用激励函数把数据激活 return x #输出数据 net=Net(n_feature=1,n_hidden=10,n_output=1) #一个隐藏层有10节点,输出层有1节点,输出数数据为一个
(3)训练网络
optimizer=torch.optim.SGD(net.parameter().lr=0.2)#传入 net 的所有参数, lr代表学习率,optimizer是训练工具 loss_func=torch.nn.MSELoss()#预测值和真实值的误差计算公式 (均方差) for t in range(100): prediction = net(x) # 喂给 net 训练数据 x, 输出预测值 loss = loss_func(prediction, y) # 计算两者的误差 optimizer.zero_grad() # 清空上一步的残余更新参数值 loss.backward() # 误差反向传播, 计算参数更新值 optimizer.step() # 将参数更新值施加到 net 的 parameters 上
(四)可视化训练
import matplotlib.pyplot as plt
plt.ion() # 画图
plt.show()
for t in range(200):
...
loss.backward()
optimizer.step()
# 接着上面来
if t % 5 == 0:
# plot and show learning process
plt.cla()
plt.scatter(x.data.numpy(), y.data.numpy())
plt.plot(x.data.numpy(), prediction.data.numpy(), 'r-', lw=5)
plt.text(0.5, 0, 'Loss=%.4f' % loss.data.numpy(), fontdict={'size': 20, 'color': 'red'})
plt.pause(0.1)会得到如下图像:
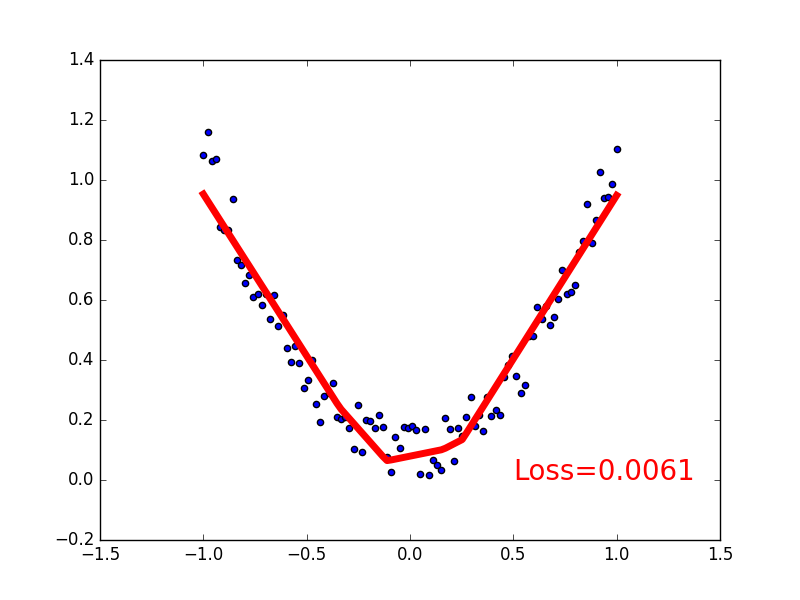
整体代码如下:
import torch
import matplotlib.pyplot as plt
x=torch.unsqueeze(torch.linspace(-2,2,100),dim=1)
y=x.pow(2)+0.2*torch.rand(x.size())
import torch
import torch.nn.functional as F
class Net(torch.nn.Module):
def __init__(self,n_feature,n_hidden,n_output):
super(Net,self).__init__()
self.hidden=torch.nn.Linear(n_feature,n_hidden)
self.predict=torch.nn.Linear(n_hidden,n_output)
def forward(self,x):
x=F.relu(self.hidden(x))
x=self.predict(x)
return x
net=Net(n_feature=1,n_hidden=10,n_output=1)
optimizer=torch.optim.SGD(net.parameters(),lr=0.3)
loss_func=torch.nn.MSELoss()
plt.ion()
plt.show()
for t in range(100):
prediction=net(x)
loss=loss_func(prediction,y)
optimizer.zero_grad()
loss.backward()
optimizer.step()
if t % 5 == 0:
plt.cla()
plt.scatter(x.data.numpy(), y.data.numpy())
plt.plot(x.data.numpy(), prediction.data.numpy(), 'r-', lw=5)
plt.text(0.5, 0, 'Loss=%.4f' % loss.data.numpy(), fontdict={'size': 20, 'color': 'red'})
plt.pause(0.1)感谢你能够认真阅读完这篇文章,希望小编分享的“pytorch动态神经网络的实现方法”这篇文章对大家有帮助,同时也希望大家多多支持亿速云,关注亿速云行业资讯频道,更多相关知识等着你来学习!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。