您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
怎么在R语言中利用xlsx包读写Excel数据?针对这个问题,这篇文章详细介绍了相对应的分析和解答,希望可以帮助更多想解决这个问题的小伙伴找到更简单易行的方法。
> # 下载并安装xlsx包
> install.packages("xlsx")
> library(xlsx)假如是csv或txt等文本类的数据文件,利用R内置函数read.csv()与read.table()就可读取(注意编码格式的参数设置)。Excel由于使用范围最广,很多问题不可避免,因此,xlsx包提供了专门读取xlsx的函数read.xlsx和read.xlsx2,为什么有两个呢?请看以下区别:
| 函数 | 参数 |
|---|---|
| xlsx::read.xlsx() | file, sheetIndex, sheetName=NULL, rowIndex=NULL,startRow=NULL,endRow=NULL, colIndex=NULL,as.data.frame=TRUE, header=TRUE, colClasses=NA,keepFormulas=FALSE, encoding=“unknown”, password=NULL, … |
| xlsx::read.xlsx2() | file, sheetIndex, sheetName=NULL, startRow=1,colIndex=NULL, endRow=NULL, as.data.frame=TRUE, header=TRUE,colClasses=“character”, password=NULL, … |
其实只是细微的差别,大家自己体会即可。下面给个参考案例:
> # 指定file和sheetIndex(或sheetName),即可定位到相应的工作表
> data1 <- read.xlsx("iris.xlsx",sheetIndex = 1)
> head(data1)| Sepal.Length | Sepal.Width | Petal.Length | Petal.Width | Species |
|---|---|---|---|---|
| 5.1 | 3.5 | 1.4 | 0.2 | setosa |
| 4.9 | 3.0 | 1.4 | 0.2 | setosa |
| 4.7 | 3.2 | 1.3 | 0.2 | setosa |
| 4.6 | 3.1 | 1.5 | 0.2 | setosa |
| 5.0 | 3.6 | 1.4 | 0.2 | setosa |
| 5.4 | 3.9 | 1.7 | 0.4 | setosa |
切莫用R内置函数read.csv()与read.table()去生成xlsx文件,会有你意想不到的麻烦,还是采用专业的包来解决问题吧。 xlsx包同样提供了两个写入数据的函数write.xlsx()和write.xlsx2(),其中细微区别自行参透(注意参数 ...)。
| 函数 | 参数 |
|---|---|
| xlsx::write.xlsx() | x, file, sheetName=“Sheet1”, col.names=TRUE, row.names=TRUE, append=FALSE, showNA=TRUE, password=NULL |
| xlsx::write.xlsx2() | x, file, sheetName=“Sheet1”,col.names=TRUE, row.names=TRUE, append=FALSE, password=NULL, ... |
下面是参考案例:
># 指定x待写入数据,file生成的文件名,row.names为false则不生成行名,指定sheet工作表名为Sheet1 >write.xlsx(iris, file = "iris.xlsx", row.names = FALSE, sheetName = "Sheet1")
想必会有人在这里踩坑,大家应该注意到有一个append的参数,是否认为将其值设置为TRUE的话,就可以多次向表中写入数据?那就真踩坑了。查看xlsx包中的注释也很模糊:
> # a logical value indicating if x should be appended to an existing file. > # 翻译:一个逻辑值,指示是否应该将x附加到现有文件中
附加到现有文件中,实际上是增加新的sheet,而非在原有sheet工作表中继续增加数据。如需在同一个sheet工作表中多次增加数据,请继续往下看。
说随心所欲 一点不夸张,不仅可以取出excel中的数据,还能识别excel单元格的样式(包括颜色、字体、大小、标注、数据类型等等)。其原理与数据库有点相似,先是定义一个工作簿的对象,再基于工作簿定义里面的工作表,进而逐级查询。下面进行详细介绍:
【样例数据】文件名:iris10.xlsx。
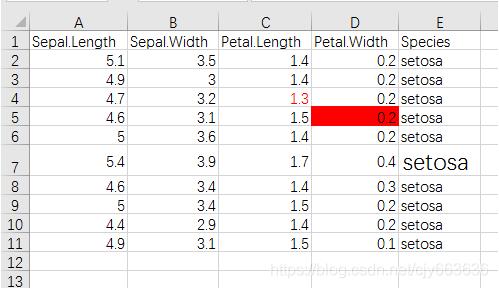
声明一个工作簿对象
> # loadWorkbook(file, password=NULL) #用于声明一个工作簿对象
> # 提醒:如果excel文件不在工作空间内,file最好指定为绝对路径
> wb <- createWorkbook("iris10.xlsx")检索工作簿中的sheet
