жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
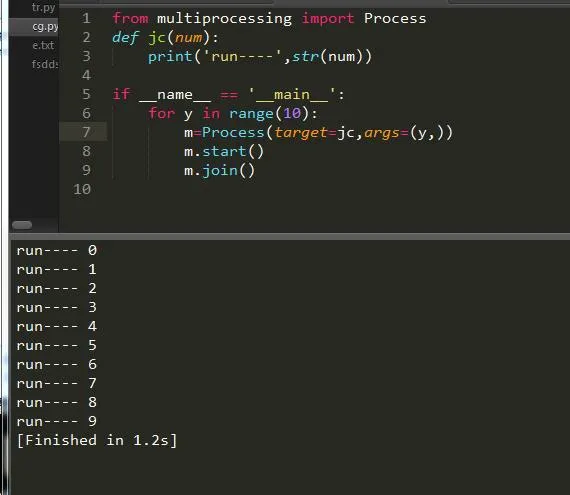
иҝҷзҜҮж–Үз« дё»иҰҒи®Іи§ЈдәҶвҖңеҰӮдҪ•зҗҶи§ЈPythonиҝӣзЁӢвҖқпјҢж–Үдёӯзҡ„и®Іи§ЈеҶ…е®№з®ҖеҚ•жё…жҷ°пјҢжҳ“дәҺеӯҰд№ дёҺзҗҶи§ЈпјҢдёӢйқўиҜ·еӨ§е®¶и·ҹзқҖе°Ҹзј–зҡ„жҖқи·Ҝж…ўж…ўж·ұе…ҘпјҢдёҖиө·жқҘз ”з©¶е’ҢеӯҰд№ вҖңеҰӮдҪ•зҗҶи§ЈPythonиҝӣзЁӢвҖқеҗ§пјҒ

иҝӣзЁӢпјҢдёҖдёӘж–°йІңзҡ„еӯ—зңјпјҢеҸҜиғҪжңүдәӣдәә并дёҚдәҶи§ЈпјҢе®ғжҳҜзі»з»ҹжҹҗдёӘиҝҗиЎҢзЁӢеәҸзҡ„иҪҪдҪ“пјҢиҝҷдёӘзЁӢеәҸеҸҜд»ҘжңүеҚ•дёӘжҲ–иҖ…еӨҡдёӘиҝӣзЁӢпјҢдёҖиҲ¬жқҘиҜҙпјҢиҝӣзЁӢжҳҜйҖҡиҝҮзі»з»ҹCPU еҶ…ж ёж•°жқҘеҲҶй…Қ并и®ҫзҪ®зҡ„пјҢжҲ‘们еҸҜд»ҘжқҘзңӢдёӢзі»з»ҹдёӯзҡ„иҝӣзЁӢпјҡ
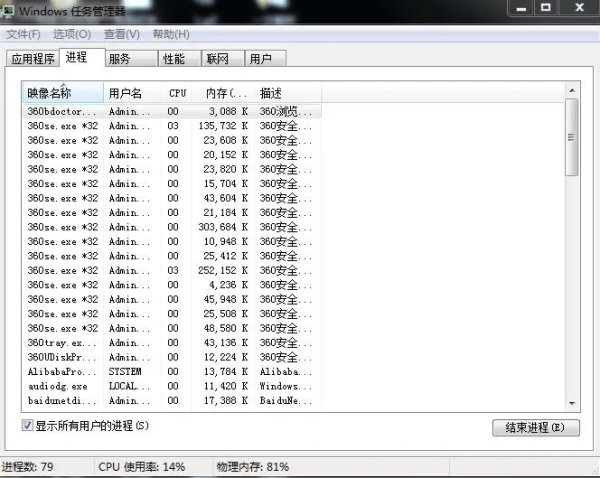
еҸҜд»ҘзңӢеҲ°пјҢ360жөҸи§ҲеҷЁжҳҜзңҹзҡ„зҡ®пјҢиҝҷд№ҲеӨҡиҝӣзЁӢе•ҠпјҢеҪ“然еҸҜд»Ҙиҝҷж ·жқҘеҚҒеҲҶжё…жҘҡзҡ„зңӢиҝӣзЁӢзәҝзЁӢдҪҝз”Ёжғ…еҶөпјҡ
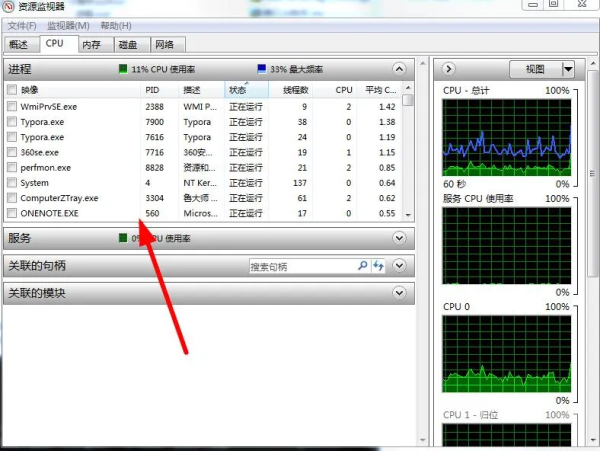
йҖҡиҝҮд»»еҠЎз®ЎзҗҶеҷЁдёӯзҡ„иө„жәҗзӣ‘и§ҶеҷЁпјҢжҳҜдёҚжҳҜеҫҲеҺүе®ідәҶпјҢе“Ҳе“Ҳе“ҲгҖӮи®Іе®ҢдәҶиҝҷдәӣпјҢеҶҚиҜҙиҜҙз”Ёжі•гҖӮ
иҝӣзЁӢиғҪе№Ід»Җд№ҲпјҢиҝҷжҳҜжҲ‘们иҰҒж·ұжҖқзҶҹиҷ‘зҡ„дәӢжғ…гҖӮжҲ‘们йғҪзҹҘйҒ“дёҖдёӘзЁӢеәҸиҝҗиЎҢдјҡеҲӣе»әиҝӣзЁӢпјҢжүҖд»ҘзЁӢеәҸеңЁеҲӣе»әиҝҷдәӣиҝӣзЁӢзҡ„ж—¶еҖҷпјҢдёәдәҶи®©е®ғ们жӣҙиғҪжңүжқЎдёҚзҙҠзҡ„е·ҘдҪңпјҢиӮҜе®ҡд№ҹеҠ е…ҘдәҶзәҝзЁӢгҖӮ
йӮЈд№ҲдёҖжқЎиҝӣзЁӢйҮҢйқўе°ұдјҡжңүеӨҡдёӘзәҝзЁӢеҚҸеҗҢдҪңжҲҳпјҢдҪҶжҳҜиҝӣзЁӢдёҚеҸҜд»ҘеҲӣе»әиҝҮеӨҡпјҢдёҚ然дјҡж¶ҲиҖ—иө„жәҗпјҢйҷӨйқһдҪ ејҖеҸ‘зҡ„жҳҜдёҖдёӘеӨ§еһӢзҡ„зі»з»ҹгҖӮйӮЈд№ҲпјҢжҲ‘们зҺ°еңЁе°ұжқҘеҲӣе»әдёҖдёӘиҝӣзЁӢеҗ§гҖӮ
