жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
scrapydweb.herokuapp.com
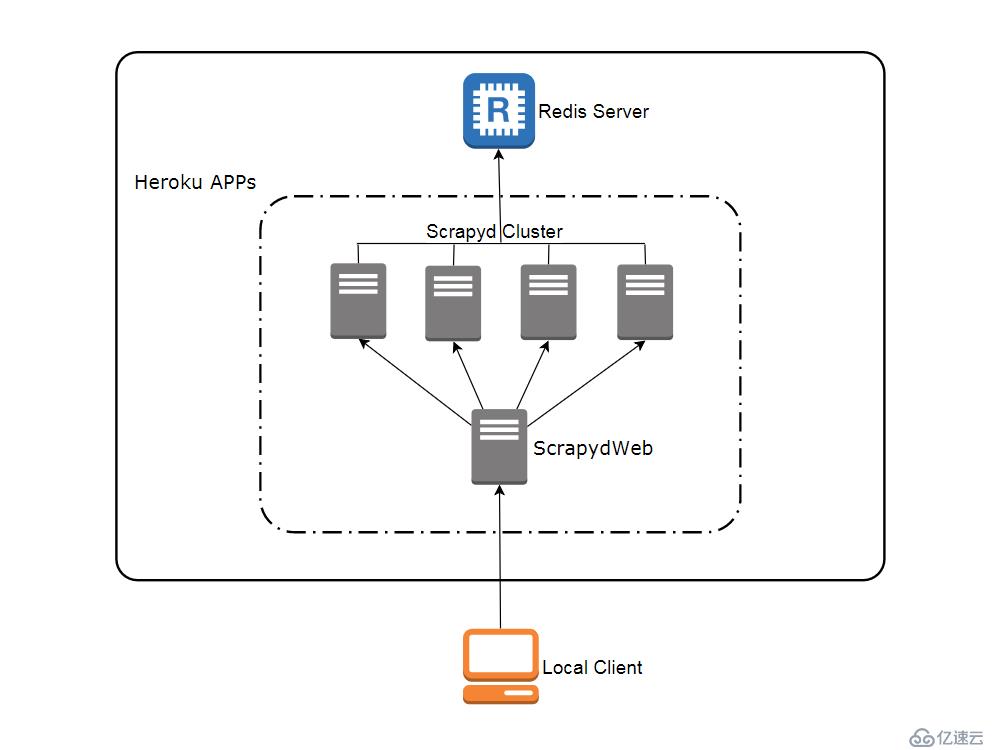
и®ҝй—® heroku.com жіЁеҶҢе…Қиҙ№иҙҰеҸ·пјҲжіЁеҶҢйЎөйқўйңҖиҰҒи°ғз”Ё google recaptcha дәәжңәйӘҢиҜҒпјҢзҷ»еҪ•йЎөйқўд№ҹйңҖиҰҒ科еӯҰең°иҝӣиЎҢдёҠзҪ‘пјҢи®ҝй—® app иҝҗиЎҢйЎөйқўеҲҷжІЎжңүиҜҘй—®йўҳпјүпјҢе…Қиҙ№иҙҰеҸ·жңҖеӨҡеҸҜд»ҘеҲӣе»әе’ҢиҝҗиЎҢ5дёӘ appгҖӮ
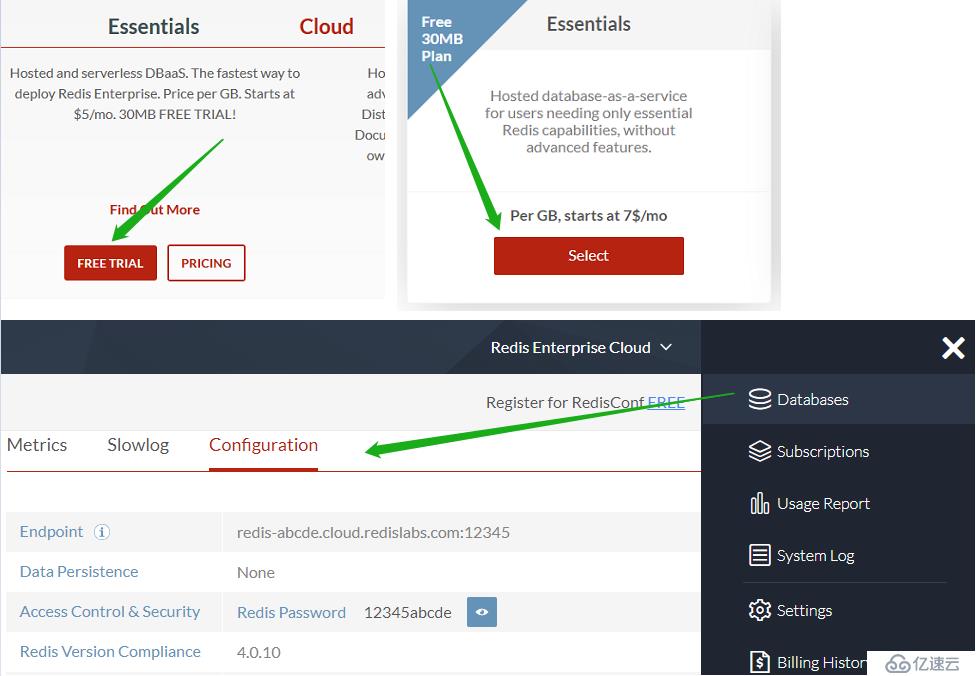
и®ҝй—® redislabs.com жіЁеҶҢе…Қиҙ№иҙҰеҸ·пјҢжҸҗдҫӣ30MB еӯҳеӮЁз©әй—ҙпјҢз”ЁдәҺдёӢж–ҮйҖҡиҝҮ scrapy-redis е®һзҺ°еҲҶеёғејҸзҲ¬иҷ«гҖӮ
svr-1, svr-2, svr-3 е’Ң svr-4myscrapydwebSCRAPYD_SERVER_2, VALUE дёә svr-2.herokuapp.com:80#group2pip install redis е‘Ҫд»ӨеҚіеҸҜгҖӮж–°ејҖдёҖдёӘе‘Ҫд»ӨиЎҢжҸҗзӨәз¬Ұпјҡ
git clone https://github.com/my8100/scrapyd-cluster-on-heroku
cd scrapyd-cluster-on-herokuheroku login
# outputs:
# heroku: Press any key to open up the browser to login or q to exit:
# Opening browser to https://cli-auth.heroku.com/auth/browser/12345-abcde
# Logging in... done
# Logged in as username@gmail.comж–°е»ә Git д»“еә“
cd scrapyd
git init
# explore and update the files if needed
git status
git add .
git commit -a -m "first commit"
git statusйғЁзҪІ Scrapyd app
heroku apps:create svr-1
heroku git:remote -a svr-1
git remote -v
git push heroku master
heroku logs --tail
# Press ctrl+c to stop logs outputting
# Visit https://svr-1.herokuapp.comж·»еҠ зҺҜеўғеҸҳйҮҸ
# python -c "import tzlocal; print(tzlocal.get_localzone())"
heroku config:set TZ=Asia/Shanghai
# heroku config:get TZheroku config:set REDIS_HOST=your-redis-host
heroku config:set REDIS_PORT=your-redis-port
heroku config:set REDIS_PASSWORD=your-redis-passwordsvr-2пјҢsvr-3 е’Ң svr-4ж–°е»ә Git д»“еә“
cd ..
cd scrapydweb
git init
# explore and update the files if needed
git status
git add .
