您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
小编给大家分享一下使用Redis时必须注意的要点有哪些,相信大部分人都还不怎么了解,因此分享这篇文章给大家参考一下,希望大家阅读完这篇文章后大有收获,下面让我们一起去了解一下吧!
1、Redis的使用规范
1.1、 key的规范要点
我们设计Redis的key的时候,要注意以下这几个点:
以业务名为key前缀,用冒号隔开,以防止key冲突覆盖。如,live:rank:1
确保key的语义清晰的情况下,key的长度尽量小于30个字符。
key禁止包含特殊字符,如空格、换行、单双引号以及其他转义字符。
Redis的key尽量设置ttl,以保证不使用的Key能被及时清理或淘汰。
1.2、value的规范要点
Redis的value值不可以随意设置的哦。
第一点,如果大量存储bigKey是会有问题的,会导致慢查询,内存增长过快等等。
如果是String类型,单个value大小控制10k以内。
如果是hash、list、set、zset类型,元素个数一般不超过5000。
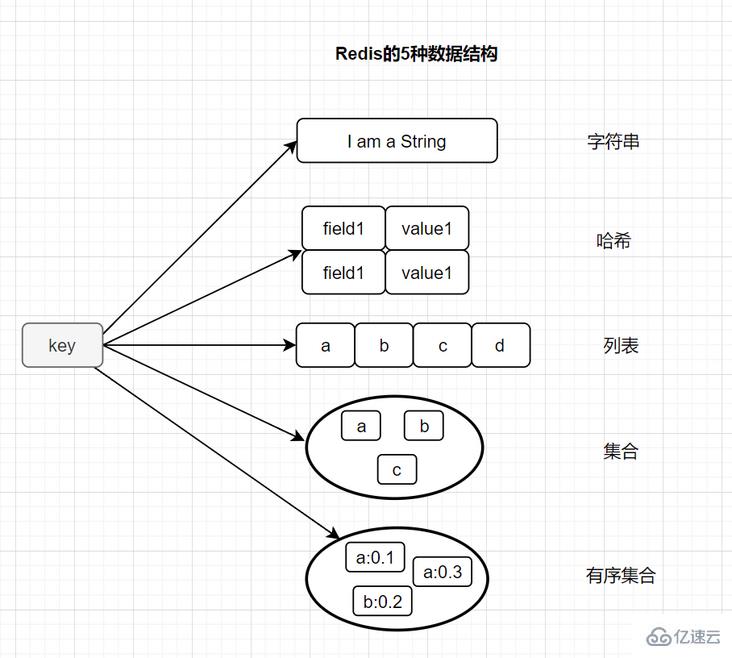
第二点,要选择适合的数据类型。不少小伙伴只用Redis的String类型,上来就是set和get。实际上,Redis 提供了丰富的数据结构类型,有些业务场景,更适合hash、zset等其他数据结果。
反例:
set user:666:name jay set user:666:age 18
正例
hmset user:666 name jay age 18
1.3. 给Key设置过期时间,同时注意不同业务的key,尽量过期时间分散一点
因为Redis的数据是存在内存中的,而内存资源是很宝贵的。
我们一般是把Redis当做缓存来用,而不是数据库,所以key的生命周期就不宜太长久啦。
因此,你的key,一般建议用expire设置过期时间。
如果大量的key在某个时间点集中过期,到过期的那个时间点,Redis可能会存在卡顿,甚至出现缓存雪崩现象,因此一般不同业务的key,过期时间应该分散一些。有时候,同业务的,也可以在时间上加一个随机值,让过期时间分散一些。
1.4.建议使用批量操作提高效率
我们日常写SQL的时候,都知道,批量操作效率会更高,一次更新50条,比循环50次,每次更新一条效率更高。其实Redis操作命令也是这个道理。
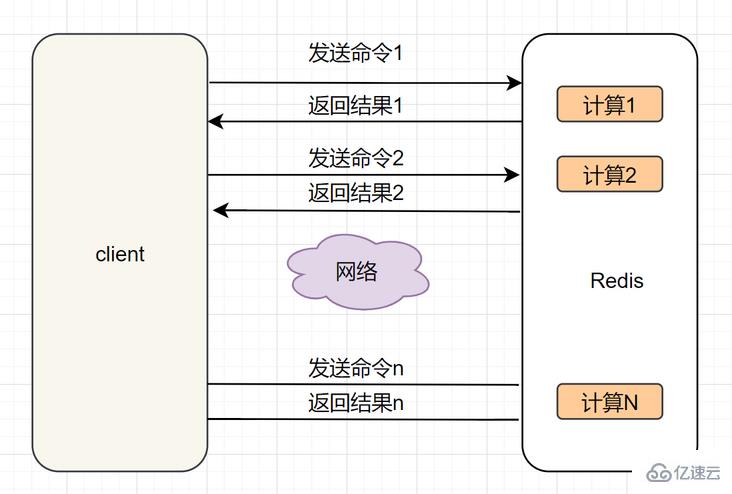
