您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
本篇内容主要讲解“鸿蒙代码如何配置混淆原理以及混淆命令”,感兴趣的朋友不妨来看看。本文介绍的方法操作简单快捷,实用性强。下面就让小编来带大家学习“鸿蒙代码如何配置混淆原理以及混淆命令”吧!
Java代码会被编译成字节码,字节码非常容易被反编译,一旦字节码被反编译,源码也就泄露了。为了很好的保护源代码,需要对编译好后的字节码文件进行混淆。代码经过混淆后,包体积会变小,并且源码都被处理过,进一步保障了应用的安全。本文将首先介绍混淆原理以及混淆命令,然后教大家如何在鸿蒙项目里面配置混淆。
ProGuard就是用来混淆代码的,主要有以下4个功能。
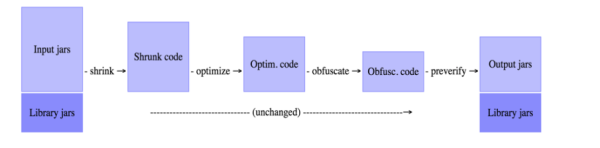
压缩(Shrink):检测并移除代码中无用的类、字段、方法和特性。可以使用下面的指令关闭压缩
# 关闭压缩 -dontshrink
优化(Optimize):对字节码进行优化,移除无用的指令。可以使用下面的指令关闭优化
# 关闭优化 -dontoptimize -optimizationpasses n 表示proguard对代码进行迭代优化的次数
混淆(Obfuscate):使用a,b,c,d这样简短而无意义的名称,对类、字段和方法进行重命名。可以使用下面的指令关闭混淆
# 关闭混淆 -dontobfuscate
预检(Preveirfy):在Java平台上对处理后的代码进行预检,确保加载的字节码文件是可执行的。
总之,Proguard是一个Java类文件压缩器、优化器、混淆器、预校验器。压缩环节会检测以及移除没有用到的类、字段、方法以及属性。优化环节会分析以及优化方法的字节码。混淆环节会用无意义的短变量去重命名类、变量、方法。这些步骤让代码更精简,更高效,也更难被逆向(破解)。
那么有一个问题,ProGuard怎么知道这个代码没有被用到呢?这里引入一个Entry Point(入口点)概念,Entry Point表示在混淆过程中不会被处理的类或方法。在压缩的步骤中,ProGuard会从上述的Entry Point开始递归遍历,搜索哪些类和类的成员在使用,对于没有被使用的类和类的成员,就会在压缩段丢弃,在接下来的优化过程中,那些非Entry Point的类、方法都会被设置为private、static或final,不使用的参数会被移除,此外,有些方法会被标记为内联的,在混淆的步骤中,ProGuard会对非Entry Point的类和方法进行重命名。
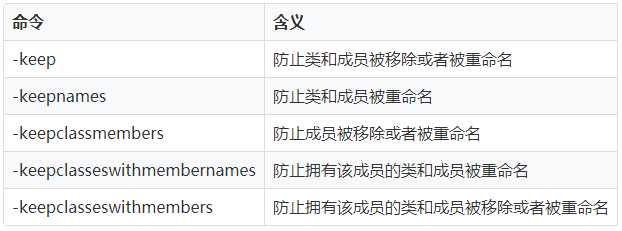
一般来说,开启混淆后,代码越乱越无规律越好,但有些代码是不能被混淆的,否则程序运行就会出错,所以就需要我们熟悉混淆指令,当开启混淆的时候,使用混淆指令告诉编译器某些代码不能被混淆。
3、1 先看如下如下的命令,一个星号表示只是保持该包下的类名,而子包下的类名还是会被混淆。
-keep class com.poetry.jianjia.bean.*
3、2 两个星号表示把本包和所含子包下的类名都保持。
-keep class com.poetry.jianjia.bean.**
3、3 用以上方法保持类后,虽然类名未混淆,但类里面的方法和变量命名还是会变,如果既想保持类名,又想保持里面的内容不被混淆,就需要加上{*;}
-keep class com.poetry.jianjia.bean.**{*;}3、4 在此基础上,还可以使用extends、implements等关键字来保护特定类不被混淆,如下例子表示实现Serializable接口的类名不被混淆
-keep class * implements java.io.Serializable
3、5 如果想保留内部类不被混淆则需要用$符号,如下例子MainAbilitySlice内部类InnerClass中的所有public内容不被混淆。
-keepclassmembers class com.poetry.jianjia.slice.MainAbilitySlice$InnerClass{ public *; }3、6 如果只是希望类里面的特定内容不被混淆,就可以使用
<init>; //匹配所有构造方法 <fields>; //匹配所有变量 <methods>; //匹配所有方法
3、7 可以在
