您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
今天就跟大家聊聊有关怎么在Docker中部署一个Redis 6.x集群,可能很多人都不太了解,为了让大家更加了解,小编给大家总结了以下内容,希望大家根据这篇文章可以有所收获。
Redis 版本:6.0.8
Docker 版本:19.03.12
系统版本:CoreOS 7.8
内核版本:5.8.5-1.el7.elrepo.x86_64
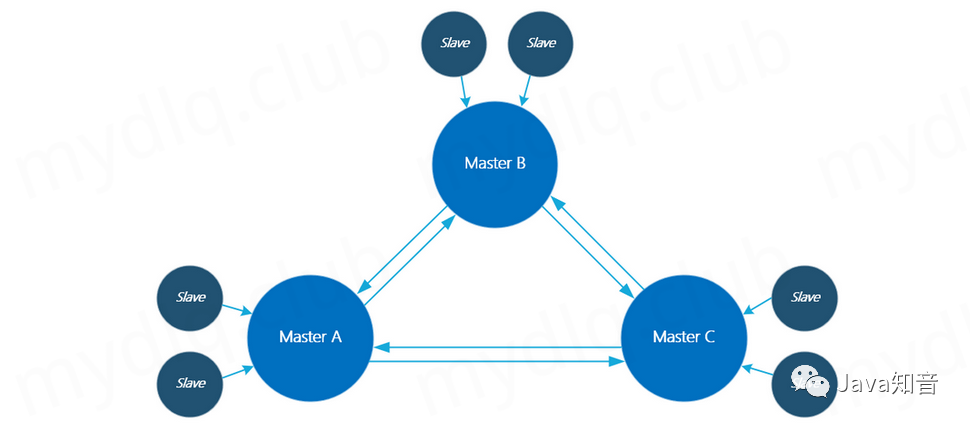
在 Redis 3.0 版本后正式推出 Redis 集群模式,该模式是 Redis 的分布式的解决方案,是一个提供在多个 Redis 节点间共享数据的程序集,且 Redis 集群是去中心化的,它的每个 Master 节点都可以进行读写数据,每个节点都拥有平等的关系,每个节点都保持各自的数据和整个集群的状态。
Redis 集群设计的主要目的是让 Redis 数据存储能够线性扩展,通过分区来提供一定程度的可用性,在实际环境中当某个节点宕机或者不可达的情况下其可以继续处理命令。但是,如果发生较大故障(例如,大多数主站不可用时)时集群会停止运行,即 redis 集群不能保证数据的强一致性。
高可用性: Redis 在集群模式下每个 Master 都是主从复制模式,其 Master 节点上的数据会实时同步到 Slave 节点上,当 Master 节点不可用时,其对应的 Slave 节点身份会更改为 Master 节点,保证集群的可用性。
数据横向扩展: Redis 是一个内存数据库,所有数据都存在内存中,在单节点中所在服务器能给与的内存是有一定限制。当数据量达到一定程度后,内存将不足以支撑这么多的数据存储,这时候需要将数据进行分片存储,而 Redis 集群模式就是将数据分片存储,非常方便横向扩展。
Redis 集群没有使用一致性 Hash, 而是引入了”哈希槽”的概念。Redis 集群有 16384 个哈希槽,每个 key 通过 CRC16 校验后对 16384 取模来决定放置哪个槽,集群的每个节点负责一部分 hash 槽。
举个例子,比如当前集群有3个节点,那么:
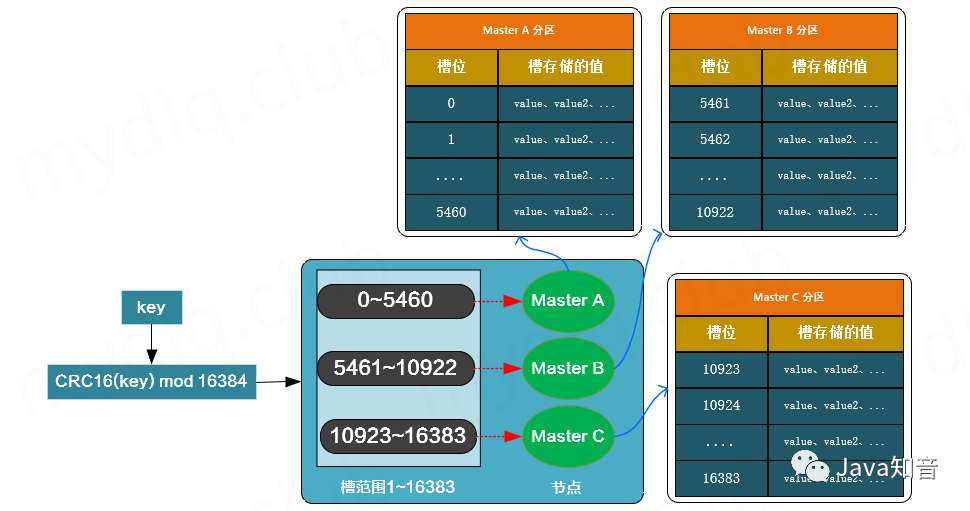
节点 A 包含 0 到 5460 号哈希槽;
节点 B 包含 5461 到 10922 号哈希槽;
节点 C 包含 10923 到 16383 号哈希槽;
这种结构很容易”添加”或者”删除”节点. 比如如果我想新添加个节点 D,我需要从节点 A, B, C 中得部分槽转移到节点 D 上, 如果我想移除节点 A,则需要将 A 中的槽移到 B 和 C 节点上,然后将没有任何槽的 A 节点从集群中移除即可。由于从一个节点将哈希槽移动到另一个节点并不会停止服务,所以无论添加删除或者改变某个节点的哈希槽的数量都不会造成集群不可用的状态。
Redis 支持多个 key 操作,只要这些 key 在一个单个命令中执行(或者一个事务,或者 Lua 脚本执行),那么它们就属于相同的 Hash 槽。你也可以用 hash tags 命令强制多个 key 都在相同的 hash 槽中。
集群中的主从模型
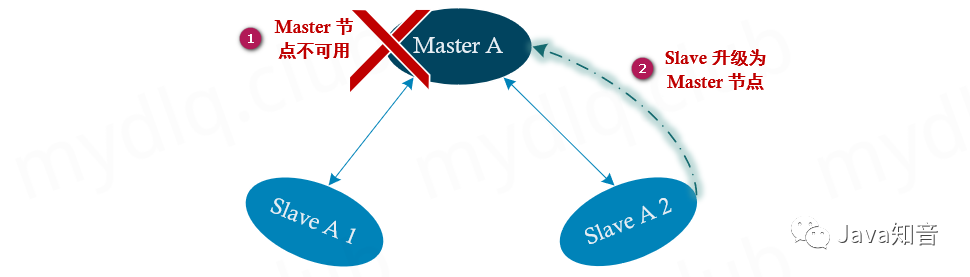
在 Redis 集群模式下,为了防止集群部分节点因宕机等情况造成不可用,故而 Redis 集群使用了主从复制模式。在该模式下要求 Redis 集群至少要存在六个节点,其中三个节点为主节点,能够对外提供读写。还有三个节点为从节点,会同步其对应的主节点的数据。当某个主节点出现问题不可用时,Redis 将通过选举算法从主节点对应的从节点中选择一个节点(主节点存在多个从节点的情况下),将其更改为一个新的主节点,且能够对外提供服务。
例如,在存在 A,B,C 三个主节点和其对应的 (A1、A2),(B1、B2),(C1、C2) 六个从节点,共九个节点中,如果节点 A 节点挂掉,那么其对应的从节点 A1、A2 节点将通过选举算法,选择其中一个节点提升为主节点,以确保集群能够正常服务。不过当 A1、A2 两个从节点或者或者半数以上主节点不可用时,那么集群也是不可用的。
