жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
жң¬зҜҮеҶ…е®№дё»иҰҒи®Іи§ЈвҖңйЎәеәҸжҹҘжүҫе’ҢдәҢеҸүжҹҘжүҫзҡ„иҜҰз»Ҷд»Ӣз»ҚвҖқпјҢж„ҹе…ҙи¶Јзҡ„жңӢеҸӢдёҚеҰЁжқҘзңӢзңӢгҖӮжң¬ж–Үд»Ӣз»Қзҡ„ж–№жі•ж“ҚдҪңз®ҖеҚ•еҝ«жҚ·пјҢе®һз”ЁжҖ§ејәгҖӮдёӢйқўе°ұи®©е°Ҹзј–жқҘеёҰеӨ§е®¶еӯҰд№ вҖңйЎәеәҸжҹҘжүҫе’ҢдәҢеҸүжҹҘжүҫзҡ„иҜҰз»Ҷд»Ӣз»ҚвҖқеҗ§!
жң¬ж–Үдё»иҰҒе…Ҳд»Ӣз»ҚжҹҘжүҫзҡ„жҰӮеҝөпјҢ然еҗҺд»Ӣз»ҚжңҖз®ҖеҚ•зҡ„жҹҘжүҫз®—жі•——йЎәеәҸжҹҘжүҫпјҢжңҖеҗҺд»Ӣз»ҚдәҢеҲҶжҹҘжүҫгҖӮ
жҲ‘们平常еҒҡеҫҲеӨҡдәӢжғ…пјҢйғҪдјҡж¶үеҸҠеҲ°еӨ§йҮҸзҡ„еўһеҲ ж”№жҹҘж“ҚдҪңгҖӮжҜ”еҰӮдёҖдёӘз”ЁжҲ·з®ЎзҗҶзі»з»ҹпјҢдјҡж¶үеҸҠз”ЁжҲ·жіЁеҶҢ(еўһ)гҖҒз”ЁжҲ·жіЁй”Җ(еҲ )гҖҒдҝ®ж”№з”ЁжҲ·дҝЎжҒҜ(ж”№)гҖҒжҹҘжүҫз”ЁжҲ·(жҹҘ)пјҢе…¶дёӯвҖңеҲ вҖқе’ҢвҖңж”№вҖқиҰҒдҫқиө–вҖңжҹҘвҖқж“ҚдҪңгҖӮ
дёӢйқўйҮҚзӮ№жқҘд»Ӣз»ҚдёҖдёӢжҹҘжүҫиҝҷдёӘйҮҚиҰҒзҡ„ж“ҚдҪңгҖӮ
зҺ°з»ҷдҪ дёҖдёӘзӮ№еҗҚеҶҢпјҢи®©дҪ жҹҘжүҫдёҖдёӘеӯҰз”ҹгҖӮжҲ‘们зҡ„еҒҡжі•жҳҜпјҡж №жҚ®иҝҷдёӘеӯҰз”ҹзҡ„姓еҗҚжҲ–иҖ…еӯҰеҸ·пјҢеңЁзӮ№еҗҚеҶҢдёӯдёҖдёӘдёӘзҡ„жҜ”еҜ№пјҢзӣҙеҲ°жүҫеҲ°дёҖдёӘеӯҰеҸ·жҲ–姓еҗҚз¬ҰеҗҲжқЎд»¶зҡ„еӯҰз”ҹдёәжӯўпјҢеҗҰеҲҷе°ұеҸҜд»ҘиҜҙзӮ№еҗҚеҶҢдёӯжІЎжңүиҜҘеӯҰз”ҹгҖӮ
зӮ№еҗҚеҶҢжҳҜдёҖдёӘйӣҶеҗҲпјҢд№ҹеҸҜз§°д№ӢдёәжҹҘжүҫиЎЁпјҢе…¶дёӯжңүеӨ§йҮҸеҗҢдёҖзұ»еһӢзҡ„е…ғзҙ пјҢд№ҹеҸҜз§°д№Ӣдёәи®°еҪ•——еӯҰз”ҹгҖӮеӯҰз”ҹдёӯеҸҜиғҪжңүйҮҚеҗҚзҡ„пјҢдҪҶдёҚдјҡжңүйҮҚеӯҰеҸ·зҡ„пјҢд№ҹеҚіпјҢдёҖдёӘеӯҰеҸ·е”ҜдёҖеҜ№еә”дёҖдёӘеӯҰз”ҹпјҢдёҖдёӘ姓еҗҚеҸҜиғҪеҜ№еә”еӨҡдёӘеӯҰз”ҹгҖӮеҰӮжһңжҲ‘д»¬ж №жҚ®еӯҰеҸ·жүҫпјҢеҸӘиҰҒзӮ№еҗҚеҶҢдёӯжңүпјҢйӮЈд№Ҳе°ұеҸҜд»ҘжүҫеҲ°е”ҜдёҖдёҖдёӘз¬ҰеҗҲжқЎд»¶зҡ„еӯҰз”ҹгҖӮеҰӮжһңжҲ‘д»¬ж №жҚ®е§“еҗҚжүҫпјҢйӮЈд№ҲжҲ‘们е°ұеҸҜиғҪжүҫеҲ°еӨҡдёӘз¬ҰеҗҲжқЎд»¶зҡ„еӯҰз”ҹгҖӮ
еғҸеӯҰеҸ·е’Ң姓еҗҚиҝҷз§ҚеҸҜд»Ҙж ҮиҜҶдёҖдёӘеӯҰз”ҹзҡ„еҖјпјҢжҲ‘们称д№Ӣдёәе…ій”®еӯ—пјҢеӯҰеҸ·иҝҷз§Қе”ҜдёҖж ҮиҜҶдёҖдёӘе…ғзҙ зҡ„еҖјдёәдё»е…ій”®еӯ—пјҢ姓еҗҚиҝҷз§ҚеҸҜиғҪж ҮиҜҶиӢҘе№Іе…ғзҙ зҡ„еҖјдёәж¬Ўе…ій”®еӯ—гҖӮеҪ“йӣҶеҗҲдёӯзҡ„е…ғзҙ еҸӘжңүдёҖдёӘж•°жҚ®йЎ№ж—¶пјҢе…¶е…ій”®еӯ—еҚідёәиҜҘж•°жҚ®е…ғзҙ зҡ„еҖјгҖӮ
жҜ”еҰӮж•°з»„[1, 2, 3, 4, 5, 6, 7, 8, 9]пјҢе…¶е…ғзҙ еҸӘжңүдёҖдёӘж•°жҚ®йЎ№пјҢе…ій”®еӯ—еҚіе…ғзҙ еҖјжң¬иә«;иҖҢзӮ№еҗҚеҶҢдёӯзҡ„е…ғзҙ ——еӯҰз”ҹпјҢеҚҙжңүдёүдёӘж•°жҚ®йЎ№——еӯҰеҸ·гҖҒ姓еҗҚгҖҒдё“дёҡпјҢе…¶дёӯеӯҰеҸ·гҖҒ姓еҗҚдёәе…ій”®еӯ—гҖӮ
еҰӮжһңдҪ еӯҰиҝҮж•°жҚ®еә“пјҢйӮЈд№Ҳд»ҘдёҠжҰӮеҝөеҫҲе®№жҳ“зҗҶи§ЈгҖӮ
жүҖи°“жҹҘжүҫпјҢйҖҡдҝ—зӮ№иҜҙе°ұжҳҜеңЁдёҖеӨ§зҫӨе…ғзҙ (йӣҶеҗҲ / жҹҘжүҫиЎЁ)дёӯпјҢдҫқз…§жҹҗдёӘжҹҘжүҫдҫқжҚ®пјҢжүҫдёҖдёӘзү№е®ҡзҡ„гҖҒз¬ҰеҗҲиҰҒжұӮзҡ„е…ғзҙ (и®°еҪ•)гҖӮ
еҰӮжһңжүҫеҲ°дәҶпјҢеҚіжҹҘжүҫжҲҗеҠҹпјҢиҝ”еӣһе…ғзҙ зҡ„дҝЎжҒҜ;
еҰӮжһңжүҫйҒҚжүҖжңүе…ғзҙ иҝҳжІЎжүҫеҲ°пјҢиҜҙжҳҺиҝҷзҫӨе…ғзҙ дёӯжІЎжңүз¬ҰеҗҲиҰҒжұӮзҡ„е…ғзҙ пјҢеҚіжҹҘжүҫеӨұиҙҘпјҢиҝ”еӣһдёҖдёӘеҸҜд»ҘжҳҺжҳҫж Үи®°еӨұиҙҘзҡ„еҖјпјҢжҜ”еҰӮвҖңз©әи®°еҪ•вҖқжҲ–вҖңз©әжҢҮй’ҲвҖқгҖӮ
