жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
е°Ҹзј–з»ҷеӨ§е®¶еҲҶдә«дёҖдёӢJavaеҶ…еӯҳжЁЎеһӢд№ӢйҮҚжҺ’еәҸзҡ„зӨәдҫӢеҲҶжһҗпјҢеёҢжңӣеӨ§е®¶йҳ…иҜ»е®ҢиҝҷзҜҮж–Үз« д№ӢеҗҺйғҪжңүжүҖ收иҺ·пјҢдёӢйқўи®©жҲ‘们дёҖиө·еҺ»жҺўи®Ёеҗ§пјҒ
еҰӮжһңдёӨдёӘж“ҚдҪңи®ҝй—®еҗҢдёҖдёӘеҸҳйҮҸпјҢиҖҢдё”иҝҷдёӨдёӘж“ҚдҪңдёӯжңүдёҖдёӘж“ҚдҪңдёәеҶҷж“ҚдҪңпјҢжӯӨж—¶иҝҷдёӨдёӘж“ҚдҪңд№Ӣй—ҙеӯҳеңЁж•°жҚ®дҫқиө–жҖ§гҖӮж•°жҚ®дҫқиө–жҖ§еҲҶдёәдёүз§ҚпјҢеҰӮиЎЁжүҖзӨәпјҡ
| еҗҚз§° | д»Јз ҒзӨәдҫӢ | иҜҙжҳҺ |
|---|---|---|
| еҶҷеҗҺиҜ» | a=1;b=a; | еҶҷдёҖдёӘеҸҳйҮҸеҗҺпјҢеҶҚиҜ»иҝҷдёӘдҪҚзҪ® |
| еҶҷеҗҺеҶҷ | a=1;a=2; | еҶҷдёҖдёӘеҸҳйҮҸеҗҺпјҢеңЁеҶҷиҝҷдёӘеҸҳйҮҸ |
| иҜ»еҗҺеҶҷ | a=b;b=1; | иҜ»дёҖдёӘеҸҳйҮҸеҗҺпјҢеҶҚеҶҷиҝҷдёӘеҸҳйҮҸ |
дёҠйқўзҡ„иҝҷдёүз§Қжғ…еҶөпјҢеҸӘиҰҒйҮҚжҺ’еәҸдәҶдёӨдёӘж“ҚдҪңзҡ„жү§иЎҢйЎәеәҸпјҢзЁӢеәҸзҡ„жү§иЎҢз»“жһңе°ұдјҡиў«ж”№еҸҳгҖӮзј–иҜ‘еҷЁе’ҢеӨ„зҗҶеҷЁй’ҲеҜ№еҚ•дёӘеӨ„зҗҶеҷЁдёӯжү§иЎҢзҡ„жҢҮд»ӨеәҸеҲ—е’ҢеҚ•дёӘзәҝзЁӢдёӯжү§иЎҢзҡ„ж“ҚдҪңйҮҚжҺ’еәҸж—¶пјҢдјҡйҒөе®Ҳж•°жҚ®дҫқиө–жҖ§пјҢзј–иҜ‘еҷЁе’ҢеӨ„зҗҶеҷЁдёҚдјҡж”№еҸҳеӯҳеңЁж•°жҚ®дҫқиө–е…ізі»зҡ„дёӨдёӘж“ҚдҪңзҡ„жү§иЎҢйЎәеәҸгҖӮпјҲдёҚеҗҢеӨ„зҗҶеҷЁе’ҢдёҚеҗҢзәҝзЁӢд№Ӣй—ҙзҡ„ж•°жҚ®дҫқиө–жҖ§дёҚиў«зј–иҜ‘еҷЁе’ҢеӨ„зҗҶеҷЁиҖғиҷ‘пјүгҖӮ
