жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
иҝҷзҜҮж–Үз« з»ҷеӨ§е®¶д»Ӣз»ҚжҖҺд№ҲеңЁRedisдёӯе®һзҺ°жҢҒд№…еҢ–дёҺдё»д»ҺеӨҚеҲ¶пјҢеҶ…е®№йқһеёёиҜҰз»ҶпјҢж„ҹе…ҙи¶Јзҡ„е°Ҹдјҷдјҙ们еҸҜд»ҘеҸӮиҖғеҖҹйүҙпјҢеёҢжңӣеҜ№еӨ§е®¶иғҪжңүжүҖеё®еҠ©гҖӮ
RedisжҳҜеҹәдәҺеҶ…еӯҳзҡ„NoSQLж•°жҚ®еә“пјҢиҜ»еҶҷйҖҹеәҰиҮӘ然еҝ«пјҢдҪҶеҶ…еӯҳжҳҜзһ¬ж—¶зҡ„пјҢеңЁredisжңҚеҠЎе…ій—ӯжҲ–йҮҚеҗҜд№ӢеҗҺпјҢredisеӯҳж”ҫеңЁеҶ…еӯҳзҡ„ж•°жҚ®е°ұдјҡдёўеӨұпјҢдёәдәҶи§ЈеҶіиҝҷдёӘй—®йўҳпјҢredisжҸҗдҫӣдәҶдёӨз§ҚжҢҒд№…еҢ–ж–№ејҸпјҢд»ҘдҫҝеңЁеҸ‘з”ҹж•…йҡңеҗҺжҒўеӨҚж•°жҚ®гҖӮ
redisжҸҗдҫӣдәҶдёӨз§ҚдёҚеҗҢзҡ„жҢҒд№…еҢ–ж–№ејҸжқҘе°Ҷж•°жҚ®еӯҳеӮЁеҲ°зЎ¬зӣҳдёӯгҖӮдёҖз§ҚжҳҜеҝ«з…§ж–№ејҸпјҲд№ҹеҸ«RDBж–№ејҸпјүпјҢе®ғеҸҜд»Ҙе°ҶиҺ«дёҖж—¶еҲ»еӯҳеңЁдәҺredisдёӯзҡ„жүҖжңүж•°жҚ®еӯҳеӮЁеҲ°зЎ¬зӣҳпјӣеҸҰдёҖз§ҚеҸ«еҸӘиҝҪеҠ ж–Ү件пјҲAOFпјүж–№ејҸпјҢе®ғдјҡе®ҡж—¶зҡ„еӨҚеҲ¶redisжү§иЎҢзҡ„жүҖжңүеҶҷе‘Ҫд»ӨеҲ°зЎ¬зӣҳгҖӮиҝҷдёӨз§ҚжҢҒд№…еҢ–ж–№ејҸеҗ„жңүеҚғз§ӢпјҢж—ўеҸҜд»ҘеҗҢж—¶дҪҝз”ЁпјҢд№ҹеҸҜд»ҘзӢ¬з«ӢдҪҝз”ЁпјҢеңЁжҹҗдәӣжғ…еҶөдёӢз”ҡиҮіеҸҜд»ҘдёӨз§ҚйғҪдёҚдҪҝз”ЁгҖӮ
RDBж–№ејҸ
RDBж–№ејҸд№ҹз§°еҝ«з…§ж–№ејҸпјҢйҖҡиҝҮеҲӣе»әеҝ«з…§жқҘдҝқеӯҳжҹҗдёӘж—¶й—ҙзӮ№дёҠзҡ„ж•°жҚ®еүҜжң¬пјҲ.rdbпјүеҲ°зЎ¬зӣҳгҖӮеңЁйҮҚеҗҜжңҚеҠЎеҷЁеҗҺпјҢredisдјҡеҠ иҪҪиҝҷдёӘrdbж–Ү件жқҘиҝҳеҺҹж•°жҚ®гҖӮе…ҲжқҘзңӢдёҖдёӢrdbжҢҒд№…еҢ–й…ҚзҪ®гҖӮvi redis.confжү“ејҖredisзҡ„й…ҚзҪ®ж–Ү件пјҢжүҫеҲ°SNAPSHOTTINGйғЁеҲҶ,еҸ‘зҺ°еҰӮдёӢеҶ…е®№пјҡ
save 900 1 save 300 10 save 60 10000 вҖҰвҖҰ dbfilename dump.rdb dir ./
иҜҙжҳҺ
save seconds changesпјҡиЎЁзӨәеңЁsecondsз§’еҗҺпјҢеҰӮжһңжңүдёҚе°‘дёҺchangesдёӘkeyеҸ‘з”ҹж”№еҸҳпјҢеҲҷдҝқеӯҳдёҖж¬Ўеҝ«з…§гҖӮеҸҜд»ҘзңӢеҲ°пјҢrdbжҢҒд№…еҢ–й»ҳи®ӨжҳҜејҖеҗҜзҡ„пјҢ并且й…ҚзҪ®дәҶдёүдёӘsaveйҖүйЎ№пјҢеҰӮжһңжғіиҰҒе…ій—ӯrdbжҢҒд№…еҢ–пјҢе°ҶжүҖжңүзҡ„saveжіЁйҮҠжҺүе°ұеҘҪдәҶ
dbfilenameпјҡrdbж–Ү件еҗҚ
dirпјҡrdbж–Ү件еӯҳж”ҫи·Ҝеҫ„
еҲӣе»әеҝ«з…§
