жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
иҝҷзҜҮж–Үз« дё»иҰҒд»Ӣз»ҚвҖңKafkaеҹәжң¬жЎҶжһ¶жҳҜд»Җд№ҲвҖқпјҢеңЁж—Ҙеёёж“ҚдҪңдёӯпјҢзӣёдҝЎеҫҲеӨҡдәәеңЁKafkaеҹәжң¬жЎҶжһ¶жҳҜд»Җд№Ҳй—®йўҳдёҠеӯҳеңЁз–‘жғ‘пјҢе°Ҹзј–жҹҘйҳ…дәҶеҗ„ејҸиө„ж–ҷпјҢж•ҙзҗҶеҮәз®ҖеҚ•еҘҪз”Ёзҡ„ж“ҚдҪңж–№жі•пјҢеёҢжңӣеҜ№еӨ§е®¶и§Јзӯ”вҖқKafkaеҹәжң¬жЎҶжһ¶жҳҜд»Җд№ҲвҖқзҡ„з–‘жғ‘жңүжүҖеё®еҠ©пјҒжҺҘдёӢжқҘпјҢиҜ·и·ҹзқҖе°Ҹзј–дёҖиө·жқҘеӯҰд№ еҗ§пјҒ
Kafka жҳҜжңҖеҲқз”ұ Linkedin е…¬еҸёејҖеҸ‘пјҢжҳҜдёҖдёӘеҲҶеёғејҸгҖҒж”ҜжҢҒеҲҶеҢәзҡ„пјҲpartitionпјүгҖҒеӨҡеүҜжң¬зҡ„пјҲreplicaпјүпјҢеҹәдәҺ zookeeper еҚҸи°ғзҡ„еҲҶеёғејҸж¶ҲжҒҜзі»з»ҹпјҢе®ғзҡ„жңҖеӨ§зҡ„зү№жҖ§е°ұжҳҜеҸҜд»Ҙе®һж—¶зҡ„еӨ„зҗҶеӨ§йҮҸж•°жҚ®д»Ҙж»Ўи¶іеҗ„з§ҚйңҖжұӮеңәжҷҜпјҡжҜ”еҰӮеҹәдәҺ hadoop зҡ„жү№еӨ„зҗҶзі»з»ҹгҖҒдҪҺ延иҝҹзҡ„е®һж—¶зі»з»ҹгҖҒstorm/Spark жөҒејҸеӨ„зҗҶеј•ж“ҺпјҢweb/nginx ж—Ҙеҝ—гҖҒи®ҝй—®ж—Ҙеҝ—пјҢж¶ҲжҒҜжңҚеҠЎзӯүзӯүпјҢз”Ё scala иҜӯиЁҖзј–еҶҷпјҢLinkedin дәҺ 2010 е№ҙиҙЎзҢ®з»ҷдәҶ Apache еҹәйҮ‘дјҡ并жҲҗдёәйЎ¶зә§ејҖжәҗйЎ№зӣ®гҖӮ
еҪ“д»ҠзӨҫдјҡеҗ„з§Қеә”з”Ёзі»з»ҹиҜёеҰӮе•ҶдёҡгҖҒзӨҫдәӨгҖҒжҗңзҙўгҖҒжөҸи§ҲзӯүеғҸдҝЎжҒҜе·ҘеҺӮдёҖж ·дёҚж–ӯзҡ„з”ҹдә§еҮәеҗ„з§ҚдҝЎжҒҜпјҢеңЁеӨ§ж•°жҚ®ж—¶д»ЈпјҢжҲ‘们йқўдёҙеҰӮдёӢеҮ дёӘжҢ‘жҲҳпјҡ
йёҝи’ҷе®ҳж–№жҲҳз•ҘеҗҲдҪңе…ұе»әвҖ”вҖ”HarmonyOSжҠҖжңҜзӨҫеҢә
еҰӮдҪ•ж”¶йӣҶиҝҷдәӣе·ЁеӨ§зҡ„дҝЎжҒҜ;
еҰӮдҪ•еҲҶжһҗе®ғ;
еҰӮдҪ•еҸҠж—¶еҒҡеҲ°еҰӮдёҠдёӨзӮ№;
д»ҘдёҠеҮ дёӘжҢ‘жҲҳеҪўжҲҗдәҶдёҖдёӘдёҡеҠЎйңҖжұӮжЁЎеһӢпјҢеҚі з”ҹдә§иҖ…з”ҹдә§пјҲproduceпјүеҗ„з§ҚдҝЎжҒҜпјҢж¶Ҳиҙ№иҖ…ж¶Ҳиҙ№пјҲconsumeпјүпјҲеӨ„зҗҶеҲҶжһҗпјүиҝҷдәӣдҝЎжҒҜпјҢиҖҢеңЁз”ҹдә§иҖ…дёҺж¶Ҳиҙ№иҖ…д№Ӣй—ҙпјҢйңҖиҰҒдёҖдёӘжІҹйҖҡдёӨиҖ…зҡ„жЎҘжўҒ-ж¶ҲжҒҜзі»з»ҹ гҖӮд»ҺдёҖдёӘеҫ®и§ӮеұӮйқўжқҘиҜҙпјҢиҝҷз§ҚйңҖжұӮд№ҹеҸҜзҗҶи§ЈдёәдёҚеҗҢзҡ„зі»з»ҹд№Ӣй—ҙеҰӮдҪ•дј йҖ’ж¶ҲжҒҜгҖӮ
Kafka дёҖдёӘеҲҶеёғејҸж¶ҲжҒҜзі»з»ҹеә”иҝҗиҖҢз”ҹпјҡ
йёҝи’ҷе®ҳж–№жҲҳз•ҘеҗҲдҪңе…ұе»әвҖ”вҖ”HarmonyOSжҠҖжңҜзӨҫеҢә
Kafka-з”ұ linked-in ејҖжәҗпјӣ
kafka-еҚіжҳҜи§ЈеҶідёҠиҝ°иҝҷзұ»й—®йўҳзҡ„дёҖдёӘжЎҶжһ¶пјҢе®ғе®һзҺ°дәҶз”ҹдә§иҖ…е’Ңж¶Ҳиҙ№иҖ…д№Ӣй—ҙзҡ„ж— зјқиҝһжҺҘпјӣ
kafka-й«ҳдә§еҮәзҡ„еҲҶеёғејҸж¶ҲжҒҜзі»з»ҹ(A high-throughput distributed messaging system)пјӣ
и§ЈиҖҰ пјҡ
е…Ғи®ёдҪ зӢ¬з«Ӣзҡ„жү©еұ•жҲ–дҝ®ж”№дёӨиҫ№зҡ„еӨ„зҗҶиҝҮзЁӢпјҢеҸӘиҰҒзЎ®дҝқе®ғ们йҒөе®ҲеҗҢж ·зҡ„жҺҘеҸЈзәҰжқҹгҖӮ
еҶ—дҪҷ пјҡ
ж¶ҲжҒҜйҳҹеҲ—жҠҠж•°жҚ®иҝӣиЎҢжҢҒд№…еҢ–зӣҙеҲ°е®ғ们已з»Ҹиў«е®Ңе…ЁеӨ„зҗҶпјҢйҖҡиҝҮиҝҷдёҖж–№ејҸ规йҒҝдәҶж•°жҚ®дёўеӨұйЈҺйҷ©гҖӮи®ёеӨҡж¶ҲжҒҜйҳҹеҲ—жүҖйҮҮз”Ёзҡ„"жҸ’е…Ҙ-иҺ·еҸ–-еҲ йҷӨ"иҢғејҸдёӯпјҢеңЁжҠҠдёҖдёӘж¶ҲжҒҜд»ҺйҳҹеҲ—дёӯеҲ йҷӨд№ӢеүҚпјҢйңҖиҰҒдҪ зҡ„еӨ„зҗҶзі»з»ҹжҳҺзЎ®зҡ„жҢҮеҮәиҜҘж¶ҲжҒҜе·Із»Ҹиў«еӨ„зҗҶе®ҢжҜ•пјҢд»ҺиҖҢзЎ®дҝқдҪ зҡ„ж•°жҚ®иў«е®үе…Ёзҡ„дҝқеӯҳзӣҙеҲ°дҪ дҪҝз”Ёе®ҢжҜ•гҖӮ
жү©еұ•жҖ§ пјҡ