-keep class com.poetry.jianjia.Banner { public <methods>; }3、8 类中可以有重载方法,如果希望某个重载方法不被混淆,可以加上方法参数,如下例子,带有一个字符串参数的构造方法不被混淆
-keep class com.poetry.jianjia.Banner { public <init>(java.lang.String); }3、9 有时类名可以被混淆,但是希望该类下的特定方法不被混淆,那就不能用keep了,keep不会混淆类名,而需要用keepclassmembers。如下例子,实现了Serializable接口的类名可以被混淆,但类中的具体变量和方法不被混淆
-keepclassmembers class * implements java.io.Serializable { static final long serialVersionUID; private static final java.io.ObjectStreamField[] serialPersistentFields; private void writeObject(java.io.ObjectOutputStream); private void readObject(java.io.ObjectInputStream); java.lang.Object writeReplace(); java.lang.Object readResolve(); }3、10 有些类或者类成员是不能被重命名的,keepclasseswithmembernames会防止类和成员被重命名。如下实例,本地方法不能被重命名。
-keepclasseswithmembernames class * { native <methods>; }3、11 保持枚举不被混淆
-keepclassmembers enum * { public static **[] values(); public static ** valueOf(java.lang.String); }3、12 反射用到的类不能被混淆。
3、13 配置文件中的类不能被混淆,配置文件中声明的Ability默认不会被混淆,在配置文件中声明的类不需要额外的配置混淆。
3、14 使用gson、fastjson等框架解析服务端数据时,所写的json对象类不能混淆,否则无法将json解析成对应的对象。
3、15 第三方开源库会大量的使用注解、反射、泛型,使用第三方开源库或者引用其他第三方的SDK包时,如果有特别要求,也需要在混淆文件中加入对应的混淆规则。
4、1 我们已经熟悉了混淆指令,那如何给鸿蒙项目配置混淆呢?在最新版的编译器里面创建项目,编译器会帮我们创建一个proguard-rules.pro文件,proguard-rules.pro文件是什么呢?鸿蒙使用proguard进行混淆,proguard-rules.pro文件就是用来配置混淆规则的,将不能被混淆的代码配置在proguard-rules.pro文件中。请注意,老版本的编译器不支持混淆,使用老版本的编译器创建项目,编译器不会创建proguard-rules.pro文件。
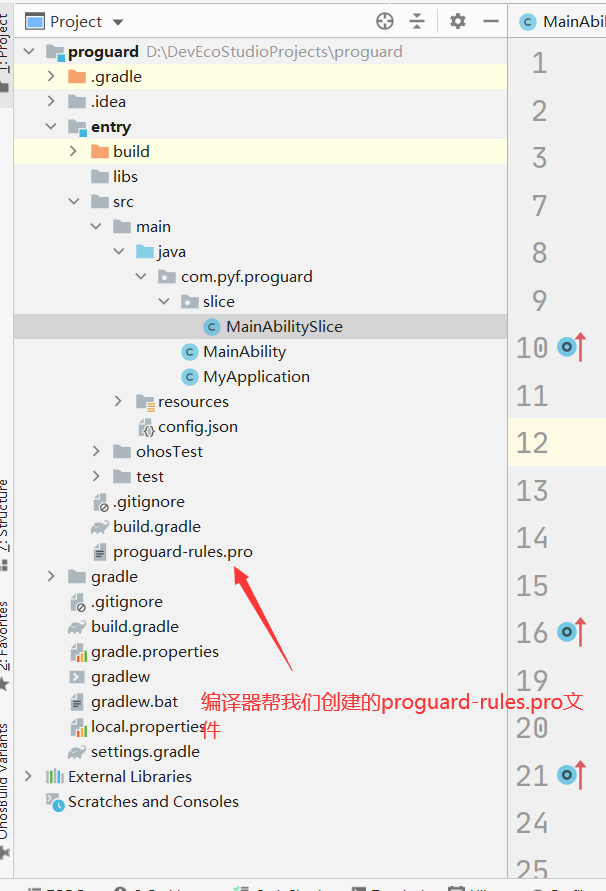
4、2 编译器除了帮我们创建proguard-rules.pro文件外,还在build.gradle文件中添加了新代码,打开build.gradle文件

编译器在buildTypes闭包里面添加release闭包,release表示正式包。release闭包下面又有一个proguardOpt闭包,proguardOpt就是用来配置混淆的。proguardEnabled表示是否开启混淆,true表示开始混淆,false表示不开启混淆。rulesFiles则表示配置混淆的规则文件。
可以看出,默认情况下,是不开启混淆的,出于保护源码的原因,当我们打正式包的时候,是需要开启混淆的。其实,我们也可以给测试包配置混淆,如下代码。我们手动添加了一个debug闭包,debug表示测试包,不要在测试包里面开启混淆,当你在测试包开启混淆,断点调试的时候将看不到变量的值。