在部署 Redis 集群模式时,至少需要六个节点组成集群才能保证集群的可用性。
(1)、全量复制与增量复制
在 Redis 主从复制中,分为”全量复制”和”增量复制”两种数据同步方式:
全量复制: 用于初次复制或其它无法进行部分复制的情况,将主节点中的所有数据都发送给从节点。当数据量过大的时候,会造成很大的网络开销。
增量复制: 用于处理在主从复制中因网络闪退等原因造成数据丢失场景,当从节点再次连上主节点,如果条件允许,主节点会补发丢失数据给从节点,因为补发的数据远远小于全量数据,可以有效避免全量复制的过高开销。但需要注意,如果网络中断时间过长,造成主节点没有能够完整地保存中断期间执行的写命令,则无法进行部分复制,仍使用全量复制。
(2)、记录复制位置的偏移量
参与复制的主从节点都会维护自身复制偏移量,主节点在处理完写入命令操作后,会把命令的字节长度做累加记录,可以使用 info replication 命令查询 master_repl_offset 偏移量信息。
从节点每秒钟上报自身的复制偏移量给主节点,因此主节点也会保存从节点的复制偏移量。
从节点在接收到主节点发送的命令后,也会累加记录自身的偏移量,可以使用 info replication 命令查询 slave_repl_offset 偏移量信息。
(3)、复制积压缓冲区
复制积压缓冲区(backlog)是保存在主节点上的一个固定长度的队列,默认大小为 1MB,当主节点有连接的从节点时被创建,这时主节点响应写命令时,不但会把命令发给从节点,还会写入复制积压缓冲区,作为写命令的备份。
除了存储写命令,复制积压缓冲区中还存储了其中的每个字节对应的复制偏移量(offset) 。由于复制积压缓冲区定长且先进先出,所以它保存的是主节点最近执行的写命令,时间较早的写命令会被挤出缓冲区。
(4)、节点运行的 ID
每个 Redis 节点启动后都会动态分配一个 40 位的十六进制字符串为运行 ID。运行 ID 的主要作用是来唯一识别 Redis 节点,比如,从节点保存主节点的运行 ID 识别自已正在复制是哪个主节点。如果只使用 IP + Port 的方式识别主节点,那么主节点重启变更了整体数据集(如替换 RDB/AOF 文件),从节点再基于偏移量复制数据将是不安全的,因此当运行 ID 变化后从节点将做全量复制。可以在 info server 命令查看当前节点的运行 ID。
需要注意的是 Redis 关闭再启动,运行的 ID 会随之变化。
(1)、psync 命令
从节点使用 psync 从主节点获取 runid 与 offset。
主节点会根据自身情况返回响应信息,可能是 FULLRESYNC runid offset 触发全量复制,可能是 CONTINUE 触发增量复制。
(2)、psync 触发全量复制
从节点使用 psync 命令完成部分复制和全量复制功能:
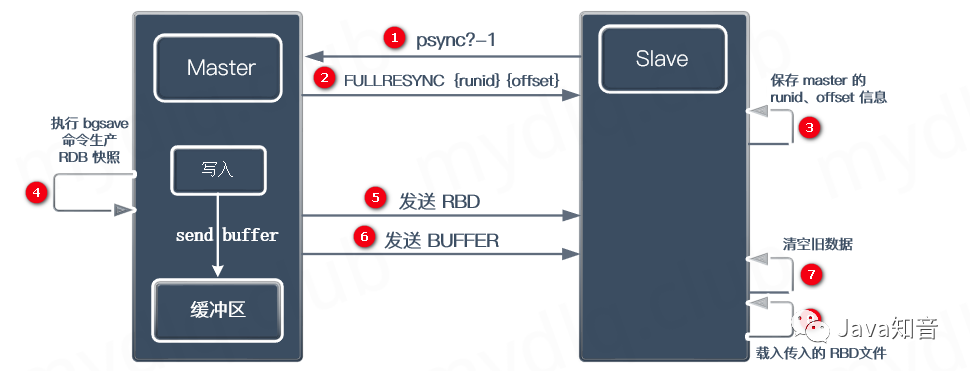
当从节点第一次连接主节点时候,执行全量复制:
① Slave 节点发送 psync? - 1 命令,表示要求 Master 执行数据同步;
② Master 检测到没有 offset ,是第一次执行复制,执行全量复制,就发送 FULLRESYNC {runid} {offset} 命令,将 runid 和 offset 发送到 slave 节点。
③ Slave 节点保存 Master 节点传递的 runid 与 offset 信息。
④ Master 节点执行 bgsave 生成 RBD 快照文件,并使用缓冲区记录从现在开始执行的全部命令。
⑤ Master 节点发送 RBD 文件到 Slave 节点。
⑥ Master 节点发送 BUFFER 缓存区记录的写命令到 Slave 节点。
⑦ Slave 节点清空旧数据。
⑧ Slave 节点载入 Master 节点传入的 RBD 文件。
(2)、psync 触发增量复制
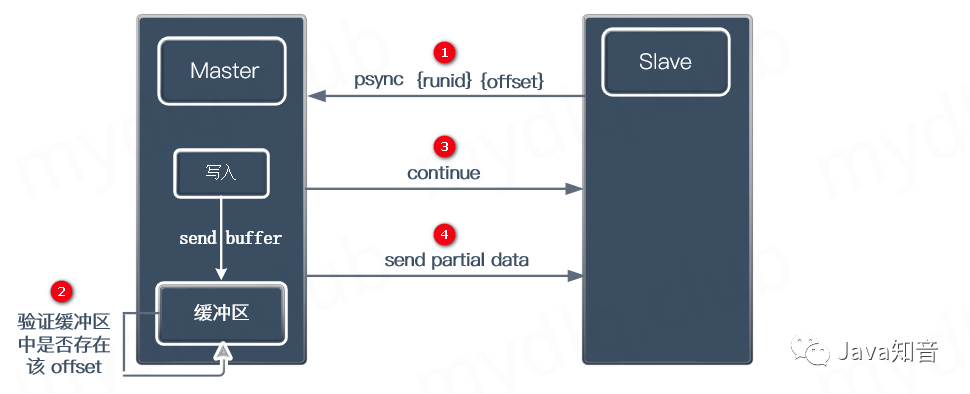
