您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
本篇内容介绍了“Java8 ConcurrentHashMap源码中隐藏的两个Bug是什么”的有关知识,在实际案例的操作过程中,不少人都会遇到这样的困境,接下来就让小编带领大家学习一下如何处理这些情况吧!希望大家仔细阅读,能够学有所成!

Java 7的ConcurrenHashMap的源码我建议大家都看看,那个版本的源码就是Java多线程编程的教科书。在Java 7的源码中,作者对悲观锁的使用非常谨慎,大多都转换为自旋锁加volatile获得相同的语义,即使最后迫不得已要用,作者也会通过各种技巧减少锁的临界区。在上一篇文章中我们也有讲到,自旋锁在临界区比较小的时候是一个较优的选择是因为它避免了线程由于阻塞而切换上下文,但本质上它也是个锁,在自旋等待期间只有一个线程能进入临界区,其他线程只会自旋消耗CPU的时间片。Java 8中ConcurrentHashMap的实现通过一些巧妙的设计和技巧,避开了自旋锁的局限,提供了更高的并发性能。如果说Java 7版本的源码是在教我们如何将悲观锁转换为自旋锁,那么在Java 8中我们甚至可以看到如何将自旋锁转换为无锁的方法和技巧。
把书读薄
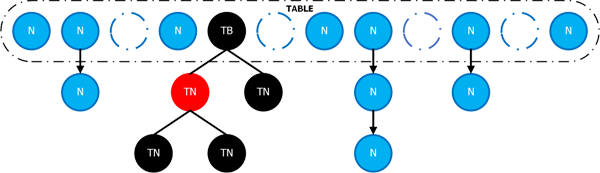
image
图片来源:https://www.zhenchao.org/2019/01/31/java/cas-based-concurrent-hashmap/
在开始本文之前,大家首先在心里还是要有这样的一张图,如果有同学对HashMap比较熟悉,那这张图也应该不会陌生。事实上在整体的数据结构的设计上Java 8的ConcurrentHashMap和HashMap基本上是一致的。
Java 7中ConcurrentHashMap为了提升性能使用了很多的编程技巧,但是引入Segment的设计还是有很大的改进空间的,Java 7中ConcurrrentHashMap的设计有下面这几个可以改进的点:
1. Segment在扩容的时候非扩容线程对本Segment的写操作时都要挂起等待的
2. 对ConcurrentHashMap的读操作需要做两次哈希寻址,在读多写少的情况下其实是有额外的性能损失的
3. 尽管size()方法的实现中先尝试无锁读,但是如果在这个过程中有别的线程做写入操作,那调用size()的这个线程就会给整个ConcurrentHashMap加锁,这是整个ConcurrrentHashMap唯一一个全局锁,这点对底层的组件来说还是有性能隐患的
4. 极端情况下(比如客户端实现了一个性能很差的哈希函数)get()方法的复杂度会退化到O(n)。
针对1和2,在Java 8的设计是废弃了Segment的使用,将悲观锁的粒度降低至桶维度,因此调用get的时候也不需要再做两次哈希了。size()的设计是Java 8版本中最大的亮点,我们在后面的文章中会详细说明。至于红黑树,这篇文章仍然不做过多阐述。接下来的篇幅会深挖细节,把书读厚,涉及到的模块有:初始化,put方法, 扩容方法transfer以及size()方法,而其他模块,比如hash函数等改变较小,故不再深究。
ForwardingNode
static final class ForwardingNode<K,V> extends Node<K,V> { final Node<K,V>[] nextTable; ForwardingNode(Node<K,V>[] tab) { // MOVED = -1,ForwardingNode的哈希值为-1 super(MOVED, null, null, null); this.nextTable = tab; } }除了普通的Node和TreeNode之外,ConcurrentHashMap还引入了一个新的数据类型ForwardingNode,我们这里只展示他的构造方法,ForwardingNode的作用有两个:
在动态扩容的过程中标志某个桶已经被复制到了新的桶数组中
如果在动态扩容的时候有get方法的调用,则ForwardingNode将会把请求转发到新的桶数组中,以避免阻塞get方法的调用,ForwardingNode在构造的时候会将扩容后的桶数组nextTable保存下来。
这是在Java 8版本的ConcurrentHashMap实现CAS的工具,以int类型为例其方法定义如下:
/** * Atomically update Java variable to <tt>x</tt> if it is currently * holding <tt>expected</tt>. * @return <tt>true</tt> if successful */ public final native boolean compareAndSwapInt(Object o, long offset, int expected, int x);
相应的语义为:
如果对象o起始地址偏移量为offset的值等于expected,则将该值设为x,并返回true表明更新成功,否则返回false,表明CAS失败
public ConcurrentHashMap(int initialCapacity, float loadFactor, int concurrencyLevel) { if (!(loadFactor > 0.0f) || initialCapacity < 0 || concurrencyLevel <= 0) // 检查参数 throw new IllegalArgumentException(); if (initialCapacity < concurrencyLevel) initialCapacity = concurrencyLevel; long size = (long)(1.0 + (long)initialCapacity / loadFactor); int cap = (size >= (long)MAXIMUM_CAPACITY) ? MAXIMUM_CAPACITY : tableSizeFor((int)size); // tableSizeFor,求不小于size的 2^n的算法,jdk1.8的HashMap中说过 this.sizeCtl = cap; }即使是最复杂的一个初始化方法代码也是比较简单的,这里我们只需要注意两个点:
concurrencyLevel在Java 7中是Segment数组的长度,由于在Java 8中已经废弃了Segment,因此concurrencyLevel只是一个保留字段,无实际意义
sizeCtl这个值第一次出现,这个值如果等于-1则表明系统正在初始化,如果是其他负数则表明系统正在扩容,在扩容时sizeCtl二进制的低十六位等于扩容的线程数加一,高十六位(除符号位之外)包含桶数组的大小信息
public V put(K key, V value) { return putVal(key, value, false); }put方法将调用转发到putVal方法:
final V putVal(K key, V value, boolean onlyIfAbsent) { if (key == null || value == null) throw new NullPointerException(); int hash = spread(key.hashCode()); int binCount = 0; for (Node<K,V>[] tab = table;;) { Node<K,V> f; int n, i, fh; // 【A】延迟初始化 if (tab == null || (n = tab.length) == 0) tab = initTable(); // 【B】当前桶是空的,直接更新 else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) { if (casTabAt(tab, i, null, new Node<K,V>(hash, key, value, null))) break; // no lock when adding to empty bin } // 【C】如果当前的桶的第一个元素是一个ForwardingNode节点,则该线程尝试加入扩容 else if ((ffh = f.hash) == MOVED) tab = helpTransfer(tab, f); // 【D】否则遍历桶内的链表或树,并插入 else { // 暂时折叠起来,后面详细看 } } // 【F】流程走到此处,说明已经put成功,map的记录总数加一 addCount(1L, binCount); return null; }从整个代码结构上来看流程还是比较清楚的,我用括号加字母的方式标注了几个非常重要的步骤,put方法依然牵扯出很多的知识点
private final Node<K,V>[] initTable() { Node<K,V>[] tab; int sc; while ((tab = table) == null || tab.length == 0) { if ((sc = sizeCtl) < 0) // 说明已经有线程在初始化了,本线程开始自旋 Thread.yield(); // lost initialization race; just spin else if (U.compareAndSwapInt(this, SIZECTL, sc, -1)) { // CAS保证只有一个线程能走到这个分支 try { if ((tab = table) == null || tab.length == 0) { int n = (sc > 0) ? sc : DEFAULT_CAPACITY; @SuppressWarnings("unchecked") Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n]; tabtable = tab = nt; // sc = n - n/4 = 0.75n sc = n - (n >>> 2); } } finally { // 恢复sizeCtl > 0相当于释放锁 sizeCtl = sc; } break; } } return tab; }在初始化桶数组的过程中,系统如何保证不会出现并发问题呢,关键点在于自旋锁的使用,当有多个线程都执行initTable方法的时候,CAS可以保证只有一个线程能够进入到真正的初始化分支,其他线程都是自旋等待。这段代码中我们关注三点即可:
依照前文所述,当有线程开始初始化桶数组时,会通过CAS将sizeCtl置为-1,其他线程以此为标志开始自旋等待
当桶数组初始化结束后将sizeCtl的值恢复为正数,其值等于0.75倍的桶数组长度,这个值的含义和之前HashMap中的THRESHOLD一致,是系统触发扩容的临界点
在finally语句中对sizeCtl的操作并没有使用CAS是因为CAS保证只有一个线程能够执行到这个地方
static final <K,V> Node<K,V> tabAt(Node<K,V>[] tab, int i) { return (Node<K,V>)U.getObjectVolatile(tab, ((long)i << ASHIFT) + ABASE); } static final <K,V> boolean casTabAt(Node<K,V>[] tab, int i, Node<K,V> c, Node<K,V> v) { return U.compareAndSwapObject(tab, ((long)i << ASHIFT) + ABASE, c, v); }put方法的第二个分支会用tabAt判断当前桶是否是空的,如果是则会通过CAS写入,tabAt通过UNSAFE接口会拿到桶中的最新元素,casTabAt通过CAS保证不会有并发问题,如果CAS失败,则通过循环再进入其他分支
