жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
жң¬зҜҮеҶ…е®№д»Ӣз»ҚдәҶвҖңд»Җд№ҲжҳҜиө«еӨ«жӣјзј–з ҒвҖқзҡ„жңүе…ізҹҘиҜҶпјҢеңЁе®һйҷ…жЎҲдҫӢзҡ„ж“ҚдҪңиҝҮзЁӢдёӯпјҢдёҚе°‘дәәйғҪдјҡйҒҮеҲ°иҝҷж ·зҡ„еӣ°еўғпјҢжҺҘдёӢжқҘе°ұи®©е°Ҹзј–еёҰйўҶеӨ§е®¶еӯҰд№ дёҖдёӢеҰӮдҪ•еӨ„зҗҶиҝҷдәӣжғ…еҶөеҗ§пјҒеёҢжңӣеӨ§е®¶д»”з»Ҷйҳ…иҜ»пјҢиғҪеӨҹеӯҰжңүжүҖжҲҗпјҒ
иө«еӨ«жӣјзј–з Ғд№ҹзҝ»иҜ‘дёә(е“ҲеӨ«жӣјзј–з Ғ)Huffman CodingпјҢеҸҲз§°дёәйңҚеӨ«жӣјзј–з ҒпјҢжҳҜдёҖз§Қзј–з Ғж–№ејҸпјҢеұһдәҺдёҖз§ҚзЁӢеәҸз®—жі•гҖӮ
иө«еӨ«жӣјзј–з ҒжҳҜиө«еӨ«жӣјж ‘еңЁз”өи®ҜйҖҡи®Ҝдёӯзҡ„з»Ҹе…ёзҡ„еә”з”ЁеңәжҷҜд№ӢдёҖгҖӮ
иө«еӨ«жӣјзј–з Ғе№ҝжіӣзҡ„з”ЁдәҺж•°жҚ®ж–Ү件еҺӢзј©гҖӮе…¶еҺӢзј©зҺҮйҖҡеёёеңЁ20%~90%д№Ӣй—ҙгҖӮ
иө«еӨ«жӣјз ҒжҳҜеҸҜеҸҳеӯ—й•ҝзј–з Ғ(VLC)зҡ„дёҖз§Қ.HufuumanдәҺ1952е№ҙжҸҗеҮәдёҖз§Қзј–з Ғж–№жі•пјҢз§°д№ӢдёәжңҖдҪізј–з ҒгҖӮ
еҰӮ: i like like like java do you like a java е…ұ40дёӘеӯ—з¬ҰпјҢеҢ…жӢ¬з©әж јпјҢе…¶еҜ№еә”зҡ„ASCIIз Ғ,дёҺдәҢиҝӣеҲ¶зј–з ҒеҰӮдёӢеӣҫ

жҢүз…§дәҢиҝӣеҲ¶жқҘдј йҖ’дҝЎжҒҜпјҢжҖ»зҡ„й•ҝеәҰжҳҜ359(еҢ…еҗ«з©әж ј)
i like like like java do you like a java е…ұ40дёӘеӯ—з¬ҰпјҢеҢ…жӢ¬з©әж јгҖӮеҸҳй•ҝзј–з ҒеӨ„зҗҶеҰӮдёӢеӣҫ

еӯ—з¬Ұзҡ„зј–з ҒйғҪдёҚиғҪжҳҜе…¶д»–еӯ—з¬Ұзј–з Ғзҡ„еүҚзјҖпјҢз¬ҰеҗҲжӯӨиҰҒжұӮзҡ„зј–з ҒеҸ«еҒҡеүҚзјҖзј–з ҒпјҢеҚідёҚиғҪеҢ№й…ҚеҲ°йҮҚеӨҚзҡ„зј–з ҒгҖӮ
i like like like java do you like a java е…ұ40дёӘеӯ—з¬ҰпјҢеҢ…жӢ¬з©әж јгҖӮеҸҳй•ҝзј–з ҒеӨ„зҗҶеҰӮдёӢеӣҫ

жҢүз…§дёҠйқўеӯ—з¬ҰеҮәзҺ°зҡ„ж¬Ўж•°жһ„е»әдёҖйў—иө«еӨ«жӣјж ‘пјҢж¬Ўж•°дҪңдёәжқғеҖјгҖӮ
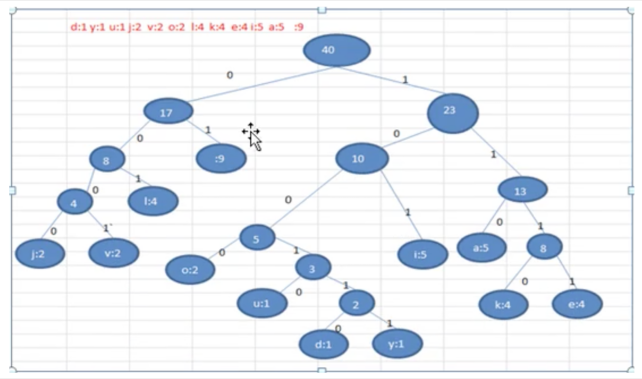
ж №жҚ®иө«еӨ«жӣјж ‘пјҢз»ҷеҗ„дёӘеӯ—з¬ҰпјҢ规е®ҡзј–з Ғ(еүҚзјҖзј–з Ғ),еҗ‘е·Ұзҡ„и·Ҝеҫ„дёә0 еҗ‘еҸізҡ„и·Ҝеҫ„дёә1пјҡзј–з ҒеҰӮдёӢпјҡ
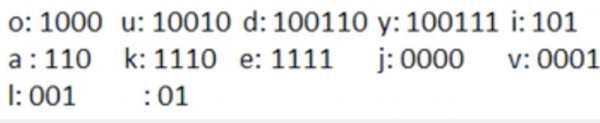
жҢүз…§дёҠйқўзҡ„иө«еӨ«жӣјзј–з ҒпјҢжҲ‘们зҡ„"i like like like java do you like a java" еӯ—з¬ҰдёІеҜ№еә”зҡ„зј–з Ғ(жіЁж„ҸиҝҷйҮҢжҲ‘们дҪҝз”Ёзҡ„ж— жҚҹеҺӢзј©)еҰӮдёӢеӣҫгҖӮ