BGSAVEпјҡBGSAVEе‘Ҫд»ӨеҸҜд»Ҙз”ЁдәҺеҲӣе»әдёҖдёӘеҝ«з…§пјҢеңЁredisжҺҘ收еҲ°BGSAVEе‘Ҫд»ӨеҗҺдјҡforkеҮәдёҖдёӘеӯҗиҝӣзЁӢпјҢеӯҗиҝӣзЁӢиҙҹиҙЈе°Ҷеҝ«з…§еҶҷе…ҘзЎ¬зӣҳпјҢиҖҢзҲ¶иҝӣзЁӢеҲҷ继з»ӯеӨ„зҗҶе‘Ҫд»ӨиҜ·жұӮгҖӮйңҖиҰҒжіЁж„Ҹзҡ„жҳҜredisеңЁеҲӣе»әеӯҗиҝӣзЁӢж—¶дјҡйҳ»еЎһзҲ¶иҝӣзЁӢпјҢж—¶й—ҙй•ҝзҹӯдёҺredisеҚ з”Ёзҡ„еҶ…еӯҳеӨ§е°ҸжҲҗжӯЈжҜ”гҖӮ
йҷӨдәҶжүӢеҠЁзҡ„и°ғз”ЁBGSAVEе‘Ҫд»ӨеӨ–пјҢBGSAVEе‘Ҫд»Өзҡ„и§ҰеҸ‘жқЎд»¶жңүеҰӮдёӢдёӨз§Қпјҡ
з”ЁжҲ·й…ҚзҪ®дәҶsaveйҖүйЎ№пјҢд»ҺredisжңҖиҝ‘дёҖж¬ЎеҲӣе»әеҝ«з…§ејҖе§Ӣз®—иө·пјҢеҪ“д»»ж„ҸдёҖдёӘsaveйҖүйЎ№зҡ„жқЎд»¶иў«ж»Ўи¶іж—¶пјҢдјҡи§ҰеҸ‘дёҖж¬ЎBGSAVEе‘Ҫд»ӨгҖӮ
еңЁиҝӣиЎҢдё»д»ҺеӨҚеҲ¶иҝһжҺҘж—¶пјҢеҲҡиҝһдёҠжқҘзҡ„д»ҺжңҚеҠЎеҷЁдјҡеҗ‘дё»жңҚеҠЎеҷЁеҸ‘йҖҒSYNCе‘Ҫд»ӨиҜ·жұӮж•°жҚ®еҗҢжӯҘпјҢеңЁдё»жңҚеҠЎеҷЁж”¶еҲ°SYNCе‘Ҫд»ӨеҗҺпјҢдјҡжү§иЎҢдёҖж¬ЎBGSAVEе‘Ҫд»ӨпјҢеҗҺе°Ҷз”ҹжҲҗзҡ„rdbж–Ү件еҸ‘йҖҒз»ҷд»ҺжңҚеҠЎеҷЁиҝӣиЎҢж•°жҚ®еҗҢжӯҘгҖӮ
SAVEпјҡSAVEе‘Ҫд»ӨеҗҢж ·еҸҜд»ҘеҲӣе»әдёҖдёӘеҝ«з…§пјҢдҪҶдёҺBGSAVEе‘Ҫд»ӨдёҚеҗҢзҡ„жҳҜSAVEе‘Ҫд»ӨдёҚдјҡеҲӣе»әеӯҗиҝӣзЁӢпјҢжүҖд»ҘжҺҘ收еҲ°SAVEе‘Ҫд»Өзҡ„redisжңҚеҠЎеҷЁеңЁеҝ«з…§еҲӣе»әе®ҢжҜ•д№ӢеүҚдёҚдјҡе“Қеә”е…¶д»–д»»дҪ•е‘Ҫд»ӨгҖӮз”ұдәҺеңЁеҲӣе»әеҝ«з…§зҡ„иҝҮзЁӢдёӯжІЎжңүе…¶д»–иҝӣзЁӢжҠўеӨәиө„жәҗпјҢжүҖд»ҘSAVEе‘Ҫд»ӨеҲӣе»әеҝ«з…§зҡ„йҖҹеәҰдјҡжҜ”BGSAVEе‘Ҫд»ӨеҲӣе»әеҝ«з…§жӣҙеҝ«дёҖдәӣгҖӮеҚідҪҝиҝҷж ·пјҢSAVEе‘Ҫд»Өд№ҹ并дёҚеёёз”ЁпјҢйҖҡеёёеҸӘдјҡеңЁжІЎжңүи¶іеӨҹеҶ…еӯҳжҲ–зӯүеҫ…еҝ«з…§з”ҹжҲҗе®ҢжҜ•д№ҹж— жүҖи°“зҡ„жғ…еҶөдёӢжүҚдјҡдҪҝз”ЁгҖӮ
дҫӢеҰӮпјҢеҪ“redis收еҲ°SHUTDOWNе‘Ҫд»Өе…ій—ӯжңҚеҠЎж—¶пјҢе°ұдјҡжү§иЎҢдёҖж¬ЎSAVEе‘Ҫд»ӨпјҢйҳ»еЎһжүҖжңүе®ўжҲ·з«ҜпјҢ并еңЁSAVEе‘Ҫд»Өжү§иЎҢе®ҢжҜ•еҗҺе…ій—ӯгҖӮ
RDBж–№ејҸзҡ„дјҳеҠЈ
дјҳеҠҝпјҡ
д»…з”ЁдёҖдёӘж–Ү件еӨҮд»Ҫж•°жҚ®пјҢзҒҫеҗҺжҳ“дәҺжҒўеӨҚзӣёжҜ”дәҺaofпјҢrdbж–Ү件жӣҙе°ҸпјҢ并且еҠ иҪҪrdbж–Ү件жҒўеӨҚж•°жҚ®д№ҹжӣҙеҝ«
еҠЈеҠҝпјҡ
еҰӮжһңredisжңҚеҠЎеӣ ж•…йҡңе…ій—ӯжҲ–йҮҚеҗҜпјҢдјҡдёўеӨұжңҖиҝ‘дёҖж¬Ўеҝ«з…§еҲӣе»әеҗҺеҶҷе…Ҙзҡ„ж•°жҚ®еҪ“ж•°жҚ®йҮҸеҫҲеӨ§зҡ„ж—¶еҖҷпјҢеҲӣе»әеӯҗиҝӣзЁӢдјҡеҜјиҮҙredisиҫғй•ҝж—¶й—ҙзҡ„еҒңйЎҝ