final Node<K,V>[] helpTransfer(Node<K,V>[] tab, Node<K,V> f) { Node<K,V>[] nextTab; int sc; if (tab != null && (f instanceof ForwardingNode) && (nextTab = ((ForwardingNode<K,V>)f).nextTable) != null) { int rs = resizeStamp(tab.length); while (nextTab == nextTable && table == tab && (sc = sizeCtl) < 0) { // RESIZE_STAMP_SHIFT = 16 if ((sc >>> RESIZE_STAMP_SHIFT) != rs || sc == rs + 1 || sc == rs + MAX_RESIZERS || transferIndex <= 0) break; // 这里将sizeCtl的值自增1,表明参与扩容的线程数量+1 if (U.compareAndSwapInt(this, SIZECTL, sc, sc + 1)) { transfer(tab, nextTab); break; } } return nextTab; } return table; }在这个地方我们就要详细说下sizeCtl这个标志位了,临时变量rs由resizeStamp这个方法返回
static final int resizeStamp(int n) { // RESIZE_STAMP_BITS = 16 return Integer.numberOfLeadingZeros(n) | (1 << (RESIZE_STAMP_BITS - 1)); }因为入参n是一个int类型的值,所有Integer.numberOfLeadingZeros(n)的返回值介于0到32之间,如果转换成二进制
Integer.numberOfLeadingZeros(n)的最大值是:00000000 00000000 00000000 00100000
Integer.numberOfLeadingZeros(n)的最小值是:00000000 00000000 00000000 00000000
因此resizeStampd的返回值也就介于00000000 00000000 10000000 00000000到00000000 00000000 10000000 00100000之间,从这个返回值的范围可以看出来resizeStamp的返回值高16位全都是0,是不包含任何信息的。因此在ConcurrrentHashMap中,会把resizeStamp的返回值左移16位拼到sizeCtl中,这就是为什么sizeCtl的高16位包含整个Map大小的原理。有了这个分析,这段代码中比较长的if判断也就能看懂了
if ((sc >>> RESIZE_STAMP_SHIFT) != rs || sc == rs + 1 || sc == rs + MAX_RESIZERS || transferIndex <= 0) break; (sc >>> RESIZE_STAMP_SHIFT) != rs保证所有线程要基于同一个旧的桶数组扩容 transferIndex <= 0已经有线程完成扩容任务了
至于sc == rs + 1 || sc == rs + MAX_RESIZERS这两个判断条件如果是细心的同学一定会觉得难以理解,这个地方确实是JDK的一个BUG,这个BUG已经在JDK 12中修复,详细情况可以参考一下Oracle的官网:https://bugs.java.com/bugdatabase/view_bug.do?bug_id=JDK-8214427,这两个判断条件应该写成这样:sc == (rs << RESIZE_STAMP_SHIFT) + 1 || sc == (rs << RESIZE_STAMP_SHIFT) + MAX_RESIZERS,因为直接比较rs和sc是没有意义的,必须要有移位操作。它表达的含义是
sc == (rs << RESIZE_STAMP_SHIFT) + 1当前扩容的线程数为0,即已经扩容完成了,就不需要再新增线程扩容
sc == (rs << RESIZE_STAMP_SHIFT) + MAX_RESIZERS参与扩容的线程数已经到了最大,就不需要再新增线程扩容
真正扩容的逻辑在transfer方法中,我们后面会详细看,不过有个小细节可以提前注意,如果nextTable已经初始化了,transfer会返回nextTable的的引用,后续可以直接操作新的桶数组。
如果桶数组已经初始化好了,该扩容的也扩容了,并且根据哈希定位到的桶中已经有元素了,那流程就跟普通的HashMap一样了,唯一一点不同的就是,这时候要给当前的桶加锁,且看代码:
final V putVal(K key, V value, boolean onlyIfAbsent) { if (key == null || value == null) throw new NullPointerException(); int hash = spread(key.hashCode()); int binCount = 0; for (Node<K,V>[] tab = table;;) { Node<K,V> f; int n, i, fh; if (tab == null || (n = tab.length) == 0)// 折叠 else if ((f = tabAt(tab, i = (n - 1) & hash)) == null) {// 折叠} else if ((ffh = f.hash) == MOVED)// 折叠 else { V oldVal = null; synchronized (f) { // 要注意这里这个不起眼的判断条件 if (tabAt(tab, i) == f) { if (fh >= 0) { // fh>=0的节点是链表,否则是树节点或者ForwardingNode binCount = 1; for (Node<K,V> e = f;; ++binCount) { K ek; if (e.hash == hash && ((eek = e.key) == key || (ek != null && key.equals(ek)))) { oldVal = e.val; // 如果链表中有值了,直接更新 if (!onlyIfAbsent) e.val = value; break; } Node<K,V> pred = e; if ((ee = e.next) == null) { // 如果流程走到这里,则说明链表中还没值,直接连接到链表尾部 pred.next = new Node<K,V>(hash, key, value, null); break; } } } // 红黑树的操作先略过 } } } } // put成功,map的元素个数+1 addCount(1L, binCount); return null; }这段代码中要特备注意一个不起眼的判断条件(上下文在源码上已经标注出来了):tabAt(tab, i) == f,这个判断的目的是为了处理调用put方法的线程和扩容线程的竞争。因为synchronized是阻塞锁,如果调用put方法的线程恰好和扩容线程同时操作同一个桶,且调用put方法的线程竞争锁失败,等到该线程重新获取到锁的时候,当前桶中的元素就会变成一个ForwardingNode,那就会出现tabAt(tab, i) != f的情况。
private final void transfer(Node<K,V>[] tab, Node<K,V>[] nextTab) { int n = tab.length, stride; if ((stride = (NCPU > 1) ? (n >>> 3) / NCPU : n) < MIN_TRANSFER_STRIDE) stride = MIN_TRANSFER_STRIDE; // subdivide range if (nextTab == null) { // 初始化新的桶数组 try { @SuppressWarnings("unchecked") Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n << 1]; nextTab = nt; } catch (Throwable ex) { // try to cope with OOME sizeCtl = Integer.MAX_VALUE; return; } nextTabnextTable = nextTab; transferIndex = n; } int nextn = nextTab.length; ForwardingNode<K,V> fwd = new ForwardingNode<K,V>(nextTab); boolean advance = true; boolean finishing = false; // to ensure sweep before committing nextTab for (int i = 0, bound = 0;;) { Node<K,V> f; int fh; while (advance) { int nextIndex, nextBound; if (--i >= bound || finishing) advance = false; else if ((nextIndex = transferIndex) <= 0) { i = -1; advance = false; } else if (U.compareAndSwapInt (this, TRANSFERINDEX, nextIndex, nextBound = (nextIndex > stride ? nextIndex - stride : 0))) { bound = nextBound; i = nextIndex - 1; advance = false; } } if (i < 0 || i >= n || i + n >= nextn) { int sc; if (finishing) { nextTable = null; table = nextTab; sizeCtl = (n << 1) - (n >>> 1); return; } if (U.compareAndSwapInt(this, SIZECTL, sc = sizeCtl, sc - 1)) { // 判断是会否是最后一个扩容线程 if ((sc - 2) != resizeStamp(n) << RESIZE_STAMP_SHIFT) return; finishing = advance = true; i = n; // recheck before commit } } else if ((f = tabAt(tab, i)) == null) advance = casTabAt(tab, i, null, fwd); else if ((ffh = f.hash) == MOVED) // 只有最后一个扩容线程才有机会执行这个分支 advance = true; // already processed else { // 复制过程与HashMap类似,这里不再赘述 synchronized (f) { // 折叠 } } } }在深入到源码细节之前我们先根据下图看一下在Java 8中ConcurrentHashMap扩容的几个特点:
新的桶数组nextTable是原先桶数组长度的2倍,这与之前HashMap一致
参与扩容的线程也是分段将table中的元素复制到新的桶数组nextTable中
桶一个桶数组中的元素在新的桶数组中均匀的分布在两个桶中,桶下标相差n(旧的桶数组的长度),这一点依然与HashMap保持一致
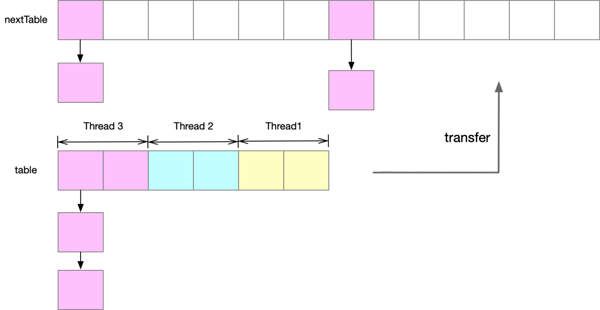
image-20210424202636495
先看一个关键的变量transferIndex,这是一个被volatile修饰的变量,这一点可以保证所有线程读到的一定是最新的值。
private transient volatile int transferIndex;
这个值会被第一个参与扩容的线程初始化,因为只有第一个参与扩容的线程才满足条件nextTab == null
if (nextTab == null) { // initiating try { @SuppressWarnings("unchecked") Node<K,V>[] nt = (Node<K,V>[])new Node<?,?>[n << 1]; nextTab = nt; } catch (Throwable ex) { // try to cope with OOME sizeCtl = Integer.MAX_VALUE; return; } nextTabnextTable = nextTab; transferIndex = n; }在了解了transferIndex属性的基础上,上面的这个循环就好理解了
while (advance) { int nextIndex, nextBound; // 当bound <= i <= transferIndex的时候i自减跳出这个循环继续干活 if (--i >= bound || finishing) advance = false; // 扩容的所有任务已经被认领完毕,本线程结束干活 else if ((nextIndex = transferIndex) <= 0) { i = -1; advance = false; } // 否则认领新的一段复制任务,并通过`CAS`更新transferIndex的值 else if (U.compareAndSwapInt (this, TRANSFERINDEX, nextIndex, nextBound = (nextIndex > stride ? nextIndex - stride : 0))) { bound = nextBound; i = nextIndex - 1; advance = false; } }transferIndex就像是一个游标,每个线程认领一段复制任务的时候都会通过CAS将其更新为transferIndex - stride, CAS可以保证transferIndex可以按照stride这个步长降到0。
对于每一个扩容线程,for循环的变量i代表要复制的桶的在桶数组中的下标,这个值的上限和下限通过游标transferIndex和步长stride计算得来,当i减小为负数,则说明当前扩容线程完成了扩容任务,这时候流程会走到这个分支:
// i >= n || i + n >= nextn现在看来取不到 if (i < 0 || i >= n || i + n >= nextn) { int sc; if (finishing) { // 【A】完成整个扩容过程 nextTable = null; table = nextTab; sizeCtl = (n << 1) - (n >>> 1); return; } // 【B】判断是否是最后一个扩容线程,如果是,则需要重新扫描一遍桶数组,做二次确认 if (U.compareAndSwapInt(this, SIZECTL, sc = sizeCtl, sc - 1)) { // (sc - 2) == resizeStamp(n) << RESIZE_STAMP_SHIFT 说明是最后一个扩容线程 if ((sc - 2) != resizeStamp(n) << RESIZE_STAMP_SHIFT) return; // 重新扫描一遍桶数组,做二次确认 finishing = advance = true; i = n; // recheck before commit } }因为变量finishing被初始化为false,所以当线程第一次进入这个if分支的话,会先执行注释为【B】的这个分支,同时因为sizeCtl的低16位被初始化为参与扩容的线程数加一,因此,当条件(sc - 2) != resizeStamp(n) << RESIZE_STAMP_SHIFT满足时,就能证明当前线程就是最后一个扩容线程了,这这时候将i置为n重新扫描一遍桶数组,并且将finishing置为true保证当桶数组被扫描结束后能够进入注释为【A】的分支结束扩容。
这里就有一个问题,按照我们前面的分析,扩容线程能够通力协作,保证各自负责的桶数组的分段不重不漏,这里为什么还需要做二次确认么?有一个开发者在concurrency-interest这个邮件列表中也关于这件事咨询了Doug Lea(地址:http://cs.oswego.edu/pipermail/concurrency-interest/2020-July/017171.html),他给出的回复是:
Yes, this is a valid point; thanks. The post-scan was needed in a previous version, and could be removed. It does not trigger often enough to matter though, so is for now another minor tweak that might be included next time CHM is updated.
