жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
еҰӮдҪ•еңЁMySQLдёӯз»ҙжҠӨзҙўеј•е’Ңж•°жҚ®иЎЁпјҹеҫҲеӨҡж–°жүӢеҜ№жӯӨдёҚжҳҜеҫҲжё…жҘҡпјҢдёәдәҶеё®еҠ©еӨ§е®¶и§ЈеҶіиҝҷдёӘйҡҫйўҳпјҢдёӢйқўе°Ҹзј–е°ҶдёәеӨ§е®¶иҜҰз»Ҷи®Іи§ЈпјҢжңүиҝҷж–№йқўйңҖжұӮзҡ„дәәеҸҜд»ҘжқҘеӯҰд№ дёӢпјҢеёҢжңӣдҪ иғҪжңүжүҖ收иҺ·гҖӮ
ж•°жҚ®иЎЁжңҖзіҹзі•зҡ„дәӢжғ…е°ұжҳҜеҸ‘з”ҹеҶІзӘҒгҖӮдҪҝз”ЁMyISAMеӯҳеӮЁеј•ж“Һж—¶пјҢйҖҡеёёеӣ дёәеҙ©жәғеҜјиҮҙеҶІзӘҒгҖӮ然иҖҢпјҢеҪ“еӯҳеңЁзЎ¬д»¶ж•…йҡңгҖҒMySQLеҶ…йғЁBugжҲ–ж“ҚдҪңзі»з»ҹBugж—¶пјҢжүҖжңүзҡ„еӯҳеӮЁеј•ж“ҺйғҪеҸҜиғҪйҒӯеҸ—зҙўеј•еҶІзӘҒгҖӮ
еҶІзӘҒзҡ„зҙўеј•еҸҜиғҪеҜјиҮҙжҹҘиҜўиҝ”еӣһй”ҷиҜҜзҡ„з»“жһңпјҢеңЁжІЎжңүйҮҚеӨҚеҖјж—¶зҡ„йҮҚеӨҚзҙўеј•й”ҷиҜҜеўһеҠ пјҢз”ҡиҮіеҸҜиғҪеҜјиҮҙе…ЁиЎЁжү«жҸҸжҲ–еҙ©жәғгҖӮеҰӮжһңдҪ йҒҮеҲ°иҝҮеҒ¶еҸ‘зҡ„дәӢ件пјҢдҫӢеҰӮдёҖдёӘдҪ и®ӨдёәдёҚдјҡеҸ‘з”ҹзҡ„й”ҷиҜҜпјҢиҝҷдёӘж—¶еҖҷиҝҗиЎҢCHECK TABLEе‘Ҫд»ӨеҺ»жЈҖжөӢж•°жҚ®иЎЁжҳҜеҗҰжңүеҶІзӘҒпјҲжіЁж„Ҹжңүдәӣж•°жҚ®еә“еј•ж“ҺдёҚж”ҜжҢҒиҝҷдёӘе‘Ҫд»ӨпјҢжңүдәӣеҲҷж”ҜжҢҒеӨҡз§ҚйҖүйЎ№еҸӮж•°еҺ»жҢҮе®ҡеҰӮдҪ•жЈҖжөӢиЎЁпјүгҖӮйҖҡеёёпјҢCHECK TABLEе‘Ҫд»ӨдјҡжҚ•иҺ·еӨ§йғЁеҲҶзҡ„ж•°жҚ®иЎЁе’Ңзҙўеј•й”ҷиҜҜгҖӮ