当从节点与主节点发送中断后,从节点会重新连接主节点,这时会触发增量复制,过程如下:
① Slave 节点使用 psync 发送 runid 和 offset 值。
② Master 节点验证 Slave 节点发送的 runid 是否和自己相同:
不相同: 不相同则执行全量复制;
相同: 则还需要验证缓存区中是否存在对应的 offset,如果不存在就执行全量复制,否则执行增量复制;
③ 满足存在对应 offset 这个条件后,则验证缓存区中的 offset 值是否和 Slave 节点发送的 offset 相同:
相同: 返回 offset 值相同,不进行复制操作;
不相同: 发送 CONTINUE offset 命令(注意:这里的 offset 是 Master 节点缓存区记录的 offset 值,不是 Slave 节点传递的 offset 值);
④ Master 节点从复制缓存区拷贝数据,从 Slave 节点发送的 offset 开始,到 Master 节点缓存区记录的 offset 结束,将这个范围内的数据给 Slave 节点。
Redis 在官方文档中提及,其并不能保证数据的强一致性,即 Redis 集群在特定的条件下写入的数据可能会丢失,主要原因是因为 Redis 集群使用了异步复制模式,其写入的操作过程如下:
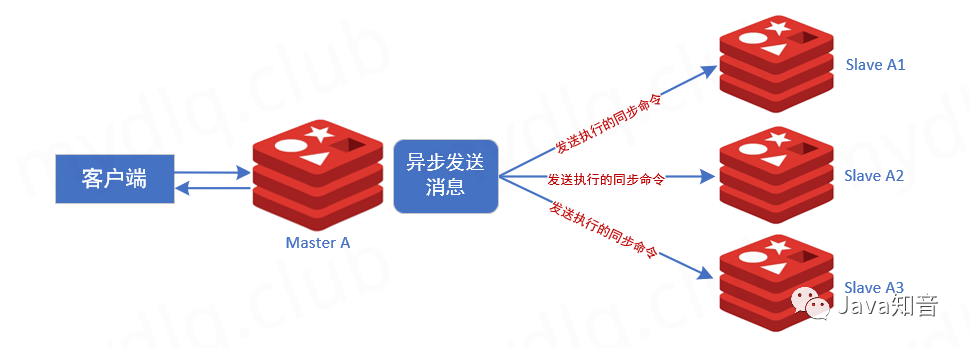
执行顺序如下:
① 客户端向任意一台主节点写入一条命令;
② 主节点对向客户端回复命令执行的状态;
③ 主节点将写操作命令传递给他的从节点;
Redis 集群对性能和一致性之间做出权衡,设置主节点在接收到客户端写命令后再将执行的命令发送到各个从节点进行同步,这个过程是异步操作,且主节点不会等待从节点回复信息就立即回复客户端命令的执行状态。这样减少同步操作,可以很大提高系统的执行速度,避免等待从节点回复消息这个过程成为系统性能的瓶颈。
然而,因为主节点不等待从节点收到信息后进行回复,就将命令的执行状态回复给了客户端,那么在节点出现问题时很可能导致出现数据丢失问题,比如客户端向主节点发送一条命令,然后主节点将该命令异步发送到它的从节点进行数据备份,然后立即回复客户端命令的执行状态。如果在这个过程中,主节点出现问导致宕机,且从节点在处理主节点发送过来的同步数据时,也发生错误。这时正好赶上主节点宕机等不可用情况,那么从节点将转换为新的主节点,在之前主节点执行的命令将丢失。
在 Redis 集群中,数据节点提供两个 TCP 端口,在配置防火墙时需要同时开启下面两类端口:
普通端口: 即客户端访问端口,如默认的 6379;
集群端口: 普通端口号加 10000,如 6379 的集群端口为 16379,用于集群节点之间的通讯;
集群的节点之间通讯采用 Gossip 协议,节点根据固定频率(每秒10次)定时任务进行判断,当集群状态发生变化,如增删节点、槽状态变更时,会通过节点间通讯同步集群状态,使集群收敛。集群间发送的 Gossip 消息有下面五种消息类型:
MEET: 在节点握手阶段,对新加入的节点发送 meet 消息,请求新节点加入当前集群,新节点收到消息会回复 pong 消息;
PING: 节点之间互相发送 ping 消息,收到消息的会回复 pong 消息。ping 消息内容包含本节点和其他节点的状态信息,以此达到状态同步;
PONG: pong 消息包含自身的状态数据,在接收到 ping 或 meet 消息时会回复 pong 消息,也会主动向集群广播 pong 消息;
FAIL: 当一个主节点判断另一个主节点进入 fail 状态时,会向集群广播这个消息,接收到的节点会保存该消息并对该 fail 节点做状态判断;
PUBLISH: 当节点收到 publish 命令时,会先执行命令,然后向集群广播 publish 消息,接收到消息的节点也会执行 publish 命令;
在 Redis 集群模式下也不可能百分百保证集群可用性,当发生不可预知的事件导致 Redis 集群将进入失败状态,在这种状态下 Redis 集群将不能正常提供服务。其中进入失败状态的条件主要为:
① 全部节点都宕机,集群将进入 fail 状态;