git commit -a -m "first commit"
git statusйғЁзҪІ ScrapydWeb app
heroku apps:create myscrapydweb
heroku git:remote -a myscrapydweb
git remote -v
git push heroku masterж·»еҠ зҺҜеўғеҸҳйҮҸ
heroku config:set TZ=Asia/Shanghaiheroku config:set SCRAPYD_SERVER_1=svr-1.herokuapp.com:80
heroku config:set SCRAPYD_SERVER_2=svr-2.herokuapp.com:80#group1
heroku config:set SCRAPYD_SERVER_3=svr-3.herokuapp.com:80#group1
heroku config:set SCRAPYD_SERVER_4=svr-4.herokuapp.com:80#group2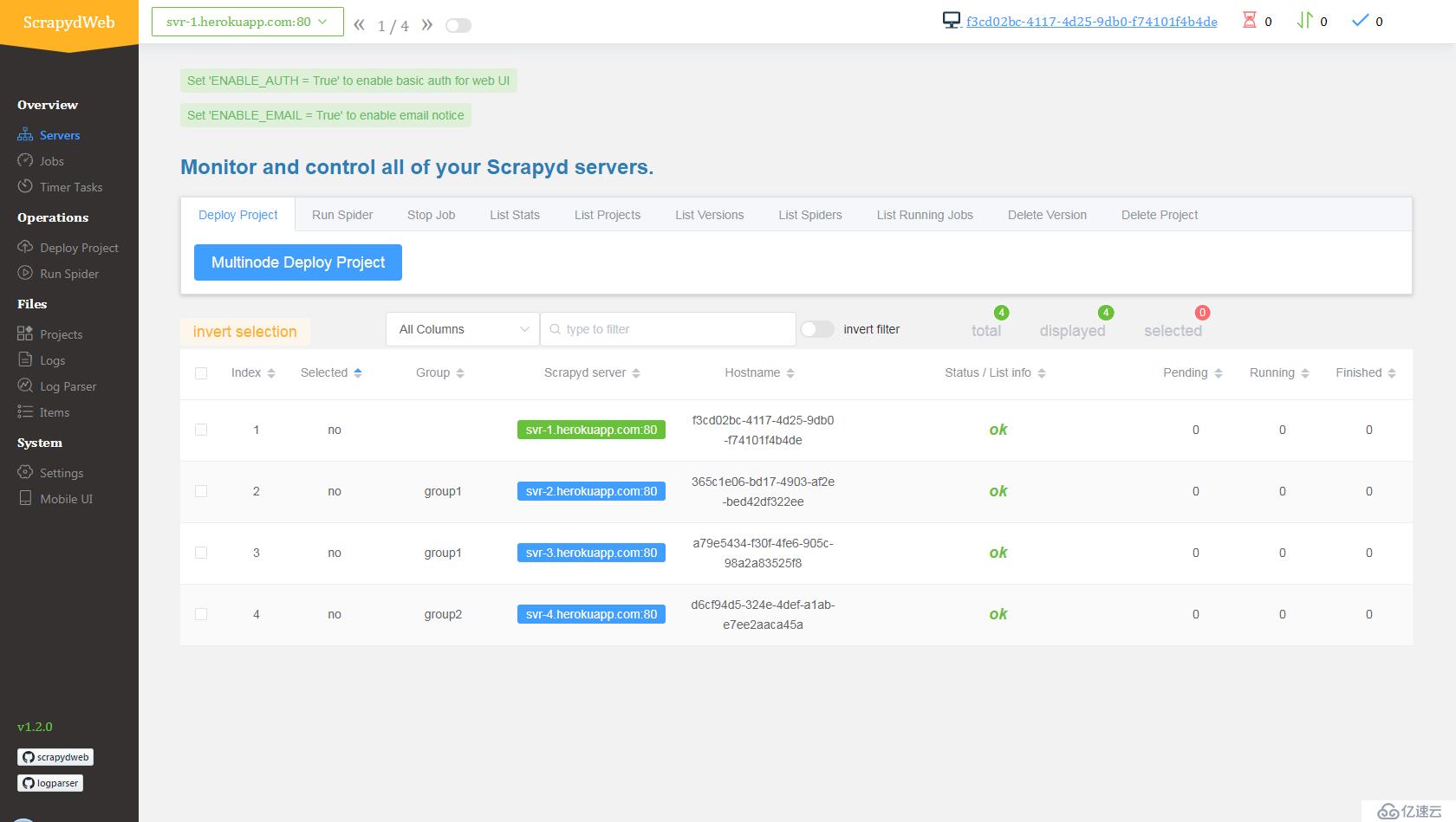
mycrawler:start_urls и§ҰеҸ‘зҲ¬иҷ«е№¶жҹҘзңӢз»“жһңIn [1]: import redis # pip install redis
In [2]: r = redis.Redis(host='your-redis-host', port=your-redis-port, password='your-redis-password')
In [3]: r.delete('mycrawler_redis:requests', 'mycrawler_redis:dupefilter', 'mycrawler_redis:items')