> # sheets <- getSheets(wb) #用于生成一个list对象,其中包含所有工作表的信息,数据类型为rJava::jobjRef,在此不深入讲解 > sheets <- getSheets(wb)
定位目标sheet
> # 本例只有一个sheet,名称为“Sheet1” > sheet <- sheets[["Sheet1"]] # sheet的数据类型为rJava::jobjRef
读取数据【方法一】
上面read.xlsx()方法能够将整个sheet工作表的数据读取出来,在这里提供另一种方法,不过相对麻烦一点,使用的是xlsx::readColumns()函数
| 函数 | 参数 |
|---|---|
| xlsx::readColumns() | sheet,startColumn,endColumn,startRow,endRow=NULL,as.data.frame=TRUE,header=TRUE, colClasses=NA, … |
| xlsx::readRows() | sheet, startRow, endRow, startColumn, endColumn=NULL |
xlsx::readRows()使用起来比较麻烦,不如xlsx::readColumns()好用,有兴趣的可自行研究一下。另外还有两个函数,用于定位表内数据第一行和最后一行的索引(这里与Java的性质一致,从0开始算起)
| 函数 | 参数 |
|---|---|
| getFirstRowNum() | 无参。该函数必须基于sheet对象 |
| getLastRowNum() | 无参。该函数必须基于sheet对象 |
xlsx::readRows()使用起来比较麻烦,不如xlsx::readColumns()好用,有兴趣的可自行研究一下。另外还有两个函数,用于定位表内数据第一行和最后一行的索引(这里与Java的性质一致,从0开始算起)
| 函数 | 参数 |
|---|---|
| getFirstRowNum() | 无参。该函数必须基于sheet对象 |
| getLastRowNum() | 无参。该函数必须基于sheet对象 |
下面以xlsx::readColumns()为例获取数据:
> # 该函数必须提供数据的起始列索引值、终止列索引值、起始行索引值、终止行索引值; > dataTmp <- readColumns(sheet, startColumn = 1, endColumn = 10, startRow = sheet$getFirstRowNum()+1, endRow = sheet$getLastRowNum()+1, header = T, as.data.frame=TRUE)
as.data.frame=TRUE决定了输出结果为一个数据框。
缺点:在不清楚数据结构的情况下,首行和末行索引值可以求得,但列数一般难以确定,可能导致列缺失或生成多余的列
读取数据【方法二】
另一种方法相对【方法一】要好一点,先是将所有单元格的值获取出来,再生成数据框。(稍微复杂一点)
| 函数 | 参数 | 注释 |
|---|---|---|
| xlsx::getRows() | sheet, rowIndex=NULL | 用于获取sheet的每一行数据,返回值list,数据类型为rJava::jobjRef |
| xlsx::getCells() | row, colIndex=NULL, simplify=TRUE | 用于获取行内每个单元格的数据,返回值list,数据类型为rJava::jobjRef |
| xlsx::getCellValue() | cell, keepFormulas=FALSE, encoding=“unknown” | 用于获取所有单元格的值,返回值list,数据类型为character,长度为数据表m*n |
注意:这里连同标题行也作为单元格数据一并获取,并且如果有null值的单元格,会跳过该单元格
> # 获取cells进而获取values > cells <- sheet %>% getRows() %>% getCells() > values <- lapply(cells,getCellValue)
values获取出来就如下面这个样子,你会发现value的名称向量,每个值都包含了所在单元格的x、y坐标值。
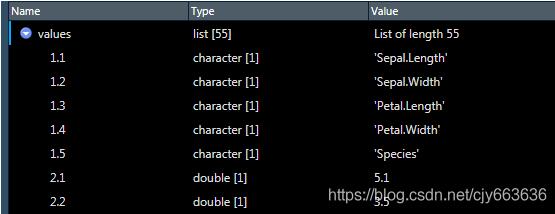
> names(values) #查看values的名称向量 [1] "1.1" "1.2" "1.3" "1.4" "1.5" "2.1" "2.2" "2.3" "2.4" "2.5" "3.1" "3.2" "3.3" "3.4" "3.5" "4.1" [17] "4.2" "4.3" "4.4" "4.5" "5.1" "5.2" "5.3" "5.4" "5.5" "6.1" "6.2" "6.3" "6.4" "6.5" "7.1" "7.2" [33] "7.3" "7.4" "7.5" "8.1" "8.2" "8.3" "8.4" "8.5" "9.1" "9.2" "9.3" "9.4" "9.5" "10.1" "10.2" "10.3" [49] "10.4" "10.5" "11.1" "11.2" "11.3" "11.4" "11.5"
将这些坐标值拆分出来,作为等会重排数据的索引
> addresses <- sapply(names(values),FUN = function(x) str_split(string = x,pattern = "[.]"))
