您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
三元运算符又称三目运算,是对简单的条件语句的简写
语法:val =1 if 条件成立 else 2
简单条件语句:
a = 0
if a == 0:
val = 0
else:
val = 1
print(val)
三目运算:
val = 0 if a == 0 else 2
print(val)
E:\PythonProject\python-test\venvP3\Scripts\python.exe E:/PythonProject/python-test/BasicGrammer/test.py
0
0
Process finished with exit code 0错误案例
a = 0
val = 0 if a == 0 else val = 2
print(val)
E:\PythonProject\python-test\venvP3\Scripts\python.exe E:/PythonProject/python-test/BasicGrammer/test.py
File "E:/PythonProject/python-test/BasicGrammer/test.py", line 8
val = 0 if a == 0 else val = 2
^
SyntaxError: can't assign to conditional expression
Process finished with exit code 1
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# Author: vita
f = open(file="读文件.txt", mode="r", encoding="utf-8")
data = f.read()
f.close()
print(type(data))
print(data)
# file="读文件.txt" 表示文件路径
# mode="r" 表示"只读"(可以修改为其他)
# encoding="utf-8" 表示将硬盘上的0101010101按照utf-8的规则去"断句",再将"断句"后的每一段01010101转换成unicode的0101010,unicode对照表中有010101和字符的对应关系
# f.read()表示读取多有内容,内容是已经转换完成的"字符串"
# f.close() 表示关闭文件
E:\PythonProject\python-test\venvP3\Scripts\python.exe E:/PythonProject/python-test/BasicGrammer/test.py
<class 'str'>
哈哈
Process finished with exit code 0
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# Author: vita
f = open(file="读文件.txt", mode="rb")
data = f.read()
f.close()
print(type(data))
print(data)
E:\PythonProject\python-test\venvP3\Scripts\python.exe E:/PythonProject/python-test/BasicGrammer/test.py
<class 'bytes'>
b'\xe5\x93\x88\xe5\x93\x88\r\n'
Process finished with exit code 0
# mode="rb" 表示只读(可以修改为其他)
# 数据类型是"bytes"
# rb 与 r 的区别:
# "rb"在打开文件的时候不需要指定encoding,因为直接以rb模式打开文件
# rb是二进制模式,数据读到内存中直接就是bytes模式,如果想要看内容,还需要手动decode
# 因此文件打开阶段不要指定编码
# 手动decode也需要知道源文件的编码,否则,decode后还是乱码的
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# Author: vita
import chardet
result = chardet.detect(open(file="读文件.txt", mode="rb").read())
print(result)
