您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
这篇文章主要介绍“Python怎么实现多线程的事件监控”,在日常操作中,相信很多人在Python怎么实现多线程的事件监控问题上存在疑惑,小编查阅了各式资料,整理出简单好用的操作方法,希望对大家解答”Python怎么实现多线程的事件监控”的疑惑有所帮助!接下来,请跟着小编一起来学习吧!
设想这样一个场景:
你创建了10个子线程,每个子线程分别爬一个网站,一开始所有子线程都是阻塞等待。一旦某个事件发生:例如有人在网页上点了一个按钮,或者某人在命令行输入了一个命令,10个爬虫同时开始工作。
肯定有人会想到用Redis来实现这个开关:所有子线程全部监控Redis中名为start_crawl的字符串,如果这个字符串不存在,或者为0,那么就等待1秒钟,再继续检查。如果这个字符串为1,那么就开始运行。
代码片段可以简写为:
import time import redis client = redis.Redis() while client.get('start_crawl') != 1: print('继续等待') time.sleep(1)这样做确实可以达到目的,不过每一个子线程都会频繁检查Redis。
实际上,在Python的多线程中,有一个Event模块,天然就是用来实现这个目的的。
Event是一个能在多线程中共用的对象,一开始它包含一个为False的信号标志,一旦在任一一个线程里面把这个标记改为True,那么所有的线程都会看到这个标记变成了True。
我们通过一段代码来说明它的使用方法:
import threading import time class spider(threading.Thread): def __init__(self, n, event): super().__init__() self.n = n self.event = event def run(self): print(f'第{self.n}号爬虫已就位!') self.event.wait() print(f'信号标记变为True!!第{self.n}号爬虫开始运行') eve = threading.Event() for num in range(10): crawler = spider(num, eve) crawler.start() input('按下回车键,启动所有爬虫!') eve.set() time.sleep(10)运行效果如下图所示:
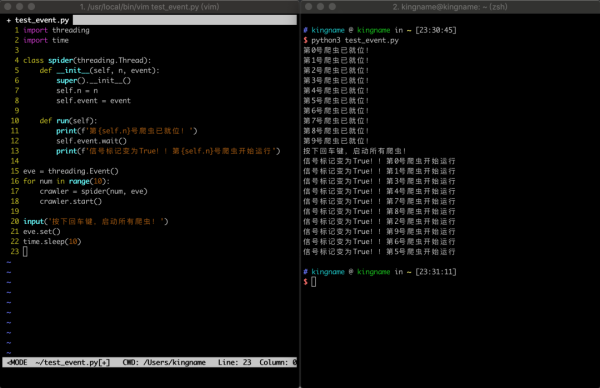
在这段代码中,线程spider在运行以后,会运行到self.event.wait()这一行,然后10个子线程会全部阻塞在这里。而这里的self.event,就是主线程中eve = threading.Event()生成的对象传入进去的。
在主线程里面,当执行了eve.set()后,所有子线程的阻塞会被同时解除,于是子线程就可以继续运行了。
到此,关于“Python怎么实现多线程的事件监控”的学习就结束了,希望能够解决大家的疑惑。理论与实践的搭配能更好的帮助大家学习,快去试试吧!若想继续学习更多相关知识,请继续关注亿速云网站,小编会继续努力为大家带来更多实用的文章!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。