дҪ еҸҜд»ҘйҖҡиҝҮREPAIR TABLEе‘Ҫд»Өдҝ®еӨҚж•°жҚ®иЎЁй”ҷиҜҜпјҢдҪҶжҳҜд№ҹдёҚжҳҜе…ЁйғЁеӯҳеӮЁеј•ж“ҺйғҪж”ҜжҢҒиҝҷдёӘе‘Ҫд»ӨгҖӮиҝҷдёӘж—¶еҖҷдҪ йңҖиҰҒжү§иЎҢдёҖдёӘвҖңжІЎжңүж“ҚдҪңвҖқзҡ„ALTERиҜӯеҸҘпјҢдҫӢеҰӮе°ҶдёҖдёӘж•°жҚ®иЎЁзҡ„еј•ж“Һдҝ®ж”№дёәе’ҢеҪ“еүҚзҡ„еј•ж“ҺдёҖж ·пјҢдҫӢеҰӮеҸҜд»ҘеҜ№InnoDBзҡ„ж•°жҚ®иЎЁжү§иЎҢдёӢйқўзҡ„иҜӯеҸҘпјҡ
ALTER TABLE innodb_tb1 ENGINE=INNODB;
зӣёеә”ең°пјҢдҪ д№ҹеҸҜд»ҘдҪҝз”ЁдёҖдёӘеӯҳеӮЁеј•ж“ҺжҢҮе®ҡзҡ„зҰ»зәҝдҝ®еӨҚе·Ҙе…·пјҢдҫӢеҰӮmyisamchkпјҢжҲ–иҖ…еҜјеҮәж•°жҚ®еҶҚйҮҚж–°еҜје…ҘгҖӮ然иҖҢпјҢеҰӮжһңеҶІзӘҒеҸ‘з”ҹеңЁзі»з»ҹеҢәпјҢжҲ–иҖ…еңЁж•°жҚ®иЎЁзҡ„ж•°жҚ®иЎҢеҢәеҹҹпјҢиҖҢдёҚжҳҜзҙўеј•зҡ„иҜқпјҢдҪ еҸҜиғҪж— жі•дҪҝз”ЁиҝҷдәӣеҠһжі•гҖӮиҝҷз§Қжғ…еҶөдёӢпјҢдҪ еҸҜиғҪйңҖиҰҒд»ҺдҪ зҡ„еӨҮд»ҪдёӯжҒўеӨҚж•°жҚ®жҲ–д»ҺеҶІзӘҒзҡ„ж–Ү件дёӯжҒўеӨҚж•°жҚ®гҖӮ
еҰӮжһңдҪ еңЁInnoDBдёӯд№ҹйҒҮеҲ°дәҶеҶІзӘҒпјҢиҝҷдјҡжҳҜжһҒе…¶дёҘйҮҚзҡ„й”ҷиҜҜпјҢдҪ йңҖиҰҒдҪҝз”ЁжӯЈзЎ®зҡ„ж–№жі•еҺ»еҲҶжһҗй—®йўҳгҖӮInnoDBйҖҡеёёдёҚдјҡеҸ‘з”ҹеҶІзӘҒгҖӮе®ғзҡ„и®ҫи®ЎеҜ№еҶІзӘҒеӨ„зҗҶеҫҲеҒҘеЈ®гҖӮеҶІзӘҒдјҡжҳҜ硬件故йҡңпјҲеҰӮеҶ…еӯҳеҢәй”ҷиҜҜжҲ–зЈҒзӣҳй”ҷиҜҜпјүпјҢDBAзҡ„ж“ҚдҪңй”ҷиҜҜпјҲеҰӮеңЁMySQLзҺҜеўғеӨ–ж“ҚдҪңдәҶж•°жҚ®еә“ж–Ү件пјүжҲ–InnoDBиҮӘиә«зҡ„Bug (иҝҷз§ҚжҰӮзҺҮеҫҲдҪҺпјүзҡ„иЎЁзҺ°гҖӮйҖҡеёёзҡ„дёҖдёӘеҺҹеӣ зұ»дјји§ҶеӣҫдҪҝз”Ёrsyncе·Ҙе…·еҲӣе»әеӨҮд»Ҫзҡ„й”ҷиҜҜгҖӮиҝҷж—¶жІЎжңүеҸҜжү§иЎҢзҡ„жҹҘиҜўвҖ”вҖ”з”ұдәҺиҝҷдјҡеј•иө·InnoDBзҡ„ж•°жҚ®еҶІзӘҒпјҢиҖҢдҪ и®ӨдёәиҝҷдјҡйҒҝе…ҚгҖӮеҰӮжһңдҪ йҖҡиҝҮдёҖдёӘжңүй—®йўҳзҡ„жҹҘиҜўеј•иө·дәҶInnoDBзҡ„ж•°жҚ®еҶІзӘҒпјҢйӮЈиҝҷ并дёҚжҳҜдҪ зҡ„й”ҷиҜҜпјҢиҝҷжҳҜInnoDBзҡ„BugгҖӮ