E:\PythonProject\python-test\venvP3\Scripts\python.exe E:/PythonProject/python-test/BasicGrammer/test.py
{'encoding': 'utf-8', 'confidence': 0.7525, 'language': ''}
Process finished with exit code 0
# 查看到源文件编码是utf-8,下面就使用utf-8解码
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# Author: vita
data = open(file="读文件.txt", mode="rb").read()
print(data.decode(encoding="utf-8"))
E:\PythonProject\python-test\venvP3\Scripts\python.exe E:/PythonProject/python-test/BasicGrammer/test.py
哈哈
Process finished with exit code 0#!/usr/bin/env python
# -*- coding:utf-8 -*-
# Author: vita
f = open(file="读文件.txt", mode="r", encoding='utf-8')
print("--------readline-------")
print(f.readline())
print(f.readline())
print(type(f.readline()))
# readline读取一行,这一行的数据类型是str
print("--------readline-------")
print("--------readlines-------")
print(f.readlines())
print(type(f.readlines()))
# readlines是全部读取出来,数据类型是list
print("--------readlines-------")
print("--------read-------")
print(f.read())
print(type(f.read()))
# read是全部读取出来,数据类型是str
# 这里为空,是因为上面的代码已经把文件读取完了
print("--------read-------")
E:\PythonProject\python-test\venvP3\Scripts\python.exe E:/PythonProject/python-test/BasicGrammer/test.py
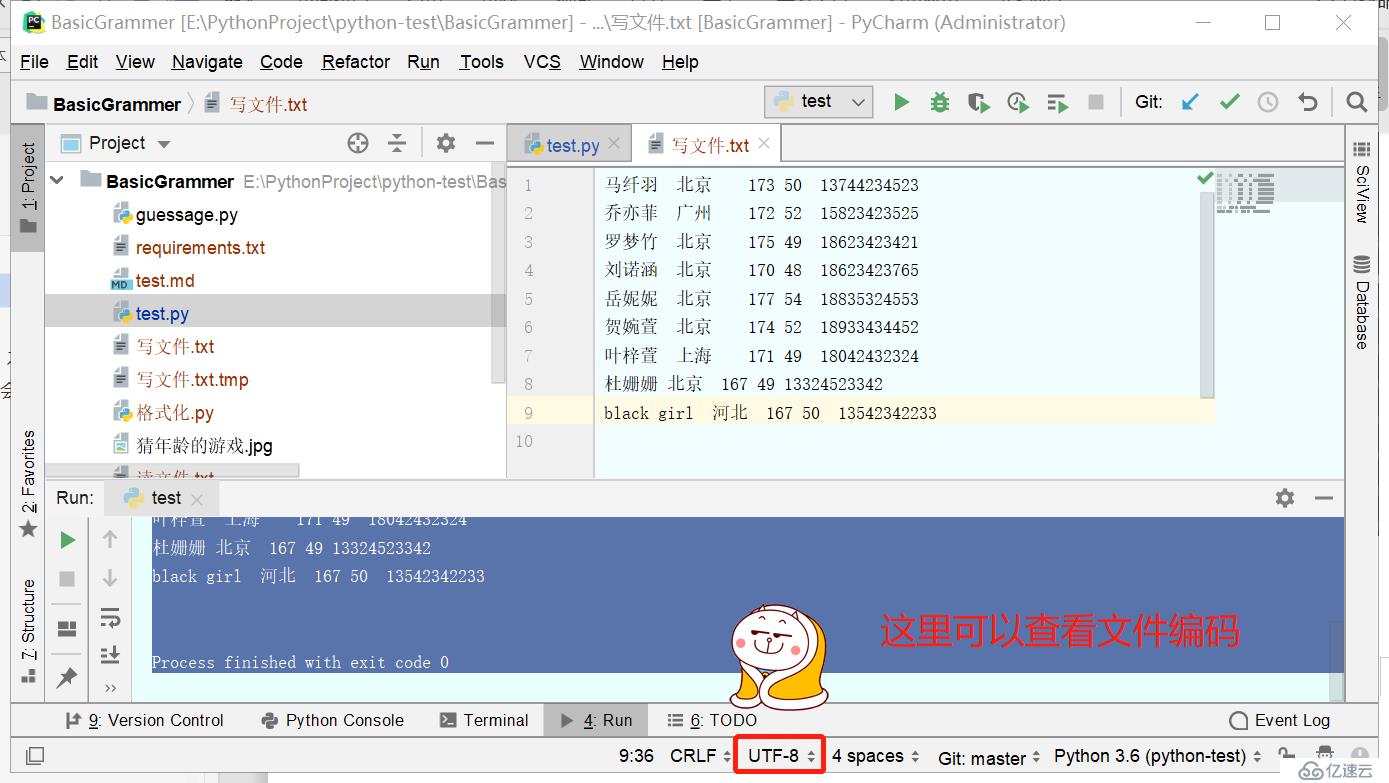
--------readline-------
马纤羽 北京 173 50 13744234523
乔亦菲 广州 172 52 15823423525
<class 'str'>
--------readline-------
--------readlines-------
['刘诺涵 \t北京\t170\t48\t18623423765\n', '岳妮妮 \t北京\t177\t54\t18835324553\n', '贺婉萱 \t北京\t174\t52\t18933434452\n', '叶梓萱\t上海\t171\t49\t18042432324\n', '杜姗姗 北京 167 49 13324523342\n', 'black girl 河北 167 50 13542342233']
<class 'list'>
--------readlines-------
--------read-------
<class 'str'>
--------read-------
Process finished with exit code 0
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# Author: vita
f = open(file="读文件.txt", mode="r", encoding='utf-8')
for line in f:
print(line)
E:\PythonProject\python-test\venvP3\Scripts\python.exe E:/PythonProject/python-test/BasicGrammer/test.py