жүҖи°“жҹҘжүҫдҫқжҚ®пјҢе°ұжҳҜз»ҷе®ҡдёҖдёӘзӣ®ж ҮеҖјпјҢжҜ”иҫғиҜҘзӣ®ж ҮеҖје’Ңе…ій”®еӯ—жҳҜеҗҰзӣёзӯүгҖӮиҝҷе°ұиҰҒжұӮзӣ®ж ҮеҖје’Ңе…ій”®еӯ—зҡ„зұ»еһӢиҰҒзӣёеҗҢгҖӮ
йЎәеәҸжҹҘжүҫжҳҜжҲ‘们жңҖе®№жҳ“жғіеҲ°зҡ„жҹҘжүҫж–№ејҸпјҢдёҠйқўзҡ„зӮ№еҗҚеҶҢдҫӢеӯҗдёӯпјҢжҹҘжүҫдёҖдёӘеӯҰз”ҹе°ұжҳҜз”Ёзҡ„е°ұжҳҜйЎәеәҸжҹҘжүҫгҖӮ
д»ҺйӣҶеҗҲдёӯзҡ„第дёҖдёӘе…ғзҙ ејҖе§ӢиҮіжңҖеҗҺдёҖдёӘе…ғзҙ пјҢйҖҗдёӘжҜ”иҫғе…¶е…ій”®еӯ—е’Ңзӣ®ж ҮеҖјгҖӮ
иӢҘжҹҗдёӘе…ій”®еӯ—е’Ңзӣ®ж ҮеҖјзӣёзӯүпјҢеҲҷжҹҘжүҫжҲҗеҠҹпјҢиҝ”еӣһжүҖжҹҘе…ғзҙ зҡ„дҝЎжҒҜ;
иӢҘжІЎжңүдёҖдёӘе…ій”®еӯ—е’Ңзӣ®ж ҮеҖјзӣёзӯүпјҢеҲҷжҹҘжүҫеӨұиҙҘпјҢиҝ”еӣһеӨұиҙҘж ҮиҜҶеҖјгҖӮ
жҜ”еҰӮпјҢз»ҷе®ҡдёҖдёӘж•°з»„[11, 8, 4, 6, 9, 1, 16, 22, 14, 10]пјҢз»ҷе®ҡзӣ®ж ҮеҖј keyпјҢиӢҘжүҫеҲ°пјҢеҲҷиҝ”еӣһе…¶ж•°з»„дёӢж Ү;еҗҰеҲҷпјҢиҝ”еӣһ -1пјҡ

еҸӘйңҖд»ҺдёӢж Ү 0 ејҖе§ӢйҒҚеҺҶж•ҙдёӘж•°з»„иҝӣиЎҢжҜ”иҫғеҚіеҸҜпјҡ
/** * @description: д»ҺеӨҙеҲ°е°ҫйҒҚеҺҶж•ҙдёӘж•°з»„пјҢжҹҘжүҫзӣ®ж ҮеҖј keyпјҢиҝ”еӣһе…¶дёӢж Ү index * @param {int} *array ж•°з»„ дёәдәҶиҜҙжҳҺй—®йўҳз®ҖеҚ•пјҢиҝҷйҮҢзҡ„ж•°з»„е…ғзҙ дёҚйҮҚеӨҚ * @param {int} length ж•°з»„й•ҝеәҰ * @param {int} key зӣ®ж ҮеҖј * @return {int} еҰӮжһңжүҫеҲ°пјҢиҝ”еӣһзӣ®ж ҮеҖјдёӢж ҮпјӣеҗҰеҲҷиҝ”еӣһ -1 */ int sequential_search(int *array, int