еҰӮжһңзңҹзҡ„йҒҮеҲ°дәҶж•°жҚ®еҶІзӘҒпјҢжңҖйҮҚиҰҒзҡ„дәӢжғ…жҳҜжҗһжё…жҘҡеј•иө·еҶІзӘҒзҡ„еҺҹеӣ пјҢеңЁиҝҷд№ӢеүҚдёҚиҰҒз®ҖеҚ•ең°дҝ®еӨҚж•°жҚ®пјҢд№ҹи®ёиҝҷдёӘеҶІзӘҒдјҡиҮӘеҠЁж¶ҲеӨұгҖӮдҪ еҸҜд»ҘйҖҡиҝҮinnodb_force_recoveryеҸӮж•°е°ҶInnoDBдҝ®ж”№дёәејәеҲ¶жҒўеӨҚжЁЎејҸжқҘдҝ®еӨҚж•°жҚ®пјҲеҸҜд»ҘжҹҘйҳ…MySQLзҡ„ж“ҚдҪңжүӢеҶҢпјүгҖӮдҪ д№ҹеҸҜд»ҘдҪҝз”ЁејҖжәҗзҡ„Percona InnoDBж•°жҚ®жҒўеӨҚе·Ҙе…·пјҲwww.percona.com/software/myвҖҰпјүд»ҺжҚҹеқҸзҡ„ж•°жҚ®ж–Ү件дёӯжҸҗеҸ–ж•°жҚ®гҖӮ
MySQLжҹҘиҜўдјҳеҢ–еҷЁеңЁеҶіе®ҡеҰӮдҪ•дҪҝз”Ёзҙўеј•еүҚпјҢдјҡи°ғз”ЁдёӨдёӘAPIиҺ·еҸ–зҙўеј•еҖјзҡ„еҲҶеёғгҖӮ第дёҖдёӘжҳҜrecords_in_rangeж–№жі•пјҢиҜҘж–№жі•жҺҘ收дёҖдёӘиҢғеӣҙеҸӮж•°пјҢ然еҗҺиҝ”еӣһиҜҘиҢғеӣҙзҡ„з»“жһңж•°йҮҸгҖӮеҜ№дәҺMyISAMеј•ж“ҺжқҘиҜҙиҝ”еӣһз»“жһңжҳҜеҮҶзЎ®зҡ„пјҢдҪҶжҳҜеҜ№дәҺInnoDBжқҘиҜҙжҳҜдј°и®ЎеҖјгҖӮ
第дәҢдёӘAPIжҳҜinfoж–№жі•пјҢиҜҘж–№жі•иҝ”еӣһеӨҡз§Қзұ»еһӢзҡ„ж•°жҚ®пјҢеҢ…жӢ¬зҙўеј•еҖҷйҖүиҖ…пјҲеҚіжҜҸдёӘзҙўеј•еҜ№еә”зҡ„и®°еҪ•ж•°йҮҸдј°и®ЎеҖјпјүгҖӮ
