您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
目前,各组织正在利用数据科学和机器学习来解决各种业务问题。为了创造一个真正的业务影响,如何弥合数据科学管道和业务决策管道之间的差距显得尤为重要。
数据科学管道的结果往往是数据中的预测、模式和洞察(通常没有任何约束的概念),但仅此一项并不足以让股东做出决定。数据科学的输出应该要接入某种商业决策导管;这个导管包含有一些可以模拟商业关键方面的限制和决策变量的改善。
例如,如果您正在运行一个超市链—您的数据科学管道将会预测预期的销售额。然后,您将接受这些输入的数据并创建一个优化的库存方式或销售策略。
在这篇文章中,我们将展示一个这样的例子,用线性优化来选择观看哪一个TED视频。
索引
线性优化导论
待解决问题–为TED视频创建观看列表
步骤1-导入相关软件包
步骤2-为TED会谈创建数据框架
步骤3-设置线性优化问题
步骤4-将优化结果转换为可理解的形式
在优化技术中,采用单纯形法进行线性优化是最有效的方法之一,也被评为二十世纪十大种算法之一。作为数据科学从业者,在实现线性优化方面有实际的知识是很重要的,这篇博文是用Python的PuLP包装来说明它的实现。
为了使事情变得有趣并容易理解,我们会通过将它应用于实际的日常问题来学习这种优化技术。与此同时,我们学到的东西也适用于各种商业问题。
TED是一个致力于传播思想的非营利组织。TED于1984年成立,以会议的形式融合了技术、娱乐和设计等方面的知识;到了今天,TED几乎涵盖了100多种语言中以及近乎所有主题—从科学到商业再到全球问题。TED演讲是由拥有丰富的信息并热爱其所在领域的专家们所提供的。
现在,别忘了这个博客文章的目的,想象一下这种情况:你想创建一个根据不同条件下的(可以观看的时间以及演讲的数量等)TED会谈最受欢迎的观看列表。我们来看看如何通过Python程序来帮助我们以最佳的方式创建观看列表。
本文的代码可以在这里找到。我的Jupyter的截图如下所示:

PuLP是在Python下的一款免费开源软件。它可以将优化问题描述为数学模型。PuLP也可以调用许多外部的LP求解程序(例如CBC,GLPK,CPLEX,Gurobi等)来解决这个模型,然后使用python命令来操作和显示解决方案。默认情况下,CoinMP求解程序是与PuLP捆绑在一起的。

从Kaggle下载所有TED演讲(2550)的数据集,都并写入数据框架。选择相关列的子集,并且结果数据集应包含以下详细信息—讲演的索引、讲演的名称、TED事件的名称、讲演的持续时间(以分钟计)、视图数(代表演讲的人气)