import multiprocess as m m.Process(targetпјҢargs)
е…¶е®һиҝҷз§ҚеҶҷжі•жҳҜдёҚеҜ№зҡ„пјҢе°ұеҘҪжҜ”bs4дёӯзҡ„BeautifulSoupпјҢдҪ жғійҖҡиҝҮе…ҲеҜје…Ҙbs4пјҢ然еҗҺеҶҚеј•е…ҘBeautifulSoupжҳҜиЎҢдёҚйҖҡзҡ„пјҢеҝ…йЎ»иҝҷж ·пјҡ
from multiprocessing import Process Process(group, target, args, kwargs, name) group:з”ЁжҲ·з»„ target:и°ғз”ЁеҮҪж•° args:еҸӮж•°е…ғзҘ– kwargs:еҸӮж•°еӯ—е…ё name:еӯҗиҝӣзЁӢеҗҚз§°
еҸҜд»ҘзңӢеҮәиҝӣзЁӢе’ҢзәҝзЁӢзҡ„з”Ёжі•еҹәжң¬е·®дёҚеӨҡпјҢеҸӘжҳҜеҗҚз§°еҠҹиғҪдёҚеҗҢиҖҢе·ІгҖӮиҖҢдё”иҝҳжңүеҫҲеӨҡе…¶е®ғдјҳз§Җзҡ„ж–№жі•пјҡ
# иҝ”еӣһеҪ“еүҚиҝӣзЁӢеӯҳжҙ»зҡ„еӯҗиҝӣзЁӢзҡ„еҲ—иЎЁгҖӮи°ғз”ЁиҜҘж–№жі•жңүвҖңзӯүеҫ…вҖқе·Із»Ҹз»“жқҹзҡ„иҝӣзЁӢзҡ„еүҜдҪңз”ЁгҖӮ multiprocessing.active_children() # иҝ”еӣһзі»з»ҹзҡ„CPUж•°йҮҸгҖӮ multiprocessing.cpu_count()
з”ұдёҠиҝ°еҸӮж•°еҸҜзҹҘеҮҪж•°зҡ„иҝ”еӣһеҖјпјҢеҹәжң¬дёҺзәҝзЁӢж— е·®ејӮеҢ–гҖӮ
#еҗҜеҠЁиҝӣзЁӢпјҢи°ғз”ЁиҝӣзЁӢдёӯзҡ„run()ж–№жі•гҖӮ start() #иҝӣзЁӢжҙ»еҠЁзҡ„ж–№жі• run() #ејәеҲ¶з»ҲжӯўиҝӣзЁӢпјҢдёҚдјҡиҝӣиЎҢд»»дҪ•жё…зҗҶж“ҚдҪңгҖӮеҰӮжһңз»ҲжӯўеүҚеҲӣе»әдәҶеӯҗиҝӣзЁӢпјҢйӮЈд№ҲиҜҘеӯҗиҝӣзЁӢеңЁе…¶ејәеҲ¶з»“жқҹеҗҺеҸҳдёәеғөе°ёиҝӣзЁӢпјӣеҰӮжһңиҜҘиҝӣзЁӢиҝҳдҝқеӯҳдәҶдёҖдёӘй”ҒпјҢйӮЈд№Ҳд№ҹе°ҶдёҚдјҡиў«йҮҠж”ҫпјҢиҝӣиҖҢеҜјиҮҙжӯ»й”ҒгҖӮ terminate() #еҲӨж–ӯжҹҗиҝӣзЁӢжҳҜеҗҰеӯҳжҙ»пјҢеӯҳжҙ»иҝ”еӣһTrueпјҢеҗҰеҲҷFalseгҖӮ is_alive() дё»зәҝзЁӢзӯүеҫ…еӯҗзәҝзЁӢз»ҲжӯўгҖӮtimeoutдёәеҸҜйҖүжӢ©и¶…ж—¶ж—¶й—ҙпјӣйңҖиҰҒејәи°ғзҡ„жҳҜпјҡp.joinеҸӘиғҪjoinдҪҸstartејҖеҗҜзҡ„иҝӣзЁӢпјҢиҖҢдёҚиғҪjoinдҪҸrunејҖеҗҜзҡ„иҝӣзЁӢгҖӮ join([timeout]) #и®ҫзҪ®иҝӣзЁӢдёәеҗҺеҸ°е®ҲжҠӨиҝӣзЁӢпјӣеҪ“иҜҘиҝӣзЁӢзҡ„зҲ¶иҝӣзЁӢз»Ҳжӯўж—¶пјҢиҜҘиҝӣзЁӢд№ҹйҡҸд№Ӣз»ҲжӯўпјҢ并且иҜҘиҝӣзЁӢдёҚиғҪеҲӣе»әеӯҗиҝӣзЁӢпјҢи®ҫзҪ®иҜҘеұһжҖ§еҝ…йЎ»еңЁstart()д№ӢеүҚ daemon #иҝӣзЁӢеҗҚз§°гҖӮ name #иҝӣзЁӢpidпјҢеңЁstartеҗҺжүҚиғҪдә§з”ҹ pid #еӯҗиҝӣзЁӢзҡ„йҖҖеҮәд»Јз ҒгҖӮеҰӮжһңиҝӣзЁӢе°ҡжңӘз»ҲжӯўпјҢиҝҷе°ҶжҳҜ NoneпјҢиҙҹеҖј-NиЎЁзӨәеӯҗиҝӣзЁӢиў«дҝЎеҸ·Nз»ҲжӯўгҖӮ exitcode #иҝӣзЁӢиә«д»ҪйӘҢиҜҒпјҢй»ҳи®ӨжҳҜos.urandom()йҡҸжңәз”ҹжҲҗзҡ„еӯ—з¬ҰдёІгҖӮж ЎйӘҢзҪ‘иҝӣзЁӢиҝһжҺҘжҳҜеҗҰжӯЈзЎ® authkey #зі»з»ҹеҜ№иұЎзҡ„ж•°еӯ—еҸҘжҹ„пјҢеҪ“иҝӣзЁӢз»“жқҹж—¶е°ҶеҸҳдёә "ready" гҖӮ sentinel #жқҖиҝӣзЁӢ kill() #е…ій—ӯиҝӣзЁӢ close()
иҜ·жіЁж„ҸпјҡеҲӣе»әиҝӣзЁӢеҠЎеҝ…е°Ҷе®ғеҠ е…ҘеҰӮдёӢиҜӯеҸҘдёӯпјҡ
if __name__ == '__main__':
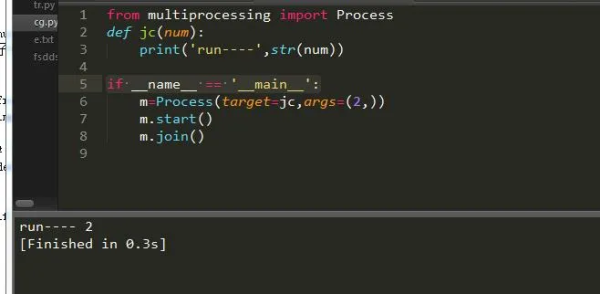
иҝҷж ·е°ұе®һзҺ°дәҶжҲ‘们зҡ„дёҖдёӘе…ідәҺиҝӣзЁӢзҡ„зЁӢеәҸдәҶгҖӮеҸҰеӨ–жҲ‘们д№ҹеҸҜд»ҘйҖҡиҝҮ继жүҝиҝӣзЁӢзұ»жқҘе®һзҺ°пјҡ
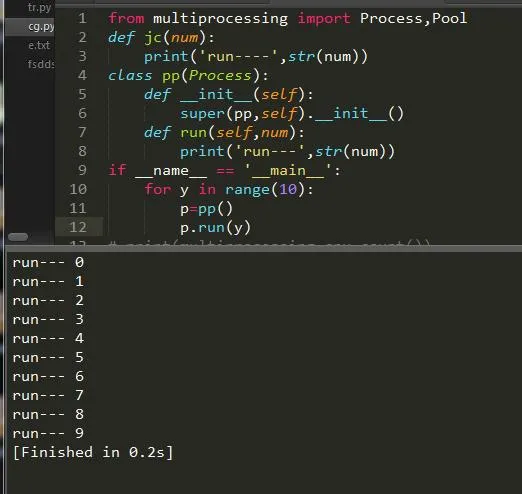
еҸҜд»ҘиҜҙжҲ‘们жҜҸеҲӣе»әдёҖдёӘиҝӣзЁӢе®ғе°ұдјҡжңүдёҖдёӘIDжқҘж Үеҝ—е®ғпјҢдёӢйқўжғ…еҶөпјҡ
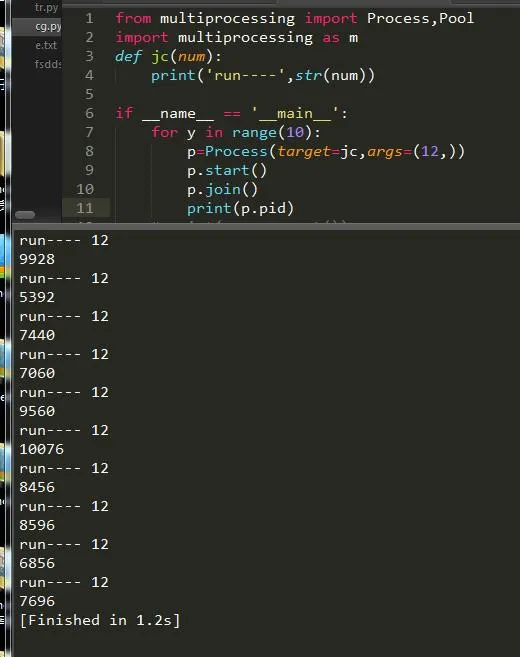