еҺҹжқҘзҡ„й•ҝеәҰжҳҜ359пјҢеҺӢзј©дәҶ(359-133)/359=62.9%
жӯӨзј–з Ғж»Ўи¶іеүҚзјҖзј–з ҒпјҢеҚіеӯ—з¬Ұзҡ„зј–з ҒйғҪдёҚиғҪжҳҜе…¶д»–еӯ—з¬Ұзј–з Ғзҡ„еүҚзјҖгҖӮдёҚдјҡйҖ жҲҗеҢ№й…Қзҡ„еӨҡд№үжҖ§гҖӮ
иө«еӨ«жӣјзј–з ҒжҳҜж— жҚҹеҺӢзј©!!
иҝҷдёӘиө«еӨ«жӣјж ‘ж №жҚ®жҺ’еәҸж–№жі•дёҚеҗҢпјҢд№ҹеҸҜиғҪдёҚдёҖж ·пјҢиҝҷж ·еҜ№еә”зҡ„иө«еӨ«жӣјзј–з Ғд№ҹдёҚе®Ңе…ЁдёҖж ·пјҢдҪҶжҳҜwplжҳҜдёҖж ·зҡ„пјҢйғҪжҳҜжңҖе°Ҹзҡ„пјҢжҜ”еҰӮжҲ‘们让жҜҸж¬Ўз”ҹжҲҗзҡ„ж–°зҡ„дәҢеҸүж ‘жҖ»жҳҜжҺ’еңЁжқғеҖјзӣёеҗҢзҡ„дәҢеҸүж ‘зҡ„жңҖеҗҺдёҖдёӘпјҢеҲҷз”ҹжҲҗзҡ„дәҢеҸүж ‘дёәпјҡ
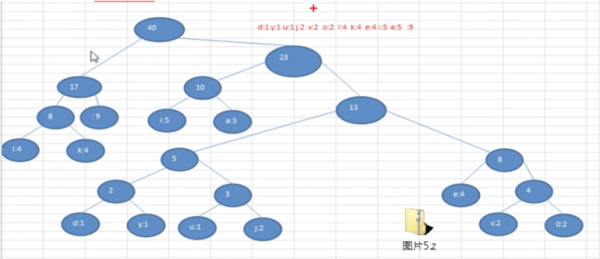
ж №жҚ®иө«еӨ«жӣјзј–з ҒеҺӢзј©ж•°жҚ®зҡ„еҺҹзҗҶпјҢйңҖиҰҒеҲӣе»ә"i like like like java do you like a java" еҜ№еә”зҡ„иө«еӨ«жӣјж ‘
е…ҲеҲӣе»әNodeиҠӮзӮ№пјҢNode {data{еӯҳж”ҫж•°жҚ®}пјҢweight(жқғеҖј),left,right};
еҫ—еҲ°"i like like like java do you like a java" еҜ№еә”зҡ„byte[] ж•°з»„;
зј–еҶҷдёҖдёӘж–№жі•пјҢе°ҶеҮҶеӨҮжһ„е»әиө«еӨ«жӣјж ‘зҡ„nodeиҠӮзӮ№ж”ҫеҲ°List
еҸҜд»ҘйҖҡиҝҮйӣҶеҗҲList
е°ҶдёҖдёІеӯ—з¬ҰдёІиҝӣиЎҢеҺӢзј©дёҺи§ЈеҺӢзј©
package com.xie.huffmancode; import java.util.*; public class HuffmanCode { public static void main(String[] args) { String str = "i like like like java do you like a java"; byte[] contentBytes = str.getBytes(); System.out.println("contentBytes=" + Arrays.toString(contentBytes)); List<Node> nodes = getNodes(contentBytes); //з”ҹжҲҗиө«еӨ«жӣјж ‘ Node hufffmanTreeRoot = createHufffmanTree(nodes); //з”ҹжҲҗзҡ„иө«еӨ«жӣјзј–з ҒиЎЁ getCodes(hufffmanTreeRoot, "", stringBuilder); byte[] huffmanCodeBytes = zip(contentBytes, huffmanCodes); System.out.println("huffmanCodeBytes = " + Arrays.toString(huffmanCodeBytes)); byte[] decode = decode(huffmanCodes, huffmanCodeBytes); System.out.println("иө«еӨ«жӣји§Јз ҒеҗҺеҜ№еә”зҡ„ж•°з»„" + new String(decode)); /** * contentBytes=[105, 32, 108, 105, 107, 101, 32, 108, 105, 107, 101, 