② 半数以上主节点不可用,集群将进入 fail 状态;
③ 任意主节点挂掉,且该主节点没有对应的从节点或者从节点也全部挂掉,集群将进入 fail 状态;
Redis 集群重新分片(新增/移除节点)机制:
新增节点:别的节点上的槽分一些出来给新的节点
删除节点:删除节点的槽分给别的节点
但这些操作是需要手动完成的,可以在不停止服务器的情况下执行。
复制结构只支持单层结构,不支持树型结构。
不支持多数据库,只能使用 0 数据库,执行 select 0 命令;
键是数据分区的最小粒度,不能将一个很大的键值对映射到不同的节点;
键事务支持有限,当多个键分布在不同节点时无法使用事务,同一节点才能支持事务;
键的批量操作支持有限,比如 mset, mget 命令,如果多个键映射在不同的槽中,就不能正常使用这些命令了;
我们即将创建一个示例集群部署。在继续之前,让我们介绍Redis Cluster在redis.conf文件中引入的配置参数。
cluster-config-file: 设置 Redis 集群配置信息及状态的存储位置,该文件由 Redis 集群生成,我们只能指定其存储的位置。
cluster-node-timeout: 设置 Redis 群集节点的通信的超时时间;
cluster-migration-barrier: 主节点需要的最小从节点数,只有达到这个数,主节点失败时,它从节点才会进行迁移。
cluster-enabled: 是否开启 Redis 集群模式。
yes:启用 Redis 群集;
no:不启用集群模式;
cluster-require-full-coverage: 设置集群可用性。
yes:表示当负责一个插槽的主库下线,且没有相应的从库进行故障恢复时,集群不可用,下面论证该情况。
no:表示当负责一个插槽的主库下线且没有相应的从库进行故障恢复时,集群仍然可用,下面论证该情况。
cluster-slave-validity-factor:
0:则无论从节点与主节点失联多久,从节点都会尝试升级成主节点。
正数:则 cluster-node-timeout * cluster-slave-validity-factor 得到的时间,是从节点与主节点失联后,此从节点数据有效的最长时间,超过这个时间,从节点不会启动故障迁移。假设 cluster-node-timeout=5,cluster-slave-validity-factor=10,则如果从节点跟主节点失联超过50秒,此从节点不能成为主节点。
这里对待部署的 Redis 集群的节点进行分配,将其部署到不同的机器上,安排如下:

提前创建好用于存储 Redis 的配置文件和持久化数据的目录:
第一台服务器 192.168.2.11 中执行创建存储目录命令:
$ mkdir -p /var/lib/redis/7000 & mkdir -p /var/lib/redis/7003
第二台服务器 192.168.2.12 中执行创建存储目录命令:
$ mkdir -p /var/lib/redis/7001 & mkdir -p /var/lib/redis/7004
第三台服务器 192.168.2.13 中执行创建存储目录命令:
$ mkdir -p /var/lib/redis/7002 & mkdir -p /var/lib/redis/7005
第一台服务器 192.168.2.11 配置文件:
## 7000 端口配置文件 $ cat > /var/lib/redis/7000/redis.conf << EOF port 7000 cluster-enabled yes cluster-config-file nodes.conf cluster-node-timeout 5000 appendonly yes daemonize no protected-mode no pidfile /data/redis.pid EOF ## 7003 端口配置文件 $ cat > /var/lib/redis/7003/redis.conf << EOF port 7003 cluster-enabled yes cluster-config-file nodes.conf cluster-node-timeout 5000 appendonly yes daemonize no protected-mode no pidfile /data/redis.pid EOF
第二台服务器 192.168.2.12 配置文件