as-if-serialиҜӯд№үжҢҮзҡ„жҳҜпјҡдёҚз®ЎжҖҺд№ҲйҮҚжҺ’еәҸпјҢеҚ•зәҝзЁӢжү§иЎҢзЁӢеәҸзҡ„жү§иЎҢз»“жһңдёҚиғҪиў«ж”№еҸҳгҖӮзј–иҜ‘еҷЁгҖҒruntimeе’ҢеӨ„зҗҶеҷЁйғҪеҝ…йЎ»йҒөе®Ҳas-if-serialиҜӯд№үгҖӮ
дёәдәҶйҒөе®Ҳas-if-serialиҜӯд№үпјҢзј–иҜ‘еҷЁе’ҢеӨ„зҗҶеҷЁдёҚдјҡеҜ№еӯҳеңЁж•°жҚ®дҫқиө–е…ізі»зҡ„ж“ҚдҪңеҒҡйҮҚжҺ’еәҸпјҢеӣ дёә иҝҷз§ҚйҮҚжҺ’еәҸдјҡж”№еҸҳжү§иЎҢз»“жһңгҖӮдҪҶжҳҜпјҢеҰӮжһңж“ҚдҪңд№Ӣй—ҙдёҚеӯҳеңЁж•°жҚ®дҫқиө–е…ізі»пјҢиҝҷдәӣж“ҚдҪңе°ұеҸҜиғҪиў«зј–иҜ‘еҷЁе’ҢеӨ„зҗҶеҷЁйҮҚжҺ’еәҸгҖӮ
дёҫдҫӢиҜҙжҳҺпјҢи®Ўз®—еңҶйқўз§Ҝзҡ„д»Јз ҒзӨәдҫӢпјҡ
double pi = 3.14; // A double r = 1.0; // B double area = pi * r; // C
дёҠйқў3дёӘж“ҚдҪңзҡ„ж•°жҚ®дҫқиө–е…ізі»еҰӮдёӢжүҖзӨәпјҡ
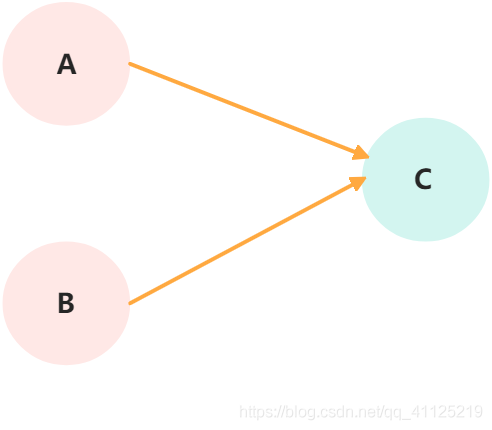
3дёӘж“ҚдҪңд№Ӣй—ҙзҡ„дҫқиө–е…ізі»
и§ЈйҮҠпјҡAе’ҢBд№Ӣй—ҙеӯҳеңЁж•°жҚ®дҫқиө–е…ізі»пјҢеҗҢж—¶Bе’ҢCд№Ӣй—ҙд№ҹеӯҳеңЁж•°жҚ®дҫқиө–е…ізі»гҖӮеӣ жӯӨеңЁжңҖз»Ҳжү§иЎҢзҡ„жҢҮд»ӨеәҸеҲ—дёӯпјҢCдёҚеҸҜиғҪиў«жҺ’еҲ°Aе’ҢBзҡ„еүҚйқўпјҲCжҺ’еҲ°Aе’ҢBзҡ„еүҚйқўпјҢзЁӢеәҸзҡ„з»“жһңе°Ҷдјҡиў«ж”№еҸҳпјүгҖӮдҪҶAе’ҢBд№Ӣй—ҙжІЎжңүж•°жҚ®дҫқиө–е…ізі»пјҢзј–иҜ‘еҷЁе’ҢеӨ„зҗҶеҷЁеҸҜйҮҚжҺ’еәҸAе’ҢBд№Ӣй—ҙзҡ„жү§иЎҢйЎәеәҸгҖӮ