еҚ•дёӘиҝӣзЁӢеҫҖеҫҖйғҪжҳҜдёҚеӨҹз”Ёзҡ„пјҢжүҖжңүжҲ‘们йңҖиҰҒеҲӣе»әдёҖдёӘеӨҡиҝӣзЁӢпјҢеӨҡиҝӣзЁӢеҲӣе»әж–№жі•д№ҹеҫҲз®ҖеҚ•пјҢеҠ дёҖеұӮеҫӘзҺҜеҚіеҸҜпјҡ
иҝҷж ·е°ұиҪ»жқҫеҲӣе»әдәҶеӨҡиҝӣзЁӢзҡ„д»»еҠЎпјҢйҖҹеәҰжҜ”д»ҘеҫҖе°ұиҰҒжӣҙеҝ«дәҶгҖӮ
иҝӣзЁӢжұ зҡ„и®ҫи®Ўд№ӢеҲқе°ұжҳҜдёәдәҶж–№дҫҝжҲ‘们жӣҙжңүж•Ҳзҡ„еҲ©з”Ёиө„жәҗпјҢйҒҝе…ҚжөӘиҙ№пјҢеҰӮжһңд»»еҠЎйҮҸеӨ§е°ұеӨҡдёӘж ёдёҖиө·её®еҝҷпјҢеҰӮжһңе°‘е°ұеҸӘејҖдёҖдёӨдёӘж ёпјҢдёӢйқўжҲ‘们жқҘзңӢзңӢе®һзҺ°иҝҮзЁӢпјҡ
йҰ–е…ҲеҜје…ҘеҢ…:
from multiprocessing import Pool import multiprocessing as m
иҝӣзЁӢжұ зҡ„е®үиЈ…еҢ…дёәPoolпјҢ然еҗҺжҲ‘们жқҘзңӢдёӢе®ғзҡ„CPUеҶ…ж ёж•°пјҡ
num=m.cpu_count()#CPUеҶ…ж ёж•°
зҙ§жҺҘзқҖжҲ‘们еңЁжқҘеҲӣе»әиҝӣзЁӢжұ пјҡ
pool=multiprocessing.Pool(num)
иҝӣзЁӢжұ дёӯд№ҹжңүеҫҲеӨҡж–№жі•дҫӣжҲ‘们дҪҝз”Ёпјҡ
apply(funcпјҢargsпјҢkwargs) еҗҢжӯҘжү§иЎҢпјҲдёІиЎҢпјү йҳ»еЎһ apply_async(funcпјҢargsпјҢkwargs) ејӮжӯҘжү§иЎҢпјҲ并иЎҢпјү йқһйҳ»еЎһ terminate() ејәеҲ¶з»ҲжӯўиҝӣзЁӢпјҢдёҚеңЁеӨ„зҗҶжңӘе®ҢжҲҗзҡ„д»»еҠЎгҖӮ join() дё»иҝӣзЁӢйҳ»еЎһпјҢзӯүеҫ…еӯҗиҝӣзЁӢзҡ„йҖҖеҮәгҖӮеҝ…йЎ»еңЁcloseжҲ–terminate()д№ӢеҗҺдҪҝз”Ё close() зӯүеҫ…жүҖжңүиҝӣзЁӢз»“жқҹеҗҺпјҢжүҚе…ій—ӯиҝӣзЁӢжұ map(funcпјҢiterableпјҢchunksize=int) mapеҮҪж•°зҡ„并иЎҢзүҲжң¬пјҢдҝқжҢҒйҳ»еЎһзӣҙеҲ°иҺ·еҫ—з»“жһң #иҝ”еӣһдёҖдёӘеҸҜз”ЁдәҺиҺ·еҸ–з»“жһңзҡ„еҜ№иұЎпјҢеӣһи°ғеҮҪж•°еә”иҜҘз«ӢеҚіжү§иЎҢе®ҢжҲҗпјҢеҗҰеҲҷдјҡйҳ»еЎһиҙҹиҙЈеӨ„зҗҶз»“жһңзҡ„зәҝзЁӢ map_async(funcпјҢiterableпјҢchunksizeпјҢcallbackпјҢerror_callback) imap(funcпјҢiterableпјҢchunksize) mapзҡ„延иҝҹжү§иЎҢзүҲжң¬ #е’Ңimap() зӣёеҗҢпјҢеҸӘдёҚиҝҮйҖҡиҝҮиҝӯд»ЈеҷЁиҝ”еӣһзҡ„з»“жһңжҳҜд»»ж„Ҹзҡ„ imap_unordered(funcпјҢiterableпјҢchunksize) #е’Ң map() зұ»дјјпјҢдёҚиҝҮ iterable дёӯзҡ„жҜҸдёҖйЎ№дјҡиў«и§ЈеҢ…еҶҚдҪңдёәеҮҪж•°еҸӮж•°гҖӮ starmap(funcпјҢiterableпјҢchunksize)
дёәжӯӨжҲ‘们еҸҜд»ҘеҲӣе»әеҗҢжӯҘе’ҢејӮжӯҘзҡ„зЁӢеәҸпјҢеҰӮжһңдҪ еҜ№иҝҷеҜ№дәҺзҲ¬иҷ«жқҘиҜҙжҳҜеҫҲдёҚй”ҷзҡ„йҖүжӢ©пјҢе°ҸзӮ№зҡ„зҲ¬иҷ«еҗҢжӯҘе°ұеҘҪпјҢеӨ§зҡ„зҲ¬иҷ«ејӮжӯҘж•ҲжһңжӣҙдҪіпјҢеҫҲеӨҡдәәдёҚдәҶи§ЈејӮжӯҘе’ҢеҗҢжӯҘпјҢе…¶е®һеҗҢжӯҘејӮжӯҘе°ұжҳҜдёІиЎҢе’Ң并иЎҢзҡ„ж„ҸжҖқдёІиЎҢе’Ң并иЎҢз®ҖеҚ•зӮ№иҜҙе°ұжҳҜдёІиҒ”е’Ң并иҒ”гҖӮдёӢйқўжҲ‘们йҖҡиҝҮе®һдҫӢдёҖиө·жқҘзңӢдёҖдёӢпјҡ
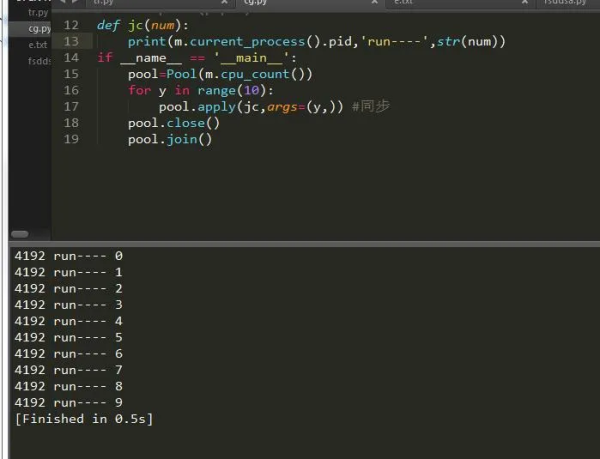
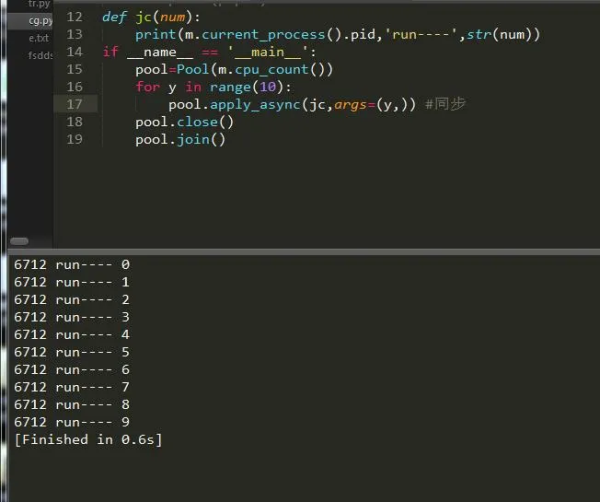
еҸҜд»ҘзңӢеҲ°пјҢд»…д»…еҸӘжҳҜдёҖдёӘеҸӮж•°зҡ„еҸҳеҢ–иҖҢе·ІпјҢе…¶е®ғзҡ„йғҪжҳҜеӨ§еҗҢе°ҸејӮпјҢжҲ‘们иҺ·еҸ–еҲ°дәҶеҪ“еүҚиҝӣзЁӢзҡ„pidпјҢ然еҗҺжҠҠе®ғжү“еҚ°еҮәжқҘдәҶгҖӮ
иҷҪ然ејӮжӯҘзј–зЁӢеӨҡиҝӣзЁӢз»ҷжҲ‘们еёҰжқҘдәҶдҫҝеҲ©пјҢдҪҶжҳҜиҝӣзЁӢеҗҜеҠЁеҗҺжҳҜдёҚеҸҜжҺ§зҡ„пјҢжҲ‘们йңҖиҰҒе°Ҷе®ғжҺ§еҲ¶дҪҸпјҢи®©е®ғе№ІжҲ‘们и§үеҫ—жңүж„Ҹд№үзҡ„дәӢпјҢиҝҷдёӘж—¶еҖҷжҲ‘们йңҖиҰҒз»ҷе®ғеҠ й”ҒпјҢе’ҢзәҝзЁӢдёҖж ·йғҪжҳҜlockпјҡ
йҰ–е…ҲеҜје…ҘиҝӣзЁӢй”Ғзҡ„жЁЎеқ—пјҡ
from multiprocessing import Lock
然еҗҺжҲ‘们жқҘеҲӣе»әдёҖдёӘе…ідәҺй”Ғзҡ„зЁӢеәҸпјҡ