Redis客户端执行一次命令可分为4个过程:1.发送命令-> 2.命令排队-> 3.命令执行-> 4. 返回结果。1和4 称为RRT(命令执行往返时间)。 Redis提供了批量操作命令,如mget、mset等,可有效节约RRT。但是呢,大部分的命令,是不支持批量操作的,比如hgetall,并没有mhgetall存在。Pipeline 则可以解决这个问题。
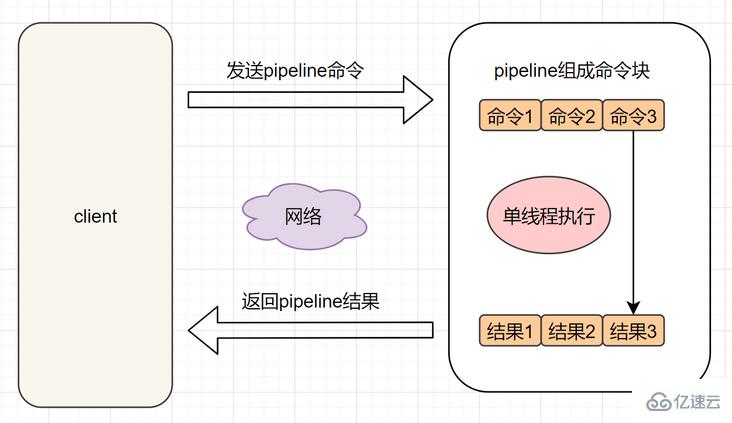
Pipeline是什么呢?它能将一组Redis命令进行组装,通过一次RTT传输给Redis,再将这组Redis命令的执行结果按顺序返回给客户端.
我们先来看下没有使用Pipeline执行了n条命令的模型:
使用Pipeline执行了n次命令,整个过程需要1次RTT,模型如下:
2、Redis 有坑的那些命令
2.1. 慎用O(n)复杂度命令,如hgetall、smember,lrange等
因为Redis是单线程执行命令的。hgetall、smember等命令时间复杂度为O(n),当n持续增加时,会导致 Redis CPU 持续飙高,阻塞其他命令的执行。
hgetall、smember,lrange等这些命令不是一定不能使用,需要综合评估数据量,明确n的值,再去决定。 比如hgetall,如果哈希元素n比较多的话,可以优先考虑使用hscan。
2.2 慎用Redis的monitor命令
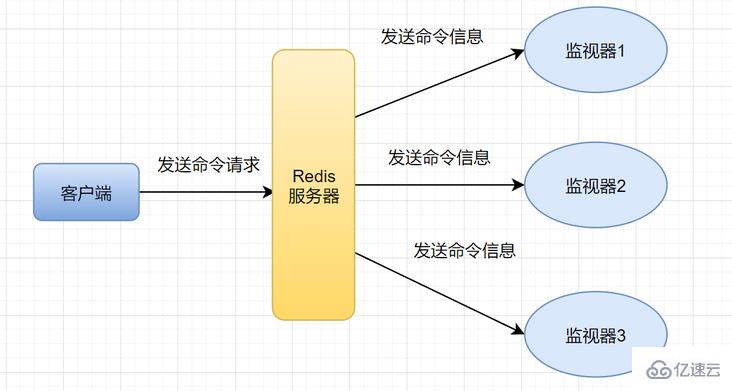
Redis Monitor 命令用于实时打印出Redis服务器接收到的命令,如果我们想知道客户端对redis服务端做了哪些命令操作,就可以用Monitor 命令查看,但是它一般调试用而已,尽量不要在生产上用!因为monitor命令可能导致redis的内存持续飙升。
monitor的模型是酱紫的,它会将所有在Redis服务器执行的命令进行输出,一般来讲Redis服务器的QPS是很高的,也就是如果执行了monitor命令,Redis服务器在Monitor这个客户端的输出缓冲区又会有大量“存货”,也就占用了大量Redis内存。
2.3、生产环境不能使用 keys指令
Redis Keys 命令用于查找所有符合给定模式pattern的key。如果想查看Redis 某类型的key有多少个,不少小伙伴想到用keys命令,如下:
keys key前缀*
但是,redis的keys是遍历匹配的,复杂度是O(n),数据库数据越多就越慢。我们知道,redis是单线程的,如果数据比较多的话,keys指令就会导致redis线程阻塞,线上服务也会停顿了,直到指令执行完,服务才会恢复。因此,一般在生产环境,不要使用keys指令。官方文档也有声明:
Warning: consider KEYS as a command that should only be used in production environments with extreme care. It may ruin performance when it is executed against large databases. This command is intended for debugging and special operations, such as changing your keyspace layout. Don't use KEYS in your regular application code. If you're looking for a way to find keys in a subset of your keyspace, consider using sets.
其实,可以使用scan指令,它同keys命令一样提供模式匹配功能。它的复杂度也是 O(n),但是它通过游标分步进行,不会阻塞redis线程;但是会有一定的重复概率,需要在客户端做一次去重。
scan支持增量式迭代命令,增量式迭代命令也是有缺点的:举个例子, 使用 SMEMBERS 命令可以返回集合键当前包含的所有元素, 但是对于 SCAN 这类增量式迭代命令来说, 因为在对键进行增量式迭代的过程中, 键可能会被修改, 所以增量式迭代命令只能对被返回的元素提供有限的保证 。
2.4 禁止使用flushall、flushdb
Flushall 命令用于清空整个 Redis 服务器的数据(删除所有数据库的所有 key )。
Flushdb 命令用于清空当前数据库中的所有 key。
这两命令是原子性的,不会终止执行。一旦开始执行,不会执行失败的。
2.5 注意使用del命令
删除key你一般使用什么命令?是直接del?如果删除一个key,直接使用del命令当然没问题。但是,你想过del的时间复杂度是多少嘛?我们分情况探讨一下:
如果删除一个String类型的key,时间复杂度就是O(1),可以直接del。
如果删除一个List/Hash/Set/ZSet类型时,它的复杂度是O(n), n表示元素个数。
因此,如果你删除一个List/Hash/Set/ZSet类型的key时,元素越多,就越慢。当n很大时,要尤其注意,会阻塞主线程的。那么,如果不用del,我们应该怎么删除呢?
