жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
иҝҷжңҹеҶ…е®№еҪ“дёӯе°Ҹзј–е°Ҷдјҡз»ҷеӨ§е®¶еёҰжқҘжңүе…іж•°жҚ®еҪ’дёҖеҢ–еӨ„зҗҶзҡ„дҪңз”ЁжҳҜд»Җд№ҲпјҢж–Үз« еҶ…е®№дё°еҜҢдё”д»Ҙдё“дёҡзҡ„и§’еәҰдёәеӨ§е®¶еҲҶжһҗе’ҢеҸҷиҝ°пјҢйҳ…иҜ»е®ҢиҝҷзҜҮж–Үз« еёҢжңӣеӨ§е®¶еҸҜд»ҘжңүжүҖ收иҺ·гҖӮ
ж•°жҚ®еҪ’дёҖеҢ–еӨ„зҗҶзҡ„зӣ®зҡ„жҳҜпјҡдҪҝеҫ—йў„еӨ„зҗҶзҡ„ж•°жҚ®иў«йҷҗе®ҡеңЁдёҖе®ҡзҡ„иҢғеӣҙеҶ…пјҢд»ҺиҖҢж¶ҲйҷӨеҘҮејӮж ·жң¬ж•°жҚ®еҜјиҮҙзҡ„дёҚиүҜеҪұе“ҚгҖӮж•°жҚ®еҪ’дёҖеҢ–еӨ„зҗҶеҗҺпјҢеҸҜд»ҘеҠ еҝ«жўҜеәҰдёӢйҷҚжұӮжңҖдјҳи§Јзҡ„йҖҹеәҰпјҢдё”жңүеҸҜиғҪжҸҗй«ҳзІҫеәҰпјҲеҰӮKNNпјүгҖӮ
еҪ’дёҖеҢ–зҡ„зӣ®зҡ„е°ұжҳҜдҪҝеҫ—йў„еӨ„зҗҶзҡ„ж•°жҚ®иў«йҷҗе®ҡеңЁдёҖе®ҡзҡ„иҢғеӣҙеҶ…пјҲжҜ”еҰӮ[0,1]жҲ–иҖ…[-1,1]пјүпјҢд»ҺиҖҢж¶ҲйҷӨеҘҮејӮж ·жң¬ж•°жҚ®еҜјиҮҙзҡ„дёҚиүҜеҪұе“ҚгҖӮ
1пјүеңЁз»ҹи®ЎеӯҰдёӯпјҢеҪ’дёҖеҢ–зҡ„е…·дҪ“дҪңз”ЁжҳҜеҪ’зәіз»ҹдёҖж ·жң¬зҡ„з»ҹи®ЎеҲҶеёғжҖ§гҖӮеҪ’дёҖеҢ–еңЁ0~1д№Ӣй—ҙжҳҜз»ҹи®Ўзҡ„жҰӮзҺҮеҲҶеёғпјҢеҪ’дёҖеҢ–еңЁ-1~+1д№Ӣй—ҙжҳҜз»ҹи®Ўзҡ„еқҗж ҮеҲҶеёғгҖӮ
2пјүеҘҮејӮж ·жң¬ж•°жҚ®жҳҜжҢҮзӣёеҜ№дәҺе…¶д»–иҫ“е…Ҙж ·жң¬зү№еҲ«еӨ§жҲ–зү№еҲ«е°Ҹзҡ„ж ·жң¬зҹўйҮҸпјҲеҚізү№еҫҒеҗ‘йҮҸпјүпјҢиӯ¬еҰӮпјҢдёӢйқўдёәе…·жңүдёӨдёӘзү№еҫҒзҡ„ж ·жң¬ж•°жҚ®x1гҖҒx2гҖҒx3гҖҒx4гҖҒx5гҖҒx6пјҲзү№еҫҒеҗ‘йҮҸвҖ”>еҲ—еҗ‘йҮҸпјү,е…¶дёӯx6иҝҷдёӘж ·жң¬зҡ„дёӨдёӘзү№еҫҒзӣёеҜ№е…¶д»–ж ·жң¬иҖҢиЁҖзӣёе·®жҜ”иҫғеӨ§пјҢеӣ жӯӨпјҢx6и®ӨдёәжҳҜеҘҮејӮж ·жң¬ж•°жҚ®гҖӮ
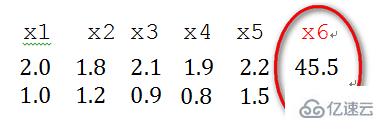