йҮҚжҺ’еәҸеҗҺеӯҳеңЁеҰӮдёӢзҡ„жү§иЎҢеҸҜиғҪпјҡ
жҖ»з»“пјҡas-if-serialиҜӯд№үеҗ§еҚ•зәҝзЁӢзЁӢеәҸдҝқжҠӨиө·жқҘдәҶпјҢйҒөе®Ҳas-if-serialиҜӯд№үзҡ„зј–иҜ‘еҷЁгҖҒruntimeе’ҢеӨ„зҗҶеҷЁе…ұеҗҢдёәзј–еҶҷеҚ•зәҝзЁӢзЁӢеәҸзҡ„зЁӢеәҸе‘ҳеҲӣе»әдәҶдёҖдёӘй”ҷиҜҜзҡ„е№»и§үпјҡеҚ•зәҝзЁӢзЁӢеәҸжҳҜжҢүзЁӢеәҸзҡ„йЎәеәҸжқҘжү§иЎҢзҡ„гҖӮas-if-serialиҜӯд№үдҪҝеҚ•зәҝзЁӢзЁӢеәҸе‘ҳж— йңҖжӢ…еҝғйҮҚжҺ’еәҸдјҡе№Іжү°д»–们пјҢд№ҹж— йңҖжӢ…еҝғеҶ…еӯҳеҸҜи§ҒжҖ§й—®йўҳгҖӮ
ж №жҚ®happens-beforeзҡ„зЁӢеәҸ规еҲҷпјҢдёҠйқўи®Ўз®—еңҶзҡ„йқўз§Ҝзҡ„зӨәдҫӢд»Јз ҒеӯҳеңЁ3дёӘhappens-beforeе…ізі»гҖӮ
1.A happens-before B
2.B happens-before C
3.A happens-before C
A happens-before CжҳҜж №жҚ®1е’Ң2жҺЁеҜјеҮәжқҘзҡ„гҖӮ
иҷҪ然A happens-before BдҪҶжҳҜе®һйҷ…жү§иЎҢж—¶BеҚҙеҸҜд»ҘжҺ’еңЁAеүҚйқўжү§иЎҢпјҲеңЁдёҠйқўзҡ„жү§иЎҢеӣҫдёӯпјүгҖӮеҰӮжһңA happens-before BпјҢJMM并дёҚиҰҒжұӮAдёҖе®ҡиҰҒеңЁBд№ӢеүҚжү§иЎҢпјҢJMMд»…д»…иҰҒжұӮеүҚдёҖдёӘж“ҚдҪңпјҲжү§иЎҢзҡ„з»“жһңпјүеҜ№еҗҺдёҖдёӘж“ҚдҪңеҸҜи§ҒпјҢдё”еүҚдёҖдёӘж“ҚдҪңжҢүйЎәеәҸжҺ’еңЁз¬¬дәҢдёӘж“ҚдҪңд№ӢеүҚгҖӮиҝҷйҮҢAзҡ„жү§иЎҢз»“жһңдёҚйңҖиҰҒеҜ№BеҸҜи§ҒпјӣиҖҢдё”йҮҚжҺ’еәҸж“ҚдҪңAе’Ңж“ҚдҪңBеҗҺзҡ„жү§иЎҢз»“жһңпјҢдёҺAе’Ңж“ҚдҪңBжҢүhappens-beforeйЎәеәҸжү§иЎҢзҡ„з»“жһңдёҖиҮҙгҖӮеңЁиҝҷз§Қжғ…еҶөдёӢпјҢJMMдјҡи®Өдёәиҝҷз§ҚйҮҚжҺ’еәҸ并дёҚйқһжі•пјҲnot illegalпјүпјҢJMMиҝҗиЎҢиҝҷз§ҚйҮҚжҺ’еәҸгҖӮ
