您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
这篇文章给大家分享的是有关Python爬虫之如何爬取我爱我家二手房数据的内容。小编觉得挺实用的,因此分享给大家做个参考,一起跟随小编过来看看吧。
首先,运行下述代码,复现问题:
# -*-coding:utf-8-*-
import re
import requests
from bs4 import BeautifulSoup
cookie = 'PHPSESSID=aivms4ufg15sbrj0qgboo3c6gj; HMF_CI=4d8ff20092e9832daed8fe5eb0475663812603504e007aca93e6630c00b84dc207; _ga=GA1.2.556271139.1620784679; gr_user_id=4c878c8f-406b-46a0-86ee-a9baf2267477; _dx_uzZo5y=68b673b0aaec1f296c34e36c9e9d378bdb2050ab4638a066872a36f781c888efa97af3b5; smidV2=20210512095758ff7656962db3adf41fa8fdc8ddc02ecb00bac57209becfaa0; yfx_c_g_u_id_10000001=_ck21051209583410015104784406594; __TD_deviceId=41HK9PMCSF7GOT8G; zufang_cookiekey=["%7B%22url%22%3A%22%2Fzufang%2F_%25E9%2595%25BF%25E6%2598%25A5%25E6%25A1%25A5%3Fzn%3D%25E9%2595%25BF%25E6%2598%25A5%25E6%25A1%25A5%22%2C%22x%22%3A%220%22%2C%22y%22%3A%220%22%2C%22name%22%3A%22%E9%95%BF%E6%98%A5%E6%A1%A5%22%2C%22total%22%3A%220%22%7D","%7B%22url%22%3A%22%2Fzufang%2F_%25E8%258B%258F%25E5%25B7%259E%25E8%25A1%2597%3Fzn%3D%25E8%258B%258F%25E5%25B7%259E%25E8%25A1%2597%22%2C%22x%22%3A%220%22%2C%22y%22%3A%220%22%2C%22name%22%3A%22%E8%8B%8F%E5%B7%9E%E8%A1%97%22%2C%22total%22%3A%220%22%7D","%7B%22url%22%3A%22%2Fzufang%2F_%25E8%258B%258F%25E5%25B7%259E%25E6%25A1%25A5%3Fzn%3D%25E8%258B%258F%25E5%25B7%259E%25E6%25A1%25A5%22%2C%22x%22%3A%220%22%2C%22y%22%3A%220%22%2C%22name%22%3A%22%E8%8B%8F%E5%B7%9E%E6%A1%A5%22%2C%22total%22%3A%220%22%7D"]; ershoufang_cookiekey=["%7B%22url%22%3A%22%2Fzufang%2F_%25E9%2595%25BF%25E6%2598%25A5%25E6%25A1%25A5%3Fzn%3D%25E9%2595%25BF%25E6%2598%25A5%25E6%25A1%25A5%22%2C%22x%22%3A%220%22%2C%22y%22%3A%220%22%2C%22name%22%3A%22%E9%95%BF%E6%98%A5%E6%A1%A5%22%2C%22total%22%3A%220%22%7D","%7B%22url%22%3A%22%2Fershoufang%2F_%25E8%258B%258F%25E5%25B7%259E%25E6%25A1%25A5%3Fzn%3D%25E8%258B%258F%25E5%25B7%259E%25E6%25A1%25A5%22%2C%22x%22%3A%220%22%2C%22y%22%3A%220%22%2C%22name%22%3A%22%E8%8B%8F%E5%B7%9E%E6%A1%A5%22%2C%22total%22%3A%220%22%7D"]; zufang_BROWSES=501465046,501446051,90241951,90178388,90056278,90187979,501390110,90164392,90168076,501472221,501434480,501480593,501438374,501456072,90194547,90223523,501476326,90245144; historyCity=["\u5317\u4eac"]; _gid=GA1.2.23153704.1621410645; Hm_lvt_94ed3d23572054a86ed341d64b267ec6=1620784715,1621410646; _Jo0OQK=4958FA78A5CC420C425C480565EB46670E81832D8173C5B3CFE61303A51DE43E320422D6C7A15892C5B8B66971ED1B97A7334F0B591B193EBECAAB0E446D805316B26107A0B847CA53375B268E06EC955BB75B268E06EC955BB9D992FB153179892GJ1Z1OA==; ershoufang_BROWSES=501129552; domain=bj; 