您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
这篇文章给大家分享的是有关pytorch如何实现手写数字图片识别的内容。小编觉得挺实用的,因此分享给大家做个参考,一起跟随小编过来看看吧。
具体内容如下
数据集:MNIST数据集,代码中会自动下载,不用自己手动下载。数据集很小,不需要GPU设备,可以很好的体会到pytorch的魅力。
模型+训练+预测程序:
import torch
from torch import nn
from torch.nn import functional as F
from torch import optim
import torchvision
from matplotlib import pyplot as plt
from utils import plot_image, plot_curve, one_hot
# step1 load dataset
batch_size = 512
train_loader = torch.utils.data.DataLoader(
torchvision.datasets.MNIST('mnist_data', train=True, download=True,
transform=torchvision.transforms.Compose([
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize(
(0.1307,), (0.3081,)
)
])),
batch_size=batch_size, shuffle=True)
test_loader = torch.utils.data.DataLoader(
torchvision.datasets.MNIST('mnist_data/', train=False, download=True,
transform=torchvision.transforms.Compose([
torchvision.transforms.ToTensor(),
torchvision.transforms.Normalize(
(0.1307,), (0.3081,)
)
])),
batch_size=batch_size, shuffle=False)
x , y = next(iter(train_loader))
print(x.shape, y.shape, x.min(), x.max())
plot_image(x, y, "image_sample")
class Net(nn.Module):
def __init__(self):
super(Net, self).__init__()
self.fc1 = nn.Linear(28*28, 256)
self.fc2 = nn.Linear(256, 64)
self.fc3 = nn.Linear(64, 10)
def forward(self, x):
# x: [b, 1, 28, 28]
# h2 = relu(xw1 + b1)
x = F.relu(self.fc1(x))
# h3 = relu(h2w2 + b2)
x = F.relu(self.fc2(x))
# h4 = h3w3 + b3
x = self.fc3(x)
return x
net = Net()
optimizer = optim.SGD(net.parameters(), lr=0.01, momentum=0.9)
train_loss = []
for epoch in range(3):
for batch_idx, (x, y) in enumerate(train_loader):
#加载进来的图片是一个四维的tensor,x: [b, 1, 28, 28], y:[512]
#但是我们网络的输入要是一个一维向量(也就是二维tensor),所以要进行展平操作
x = x.view(x.size(0), 28*28)
# [b, 10]
out = net(x)
y_onehot = one_hot(y)
# loss = mse(out, y_onehot)
loss = F.mse_loss(out, y_onehot)
optimizer.zero_grad()
loss.backward()
# w' = w - lr*grad
optimizer.step()
train_loss.append(loss.item())
if batch_idx % 10 == 0:
print(epoch, batch_idx, loss.item())
plot_curve(train_loss)
# we get optimal [w1, b1, w2, b2, w3, b3]
total_correct = 0
for x,y in test_loader:
x = x.view(x.size(0), 28*28)
out = net(x)
# out: [b, 10]
pred = out.argmax(dim=1)
correct = pred.eq(y).sum().float().item()
total_correct += correct
total_num = len(test_loader.dataset)
acc = total_correct/total_num
print("acc:", acc)
x, y = next(iter(test_loader))
out = net(x.view(x.size(0), 28*28))
pred = out.argmax(dim=1)
plot_image(x, pred, "test")主程序中调用的函数(注意命名为utils):
import torch
from matplotlib import pyplot as plt
def plot_curve(data):
fig = plt.figure()
plt.plot(range(len(data)), data, color='blue')
plt.legend(['value'], loc='upper right')
plt.xlabel('step')
plt.ylabel('value')
plt.show()
def plot_image(img, label, name):
fig = plt.figure()
for i in range(6):
plt.subplot(2, 3, i + 1)
plt.tight_layout()
plt.imshow(img[i][0]*0.3081+0.1307, cmap='gray', interpolation='none')
plt.title("{}: {}".format(name, label[i].item()))
plt.xticks([])
plt.yticks([])
plt.show()
def one_hot(label, depth=10):
out = torch.zeros(label.size(0), depth)
idx = torch.LongTensor(label).view(-1, 1)
out.scatter_(dim=1, index=idx, value=1)
return out打印出损失下降的曲线图:
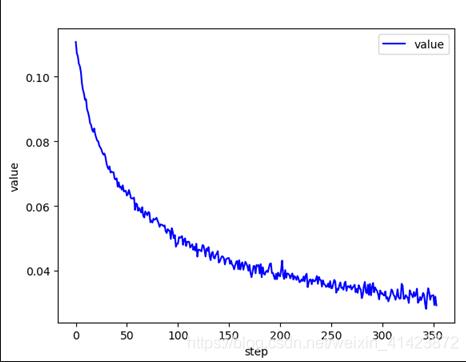
训练3个epoch之后,在测试集上的精度就可以89%左右,可见模型的准确度还是很不错的。
输出六张测试集的图片以及预测结果:

六张图片的预测全部正确。
1.PyTorch是相当简洁且高效快速的框架;2.设计追求最少的封装;3.设计符合人类思维,它让用户尽可能地专注于实现自己的想法;4.与google的Tensorflow类似,FAIR的支持足以确保PyTorch获得持续的开发更新;5.PyTorch作者亲自维护的论坛 供用户交流和求教问题6.入门简单
感谢各位的阅读!关于“pytorch如何实现手写数字图片识别”这篇文章就分享到这里了,希望以上内容可以对大家有一定的帮助,让大家可以学到更多知识,如果觉得文章不错,可以把它分享出去让更多的人看到吧!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。