еңЁи®Ўз®—жңәдёӯпјҢиҪҜ件жҠҖжңҜе’Ң硬件жҠҖжңҜжңүдёҖдёӘе…ұеҗҢзӣ®ж ҮпјҡеҶҚдёҚж”№еҸҳзЁӢеәҸжү§иЎҢз»“жһңзҡ„еүҚжҸҗдёӢпјҢе°ҪеҸҜиғҪжҸҗй«ҳ并иЎҢеәҰгҖӮзј–иҜ‘еҷЁе’ҢеӨ„зҗҶеҢәйҒөд»ҺиҝҷдёҖзӣ®ж ҮпјҢд»Һhappens-beforeзҡ„е®ҡд№үжҲ‘们еҸҜд»ҘзңӢеҮәпјҢJMMеҗҢж ·д№ҹйҒөеҫӘиҝҷдёҖзӣ®ж ҮгҖӮ
йҮҚжҺ’еәҸжҳҜеҗҰдјҡеҪұе“ҚеӨҡзәҝзЁӢзҡ„жү§иЎҢз»“жһңе‘ўпјҹ
package com.lizba.p1;
/**
* <p>
*
* </p>
*
* @Author: Liziba
* @Date: 2021/6/7 23:01
*/
public class ReorderExample {
// е®ҡд№үеҸҳйҮҸa
int a = 0;
// flagеҸҳйҮҸжҳҜдёӘж Үи®°пјҢз”ЁжқҘж Үеҝ—еҸҳйҮҸaжҳҜеҗҰиў«еҶҷе…Ҙ
boolean flag = false;
public void writer() {
a = 1; // 1
flag = true; // 2
}
public void reader() {
if (flag) { // 3
int i = a * a; // 4
System.out.println("i:" + i);
}
}
/**
* жөӢиҜ•
*
* @param args
*/
public static void main(String[] args) {
final ReorderExample re = new ReorderExample();
new Thread() {
public void run() {
re.writer();
}
}.start();
new Thread() {
public void run() {
re.reader();
}
}.start();
}