length, int key) { for (int index = 0; index < length; index++) { if (array[index] == key) { return index; } } return -1; }д»ҘдёҠд»Јз ҒеӯҳеңЁеҸҜдјҳеҢ–зҡ„ең°ж–№пјҢеӣ дёәжҜҸж¬ЎжҜ”иҫғд№ӢеүҚиҰҒеҲӨж–ӯж•°з»„жҳҜеҗҰи¶Ҡз•Ңпјҡindex < lengthпјҢеўһеҠ е“Ёе…өеҲҷеҸҜд»ҘйҒҝе…ҚиҝҷдёҖжӯҘжҜ”иҫғгҖӮ
жүҖи°“е“Ёе…өпјҢжҳҜдёҖз§ҚеҪўиұЎзҡ„иҜҙжі•пјҢе°Ҷе…¶ж”ҫеңЁж•°з»„еӨҙжҲ–е°ҫпјҢз”ЁжқҘж Үи®°з»“жқҹпјҢеҪ“йҒҚеҺҶеҲ°вҖңе“Ёе…өвҖқж—¶пјҢе°ұиҜҙжҳҺж•°з»„дёӯжІЎжңүзӣ®ж ҮеҖјпјҢжҹҘжүҫеӨұиҙҘгҖӮ
дёәжӯӨпјҢжҲ‘们иҰҒзү№ж„ҸеңЁж•°з»„дёӯз•ҷеҮәдёҖдёӘдҪҚзҪ®з»ҷвҖңе“Ёе…өвҖқпјҢ并且жҠҠе“Ёе…өзҡ„еҖји®ҫзҪ®дёәзӣ®ж ҮеҖјпјҡ
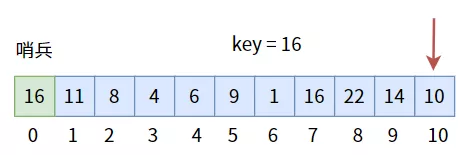
еғҸиҝҷж ·пјҢд»ҺеҸҰдёҖдҫ§еҫҖвҖңе“Ёе…өвҖқдёҖдҫ§йҒҚеҺҶгҖӮеҰӮжһңж•°з»„дёӯжңүзӣ®ж ҮеҖјпјҢеҲҷдёҖе®ҡиғҪжүҫеҲ°;еҰӮжһңж•°з»„дёӯжІЎжңүзӣ®ж ҮеҖјпјҢйӮЈд№Ҳе°ұдјҡйҒҚеҺҶиҮівҖңе“Ёе…өвҖқиҖҢеҒңдёӢпјҢеӣ дёәвҖңе“Ёе…өвҖқзҡ„еҖје°ұжҳҜзӣ®ж ҮеҖјпјҢжүҖд»Ҙиҝ”еӣһдёӢж Үдёә 0 ж—¶пјҢж„Ҹе‘ізқҖжҹҘжүҫеӨұиҙҘгҖӮ
/** * @description: йЎәеәҸжҹҘжүҫж”№иҝӣпјҢеўһеҠ е“Ёе…ө * @param {int} *array array[0] дёҚеӯҳж”ҫж•°жҚ®е…ғзҙ пјҢе……еҪ“е“Ёе…ө * @param {int} length ж•°з»„й•ҝеәҰ * @param {int} key зӣ®ж ҮеҖј * @return {int} иҝ”еӣһ0пјҢеҚіе“Ёе…өдёӢж ҮпјҢеҲҷжҹҘжүҫеӨұиҙҘпјӣеҗҰеҲҷжҲҗеҠҹ */ int sequential_search_pro(int *array, int