еӣ дёәж¶ҲжҒҜйҳҹеҲ—и§ЈиҖҰдәҶдҪ зҡ„еӨ„зҗҶиҝҮзЁӢпјҢжүҖд»ҘеўһеӨ§ж¶ҲжҒҜе…Ҙйҳҹе’ҢеӨ„зҗҶзҡ„йў‘зҺҮжҳҜеҫҲе®№жҳ“зҡ„пјҢеҸӘиҰҒеҸҰеӨ–еўһеҠ еӨ„зҗҶиҝҮзЁӢеҚіеҸҜгҖӮ
зҒөжҙ»жҖ§ & еі°еҖјеӨ„зҗҶиғҪеҠӣ пјҡ
еңЁи®ҝй—®йҮҸеү§еўһзҡ„жғ…еҶөдёӢпјҢеә”з”Ёд»Қ然йңҖиҰҒ继з»ӯеҸ‘жҢҘдҪңз”ЁпјҢдҪҶжҳҜиҝҷж ·зҡ„зӘҒеҸ‘жөҒйҮҸ并дёҚеёёи§ҒгҖӮеҰӮжһңдёәд»ҘиғҪеӨ„зҗҶиҝҷзұ»еі°еҖји®ҝй—®дёәж ҮеҮҶжқҘжҠ•е…Ҙиө„жәҗйҡҸж—¶еҫ…е‘Ҫж— з–‘жҳҜе·ЁеӨ§зҡ„жөӘиҙ№гҖӮдҪҝз”Ёж¶ҲжҒҜйҳҹеҲ—иғҪеӨҹдҪҝ关键组件顶дҪҸзӘҒеҸ‘зҡ„и®ҝй—®еҺӢеҠӣпјҢиҖҢдёҚдјҡеӣ дёәзӘҒеҸ‘зҡ„и¶…иҙҹиҚ·зҡ„иҜ·жұӮиҖҢе®Ңе…Ёеҙ©жәғгҖӮ
еҸҜжҒўеӨҚжҖ§ пјҡ
зі»з»ҹзҡ„дёҖйғЁеҲҶ组件еӨұж•Ҳж—¶пјҢдёҚдјҡеҪұе“ҚеҲ°ж•ҙдёӘзі»з»ҹгҖӮж¶ҲжҒҜйҳҹеҲ—йҷҚдҪҺдәҶиҝӣзЁӢй—ҙзҡ„иҖҰеҗҲеәҰпјҢжүҖд»ҘеҚідҪҝдёҖдёӘеӨ„зҗҶж¶ҲжҒҜзҡ„иҝӣзЁӢжҢӮжҺүпјҢеҠ е…ҘйҳҹеҲ—дёӯзҡ„ж¶ҲжҒҜд»Қ然еҸҜд»ҘеңЁзі»з»ҹжҒўеӨҚеҗҺиў«еӨ„зҗҶгҖӮ
йЎәеәҸдҝқиҜҒ пјҡ
еңЁеӨ§еӨҡдҪҝз”ЁеңәжҷҜдёӢпјҢж•°жҚ®еӨ„зҗҶзҡ„йЎәеәҸйғҪеҫҲйҮҚиҰҒгҖӮеӨ§йғЁеҲҶж¶ҲжҒҜйҳҹеҲ—жң¬жқҘе°ұжҳҜжҺ’еәҸзҡ„пјҢ并且иғҪдҝқиҜҒж•°жҚ®дјҡжҢүз…§зү№е®ҡзҡ„йЎәеәҸжқҘеӨ„зҗҶгҖӮпјҲKafka дҝқиҜҒдёҖдёӘ Partition еҶ…зҡ„ж¶ҲжҒҜзҡ„жңүеәҸжҖ§пјү
зј“еҶІ пјҡ
жңүеҠ©дәҺжҺ§еҲ¶е’ҢдјҳеҢ–ж•°жҚ®жөҒз»ҸиҝҮзі»з»ҹзҡ„йҖҹеәҰпјҢи§ЈеҶіз”ҹдә§ж¶ҲжҒҜе’Ңж¶Ҳиҙ№ж¶ҲжҒҜзҡ„еӨ„зҗҶйҖҹеәҰдёҚдёҖиҮҙзҡ„жғ…еҶөгҖӮ
ејӮжӯҘйҖҡдҝЎ пјҡ
еҫҲеӨҡж—¶еҖҷпјҢз”ЁжҲ·дёҚжғід№ҹдёҚйңҖиҰҒз«ӢеҚіеӨ„зҗҶж¶ҲжҒҜгҖӮж¶ҲжҒҜйҳҹеҲ—жҸҗдҫӣдәҶејӮжӯҘеӨ„зҗҶжңәеҲ¶пјҢе…Ғи®ёз”ЁжҲ·жҠҠдёҖдёӘж¶ҲжҒҜж”ҫе…ҘйҳҹеҲ—пјҢдҪҶ并дёҚз«ӢеҚіеӨ„зҗҶе®ғгҖӮжғіеҗ‘йҳҹеҲ—дёӯж”ҫе…ҘеӨҡе°‘ж¶ҲжҒҜе°ұж”ҫеӨҡе°‘пјҢ然еҗҺеңЁйңҖиҰҒзҡ„ж—¶еҖҷеҶҚеҺ»еӨ„зҗҶе®ғ们гҖӮ
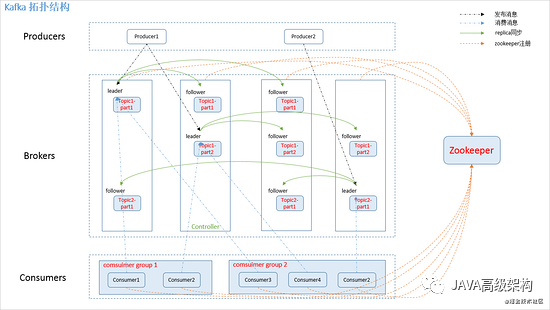
producer пјҡж¶ҲжҒҜз”ҹдә§иҖ…пјҢеҸ‘еёғж¶ҲжҒҜеҲ° kafka йӣҶзҫӨзҡ„з»Ҳз«ҜжҲ–жңҚеҠЎгҖӮ
broker пјҡkafka йӣҶзҫӨдёӯеҢ…еҗ«зҡ„жңҚеҠЎеҷЁгҖӮ
topic пјҡжҜҸжқЎеҸ‘еёғеҲ° kafka йӣҶзҫӨзҡ„ж¶ҲжҒҜеұһдәҺзҡ„зұ»еҲ«пјҢеҚі kafka жҳҜйқўеҗ‘ topic зҡ„гҖӮ
partition пјҡpartition жҳҜзү©зҗҶдёҠзҡ„жҰӮеҝөпјҢжҜҸдёӘ topic еҢ…еҗ«дёҖдёӘжҲ–еӨҡдёӘ partitionгҖӮkafka еҲҶй…Қзҡ„еҚ•дҪҚжҳҜ partitionгҖӮ
consumer пјҡд»Һ kafka йӣҶзҫӨдёӯж¶Ҳиҙ№ж¶ҲжҒҜзҡ„з»Ҳз«ҜжҲ–жңҚеҠЎгҖӮ
consumer group пјҡhigh-level consumer API дёӯпјҢжҜҸдёӘ consumer йғҪеұһдәҺдёҖдёӘ consumer groupпјҢжҜҸжқЎж¶ҲжҒҜеҸӘиғҪиў« consumer group дёӯзҡ„дёҖдёӘ Consumer ж¶Ҳиҙ№пјҢдҪҶеҸҜд»Ҙиў«еӨҡдёӘ consumer group ж¶Ҳиҙ№гҖӮ
replica пјҡpartition зҡ„еүҜжң¬пјҢдҝқйҡң partition зҡ„й«ҳеҸҜз”ЁгҖӮ
leader пјҡreplica дёӯзҡ„дёҖдёӘи§’иүІпјҢ producer е’Ң consumer еҸӘи·ҹ leader дәӨдә’гҖӮ
follower пјҡreplica дёӯзҡ„дёҖдёӘи§’иүІпјҢд»Һ leader дёӯеӨҚеҲ¶ж•°жҚ®гҖӮ
controller пјҡkafka йӣҶзҫӨдёӯзҡ„е…¶дёӯдёҖдёӘжңҚеҠЎеҷЁпјҢз”ЁжқҘиҝӣиЎҢ leader election д»ҘеҸҠ еҗ„з§Қ failoverгҖӮ
zookeeper пјҡkafka йҖҡиҝҮ zookeeper жқҘеӯҳеӮЁйӣҶзҫӨзҡ„ meta дҝЎжҒҜгҖӮ
йёҝи’ҷе®ҳж–№жҲҳз•ҘеҗҲдҪңе…ұе»әвҖ”вҖ”HarmonyOSжҠҖжңҜзӨҫеҢә