虽然Doug在邮件中的措辞用了could be, not often enough等,但也确认了最后一个扩容线程的二次检查是没有必要的。具体的复制过程与HashMap类似,感兴趣的读者可以翻一下高端的面试从来不会在HashMap的红黑树上纠缠太多这篇文章。
// 记录map元素总数的成员变量 private transient volatile long baseCount;
在put方法的最后,有一个addCount方法,因为putVal执行到此处说明已经成功新增了一个元素,所以addCount方法的作用就是维护当前ConcurrentHashMap的元素总数,在ConcurrentHashMap中有一个变量baseCount用来记录map中元素的个数,如下图所示,如果同一时刻有n个线程通过CAS同时操作baseCount变量,有且仅有一个线程会成功,其他线程都会陷入无休止的自旋当中,那一定会带来性能瓶颈。

image-20210420221407349
为了避免大量线程都在自旋等待写入baseCount,ConcurrentHashMap引入了一个辅助队列,如下图所示,现在操作baseCount的线程可以分散到这个辅助队列中去了,调用size()的时候只需要将baseCount和辅助队列中的数值相加即可,这样就实现了调用size()无需加锁。
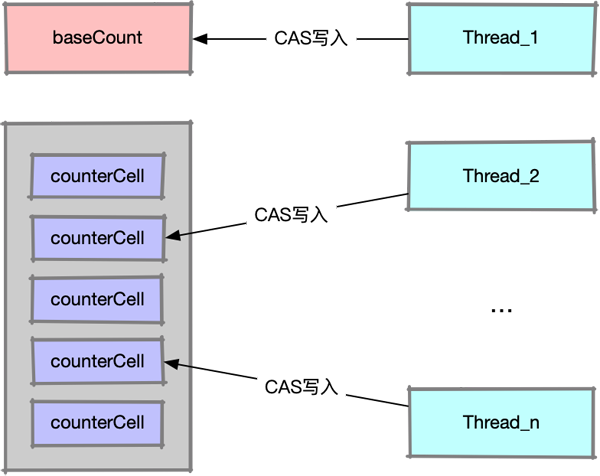
image-20210420222306734
辅助队列是一个类型为CounterCell的数组:
@sun.misc.Contended static final class CounterCell { volatile long value; CounterCell(long x) { value = x; } }可以简单理解为只是包装了一个long型的变量value,还需要解决一个问题是,对于某个具体的线程它是如何知道操作辅助队列中的哪个值呢?答案是下面的这个方法:
static final int getProbe() { return UNSAFE.getInt(Thread.currentThread(), PROBE); }getProbe方法会返回当前线程的一个唯一身份码,这个值是不会变的,因此可以将getProbe的返回值与辅助队列的长度作求余运算得到具体的下标,它的返回值可能是0,如果返回0则需要调用ThreadLocalRandom.localInit()初始化。addCount方法中有两个细节需要注意
private final void addCount(long x, int check) { CounterCell[] as; long b, s; // 注意这里的判断条件,是有技巧的 if ((as = counterCells) != null || !U.compareAndSwapLong(this, BASECOUNT, b = baseCount, s = b + x)) { CounterCell a; long v; int m; boolean uncontended = true; if (as == null || (m = as.length - 1) < 0 || (a = as[ThreadLocalRandom.getProbe() & m]) == null || // 变量uncontended记录着这个CAS操作是否成功 !(uncontended = U.compareAndSwapLong(a, CELLVALUE, v = a.value, v + x))) { fullAddCount(x, uncontended); return; } if (check <= 1) return; s = sumCount(); } if (check >= 0) { // 检查是否需要扩容,后面再详细看 } }细节一:
首先我们要注意方法中刚进来的if判断条件:
if ((as = counterCells) != null || !U.compareAndSwapLong(this, BASECOUNT, b = baseCount, s = b + x)) { }作者在这里巧妙的运用了逻辑短路,如果(as = counterCells) != null则后面的CAS是不会执行的,为什么要这么设置呢?作者有两点考虑:
1. 原因在于如果(as = counterCells) != null,则说明辅助队列已经初始化好了,相比于所有的线程都自旋等待baseCount这一个变量,让线程通过CAS去操作队列中的值有更大的可能性成功,因为辅助队列的最大长度为大于当前处理器个数的2的正整数幂,可以支持更大的并发
2. 如果辅助队列还没有初始化好,直到有必要的时候再去创建队列,如何判断“必要性”呢?就看对baseCount的CAS操作能否成功,如果失败,就说明当前系统的并发已经比较高了,需要队列的辅助,否则直接操作baseCount