еҪ“еӯҳеӮЁеј•ж“Һз»ҷжҹҘиҜўдјҳеҢ–еҷЁжҸҗдҫӣдёҚеӨӘеҮҶзЎ®зҡ„ж•°жҚ®иЎҢж•°дҝЎжҒҜпјҢжҲ–жҹҘиҜўи®ЎеҲ’иҝҮдәҺеӨҚжқӮиҖҢж— жі•дј°и®ЎеҮҶзЎ®зҡ„иЎҢж•°ж—¶пјҢдјҳеҢ–еҷЁдҪҝз”Ёзҙўеј•з»ҹи®ЎеҺ»дј°и®Ўж•°жҚ®иЎҢж•°гҖӮMySQLдјҳеҢ–еҷЁжҳҜеҹәдәҺжҹҘиҜўд»Јд»·еҒҡеҮәеҶізӯ–зҡ„пјҢжңҖдё»иҰҒзҡ„д»Јд»·еҮҶеҲҷе°ұжҳҜиҝҷж¬ЎжҹҘиҜўдјҡжҹҘжүҫзҡ„ж•°жҚ®йҮҸгҖӮеҰӮжһңзҙўеј•з»ҹи®Ўд»ҺжқҘжІЎжңүз”ҹжҲҗпјҢжҲ–иҖ…жҳҜиҝҮжңҹдәҶпјҢдјҳеҢ–еҷЁеҸҜиғҪдјҡеҒҡеҮәй”ҷиҜҜзҡ„еҶіе®ҡгҖӮи§ЈеҶізҡ„ж–№жЎҲжҳҜиҝҗиЎҢANALYZE TABLEе‘Ҫд»ӨпјҢиҜҘе‘Ҫд»ӨдјҡйҮҚе»әзҙўеј•з»ҹи®ЎгҖӮ
жҜҸдёӘеӯҳеӮЁеј•ж“Һе®һзҺ°зҙўеј•з»ҹи®Ўзҡ„ж–№ејҸдёҚеҗҢпјҢеӣ жӯӨдҪ иҝҗиЎҢANALUZE TABLEе‘Ҫд»Өзҡ„йў‘зҺҮд№ҹдјҡдёҚеҗҢпјҢиҝҗиЎҢиҜҘе‘Ҫд»Өзҡ„д»Јд»·д№ҹдёҚеҗҢпјҢе…ёеһӢзҡ„еӯҳеӮЁеј•ж“ҺеҜ№зҙўеј•з»ҹи®ЎеӨ„зҗҶж–№ејҸеҰӮдёӢпјҡ
Memoryеј•ж“ҺдёҚеӯҳеӮЁзҙўеј•з»ҹи®ЎгҖӮ
MyISAMеңЁзЈҒзӣҳеӯҳеӮЁзҙўеј•з»ҹи®ЎпјҢ并且ANALYZE TABLEеңЁи®Ўз®—еҖҷйҖүж•°жҚ®иЎҢзҡ„ж—¶еҖҷдҪҝз”Ёе…Ёзҙўеј•жү«жҸҸгҖӮж•ҙдёӘиЎЁеңЁиҝҷдёӘиҝҮзЁӢдёӯдјҡиў«й”Ғе®ҡгҖӮ
InnoDBеңЁMySQL 5.5зүҲжң¬дёӯдёҚеңЁзЈҒзӣҳеӯҳеӮЁзҙўеј•з»ҹи®ЎпјҢиҖҢжҳҜйҖҡиҝҮйҡҸжңәзҡ„зҙўеј•йҮҮж ·е®һзҺ°е№¶дё”е°Ҷз»“жһңеӯҳеңЁеҶ…еӯҳдёӯгҖӮ
еҸҜд»ҘйҖҡиҝҮSHOW INDEX FROMе‘Ҫд»ӨжЈҖжҹҘзҙўеј•зҡ„еҖҷйҖүиҖ…гҖӮдҫӢеҰӮпјҡ
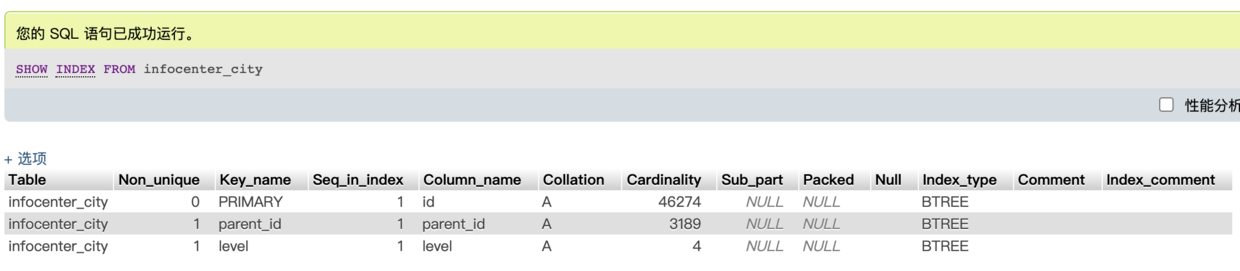