й«ҳеҗһеҗҗйҮҸгҖҒдҪҺ延иҝҹ пјҡkafkaжҜҸз§’еҸҜд»ҘеӨ„зҗҶеҮ еҚҒдёҮжқЎж¶ҲжҒҜпјҢе®ғзҡ„延иҝҹжңҖдҪҺеҸӘжңүеҮ жҜ«з§’пјӣ
еҸҜжү©еұ•жҖ§ пјҡkafkaйӣҶзҫӨж”ҜжҢҒзғӯжү©еұ•пјӣ
жҢҒд№…жҖ§гҖҒеҸҜйқ жҖ§ пјҡж¶ҲжҒҜиў«жҢҒд№…еҢ–еҲ°жң¬ең°зЈҒзӣҳпјҢ并且ж”ҜжҢҒж•°жҚ®еӨҮд»ҪйҳІжӯўж•°жҚ®дёўеӨұпјӣ
е®№й”ҷжҖ§ пјҡе…Ғи®ёйӣҶзҫӨдёӯиҠӮзӮ№еӨұиҙҘпјҲиӢҘеүҜжң¬ж•°йҮҸдёәn,еҲҷе…Ғи®ёn-1дёӘиҠӮзӮ№еӨұиҙҘпјүпјӣ
й«ҳ并еҸ‘ пјҡж”ҜжҢҒж•°еҚғдёӘе®ўжҲ·з«ҜеҗҢж—¶иҜ»еҶҷпјӣ
consumergroup пјҡеҗ„дёӘ consumer еҸҜд»Ҙз»„жҲҗдёҖдёӘз»„пјҢжҜҸдёӘж¶ҲжҒҜеҸӘиғҪиў«з»„дёӯзҡ„дёҖдёӘ consumer ж¶Ҳиҙ№пјҢеҰӮжһңдёҖдёӘж¶ҲжҒҜеҸҜд»Ҙиў«еӨҡдёӘ consumer ж¶Ҳиҙ№зҡ„иҜқпјҢйӮЈд№Ҳиҝҷдәӣ consumer еҝ…йЎ»еңЁдёҚеҗҢзҡ„з»„гҖӮ
ж¶ҲжҒҜзҠ¶жҖҒ пјҡеңЁ Kafka дёӯпјҢж¶ҲжҒҜзҡ„зҠ¶жҖҒиў«дҝқеӯҳеңЁ consumer дёӯпјҢbroker дёҚдјҡе…іеҝғе“ӘдёӘж¶ҲжҒҜиў«ж¶Ҳиҙ№дәҶиў«и°Ғж¶Ҳиҙ№дәҶпјҢеҸӘи®°еҪ•дёҖдёӘ offset еҖјпјҲжҢҮеҗ‘ partition дёӯдёӢдёҖдёӘиҰҒиў«ж¶Ҳиҙ№зҡ„ж¶ҲжҒҜдҪҚзҪ®пјүпјҢиҝҷе°ұж„Ҹе‘ізқҖеҰӮжһң consumer еӨ„зҗҶдёҚеҘҪзҡ„иҜқпјҢbroker дёҠзҡ„дёҖдёӘж¶ҲжҒҜеҸҜиғҪдјҡиў«ж¶Ҳиҙ№еӨҡж¬ЎгҖӮ
ж¶ҲжҒҜжҢҒд№…еҢ– пјҡKafka дёӯдјҡжҠҠж¶ҲжҒҜжҢҒд№…еҢ–еҲ°жң¬ең°ж–Ү件系з»ҹдёӯпјҢ并且дҝқжҢҒжһҒй«ҳзҡ„ж•ҲзҺҮгҖӮ
ж¶ҲжҒҜжңүж•Ҳжңҹ пјҡKafka дјҡй•ҝд№…дҝқз•ҷе…¶дёӯзҡ„ж¶ҲжҒҜпјҢд»Ҙдҫҝ consumer еҸҜд»ҘеӨҡж¬Ўж¶Ҳиҙ№пјҢеҪ“然其дёӯеҫҲеӨҡз»ҶиҠӮжҳҜеҸҜй…ҚзҪ®зҡ„гҖӮ
жү№йҮҸеҸ‘йҖҒ пјҡKafka ж”ҜжҢҒд»Ҙж¶ҲжҒҜйӣҶеҗҲдёәеҚ•дҪҚиҝӣиЎҢжү№йҮҸеҸ‘йҖҒпјҢд»ҘжҸҗй«ҳ push ж•ҲзҺҮгҖӮ
push-and-pull : Kafka дёӯзҡ„ Producer е’Ң consumer йҮҮз”Ёзҡ„жҳҜ push-and-pull жЁЎејҸпјҢеҚі Producer еҸӘз®Ўеҗ‘ broker push ж¶ҲжҒҜпјҢconsumer еҸӘз®Ўд»Һ broker pull ж¶ҲжҒҜпјҢдёӨиҖ…еҜ№ж¶ҲжҒҜзҡ„з”ҹдә§е’Ңж¶Ҳиҙ№жҳҜејӮжӯҘзҡ„гҖӮKafkaйӣҶзҫӨдёӯ broker д№Ӣй—ҙзҡ„е…ізі»пјҡдёҚжҳҜдё»д»Һе…ізі»пјҢеҗ„дёӘ broker еңЁйӣҶзҫӨдёӯең°дҪҚдёҖж ·пјҢжҲ‘们еҸҜд»ҘйҡҸж„Ҹзҡ„еўһеҠ жҲ–еҲ йҷӨд»»дҪ•дёҖдёӘ broker иҠӮзӮ№гҖӮ
иҙҹиҪҪеқҮиЎЎж–№йқў пјҡKafka жҸҗдҫӣдәҶдёҖдёӘ metadata API жқҘз®ЎзҗҶ broker д№Ӣй—ҙзҡ„иҙҹиҪҪпјҲеҜ№ Kafka 0.8.x иҖҢиЁҖпјҢеҜ№дәҺ 0.7.x дё»иҰҒйқ zookeeper жқҘе®һзҺ°иҙҹиҪҪеқҮиЎЎпјүгҖӮ
еҗҢжӯҘејӮжӯҘ пјҡProducer йҮҮз”ЁејӮжӯҘ push ж–№ејҸпјҢжһҒеӨ§жҸҗй«ҳ Kafka зі»з»ҹзҡ„еҗһеҗҗзҺҮпјҲеҸҜд»ҘйҖҡиҝҮеҸӮж•°жҺ§еҲ¶жҳҜйҮҮз”ЁеҗҢжӯҘиҝҳжҳҜејӮжӯҘж–№ејҸпјүгҖӮ
еҲҶеҢәжңәеҲ¶ partition пјҡKafka зҡ„ broker з«Ҝж”ҜжҢҒж¶ҲжҒҜеҲҶеҢәпјҢProducer еҸҜд»ҘеҶіе®ҡжҠҠж¶ҲжҒҜеҸ‘еҲ°е“ӘдёӘеҲҶеҢәпјҢеңЁдёҖдёӘеҲҶеҢәдёӯж¶ҲжҒҜзҡ„йЎәеәҸе°ұжҳҜ Producer еҸ‘йҖҒж¶ҲжҒҜзҡ„йЎәеәҸпјҢдёҖдёӘдё»йўҳдёӯеҸҜд»ҘжңүеӨҡдёӘеҲҶеҢәпјҢе…·дҪ“еҲҶеҢәзҡ„ж•°йҮҸжҳҜеҸҜй…ҚзҪ®зҡ„гҖӮеҲҶеҢәзҡ„ж„Ҹд№үеҫҲйҮҚеӨ§пјҢеҗҺйқўзҡ„еҶ…е®№дјҡйҖҗжёҗдҪ“зҺ°гҖӮ
зҰ»зәҝж•°жҚ®иЈ…иҪҪ пјҡKafka з”ұдәҺеҜ№еҸҜжӢ“еұ•зҡ„ж•°жҚ®жҢҒд№…еҢ–зҡ„ж”ҜжҢҒпјҢе®ғд№ҹйқһеёёйҖӮеҗҲеҗ‘ Hadoop жҲ–иҖ…ж•°жҚ®д»“еә“дёӯиҝӣиЎҢж•°жҚ®иЈ…иҪҪгҖӮ