}иҝҷйҮҢеҒҮи®ҫдёӨдёӘзәҝзЁӢAе’ҢBпјҢAйҰ–е…Ҳжү§иЎҢwrite()пјҢBеҶҚжү§иЎҢreadr()гҖӮзәҝзЁӢBеңЁжү§иЎҢж“ҚдҪң4ж—¶пјҢиғҪеҗҰзңӢеҲ°зәҝзЁӢAеңЁж“ҚдҪң1еҜ№е…ұдә«еҸҳйҮҸaзҡ„еҶҷе…Ҙе‘ўпјҹ
зӯ”жЎҲжҳҜпјҡдёҚдёҖе®ҡиғҪпјҒ
з”ұдәҺж“ҚдҪң1е’Ңж“ҚдҪң2жІЎжңүж•°жҚ®дҫқиө–е…ізі»пјҢзј–иҜ‘еҷЁе’ҢеӨ„зҗҶеҷЁеҸҜд»ҘеҜ№иҝҷдёӨдёӘж“ҚдҪңйҮҚжҺ’еәҸпјӣеҗҢж ·пјҢж“ҚдҪң3е’Ңж“ҚдҪң4жІЎжңүж•°жҚ®дҫқиө–е…ізі»пјҢзј–иҜ‘еҷЁе’ҢеӨ„зҗҶеҷЁд№ҹеҸҜд»ҘеӨҡиҝҷдёӨдёӘж“ҚдҪңйҮҚжҺ’еәҸгҖӮ
еҒҮи®ҫж“ҚдҪң1е’Ңж“ҚдҪң2йҮҚжҺ’еәҸпјҡпјҲиҷҡз®ӯзәҝд»ЈиЎЁй”ҷиҜҜзҡ„иҜ»ж“ҚдҪңпјү
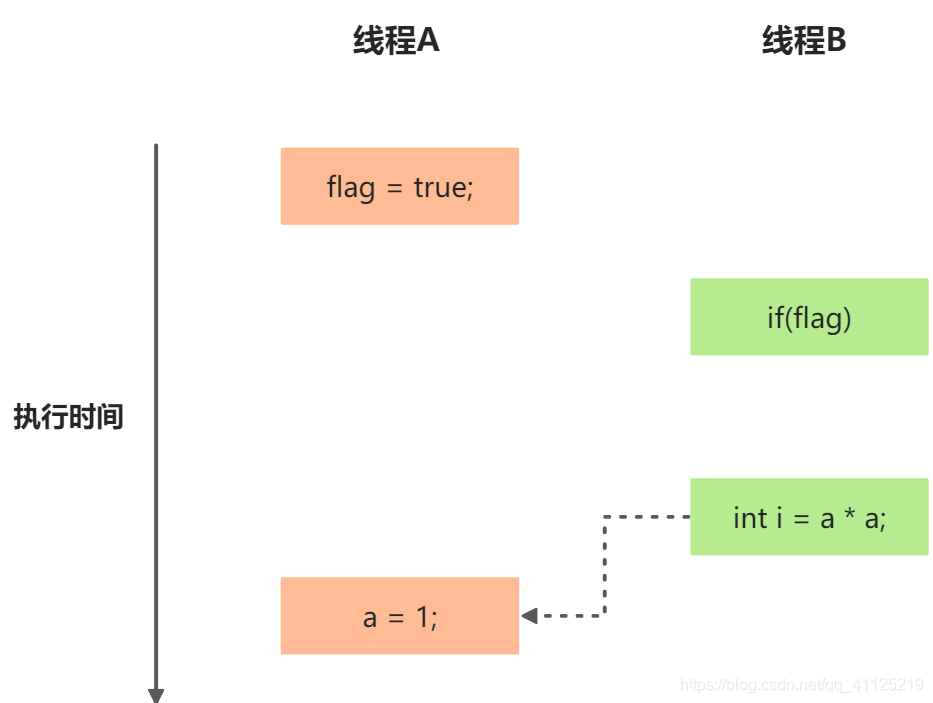
зЁӢеәҸжү§иЎҢж—¶еәҸеӣҫ
еҰӮдёҠеӣҫж“ҚдҪң1е’Ңж“ҚдҪң2еҸ‘з”ҹдәҶйҮҚжҺ’еәҸгҖӮзЁӢеәҸжү§иЎҢж—¶пјҢзәҝзЁӢAйҰ–е…ҲеҶҷж Үи®°еҸҳйҮҸflagпјҢйҡҸеҗҺзәҝзЁӢBиҜ»еҸ–иҝҷдёӘеҸҳйҮҸпјҢжқЎд»¶еҲӨж–ӯдёәзңҹпјҢзәҝзЁӢBиҜ»еҸ–еҸҳйҮҸaзҡ„еҖјгҖӮжӯӨж—¶пјҢеҸҳйҮҸaиҝҳжІЎжңүиў«зәҝзЁӢAеҶҷе…ҘпјҢеңЁиҝҷйҮҢеӨҡзәҝзЁӢзЁӢеәҸзҡ„иҜӯд№үиў«йҮҚжҺ’еәҸз ҙеқҸдәҶгҖӮ
еҒҮи®ҫж“ҚдҪң3е’Ңж“ҚдҪң4йҮҚжҺ’еәҸпјҡ
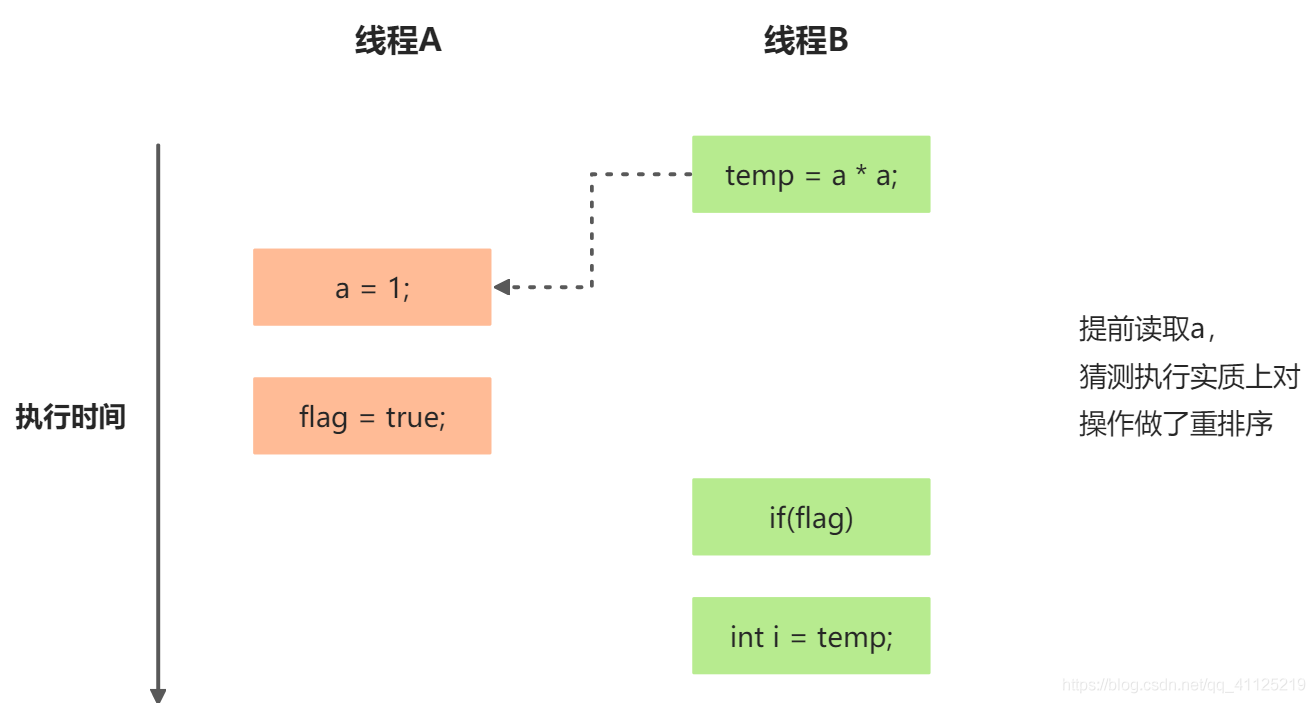
зЁӢеәҸжү§иЎҢж—¶еәҸеӣҫ