иҝҷдёӘе‘Ҫд»Өз»ҷдәҶеҫҲеӨҡзҙўеј•зӣёе…ізҡ„дҝЎжҒҜпјҢеҸҜд»ҘжҹҘйҳ…MySQLзҡ„жүӢеҶҢдәҶи§Је…·дҪ“з»ҶиҠӮгҖӮиҝҷйҮҢйңҖиҰҒзү№еҲ«е…іжіЁзҡ„жҳҜCardinalityеҲ—гҖӮиҜҘеҲ—еұ•зӨәдәҶеӯҳеӮЁеј•ж“Һдј°и®Ўзҡ„зҙўеј•еҜ№еә”дәҶеӨҡе°‘дёӘдёҚеҗҢзҡ„еҖјгҖӮеңЁMySQL 5.0еҸҠжӣҙж–°зҡ„зүҲжң¬дёӯпјҢд№ҹеҸҜд»ҘйҖҡиҝҮINFORMATION_SCHEMA.STATISTICSиЎЁдёӯиҺ·еҸ–иҝҷдәӣдҝЎжҒҜпјҢиҝҷеҚҒеҲҶж–№дҫҝгҖӮдҫӢеҰӮпјҢдҪ еҸҜд»Ҙж №жҚ®INFORMATION_SCHEMAжҹҘиҜўеҺ»жүҫеҲ°йӮЈдәӣдҪҺзӯӣйҖүжҖ§зҡ„зҙўеј•гҖӮдҪҶжҳҜжіЁж„ҸпјҢеҜ№дәҺж•°жҚ®йҮҸеәһеӨ§зҡ„жңҚеҠЎеҷЁпјҢиҝҷдәӣдёӯй—ҙиЎЁеҸҜиғҪдјҡеҜјиҮҙжңҚеҠЎеҷЁзҡ„иҙҹиҚ·еӨ§йҮҸеўһеҠ гҖӮ
InnoDBзҡ„з»ҹи®ЎеҖјеҫ—ж·ұе…Ҙз ”з©¶гҖӮз»ҹи®Ўзҡ„з»“жһңжҳҜйҖҡиҝҮзҙўеј•ж•°жҚ®йЎөзҡ„йҡҸжңәйҮҮж ·и®Ўз®—еҫ—еҲ°зҡ„пјҢиҝҷжҳҜеҒҮи®ҫеү©дҪҷжңӘиў«йҮҮж ·еҲ°зҡ„ж•°жҚ®д№ҹжҳҜзұ»дјјзҡ„еҲҶеёғгҖӮеңЁж—§зҡ„InnoDBзүҲжң¬дёӯпјҢиҝҷдёӘйҮҮж ·зҡ„йЎөж•°жҳҜ8пјҢдҪҶжңҖж–°зүҲжң¬зҡ„еҸҜд»ҘйҖҡиҝҮinnodb_stats_sample_pagesеҸҳйҮҸи°ғж•ҙгҖӮе°ҶиҝҷдёӘеҖји®ҫзҪ®дёәеӨ§дәҺ8жңүеҠ©дәҺз”ҹжҲҗжӣҙе…·д»ЈиЎЁжҖ§зҡ„зҙўеј•з»ҹи®ЎпјҢе°Өе…¶жҳҜеҜ№дәҺеӨ§зҡ„ж•°жҚ®иЎЁпјҢдҪҶжүҖйңҖиҰҒиҠұзҡ„д»Јд»·д№ҹдјҡдёҚеҗҢгҖӮ
InnoDBеңЁж•°жҚ®иЎЁз¬¬дёҖж¬Ўжү“ејҖпјҢиҝҗиЎҢANALUZE TABLEе’Ңж•°жҚ®иЎЁеӯҳеӮЁеӨ§е°Ҹжҳҫи‘—ж”№еҸҳж—¶пјҲ1/16зҡ„еҸҳеҢ–йҮҸжҲ–20дәҝиЎҢзҡ„жҸ’е…Ҙпјүдјҡи®Ўз®—зҙўеј•з»ҹи®ЎгҖӮ