жҸ’件ж”ҜжҢҒ пјҡзҺ°еңЁдёҚе°‘жҙ»и·ғзҡ„зӨҫеҢәе·Із»ҸејҖеҸ‘еҮәдёҚе°‘жҸ’件жқҘжӢ“еұ• Kafka зҡ„еҠҹиғҪпјҢеҰӮз”ЁжқҘй…ҚеҗҲ StormгҖҒHadoopгҖҒflume зӣёе…ізҡ„жҸ’件гҖӮ
ж—Ҙеҝ—收йӣҶ пјҡдёҖдёӘе…¬еҸёеҸҜд»Ҙз”ЁKafkaеҸҜд»Ҙ收йӣҶеҗ„з§ҚжңҚеҠЎзҡ„ logпјҢйҖҡиҝҮ kafka д»Ҙз»ҹдёҖжҺҘеҸЈжңҚеҠЎзҡ„ж–№ејҸејҖж”ҫз»ҷеҗ„з§Қ consumerпјҢдҫӢеҰӮ hadoopгҖҒHbaseгҖҒSolr зӯүгҖӮ
ж¶ҲжҒҜзі»з»ҹ пјҡи§ЈиҖҰе’Ңз”ҹдә§иҖ…е’Ңж¶Ҳиҙ№иҖ…гҖҒзј“еӯҳж¶ҲжҒҜзӯүгҖӮ
з”ЁжҲ·жҙ»еҠЁи·ҹиёӘ пјҡKafka з»Ҹеёёиў«з”ЁжқҘи®°еҪ• web з”ЁжҲ·жҲ–иҖ… app з”ЁжҲ·зҡ„еҗ„з§Қжҙ»еҠЁпјҢеҰӮжөҸи§ҲзҪ‘йЎөгҖҒжҗңзҙўгҖҒзӮ№еҮ»зӯүжҙ»еҠЁпјҢиҝҷдәӣжҙ»еҠЁдҝЎжҒҜиў«еҗ„дёӘжңҚеҠЎеҷЁеҸ‘еёғеҲ° kafka зҡ„ topic дёӯпјҢ然еҗҺи®ўйҳ…иҖ…йҖҡиҝҮи®ўйҳ…иҝҷдәӣ topic жқҘеҒҡе®һж—¶зҡ„зӣ‘жҺ§еҲҶжһҗпјҢжҲ–иҖ…иЈ…иҪҪеҲ° hadoopгҖҒж•°жҚ®д»“еә“дёӯеҒҡзҰ»зәҝеҲҶжһҗе’ҢжҢ–жҺҳгҖӮ
иҝҗиҗҘжҢҮж Ү пјҡKafka д№ҹз»Ҹеёёз”ЁжқҘи®°еҪ•иҝҗиҗҘзӣ‘жҺ§ж•°жҚ®гҖӮеҢ…жӢ¬ж”¶йӣҶеҗ„з§ҚеҲҶеёғејҸеә”з”Ёзҡ„ж•°жҚ®пјҢз”ҹдә§еҗ„з§Қж“ҚдҪңзҡ„йӣҶдёӯеҸҚйҰҲпјҢжҜ”еҰӮжҠҘиӯҰе’ҢжҠҘе‘ҠгҖӮ
жөҒејҸеӨ„зҗҶ пјҡжҜ”еҰӮ spark streaming е’Ң storm
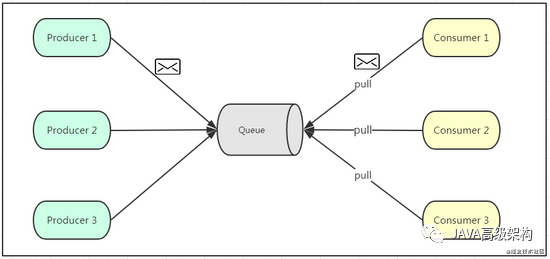
еҰӮдёҠеӣҫжүҖзӨәпјҢзӮ№еҜ№зӮ№жЁЎејҸйҖҡеёёжҳҜеҹәдәҺжӢүеҸ–жҲ–иҖ…иҪ®иҜўзҡ„ж¶ҲжҒҜдј йҖҒжЁЎеһӢпјҢиҝҷдёӘжЁЎеһӢзҡ„зү№зӮ№жҳҜеҸ‘йҖҒеҲ°йҳҹеҲ—зҡ„ж¶ҲжҒҜиў«дёҖдёӘдё”еҸӘжңүдёҖдёӘж¶Ҳиҙ№иҖ…иҝӣиЎҢеӨ„зҗҶгҖӮз”ҹдә§иҖ…е°Ҷж¶ҲжҒҜж”ҫе…Ҙж¶ҲжҒҜйҳҹеҲ—еҗҺпјҢз”ұж¶Ҳиҙ№иҖ…дё»еҠЁзҡ„еҺ»жӢүеҸ–ж¶ҲжҒҜиҝӣиЎҢж¶Ҳиҙ№гҖӮзӮ№еҜ№зӮ№жЁЎеһӢзҡ„зҡ„дјҳзӮ№жҳҜж¶Ҳиҙ№иҖ…жӢүеҸ–ж¶ҲжҒҜзҡ„йў‘зҺҮеҸҜд»Ҙз”ұиҮӘе·ұжҺ§еҲ¶гҖӮдҪҶжҳҜж¶ҲжҒҜйҳҹеҲ—жҳҜеҗҰжңүж¶ҲжҒҜйңҖиҰҒж¶Ҳиҙ№пјҢеңЁж¶Ҳиҙ№иҖ…з«Ҝж— жі•ж„ҹзҹҘпјҢжүҖд»ҘеңЁж¶Ҳиҙ№иҖ…з«ҜйңҖиҰҒйўқеӨ–зҡ„зәҝзЁӢеҺ»зӣ‘жҺ§гҖӮ
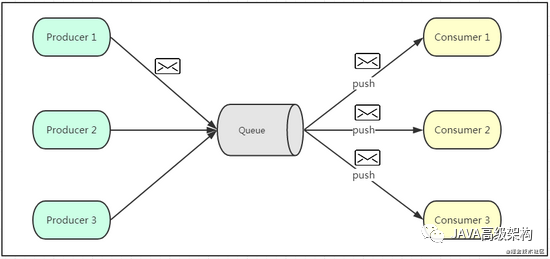
еҰӮдёҠеӣҫжүҖзӨәпјҢеҸ‘еёғи®ўйҳ…жЁЎејҸжҳҜдёҖдёӘеҹәдәҺж¶ҲжҒҜйҖҒзҡ„ж¶ҲжҒҜдј йҖҒжЁЎеһӢпјҢж”№жЁЎеһӢеҸҜд»ҘжңүеӨҡз§ҚдёҚеҗҢзҡ„и®ўйҳ…иҖ…гҖӮз”ҹдә§иҖ…е°Ҷж¶ҲжҒҜж”ҫе…Ҙж¶ҲжҒҜйҳҹеҲ—еҗҺпјҢйҳҹеҲ—дјҡе°Ҷж¶ҲжҒҜжҺЁйҖҒз»ҷи®ўйҳ…иҝҮиҜҘзұ»ж¶ҲжҒҜзҡ„ж¶Ҳиҙ№иҖ…пјҲзұ»дјјеҫ®дҝЎе…¬дј—еҸ·пјүгҖӮз”ұдәҺжҳҜж¶Ҳиҙ№иҖ…иў«еҠЁжҺҘ收жҺЁйҖҒпјҢжүҖд»Ҙж— йңҖж„ҹзҹҘж¶ҲжҒҜйҳҹеҲ—жҳҜеҗҰжңүеҫ…ж¶Ҳиҙ№зҡ„ж¶ҲжҒҜпјҒдҪҶжҳҜ consumer1гҖҒconsumer2гҖҒconsumer3 з”ұдәҺжңәеҷЁжҖ§иғҪдёҚдёҖж ·пјҢжүҖд»ҘеӨ„зҗҶж¶ҲжҒҜзҡ„иғҪеҠӣд№ҹдјҡдёҚдёҖж ·пјҢдҪҶж¶ҲжҒҜйҳҹеҲ—еҚҙж— жі•ж„ҹзҹҘж¶Ҳиҙ№иҖ…ж¶Ҳиҙ№зҡ„йҖҹеәҰпјҒжүҖд»ҘжҺЁйҖҒзҡ„йҖҹеәҰжҲҗдәҶеҸ‘еёғи®ўйҳ…жЁЎжЁЎејҸзҡ„дёҖдёӘй—®йўҳпјҒеҒҮи®ҫдёүдёӘж¶Ҳиҙ№иҖ…еӨ„зҗҶйҖҹеәҰеҲҶеҲ«жҳҜ 8M/sгҖҒ5M/sгҖҒ2M/sпјҢеҰӮжһңйҳҹеҲ—жҺЁйҖҒзҡ„йҖҹеәҰдёә5M/sпјҢеҲҷ consumer3 ж— жі•жүҝеҸ—пјҒеҰӮжһңйҳҹеҲ—жҺЁйҖҒзҡ„йҖҹеәҰдёә 2M/sпјҢеҲҷ consumer1гҖҒconsumer2 дјҡеҮәзҺ°иө„жәҗзҡ„жһҒеӨ§жөӘиҙ№пјҒ
дҪңдёәдёҖдёӘж¶ҲжҒҜзі»з»ҹпјҢ Kafka йҒөеҫӘдәҶдј з»ҹзҡ„ж–№ејҸпјҢйҖүжӢ©з”ұ Producer еҗ‘ broker push ж¶ҲжҒҜ并з”ұ Consumer д»Һ broker pull ж¶ҲжҒҜ гҖӮдёҖдәӣж—Ҙеҝ—收йӣҶзі»з»ҹ (logging-centric system)пјҢжҜ”еҰӮ Facebook зҡ„ Scribe е’Ң Cloudera зҡ„ FlumeпјҢйҮҮз”Ё push жЁЎејҸгҖӮдәӢе®һдёҠпјҢpush жЁЎејҸе’Ң pull жЁЎејҸеҗ„жңүдјҳеҠЈгҖӮ