细节二:
只有当辅助队列已存在,且由ThreadLocalRandom.getProbe()在辅助队列中确定的位置不为null时,才对其做CAS操作,这本来是一个正常的防御性判断,但是uncontended记录了CAS是否成功,如果失败,则会在fullAddCount中调用ThreadLocalRandom.advanceProbe换一个身份码调整下当前线程在辅助队列的位置,避免所有线程都在辅助队列的同一个坑位自旋等待。
// See LongAdder version for explanation // wasUncontended 记录着调用方CAS是否成功,如果失败则换一个辅助队列的元素继续CAS private final void fullAddCount(long x, boolean wasUncontended) { int h; if ((h = ThreadLocalRandom.getProbe()) == 0) { ThreadLocalRandom.localInit(); // force initialization h = ThreadLocalRandom.getProbe(); wasUncontended = true; } boolean collide = false; // True if last slot nonempty for (;;) { CounterCell[] as; CounterCell a; int n; long v; // 【A】如果辅助队列已经创建,则直接操作辅助队列 if ((as = counterCells) != null && (n = as.length) > 0) { if ((a = as[(n - 1) & h]) == null) { if (cellsBusy == 0) { // Try to attach new Cell CounterCell r = new CounterCell(x); // Optimistic create if (cellsBusy == 0 && U.compareAndSwapInt(this, CELLSBUSY, 0, 1)) { boolean created = false; try { // Recheck under lock CounterCell[] rs; int m, j; if ((rs = counterCells) != null && (m = rs.length) > 0 && rs[j = (m - 1) & h] == null) { rs[j] = r; created = true; } } finally { cellsBusy = 0; } if (created) break; continue; // Slot is now non-empty } } collide = false; } else if (!wasUncontended) // 如果调用方CAS失败了,本轮空跑,下一个循环换下标继续操作 wasUncontended = true; // Continue after rehash else if (U.compareAndSwapLong(a, CELLVALUE, v = a.value, v + x)) break; else if (counterCells != as || n >= NCPU) // 如果辅助队列长度已经超过了CPU个数,本轮空跑,下一个循环换下标继续操作 collide = false; // At max size or stale else if (!collide) // 如果上一次操作失败了(CAS失败或者新建CounterCell失败),本轮空跑,下一个循环换下标继续操作 collide = true; else if (cellsBusy == 0 && // 如果连续两次操作辅助队列失败,则考虑扩容 U.compareAndSwapInt(this, CELLSBUSY, 0, 1)) { try { if (counterCells == as) {// Expand table unless stale CounterCell[] rs = new CounterCell[n << 1]; for (int i = 0; i < n; ++i) rs[i] = as[i]; counterCells = rs; } } finally { cellsBusy = 0; } collide = false; continue; // Retry with expanded table } // 如果上一次操作失败或者调用方CAS失败,都会走到这里,变换要操作的辅助队列下标 h = ThreadLocalRandom.advanceProbe(h); } // 