жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
е°Ҹзј–з»ҷеӨ§е®¶еҲҶдә«дёҖдёӢJavaдёӯhashcodeзҡ„зӨәдҫӢеҲҶжһҗпјҢзӣёдҝЎеӨ§йғЁеҲҶдәәйғҪиҝҳдёҚжҖҺд№ҲдәҶи§ЈпјҢеӣ жӯӨеҲҶдә«иҝҷзҜҮж–Үз« з»ҷеӨ§е®¶еҸӮиҖғдёҖдёӢпјҢеёҢжңӣеӨ§е®¶йҳ…иҜ»е®ҢиҝҷзҜҮж–Үз« еҗҺеӨ§жңү收иҺ·пјҢдёӢйқўи®©жҲ‘们дёҖиө·еҺ»дәҶи§ЈдёҖдёӢеҗ§пјҒ
Javaзҡ„еҹәжң¬ж•°жҚ®зұ»еһӢеҲҶдёәпјҡ1гҖҒж•ҙж•°зұ»еһӢпјҢз”ЁжқҘиЎЁзӨәж•ҙж•°зҡ„ж•°жҚ®зұ»еһӢгҖӮ2гҖҒжө®зӮ№зұ»еһӢпјҢз”ЁжқҘиЎЁзӨәе°Ҹж•°зҡ„ж•°жҚ®зұ»еһӢгҖӮ3гҖҒеӯ—з¬Ұзұ»еһӢпјҢеӯ—з¬Ұзұ»еһӢзҡ„е…ій”®еӯ—жҳҜвҖңcharвҖқгҖӮ4гҖҒеёғе°”зұ»еһӢпјҢжҳҜиЎЁзӨәйҖ»иҫ‘еҖјзҡ„еҹәжң¬ж•°жҚ®зұ»еһӢгҖӮ
HashпјҢдёҖиҲ¬зҝ»иҜ‘еҒҡж•ЈеҲ—гҖҒжқӮеҮ‘пјҢжҲ–йҹіиҜ‘дёәе“ҲеёҢпјҢжҳҜжҠҠд»»ж„Ҹй•ҝеәҰзҡ„иҫ“е…ҘпјҲеҸҲеҸ«еҒҡйў„жҳ е°„pre-imageпјүйҖҡиҝҮж•ЈеҲ—з®—жі•еҸҳжҚўжҲҗеӣәе®ҡй•ҝеәҰзҡ„иҫ“еҮәпјҢиҜҘиҫ“еҮәе°ұжҳҜж•ЈеҲ—еҖјгҖӮиҝҷз§ҚиҪ¬жҚўжҳҜдёҖз§ҚеҺӢзј©жҳ е°„пјҢд№ҹе°ұжҳҜпјҢж•ЈеҲ—еҖјзҡ„з©әй—ҙйҖҡеёёиҝңе°ҸдәҺиҫ“е…Ҙзҡ„з©әй—ҙпјҢдёҚеҗҢзҡ„иҫ“е…ҘеҸҜиғҪдјҡж•ЈеҲ—жҲҗзӣёеҗҢзҡ„иҫ“еҮәпјҢжүҖд»ҘдёҚеҸҜиғҪд»Һж•ЈеҲ—еҖјжқҘзЎ®е®ҡе”ҜдёҖзҡ„иҫ“е…ҘеҖјгҖӮз®ҖеҚ•зҡ„иҜҙе°ұжҳҜдёҖз§Қе°Ҷд»»ж„Ҹй•ҝеәҰзҡ„ж¶ҲжҒҜеҺӢзј©еҲ°жҹҗдёҖеӣәе®ҡй•ҝеәҰзҡ„ж¶ҲжҒҜж‘ҳиҰҒзҡ„еҮҪж•°гҖӮ
иҝҷдёӘиҜҙзҡ„жңүзӮ№е®ҳж–№пјҢдҪ е°ұеҸҜд»ҘжҠҠе®ғз®ҖеҚ•зҡ„зҗҶи§ЈдёәдёҖдёӘkeyпјҢе°ұеғҸжҳҜmapзҡ„keyеҖјдёҖж ·пјҢжҳҜдёҚеҸҜйҮҚеӨҚзҡ„гҖӮ
1.еңЁж•ЈеҲ—иЎЁ
2.mapйӣҶеҗҲ