push жЁЎејҸеҫҲйҡҫйҖӮеә”ж¶Ҳиҙ№йҖҹзҺҮдёҚеҗҢзҡ„ж¶Ҳиҙ№иҖ…пјҢеӣ дёәж¶ҲжҒҜеҸ‘йҖҒйҖҹзҺҮжҳҜз”ұ broker еҶіе®ҡзҡ„гҖӮpush жЁЎејҸзҡ„зӣ®ж ҮжҳҜе°ҪеҸҜиғҪд»ҘжңҖеҝ«йҖҹеәҰдј йҖ’ж¶ҲжҒҜпјҢдҪҶжҳҜиҝҷж ·еҫҲе®№жҳ“йҖ жҲҗ Consumer жқҘдёҚеҸҠеӨ„зҗҶж¶ҲжҒҜпјҢе…ёеһӢзҡ„иЎЁзҺ°е°ұжҳҜжӢ’з»қжңҚеҠЎд»ҘеҸҠзҪ‘з»ңжӢҘеЎһгҖӮиҖҢ pull жЁЎејҸеҲҷеҸҜд»Ҙж №жҚ® Consumer зҡ„ж¶Ҳиҙ№иғҪеҠӣд»ҘйҖӮеҪ“зҡ„йҖҹзҺҮж¶Ҳиҙ№ж¶ҲжҒҜгҖӮ
еҜ№дәҺ Kafka иҖҢиЁҖпјҢpull жЁЎејҸжӣҙеҗҲйҖӮгҖӮpull жЁЎејҸеҸҜз®ҖеҢ– broker зҡ„и®ҫи®ЎпјҢConsumer еҸҜиҮӘдё»жҺ§еҲ¶ж¶Ҳиҙ№ж¶ҲжҒҜзҡ„йҖҹзҺҮпјҢеҗҢж—¶ Consumer еҸҜд»ҘиҮӘе·ұжҺ§еҲ¶ж¶Ҳиҙ№ж–№ејҸ——еҚіеҸҜжү№йҮҸж¶Ҳиҙ№д№ҹеҸҜйҖҗжқЎж¶Ҳиҙ№пјҢеҗҢж—¶иҝҳиғҪйҖүжӢ©дёҚеҗҢзҡ„жҸҗдәӨж–№ејҸд»ҺиҖҢе®һзҺ°дёҚеҗҢзҡ„дј иҫ“иҜӯд№ү гҖӮ
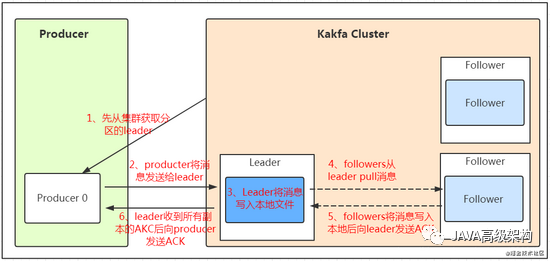
жҲ‘们зңӢдёҠйқўзҡ„жһ¶жһ„еӣҫдёӯпјҢproducer е°ұжҳҜз”ҹдә§иҖ…пјҢжҳҜж•°жҚ®зҡ„е…ҘеҸЈгҖӮжіЁж„ҸзңӢеӣҫдёӯзҡ„зәўиүІз®ӯеӨҙпјҢ Producer еңЁеҶҷе…Ҙж•°жҚ®зҡ„ж—¶еҖҷж°ёиҝңзҡ„жүҫ leaderпјҢдёҚдјҡзӣҙжҺҘе°Ҷж•°жҚ®еҶҷе…Ҙ follower пјҒйӮЈ leader жҖҺд№Ҳжүҫе‘ўпјҹеҶҷе…Ҙзҡ„жөҒзЁӢеҸҲжҳҜд»Җд№Ҳж ·зҡ„е‘ўпјҹжҲ‘们зңӢдёӢеӣҫпјҡ
йёҝи’ҷе®ҳж–№жҲҳз•ҘеҗҲдҪңе…ұе»әвҖ”вҖ”HarmonyOSжҠҖжңҜзӨҫеҢә
е…Ҳд»ҺйӣҶзҫӨиҺ·еҸ–еҲҶеҢәзҡ„ leaderпјӣ
producer е°Ҷж¶ҲжҒҜеҸ‘йҖҒз»ҷ leaderпјӣ
Leader е°Ҷж¶ҲжҒҜеҶҷе…Ҙжң¬ең°ж–Ү件пјӣ
followers д»Һl eader жӢүеҸ–ж¶ҲжҒҜпјӣ
followers е°Ҷж¶ҲжҒҜеҶҷе…Ҙжң¬ең°еҗҺеҗ‘ leader еҸ‘йҖҒ ACK зЎ®и®Өпјӣ
leader 收еҲ°жүҖжңүеүҜжң¬зҡ„ ACK еҗҺеҗ‘ producer еҸ‘йҖҒ ACK зЎ®и®Өпјӣ
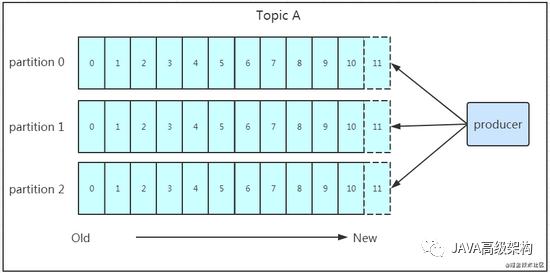
6.1.1. дҝқиҜҒж¶ҲжҒҜжңүеәҸ
йңҖиҰҒжіЁж„Ҹзҡ„дёҖзӮ№жҳҜпјҢж¶ҲжҒҜеҶҷе…Ҙ leader еҗҺпјҢfollower жҳҜдё»еҠЁзҡ„еҺ» leader иҝӣиЎҢеҗҢжӯҘзҡ„пјҒproducer йҮҮз”Ё push жЁЎејҸе°Ҷж•°жҚ®еҸ‘еёғеҲ° brokerпјҢжҜҸжқЎж¶ҲжҒҜиҝҪеҠ еҲ°еҲҶеҢәдёӯпјҢйЎәеәҸеҶҷе…ҘзЈҒзӣҳпјҢжүҖд»ҘдҝқиҜҒеҗҢдёҖеҲҶеҢәеҶ…зҡ„ж•°жҚ®жҳҜжңүеәҸзҡ„ пјҒеҶҷе…ҘзӨәж„ҸеӣҫеҰӮдёӢпјҡ
6.1.2. ж¶ҲжҒҜиҙҹиҪҪеҲҶеҢә
дёҠйқўиҜҙеҲ°ж•°жҚ®дјҡеҶҷе…ҘеҲ°дёҚеҗҢзҡ„еҲҶеҢәпјҢйӮЈ kafka дёәд»Җд№ҲиҰҒеҒҡеҲҶеҢәе‘ўпјҹзӣёдҝЎеӨ§е®¶еә”иҜҘд№ҹиғҪзҢңеҲ°пјҢеҲҶеҢәзҡ„дё»иҰҒзӣ®зҡ„жҳҜпјҡ
ж–№дҫҝжү©еұ• пјҡеӣ дёәдёҖдёӘ topic еҸҜд»ҘжңүеӨҡдёӘ partitionпјҢжүҖд»ҘжҲ‘们еҸҜд»ҘйҖҡиҝҮжү©еұ•жңәеҷЁеҺ»иҪ»жқҫзҡ„еә”еҜ№ж—ҘзӣҠеўһй•ҝзҡ„ж•°жҚ®йҮҸгҖӮ
жҸҗй«ҳ并еҸ‘ пјҡд»Ҙ partition дёәиҜ»еҶҷеҚ•дҪҚпјҢеҸҜд»ҘеӨҡдёӘж¶Ҳиҙ№иҖ…еҗҢж—¶ж¶Ҳиҙ№ж•°жҚ®пјҢжҸҗй«ҳдәҶж¶ҲжҒҜзҡ„еӨ„зҗҶж•ҲзҺҮгҖӮ
зҶҹжӮүиҙҹиҪҪеқҮиЎЎзҡ„жңӢеҸӢеә”иҜҘзҹҘйҒ“пјҢеҪ“жҲ‘们еҗ‘жҹҗдёӘжңҚеҠЎеҷЁеҸ‘йҖҒиҜ·жұӮзҡ„ж—¶еҖҷпјҢжңҚеҠЎз«ҜеҸҜиғҪдјҡеҜ№иҜ·жұӮеҒҡдёҖдёӘиҙҹиҪҪпјҢе°ҶжөҒйҮҸеҲҶеҸ‘еҲ°дёҚеҗҢзҡ„жңҚеҠЎеҷЁпјҢйӮЈеңЁ kafka дёӯпјҢеҰӮжһңжҹҗдёӘ topic жңүеӨҡдёӘ partitionпјҢproducer еҸҲжҖҺд№ҲзҹҘйҒ“иҜҘе°Ҷж•°жҚ®еҸ‘еҫҖе“ӘдёӘ partition е‘ўпјҹkafka дёӯжңүеҮ дёӘеҺҹеҲҷпјҡ
