您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
这篇文章将为大家详细讲解有关Fork跟Join原理是什么,文章内容质量较高,因此小编分享给大家做个参考,希望大家阅读完这篇文章后对相关知识有一定的了解。

只听到P8大佬不急不慢问道:谈谈对JDK并发工具的认识?
我开始仔细梳理多年的并发八股文经验,道:
线程池、Future、CompletableFuture和CompletionService这些并发工具都是帮助SE站在任务角度解决并发问题,而非纠结于线程之间协作的细节,比如线程之间如何实现等待、通知。
简单并行任务
线程池+Future 组合拳
任务间有聚合关系
AND、OR聚合,CompletableFuture 一招鲜
批量的并行任务
CompletionService 一把梭
并发编程可分为三个层面问题:分工、协作、互斥。
当关注于任务时,你会发现你的视角已跃出并发编程细节,而使用现实世界思维模式,类比现实世界的分工,其实线程池、Future、CompletableFuture和CompletionService都可列为分工问题。
简单并行任务、聚合任务和批量并行任务的现实的工作流程图
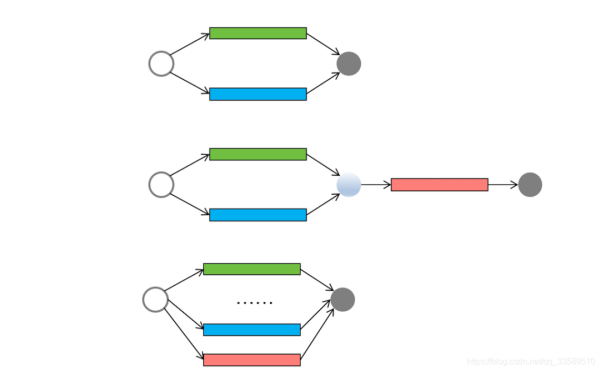
这三种任务模型,基本覆盖日常工作中的并发场景,但其实还有一种“分治”任务模型。
分治,分而治之,一种解决复杂问题的思维方法和模式。把一个复杂问题分解成多个相似的子问题,然后再把子问题分解成更小的子问题,直到子问题简单到可以直接求解。理论上解决每一个问题都对应着一个任务,所以对于问题的分治,实际上就是对于任务的分治。
P8 大佬直接开问,那你说说什么是分治任务模型?
分治任务模型可分为两个阶段:
任务分解
将任务迭代地分解为子任务,直至子任务可计算出结果。将地区具体事务分属各个地方行政官。
结果合并
逐层合并子任务的执行结果,直至获得最终结果。各地方行政官最终将治理成果汇报上级。
就像官僚制度一样:
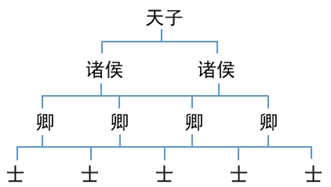
那你平时开发是如何使用Fork/Join的?
我,我平时还真没通过啊,就背过。还好这道题,我面试前也准备了…
Fork/Join是一个并行计算框架,以支持分治任务模型
Fork对应分治任务模型里的任务分解
Join对应结果合并
Fork/Join计算框架主要包含两部分:
分治任务的线程池ForkJoinPool
分治任务ForkJoinTask
这俩的关系类似于 ThreadPoolExecutor 和 Runnable,都是提交任务到线程池,只不过分治任务有自己独特的任务类型ForkJoinTask。
ForkJoinTask
JDK7 提供,一个抽象类,核心方法如下:
fork()
异步执行一个子任务
join()
阻塞当前线程来等待子任务的执行结果
ForkJoinTask有两个子类——RecursiveAction和RecursiveTask,显然都是用递归处理分治任务。这两个子类都定义了抽象方法compute():