如果是List类型,你可以执行
lpop或者rpop,直到所有元素删除完成。如果是Hash/Set/ZSet类型,你可以先执行
hscan/sscan/scan查询,再执行hdel/srem/zrem依次删除每个元素。
2.6 避免使用SORT、SINTER等复杂度过高的命令。
执行复杂度较高的命令,会消耗更多的 CPU 资源,会阻塞主线程。所以你要避免执行如SORT、SINTER、SINTERSTORE、ZUNIONSTORE、ZINTERSTORE等聚合命令,一般建议把它放到客户端来执行。
3、项目实战避坑操作
3.1 分布式锁使用的注意点
分布式锁其实就是,控制分布式系统不同进程共同访问共享资源的一种锁的实现。秒杀下单、抢红包等等业务场景,都需要用到分布式锁。我们经常使用Redis作为分布式锁,主要有这些注意点:
3.1.1 两个命令SETNX + EXPIRE分开写(典型错误实现范例)
if(jedis.setnx(key_resource_id,lock_value) == 1){ //加锁
expire(key_resource_id,100); //设置过期时间
try {
do something //业务请求
}catch(){
}
finally {
jedis.del(key_resource_id); //释放锁
}
}如果执行完setnx加锁,正要执行expire设置过期时间时,进程crash或者要重启维护了,那么这个锁就“长生不老”了,别的线程永远获取不到锁啦,所以一般分布式锁不能这么实现。
3.1.2 SETNX + value值是过期时间 (有些小伙伴是这么实现,有坑)
long expires = System.currentTimeMillis() + expireTime; //系统时间+设置的过期时间
String expiresStr = String.valueOf(expires);
// 如果当前锁不存在,返回加锁成功
if (jedis.setnx(key_resource_id, expiresStr) == 1) {
return true;
}
// 如果锁已经存在,获取锁的过期时间
String currentValueStr = jedis.get(key_resource_id);
// 如果获取到的过期时间,小于系统当前时间,表示已经过期
if (currentValueStr != null && Long.parseLong(currentValueStr) < System.currentTimeMillis()) {
// 锁已过期,获取上一个锁的过期时间,并设置现在锁的过期时间(不了解redis的getSet命令的小伙伴,可以去官网看下哈)
String oldValueStr = jedis.getSet(key_resource_id, expiresStr);
if (oldValueStr != null && oldValueStr.equals(currentValueStr)) {
// 考虑多线程并发的情况,只有一个线程的设置值和当前值相同,它才可以加锁
return true;
}
}
//其他情况,均返回加锁失败
return false;
}这种方案的缺点:
过期时间是客户端自己生成的,分布式环境下,每个客户端的时间必须同步
没有保存持有者的唯一标识,可能被别的客户端释放/解锁。
锁过期的时候,并发多个客户端同时请求过来,都执行了
jedis.getSet(),最终只能有一个客户端加锁成功,但是该客户端锁的过期时间,可能被别的客户端覆盖。
3.1.3: SET的扩展命令(SET EX PX NX)(注意可能存在的问题)
if(jedis.set(key_resource_id, lock_value, "NX", "EX", 100s) == 1){ //加锁
try {
do something //业务处理
}catch(){
}
finally {
jedis.del(key_resource_id); //释放锁
}
}这个方案还是可能存在问题:
锁过期释放了,业务还没执行完。
锁被别的线程误删。
3.1.4 SET EX PX NX + 校验唯一随机值,再删除(解决了误删问题,还是存在锁过期,业务没执行完的问题)
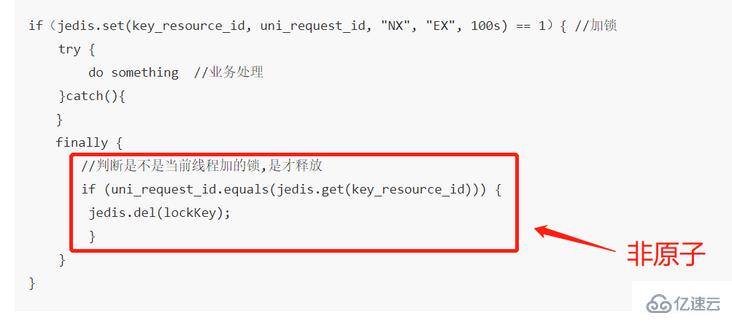
if(jedis.set(key_resource_id, uni_request_id, "NX", "EX", 100s) == 1){ //加锁
try {
do something //业务处理
}catch(){
}
finally {
//判断是不是当前线程加的锁,是才释放
if (uni_request_id.equals(jedis.get(key_resource_id))) {
jedis.del(lockKey); //释放锁
}
}
}在这里,判断是不是当前线程加的锁和释放锁不是一个原子操作。如果调用jedis.del()释放锁的时候,可能这把锁已经不属于当前客户端,会解除他人加的锁。
一般也是用lua脚本代替。lua脚本如下:
if redis.call('get',KEYS[1]) == ARGV[1] then
return redis.call('del',KEYS[1])
else
return 0
end;3.1.5 Redisson框架 + Redlock算法 解决锁过期释放,业务没执行完问题+单机问题
Redisson 使用了一个Watch dog解决了锁过期释放,业务没执行完问题,Redisson原理图如下:
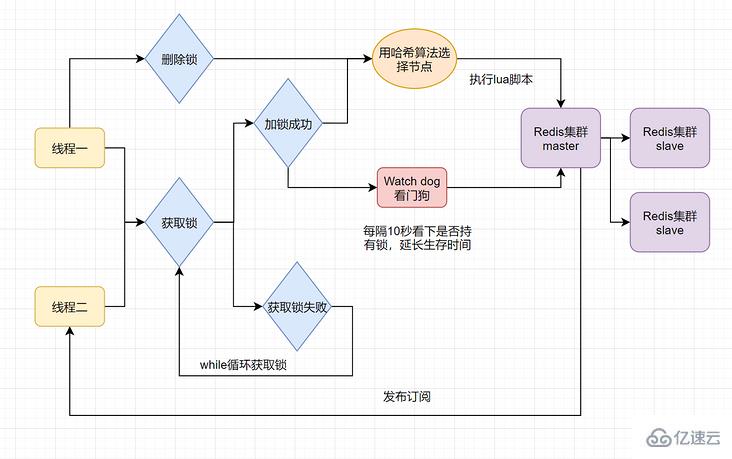
以上的分布式锁,还存在单机问题:
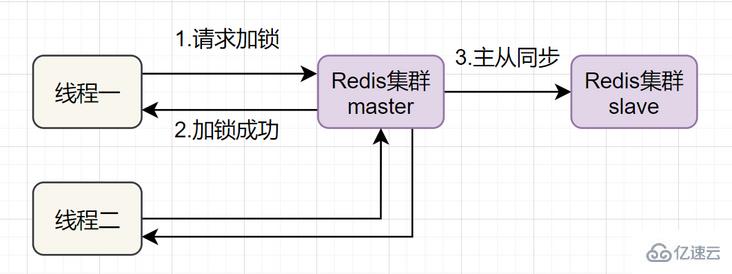
如果线程一在Redis的master节点上拿到了锁,但是加锁的key还没同步到slave节点。恰好这时,master节点发生故障,一个slave节点就会升级为master节点。线程二就可以获取同个key的锁啦,但线程一也已经拿到锁了,锁的安全性就没了。
针对单机问题,可以使用Redlock算法。有兴趣的朋友可以看下我这篇文章哈,七种方案!探讨Redis分布式锁的正确使用姿势
3.2 缓存一致性注意点
如果是读请求,先读缓存,后读数据库
如果写请求,先更新数据库,再写缓存
每次更新数据后,需要清除缓存
缓存一般都需要设置一定的过期失效
一致性要求高的话,可以使用biglog+MQ保证。
有兴趣的朋友,可以看下我这篇文章哈:并发环境下,先操作数据库还是先操作缓存?