еҘҮејӮж ·жң¬ж•°жҚ®зҡ„еӯҳеңЁдјҡеј•иө·и®ӯз»ғж—¶й—ҙеўһеӨ§пјҢеҗҢж—¶д№ҹеҸҜиғҪеҜјиҮҙж— жі•ж”¶ж•ӣпјҢеӣ жӯӨпјҢеҪ“еӯҳеңЁеҘҮејӮж ·жң¬ж•°жҚ®ж—¶пјҢеңЁиҝӣиЎҢи®ӯз»ғд№ӢеүҚйңҖиҰҒеҜ№йў„еӨ„зҗҶж•°жҚ®иҝӣиЎҢеҪ’дёҖеҢ–пјӣеҸҚд№ӢпјҢдёҚеӯҳеңЁеҘҮејӮж ·жң¬ж•°жҚ®ж—¶пјҢеҲҷеҸҜд»ҘдёҚиҝӣиЎҢеҪ’дёҖеҢ–гҖӮ
--еҰӮжһңдёҚиҝӣиЎҢеҪ’дёҖеҢ–пјҢйӮЈд№Ҳз”ұдәҺзү№еҫҒеҗ‘йҮҸдёӯдёҚеҗҢзү№еҫҒзҡ„еҸ–еҖјзӣёе·®иҫғеӨ§пјҢдјҡеҜјиҮҙзӣ®ж ҮеҮҪж•°еҸҳвҖңжүҒвҖқгҖӮиҝҷж ·еңЁиҝӣиЎҢжўҜеәҰдёӢйҷҚзҡ„ж—¶еҖҷпјҢжўҜеәҰзҡ„ж–№еҗ‘е°ұдјҡеҒҸзҰ»жңҖе°ҸеҖјзҡ„ж–№еҗ‘пјҢиө°еҫҲеӨҡејҜи·ҜпјҢеҚіи®ӯз»ғж—¶й—ҙиҝҮй•ҝгҖӮ
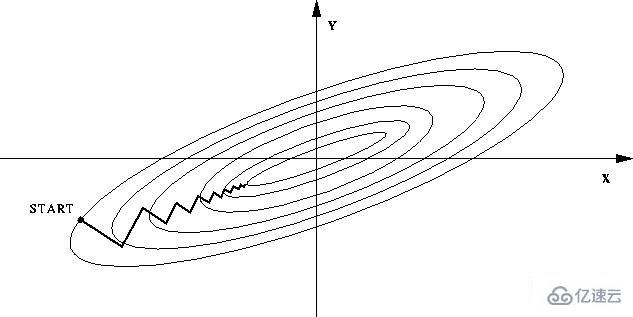
--еҰӮжһңиҝӣиЎҢеҪ’дёҖеҢ–д»ҘеҗҺпјҢзӣ®ж ҮеҮҪж•°дјҡе‘ҲзҺ°жҜ”иҫғвҖңеңҶвҖқпјҢиҝҷж ·и®ӯз»ғйҖҹеәҰеӨ§еӨ§еҠ еҝ«пјҢе°‘иө°еҫҲеӨҡејҜи·ҜгҖӮ
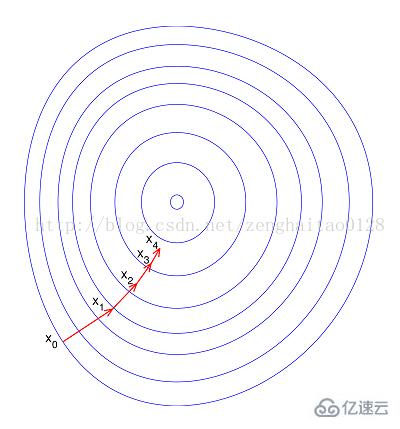
з»јдёҠеҸҜзҹҘпјҢеҪ’дёҖеҢ–жңүеҰӮдёӢеҘҪеӨ„пјҢеҚі
1пјүеҪ’дёҖеҢ–еҗҺеҠ еҝ«дәҶжўҜеәҰдёӢйҷҚжұӮжңҖдјҳи§Јзҡ„йҖҹеәҰпјӣ
2пјүеҪ’дёҖеҢ–жңүеҸҜиғҪжҸҗй«ҳзІҫеәҰпјҲеҰӮKNNпјү
жіЁпјҡжІЎжңүдёҖз§Қж•°жҚ®ж ҮеҮҶеҢ–зҡ„ж–№жі•пјҢж”ҫеңЁжҜҸдёҖдёӘй—®йўҳпјҢж”ҫеңЁжҜҸдёҖдёӘжЁЎеһӢпјҢйғҪиғҪжҸҗй«ҳз®—жі•зІҫеәҰе’ҢеҠ йҖҹз®—жі•зҡ„收ж•ӣйҖҹеәҰгҖӮ
дёҠиҝ°е°ұжҳҜе°Ҹзј–дёәеӨ§е®¶еҲҶдә«зҡ„ж•°жҚ®еҪ’дёҖеҢ–еӨ„зҗҶзҡ„дҪңз”ЁжҳҜд»Җд№ҲдәҶпјҢеҰӮжһңеҲҡеҘҪжңүзұ»дјјзҡ„з–‘жғ‘пјҢдёҚеҰЁеҸӮз…§дёҠиҝ°еҲҶжһҗиҝӣиЎҢзҗҶи§ЈгҖӮеҰӮжһңжғізҹҘйҒ“жӣҙеӨҡзӣёе…ізҹҘиҜҶпјҢж¬ўиҝҺе…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“гҖӮ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