AOFж–№ејҸ
з®ҖеҚ•жқҘиҜҙпјҢAOFжҢҒд№…еҢ–дјҡе°Ҷиў«жү§иЎҢзҡ„еҶҷе‘Ҫд»ӨеҶҷеҲ°aofж–Ү件зҡ„жң«е°ҫпјҢд»ҘжӯӨжқҘи®°еҪ•ж•°жҚ®еҸ‘з”ҹзҡ„еҸҳеҢ–гҖӮеӣ жӯӨпјҢredisеҸӘиҰҒд»ҺеӨҙеҲ°е°ҫйҮҚж–°жү§иЎҢдёҖйҒҚaofж–Ү件дёӯеҢ…еҗ«зҡ„жүҖжңүеҶҷе‘Ҫд»ӨпјҢе°ұеҸҜд»ҘжҒўеӨҚж•°жҚ®гҖӮ
жү“ејҖredisй…ҚзҪ®ж–Ү件еҸҜд»ҘзңӢеҲ°пјҡ
# жҳҜеҗҰејҖеҗҜaofжҢҒд№…еҢ–пјҢй»ҳи®Өдёәе…ій—ӯпјҲnoпјү appendonly yes # и®ҫзҪ®еҜ№aofж–Ү件зҡ„еҗҢжӯҘйў‘зҺҮ # жҜҸжҺҘ收еҲ°дёҖжқЎеҶҷе‘Ҫд»Өе°ұиҝӣиЎҢдёҖж¬ЎеҗҢжӯҘпјҢж•°жҚ®дҝқйҡңжңҖжңүеҠӣпјҢдҪҶеҜ№жҖ§иғҪеҪұе“ҚеҚҒеҲҶдёҘйҮҚ appendfsync always # жҜҸз§’иҝӣиЎҢдёҖж¬ЎеҗҢжӯҘпјҢжҺЁиҚҗ appendfsync everysec # з”ұж“ҚдҪңзі»з»ҹжқҘеҶіе®ҡдҪ•ж—¶иҝӣиЎҢеҗҢжӯҘ appendfsync no # йҮҚеҶҷaofзӣёе…і auto-aof-rewrite-percentage 100 auto-aof-rewrite-min-size 64mb
йҮҚеҶҷ/еҺӢзј©aofж–Ү件
з”ұдәҺaofжҢҒд№…еҢ–дјҡдёҚж–ӯең°и®°еҪ•redisзҡ„еҶҷе‘Ҫд»ӨпјҢйҡҸзқҖredisзҡ„иҝҗиЎҢпјҢaofж–Ү件дјҡи¶ҠжқҘи¶ҠеӨ§пјҢеҚ з”ЁиҝҮеӨҡзҡ„зЎ¬зӣҳз©әй—ҙпјҢ并еўһеҠ redisиҝӣиЎҢж•°жҚ®иҝҳеҺҹж“ҚдҪңзҡ„ж—¶й—ҙгҖӮеӣ жӯӨпјҢеҝ…йЎ»иҰҒжңүйҒҝе…Қaofж–Ү件дҪ“з§ҜиҝҮеӨ§зҡ„жҺ§еҲ¶ж–№жЎҲгҖӮ
redisжҸҗдҫӣдәҶBGREWRITEAOFе‘Ҫд»ӨеҜ№aofж–Ү件иҝӣиЎҢйҮҚеҶҷпјҢBGREWRITEAOFдјҡйҖҡиҝҮ移йҷӨеҺҹaofж–Ү件дёӯеҶ—дҪҷзҡ„е‘Ҫд»ӨжқҘе°ҪеҸҜиғҪзҡ„еҮҸе°Ҹaofж–Ү件зҡ„дҪ“з§ҜгҖӮBGREWRITEAOFзҡ„е·ҘдҪңеҺҹзҗҶдёҺBGSAVEеҫҲеғҸпјҢдјҡз”ұredisеҲӣе»әдёҖдёӘеӯҗиҝӣзЁӢпјҢеҶҚз”ұеӯҗиҝӣзЁӢеҜ№aofж–Ү件иҝӣиЎҢйҮҚеҶҷгҖӮ
еҪ“然пјҢBGREWRITEAOFе‘Ҫд»ӨеҗҢж ·д№ҹжңүиҮӘеҠЁи§ҰеҸ‘зҡ„жңәеҲ¶пјҢеҸҜйҖҡиҝҮй…ҚзҪ®auto-aof-rewrite-percentageе’Ңauto-aof-rewrite-min-sizeжқҘиҮӘеҠЁжү§иЎҢгҖӮдҫӢеҰӮпјҢй…ҚзҪ®дәҶauto-aof-rewrite-percentage 100 е’Ң auto-aof-rewrite-min-size 64mbпјҢ并且ејҖеҗҜдәҶaofжҢҒд№…еҢ–пјҢйӮЈд№ҲеңЁaofж–Ү件дҪ“з§ҜеӨ§дәҺ64mbдё”еҪ“еүҚж–Ү件жҜ”дёҠдёҖж¬ЎйҮҚеҶҷеҗҺзҡ„ж–Ү件дҪ“з§ҜеӨ§дәҶдёҖеҖҚ(100%)д»ҘдёҠж—¶пјҢredisдјҡиҮӘеҠЁжү§иЎҢBGREWRITEAOFе‘Ҫд»ӨгҖӮ
AOFжҢҒд№…еҢ–зҡ„дјҳеҠЈ
дјҳеҠҝ