马纤羽 北京 173 50 13744234523
乔亦菲 广州 172 52 15823423525
罗梦竹 北京 175 49 18623423421
刘诺涵 北京 170 48 18623423765
岳妮妮 北京 177 54 18835324553
贺婉萱 北京 174 52 18933434452
叶梓萱 上海 171 49 18042432324
杜姗姗 北京 167 49 13324523342
black girl 河北 167 50 13542342233
Process finished with exit code 0
# read()方法读取文件,是一下子把整个文件都读取到内存中,一次性读完,但是如果文件很大,会出现内存溢出的情况,所以可以每次读取部分数据
# 为什么每行的后面都有一个空行呢?
# 因为print()函数就是自动会换行,而且每行的后面已经存在\n了,所以会有个空行
# 上面使用readlins()函数时,可以看到每行结尾都是有\n的#!/usr/bin/env python
# -*- coding:utf-8 -*-
# Author: vita
f = open(file="写文件.txt", mode="w", encoding='utf-8')
# "这时文件还没真正写入硬盘中,还在内存中,可以f.write()后调用f.flush()把内容写入到硬盘中,防止数据丢失"
f.write('写入文件')
# "这时文件才写入硬盘"
f.close()
E:\PythonProject\python-test\venvP3\Scripts\python.exe E:/PythonProject/python-test/BasicGrammer/test.py
Process finished with exit code 0
查看文件内容
写入文件
# mode = "w" 表示只写,"w"是创建模式,会清空之前的内容,重新写入,比较危险
# encoding='utf-8' 将要写入的unicode字符串编码成utf-8格式
# f.write() 表示写入内容,写入的内容是unicode字符串类型,内部会根据encoding转换成特定编码的01010101,即字节类型
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# Author: vita
f = open(file="写文件.txt", mode="wb")
f.write('写入文件'.encode("utf-8"))
f.close()
# "写入文件的时候,需要手动把写入的内容encode(),指定编码"
E:\PythonProject\python-test\venvP3\Scripts\python.exe E:/PythonProject/python-test/BasicGrammer/test.py
Process finished with exit code 0
查看文件内容
写入文件#!/usr/bin/env python
# -*- coding:utf-8 -*-
# Author: vita
f = open(file="写文件.txt", mode="a",encoding="utf-8")
f.write("追加写入文件")
f.write("\n追加写入文件\n追加换行")
f.close()
# mode = a或ab模式打开,只能追加,即:在原来内容的尾部追加内容
# a追加时,需要指定编码。ab追加时,需要手动设定编码
"a和ab默认都是在本行内追加,要想换行,需要手动追加\n"
E:\PythonProject\python-test\venvP3\Scripts\python.exe E:/PythonProject/python-test/BasicGrammer/test.py
Process finished with exit code 0
查看文件内容
写入文件追加写入文件
追加写入文件
追加换行
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# Author: vita
f = open(file="写文件.txt", mode="ab")
f.write("追加写入文件ab".encode("utf-8"))
f.write("\n追加写入文件ab\n追加换行ab".encode("utf-8"))
f.close()
# mode = a或ab模式打开,只能追加,即:在原来内容的尾部追加内容
# a追加时,需要指定编码。ab追加时,需要手动设定编码
E:\PythonProject\python-test\venvP3\Scripts\python.exe E:/PythonProject/python-test/BasicGrammer/test.py
Process finished with exit code 0
查看文件内容
写入文件追加写入文件
追加写入文件
追加换行追加写入文件ab
追加写入文件ab
追加换行ab查看源文件内容
追加换行追加写入文件ab
追加写入文件ab
追加换行ab
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# Author: vita
f = open(file="写文件.txt", mode="r+", encoding="utf-8")
f.write("\nr+写入文件")
f.close()
E:\PythonProject\python-test\venvP3\Scripts\python.exe E:/PythonProject/python-test/BasicGrammer/test.py
Process finished with exit code 0
运行后查看文件中内容
"1.r+写入时,默认是写入到文件的开头位置"
"2.由于中文在utf-8编码时,是每个字占用3个字节,英文和+是占一个字节共占用2个字节,由于write()时是覆盖原位置的内容,出现字节数不匹配,就出现了乱码"
"下面我们继续实验刚好追加相同字节数的内容"
查看源文件内容
追加换行追加写入文件ab
追加写入文件ab
追加换行ab
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# Author: vita
f = open(file="写文件.txt", mode="r+", encoding="utf-8")
f.write("r++写入文件")
f.close()
运行后查看文件内容
r++写入文件加写入文件ab
追加写入文件ab
追加换行ab
这次就没有出现乱码
"先read,再write"
查看源文件内容
加写入文件ab
追加写入文件ab
追加换行ab
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# Author: vita