## 7001 端口配置:redis.conf $ cat > /var/lib/redis/7001/redis.conf << EOF port 7001 cluster-enabled yes cluster-config-file nodes.conf cluster-node-timeout 5000 appendonly yes daemonize no protected-mode no pidfile /data/redis.pid EOF ## 7004 端口配置:redis-7004.conf $ cat > /var/lib/redis/7004/redis.conf << EOF port 7004 cluster-enabled yes cluster-config-file nodes.conf cluster-node-timeout 5000 appendonly yes daemonize no protected-mode no pidfile /data/redis.pid EOF
第三台服务器 192.168.2.13 配置文件
## 7002 端口配置:redis-7002.conf $ cat > /var/lib/redis/7002/redis.conf << EOF port 7002 cluster-enabled yes cluster-config-file nodes.conf cluster-node-timeout 5000 appendonly yes daemonize no protected-mode no pidfile /data/redis.pid EOF ## 7005 端口配置:redis-7005.conf $ cat > /var/lib/redis/7005/redis.conf << EOF port 7005 cluster-enabled yes cluster-config-file nodes.conf cluster-node-timeout 5000 appendonly yes daemonize no protected-mode no pidfile /data/redis.pid EOF
三台服务器中提前拉取 Redis 镜像,避免在执行运行时候还得拉取镜像,导致运行慢。
$ docker pull redis:6.0.8
三台服务器分别执行 Docker 运行命令来启动 Redis 镜像。这里需要注意的是,不同服务器间的 Docker 是不能相互通信的,所有这里我们设置启动的容器网络模式为 host 模式,这样容器不会创建虚拟网卡,而是使用宿主机的网络。
-d:设置容器后台运行;
-v:指定挂载的宿主机存储目录;
--name:指定运行后的容器名称;
--cpus:指定容器使用 CPU 数量;
--memory:限制容器使用内存数量;
--memory-swap:指定交换内存大小,这里设置为 0,即不用交换内存;
--net:指定 Docker 使用的网络模式;
--restart:指定 Docker 重启时容器的重启策略;
--privileged:设置容器拥有特权,能够获取宿主机 Root 权限;
第一台服务器 192.168.2.11 执行如下命令