жӯӨеӨ„еҸӘжҳҜеҒҡдәҶдёҖдёӘз®ҖеҚ•зҡ„д»Ӣз»ҚпјҢе…¶е®һиҝңиҝңжІЎжңүйӮЈд№Ҳз®ҖеҚ•пјҢеҰӮз®—жі•йҮҢйқўзҡ„ж•ЈеҲ—иЎЁпјҢж•ЈеҲ—еҮҪж•°пјҢд»ҘеҸҠmapзҡ„дёҖдёӘдёҚеҸҜйҮҚеӨҚеҲ°еә•жҳҜжҖҺд№Ҳж ·еҺ»еҲӨж–ӯзҡ„пјҢд»ҘеҸҠhashеҶІзӘҒзҡ„й—®йўҳпјҢйғҪдёҺhashеҖјзҰ»дёҚејҖе…ізі»гҖӮ
public int hashCode() {
int h = hash;
if (h == 0 && value.length > 0) {
char val[] = value;
for (int i = 0; i < value.length; i++) {
h = 31 * h + val[i];
}
hash = h;
}
return h;
}еҸҜд»ҘзңӢеҲ°пјҢStringзұ»зҡ„hashcodeж–№жі•жҳҜйҖҡиҝҮпјҢcharзұ»еһӢзҡ„ж–№ејҸиҝӣиЎҢдёҖдёӘзӣёеҠ пјҢеӣ дёәStringзұ»зҡ„еә•еұӮе°ұжҳҜйҖҡиҝҮcharж•°з»„жқҘе®һзҺ°зҡ„гҖӮ
еҰӮ:String str="ab"; е…¶е®һе°ұжҳҜдёҖдёӘcharж•°з»„ char[] str={'a','b'};
еҰӮпјҡеӯ—з¬ҰдёІ String star=вҖңabвҖқ;йӮЈд№Ҳд»–еҜ№еә”зҡ„hashеҖје°ұжҳҜпјҡ3105
жҖҺд№Ҳз®—еҮәжқҘзҡ„е‘ўпјҹ
val[0]='a' ; val[1]='b'
aеҜ№еә”зҡ„Ascallз ҒеҖјдёәпјҡ97
bеҜ№зҡ„Ascallз ҒеҖјдёәпјҡ98
йӮЈд№Ҳз»ҸиҝҮеҰӮдёӢд»Јз Ғзҡ„еҫӘзҺҜзӣёеҠ
for (int i = 0; i < value.length; i++) {
h = 31 * h + val[i];
}еҫ—еҮәпјҡ97*31+98=3105пјӣ
жҲ‘们еҶҚзңӢпјҡ int h = hash;иҝҷдёҖдёӘд»Јз ҒпјҢдёәд»Җд№Ҳжңүж—¶еҖҷи°ғз”Ёhashcodeж–№жі•иҝ”еӣһзҡ„hashеҖјжҳҜиҙҹж•°е‘ўпјҹ
еӣ дёәеҰӮжһңиҝҷдёӘеӯ—з¬ҰдёІеҫҲй•ҝпјҹйӮЈд№Ҳhзҡ„еҖје°ұдјҡи¶…иҝҮintзұ»еһӢзҡ„жңҖеӨ§еҖјпјҢжңүжІЎжңүжғіиҝҮпјҢеҰӮжһңдёҖдёӘintзұ»еһӢзҡ„жңҖеӨ§еҖјпјҢи¶…иҝҮд»–зҡ„иҢғеӣҙд№ӢеҗҺдјҡжҖҺд№Ҳж ·е‘ўпјҹ
жҲ‘们е…ҲжқҘзңӢиҝҷж ·дёҖдёӘз®ҖеҚ•зҡ„д»Јз Ғпјҡ
int count=0;
while (true){
if (count++<10){
System.out.println("hello world");
}
}еӨ§е®¶и®Өдёәhello worldдјҡиҫ“еҮәеӨҡе°‘ж¬Ўе‘ўпјҹ