length, int key) { array[0] = key; // е“Ёе…ө int index = length - 1; while (array[index] != key) { index--; } return index; }еңЁдёҖдҫ§ж”ҫзҪ®вҖңе“Ёе…өвҖқзҡ„еҒҡжі•йҒҝе…ҚдәҶжҜҸж¬ЎйҒҚеҺҶиҝӣиЎҢзҡ„ж•°з»„и¶Ҡз•ҢжЈҖжҹҘпјҢиҝҷж ·иғҪжҸҗй«ҳж•ҲзҺҮгҖӮдҪ еҸҜиғҪдјҡй—®е°ұдёҖеҸҘжҜ”иҫғиғҪжҸҗй«ҳеӨҡе°‘ж•ҲзҺҮ?иҡҠеӯҗи…ҝеҶҚе°Ҹд№ҹжҳҜиӮүпјҢиҖҢдё”еҪ“ж•°жҚ®йҮҸеҫҲеӨҡж—¶пјҢиҝҷдәӣвҖңиҡҠеӯҗи…ҝвҖқе°ұдјҡз§ҜзҙҜжҲҗвҖңеӨ§иұЎи…ҝвҖқдәҶгҖӮ
д»ҘдёҠе°ұжҳҜйЎәеәҸжҹҘжүҫзҡ„еҹәжң¬еҶ…е®№пјҢиҷҪ然еҠ дәҶвҖңе“Ёе…өвҖқеҸҜд»Ҙе°Ҹе°Ҹең°дјҳеҢ–дёҖдёӢпјҢдҪҶеҪ“ж•°жҚ®йҮҸжһҒеӨ§ж—¶пјҢд»Қ然改еҸҳдёҚдәҶиҝҷз§ҚжҹҘжүҫж–№жі•ж•ҲзҺҮдҪҺдёӢзҡ„дәӢе®һгҖӮ
еӣ дёәжҲ‘们жҳҜд»ҺдёҖеӨҙеҲ°еҸҰдёҖеӨҙвҖңйЎәеәҸйҒҚеҺҶвҖқпјҢжүҖд»Ҙжңүж—¶еҖҷеҸҜиғҪзӣ®ж ҮеҖје°ұеңЁз¬¬дёҖдёӘдҪҚзҪ®пјҢеҸӘжҹҘжүҫдёҖж¬Ўе°ұжүҫеҲ°дәҶпјҢд»ҝдҪӣжҳҜеӨ©йҖүд№Ӣеӯҗ;дҪҶжңүж—¶еҖҷеҸҜиғҪзӣ®ж ҮеҖјеңЁжңҖеҗҺдёҖдёӘдҪҚзҪ®пјҢйӮЈе°ұйңҖиҰҒжҠҠжүҖжңүе…ғзҙ йғҪжҹҘжүҫдёҖйҒҚжүҚиЎҢпјҢеҪ“жңүеҚғдёҮгҖҒдәҝжқЎж•°жҚ®ж—¶пјҢиҝҷз§Қе°ұеӨӘеҸҜжҖ•дәҶгҖӮ
еҪ“然пјҢдјҳзӮ№д№ҹжңүпјҡз®—жі•з®ҖеҚ•еҘҪзҗҶи§ЈгҖҒйҖӮеҗҲж•°жҚ®йҮҸе°Ҹзҡ„жғ…еҶөдҪҝз”Ё(дҪҝз”Ёж—¶е°ҪйҮҸжҠҠеёёз”Ёж•°жҚ®жҺ’еңЁеүҚйқўпјҢиҝҷж ·еҸҜд»ҘжҸҗй«ҳж•ҲзҺҮ)гҖӮ
еӣһеҲ°дёҠйқўдёҫеҫ—йӮЈдёӘзӮ№еҗҚеҶҢзҡ„дҫӢеӯҗпјҢйӮЈж ·дёҖдёӘдёӘең°жүҫеӯҰеҸ·жҲ–姓еҗҚе®һеңЁжҳҜеӨӘж…ўдәҶпјҢжңүжІЎжңүд»Җд№Ҳжӣҙеҝ«зҡ„ж–№жі•е‘ў?