f = open(file="写文件.txt", mode="r+", encoding="utf-8")
print(f.read())
f.write("\nr++写入文件")
print(f.read())
# "这一次的read没有显示出刚刚追加的内容,因为读取文件的小指针已经在文件位置了,写入文件也会移动指针"
f.close()
E:\PythonProject\python-test\venvP3\Scripts\python.exe E:/PythonProject/python-test/BasicGrammer/test.py
加写入文件ab
追加写入文件ab
追加换行ab
Process finished with exit code 0
查看文件中内容
加写入文件ab
追加写入文件ab
追加换行ab
r++写入文件"以写的模式打开,然后可以读。所以会覆盖旧的内容,同样是危险的"
查看文件中内容
加写入文件ab
追加写入文件ab
追加换行ab
r++写入文件
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# Author: vita
f = open(file="写文件.txt", mode="w+", encoding="utf-8")
f.write("w++写入文件")
print(f.read())
f.close()
E:\PythonProject\python-test\venvP3\Scripts\python.exe E:/PythonProject/python-test/BasicGrammer/test.py
Process finished with exit code 0
查看文件内容
w++写入文件
@abstractmethod
def fileno(self) -> int:
pass
"返回文件句柄在内核中的索引值,以后做IO多路复用时可以用到"
@abstractmethod
def flush(self) -> None:
pass
"把文件从内存buffer里强制刷新到硬盘"
把文件从内存buffer里强制刷新到硬盘中
>>> f = open(file="写文件.txt", mode="w", encoding="UTF-8")
>>> f.write("写如硬盘flush测试")
12
这是看文件,文件中是空的
>>> f.close()
这时看文件,文件中内容
写如硬盘flush测试 @abstractmethod
def readable(self) -> bool:
pass
"判断文件是否可读" @abstractmethod
def readable(self) -> bool:
pass
"判断文件是否可读" @abstractmethod
def readline(self, limit: int = -1) -> AnyStr:
pass
只读一行,遇到\r或\n为止
>>> f = open(file="读文件.txt", mode="r", encoding="UTF-8")
>>> f.readline()
'哈哈\n'
>>> f.readline()
'呵呵\n'
>>> f.readline()
'呜呜'
>>> f.readline()
''
>>> @abstractmethod
def seek(self, offset: int, whence: int = 0) -> int:
pass
@abstractmethod
def tell(self) -> int:
pass
"seek按照字节读取,read()按照字符读取"
"tell返回文件光标当前所在的位置"
文件中内容
哈哈
呵呵
呜呜
>>> f = open(file="读文件.txt", mode="r", encoding="UTF-8")
>>> f.tell()
0
>>> f.seek(3)
3
>>> f.readline()
'哈\n'
>>> f.tell()
8
>>> f.seek(10)
10
>>> f.readlilne()
Traceback (most recent call last):
File "<stdin>", line 1, in <module>
AttributeError: '_io.TextIOWrapper' object has no attribute 'readlilne'
>>> f.seek(11)
11
>>> f.readline()
'呵\n'
>>> f.tell()
16
>>>
>>> f.read(1) --read按照字符读取
'呜'
>>> f.tell() --seek和tell是按照字节读取
19
@abstractmethod
def seekable(self) -> bool:
pass
"判断文件是否能进行seek操作"
@abstractmethod
def writable(self) -> bool:
pass
判断文件是否可写入 @abstractmethod
def truncate(self, size: int = None) -> int:
pass
"按照指定长度截断文件,不管当前位置在哪,都是留取从头开始的指定长度的内容"
"指定长度的话,就从文件开头开始截断指定长度,不指定长度的话,就从当前位置到文件尾部的内容全去掉"
文件中内容
你好中国
>>> f = open(file="读文件.txt", mode="r+", encoding="UTF-8")
>>> f.truncate()
0
查看文件内容,文件为空
>>> f = open(file="读文件.txt", mode="r+", encoding="UTF-8")
>>> f.truncate(3) --指定位置,这里面的3,意思是不管你在哪里,都是从头开始,保留3个字节,下面两个实验验证
3
>>> f.read() --查看只留下了一个字,其余的都删除了
'你'
验证一:
>>> f = open(file="读文件.txt", mode="r+", encoding="UTF-8")
>>> f.seek(3)
3
>>> f.truncate(6) --这里是从头开始,保留6个字节,所以文件中的内容最后为你好
6
>>> f.read()
'好'
>>>
查看文件内容
你好
验证二:
>>> f = open(file="读文件.txt", mode="r+", encoding="UTF-8")
>>> f.seek(6) --当前位置在第六字节处
6
>>> f.truncate(3) --截取从头开始,到第三字节处,所以文件中只剩下你
3
>>> f.read()
''
查看文件内容
你尝试直接以r+模式打开文件,默认会把新增的内容追加到文件最后面。但是如果想要修改中间的内容,怎样操作呢?