жӯЈеёёжғ…еҶөжқҘиҜҙcountе°ҸдәҺ10е°ұдёҚдјҡиҫ“еҮәдәҶеҜ№д№Ҳпјҹ
дҪҶжҳҜе…¶е®һ并дёҚжҳҜиҝҷж ·зҡ„пјҢеҫҲжҳҺзЎ®зҡ„е‘ҠиҜүеӨ§е®¶пјҢиҝҷжҳҜдёҖдёӘжӯ»еҫӘзҺҜгҖӮ
еӣ дёәcountдёҖзӣҙеҠ пјҢжңҖејҖе§ӢifжҲҗз«ӢпјҢеҲ°еҗҺйқўзҡ„ifдёҚжҲҗз«ӢпјҢеҶҚеҲ°еҗҺйқўifдјҡеҶҚж¬ЎжҲҗз«ӢпјҢдёәд»Җд№ҲдјҡжҲҗз«Ӣе‘ўпјҹеӣ дёәcountеҸҳдёәдәҶиҙҹж•°гҖӮ
пјҹпјҹпјҹпјҹ дёәд»Җд№Ҳпјҹеӣ дёәcountдёҖзӣҙж— йҷҗеҲ¶зҡ„еҠ пјҢз”ұдәҺжҳҜзәҝжҖ§еўһй•ҝпјҢи®Ўз®—йҖҹеәҰжҳҜйқһеёёеҝ«зҡ„пјҢжүҖд»ҘпјҢиҰҒдёҚдәҶеӨҡд№…пјҢе°ұдјҡи¶…еҮәintзұ»еһӢзҡ„жңҖеӨ§еҖјгҖӮжҺ§еҲ¶иҫ“еҮәзҡ„countеҸҳдёәдәҶиҙҹж•°пјҢжүҖд»Ҙе‘ўжӯӨж—¶зҡ„ifжқЎд»¶еҸҲжҲҗз«ӢдәҶгҖӮ

йҰ–е…ҲжҲ‘们жқҘзңӢдёӢintзҡ„иҢғеӣҙ пјҡint дёә4дёӘеӯ—иҠӮпјҢдёҖдёӘеӯ—иҠӮдёә8дҪҚпјҢдёҖдёӘintеҖјжҳҜйңҖиҰҒзҡ„еӯҳеӮЁз©әй—ҙжҳҜ32дҪҚпјҢдҪҶжҳҜе‘ўпјҹиҝҷжҳҜдёҖдёӘжңүз¬ҰеҸ·дҪҚзҡ„intпјҢйңҖиҰҒдёҖдёӘз¬ҰеҸ·дҪҚжқҘиЎЁзӨәжӯЈж•°е’Ңиҙҹж•°пјҢ
intеҖјзҡ„иҢғеӣҙе°ұжҳҜпјҡ-2^31 ~ 2^31 д№ҹе°ұжҳҜпјҡ-2147483648 еҲ°2147483647
жҲ‘们жқҘзңӢдёӢintжңҖеӨ§еҖјеҜ№еә”зҡ„дәҢиҝӣеҲ¶дҪҚжҳҜеҜ№е°‘пјҹ
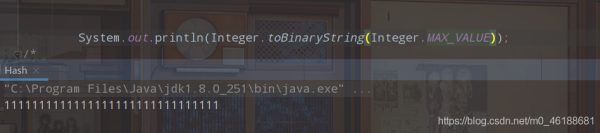
е…ЁжҳҜ1пјҹ 2147483647жңҖеӨ§еҖјдёҚжҳҜдёҖдёӘжӯЈж•°д№ҲпјҹйҡҫйҒ“第дёҖдҪҚйҡҫйҒ“дёҚжҳҜеә”иҜҘз”Ё0иЎЁзӨәд№Ҳпјҹ
жӯӨж—¶иҝҷдёӘ0д»–жҳҜзңҒз•ҘжҺүдәҶжІЎеҶҷзҡ„пјҢз”ұдәҺдәҢиҝӣеҲ¶зі»з»ҹжҳҜйҖҡиҝҮиЎҘз ҒжқҘдҝқеӯҳж•°жҚ®зҡ„гҖӮ第дёҖдҪҚжҳҜз¬ҰеҸ·дҪҚпјҢ0дёәжӯЈпјҢ1дёәиҙҹпјҢеҪ“жӯЈзҡ„йҷӨдәҶз¬ҰеҸ·дҪҚе…Ёдёә1пјҢеҶҚеҠ 1е°ұиҝӣдҪҚдәҶпјҢз¬ҰеҸ·дҪҚе°ұдјҡеҸҳжҲҗ1пјҢжҳҜиҙҹж•°пјҢе…¶д»–дёә0гҖӮ
жүҖд»ҘиҜҙеҪ“intзҡ„жңҖеӨ§еҖјеҠ дёҖдёӘ1пјҢе°ұеҸҳдёәдәҶпјҢжңҖе°ҸеҖј