【B】如果辅助队列还未创建,则加锁创建 else if (cellsBusy == 0 && counterCells == as && U.compareAndSwapInt(this, CELLSBUSY, 0, 1)) { boolean init = false; try { // Initialize table if (counterCells == as) { CounterCell[] rs = new CounterCell[2]; rs[h & 1] = new CounterCell(x); counterCells = rs; init = true; } } finally { cellsBusy = 0; } if (init) break; } // 【C】如果辅助队列创建失败(拿锁失败),则尝试直接操作`baseCount` else if (U.compareAndSwapLong(this, BASECOUNT, v = baseCount, v + x)) break; // Fall back on using base } }因为counterCells是一个普通的数组,因此对其的写操作,包括初始化,扩容以及元素的写都需要加锁,加锁的方式是对全局变量cellsBusy的自旋锁。先看最外层的三个分支:
【B】如果辅助队列还没有创建,则加锁创建
【C】如果因为拿锁失败导致辅助队列创建失败,则尝试自旋写入变量baseCount,万一真的成功了呢
【A】如果辅助队列已经创建了,则直接去操作辅助队列相应的元素
注释中标注【A】的这个分支代码较多,其主要思路是如果通过CAS或者加锁操作辅助队列中的某个元素失败,则首先通过调用ThreadLocalRandom.advanceProbe(h)换一个队列中的元素继续操作,这次操作是否成功会记录在临时变量collide中。如果下一次操作还是失败,则说明此时的并发量比较大需要扩容了。如果辅助队列的长度已经超过了CPU的个数,那就不再扩容,继续换一个元素操作,因为同一时间能运行的线程数最大不会超过计算机的CPU个数。
在这个过程中有四个细节仍然需要注意:
细节一:
counterCells只是一个普通的数组,因此并不是线程安全的,所以对其写操作需要加锁保证并发安全
细节二:
加锁的时候,作者做了一个double-check的动作,我看有的文章将其解读为“类似于单例模式的double-check”,这个是不对的,作者这样做的原因我们在上一篇文章中有讲过,首先第一个检查cellsBusy == 0是流程往下走的基础,如果cellsBusy == 1则直接拿锁失败退出,调用h = ThreadLocalRandom.advanceProbe(h);更新h后重试,如果cellsBusy == 0校验通过,则调用CounterCell r = new CounterCell(x);初始化一个CounterCell,这样做是为了减少自旋锁的临界区的大小,以此来提升并发性能
细节三:
在加锁的时候先判断下cellsBusy是否为0,如果为1那直接宣告拿锁失败,为什么这么做呢?因为相比于调用UNSAFE的CAS操作,直接读取volatile的消耗更少,如果直接读取cellsBusy已经能判断出拿锁失败,那就没必要再调用耗时更多的CAS了
细节四:
对cellsBusy从0到1的更改调用了CAS但是从1置为0却只用了赋值操作,这是因为CAS可以保证能走到这条语句的只有一个线程,因此可以用赋值操作来更改cellsBusy的值。
前面两个方法主要是把ConcurrentHashMap中的元素个数分散的记录到baseCount和辅助队列中,调用size()方法的时候只需要把这些值相加即可。
public int size() { long n = sumCount(); return ((n < 0L) ? 0 : (n > (long)Integer.MAX_VALUE) ? Integer.MAX_VALUE : (int)n); } final long sumCount() { CounterCell[] as = counterCells; CounterCell a; long sum = baseCount; if (as != null) { for (int i = 0; i < as.length; ++i) { if ((a = as[i]) != null) sum += a.value; } } return sum; }“Java8 ConcurrentHashMap源码中隐藏的两个Bug是什么”的内容就介绍到这里了,感谢大家的阅读。如果想了解更多行业相关的知识可以关注亿速云网站,小编将为大家输出更多高质量的实用文章!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。