еҸҜд»Ҙе°ҶдёўеӨұж•°жҚ®зҡ„ж—¶й—ҙзӘ—еҸЈйҷҚдҪҺиҮі1з§’пјҢ并且дёҚдјҡеҜ№жҖ§иғҪеңЁжҲҗеӨӘеӨ§еҪұе“ҚaofеҜ№дәҺж—Ҙеҝ—ж–Ү件йҮҮз”Ёзҡ„жҳҜиҝҪеҠ жЁЎејҸпјҢеӣ жӯӨеңЁеҶҷе…ҘиҝҮзЁӢдёӯеҚідҪҝеҮәзҺ°е®•жңәпјҢд№ҹдёҚдјҡз ҙеқҸж—Ҙеҝ—ж–Ү件дёӯе·Із»ҸеӯҳеңЁзҡ„еҶ…е®№пјӣиӢҘеҸӘеҶҷе…ҘдёҖеҚҠж•°жҚ®е°ұе®•жңәпјҢеңЁredisдёӢж¬ЎеҗҜеҠЁж—¶пјҢеҸҜйҖҡиҝҮredis-check-aodе·Ҙе…·жқҘи§ЈеҶіж•°жҚ®дёҖиҮҙжҖ§зҡ„й—®йўҳ
еҠЈеҠҝ
aofж–Ү件зҡ„дҪ“з§ҜдёҖзӣҙжҳҜAOFжҢҒд№…еҢ–жңҖеӨ§зҡ„зјәйҷ·пјҢеҚідҪҝжңүйҮҚеҶҷaofж–Ү件зҡ„жңәеҲ¶еӯҳеңЁиҪҪе…Ҙaofж–Ү件жҒўеӨҚж•°жҚ®зҡ„иҝҮзЁӢдјҡжҜ”иҪҪе…Ҙrdbж–Ү件иҖ—ж—¶жӣҙй•ҝ
е°Ҫз®ЎredisжҖ§иғҪеҚҒеҲҶдјҳз§ҖпјҢдҪҶиҝҳжҳҜдјҡйҒҮеҲ°ж— жі•еҝ«йҖҹеӨ„зҗҶиҜ·жұӮзҡ„й—®йўҳпјҢдёәдәҶжҠ—й«ҳ并еҸ‘еёҰжқҘзҡ„ж•°жҚ®еә“жҖ§иғҪй—®йўҳпјҢredisеҸҜд»ҘеғҸе…ізі»еһӢж•°жҚ®еә“дёҖж ·иҝӣиЎҢдё»д»ҺеӨҚеҲ¶гҖҒиҜ»еҶҷеҲҶзҰ»гҖӮеҚіеҗ‘дё»жңҚеҠЎеҷЁеҶҷе…Ҙж•°жҚ®пјҢд»ҺжңҚеҠЎеҷЁе®һ时收еҲ°жӣҙж–°пјҢ并дҪҝз”Ёд»ҺжңҚеҠЎеҷЁеӨ„зҗҶжүҖжңүзҡ„иҜ»иҜ·жұӮпјҢиҖҢдёҚжҳҜеғҸд»ҘеүҚдёҖж ·е°ҶжүҖжңүиҜ»иҜ·жұӮйғҪеҸ‘йҖҒз»ҷдё»жңҚеҠЎеҷЁпјҢйҖ жҲҗдё»жңҚеҠЎеҷЁеҺӢеҠӣиҝҮеӨ§пјҢйҖҡеёёиҜ»иҜ·жұӮдјҡйҡҸжңәең°йҖүжӢ©дҪҝз”Ёе“ӘдёҖдёӘд»ҺжңҚеҠЎеҷЁпјҢд»ҺиҖҢдҪҝиҙҹиҪҪеқҮиЎЎең°еҲҶй…ҚеҲ°жҜҸдёҖдёӘд»ҺжңҚеҠЎеҷЁдёҠгҖӮдёӢеӣҫжҳҜдёҖдёӘз®ҖеҚ•зҡ„redisдё»д»Һжһ¶жһ„гҖӮ
йҰ–е…ҲеңЁдҪ зҡ„redisзӣ®еҪ•дёӢжү§иЎҢvi redis6380.confеңЁеҪ“еүҚзӣ®еҪ•дёӢеҲӣе»әдёҖдёӘredisй…ҚзҪ®ж–Ү件пјҢеҶҷе…ҘеҰӮдёӢеҶ…е®№пјҡ
include /usr/local/redis-4.0.13/redis.conf port 6380 pidfile /var/run/redis_6380.pid logfile 6380.log dbfilename dump6380.rdb
иҜҙжҳҺпјҡ
includeпјҡеҗ‘еҪ“еүҚй…ҚзҪ®ж–Ү件дёӯеј•е…ҘжүҖжҢҮеҗ‘зҡ„й…ҚзҪ®ж–Ү件зҡ„й…ҚзҪ®дҝЎжҒҜпјҢиҝҷйҮҢеј•е…Ҙзҡ„жҳҜredisй»ҳи®Өй…ҚзҪ®ж–Ү件пјҢе…¶дёӯе·Із»Ҹи®ҫзҪ®иҝҮиҝңзЁӢи®ҝй—®гҖҒеҜҶз ҒзӯүпјҢжІЎеҝ…иҰҒеңЁж–°зҡ„й…ҚзҪ®ж–Ү件дёӯйҮҚж–°и®ҫзҪ®гҖӮеҜ№дәҺжңүеҝ…иҰҒйҮҚж–°й…ҚзҪ®зҡ„й…ҚзҪ®дҝЎжҒҜжқҘиҜҙпјҲеҰӮз«ҜеҸЈеҸ·пјүпјҢincludeиЎҢдёӢиҝӣиЎҢзҡ„й…ҚзҪ®еҸҜд»ҘиҰҶзӣ–еј•з”Ёзҡ„й…ҚзҪ®гҖӮ