жқҘпјҒеҸЈиҜҙж— еҮӯпјҢжІЎжңүиҜҙжңҚеҠӣпјҢжҲ‘们зӣҙжҺҘжқҘзңӢд»Јз Ғпјҡ
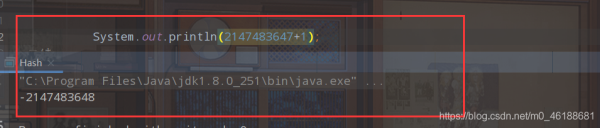
йӮЈд№ҲжҲ‘们еңЁеҸҚиҝҮжқҘжғіпјҢжңҖе°ҸеҖјеҮҸ1е‘ўпјҹйӮЈжҳҜдёҚжҳҜе°ұжҳҜеҜ№еҜ№еә”зҡ„жҳҜжҲ‘们intзұ»еһӢзҡ„жңҖеӨ§еҖјдәҶе‘Җпјҹ
и®Өзңҹд»”з»Ҷзҡ„зңӢе®ҢиҝҷдёӘпјҢдҪ е°ұзҹҘйҒ“дёәд»Җд№Ҳhashcodeж–№жі•и°ғз”Ёзҡ„ж—¶еҖҷжңүж—¶еҖҷжҳҜжӯЈж•°пјҢжңүж—¶еҖҷжҳҜиҙҹж•°дәҶеҗ§пјҹжүҖд»ҘиҜҙеә•еұӮиҝҳжҳҜеҫҲжңүж„ҸжҖқзҡ„пјҢжҜ”еҰӮеҫҖеҗҺеҒҡеӨ§ж•°жҚ®ејҖеҸ‘пјҢйӮЈд№ҲиӮҜе®ҡжҳҜйңҖиҰҒж·ұе…ҘзҗҶи§Јиҝҷдәӣж•°жҚ®зұ»еһӢзҡ„иҢғеӣҙпјҢд»ҘеҸҠд»–зҡ„дёҖдёӘеҸҳеҢ–规еҲҷпјҢеҗҰеҲҷжңүж—¶еҖҷдёҚзҹҘдёҚи§үзҡ„е°ұзҠҜй”ҷдәҶпјҢдҪ иҝҳдёҚзҹҘйҒ“й”ҷиҜҜеңЁйӮЈе„ҝпјҹдёҘйҮҚзҡ„иҜқе°ұжҳҜдјҡжҚҹеӨұзІҫеәҰпјҢеҜјиҮҙз»“жһңе’ҢдҪ йў„жңҹзҡ„з»“жһңзӣёе·®з”ҡиҝңгҖӮе°ұеӣ дёәеҠ дәҶдёӘ1пјҢе°ұеҜјиҮҙз»“жһңе’Ңйў„жңҹз»“жһңзӣёе·®еҚҒдёҮе…«еҚғйҮҢгҖӮ
иҝҷжҳҜStringзұ»зҡ„hashcodeж–№жі•зҡ„дёҖдёӘе…·дҪ“е®һзҺ°иҝҮзЁӢгҖӮ
йҰ–е…Ҳе‘ўпјҹиҝҷдёӘиӮҜе®ҡжҳҜдёҚеҜ№зҡ„гҖӮ
еӣ дёәиҝҷдёӨдёӘж–№жі•йғҪеҸҜд»ҘйҮҚеҶҷпјҢеҰӮжһңжҳҜиҮӘе·ұзҡ„зұ»пјҢйӮЈд№ҲеҸҜд»ҘзҒөжҙ»йҮҚеҶҷпјҢеҰӮжһңжҳҜjdkиҮӘе·ұзҡ„зұ»пјҢйӮЈе°ұиҰҒзңӢд»–еҲ°еә•жңүжІЎжңүйҮҚеҶҷиҝҷдёӨдёӘж–№жі•гҖӮ
жҲ‘们д»ҘStringзұ»зҡ„equlasж–№жі•дёәдҫӢпјҡжҲ‘们йғҪзҹҘйҒ“пјҢеҰӮжһңequlasж–№жі•еҰӮжһңжІЎжңүйҮҚеҶҷпјҢйӮЈе°ұ继жүҝObjectзұ»зҡ„equlasж–№жі•пјҢй»ҳи®ӨжҜ”иҫғзҡ„жҳҜдёӨдёӘеҜ№иұЎзҡ„еҶ…еӯҳең°еқҖпјҢеҰӮжһңйҮҚеҶҷдәҶпјҢйӮЈе°ұж №жҚ®жҲ‘们иҮӘе·ұйҮҚеҶҷзҡ„规еҲҷжқҘжҜ”иҫғдёӨдёӘеҜ№иұЎжҳҜеҗҰзӣёзӯүгҖӮ