## 运行 Redis 镜像 7000 端口 $ docker run -d -v /var/lib/redis/7000:/data \ --cpus=1 --memory=2GB --memory-swap=0 \ --privileged=true \ --restart=always \ --net host \ --name redis-7000 \ redis:6.0.8 redis-server /data/redis.conf ## 运行 Redis 镜像 7003 端口 $ docker run -d -v /var/lib/redis/7003:/data \ --cpus=1 --memory=2GB --memory-swap=0 \ --privileged=true \ --restart=always \ --net host \ --name redis-7003 \ redis:6.0.8 redis-server /data/redis.conf
第二台服务器 192.168.2.12 执行如下命令
## 运行 Redis 镜像 7001 端口 $ docker run -d -v /var/lib/redis/7001:/data \ --cpus=1 --memory=2GB --memory-swap=0 \ --privileged=true \ --restart=always \ --net host \ --name redis-7001 \ redis:6.0.8 redis-server /data/redis.conf ## 运行 Redis 镜像 7004端口 $ docker run -d -v /var/lib/redis/7004:/data \ --cpus=1 --memory=2GB --memory-swap=0 \ --privileged=true \ --restart=always \ --net host \ --name redis-7004 \ redis:6.0.8 redis-server /data/redis.conf
第三台服务器 192.168.2.13 执行如下命令:
## 运行 Redis 镜像 7002 端口 $ docker run -d -v /var/lib/redis/7002:/data \ --cpus=1 --memory=2GB --memory-swap=0 \ --privileged=true \ --restart=always \ --net host \ --name redis-7002 \ redis:6.0.8 redis-server /data/redis.conf ## 运行 Redis 镜像 7005 端口 $ docker run -d -v /var/lib/redis/7005:/data \ --cpus=1 --memory=2GB --memory-swap=0 \ --privileged=true \ --restart=always \ --net host \ --name redis-7005 \ redis:6.0.8 redis-server /data/redis.conf
随意进入一台服务器,使用 Redis 镜像的 redis-cli 工具执行创建集群命令使各个 Redis 组成集群,这里本人进入第一台服务器 192.168.2.11 中,使用端口为 7000 的 Redis 端镜像,可以执行下面命令:
-p:指定连接 Redis 的端口;
create:创建 Redis 集群;
--cluster:使用 Redis 集群模式命令;
--cluster-replicas:指定副本数(slave 数量);
$ docker exec -it redis-7000 \ redis-cli -p 7000 --cluster create \ 192.168.2.11:7000 192.168.2.12:7001 192.168.2.13:7002 \ 192.168.2.11:7003 192.168.2.12:7004 192.168.2.13:7005 \ --cluster-replicas 1
然后会看到下面信息:
>>> Performing hash slots allocation on 6 nodes... Master[0] -> Slots 0 - 5460 Master[1] -> Slots 5461 - 10922 Master[2] -> Slots 10923 - 16383 Adding replica 192.168.2.12:7004 to 192.168.2.11:7000 Adding replica 192.168.2.13:7005 to 192.168.2.12:7001 Adding replica 192.168.2.11:7003 to 192.168.2.13:7002 M: 5e50824c55d4df42db4d2987796f0c0b468c273f 192.168.2.11:7000 slots:[0-5460] (5461 slots) master M: 36565e0273fd62921aa1f2d85c5f7ac98a5b9466 192.168.2.12:7001 slots:[5461-10922] (5462 slots) master M: 0cc1aaf960defae7332e9256dd25ee5e5c99e65f 192.168.2.13:7002 slots:[10923-16383] (5461 slots) master S: 42d6e3979395ba93cd1352b6d17044f6b25d9379 192.168.2.11:7003 replicates 0cc1aaf960defae7332e9256dd25ee5e5c99e65f S: ac5d34b57a8f73dabc60d3a56469055ec64fcde7 192.168.2.12:7004 replicates 5e50824c55d4df42db4d2987796f0c0b468c273f S: 470b7ff823f10a309fb07311097456210506f6d8 192.168.2.13:7005 replicates 36565e0273fd62921aa1f2d85c5f7ac98a5b9466 Can I set the above configuration? (type 'yes' to accept): yes >>> Nodes configuration updated >>> Assign a different config epoch to each node >>> Sending CLUSTER MEET messages to join the cluster Waiting for the cluster to join . >>> Performing Cluster Check (using node 192.168.2.11:7000) M: 5e50824c55d4df42db4d2987796f0c0b468c273f 192.168.2.11:7000 slots:[0-5460] (5461 slots) master 1 additional replica(s) S: 470b7ff823f10a309fb07311097456210506f6d8 192.168.2.13:7005 slots: (0 slots) slave replicates 36565e0273fd62921aa1f2d85c5f7ac98a5b9466 S: 42d6e3979395ba93cd1352b6d17044f6b25d9379 192.168.2.11:7003 slots: (0 slots) slave replicates 0cc1aaf960defae7332e9256dd25ee5e5c99e65f S: ac5d34b57a8f73dabc60d3a56469055ec64fcde7 192.168.2.12:7004 slots: (0 slots) slave replicates 5e50824c55d4df42db4d2987796f0c0b468c273f M: 0cc1aaf960defae7332e9256dd25ee5e5c99e65f 192.168.2.13:7002 slots:[10923-16383] (5461 slots) master 1 additional replica(s) M: 36565e0273fd62921aa1f2d85c5f7ac98a5b9466 192.168.2.12:7001 slots:[5461-10922] (5462 slots) master 1 additional replica(s) [OK] All nodes agree about slots configuration. >>> Check for open slots... >>> Check slots coverage... [OK] All 16384 slots covered.