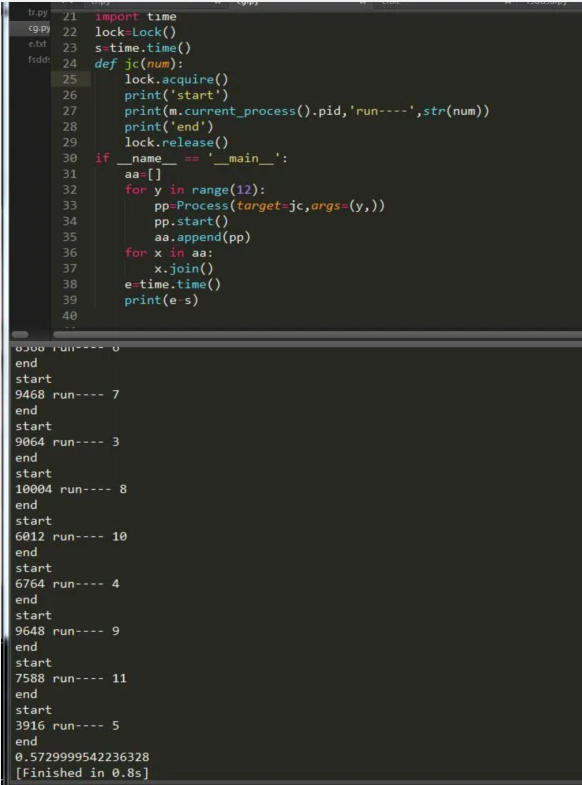
еҸҜд»ҘзңӢеҲ°пјҢеҠ й”Ғзҡ„иҝҮзЁӢиҝҳжҳҜжҜ”иҫғйЎәеҲ©зҡ„пјҢи·ҹеӨҡзәҝзЁӢдёҖж ·з®ҖеҚ•пјҢдҪҶжҳҜзӣёеҜ№жқҘиҜҙйҖҹеәҰдјҡж…ўдёҖзӮ№гҖӮ既然жңүLockпјҢйӮЈд№ҲеҠҝеҝ…е°ұжңүRLockдәҶпјҢеңЁpython дёӯпјҢиҝӣзЁӢе’ҢзәҝзЁӢзҡ„еҫҲеӨҡз”Ёжі•дёҖиҮҙпјҢй”Ғе°ұжҳҜгҖӮжҲ‘们еҸҜд»ҘжҠҠе®ғж”№дёәRLockпјҢдёӢйқўдҫҝжҳҜеҸҜйҮҚе…Ҙй”ҒпјҢд№ҹе°ұжҳҜеҸҜд»ҘйҖ’еҪ’:
import time lock1=RLock() lock2=RLock() s=time.time() def jc(num): lock1.acquire() lock2.acquire() print('start') print(m.current_process().pidпјҢ'run----'пјҢstr(num)) lock1.release() lock2.release() print('end') if __name__ == '__main__': aa=[] for y in range(12): pp=Process(target=jcпјҢargs=(yпјҢ)) pp.start() aa.append(pp) for x in aa: x.join() e=time.time() print(e-s)иҝӣзЁӢй—ҙз”ЁдәҺйҖҡдҝЎпјҢж–№жі•е’ҢзәҝзЁӢзҡ„дёҖжЁЎдёҖж ·пјҢиҝҷйҮҢдёҫдёӘе°Ҹж —еӯҗпјҢдёҚеңЁиҜҰз»ҶжҸҸиҝ°пјҢдёҚжҮӮзҡ„еҸҜд»ҘзңӢжҲ‘дёҠдёҖзҜҮе…ідәҺзәҝзЁӢзҡ„ж–Үз« пјҢжҲ‘们д»ҠеӨ©иҰҒи®Ізҡ„жҳҜе…¶е®ғзҡ„иҝӣзЁӢй—ҙйҖҡдҝЎж–№ејҸпјҢдёӢйқўиҜ·зңӢпјҡ
import time e=Event() def main(num): while True: if num<5: e.clear() #жё…з©әдҝЎеҸ·ж Үеҝ— print('жё…з©ә') if num>=5: e.wait(timeout=1) #зӯүеҫ…дҝЎеҸ·ж Үеҝ—дёәзңҹ e.set() print('еҗҜеҠЁ') if num==10: e.wait(timeout=3) e.clear() print('йҖҖеҮә') break num+=1 time.sleep(2) if __name__ == '__main__': for y in