3.3 合理评估Redis容量,避免由于频繁set覆盖,导致之前设置的过期时间无效。
我们知道,Redis的所有数据结构类型,都是可以设置过期时间的。假设一个字符串,已经设置了过期时间,你再去重新设置它,就会导致之前的过期时间无效。

Redis setKey源码如下:
void setKey(redisDb *db,robj *key,robj *val) {
if(lookupKeyWrite(db,key)==NULL) {
dbAdd(db,key,val);
}else{
dbOverwrite(db,key,val);
}
incrRefCount(val);
removeExpire(db,key); //去掉过期时间
signalModifiedKey(db,key);
}实际业务开发中,同时我们要合理评估Redis的容量,避免频繁set覆盖,导致设置了过期时间的key失效。新手小白容易犯这个错误。
3.4 缓存穿透问题
先来看一个常见的缓存使用方式:读请求来了,先查下缓存,缓存有值命中,就直接返回;缓存没命中,就去查数据库,然后把数据库的值更新到缓存,再返回。
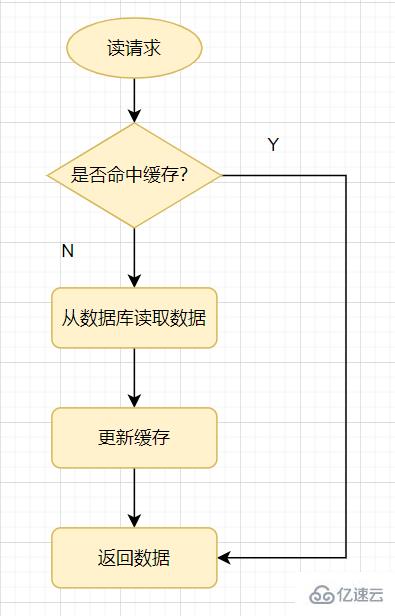
缓存穿透:指查询一个一定不存在的数据,由于缓存是不命中时需要从数据库查询,查不到数据则不写入缓存,这将导致这个不存在的数据每次请求都要到数据库去查询,进而给数据库带来压力。
通俗点说,读请求访问时,缓存和数据库都没有某个值,这样就会导致每次对这个值的查询请求都会穿透到数据库,这就是缓存穿透。
缓存穿透一般都是这几种情况产生的:
业务不合理的设计,比如大多数用户都没开守护,但是你的每个请求都去缓存,查询某个userid查询有没有守护。
业务/运维/开发失误的操作,比如缓存和数据库的数据都被误删除了。
黑客非法请求攻击,比如黑客故意捏造大量非法请求,以读取不存在的业务数据。
如何避免缓存穿透呢? 一般有三种方法。
如果是非法请求,我们在API入口,对参数进行校验,过滤非法值。
如果查询数据库为空,我们可以给缓存设置个空值,或者默认值。但是如有有写请求进来的话,需要更新缓存哈,以保证缓存一致性,同时,最后给缓存设置适当的过期时间。(业务上比较常用,简单有效)
使用布隆过滤器快速判断数据是否存在。即一个查询请求过来时,先通过布隆过滤器判断值是否存在,存在才继续往下查。
布隆过滤器原理:它由初始值为0的位图数组和N个哈希函数组成。一个对一个key进行N个hash算法获取N个值,在比特数组中将这N个值散列后设定为1,然后查的时候如果特定的这几个位置都为1,那么布隆过滤器判断该key存在。
3.5 缓存雪奔问题
缓存雪奔: 指缓存中数据大批量到过期时间,而查询数据量巨大,请求都直接访问数据库,引起数据库压力过大甚至down机。
缓存雪奔一般是由于大量数据同时过期造成的,对于这个原因,可通过均匀设置过期时间解决,即让过期时间相对离散一点。如采用一个较大固定值+一个较小的随机值,5小时+0到1800秒酱紫。
Redis 故障宕机也可能引起缓存雪奔。这就需要构造Redis高可用集群啦。
3.6 缓存击穿问题
缓存击穿: 指热点key在某个时间点过期的时候,而恰好在这个时间点对这个Key有大量的并发请求过来,从而大量的请求打到db。
缓存击穿看着有点像,其实它两区别是,缓存雪奔是指数据库压力过大甚至down机,缓存击穿只是大量并发请求到了DB数据库层面。可以认为击穿是缓存雪奔的一个子集吧。有些文章认为它俩区别,是区别在于击穿针对某一热点key缓存,雪奔则是很多key。
解决方案就有两种:
1.使用互斥锁方案。缓存失效时,不是立即去加载db数据,而是先使用某些带成功返回的原子操作命令,如(Redis的setnx)去操作,成功的时候,再去加载db数据库数据和设置缓存。否则就去重试获取缓存。
2. “永不过期”,是指没有设置过期时间,但是热点数据快要过期时,异步线程去更新和设置过期时间。
3.7、缓存热key问题
在Redis中,我们把访问频率高的key,称为热点key。如果某一热点key的请求到服务器主机时,由于请求量特别大,可能会导致主机资源不足,甚至宕机,从而影响正常的服务。
而热点Key是怎么产生的呢?主要原因有两个:
用户消费的数据远大于生产的数据,如秒杀、热点新闻等读多写少的场景。
请求分片集中,超过单Redi服务器的性能,比如固定名称key,Hash落入同一台服务器,瞬间访问量极大,超过机器瓶颈,产生热点Key问题。
那么在日常开发中,如何识别到热点key呢?