portпјҡз«ҜеҸЈеҸ·пјҢжҲ‘们зҡ„дё»д»ҺжңҚеҠЎеҷЁжҳҜи·‘еңЁеҗҢдёҖеҸ°иҷҡжӢҹжңәдёҠзҡ„пјҢеӣ жӯӨйңҖиҰҒй…ҚзҪ®дёҚеҗҢзҡ„з«ҜеҸЈеҸ·гҖӮ
pidfileпјҡиҮӘе®ҡд№үзҡ„pidж–Ү件пјҢеҗҺеҸ°зЁӢеәҸзҡ„pidеӯҳеңЁиҝҷдёӘж–Ү件йҮҢгҖӮ
logfileпјҡж—Ҙеҝ—ж–Ү件гҖӮ
dbfilenameпјҡrdbж–Ү件зҡ„еҗҚеӯ—гҖӮ
з»ҸиҝҮдёҠиҝ°ж“ҚдҪңпјҢдёҖдёӘж–°зҡ„дё»жңҚеҠЎеҷЁе°ұй…ҚзҪ®еҘҪдәҶпјҢжҺҘдёӢжқҘй…ҚзҪ®д»ҺжңҚеҠЎеҷЁпјҢеҗҢж ·еңЁеҪ“еүҚзӣ®еҪ•дёӢеҲӣе»әдёҖдёӘredisй…ҚзҪ®ж–Ү件иө·еҗҚredis6382vi redis6382.conf
include /usr/local/redis-4.0.13/redis.conf port 6382 pidfile /var/run/redis_6382.pid logfile 6382.log dbfilename dump6382.rdb slaveof 127.0.0.1 6380 masterauth дё»жңҚеҠЎеҷЁзҡ„еҜҶз Ғ
е…¶дёӯжңүдёҖдәӣд»ҺжңҚеҠЎеҷЁйўқеӨ–зҡ„й…ҚзҪ®пјҡ
slaveofпјҡиЎЁзӨәжҲ‘жҳҜи°Ғзҡ„д»ҺжңҚеҠЎеҷЁпјҢйңҖиҰҒеҲ¶е®ҡдё»жңҚеҠЎеҷЁзҡ„ipең°еқҖе’Ңз«ҜеҸЈеҸ·
masterauthпјҡеҒҮеҰӮдҪ зҡ„дё»жңҚеҠЎеҷЁй…ҚзҪ®дәҶеҜҶз ҒпјҢйӮЈд№ҲйңҖиҰҒеңЁжӯӨиҝӣиЎҢй…ҚзҪ®пјҢеҗҰеҲҷд»ҺжңҚеҠЎеҷЁе°Ҷж— жі•иҝһжҺҘеҲ°дё»жңҚеҠЎеҷЁ
е…¶д»–зҡ„д»ҺжңҚеҠЎеҷЁй…ҚзҪ®д№ҹйғҪзұ»дјјпјҢжіЁж„ҸеҲҶй…Қз«ҜеҸЈеҸ·пјҢжҲ‘иҝҷйҮҢеҸҲй…ҚзҪ®дәҶдёҖдёӘ6384гҖӮ
й…ҚзҪ®жҲҗеҠҹеҗҺпјҢеңЁsrcзӣ®еҪ•дёӢдҪҝз”Ё./redis-server ../redis6380.confе°ұеҸҜд»ҘејҖеҗҜдё»жңҚеҠЎеҷЁдәҶпјҢжҺҘдёӢжқҘејҖеҗҜд»ҺжңҚеҠЎеҷЁдјҡиҮӘеҠЁиҝһеҲ°дё»жңҚеҠЎеҷЁдёҠпјҢжіЁж„ҸжҢҮе®ҡеҜ№еә”зҡ„й…ҚзҪ®ж–Ү件гҖӮ
жү§иЎҢps -ef | grep redisзңӢеҲ°еҰӮдёӢеҶ…е®№еҲҷиЎЁзӨәдё»д»ҺжңҚеҠЎеҷЁеҗҜеҠЁжҲҗеҠҹпјҡ
root 2625 1 0 16:15 ? 00:00:00 ./redis-server *:6380 root 2630 1 0 16:15 ? 00:00:00 ./redis-server *:6382 root 2636 1 0 16:15 ? 00:00:00 ./redis-server *:6384
еңЁдё»д»ҺжңҚеҠЎеҷЁйғҪеҗҜеҠЁеҘҪдәҶд»ҘеҗҺпјҢиҝӣе…Ҙдё»жңҚеҠЎеҷЁзҡ„е®ўжҲ·з«Ҝ./redis-cli -p 6380 -a дҪ зҡ„еҜҶз ҒпјҢжү§иЎҢinfo replicationеҸҜд»ҘжҹҘзңӢдё»д»ҺжңҚеҠЎеҷЁдҝЎжҒҜпјҢеҰӮдёӢ