еҰӮдёӢжҳҜjdkStringзұ»дёӯиҮӘе·ұйҮҚеҶҷзҡ„equalsж–№жі•пјҢ
public boolean equals(Object anObject) {
// еҰӮжһңдёӨдёӘStringзұ»еһӢзҡ„еҜ№иұЎеҶ…еӯҳең°еқҖзӣёзӯүзӣҙжҺҘиҝ”еӣһtrue
if (this == anObject) {
return true;
}
// еҰӮдёӢеҒҡзҡ„ж“ҚдҪңе°ұжҳҜжҜ”иҫғдёӨдёӘеӯ—з¬ҰдёІдёӯзҡ„жҜҸдёҖдёӘcharзұ»еһӢзҡ„ж•°жҚ®пјҢеҰӮжһңйғҪе®Ңе…ЁеҢ№й…ҚпјҢйӮЈд№Ҳе°ұжҳҜиҝ”еӣһtrueпјҢеҰӮжһңжңүдёҖдёӘдёҚзӣёеҗҢпјҢзӣҙжҺҘиҝ”еӣһfalseпјҢ并且дёӨдёӘеӯ—з¬ҰдёІзҡ„й•ҝеәҰиҰҒзӣёзӯүпјҢеҰӮжһңдёҚзӣёеҗҢпјҢйӮЈд№ҲиӮҜе®ҡд№ҹе°ұдёҚеҸҜиғҪеҖјдёҖж ·дәҶеҳӣ
if (anObject instanceof String) {
String anotherString = (String)anObject;
int n = value.length;
if (n == anotherString.value.length) {
char v1[] = value;
char v2[] = anotherString.value;
int i = 0;
while (n-- != 0) {
if (v1[i] != v2[i])
return false;
i++;
}
return true;
}
}
return false;
}еҶҚзңӢдёӢStringзҡ„hashcodeж–№жі•пјҡе°ұжҳҜжҲ‘们дёҠйқўеҲҡеҲҡи®ІиҝҮзҡ„йӮЈдёӘж–№жі•
public int hashCode() {
int h = hash;
if (h == 0 && value.length > 0) {
char val[] = value;
for (int i = 0; i < value.length; i++) {
h = 31 * h + val[i];
}
hash = h;
}
return h;
}1пјҡеҰӮжһңдёӨдёӘStringзұ»еһӢзҡ„еҜ№иұЎеҶ…еӯҳең°еқҖзӣёзӯүзӣҙжҺҘиҝ”еӣһtrue
2пјҡжҜ”иҫғдёӨдёӘеӯ—з¬ҰдёІдёӯзҡ„жҜҸдёҖдёӘcharзұ»еһӢзҡ„ж•°жҚ®пјҢеҰӮжһңйғҪе®Ңе…ЁеҢ№й…ҚпјҢйӮЈд№Ҳе°ұжҳҜиҝ”еӣһtrueпјҢеҰӮжһңжңүдёҖдёӘдёҚзӣёеҗҢпјҢзӣҙжҺҘиҝ”еӣһfalseпјҢ并且дёӨдёӘеӯ—з¬ҰдёІзҡ„й•ҝеәҰиҰҒзӣёзӯүпјҢеҰӮжһңдёҚзӣёеҗҢпјҢйӮЈд№ҲиӮҜе®ҡд№ҹе°ұдёҚеҸҜиғҪеҖјдёҖж ·дәҶеҳӣ