凭经验判断哪些是热Key;
客户端统计上报;
服务代理层上报
如何解决热key问题?
Redis集群扩容:增加分片副本,均衡读流量;
对热key进行hash散列,比如将一个key备份为key1,key2……keyN,同样的数据N个备份,N个备份分布到不同分片,访问时可随机访问N个备份中的一个,进一步分担读流量;
使用二级缓存,即JVM本地缓存,减少Redis的读请求。
4、Redis配置运维
4.1 使用长连接而不是短连接,并且合理配置客户端的连接池
如果使用短连接,每次都需要过 TCP 三次握手、四次挥手,会增加耗时。然而长连接的话,它建立一次连接,redis的命令就能一直使用,酱紫可以减少建立redis连接时间。
连接池可以实现在客户端建立多个连接并且不释放,需要使用连接的时候,不用每次都创建连接,节省了耗时。但是需要合理设置参数,长时间不操作 Redis时,也需及时释放连接资源。
4.2 只使用 db0
Redis-standalone架构禁止使用非db0.原因有两个
一个连接,Redis执行命令select 0和select 1切换,会损耗新能。
Redis Cluster 只支持 db0,要迁移的话,成本高
4.3 设置maxmemory + 恰当的淘汰策略。
为了防止内存积压膨胀。比如有些时候,业务量大起来了,redis的key被大量使用,内存直接不够了,运维小哥哥也忘记加大内存了。难道redis直接这样挂掉?所以需要根据实际业务,选好maxmemory-policy(最大内存淘汰策略),设置好过期时间。一共有8种内存淘汰策略:
volatile-lru:当内存不足以容纳新写入数据时,从设置了过期时间的key中使用LRU(最近最少使用)算法进行淘汰;
allkeys-lru:当内存不足以容纳新写入数据时,从所有key中使用LRU(最近最少使用)算法进行淘汰。
volatile-lfu:4.0版本新增,当内存不足以容纳新写入数据时,在过期的key中,使用LFU算法进行删除key。
allkeys-lfu:4.0版本新增,当内存不足以容纳新写入数据时,从所有key中使用LFU算法进行淘汰;
volatile-random:当内存不足以容纳新写入数据时,从设置了过期时间的key中,随机淘汰数据;。
allkeys-random:当内存不足以容纳新写入数据时,从所有key中随机淘汰数据。
volatile-ttl:当内存不足以容纳新写入数据时,在设置了过期时间的key中,根据过期时间进行淘汰,越早过期的优先被淘汰;
noeviction:默认策略,当内存不足以容纳新写入数据时,新写入操作会报错。
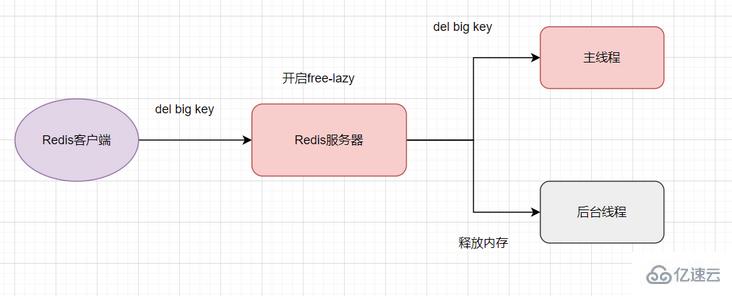
4.4 开启 lazy-free 机制
Redis4.0+版本支持lazy-free机制,如果你的Redis还是有bigKey这种玩意存在,建议把lazy-free开启。当开启它后,Redis 如果删除一个 bigkey 时,释放内存的耗时操作,会放到后台线程去执行,减少对主线程的阻塞影响。
以上是“使用Redis时必须注意的要点有哪些”这篇文章的所有内容,感谢各位的阅读!相信大家都有了一定的了解,希望分享的内容对大家有所帮助,如果还想学习更多知识,欢迎关注亿速云行业资讯频道!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。