您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
小编给大家分享一下java并发编程工具类JUC之LinkedBlockingQueue链表队列的示例分析,相信大部分人都还不怎么了解,因此分享这篇文章给大家参考一下,希望大家阅读完这篇文章后大有收获,下面让我们一起去了解一下吧!
java.util.concurrent.LinkedBlockingQueue 是一个基于单向链表的、范围任意的(其实是有界的)、FIFO阻塞队列。访问与移除操作是在队头进行,添加操作是在队尾进行,并分别使用不同的锁进行保护,只有在可能涉及多个节点的操作才同时对两个锁进行加锁。
队列是否为空、是否已满仍然是通过元素数量的计数器(count)进行判断的,由于可以同时在队头、队尾并发地进行访问、添加操作,所以这个计数器必须是线程安全的,这里使用了一个原子类 AtomicInteger,这就决定了它的容量范围是: 1 –Integer.MAX_VALUE。
在之前的文章中已经为大家介绍了java并发编程的工具:BlockingQueue接口、ArrayBlockingQueue、DelayQueue。
LinkedBlockingQueue 队列是BlockingQueue接口的实现类,所以它具有BlockingQueue接口的一切功能特点。LinkedBlockingQueue队列 按照first-in-first-out (FIFO)先进先出的方式对元素进行排序。LinkeBlockingQueue 提供了两种构造函数,一个构造函数构造一个队列容量为固定个数的队列,另一个无参构造函数构造一个队列容量为Integer.MAX_VALUE的队列.
public LinkedBlockingQueue() {
this(Integer.MAX_VALUE);
}
public LinkedBlockingQueue(int capacity) {
if (capacity <= 0) throw new IllegalArgumentException();
this.capacity = capacity;
last = head = new Node<E>(null);
}ArrayBlockingQueue和LinkedBlockingQueue都是实现BlockingQueue接口,所以在使用方式上是一致的,下面我们就不介绍使用方法,而是从二者的性能及底层数据结构的实现角度进行
ArrayBlockingQueue插入和删除数据,只采用了一个lock锁,读取和写入操作无法并行。 所以在高并发场景下执行效率会比LinkedBlockingQueue慢一些。
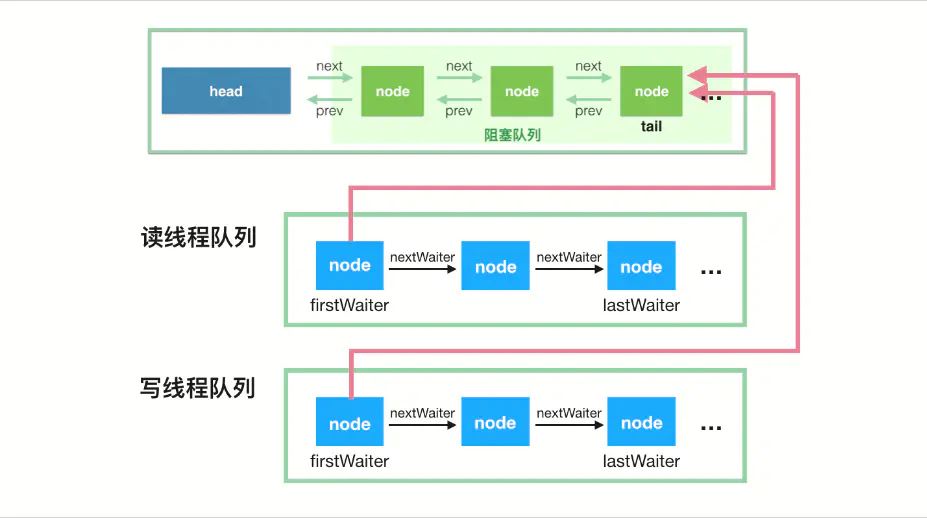
LinkedBlockingQueue采用“two lock queue”算法变体,双锁(ReentrantLock):takeLock、putLock,允许读写并行,remove(e)和迭代器iterators需要获取2个锁。这样可以降低线程由于线程无法获取到lock而进入WAITING状态的可能性,从而提高了线程并发执行的效率。
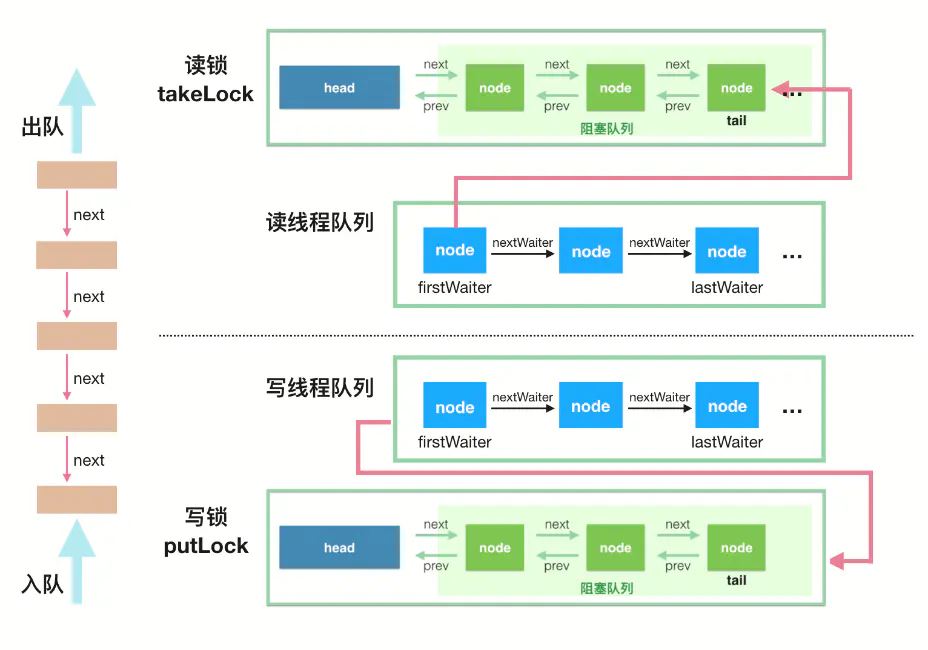
ArrayBlockingQueue底层代码是采用数组实现的,创建的时候必须指定队列的容量并分配存储空间;LinkedBlockingQueue采用的是链表数据结构实现的,其链表节点的存储空间分配是动态的,新的元素对象加入队列分配空间,元素对象从队列取出之后存储空间GC,初始化时指定的是队列的最大容量。但是使用链表数据结构既是LinkedBlockingQueue优势也是它的劣势,高并发场景下由于空间动态分配需要java JVM频繁的进行垃圾回收。
总体来说在并发场景下,LinkedBlockingQueue的吞吐量比ArrayBlockingQueue更好。但是在java实现高性能队列的首选是disruptor,它不是JDK自带的。java程序员非常熟悉的Log4j2底层性能比logback和log4j有了较大的提升,究其原因就是使用了disruptor高性能队列实现的异步日志
以上是“java并发编程工具类JUC之LinkedBlockingQueue链表队列的示例分析”这篇文章的所有内容,感谢各位的阅读!相信大家都有了一定的了解,希望分享的内容对大家有所帮助,如果还想学习更多知识,欢迎关注亿速云行业资讯频道!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。