8fcfcf2bd7c58141_gr_session_id=61676ce2-ea23-4f77-8165-12edcc9ed902; 8fcfcf2bd7c58141_gr_session_id_61676ce2-ea23-4f77-8165-12edcc9ed902=true; yfx_f_l_v_t_10000001=f_t_1620784714003__r_t_1621471673953__v_t_1621474304616__r_c_2; Hm_lpvt_94ed3d23572054a86ed341d64b267ec6=1621475617'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.72 Safari/537.36',
'Cookie': cookie.encode("utf-8").decode("latin1")
}
def run():
base_url = 'https://bj.5i5j.com/ershoufang/xichengqu/n%d/'
for page in range(1, 11):
url = base_url % page
print(url)
html = requests.get(url, headers=headers).text
soup = BeautifulSoup(html, 'lxml')
try:
for li in soup.find('div', class_='list-con-box').find('ul', class_='pList').find_all('li'):
title = li.find('h4', class_='listTit').get_text() # 名称
# print(title)
except Exception as e:
print(e)
print(html)
break
if __name__ == '__main__':
run()运行后会发现,在抓取https://bj.5i5j.com/ershoufang/xichengqu/n1/(也可能是其他页码)时,会报错:'NoneType' object has no attribute 'find',观察输出的html信息,可以发现html内容为:<HTML><HEAD><script>window.location.href="https://bj.5i5j.com/ershoufang/xichengqu/n1/?wscckey=0f36b400da92f41d_1621823822" rel="external nofollow" ;</script></HEAD><BODY>,但此链接在浏览器访问是可以看到数据的,但链接会被重定向,重定向后的url即为上面这个html的href内容。因此,可以合理的推断,针对部分页码链接,我爱我家不会直接返回数据,但会返回带有正确链接的信息,通过正则表达式获取该链接即可正确抓取数据。
在下面的完整代码中,采取的解决方法是:
1.首先判断当前html是否含有数据
2.若无数据,则通过正则表达式获取正确链接
3.重新获取html数据
if '<HTML><HEAD><script>window.location.href=' in html: url = re.search(r'.*?href="(.+)" rel="external nofollow" rel="external nofollow" .*?', html).group(1) html = requests.get(url, headers=headers).text
# -*-coding:utf-8-*-
import os
import re
import requests
import csv
import time
from bs4 import BeautifulSoup
folder_path = os.path.split(os.path.abspath(__file__))[0] + os.sep # 获取当前文件所在目录
cookie = 'PHPSESSID=aivms4ufg15sbrj0qgboo3c6gj; HMF_CI=4d8ff20092e9832daed8fe5eb0475663812603504e007aca93e6630c00b84dc207; _ga=GA1.2.556271139.1620784679; gr_user_id=4c878c8f-406b-46a0-86ee-a9baf2267477; _dx_uzZo5y=68b673b0aaec1f296c34e36c9e9d378bdb2050ab4638a066872a36f781c888efa97af3b5; smidV2=20210512095758ff7656962db3adf41fa8fdc8ddc02ecb00bac57209becfaa0; yfx_c_g_u_id_10000001=_ck21051209583410015104784406594; __TD_deviceId=41HK9PMCSF7GOT8G; zufang_cookiekey=["%7B%22url%22%3A%22%2Fzufang%2F_%25E9%2595%25BF%25E6%2598%25A5%25E6%25A1%25A5%3Fzn%3D%25E9%2595%25BF%25E6%2598%25A5%25E6%25A1%25A5%22%2C%22x%22%3A%220%22