range(10): pp=Process(target=mainпјҢargs=(yпјҢ)) pp.start() pp.join()з®ЎйҒ“жЁЎеқ—еҲқе§ӢеҢ–еҗҺиҝ”еӣһдёӨдёӘеҸӮж•°пјҢдёҖдёӘдёәеҸ‘йҖҒиҖ…пјҢдёҖдёӘдёәжҺҘ收иҖ…пјҢе®ғжңүдёӘеҸӮж•°еҸҜд»Ҙи®ҫзҪ®жЁЎејҸдёәе…ЁеҸҢе·ҘжҲ–иҖ…еҚҠеҸҢе·ҘпјҢе…ЁеҸҢе·Ҙ收еҸ‘дёҖдҪ“пјҢеҚҠеҸҢе·ҘеҸӘ收жҲ–иҖ…еҸӘеҸ‘пјҢе…ҲдәҶи§ЈдёӢе®ғзҡ„ж–№жі•пјҡ
p1пјҢp2=m.Pipe(duplex=bool) #и®ҫзҪ®жҳҜеҗҰе…ЁеҸҢе·ҘпјҢиҝ”еӣһдёӨдёӘиҝһжҺҘеҜ№иұЎ
p1.send() #еҸ‘йҖҒ p2.recv() #жҺҘ收 p1.close() #е…ій—ӯиҝһжҺҘ p1.fileno() #иҝ”еӣһиҝһжҺҘдҪҝз”Ёзҡ„ж•ҙж•°ж–Ү件жҸҸиҝ°з¬Ұ p1.poll([timeout]) #еҰӮжһңиҝһжҺҘдёҠзҡ„ж•°жҚ®еҸҜз”ЁпјҢиҝ”еӣһTrueпјҢtimeoutжҢҮе®ҡзӯүеҫ…зҡ„жңҖй•ҝж—¶йҷҗгҖӮ p2.recv_bytes([maxlength]) #жҺҘ收жңҖеӨ§еӯ—иҠӮж•° p1.send_bytes([maxlength]) #еҸ‘йҖҒжңҖеӨ§еӯ—иҠӮж•° #жҺҘ收дёҖжқЎе®Ңж•ҙзҡ„еӯ—иҠӮж¶ҲжҒҜпјҢ并жҠҠе®ғдҝқеӯҳеңЁbufferеҜ№иұЎдёӯпјҢoffsetжҢҮе®ҡзј“еҶІеҢәдёӯж”ҫзҪ®ж¶ҲжҒҜеӨ„зҡ„еӯ—иҠӮдҪҚ移. p2.recv_bytes_into(buffer [пјҢ offset])
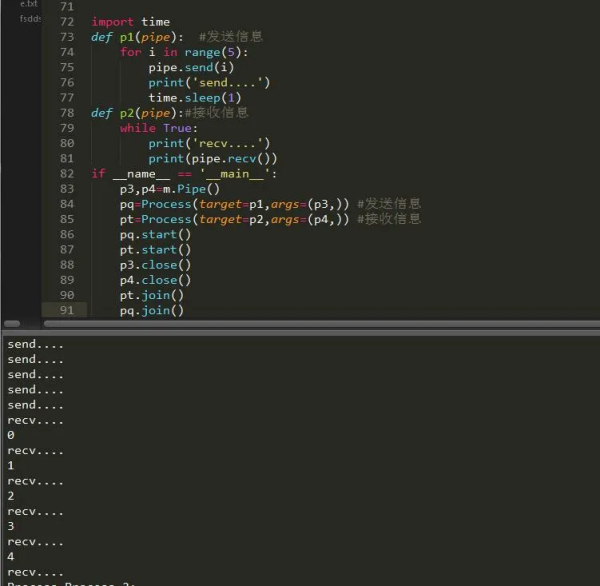
е…Ҳ收еҗҺеҸ‘пјҢе…¶е®һжҲ‘们е®Ңе…ЁеҸҜд»ҘдҪҝз”Ёй”ҒжқҘжҺ§еҲ¶е®ғзҡ„йҰ–еҸ‘пјҢеҸҜд»Ҙи®©е®ғдёҖиҫ№ж”¶дёҖиҫ№еҸ‘гҖӮ
йҳҹеҲ—дёҺе…¶е®ғдёҚеҗҢзҡ„жҳҜе®ғйҮҮеҸ–жҸ’е…Ҙе’ҢеҲ йҷӨзҡ„ж–№жі•пјҢи®©жҲ‘们жқҘзңӢдёӢпјҡ