еңЁдёҠиҝ°жү§иЎҢж–№ејҸзҡ„зЁӢеәҸдёӯпјҢж“ҚдҪң3е’Ңж“ҚдҪң4еӯҳеңЁжҺ§еҲ¶дҫқиө–е…ізі»гҖӮеҪ“д»Јз ҒдёӯеӯҳеңЁжҺ§еҲ¶дҫқиө–жҖ§ж—¶пјҢдјҡеҪұе“ҚжҢҮд»Ө并иЎҢеәҰгҖӮдёәжӯӨзј–иҜ‘еҷЁе’ҢеӨ„зҗҶеҷЁдјҡйҮҮз”ЁзҢңжөӢпјҲSpeculationпјүжү§иЎҢжқҘе…ӢжңҚжҺ§еҲ¶зӣёе…іжҖ§еҜ№е№¶иЎҢеәҰзҡ„еҪұе“ҚгҖӮд»ҘеӨ„зҗҶеҷЁзҡ„зҢңжөӢжү§иЎҢдёәдҫӢпјҢжү§иЎҢзҺ°еңәBзҡ„еӨ„зҗҶеҷЁеҸҜжҸҗеүҚиҜ»еҸ–并иЎҢи®Ўз®—a*aпјҢ然еҗҺи®Ўз®—з»“жһңдҝқеӯҳеҲ°дёҖдёӘеҗҚдёәйҮҚжҺ’еәҸзј“еҶІпјҲRecorder Buffer, ROBпјүзҡ„硬件缓еӯҳдёӯгҖӮеҪ“ж“ҚдҪң3зҡ„жқЎд»¶еҲӨж–ӯдёәзңҹж—¶пјҢе°ұжҠҠи®Ўз®—з»“жһңеҶҷе…ҘеҸҳйҮҸiдёӯгҖӮ
еңЁдёҠеӣҫдёӯеҸҜд»ҘзңӢеҮәпјҢзҢңжөӢжү§иЎҢе®һиҙЁдёҠеҜ№ж“ҚдҪң3е’Ң4еҒҡдәҶйҮҚжҺ’еәҸгҖӮйҮҚжҺ’еәҸеңЁиҝҷйҮҢз ҙеқҸдәҶеӨҡзәҝзЁӢзЁӢеәҸзҡ„иҜӯд№үпјҒ
еңЁеҚ•зәҝзЁӢзЁӢеәҸдёӯпјҢеҜ№еӯҳеңЁжҺ§еҲ¶дҫқиө–жҖ§зҡ„ж“ҚдҪңйҮҚжҺ’еәҸпјҢдёҚдјҡж”№еҸҳжү§иЎҢз»“жһңпјҲиҝҷд№ҹжҳҜas-if-serialиҜӯд№үе…Ғи®ёеҜ№еӯҳеңЁжҺ§еҲ¶дҫқиө–зҡ„ж“ҚдҪңеҒҡйҮҚжҺ’еәҸзҡ„еҺҹеӣ пјүпјӣдҪҶжҳҜеңЁеӨҡзәҝзЁӢдёӯпјҢеҜ№еӯҳеңЁжҺ§еҲ¶дҫқиө–зҡ„ж“ҚдҪңйҮҚжҺ’еәҸпјҢеҸҜиғҪдјҡж”№еҸҳзЁӢеәҸзҡ„жү§иЎҢз»“жһңгҖӮ
зңӢе®ҢдәҶиҝҷзҜҮж–Үз« пјҢзӣёдҝЎдҪ еҜ№вҖңJavaеҶ…еӯҳжЁЎеһӢд№ӢйҮҚжҺ’еәҸзҡ„зӨәдҫӢеҲҶжһҗвҖқжңүдәҶдёҖе®ҡзҡ„дәҶи§ЈпјҢеҰӮжһңжғідәҶи§ЈжӣҙеӨҡзӣёе…ізҹҘиҜҶпјҢж¬ўиҝҺе…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“пјҢж„ҹи°ўеҗ„дҪҚзҡ„йҳ…иҜ»пјҒ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