您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
本篇文章给大家分享的是有关jupyter中读取错误格式文件如何解决,小编觉得挺实用的,因此分享给大家学习,希望大家阅读完这篇文章后可以有所收获,话不多说,跟着小编一起来看看吧。
使用pandas读取xml文件报错
“ Unsupported format, or corrupt file: Expected BOF record; found b'<?xml ve' ”
转换文件格式,使用excel打开xml文件 选择:文件—>另存为---->弹框
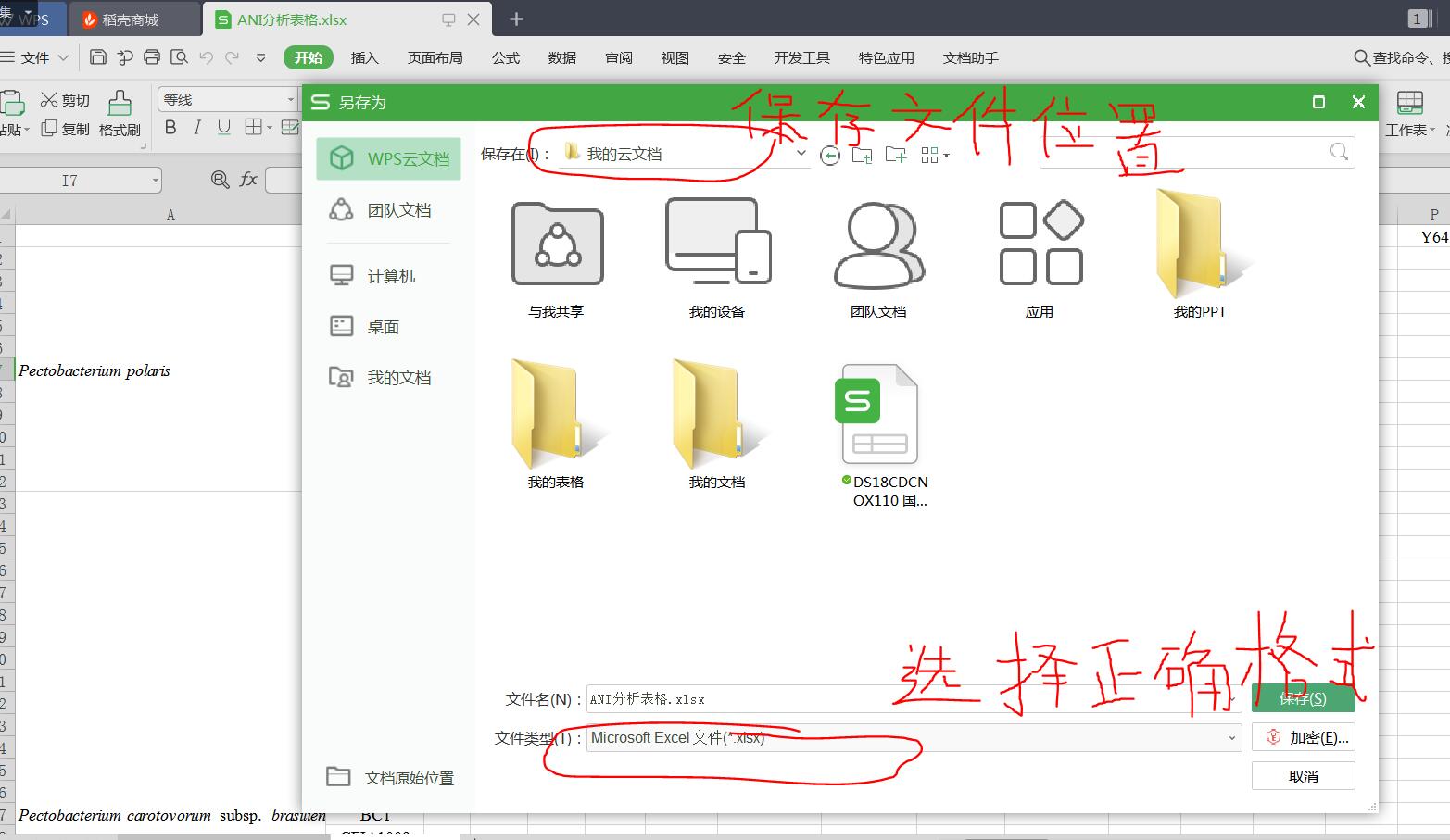
保存以后,再次用pandas读取对应格式的文件读取即可
补充:
在jupyter中读取CSV文件时出现‘utf-8' codec can't decode byte 0xd5 in position 0: invalid continuation byte解决方法
导入 import pandas as pd
使用pd.read_csv()读csv文件时,出现如下错误:
UnicodeDecodeError: ‘utf-8' codec can't decode byte 0xd5 in position 0: invalid continuation byte
CSV文件不是UTF-8进行编码,而是用gbk进行编码的。jupyter-notebook使用的Python解释器的系统编码默认使用UTF-8.
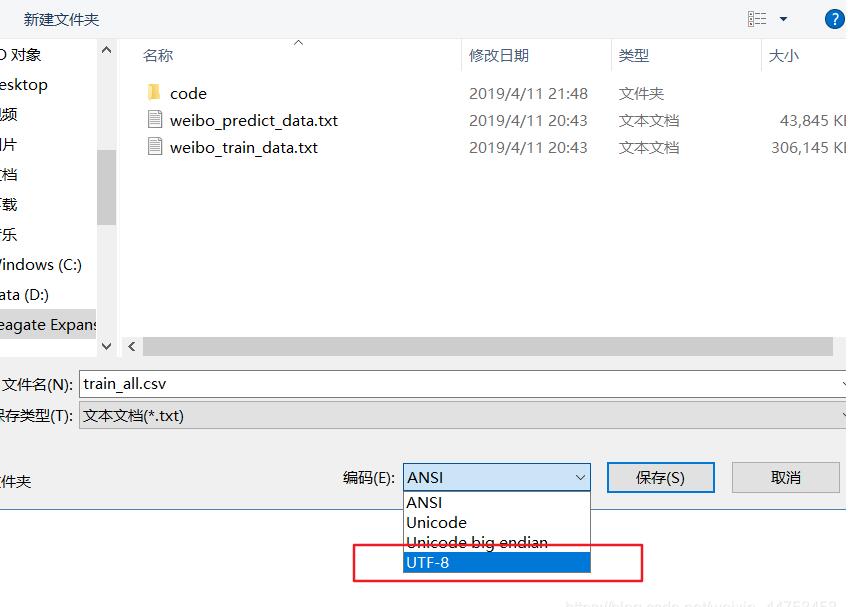
1.找到使用的csv文件--->鼠标右键--->打开方式---->选择记事本
2.打开文件选择“文件”----->"另存为“,我们可以看到默认编码是:ANSI,选择UTF-8重新保存一份,再使用pd.read_csv()打开就不会保存了

使用pd.read()读取CSV文件时,进行编码
pd.read(filename,encoding='gbk')
比如:

以上就是jupyter中读取错误格式文件如何解决,小编相信有部分知识点可能是我们日常工作会见到或用到的。希望你能通过这篇文章学到更多知识。更多详情敬请关注亿速云行业资讯频道。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。