з”ұжӯӨеҸҜд»ҘзңӢеҮәпјҢequalsж–№жі•жҳҜеҗҰиҝ”еӣһtrueи·ҹhashcodeж–№жі•жІЎжңүеҚҠжҜӣй’ұе…ізі»еҳӣгҖӮ
жҺҘдёӢжқҘжҲ‘们зңӢдёӢпјҢжҲ‘们иҮӘе®ҡд№үзҡ„еҜ№иұЎпјҢжҲ‘еҲӣе»әдёҖдёӘUserзұ»пјҢйҮҢйқўжңүеұһжҖ§idе’Ңname
public class User {
int id;
String name;
@Override
public String toString() {
return "User{" +
"id=" + id +
", name='" + name + '\'' +
'}';
}
}еңЁжІЎжңүйҮҚеҶҷhashcodeж–№жі•е’Ңequalsж–№жі•зҡ„жғ…еҶөдёӢиҝӣиЎҢжҜ”иҫғпјҡ
User user1 = new User(); User user2 = new User(); System.out.println(user1.hashCode()); System.out.println(user2.hashCode()); System.out.println(user1.equals(user2));

и§Јзӯ”пјҡеӣ дёәжҲ‘们没жңүйҮҚеҶҷпјҢиҝҷдёӨдёӘж–№жі•йғҪжҳҜ继жүҝиҮӘObjectзұ»зҡ„пјҢжүҖд»Ҙе‘ўпјҹжҜ”иҫғзҡ„жҳҜеҶ…еӯҳең°еқҖпјҢеӣ дёәжҲ‘们жҳҜйҖҡиҝҮnewзҡ„ж–№ејҸеҺ»еҲӣе»әзҡ„дёӨдёӘuserеҜ№иұЎпјҢйӮЈд№Ҳ他们зҡ„еҶ…еӯҳең°еқҖиӮҜе®ҡжҳҜдёҚзӣёеҗҢзҡ„пјҢжүҖд»ҘзӣҙжҺҘиҝ”еӣһfalseпјҢиҖҢhashcodeж–№жі•жҳҜjavaзҡ„еә•еұӮиҜӯиЁҖc++жқҘеҶҷзҡ„пјҢе…·дҪ“д»–еҶ…йғЁжҳҜжҖҺд№Ҳе®һзҺ°зҡ„пјҢе°ҒиЈ…дәҶпјҢжҲ‘д№ҹе°ұдёҚеҫ—иҖҢзҹҘдәҶпјҢеҗҺйқўеҶҚдәҶи§ЈпјҢжңүзҡ„дәәиҜҙжҳҜи·ҹеҶ…еӯҳең°еқҖзӣёе…іпјҢдҪҶжҳҜе…·дҪ“жҲ‘жІЎжңүзңӢеҲ°е…·дҪ“е®һзҺ°пјҢд№ҹдёҚж•ўиӢҹеҗҢпјҢжңүзҡ„дёңиҘҝпјҢйңҖиҰҒиҮӘе·ұдёҚж–ӯзҡ„еҺ»ж‘ёзҙўпјҢиҮӘе·ұдәІиҮӘе®һи·өпјҢжүҚжҳҜзңҹзҡ„пјҢдёҚиҰҒзӣёдҝЎеҲ«дәәиҜҙзҡ„гҖӮ
еҘҪзҡ„пјҢжҺҘдёӢжқҘжҲ‘们йҮҚеҶҷUserзұ»зҡ„hashcodeж–№жі•пјҡ
public class User {
int id;
String name;
@Override
public String toString() {