def fd(a): for y in range(10): a.put(y) #жҸ’е…Ҙж•°жҚ® print('жҸ’е…Ҙпјҡ'пјҢstr(y)) def df(b): while True: aa=b.get(True) #еҲ йҷӨж•°жҚ® print('йҮҠж”ҫпјҡ'пјҢstr(aa)) if __name__ == '__main__': q=Queue() ff=Process(target=fdпјҢargs=(qпјҢ)) dd=Process(target=dfпјҢargs=(qпјҢ)) ff.start() #ејҖе§ӢиҝҗиЎҢ dd.start() dd.terminate() #е…ій—ӯ ff.join()д»ҘдёҠи®Ізҡ„йҳҹеҲ—дё»иҰҒз”ЁдәҺеӨҡиҝӣзЁӢзҡ„йҳҹеҲ—пјҢиҝҳжңүдёҖдёӘиҝӣзЁӢжұ зҡ„йҳҹеҲ—пјҢе®ғеңЁManagerжЁЎеқ—дёӯгҖӮ
дёҺзәҝзЁӢдёӯе®Ңе…ЁдёҖж ·пјҢиҝҷйҮҢдёҚеңЁиөҳиҝ°пјҢзңӢдёӢдҫӢпјҡ
s=Semaphore(3) s.acquire() print(s.get_value()) s.release() print(s.get_value()) print(s.get_value()) s.release() print(s.get_value()) s.release() outputпјҡ 2 3 3 4
е…ұдә«ж•°жҚ®зұ»еһӢеҸҜд»ҘзӣҙжҺҘйҖҡиҝҮиҝӣзЁӢжЁЎеқ—жқҘи®ҫзҪ®пјҡ
ж•°еҖјеһӢпјҡm.Value() ж•°з»„жҖ§пјҡm.Array() еӯ—е…ёеһӢпјҡm.dict() еҲ—иЎЁеһӢ:m.list()
д№ҹеҸҜд»ҘйҖҡиҝҮиҝӣзЁӢзҡ„ManagerжЁЎеқ—жқҘе®һзҺ°пјҡ
Manager().dict() Manager.list()
дёӢйқўжҲ‘们е°ұжқҘдёҫдҫӢиҜҙжҳҺдёӢеҗ§пјҡ
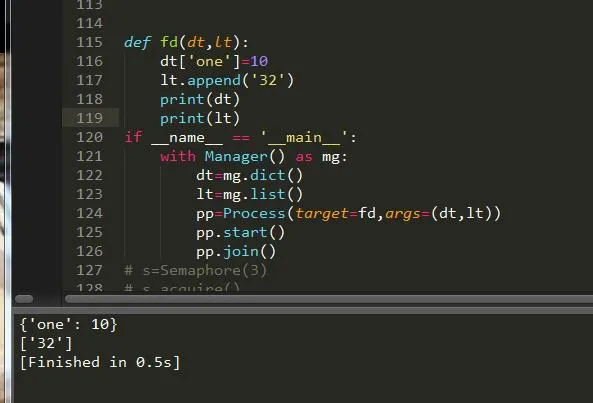
еҸҜд»ҘзңӢеҲ°жҲ‘们жҲҗеҠҹзҡ„е°Ҷж•°жҚ®ж·»еҠ дәҶиҝӣеҺ»пјҢеҪўжҲҗдәҶж•°жҚ®зҡ„е…ұдә«гҖӮ
ж„ҹи°ўеҗ„дҪҚзҡ„йҳ…иҜ»пјҢд»ҘдёҠе°ұжҳҜвҖңеҰӮдҪ•зҗҶи§ЈPythonиҝӣзЁӢвҖқзҡ„еҶ…е®№дәҶпјҢз»ҸиҝҮжң¬ж–Үзҡ„еӯҰд№ еҗҺпјҢзӣёдҝЎеӨ§е®¶еҜ№еҰӮдҪ•зҗҶи§ЈPythonиҝӣзЁӢиҝҷдёҖй—®йўҳжңүдәҶжӣҙж·ұеҲ»зҡ„дҪ“дјҡпјҢе…·дҪ“дҪҝз”Ёжғ…еҶөиҝҳйңҖиҰҒеӨ§е®¶е®һи·өйӘҢиҜҒгҖӮиҝҷйҮҢжҳҜдәҝйҖҹдә‘пјҢе°Ҹзј–е°ҶдёәеӨ§е®¶жҺЁйҖҒжӣҙеӨҡзӣёе…ізҹҘиҜҶзӮ№зҡ„ж–Үз« пјҢж¬ўиҝҺе…іжіЁпјҒ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