buildTypes { // release表示正式包 release { // 配置混淆 proguardOpt { // 正式包开启混淆 proguardEnabled true // 混淆规则配置在proguard-rules.pro文件中 rulesFiles 'proguard-rules.pro' } } // debug表示测试包 debug { // 配置混淆 proguardOpt { // 测试包不开启混淆 proguardEnabled false // 混淆规则配置在proguard-rules.pro文件中 rulesFiles 'proguard-rules.pro' } } }4、3 如果使用最新版编译器打开老版本编译器创建的项目,那么项目中不会有proguard-rules.pro文件,同时build.gradle文件中也不会有proguardOpt。这时就需要我们自己手动创建proguard-rules.pro文件,并且在build.gradle文件添加上述代码。
4、4 综上,如何给鸿蒙项目配置混淆?只需两步,第一,将proguardEnabled 设置为true,第二,在proguard-rules.pro文件中使用混淆指令配置混淆规则。
# 代码混淆压缩比,在0~7之间 -optimizationpasses 5 # 混合时不使用大小写混合,混合后的类名为小写 -dontusemixedcaseclassnames # 指定不去忽略非公共库的类 -dontskipnonpubliclibraryclasses # 不做预校验,preverify是proguard的四个步骤之一,去掉这一步能够加快混淆速度。 -dontpreverify -verbose # 避免混淆泛型 -keepattributes Signature #google推荐算法 -optimizations !code/simplification/arithmetic,!code/simplification/cast,!field/*,!class/merging/* # 保留注解、内部类、泛型、匿名类 -keepattributes *Annotation*,InnerClasses,Signature,EnclosingMethod # 重命名抛出异常时的文件名称 -renamesourcefileattribute SourceFile # 抛出异常时保留代码行号 -keepattributes SourceFile,LineNumberTable -dontwarn javax.annotation.** # 保留本地native方法不被混淆 -keepclasseswithmembernames class * { native <methods>; } # 保留枚举类不被混淆 -keepclassmembers enum * { public static **[] values(); public static ** valueOf(java.lang.String); } -keepclassmembers class * implements java.io.Serializable { static final long serialVersionUID; private static final java.io.ObjectStreamField[] serialPersistentFields; private void writeObject(java.io.ObjectOutputStream); private void readObject(java.io.ObjectInputStream); java.lang.Object writeReplace(); java.lang.Object readResolve(); } # OkHttp3 -dontwarn okhttp3.logging.** -keep class okhttp3.internal.**{*;} -dontwarn okio.** # gson -keep class sun.misc.Unsafe { *; } -keep class com.google.gson.stream.** { *; } # 在我的示例代码中,com.poetry.jianjia.bean这个包下面的类实现了Serialized接口, # 实现了Serialized接口的类不能被混淆,请把com.poetry.jianjia.bean这个包名替换成你自己的包名 -keep class com.poetry.jianjia.bean.**{*;}到此,相信大家对“鸿蒙代码如何配置混淆原理以及混淆命令”有了更深的了解,不妨来实际操作一番吧!这里是亿速云网站,更多相关内容可以进入相关频道进行查询,关注我们,继续学习!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。