127.0.0.1:6380> info replication # Replication role:master connected_slaves:2 slave0:ip=127.0.0.1,port=6382,state=online,offset=336,lag=1 slave1:ip=127.0.0.1,port=6384,state=online,offset=336,lag=1 master_replid:b5c68a979b28d2a9ef53476510758b5d1795418b master_replid2:0000000000000000000000000000000000000000 master_repl_offset:336 second_repl_offset:-1 repl_backlog_active:1 repl_backlog_size:1048576 repl_backlog_first_byte_offset:1 repl_backlog_histlen:336
еҗҢж ·пјҢеңЁд»ҺжңҚеҠЎеҷЁе®ўжҲ·з«Ҝдёӯжү§иЎҢдёҠиҝ°е‘Ҫд»ӨпјҢд№ҹиғҪеӨҹеҫ—еҲ°дҝЎжҒҜ
127.0.0.1:6384> info replication # Replication role:slave master_host:127.0.0.1 master_port:6380 master_link_status:up master_last_io_seconds_ago:2 master_sync_in_progress:0 slave_repl_offset:686 slave_priority:100 slave_read_only:1 connected_slaves:0 master_replid:b5c68a979b28d2a9ef53476510758b5d1795418b master_replid2:0000000000000000000000000000000000000000 master_repl_offset:686 second_repl_offset:-1 repl_backlog_active:1 repl_backlog_size:1048576 repl_backlog_first_byte_offset:15 repl_backlog_histlen:672
иҮіжӯӨпјҢдёҖдёӘдёҖдё»дёӨд»ҺгҖҒиҜ»еҶҷеҲҶзҰ»зҡ„redisжһ¶жһ„е·Із»Ҹй…ҚзҪ®еҘҪ并жҲҗеҠҹеҗҜеҠЁдәҶгҖӮ
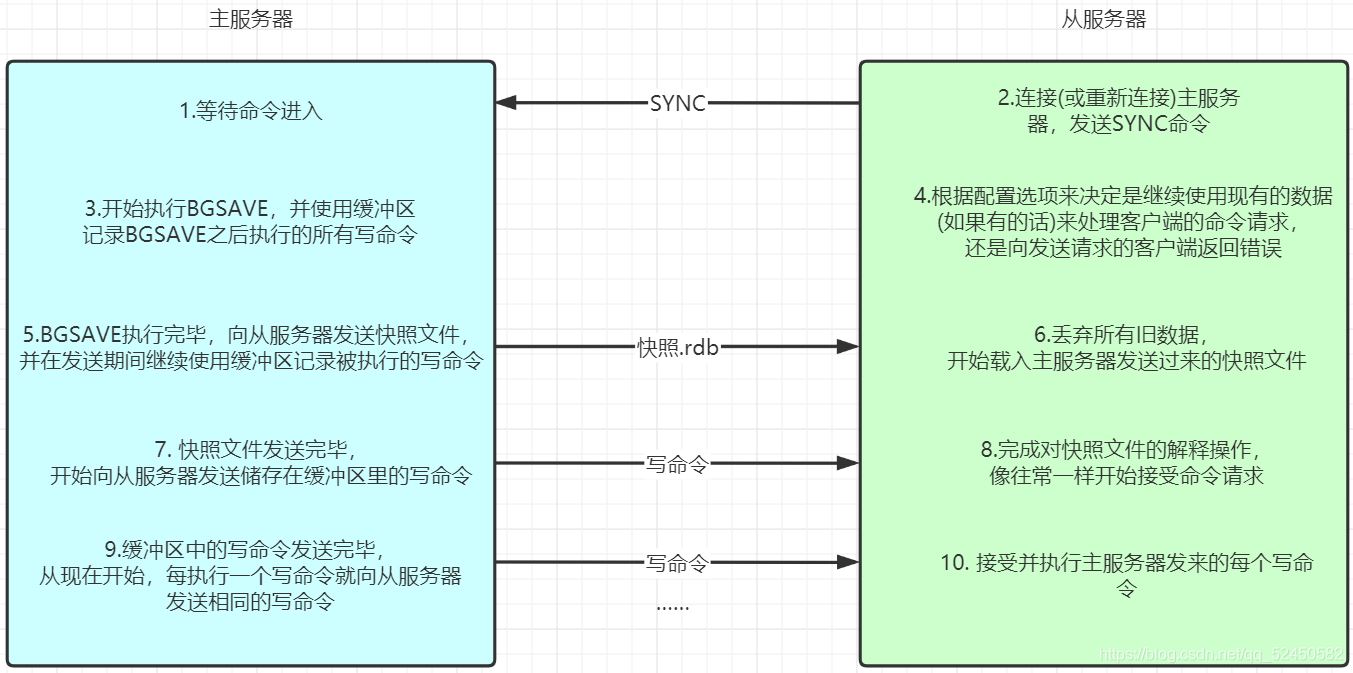
дёҠеӣҫжҳҜж—§зүҲдё»д»ҺRedisзҡ„еҗҜеҠЁиҝҮзЁӢпјҢйңҖиҰҒзү№ж®ҠиҜҙжҳҺзҡ„еҮ зӮ№жҳҜпјҡ
д»ҺжңҚеҠЎеҷЁеңЁиҝӣиЎҢеҲқе§ӢиҝһжҺҘзҡ„ж—¶еҖҷпјҢж•°жҚ®еә“дёӯеҺҹжңүзҡ„жүҖжңүж•°жҚ®йғҪе°Ҷиў«дёўеӨұпјҢ并жӣҝжҚўжҲҗдё»жңҚеҠЎеҷЁеҸ‘йҖҒжқҘзҡ„ж•°жҚ®
д»ҺжңҚеҠЎеҷЁдёҚиҙҹиҙЈkeyзҡ„иҝҮжңҹж“ҚдҪңпјҢиҖҢжҳҜиў«еҠЁзҡ„жҺҘеҸ—дё»жңҚеҠЎеҷЁеҸ‘жқҘзҡ„е‘Ҫд»ӨпјҢеҪ“дёҖдёӘ master и®©дёҖдёӘ key еҲ°жңҹпјҲжҲ–з”ұдәҺ LRU з®—жі•е°Ҷд№Ӣй©ұйҖҗпјүж—¶пјҢе®ғдјҡеҗҲжҲҗдёҖдёӘ DEL е‘Ҫд»Өе№¶дј иҫ“еҲ°жүҖжңүзҡ„ slave