Out[3]: 0
In [4]: r.lpush('mycrawler:start_urls', 'http://books.toscrape.com', 'http://quotes.toscrape.com')
Out[4]: 2
# wait for a minute
In [5]: r.lrange('mycrawler_redis:items', 0, 1)
Out[5]:
[b'{"url": "http://quotes.toscrape.com/", "title": "Quotes to Scrape", "hostname": "d6cf94d5-324e-4def-a1ab-e7ee2aaca45a", "crawled": "2019-04-02 03:42:37", "spider": "mycrawler_redis"}',
b'{"url": "http://books.toscrape.com/index.html", "title": "All products | Books to Scrape - Sandbox", "hostname": "d6cf94d5-324e-4def-a1ab-e7ee2aaca45a", "crawled": "2019-04-02 03:42:37", "spider": "mycrawler_redis"}']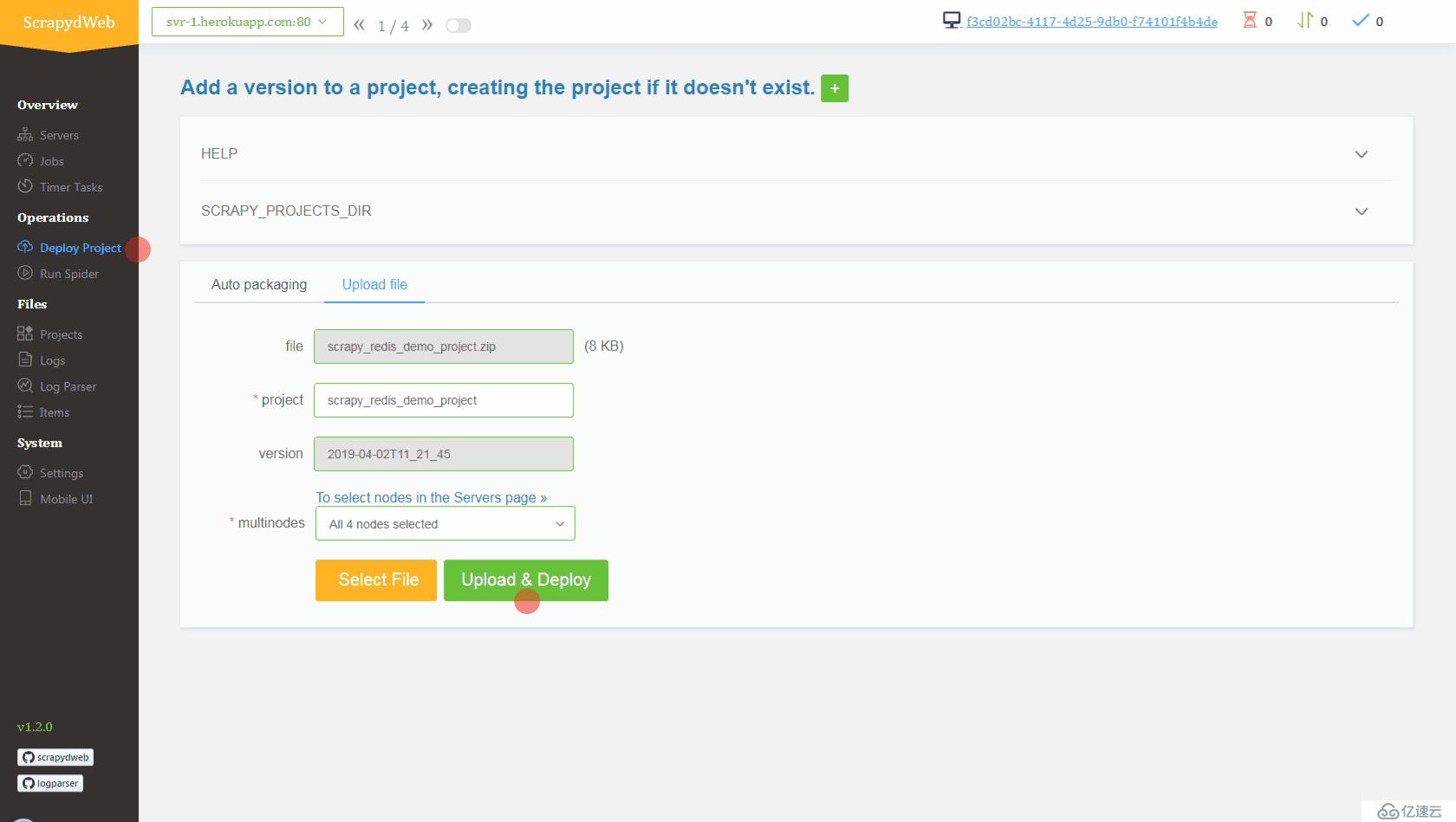
my8100/scrapyd-cluster-on-heroku
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