е…¶е®һпјҢеңЁж—Ҙеёёз”ҹжҙ»дёӯзҡ„зӮ№еҗҚеҶҢжӣҙеӨҡзҡ„жҳҜе·ІжҺ’еәҸзҡ„пјҢжҜ”еҰӮжҢү姓ж°ҸйҰ–еӯ—жҜҚгҖҒжҢүеӯҰеҸ·еӨ§е°ҸжҺ’еәҸпјҢиҝҷж ·дёҖжқҘпјҢеңЁжүҫеҗҚеӯ—жҲ–жүҫеӯҰеҸ·зҡ„ж—¶еҖҷе°ұиғҪжңүдёҖдёӘеӨ§иҮҙзҡ„еҢәеҹҹдәҶпјҢиҖҢдёҚеҝ…д»ҺеӨҙеҲ°е°ҫдёҖдёӘдёӘең°жүҫгҖӮ
жүҖд»ҘпјҢжҺ’еҘҪеәҸзҡ„йӣҶеҗҲжҳҜдҫҝдәҺжҹҘжүҫзҡ„гҖӮдёӢйқўд»Ӣз»ҚдёҖз§ҚеҲ©з”Ёе·ІжҺ’еәҸзҡ„жҹҘжүҫ——дәҢеҲҶжҹҘжүҫ(жҲ–жҠҳеҚҠжҹҘжүҫ)гҖӮ
жүҖи°“дәҢеҲҶжҹҘжүҫпјҢе…ій”®еңЁвҖңдәҢеҲҶвҖқвҖңжҠҳеҚҠвҖқдёҠпјҢйЎҫеҗҚжҖқд№үпјҢдёҚж–ӯе°ҶйӣҶеҗҲиҝӣиЎҢдәҢеҲҶ(жҠҳеҚҠ)жӢҶеҲҶпјҢд»ҘжӯӨе°ҶйӣҶеҗҲжӢҶеҲҶеҮ дёӘеҢәеҹҹпјҢ然еҗҺеңЁжҹҗдёӘеҢәеҹҹдёӯжҹҘжүҫгҖӮеүҚжҸҗжқЎд»¶жҳҜйӣҶеҗҲдёӯзҡ„е…ғзҙ жҳҜжңүеәҸзҡ„пјҢе…ғзҙ еҝ…йЎ»йҮҮз”ЁйЎәеәҸиЎЁ(ж•°з»„)еӯҳеӮЁгҖӮ
дәҢеҲҶжҹҘжүҫжҖқжғіпјҡ
еңЁжңүеәҸйЎәеәҸиЎЁдёӯпјҢеҸ–дёӯй—ҙе…ғзҙ пјҢе°ҶжңүеәҸйЎәеәҸиЎЁеҲҶдёәе·ҰеҚҠеҢәе’ҢеҸіеҚҠеҢәпјҢжҜ”иҫғдёӯй—ҙе…ғзҙ зҡ„е…ій”®еӯ—е’Ңзӣ®ж ҮеҖј key жҳҜеҗҰзӣёзӯүпјҡ
1.еҰӮжһңзӣёзӯүпјҢеҲҷжҹҘжүҫжҲҗеҠҹпјҢиҝ”еӣһдёӯй—ҙе…ғзҙ зҡ„дҝЎжҒҜ;
2.еҰӮжһңдёҚзӣёзӯүпјҢиҜҙжҳҺзӣ®ж ҮеҖј key еңЁе·ҰеҚҠеҢәжҲ–еҸіеҚҠеҢәпјҡ
иӢҘзӣ®ж ҮеҖј keyе°ҸдәҺдёӯй—ҙе…ғзҙ зҡ„е…ій”®еӯ—пјҢеҲҷжқҘеҲ°е·ҰеҚҠеҢә;
иӢҘзӣ®ж ҮеҖј key еӨ§дәҺдёӯй—ҙе…ғзҙ зҡ„е…ій”®еӯ—пјҢеҲҷжқҘеҲ°еҸіеҚҠеҢә;
дёҚж–ӯеңЁеҗ„еҚҠеҢәдёӯйҮҚеӨҚдёҠиҝ°иҝҮзЁӢпјҢзӣҙеҲ°жҹҘжүҫжҲҗеҠҹ;еҗҰеҲҷпјҢеҲҷйӣҶеҗҲдёӯж— зӣ®ж ҮеҖјпјҢжҹҘжүҫеӨұиҙҘгҖӮ
дёӢйқўз»“еҗҲе®һдҫӢпјҢзңӢдёҖдёӢе…·дҪ“иҝҮзЁӢгҖӮ
иҝҷжҳҜдёҖдёӘжңүеәҸзҡ„ж•°з»„пјҢжҲ‘们иҰҒжҹҘжүҫ 33пјҡ