SYNCжҳҜдёҖдёӘйқһеёёиҖ—иҙ№иө„жәҗзҡ„ж“ҚдҪңпјҢеңЁBGSAVEжңҹй—ҙдё»жңҚеҠЎеҷЁзҡ„жҖ»еҗһеҗҗйҮҸдёӢйҷҚпјҢжҺҘзқҖиҖ—иҙ№еӨ§йҮҸзҡ„дё»д»ҺжңҚеҠЎеҷЁзҡ„зҪ‘з»ңиө„жәҗдј йҖҒrdbж–Ү件пјҢеңЁд»ҺжңҚеҠЎеҷЁиҪҪе…Ҙrdbж–Ү件时дјҡж— жі•е“Қеә”е®ўжҲ·з«Ҝзҡ„иҜ·жұӮпјӣдҪҶSYNCжңҖеӨ§зҡ„зјәйҷ·жҳҜеңЁд»ҺжңҚеҠЎеҷЁеӣ ж–ӯзәҝиҝӣиЎҢйҮҚж–°иҝһжҺҘж—¶пјҢжІЎеҝ…иҰҒз”іиҜ·дёҖдёӘrdbж–Ү件д»ҺеӨҙеҶҚеҠ иҪҪдёҖж¬ЎпјҢеӣ дёәиҝҷдёӘж–°зҡ„rdbж–Ү件дёӯеҢ…еҗ«зҡ„еӨ§йғЁеҲҶж•°жҚ®еҫҲеҸҜиғҪеңЁж–ӯзәҝд№ӢеүҚе°ұе·Із»ҸеҶҷе…ҘдәҶд»ҺжңҚеҠЎеҷЁпјҢжӯӨж—¶д»ҺжңҚеҠЎеҷЁеҸӘйңҖиҰҒеҫ—еҲ°еңЁж–ӯзәҝжңҹй—ҙеҶҷе…Ҙзҡ„ж•°жҚ®е°ұеҫ—дәҶ
йғЁеҲҶйҮҚеҗҢжӯҘ
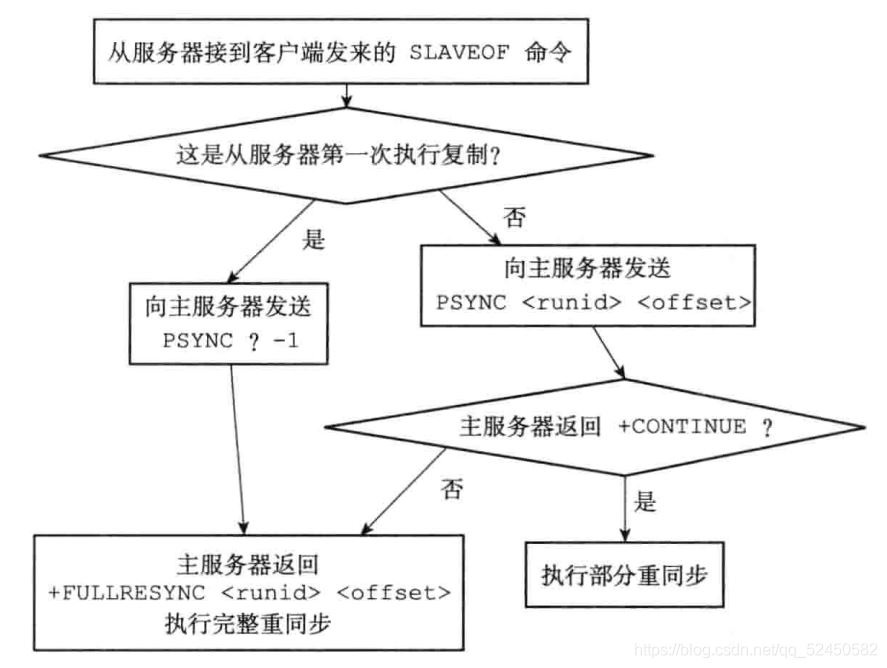
дёәдәҶејҘиЎҘж—§зүҲеӨҚеҲ¶зҡ„зјәйҷ·пјҢRedisд»Һ2.8зүҲжң¬ејҖе§ӢдҪҝз”ЁPSYNCе‘Ҫд»Өд»ЈжӣҝSYNCе‘Ҫд»ӨгҖӮPSYNCжңүе®Ңж•ҙйҮҚеҗҢжӯҘе’ҢйғЁеҲҶйҮҚеҗҢжӯҘдёӨз§ҚжЁЎејҸпјҢе…¶дёӯе®Ңж•ҙйҮҚеҗҢжӯҘе’ҢдёҠиҝ°зҡ„ж—§зүҲеҗҢжӯҘе·®дёҚеӨҡпјҢд№ҹжҳҜеҫ—еҸ‘дёӘrdbгҖӮдҪҶжҳҜйғЁеҲҶйҮҚеҗҢжӯҘеҫҲзүӣXдәҶпјҡе®ғеҸҜд»ҘеҸӘе°Ҷж–ӯзәҝжңҹй—ҙзҡ„еҶҷе…Ҙдё»жңҚеҠЎеҷЁзҡ„еҶҷе‘Ҫд»ӨеҸ‘йҖҒз»ҷд»ҺжңҚеҠЎеҷЁпјҢиҖ—иҙ№иө„жәҗжӣҙе°‘пјҢйҖҹеәҰд№ҹеҝ«зҡ„еӨҡгҖӮеҰӮдёӢеӣҫгҖӮ
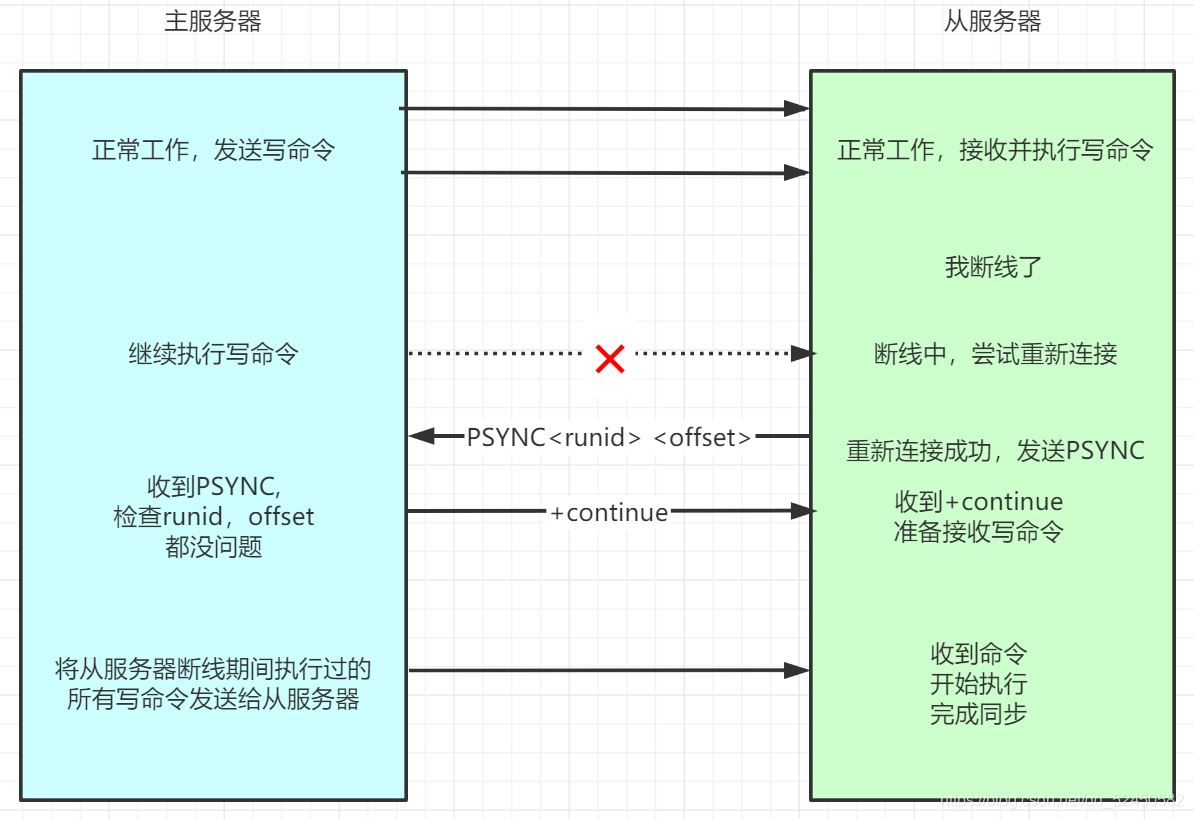
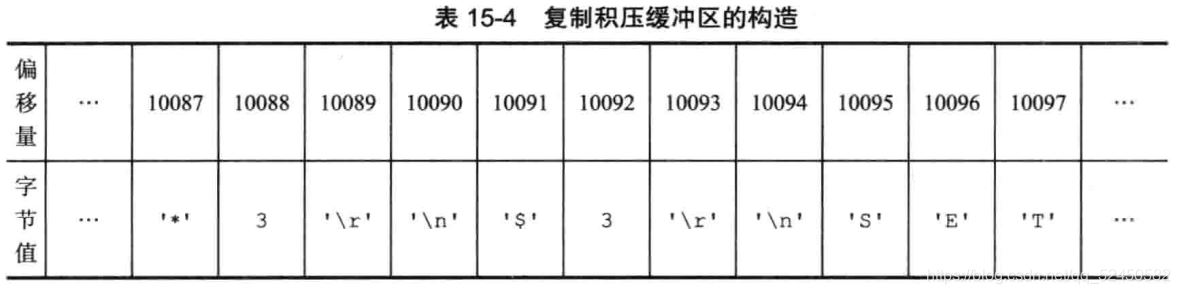
йғЁеҲҶйҮҚеҗҢжӯҘзҡ„е®һзҺ°еҺҹзҗҶ并дёҚеӨҚжқӮпјҢз”ұдёүйғЁеҲҶжһ„жҲҗпјҡеӨҚеҲ¶еҒҸ移йҮҸпјҲoffsetпјүгҖҒеӨҚеҲ¶з§ҜеҺӢзј“еҶІеҢәе’ҢжңҚеҠЎеҷЁиҝҗиЎҢidпјҲrunidпјү
еӨҚеҲ¶еҒҸ移йҮҸ
еӨҚеҲ¶еҒҸ移йҮҸжҳҜз”ЁжқҘзЎ®и®Өдё»д»ҺжңҚеҠЎеҷЁзҡ„еҗҢжӯҘзҠ¶жҖҒзҡ„гҖӮдё»д»ҺжңҚеҠЎеҷЁеҗ„иҮӘз»ҙжҠӨдёҖд»ҪеӨҚеҲ¶еҒҸ移йҮҸпјҢеҪ“дё»жңҚеҠЎеҷЁеҗ‘д»ҺжңҚеҠЎеҷЁеҸ‘йҖҒдәҶNдёӘеӯ—иҠӮзҡ„ж•°жҚ®ж—¶пјҢе°ұе°ҶиҮӘе·ұзҡ„еӨҚеҲ¶еҒҸ移йҮҸеҠ дёҠNпјӣд»ҺжңҚеҠЎеҷЁж”¶еҲ°NдёӘеӯ—иҠӮзҡ„ж•°жҚ®д№ҹдјҡе°ҶиҮӘе·ұзҡ„еӨҚеҲ¶еҒҸ移йҮҸеҠ дёҠNгҖӮйҖҡиҝҮжҜ”иҫғдё»д»ҺеҸҢж–№зҡ„еӨҚеҲ¶еҒҸ移йҮҸе°ұеҸҜд»ҘеҫҲе®№жҳ“зҡ„зЎ®и®ӨеҗҢжӯҘзҠ¶жҖҒгҖӮ
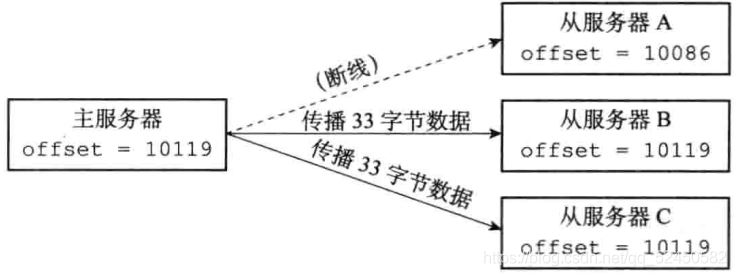
еӨҚеҲ¶з§ҜеҺӢзј“еҶІеҢә
еӨҚеҲ¶з§ҜеҺӢзј“еҶІеҢәжҳҜз”ұдё»жңҚеҠЎеҷЁз»ҙжҠӨзҡ„дёҖдёӘеӣәе®ҡй•ҝеәҰзҡ„е…Ҳиҝӣе…ҲеҮәзҡ„йҳҹеҲ—пјҢеңЁдё»жңҚеҠЎеҷЁиҝӣиЎҢе‘Ҫд»Өдј ж’ӯзҡ„ж—¶еҖҷдјҡйЎәйҒ“и®©е‘Ҫд»Өе…ҘйҳҹеҲ°еӨҚеҲ¶з§ҜеҺӢзј“еҶІеҢәдёӯпјҢеҰӮдёӢпјҡ
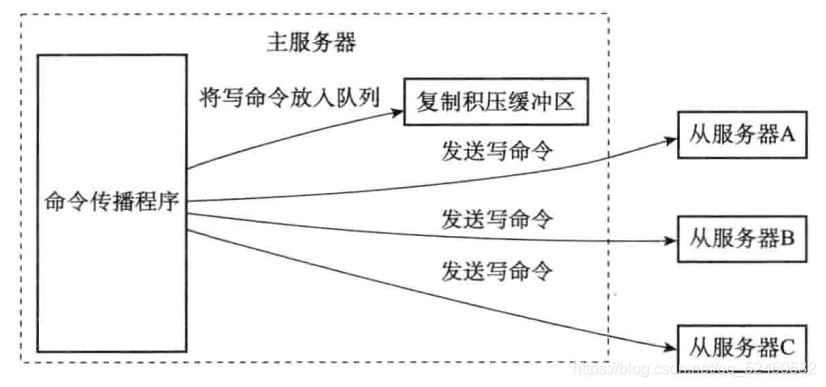