我们已经学了seek,之所以会把内容追加到最后面,是因为文件一打开,要写的时候,光标会默认移到文件的尾部,再开始写。现在如果想要修改中间的内容,是不是seek()到相应的位置,然后再写入即可呢?
下面进行操作
文件中原内容
你好中国
>>> f = open(file="读文件.txt", mode="r+", encoding="UTF-8")
>>> f.seek(6)
6
>>> f.write("吗")
1
>>> f.flush()
查看文件内容
你好吗国 --这里中被替换为了吗,并不是在"中"前面插入一个"吗",而是覆盖那个位置的内容
继续实验
>>> f.seek(3)
3
>>> f.write("nihao吗") --含有中文和英文,插入5个英文字符,占用5个字节,"吗"在UTF-8编码时占用3个字节,总共占用8个字节,由于源文件中全是中文,需要是3的倍数才不会乱码,这里占用8个字节就会乱码
6
>>> f.flush()
查看文件内容
你nihao吗�
重新实验,验证
文件中原内容
你好中国
>>> f = open(file="读文件.txt", mode="r+", encoding="UTF-8")
>>> f.seek(3)
3
>>> f.write("kkk吗") --这里英文和中文占用6个字节,刚好是原文件中的两个中文,所以没有乱码
4
>>> f.flush()
查看文件内容
你kkk吗国
"所以如果插入的内容和源文件中的相同位置的字节数相匹配,就不会乱码。但这种文件修改方式是覆盖原文件中相同位置处的内容,而不是插入内容"
要想实现在文件中间插入内容,有下面两种方式:"文件内容替换,占用硬盘方式"
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# Author: vita
# 占用硬盘的方式:即新建一个文件
source_file = "写文件.txt"
tmp_file = "写文件.txt.tmp"
s_f = open(file=source_file, mode="r", encoding="UTF-8")
t_f = open(file=tmp_file, mode="w", encoding="UTF-8")
for line in s_f:
if "深圳" in line:
line = line.replace("深圳", "北京")
t_f.write(line)
s_f.close()
t_f.close()
查看写文件.txt.tmp内容
马纤羽 北京 173 50 13744234523
乔亦菲 广州 172 52 15823423525
罗梦竹 北京 175 49 18623423421
刘诺涵 北京 170 48 18623423765
岳妮妮 北京 177 54 18835324553
贺婉萱 北京 174 52 18933434452
叶梓萱 上海 171 49 18042432324
杜姗姗 北京 167 49 13324523342
black girl 河北 167 50 13542342233"占用内存的方式"
#!/usr/bin/env python
# -*- coding:utf-8 -*-
# Author: vita
# 占用硬盘的方式:即新建一个文件
source_file = "写文件.txt"
s_f = open(file=source_file, mode="r+", encoding="UTF-8")
data = s_f.read()
data = data.replace("深圳", "北京")
s_f.seek(0)
s_f.truncate()
s_f.write(data)
s_f.close()
查看写文件.txt
马纤羽 北京 173 50 13744234523
乔亦菲 广州 172 52 15823423525
罗梦竹 北京 175 49 18623423421
刘诺涵 北京 170 48 18623423765
岳妮妮 北京 177 54 18835324553
贺婉萱 北京 174 52 18933434452
叶梓萱 上海 171 49 18042432324
杜姗姗 北京 167 49 13324523342
black girl 河北 167 50 13542342233免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。