INFORMATION_SCHEMAиЎЁзҡ„жҹҗдәӣжҹҘиҜўпјҢиҝҗиЎҢSHOW TABLE STATUSпјҢжү§иЎҢSHOW INDEXжҹҘиҜўжҲ–MySQLе‘Ҫд»ӨиЎҢе®ўжҲ·з«ҜеҗҜз”ЁдәҶиҮӘеҠЁе®ҢжҲҗи®ҫзҪ®пјҢInnoDBд№ҹдјҡи®Ўз®—зҙўеј•з»ҹи®ЎгҖӮиҝҷе®һйҷ…дјҡеҜ№еӨ§ж•°жҚ®йҮҸпјҢжҲ–I/OйҖҹеәҰеҫҲж…ўзҡ„жңҚеҠЎеҷЁйҖ жҲҗдёҘйҮҚзҡ„й—®йўҳгҖӮе®ўжҲ·з«ҜзЁӢеәҸжҲ–зӣ‘жҺ§е·Ҙе…·еҜјиҮҙеҸ‘з”ҹйҮҚж–°йҮҮж ·дјҡеҜјиҮҙеҫҲеӨҡй”Ғе’ҢеҠ йҮҚжңҚеҠЎеҷЁиҙҹжӢ…пјҢд№ҹдјҡеҪұе“Қз»Ҳз«Ҝз”ЁжҲ·зҡ„еҗҜеҠЁж—¶й—ҙгҖӮз”ұдәҺSHOW INDEXе‘Ҫд»Өдјҡжӣҙж–°зҙўеј•з»ҹи®ЎпјҢиҖҢеҰӮжһңдҪ дёҚжӣҙж”№зҡ„иҜқдҪ ж— жі•и§ӮжөӢеҲ°зҙўеј•з»ҹи®ЎгҖӮдҪ еҸҜд»ҘйҖҡиҝҮзҰҒз”Ёinnodb_stats_on_metadataпјҲй»ҳи®ӨжҳҜе…ій—ӯзҡ„пјүйҖүйЎ№еҺ»йҒҝе…Қиҝҷдәӣй—®йўҳгҖӮдёӢйқўзҡ„е‘Ҫд»ӨеҸҜд»ҘжҹҘеҮәInnoDBзҙўеј•з»ҹи®Ўзӣёе…ізҡ„зі»з»ҹеҸҳйҮҸгҖӮ
SHOW GLOBAL VARIABLES WHERE Variable_name like 'innodb_stats%'
еҰӮжһңдҪҝз”Ёзҡ„жҳҜеҢ…еҗ«дәҶжӣҝжҚўInnoDBзҡ„Percona XtraDBеӯҳеӮЁеј•ж“Һзҡ„PerconaжңҚеҠЎеҷЁпјҢдҪ еҸҜд»ҘеҒҡиҝӣдёҖжӯҘзҡ„й…ҚзҪ®гҖӮinnodb_stats_auto_updateйҖүйЎ№еҸҜд»Ҙи®©дҪ зҰҒжӯўиҮӘеҠЁйҮҮж ·пјҢеҸҜд»Ҙжңүж•ҲеҶ»з»“иҮӘеҠЁз»ҹи®Ўи®Ўз®—пјҢйҷӨйқһдҪ жүӢеҠЁиҝҗиЎҢANALYZE TABLEгҖӮиҝҷеҸҜд»Ҙи®©дҪ ж‘Ҷи„ұдёҚзЁіе®ҡзҡ„жҹҘиҜўгҖӮиҝҷдёӘзү№жҖ§жҳҜеҹәдәҺйӮЈдәӣеӨ§еһӢйғЁзҪІзі»з»ҹе®ўжҲ·зҡ„иҰҒжұӮж·»еҠ зҡ„гҖӮ