йёҝи’ҷе®ҳж–№жҲҳз•ҘеҗҲдҪңе…ұе»әвҖ”вҖ”HarmonyOSжҠҖжңҜзӨҫеҢә
partition еңЁеҶҷе…Ҙзҡ„ж—¶еҖҷеҸҜд»ҘжҢҮе®ҡйңҖиҰҒеҶҷе…Ҙзҡ„ partitionпјҢеҰӮжһңжңүжҢҮе®ҡпјҢеҲҷеҶҷе…ҘеҜ№еә”зҡ„ partitionпјӣ
еҰӮжһңжІЎжңүжҢҮе®ҡ partitionпјҢдҪҶжҳҜи®ҫзҪ®дәҶж•°жҚ®зҡ„ keyпјҢеҲҷдјҡж №жҚ® key зҡ„еҖј hash еҮәдёҖдёӘ partitionпјӣ
еҰӮжһңж—ўжІЎжҢҮе®ҡ partitionпјҢеҸҲжІЎжңүи®ҫзҪ® keyпјҢеҲҷдјҡиҪ®иҜўйҖүеҮәдёҖдёӘ partitionпјӣ
6.1.3. дҝқиҜҒж¶ҲжҒҜдёҚдёў
дҝқиҜҒж¶ҲжҒҜдёҚдёўеӨұжҳҜдёҖдёӘж¶ҲжҒҜйҳҹеҲ—дёӯй—ҙ件зҡ„еҹәжң¬дҝқиҜҒпјҢйӮЈ producer еңЁеҗ‘ kafka еҶҷе…Ҙж¶ҲжҒҜзҡ„ж—¶еҖҷпјҢ жҖҺд№ҲдҝқиҜҒж¶ҲжҒҜдёҚдёўеӨұе‘ў пјҹе…¶е®һдёҠйқўзҡ„еҶҷе…ҘжөҒзЁӢеӣҫдёӯжңүжҸҸиҝ°еҮәжқҘпјҢ йӮЈе°ұжҳҜйҖҡиҝҮ ACK еә”зӯ”жңәеҲ¶пјҒеңЁз”ҹдә§иҖ…еҗ‘йҳҹеҲ—еҶҷе…Ҙж•°жҚ®зҡ„ж—¶еҖҷеҸҜд»Ҙи®ҫзҪ®еҸӮж•°жқҘзЎ®е®ҡжҳҜеҗҰзЎ®и®Ө kafka жҺҘ收еҲ°ж•°жҚ®пјҢиҝҷдёӘеҸӮж•°еҸҜи®ҫзҪ®зҡ„еҖјдёә 0гҖҒ1гҖҒall гҖӮ
0 д»ЈиЎЁ producer еҫҖйӣҶзҫӨеҸ‘йҖҒж•°жҚ®дёҚйңҖиҰҒзӯүеҲ°йӣҶзҫӨзҡ„иҝ”еӣһпјҢдёҚзЎ®дҝқж¶ҲжҒҜеҸ‘йҖҒжҲҗеҠҹгҖӮе®үе…ЁжҖ§жңҖдҪҺдҪҶжҳҜж•ҲзҺҮжңҖй«ҳгҖӮ
1 д»ЈиЎЁ producer еҫҖйӣҶзҫӨеҸ‘йҖҒж•°жҚ®еҸӘиҰҒ leader еә”зӯ”е°ұеҸҜд»ҘеҸ‘йҖҒдёӢдёҖжқЎпјҢеҸӘзЎ®дҝқ leader еҸ‘йҖҒжҲҗеҠҹгҖӮ
all д»ЈиЎЁ producer еҫҖйӣҶзҫӨеҸ‘йҖҒж•°жҚ®йңҖиҰҒжүҖжңүзҡ„ follower йғҪе®ҢжҲҗд»Һ leader зҡ„еҗҢжӯҘжүҚдјҡеҸ‘йҖҒдёӢдёҖжқЎпјҢзЎ®дҝқ leader еҸ‘йҖҒжҲҗеҠҹе’ҢжүҖжңүзҡ„еүҜжң¬йғҪе®ҢжҲҗеӨҮд»ҪгҖӮе®үе…ЁжҖ§жңҖй«ҳпјҢдҪҶжҳҜж•ҲзҺҮжңҖдҪҺгҖӮ
жңҖеҗҺиҰҒжіЁж„Ҹзҡ„жҳҜпјҢеҰӮжһңеҫҖдёҚеӯҳеңЁзҡ„ topic еҶҷж•°жҚ®пјҢиғҪдёҚиғҪеҶҷе…ҘжҲҗеҠҹе‘ўпјҹkafka дјҡиҮӘеҠЁеҲӣе»ә topicпјҢеҲҶеҢәе’ҢеүҜжң¬зҡ„ж•°йҮҸж №жҚ®й»ҳи®Өй…ҚзҪ®йғҪжҳҜ 1гҖӮ
Producer е°Ҷж•°жҚ®еҶҷе…Ҙ kafka еҗҺпјҢйӣҶзҫӨе°ұйңҖиҰҒеҜ№ж•°жҚ®иҝӣиЎҢдҝқеӯҳдәҶпјҒkafka е°Ҷж•°жҚ®дҝқеӯҳеңЁзЈҒзӣҳпјҢеҸҜиғҪеңЁжҲ‘们зҡ„дёҖиҲ¬зҡ„и®ӨзҹҘйҮҢпјҢеҶҷе…ҘзЈҒзӣҳжҳҜжҜ”иҫғиҖ—ж—¶зҡ„ж“ҚдҪңпјҢдёҚйҖӮеҗҲиҝҷз§Қй«ҳ并еҸ‘зҡ„组件гҖӮKafka еҲқе§ӢдјҡеҚ•зӢ¬ејҖиҫҹдёҖеқ—зЈҒзӣҳз©әй—ҙпјҢйЎәеәҸеҶҷе…Ҙж•°жҚ®пјҲж•ҲзҺҮжҜ”йҡҸжңәеҶҷе…Ҙй«ҳпјүгҖӮ
6.2.1. Partition з»“жһ„
еүҚйқўиҜҙиҝҮдәҶжҜҸдёӘ topic йғҪеҸҜд»ҘеҲҶдёәдёҖдёӘжҲ–еӨҡдёӘ partitionпјҢеҰӮжһңдҪ и§үеҫ— topic жҜ”иҫғжҠҪиұЎпјҢйӮЈ partition е°ұжҳҜжҜ”иҫғе…·дҪ“зҡ„дёңиҘҝдәҶпјҒPartition еңЁжңҚеҠЎеҷЁдёҠзҡ„иЎЁзҺ°еҪўејҸе°ұжҳҜдёҖдёӘдёҖдёӘзҡ„ж–Ү件еӨ№пјҢжҜҸдёӘ partition зҡ„ж–Ү件еӨ№дёӢйқўдјҡжңүеӨҡз»„ segment ж–Ү件пјҢжҜҸз»„ segment ж–Ү件еҸҲеҢ…еҗ« .index ж–Ү件гҖҒ.log ж–Ү件гҖҒ.timeindex ж–Ү件пјҲж—©жңҹзүҲжң¬дёӯжІЎжңүпјүдёүдёӘж–Ү件пјҢ log ж–Ү件е°ұе®һйҷ…жҳҜеӯҳеӮЁ message зҡ„ең°ж–№пјҢиҖҢ index е’Ң timeindex ж–Ү件дёәзҙўеј•ж–Ү件пјҢз”ЁдәҺжЈҖзҙўж¶ҲжҒҜгҖӮ