接下来就只需要将其进行重排,形成数据框即可。
> datas.name <- vector(mode = "character") #声明一个空的向量,用来存放标题
> datas <- data.frame() # 声明一个空的数据框,用来存放目标数据
> # 用sapply代替for做循环,避免占用大量内存。同时注意sapply使用时的环境问题,用.GlobalEnv指向最外层环境的变量。
> # 这里只对数据进行重排,无需进行计算,所以invisible不显示计算结果
> invisible(sapply(addresses,FUN = function(x) {
+ if (x[1] == "1") {
+ .GlobalEnv$datas.name = c(.GlobalEnv$datas.name,.GlobalEnv$values[[1]])
+ .GlobalEnv$values[[1]] <- NULL
+ } else {
+ .GlobalEnv$datas[x[1],x[2]] <- .GlobalEnv$values[[1]]
+ .GlobalEnv$values[[1]] <- NULL
+ }
+ }))
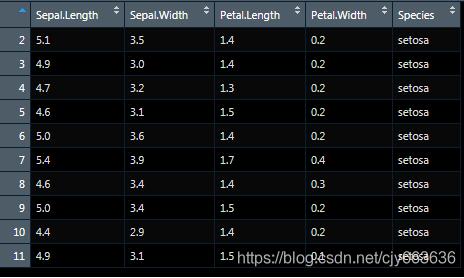
> names(datas) <- datas.name #最后在添加标题
> View(datas)得到结果与原excel数据一致
获取单元格样式与获取数据的方式一致,这里不再增加过多篇幅讲解,只做简单介绍。以下函数按函数名字面理解。
| 函数 | 参数 |
|---|---|
| xlsx::CellStyle() | wb, dataFormat=NULL, alignment=NULL,border=NULL, fill=NULL, font=NULL, cellProtection=NULL |
| xlsx::setCellStyle() | cell, cellStyle |
| xlsx::getCellStyle() | cell |
| xlsx::createCellComment() | cell, string="", author=NULL, visible=TRUE |
| getCellComment() | cell |
| removeCellComment() | cell |
其他函数后续如有机会,再做详细介绍吧。
我想大家更想看到的就是这部分内容了。确实在日常处理数据时,将数据存储到excel中进行传递是常有的事,谁叫excel是微软亲生的呢。闲话少说,直入正题。
前面基础篇通过write.xlsx()函数将数据写入excel文件中,同时指定sheet名称。但这种写入是一次性的,即一次写入多少就多少。在工作簿里面新增sheet工作表用append控制,但在同个sheet上继续写入数据,会报错:
> write.xlsx(datas,file = "iris10.xlsx",sheetName = "Sheet1",row.names = F,append = T) Error in .jcall(wb, "Lorg/apache/poi/ss/usermodel/Sheet;", "createSheet", : java.lang.IllegalArgumentException: The workbook already contains a sheet of this name
说是这个名称的sheet已经存在同名的了!
这次我们采用高级一点的方法,跟前面进阶读取数据一样,先是定义一个工作簿的对象,再创建或加载sheet工作表。
| 函数 | 参数 | 注释 |
|---|---|---|
| xlsx::createWorkbook() | type=“xlsx” | 用于生成一个新的excel工作簿 |
| xlsx::loadWorkbook() | file, password=NULL | 用于加载当前已存在的excel工作簿 |
| xlsx::saveWorkbook() | wb, file, password=NULL | 使用完必须保存工作簿 |
| xlsx::createSheet() | wb, sheetName=“Sheet1” | 用于生成一个新的sheet工作表 |
| xlsx::removeSheet() | wb, sheetName=“Sheet1” | 用于删除工作表 |
| xlsx::getSheets() | wb | 用于获取当前工作簿里的工作表清单,返回值是list |
| xlsx::addDataFrame() | x, sheet, col.names=TRUE, row.names=TRUE,startRow=1, | 用于获取当前工作簿里的工作表清单,返回值是list |
| (续上) | startColumn=1,colStyle=NULL, colnamesStyle=NULL,rownamesStyle=NULL, showNA=FALSE, characterNA="", byrow=FALSE |
前面讲过如何加载已有工作簿,这里以生成新excel工作簿为例,将数据写入文件中
> wb <- xlsx::createWorkbook() > sheets <- getSheet() # 新生成的工作簿没有sheet,系统提示:Workbook has no sheets! > sheet <- createSheet(wb,sheetName = "newSheet1")
此时R内存中已经生成了一个工作簿,包含一个空的sheet工作表,通过addDataFrame()函数将数据写入sheet中.
> # 用上面生成的datas数据框对象,取前4行数据写入当前sheet对象中 > addDataFrame(data[1:4,],sheet,row.names = F) > saveWorkbook(wb,file = "iris_new.xlsx")
==记得保存工作簿、记得保存工作簿、记得保存工作簿==
如果是在已有excel工作簿上操作,这里最好做一个判断,避免覆盖现有数据,造成不必要的麻烦。如果当前sheet的最后一行索引不等于零(说明有数据),则将新数据写到最后一行数据的下一行,同时不加入列名行(col.names = FALSE);如果为零则将数据直接添加到sheet中。
> # 用上面生成的datas数据框对象,取前4行数据写入当前sheet对象中
> if (sheet$getLastRowNum() != 0) {
+ addDataFrame(data[1:4,],sheet,row.names = F,col.names = F,startRow = sheet$getLastRowNum() + 2)
+ } else {
+ addDataFrame(data[1:4,],sheet,row.names = F)
+ }
+ }
> saveWorkbook(wb,file = "iris_new.xlsx")关于怎么在R语言中利用xlsx包读写Excel数据问题的解答就分享到这里了,希望以上内容可以对大家有一定的帮助,如果你还有很多疑惑没有解开,可以关注亿速云行业资讯频道了解更多相关知识。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。