您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
如何使用Python网络爬虫实现起点小说下载,针对这个问题,这篇文章详细介绍了相对应的分析和解答,希望可以帮助更多想解决这个问题的小伙伴找到更简单易行的方法。
今天要跟大家分享一个小说爬取案例--------起点小说的小说下载。
在做这个案例之前,我们需要对其进行分析,
1.界面分析,如图:
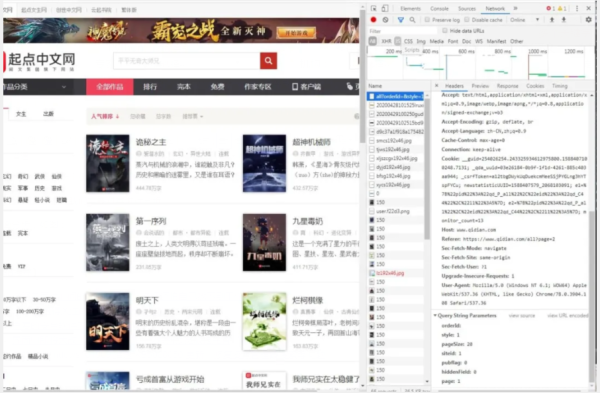
通过分析很容易就找到了我们的get请求参数,然后获取相应页面的小说名和链接:
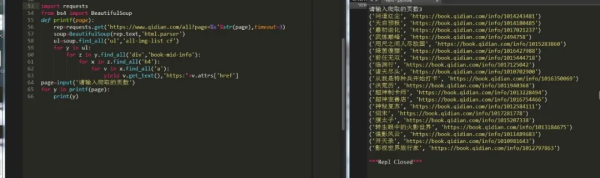
获取到数据之后,我们就随机挑选一篇小说来进行下载,我们选第一篇,

然后打开它的文章目录,可以看到是这样的,如图:
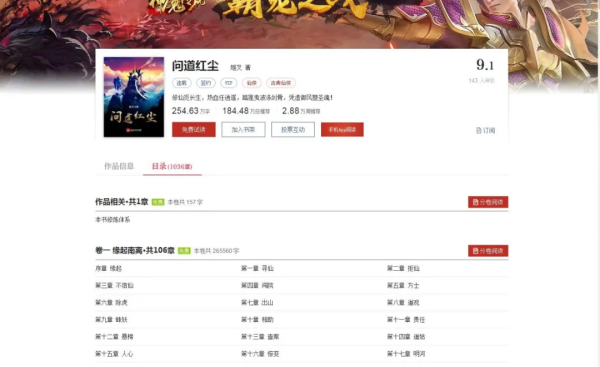
基本上这篇小说很长,可以看到它卷一和卷二是免费的,后面的收费,那么今天我们就只爬免费的章节。
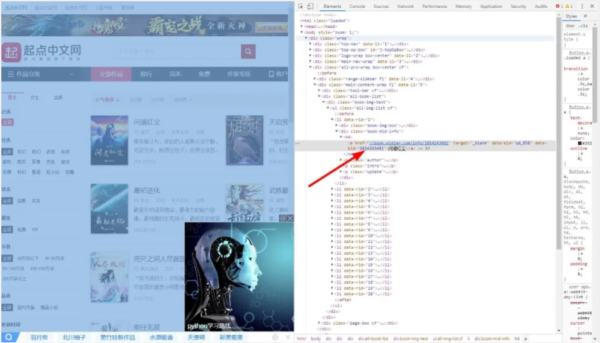
那么我们现在开始分析网页结构,如图:
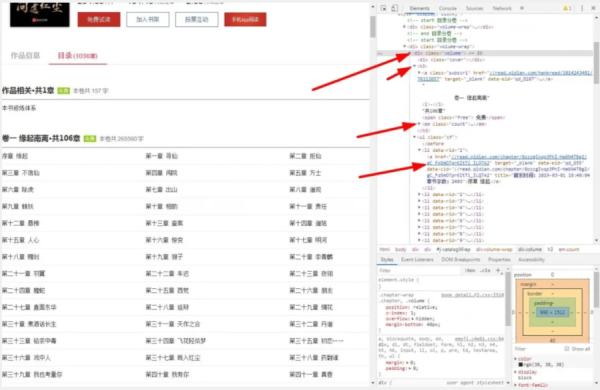
那么,我们可以先把卷一的名字和章节数以及章节下的每个章节的名字都打印出来。
首先我们可以分析下这个网页地址,如图:
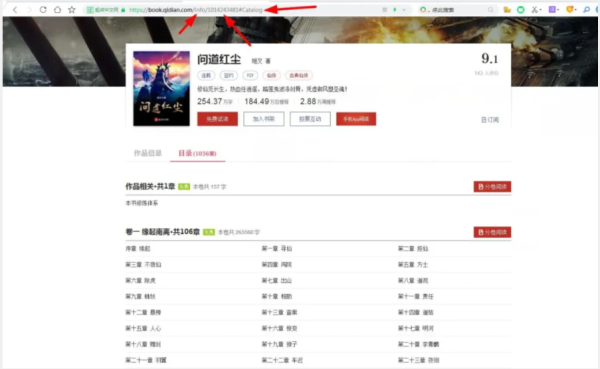
https://book.qidian.com/info/1014243481#Catalog
发觉前面的没变,基本就是后面的变了,增加了一个info/1014243481#Catalog,下面开始分析:
info:信息的意思,
1014243481:小说对应的ID,
#Catalog:数据补全,无太大意义
因为刚刚已经将文章链接的内容爬取出来,所以现在只需要拼接一个#Catalog 即可:

下面我们就可以对它发起请求然后在分析它的页面了,首先发起get请求,按照前面的网页分析结构来看,我们应该这样写:
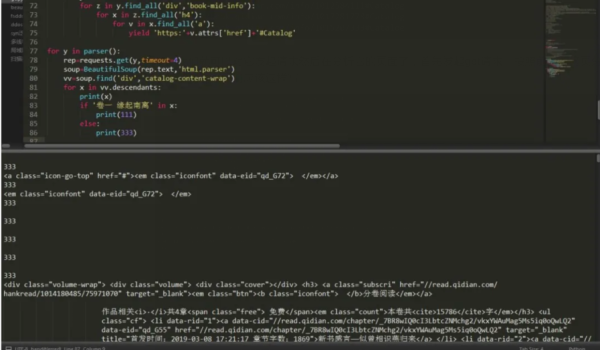
可以看出,因为这里有异步加载,所以我们的请求不会一下子全部显示出来,需要不断的请求,当然最好加个延迟。
这样我们就获取到了这个页面所有的小说,也可以这样,因为我们没找接口,所以强行解析只能解析部分内容,但是也很全面了。如图:
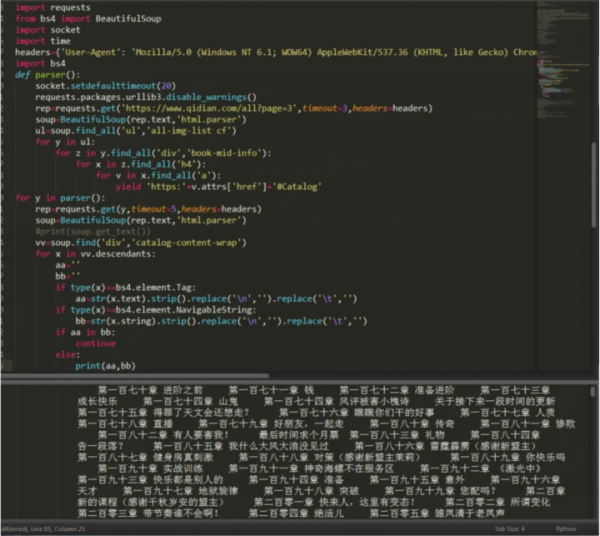
找的还算挺详细,只不过没有找接口时所拿到的数据那么规范好看了。
关于如何使用Python网络爬虫实现起点小说下载问题的解答就分享到这里了,希望以上内容可以对大家有一定的帮助,如果你还有很多疑惑没有解开,可以关注亿速云行业资讯频道了解更多相关知识。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。