еҰӮдёҠеӣҫпјҢиҝҷдёӘ partition жңүдёүз»„ segment ж–Ү件пјҢжҜҸдёӘ log ж–Ү件зҡ„еӨ§е°ҸжҳҜдёҖж ·зҡ„пјҢдҪҶжҳҜеӯҳеӮЁзҡ„ message ж•°йҮҸжҳҜдёҚдёҖе®ҡзӣёзӯүзҡ„пјҲжҜҸжқЎзҡ„ message еӨ§е°ҸдёҚдёҖиҮҙпјүгҖӮж–Ү件зҡ„е‘ҪеҗҚжҳҜд»ҘиҜҘ segment жңҖе°Ҹ offset жқҘе‘ҪеҗҚзҡ„пјҢеҰӮ 000.index еӯҳеӮЁ offset дёә 0~368795 зҡ„ж¶ҲжҒҜпјҢ kafka е°ұжҳҜеҲ©з”ЁеҲҶж®ө+зҙўеј•зҡ„ж–№ејҸжқҘи§ЈеҶіжҹҘжүҫж•ҲзҺҮзҡ„й—®йўҳ гҖӮ
6.2.2. Messageз»“жһ„
дёҠйқўиҜҙеҲ° log ж–Ү件е°ұе®һйҷ…жҳҜеӯҳеӮЁ message зҡ„ең°ж–№пјҢжҲ‘们еңЁ producer еҫҖ kafka еҶҷе…Ҙзҡ„д№ҹжҳҜдёҖжқЎдёҖжқЎзҡ„ messageпјҢйӮЈеӯҳеӮЁеңЁ log дёӯзҡ„ message жҳҜд»Җд№Ҳж ·еӯҗзҡ„е‘ўпјҹж¶ҲжҒҜдё»иҰҒеҢ…еҗ«ж¶ҲжҒҜдҪ“гҖҒж¶ҲжҒҜеӨ§е°ҸгҖҒoffsetгҖҒеҺӢзј©зұ»еһӢ...жҲ‘们йҮҚзӮ№йңҖиҰҒзҹҘйҒ“зҡ„жҳҜдёӢйқўдёүдёӘпјҡ
йёҝи’ҷе®ҳж–№жҲҳз•ҘеҗҲдҪңе…ұе»әвҖ”вҖ”HarmonyOSжҠҖжңҜзӨҫеҢә
offset пјҡoffset жҳҜдёҖдёӘеҚ 8byte зҡ„жңүеәҸ id еҸ·пјҢе®ғеҸҜд»Ҙе”ҜдёҖзЎ®е®ҡжҜҸжқЎж¶ҲжҒҜеңЁ parition еҶ…зҡ„дҪҚзҪ®пјӣ
ж¶ҲжҒҜеӨ§е°Ҹ пјҡж¶ҲжҒҜеӨ§е°ҸеҚ з”Ё 4byteпјҢз”ЁдәҺжҸҸиҝ°ж¶ҲжҒҜзҡ„еӨ§е°Ҹпјӣ
ж¶ҲжҒҜдҪ“ пјҡж¶ҲжҒҜдҪ“еӯҳж”ҫзҡ„жҳҜе®һйҷ…зҡ„ж¶ҲжҒҜж•°жҚ®пјҲиў«еҺӢзј©иҝҮпјүпјҢеҚ з”Ёзҡ„з©әй—ҙж №жҚ®е…·дҪ“зҡ„ж¶ҲжҒҜиҖҢдёҚдёҖж ·гҖӮ
6.2.3. еӯҳеӮЁзӯ–з•Ҙ
ж— и®әж¶ҲжҒҜжҳҜеҗҰиў«ж¶Ҳиҙ№пјҢkafka йғҪдјҡдҝқеӯҳжүҖжңүзҡ„ж¶ҲжҒҜгҖӮйӮЈеҜ№дәҺж—§ж•°жҚ®жңүд»Җд№ҲеҲ йҷӨзӯ–з•Ҙе‘ўпјҹ
еҹәдәҺж—¶й—ҙ пјҢй»ҳи®Өй…ҚзҪ®жҳҜ 168 е°Ҹж—¶пјҲ7еӨ©пјүпјӣ
еҹәдәҺеӨ§е°Ҹ пјҢй»ҳи®Өй…ҚзҪ®жҳҜ 1073741824гҖӮ
йңҖиҰҒжіЁж„Ҹзҡ„жҳҜпјҢ kafka иҜ»еҸ–зү№е®ҡж¶ҲжҒҜзҡ„ж—¶й—ҙеӨҚжқӮеәҰжҳҜ O(1) O ( 1 ) пјҢжүҖд»ҘиҝҷйҮҢеҲ йҷӨиҝҮжңҹзҡ„ж–Ү件并дёҚдјҡжҸҗй«ҳ kafka зҡ„жҖ§иғҪ пјҒ
ж¶ҲжҒҜеӯҳеӮЁеңЁ log ж–Ү件еҗҺпјҢж¶Ҳиҙ№иҖ…е°ұеҸҜд»ҘиҝӣиЎҢж¶Ҳиҙ№дәҶгҖӮеңЁи®Іж¶ҲжҒҜйҳҹеҲ—йҖҡдҝЎзҡ„дёӨз§ҚжЁЎејҸзҡ„ж—¶еҖҷи®ІеҲ°иҝҮзӮ№еҜ№зӮ№жЁЎејҸе’ҢеҸ‘еёғи®ўйҳ…жЁЎејҸгҖӮKafka йҮҮз”Ёзҡ„жҳҜеҸ‘еёғи®ўйҳ…жЁЎејҸпјҢж¶Ҳиҙ№иҖ…дё»еҠЁзҡ„еҺ» kafka йӣҶзҫӨжӢүеҸ–ж¶ҲжҒҜпјҢдёҺ producer зӣёеҗҢзҡ„жҳҜпјҢж¶Ҳиҙ№иҖ…еңЁжӢүеҸ–ж¶ҲжҒҜзҡ„ж—¶еҖҷд№ҹжҳҜжүҫ leader еҺ»жӢүеҸ– гҖӮ
еӨҡдёӘж¶Ҳиҙ№иҖ…еҸҜд»Ҙз»„жҲҗдёҖдёӘж¶Ҳиҙ№иҖ…з»„пјҲconsumer groupпјүпјҢжҜҸдёӘж¶Ҳиҙ№иҖ…з»„йғҪжңүдёҖдёӘз»„ idпјҒеҗҢдёҖдёӘж¶Ҳиҙ№з»„иҖ…зҡ„ж¶Ҳиҙ№иҖ…еҸҜд»Ҙж¶Ҳиҙ№еҗҢдёҖ topic дёӢдёҚеҗҢеҲҶеҢәзҡ„ж•°жҚ®пјҢдҪҶжҳҜдёҚдјҡз»„еҶ…еӨҡдёӘж¶Ҳиҙ№иҖ…ж¶Ҳиҙ№еҗҢдёҖеҲҶеҢәзҡ„ж•°жҚ®пјҒжҲ‘们зңӢдёӢеӣҫпјҡ
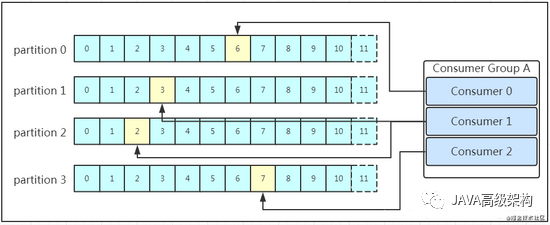
еӣҫзӨәжҳҜж¶Ҳиҙ№иҖ…з»„еҶ…зҡ„ж¶Ҳиҙ№иҖ…е°ҸдәҺ partition ж•°йҮҸзҡ„жғ…еҶөпјҢжүҖд»ҘдјҡеҮәзҺ°жҹҗдёӘж¶Ҳиҙ№иҖ…ж¶Ҳиҙ№еӨҡдёӘ partition ж•°жҚ®зҡ„жғ…еҶөпјҢж¶Ҳиҙ№зҡ„йҖҹеәҰд№ҹе°ұдёҚеҸҠеҸӘеӨ„зҗҶдёҖдёӘ partition зҡ„ж¶Ҳиҙ№иҖ…зҡ„еӨ„зҗҶйҖҹеәҰпјҒ еҰӮжһңжҳҜж¶Ҳиҙ№иҖ…з»„зҡ„ж¶Ҳиҙ№иҖ…еӨҡдәҺ partition зҡ„ж•°йҮҸпјҢйӮЈдјҡдёҚдјҡеҮәзҺ°еӨҡдёӘж¶Ҳиҙ№иҖ…ж¶Ҳиҙ№еҗҢдёҖдёӘ partition зҡ„ж•°жҚ®е‘ў пјҹдёҠйқўе·Із»ҸжҸҗеҲ°иҝҮдёҚдјҡеҮәзҺ°иҝҷз§Қжғ…еҶөпјҒ еӨҡеҮәжқҘзҡ„ж¶Ҳиҙ№иҖ…дёҚж¶Ҳиҙ№д»»дҪ• partition зҡ„ж•°жҚ® гҖӮ жүҖд»ҘеңЁе®һйҷ…зҡ„еә”з”ЁдёӯпјҢе»әи®®ж¶Ҳиҙ№иҖ…з»„зҡ„ consumer зҡ„ж•°йҮҸдёҺ partition зҡ„ж•°йҮҸдёҖиҮҙ пјҒ