%2C%22y%22%3A%220%22%2C%22name%22%3A%22%E9%95%BF%E6%98%A5%E6%A1%A5%22%2C%22total%22%3A%220%22%7D","%7B%22url%22%3A%22%2Fzufang%2F_%25E8%258B%258F%25E5%25B7%259E%25E8%25A1%2597%3Fzn%3D%25E8%258B%258F%25E5%25B7%259E%25E8%25A1%2597%22%2C%22x%22%3A%220%22%2C%22y%22%3A%220%22%2C%22name%22%3A%22%E8%8B%8F%E5%B7%9E%E8%A1%97%22%2C%22total%22%3A%220%22%7D","%7B%22url%22%3A%22%2Fzufang%2F_%25E8%258B%258F%25E5%25B7%259E%25E6%25A1%25A5%3Fzn%3D%25E8%258B%258F%25E5%25B7%259E%25E6%25A1%25A5%22%2C%22x%22%3A%220%22%2C%22y%22%3A%220%22%2C%22name%22%3A%22%E8%8B%8F%E5%B7%9E%E6%A1%A5%22%2C%22total%22%3A%220%22%7D"]; ershoufang_cookiekey=["%7B%22url%22%3A%22%2Fzufang%2F_%25E9%2595%25BF%25E6%2598%25A5%25E6%25A1%25A5%3Fzn%3D%25E9%2595%25BF%25E6%2598%25A5%25E6%25A1%25A5%22%2C%22x%22%3A%220%22%2C%22y%22%3A%220%22%2C%22name%22%3A%22%E9%95%BF%E6%98%A5%E6%A1%A5%22%2C%22total%22%3A%220%22%7D","%7B%22url%22%3A%22%2Fershoufang%2F_%25E8%258B%258F%25E5%25B7%259E%25E6%25A1%25A5%3Fzn%3D%25E8%258B%258F%25E5%25B7%259E%25E6%25A1%25A5%22%2C%22x%22%3A%220%22%2C%22y%22%3A%220%22%2C%22name%22%3A%22%E8%8B%8F%E5%B7%9E%E6%A1%A5%22%2C%22total%22%3A%220%22%7D"]; zufang_BROWSES=501465046,501446051,90241951,90178388,90056278,90187979,501390110,90164392,90168076,501472221,501434480,501480593,501438374,501456072,90194547,90223523,501476326,90245144; historyCity=["\u5317\u4eac"]; _gid=GA1.2.23153704.1621410645; Hm_lvt_94ed3d23572054a86ed341d64b267ec6=1620784715,1621410646; _Jo0OQK=4958FA78A5CC420C425C480565EB46670E81832D8173C5B3CFE61303A51DE43E320422D6C7A15892C5B8B66971ED1B97A7334F0B591B193EBECAAB0E446D805316B26107A0B847CA53375B268E06EC955BB75B268E06EC955BB9D992FB153179892GJ1Z1OA==; ershoufang_BROWSES=501129552; domain=bj; 8fcfcf2bd7c58141_gr_session_id=61676ce2-ea23-4f77-8165-12edcc9ed902; 8fcfcf2bd7c58141_gr_session_id_61676ce2-ea23-4f77-8165-12edcc9ed902=true; yfx_f_l_v_t_10000001=f_t_1620784714003__r_t_1621471673953__v_t_1621474304616__r_c_2; Hm_lpvt_94ed3d23572054a86ed341d64b267ec6=1621475617'
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/90.0.4430.72 Safari/537.36',
'Cookie': cookie.encode("utf-8").decode("latin1")
}
def get_page(url):
"""获取网页原始数据"""
global headers
html = requests.get(url, headers=headers).text
return html
def extract_info(html):
"""解析网页数据,抽取出房源相关信息"""
host = 'https://bj.5i5j.com'
soup = BeautifulSoup(html, 'lxml')
data = []
for li in soup.find('div', class_='list-con-box').find('ul', class_='pList').find_all('li'):
try:
title = li.find('h4', class_='listTit').get_text() # 名称
url = host + li.find('h4', class_='listTit').a['href'] # 链接
info_li = li.find('div', class_='listX') # 每个房源核心信息都在这里
p1 = info_li.find_all('p')[0].get_text() # 获取第一段
info1 = [i.strip() for i in p1.split(' · ')]
# 户型、面积、朝向、楼层、装修、建成时间
house_type, area, direction, floor, decoration, build_year = info1
p2 = info_li.find_all('p')[1].get_text() # 获取第二段
info2 = [i.replace(' ', '') for i in p2.split('·')]
# 小区、位于几环、交通信息
if len(info2) == 2:
residence, ring = info2
transport = '' # 部分房源无交通信息
elif len(info2) == 3:
residence, ring, transport = info2
else:
residence, ring, transport = ['', '', '']
p3 = info_li.find_all('p')[2].get_text() # 获取第三段
info3 = [i.replace(' ', '') for i in p3.split('·')]
# 关注人数、带看次数、发布时间
try:
watch, arrive, release_year = info3
except Exception as e:
print(info2, '获取带看、发布日期信息出错')
watch, arrive, release_year = ['', '', '']
total_price = li.find('p', class_='redC').get_text().strip() # 房源总价
univalence = li.find('div', class_='jia').find_all('p')[1].get_text().replace('单价', '') # 房源单价
else_info = li.find('div', class_='listTag').get_text()
data.append([title, url, house_type, area, direction, floor, decoration, residence, ring,
transport, total_price, univalence, build_year, release_year, watch, arrive, else_info])
except Exception as e:
print('extract_info: ', e)
return data
def crawl():
esf_url = 'https://bj.5i5j.com/ershoufang/' # 主页网址
fields = ['城区', '名称', '链接', '户型', '面积', '朝向', '楼层', '装修', '小区', '环', '交通情况', '总价', '单价',
'建成时间', '发布时间', '关注', '带看', '其他信息']
f = open(folder_path + 'data' + os.sep + '北京二手房-我爱我家.csv', 'w', newline='', encoding='gb18030')
writer = csv.writer(f, delimiter=',') # 以逗号分割
writer.writerow(fields)
page = 1
regex = re.compile(r'.*?href="(.+)" rel="external nofollow" rel="external nofollow" .*?')
while True:
url = esf_url + 'n%s/' % page # 构造页面链接
if page == 1:
url = esf_url
html = get_page(url)
# 部分页面链接无法获取数据,需进行判断,并从返回html内容中获取正确链接,重新获取html
if '<HTML><HEAD><script>window.location.href=' in html:
url = regex.search(html).group(1)
html = requests.get(url, headers=headers).text
print(url)
data = extract_info(html)
if data:
writer.writerows(data)
page += 1
f.close()
if __name__ == '__main__':
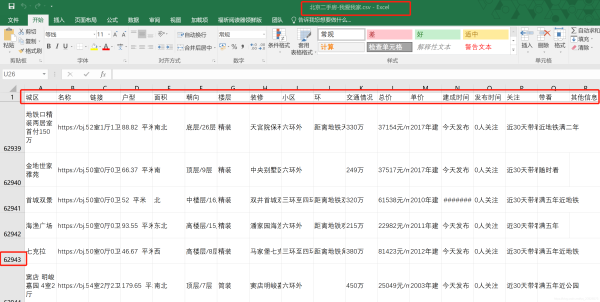
crawl() # 启动爬虫截至2021年5月23日,共获取数据62943条,基本上将我爱我家官网上北京地区的二手房数据全部抓取下来了。
感谢各位的阅读!关于“Python爬虫之如何爬取我爱我家二手房数据”这篇文章就分享到这里了,希望以上内容可以对大家有一定的帮助,让大家可以学到更多知识,如果觉得文章不错,可以把它分享出去让更多的人看到吧!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。