жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
жң¬ж–Үдё»иҰҒз»ҷеӨ§е®¶з®ҖеҚ•и®Іи®ІдҪҝз”ЁpandasжЁЎеқ—и§ЈеҶіmysqlдёӯзҡ„йҮҚеӨҚж•°жҚ®й—®йўҳпјҢзӣёе…ідё“дёҡжңҜиҜӯеӨ§е®¶еҸҜд»ҘдёҠзҪ‘жҹҘжҹҘжҲ–иҖ…жүҫдёҖдәӣзӣёе…ід№ҰзұҚиЎҘе……дёҖдёӢпјҢиҝҷйҮҢе°ұдёҚж¶үзҢҺдәҶпјҢжҲ‘们е°ұзӣҙеҘ”дё»йўҳеҗ§пјҢеёҢжңӣдҪҝз”ЁpandasжЁЎеқ—и§ЈеҶіmysqlдёӯзҡ„йҮҚеӨҚж•°жҚ®й—®йўҳиҝҷзҜҮж–Үз« еҸҜд»Ҙз»ҷеӨ§е®¶еёҰжқҘдёҖдәӣе®һйҷ…её®еҠ©гҖӮ
зӣҙжҺҘдёҠд»Јз Ғ
import pymysql
import pandas as pda
conn=pymysql.connect(host="127.0.0.1",user="root",passwd="pw",db="test001",charset="utf8")
sql="select * from table001"
data1 = pda.read_sql(sql,conn)
print(data1.count())
data2 = data1.drop_duplicates(subset="big",keep="last")
data2.to_sql("table002",con=conn,flavor="mysql",if_exists="append",index=False)
print(data2.count())table001иЎЁдёәеҺҹе§ӢиЎЁ,bigдёәиЎЁйҮҢдёҚиғҪйҮҚеӨҚзҡ„еӯ—ж®өпјҢkeep="last"д»ЈиЎЁз•ҷйҮҚеӨҚж•°жҚ®зҡ„жңҖеҗҺдёҖжқЎпјҢtable002иЎЁдёәжё…жҙ—е®Ңж•°жҚ®дҝқеӯҳж•°жҚ®зҡ„иЎЁгҖӮ
иҝҗиЎҢиҜҘи„ҡжң¬пјҢеҚҒжқҘеҲҶй’ҹе·ҰеҸіпјҢ800WжқЎж•°жҚ®е·Із»Ҹе…ЁйғЁжё…жҙ—е®ҢжҜ•пјҢиҝҳеү©дҪҷ200WжқЎдёҚйҮҚеӨҚж•°жҚ®пјҢ并且иҝҳе’ҢжңӢеҸӢжӯЈзЎ®зҡ„ж•°жҚ®дёҖжқЎдёҚе·®гҖӮ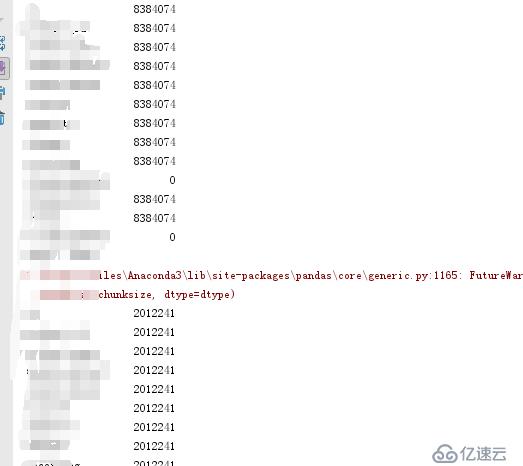
йҡҸеҗҺе°Ҷж•°жҚ®иЎЁдёҠдј иҮіжңӢеҸӢзҡ„зәҝдёҠдә‘жңҚеҠЎеҷЁпјҢжңӢеҸӢйӘҢиҜҒж•°жҚ®йғҪжІЎй—®йўҳгҖӮ
дҪҝз”ЁpandasжЁЎеқ—и§ЈеҶіmysqlдёӯзҡ„йҮҚеӨҚж•°жҚ®й—®йўҳе°ұе…Ҳз»ҷеӨ§е®¶и®ІеҲ°иҝҷйҮҢпјҢеҜ№дәҺе…¶е®ғзӣёе…ій—®йўҳеӨ§е®¶жғіиҰҒдәҶи§Јзҡ„еҸҜд»ҘжҢҒз»ӯе…іжіЁжҲ‘们зҡ„иЎҢдёҡиө„и®ҜгҖӮжҲ‘们зҡ„жқҝеқ—еҶ…е®№жҜҸеӨ©йғҪдјҡжҚ•жҚүдёҖдәӣиЎҢдёҡж–°й—»еҸҠдё“дёҡзҹҘиҜҶеҲҶдә«з»ҷеӨ§е®¶зҡ„гҖӮ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