进入 Redis 镜像内部并折佣 redis-cli 命令:
-p:指定连接 Redis 的端点;
-c:使用集群模式;
$ docker exec -it redis-7000 redis-cli -p 7000 -c
查看集群信息:
> cluster info cluster_state:ok cluster_slots_assigned:16384 cluster_slots_ok:16384 cluster_slots_pfail:0 cluster_slots_fail:0 cluster_known_nodes:6 cluster_size:3 cluster_current_epoch:6 cluster_my_epoch:1 cluster_stats_messages_ping_sent:866 cluster_stats_messages_pong_sent:854 cluster_stats_messages_sent:1720 cluster_stats_messages_ping_received:849 cluster_stats_messages_pong_received:866 cluster_stats_messages_meet_received:5 cluster_stats_messages_received:1720
查看集群节点信息:
> cluster nodes 470b7ff823f10a309fb07311097456210506f6d8 192.168.2.13:7005@17005 slave 36565e0273fd62921aa1f2d85c5f7ac98a5b9466 0 1600267217000 2 connected 42d6e3979395ba93cd1352b6d17044f6b25d9379 192.168.2.11:7003@17003 slave 0cc1aaf960defae7332e9256dd25ee5e5c99e65f 0 1600267218171 3 connected ac5d34b57a8f73dabc60d3a56469055ec64fcde7 192.168.2.12:7004@17004 slave 5e50824c55d4df42db4d2987796f0c0b468c273f 0 1600267216161 1 connected 0cc1aaf960defae7332e9256dd25ee5e5c99e65f 192.168.2.13:7002@17002 master - 0 1600267218070 3 connected 10923-16383 36565e0273fd62921aa1f2d85c5f7ac98a5b9466 192.168.2.12:7001@17001 master - 0 1600267217163 2 connected 5461-10922 5e50824c55d4df42db4d2987796f0c0b468c273f 192.168.2.11:7000@17000 myself,master - 0 1600267217000 1 connected 0-5460
看完上述内容,你们对怎么在Docker中部署一个Redis 6.x集群有进一步的了解吗?如果还想了解更多知识或者相关内容,请关注亿速云行业资讯频道,感谢大家的支持。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。