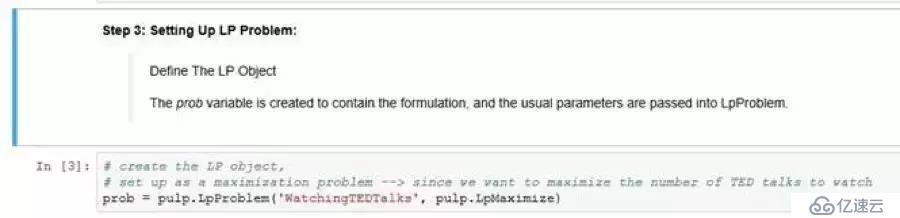
从定义LP对象开始;问题变量的创建是为了控制问题制定。
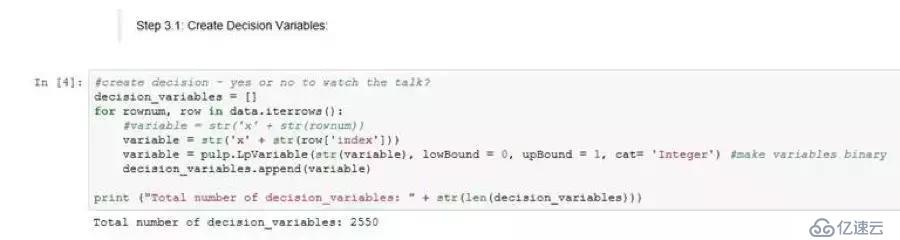
步骤3.1:创建决策变量
遍历数据框架的每一行以创建决策变量,以便每个讲演都成为一个决策变量。因为每个讲演都可以被选择或者不被选择为最后的观看名单的一部分,决策变量本质上是二进制的(1=选定,0=未选定)
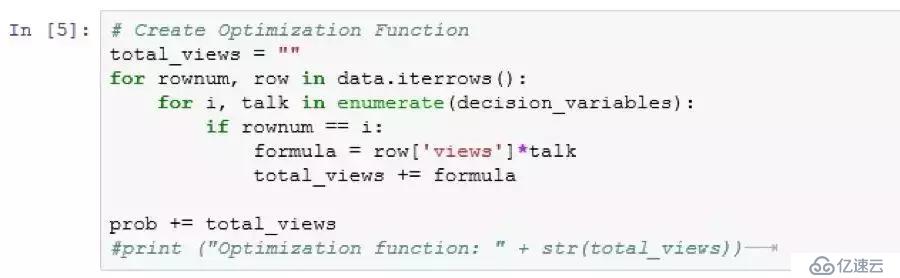
步骤3.2:定义目标函数
目标函数是每个讲演观看量的所有行的总和。这些观看量作为讲演的受欢迎度的代表,因此在本质上我们试图通过选择适当的谈话(决策变量)来最大化观看量(受欢迎度)
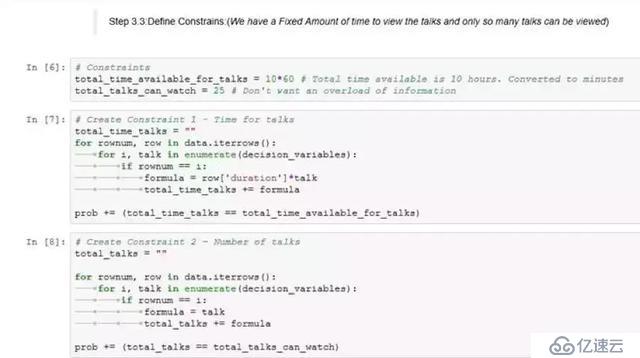
步骤3.3:定义约束
在这个问题上,我们有两个约束:
a)我们只有固定的总时间,这些时间可以被分配来观看会谈
b)我们不希望观看超过一定数量的会谈,以避免信息超载
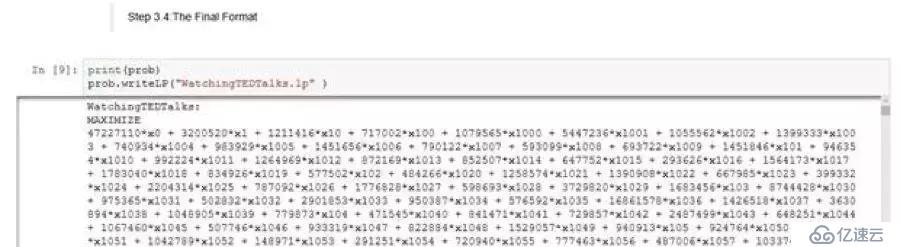
步骤3.4:最终格式(对于问题的制定)
所制定问题的最终格式会被写出到一个.lp文件中。这将列出目标函数、决策变量以及对问题施加的约束。
步骤3.5:实际优化
实际优化就是一行叫做"prob.solve"的代码。插入一句说明语句以确定是否为该问题获得了最佳结果。
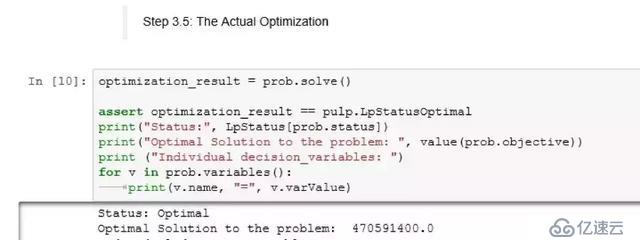
表明特定的、被选上以最大化输出的决策变量(讲演)的优化结果,必须转换成观看列表的格式,如下所示:


本文展示了如何利用Python中可用的线性优化技术,来解决创建视频观看列表的日常问题。所学的概念同样适用于更复杂的业务情况,比如涉及到数以千计的决策变量或是有许多不同的约束。
每一位数据科学从业者都需要将"优化技术"添加到他们的知识体系中,这样他们就可以使用高级的分析方式来解决现实世界中的业务问题。这篇文章旨在帮助您朝着这个方向迈出第一步。
免责声明:所有翻译文章旨在技术传播和学习交流,非商业用途。原作者:Karthikeyan Sankaran
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。