дёәиҝҪжұӮжӣҙй«ҳзҡ„жҹҘиҜўи®ЎеҲ’зЁіе®ҡжҖ§е’Ңжӣҙеҝ«зҡ„зі»з»ҹеҗҜеҠЁйҖҹеәҰпјҢдҪ еҸҜд»ҘдҪҝз”Ёзі»з»ҹзә§зҡ„ж•°жҚ®иЎЁеӯҳеӮЁзҙўеј•з»ҹи®ЎгҖӮиҝҷз§Қж–№ејҸеңЁзі»з»ҹйҮҚеҗҜжҲ–InnoDB第дёҖж¬ЎеҗҜеҠЁжү“ејҖж•°жҚ®иЎЁж—¶дёҚйңҖиҰҒйҮҚж–°и®Ўз®—зҙўеј•з»ҹи®ЎгҖӮиҝҷдёӘзү№жҖ§еңЁPercona 5.1зүҲжң¬е·Із»Ҹеҫ—еҲ°ж”ҜжҢҒпјҢ并且еңЁж ҮеҮҶзҡ„MySQL 5.6зүҲжң¬е·Із»Ҹеҫ—еҲ°ж”ҜжҢҒгҖӮPerconaжңҚеҠЎеҷЁиҝҷдёӘзү№жҖ§жҳҜйҖҡиҝҮinnodb_use_sys_stats_tableйҖүйЎ№еҗҜз”Ёзҡ„гҖӮеңЁMySQL 5.6зүҲжң¬еҗҺпјҢжҳҜйҖҡиҝҮinnodb_stats_persistentйҖүйЎ№жҺ§еҲ¶зҡ„пјҢй»ҳи®ӨжҳҜONгҖӮеҗҢж—¶пјҢиҝҳжңүдёҖдёӘеҸҳйҮҸжҺ§еҲ¶еҚ•иЎЁзҡ„пјҢinnodb_stats_auto_recalcеҸҳйҮҸй»ҳи®ӨдёәONпјҢдјҡеңЁж•°жҚ®иЎЁеҸҳеҢ–йҮҸи¶…иҝҮ10%ж—¶йҮҚж–°з»ҹи®ЎиҜҘиЎЁзҡ„зҙўеј•з»ҹи®ЎпјҲжүӢеҶҢеҸҜд»ҘеҸӮиҖғпјҡdev.mysql.com/doc/refman/вҖҰпјүгҖӮ
еҰӮжһңдҪ жІЎжңүй…ҚзҪ®иҮӘеҠЁжӣҙж–°зҙўеј•з»ҹи®ЎпјҢдҪ йңҖиҰҒе®ҡжңҹдҪҝз”ЁANALYZE TABLEе‘Ҫд»ӨжқҘжӣҙж–°зҙўеј•з»ҹи®ЎпјҢйҷӨйқһдҪ зҹҘйҒ“дёҚжӣҙж–°дёҚдјҡеҜјиҮҙзіҹзі•зҡ„жҹҘиҜўи®ЎеҲ’гҖӮ
зңӢе®ҢдёҠиҝ°еҶ…е®№жҳҜеҗҰеҜ№жӮЁжңүеё®еҠ©е‘ўпјҹеҰӮжһңиҝҳжғіеҜ№зӣёе…ізҹҘиҜҶжңүиҝӣдёҖжӯҘзҡ„дәҶи§ЈжҲ–йҳ…иҜ»жӣҙеӨҡзӣёе…іж–Үз« пјҢиҜ·е…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“пјҢж„ҹи°ўжӮЁеҜ№дәҝйҖҹдә‘зҡ„ж”ҜжҢҒгҖӮ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