RecursiveAction#compute()无返回值

RecursiveTask#compute()有返回值
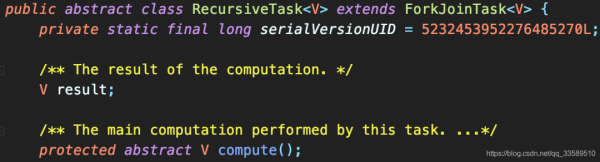
注意到这俩类都是抽象类,使用要定义子类实现。
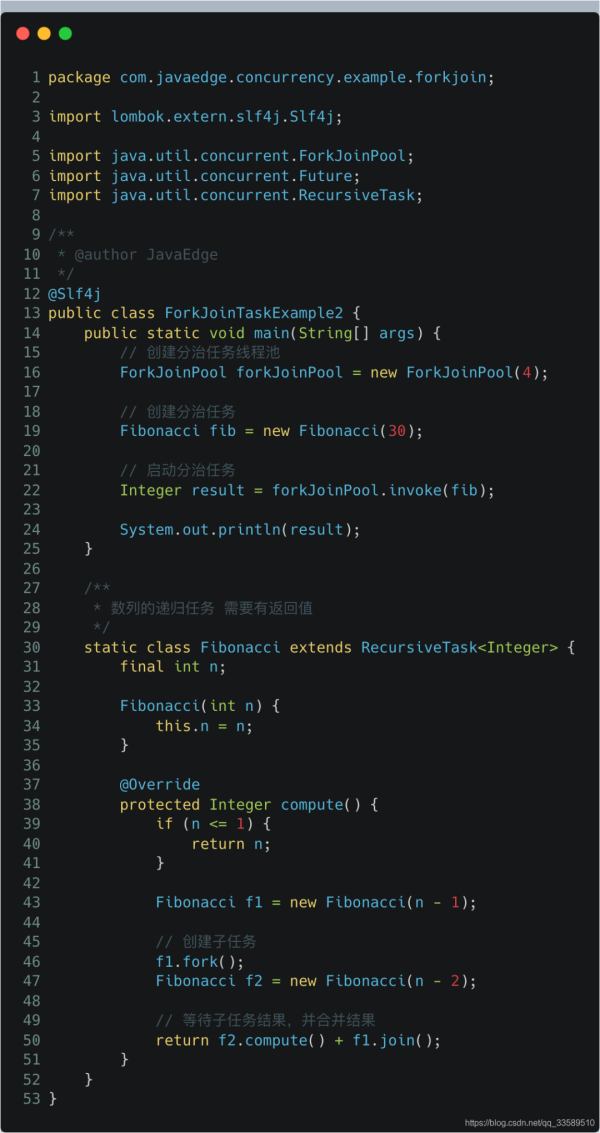
只见 P8 开始冷笑,看来要问源码级别原理了!
那你说下Fork/Join的工作原理
还好我知道阿里面试套路,凡是 java 工具,必问深入的源码。
因为Fork/Join的核心就是ForkJoinPool,让我来深入讲解ForkJoinPool原理。
ThreadPoolExecutor本质是个生产者-消费者实现,内部有一个任务队列,作为生产者和消费者的通信媒介。ThreadPoolExecutor可以有多个工作线程,这些工作线程都共享一个任务队列。
ForkJoinPool本质上也是一个生产者-消费者的实现,但更智能
ForkJoinPool工作原理图
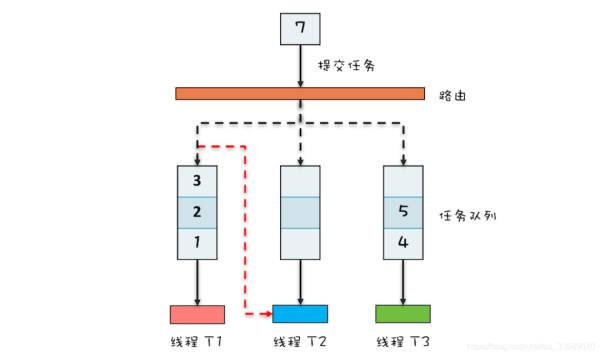
ThreadPoolExecutor内部只有一个任务队列,而ForkJoinPool内部有多个任务队列,当调用ForkJoinPool#invoke()或submit()提交任务时,ForkJoinPool把任务通过路由规则提交到一个任务队列,如果任务在执行过程中会创建出子任务,那么子任务会提交到工作线程对应的任务队列。
如果工作线程对应的任务队列空,是不是就没活儿干了?
No!ForkJoinPool有个“任务窃取”机制,若工作线程空闲了,它会“窃取”其他工作任务队列里的任务,例如刚才那个图中,线程T2对应任务队列已空
那它会“窃取”线程T1对应的任务队列的任务。这样所有工作线程都不会闲着。
ForkJoinPool的任务队列采用的是双端队列,工作线程正常获取任务和“窃取任务”分别从任务队列不同的端消费,这也能避免很多不必要的数据竞争。
ForkJoinPool支持任务窃取机制,能够让所有线程的工作量基本公平,不会出现线程有的很忙,有的一直在摸鱼,所以性能很好,是个很公正的领导。
Java8的Stream API里面并行流也是基于ForkJoinPool。
默认,所有的并行流计算都共享一个ForkJoinPool,这个共享的ForkJoinPool的默认线程数是CPU核数;
若所有并行流计算都是CPU密集型,完全没有问题,但若存在I/O密集型并行流计算,那很可能因为一个很慢的I/O计算而拖慢整个系统的性能。所以建议用不同ForkJoinPool执行不同类型的计算任务。
关于Fork跟Join原理是什么就分享到这里了,希望以上内容可以对大家有一定的帮助,可以学到更多知识。如果觉得文章不错,可以把它分享出去让更多的人看到。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。