иҰҒжғіе°Ҷж•°з»„еҲҶдёәе·ҰеҸіеҚҠеҢәпјҢйңҖиҰҒдёүдёӘж ҮиҮҙпјҡжңҖе·Ұж Үеҝ—дҪҚ leftгҖҒжңҖеҸіж Үеҝ—дҪҚ rightе’Ңдёӯй—ҙж Үеҝ—дҪҚ midгҖӮе…¶дёӯ mid = (left + right) / 2пјҢзЎ®е®ҡдәҶ mid зҡ„еҖјд№ӢеҗҺпјҢдёҺзӣ®ж ҮеҖј keyиҝӣиЎҢжҜ”иҫғпјҡ
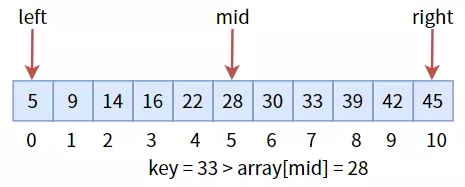
дёӯй—ҙеҖј 28 е°ҸдәҺзӣ®ж ҮеҖјkeyпјҢиҜҙжҳҺзӣ®ж ҮеҖјеңЁеҸіеҚҠеҢәпјҢжүҖд»Ҙжӣҙж–°дёүдёӘж Үеҝ—дҪҚпјҢиҝӣе…ҘеҸіеҚҠеҢәпјҢ然еҗҺ继з»ӯжҜ”иҫғпјҡ
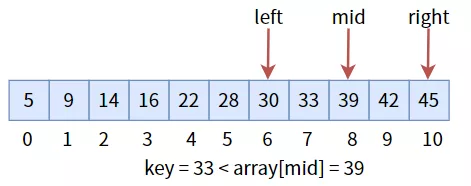
дёӯй—ҙеҖј 39 еӨ§дәҺзӣ®ж ҮеҖјkeyпјҢжӣҙж–°дёүдёӘж Үеҝ—дҪҚпјҢиҝӣе…Ҙе·ҰеҚҠеҢәпјҡ
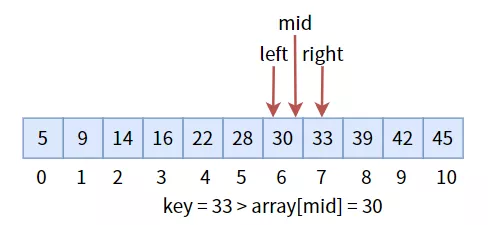
дёӯй—ҙеҖј 30 е°ҸдәҺзӣ®ж ҮеҖјkeyпјҢжӣҙж–°дёүдёӘж Үеҝ—дҪҚпјҢиҝӣе…ҘеҸіеҚҠеҢәпјҡ

дёӯй—ҙеҖј 33 зӯүдәҺзӣ®ж ҮеҖјkeyпјҢиҝ”еӣһе…¶дёӢж ҮпјҢеҚі midгҖӮ
е…·дҪ“д»Јз ҒеҰӮдёӢпјҡ
/** * @description: дәҢеҲҶжҹҘжүҫ * @param {int} *array жңүеәҸж•°з»„ * @param {int} length ж•°з»„й•ҝеәҰ * @param {int} key зӣ®ж ҮеҖјпјҢе’Ңе…ій”®еӯ—жҜ”иҫғ * @return {int} иҝ”еӣһзӣ®ж ҮеҖјдёӢж ҮпјӣиӢҘжҹҘжүҫеӨұиҙҘпјҢеҲҷиҝ”еӣһ -1 */ int binary_search(int *array, int length, int key) { int left, mid, right; left = 0; right = length - 1; while (left <= right) { mid = (left + right) / 2; // дёӯй—ҙдёӢж Ү if (key < array[mid]) { // key жҜ”дёӯй—ҙеҖје°Ҹ right = mid - 1; // жӣҙж–°жңҖеҸідёӢж ҮпјҢиҝӣе…Ҙе·ҰеҚҠеҢә } else if (key > array[mid]) { // key жҜ”дёӯй—ҙеҖјеӨ§ left = mid + 1; // жӣҙж–°жңҖе·ҰдёӢж ҮпјҢиҝӣе…ҘеҸіеҚҠеҢә } else { return mid; // key зӯүдәҺдёӯй—ҙеҖјпјҢиҝ”еӣһе…¶дёӢж Ү } } return -1; //жңӘжүҫеҲ°пјҢиҝ”еӣһ -1 }дәҢеҲҶжҹҘжүҫзҡ„зІҫй«“еңЁдәҺдёӯй—ҙж Үеҝ—дҪҚ mid жҠҠжңүеәҸйЎәеәҸиЎЁдёҖеҲҶдёәдәҢпјҢйҖҡиҝҮжҜ”иҫғдёӯй—ҙеҖје’Ңзӣ®ж ҮеҖјзҡ„еӨ§е°Ҹе…ізі»пјҢиғҪеӨҹзӯӣйҖүжҺүдёҖеҚҠзҡ„ж•°жҚ®пјҢзӣёеҪ“дәҺеҮҸе°‘дәҶдёҖеҚҠзҡ„е·ҘдҪңйҮҸгҖӮ
дёҠдҫӢеҸӘжҜ”иҫғдәҶеӣӣж¬ЎпјҢе°ұжүҫеҲ°дәҶзӣ®ж ҮеҖјпјҢеҰӮжһңдҪҝз”ЁйЎәеәҸжҹҘжүҫпјҢеҲҷйңҖиҰҒе…«ж¬ЎгҖӮ
еҸҜд»ҘзңӢеҮәпјҢдәҢеҲҶжҹҘжүҫзҡ„ж•ҲзҺҮзӣёиҫғдәҺйЎәеәҸжҹҘжүҫжңүдәҶеҫҲеӨ§жҸҗй«ҳпјҢдҪҶзҫҺдёӯдёҚи¶ізҡ„жҳҜдәҢеҲҶжҹҘжүҫеҝ…йЎ»иҰҒжұӮе…ғзҙ жңүеәҸгҖӮеңЁе…ғзҙ зҡ„жңүеәҸзҠ¶жҖҒдёҚеҸҳеҢ–жҲ–дёҚз»ҸеёёеҸҳеҢ–зҡ„жғ…жҷҜдёӢпјҢдәҢеҲҶжҹҘжүҫйқһеёёеҗҲйҖӮ;дҪҶжҳҜеҰӮжһңж¶үеҸҠеҲ°йў‘з№Ғзҡ„жҸ’е…Ҙе’ҢеҲ йҷӨж“ҚдҪңпјҢе°ұж„Ҹе‘ізқҖе…ғзҙ зҡ„жңүеәҸзҠ¶жҖҒдјҡиў«йў‘з№Ғз ҙеқҸпјҢиҝҷж ·дёҖжқҘпјҢжҲ‘们е°ұдёҚеҫ—дёҚиҠұзІҫеҠӣеҺ»з»ҙжҠӨе…ғзҙ зҡ„жңүеәҸзҠ¶жҖҒпјҢиҮӘ然еҸҲдјҡйҷҚдҪҺж•ҲзҺҮпјҢжүҖд»ҘиҰҒж №жҚ®е®һйҷ…жғ…еҶөзҒөжҙ»еҸ–иҲҚгҖӮ
д»ҘдёҠе°ұжҳҜйЎәеәҸжҹҘжүҫе’ҢдәҢеҲҶжҹҘжүҫзҡ„еҶ…е®№гҖӮ
еҲ°жӯӨпјҢзӣёдҝЎеӨ§е®¶еҜ№вҖңйЎәеәҸжҹҘжүҫе’ҢдәҢеҸүжҹҘжүҫзҡ„иҜҰз»Ҷд»Ӣз»ҚвҖқжңүдәҶжӣҙж·ұзҡ„дәҶи§ЈпјҢдёҚеҰЁжқҘе®һйҷ…ж“ҚдҪңдёҖз•Әеҗ§пјҒиҝҷйҮҢжҳҜдәҝйҖҹдә‘зҪ‘з«ҷпјҢжӣҙеӨҡзӣёе…іеҶ…е®№еҸҜд»Ҙиҝӣе…Ҙзӣёе…ійў‘йҒ“иҝӣиЎҢжҹҘиҜўпјҢе…іжіЁжҲ‘们пјҢ继з»ӯеӯҰд№ пјҒ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