еңЁдҝқеӯҳж•°жҚ®зҡ„е°ҸиҠӮйҮҢйқўпјҢжҲ‘们иҒҠеҲ°дәҶ partition еҲ’еҲҶдёәеӨҡз»„ segmentпјҢжҜҸдёӘ segment еҸҲеҢ…еҗ« .logгҖҒ.indexгҖҒ.timeindex ж–Ү件пјҢеӯҳж”ҫзҡ„жҜҸжқЎ message еҢ…еҗ« offsetгҖҒж¶ҲжҒҜеӨ§е°ҸгҖҒж¶ҲжҒҜдҪ“……жҲ‘们еӨҡж¬ЎжҸҗеҲ° segment е’Ң offsetпјҢжҹҘжүҫж¶ҲжҒҜзҡ„ж—¶еҖҷжҳҜжҖҺд№ҲеҲ©з”Ё segment+offset й…ҚеҗҲжҹҘжүҫзҡ„е‘ўпјҹеҒҮеҰӮзҺ°еңЁйңҖиҰҒжҹҘжүҫдёҖдёӘ offset дёә 368801 зҡ„ message жҳҜд»Җд№Ҳж ·зҡ„иҝҮзЁӢе‘ўпјҹжҲ‘们е…ҲзңӢзңӢдёӢйқўзҡ„еӣҫпјҡ
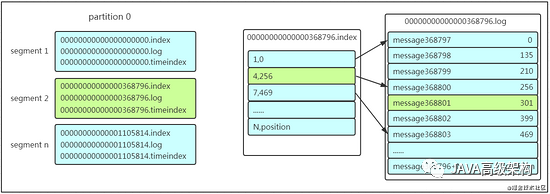
1. е…ҲжүҫеҲ° offset зҡ„ 368801 message жүҖеңЁзҡ„ segment ж–Ү件пјҲеҲ©з”ЁдәҢеҲҶжі•жҹҘжүҫпјүпјҢиҝҷйҮҢжүҫеҲ°зҡ„е°ұжҳҜеңЁз¬¬дәҢдёӘ segment ж–Ү件гҖӮ
2. жү“ејҖжүҫеҲ°зҡ„ segment дёӯзҡ„ .index ж–Ү件пјҲд№ҹе°ұжҳҜ 368796.index ж–Ү件пјҢиҜҘж–Ү件иө·е§ӢеҒҸ移йҮҸдёә 368796+1пјҢжҲ‘们иҰҒжҹҘжүҫзҡ„ offset дёә 368801 зҡ„ message еңЁиҜҘ index еҶ…зҡ„еҒҸ移йҮҸдёә 368796+5=368801пјҢжүҖд»ҘиҝҷйҮҢиҰҒжҹҘжүҫзҡ„зӣёеҜ№ offset дёә 5пјүгҖӮз”ұдәҺиҜҘж–Ү件йҮҮз”Ёзҡ„жҳҜзЁҖз–Ҹзҙўеј•зҡ„ж–№ејҸеӯҳеӮЁзқҖзӣёеҜ№ offset еҸҠеҜ№еә” message зү©зҗҶеҒҸ移йҮҸзҡ„е…ізі»пјҢжүҖд»ҘзӣҙжҺҘжүҫзӣёеҜ№ offset дёә 5 зҡ„зҙўеј•жүҫдёҚеҲ°пјҢиҝҷйҮҢеҗҢж ·еҲ©з”ЁдәҢеҲҶжі•жҹҘжүҫзӣёеҜ№ offset е°ҸдәҺжҲ–иҖ…зӯүдәҺжҢҮе®ҡзҡ„зӣёеҜ№ offset зҡ„зҙўеј•жқЎзӣ®дёӯжңҖеӨ§зҡ„йӮЈдёӘзӣёеҜ№ offsetпјҢжүҖд»ҘжүҫеҲ°зҡ„жҳҜзӣёеҜ№ offsetдёә 4 зҡ„иҝҷдёӘзҙўеј•гҖӮ
3. ж №жҚ®жүҫеҲ°зҡ„зӣёеҜ№ offset дёә 4 зҡ„зҙўеј•зЎ®е®ҡ message еӯҳеӮЁзҡ„зү©зҗҶеҒҸ移дҪҚзҪ®дёә 256гҖӮжү“ејҖж•°жҚ®ж–Ү件пјҢд»ҺдҪҚзҪ®дёә 256 зҡ„йӮЈдёӘең°ж–№ејҖе§ӢйЎәеәҸжү«жҸҸзӣҙеҲ°жүҫеҲ° offset дёә 368801 зҡ„йӮЈжқЎ MessageгҖӮ
иҝҷеҘ—жңәеҲ¶жҳҜе»әз«ӢеңЁ offset дёәжңүеәҸзҡ„еҹәзЎҖдёҠпјҢеҲ©з”Ё segment+жңүеәҸoffset+зЁҖз–Ҹзҙўеј•+дәҢеҲҶжҹҘжүҫ+йЎәеәҸжҹҘжүҫ зӯүеӨҡз§ҚжүӢж®өжқҘй«ҳж•Ҳзҡ„жҹҘжүҫж•°жҚ®гҖӮиҮіжӯӨпјҢж¶Ҳиҙ№иҖ…е°ұиғҪжӢҝеҲ°йңҖиҰҒеӨ„зҗҶзҡ„ж•°жҚ®иҝӣиЎҢеӨ„зҗҶдәҶгҖӮйӮЈжҜҸдёӘж¶Ҳиҙ№иҖ…еҸҲжҳҜжҖҺд№Ҳи®°еҪ•иҮӘе·ұж¶Ҳиҙ№зҡ„дҪҚзҪ®е‘ўпјҹеңЁж—©жңҹзҡ„зүҲжң¬дёӯпјҢж¶Ҳиҙ№иҖ…е°Ҷж¶Ҳиҙ№еҲ°зҡ„ offset з»ҙжҠӨ zookeeper дёӯпјҢconsumer жҜҸй—ҙйҡ”дёҖж®өж—¶й—ҙдёҠжҠҘдёҖж¬ЎпјҢиҝҷйҮҢе®№жҳ“еҜјиҮҙйҮҚеӨҚж¶Ҳиҙ№пјҢдё”жҖ§иғҪдёҚеҘҪпјҒеңЁж–°зҡ„зүҲжң¬дёӯж¶Ҳиҙ№иҖ…ж¶Ҳиҙ№еҲ°зҡ„ offset е·Із»ҸзӣҙжҺҘз»ҙжҠӨеңЁkafka йӣҶзҫӨзҡ„ consumer_offsets иҝҷдёӘ topic дёӯдәҶгҖӮ
еҲ°жӯӨпјҢе…ідәҺвҖңKafkaеҹәжң¬жЎҶжһ¶жҳҜд»Җд№ҲвҖқзҡ„еӯҰд№ е°ұз»“жқҹдәҶпјҢеёҢжңӣиғҪеӨҹи§ЈеҶіеӨ§е®¶зҡ„з–‘жғ‘гҖӮзҗҶи®әдёҺе®һи·өзҡ„жҗӯй…ҚиғҪжӣҙеҘҪзҡ„её®еҠ©еӨ§е®¶еӯҰд№ пјҢеҝ«еҺ»иҜ•иҜ•еҗ§пјҒиӢҘжғіз»§з»ӯеӯҰд№ жӣҙеӨҡзӣёе…ізҹҘиҜҶпјҢиҜ·з»§з»ӯе…іжіЁдәҝйҖҹдә‘зҪ‘з«ҷпјҢе°Ҹзј–дјҡ继з»ӯеҠӘеҠӣдёәеӨ§е®¶еёҰжқҘжӣҙеӨҡе®һз”Ёзҡ„ж–Үз« пјҒ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