return "User{" +
"id=" + id +
", name='" + name + '\'' +
'}';
}
@Override
public int hashCode() {
return Objects.hash(id, name);
}
}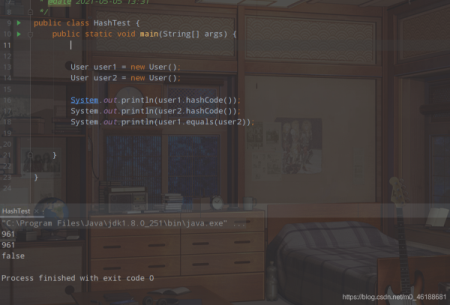
еҸҜд»ҘзңӢеҲ°зҡ„жҳҜпјҢжҲ‘们дёӨдёӘUserеҜ№иұЎзҡ„hashcodeж–№жі•иҝ”еӣһзҡ„hashеҖјжҳҜе®Ңе…ЁдёҖиҮҙзҡ„пјҢдҪҶжҳҜйҖҡиҝҮequalsж–№жі•иҝӣиЎҢжҜ”иҫғпјҢиҝҳжҳҜfalseпјҢжүҖд»ҘиҜҙпјҢдёӨдёӘеҜ№иұЎзҡ„hashcodeж–№жі•иҝ”еӣһзҡ„hashеҖјзӣёеҗҢпјҢequlasд№ҹдёҖе®ҡиҝ”еӣһtrueжҳҜе®Ңе…ЁдёҚжҲҗз«Ӣзҡ„пјҢзӣҙжҺҘжҺЁзҝ»гҖӮ
жҺҘдёӢжқҘжҲ‘们еҶҚж¬ЎйҮҚеҶҷequlasж–№жі•пјҢжӯӨж—¶жҲ‘们规е®ҡпјҢеҸӘиҰҒдёӨдёӘеҜ№иұЎзҡ„idе’ҢnameйғҪзӣёеҗҢпјҢйӮЈд№ҲиҝҷдёӨдёӘеҜ№иұЎе°ұжҳҜеҗҢдёҖдёӘеҜ№иұЎгҖӮ并且еҲ йҷӨжҺүеҲҡеҲҡжҲ‘们йҮҚеҶҷзҡ„hashcodeж–№жі•гҖӮ
public class User {
int id;
String name;
public User(int i, String name) {
this.id = id;
this.name = name;
}
@Override
public String toString() {
return "User{" +
"id=" + id +
", name='" + name + '\'' +
'}';
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
User user = (User) o;
return id == user.id &&
name.equals(user.name);
}
}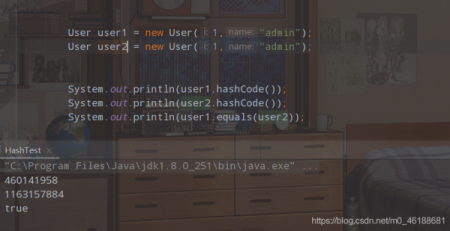
йҖҡиҝҮиҝҗиЎҢз»“жһңпјҢжҲ‘们еҸҜд»ҘзңӢеҲ°пјҢhashcodeж–№жі•иҝ”еӣһзҡ„hashеҖјдёҚдёҖиҮҙпјҢдҪҶжҳҜжҲ‘们зҡ„equlasж–№жі•дҫқж—§иҝ”еӣһзҡ„жҳҜtrueпјҢеӣ дёәиҝҷдёӘequlasж–№жі•жҳҜжҲ‘们йҮҚеҶҷиҝҮдәҶпјҢеңЁи°ғз”Ёзҡ„ж—¶еҖҷпјҢе°ұдёҚеңЁеҺ»жҺүObjectзҡ„equlasж–№жі•пјҢиҝӣиЎҢжҜ”иҫғеҶ…еӯҳең°еқҖпјҢиҖҢжҳҜжҢүз…§жҲ‘们зҡ„йҮҚеҶҷ规еҲҷпјҡеҰӮжһңдёӨдёӘuserеҜ№иұЎзҡ„idе’ҢnameзӣёеҗҢпјҢйӮЈд№Ҳе°ұжҳҜеҗҢдёҖдёӘеҜ№иұЎ,жүҖд»ҘеҲ°иҝҷйҮҢпјҢдҪ жҳҜдёҚжҳҜе°ұе…·дҪ“зҡ„зҗҶи§ЈдәҶhashcodeж–№жі•дёӘequlasд№Ӣй—ҙзҡ„е…ізі»е‘ўпјҹ