з”ұдәҺеӨҚеҲ¶з§ҜеҺӢзј“еҶІеҢәжҳҜдёҖдёӘеӣәе®ҡй•ҝеәҰзҡ„йҳҹеҲ—пјҢжүҖд»Ҙе®ғеҸӘдјҡдҝқеӯҳжңҖиҝ‘дёҖж®өж—¶й—ҙеҶ…жү§иЎҢзҡ„еҶҷе‘Ҫд»ӨпјҢ并дёәйҳҹеҲ—дёӯзҡ„жҜҸдёӘеӯ—иҠӮи®°еҪ•еҜ№еә”зҡ„еӨҚеҲ¶еҒҸ移йҮҸгҖӮеңЁд»ҺжңҚеҠЎеҷЁеҸ‘йҖҒPSYNCе‘Ҫд»Өж—¶пјҢдјҡжҗәеёҰдёҠиҮӘе·ұзҡ„еӨҚеҲ¶еҒҸ移йҮҸпјҢдё»жңҚеҠЎеҷЁжӢҝзқҖиҝҷдёӘеҒҸ移йҮҸеҺ»иҮӘе·ұзҡ„еӨҚеҲ¶з§ҜеҺӢзј“еҶІеҢәдёӯжҹҘзңӢoffset+1(еҚіж–ӯзәҝеҗҺжү§иЎҢзҡ„дёӢдёҖдёӘе‘Ҫд»Ө)иҝҳеңЁдёҚеңЁйҳҹеҲ—дёӯгҖӮеҰӮжһңиҝҳеңЁпјҢиЎЁзӨәеҸҜд»Ҙжү§иЎҢйғЁеҲҶйҮҚеҗҢжӯҘпјҢеҗҺйқўдјҡе°Ҷд»Һoffset+1еҲ°йҳҹе°ҫзҡ„жүҖжңүж•°жҚ®еҸ‘йҖҒз»ҷд»ҺжңҚеҠЎеҷЁпјӣеҰӮжһңдёҚеңЁпјҢйӮЈд»ҺжңҚеҠЎеҷЁеҸӘиғҪиҖҒиҖҒе®һе®һзҡ„еҺ»еҒҡе®Ңе…ЁйҮҚеҗҢжӯҘгҖӮ
жңҚеҠЎеҷЁиҝҗиЎҢId
жңҚеҠЎеҷЁиҝҗиЎҢIdиҜҙзҷҪдәҶе°ұжҳҜзңӢдё»д»ҺжңҚеҠЎеҷЁж–ӯзәҝд№ӢеүҚжҳҜдёҚжҳҜдёҖ家еӯҗгҖӮжҜҸдёҖдёӘredisжңҚеҠЎеҷЁйғҪжңүиҮӘе·ұзҡ„иҝҗиЎҢidпјҢдё»д»ҺеҲқж¬ЎиҝһжҺҘж—¶пјҢдё»жңҚеҠЎеҷЁдјҡжҠҠиҮӘе·ұзҡ„жңҚеҠЎеҷЁиҝҗиЎҢidеҸ‘йҖҒз»ҷд»ҺжңҚеҠЎеҷЁдҝқеӯҳиө·жқҘпјҢд»ҺжңҚеҠЎеҷЁеңЁйҮҚиҝһжҺҘзҡ„ж—¶еҖҷдјҡжҠҠд№ӢеүҚдҝқеӯҳзҡ„дё»жңҚеҠЎеҷЁrunidдёҖ并еҸ‘з»ҷдё»жңҚеҠЎеҷЁпјҢдё»жңҚеҠЎеҷЁдјҡжӢҝзқҖиҝҷдёӘrunidе’ҢиҮӘе·ұзҡ„runidиҝӣиЎҢжҜ”еҜ№гҖӮеҰӮжһңдёҖиҮҙпјҢеҲҷиЎЁзӨәиҜҘд»ҺжңҚеҠЎеҷЁд№ӢеүҚзЎ®е®һжҳҜд»ҺиҮӘе·ұиҝҷйҮҢж–ӯзәҝзҡ„пјҢжҺҘдёӢжқҘиҝӣиЎҢеҒҸ移йҮҸзҡ„жЈҖжҹҘпјӣеҰӮжһңдёҚдёҖиҮҙпјҢеҲҷиЎЁзӨәиҝҷдёӘд»ҺжңҚеҠЎеҷЁе…ҲеүҚжҳҜе…¶д»–дё»жңҚеҠЎеҷЁзҡ„slaveпјҢзӣҙжҺҘжү“еҺ»еҒҡе®Ңе…ЁйҮҚеҗҢжӯҘгҖӮ
еңЁд№ӢеүҚжү§иЎҢinfo replicationе‘Ҫд»Өзҡ„ж—¶еҖҷе°ұеҸҜд»ҘзңӢеҲ°жңҚеҠЎеҷЁиҝҗиЎҢidе’ҢеӨҚеҲ¶еҒҸ移йҮҸгҖӮ
з»јдёҠпјҢдёҖдёӘж–°зүҲredisеӨҚеҲ¶зҡ„еҗҢжӯҘиҝҮзЁӢеӨ§иҮҙеҰӮдёӢпјҡ
е…ідәҺжҖҺд№ҲеңЁRedisдёӯе®һзҺ°жҢҒд№…еҢ–дёҺдё»д»ҺеӨҚеҲ¶е°ұеҲҶдә«еҲ°иҝҷйҮҢдәҶпјҢеёҢжңӣд»ҘдёҠеҶ…е®№еҸҜд»ҘеҜ№еӨ§е®¶жңүдёҖе®ҡзҡ„её®еҠ©пјҢеҸҜд»ҘеӯҰеҲ°жӣҙеӨҡзҹҘиҜҶгҖӮеҰӮжһңи§үеҫ—ж–Үз« дёҚй”ҷпјҢеҸҜд»ҘжҠҠе®ғеҲҶдә«еҮәеҺ»и®©жӣҙеӨҡзҡ„дәәзңӢеҲ°гҖӮ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