еҰӮжһңиҝҳжҳҜдёҚжҳҺзҷҪпјҢйӮЈеҶҚзңӢдёҖж¬ЎпјҢжҲ‘们зҺ°еңЁжҠҠUserзұ»зҡ„equlasж–№жі•е’Ңhashcodeж–№жі•йғҪеҶҷдёҠпјҢдҪҶжҳҜе‘ўпјҹжҲ‘дјҡеҲӣе»әдёӨiдёҚеҗҢзҡ„UserеҜ№иұЎпјҲд№ҹе°ұжҳҜidе’ҢnameйғҪдёҚдёҖж ·пјүгҖӮ
public class User {
int id;
String name;
public User(int i, String name) {
this.id = id;
this.name = name;
}
@Override
public String toString() {
return "User{" +
"id=" + id +
", name='" + name + '\'' +
'}';
}
@Override
public boolean equals(Object o) {
if (this == o) return true;
if (o == null || getClass() != o.getClass()) return false;
User user = (User) o;
return id == user.id &&
name.equals(user.name);
}
@Override
public int hashCode() {
return Objects.hash(id, name);
}
}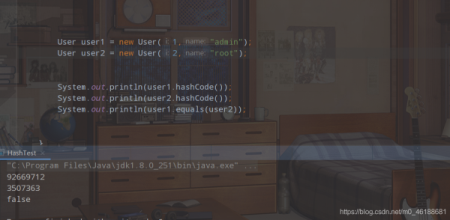
з”ұжӯӨеҸҜд»ҘзңӢеҲ°пјҢиҷҪ然hashcodeж–№жі•иҝ”еӣһзҡ„hashеҖјзӣёеҗҢпјҢдҪҶжҳҜйҖҡиҝҮequlasж–№жі•иҝӣиЎҢжҜ”иҫғпјҢиҝ”еӣһзҡ„зӣҙжҺҘе°ұжҳҜfalseгҖӮ
д»ҘдёҠжҳҜвҖңJavaдёӯhashcodeзҡ„зӨәдҫӢеҲҶжһҗвҖқиҝҷзҜҮж–Үз« зҡ„жүҖжңүеҶ…е®№пјҢж„ҹи°ўеҗ„дҪҚзҡ„йҳ…иҜ»пјҒзӣёдҝЎеӨ§е®¶йғҪжңүдәҶдёҖе®ҡзҡ„дәҶи§ЈпјҢеёҢжңӣеҲҶдә«зҡ„еҶ…е®№еҜ№еӨ§е®¶жңүжүҖеё®еҠ©пјҢеҰӮжһңиҝҳжғіеӯҰд№ жӣҙеӨҡзҹҘиҜҶпјҢж¬ўиҝҺе…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“пјҒ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