32, 108, 105, 107, 101, 32, 106, 97, 118, 97, 32, 100, 111, 32, 121, 111, 117, 32, 108, 105, 107, 101, 32, 97, 32, 106, 97, 118, 97] * huffmanCodeBytes = [-88, -65, -56, -65, -56, -65, -55, 77, -57, 6, -24, -14, -117, -4, -60, -90, 28] * иө«еӨ«жӣји§Јз ҒеҗҺеҜ№еә”зҡ„ж•°з»„i like like like java do you like a java */ } //е®ҢжҲҗж•°жҚ®зҡ„и§ЈеҺӢжҖқи·Ҝ //1.е°ҶhuffmanCodeBytes[-88, -65, -56, -65, -56, -65, -55, 77, -57, 6, -24, -14, -117, -4, -60, -90, 28] // йҮҚж–°иҪ¬жҲҗ иө«еӨ«жӣјзј–з ҒеҜ№еә”зҡ„дәҢиҝӣеҲ¶еӯ—з¬ҰдёІ"101010001011111111001000101111...." //2.иө«еӨ«жӣјзј–з ҒеҜ№еә”зҡ„дәҢиҝӣеҲ¶еӯ—з¬ҰдёІ"101010001011111111001000101111...." => еҜ№з…§иө«еӨ«жӣјзј–з ҒиЎЁ => "i like like like java do you like a java" /** * е®ҢжҲҗеҜ№еҺӢзј©ж•°жҚ®зҡ„и§Јз Ғ * * @param huffmanCodes иө«еӨ«жӣјзј–з ҒиЎЁ * @param huffmanBytes иө«еӨ«жӣјзј–з Ғеҫ—еҲ°зҡ„еӯ—иҠӮж•°з»„ * @return еҺҹжқҘзҡ„еӯ—з¬ҰдёІеҜ№еә”зҡ„ж•°з»„ */ public static byte[] decode(Map<Byte, String> huffmanCodes, byte[] huffmanBytes) { StringBuilder stringBuilder = new StringBuilder(); for (int i = 0; i < huffmanBytes.length; i++) { //еҲӨж–ӯжҳҜдёҚжҳҜжңҖеҗҺдёҖдёӘеӯ—иҠӮ boolean flag = (i == huffmanBytes.length - 1); stringBuilder.append(byteToBitString(!flag, huffmanBytes[i])); } Map<String, Byte> map = new HashMap<>(); for (Map.Entry<Byte, String> entry : huffmanCodes.entrySet()) { Byte k = entry.getKey(); String v = entry.getValue(); map.put(v, k); } List<Byte> list = new ArrayList<>(); for (int i = 0; i < stringBuilder.length();) { int count = 1; boolean flag = true; Byte b = null; while (flag) { String key = stringBuilder.substring(i, i + count);//i дёҚеҠЁпјҢcount移еҠЁпјҢзӣҙеҲ°еҢ№й…ҚдёҖдёӘеӯ—з¬Ұ b = map.get(key); if (b == null) { count++; } else { flag = false; } } list.add(b); i += count; } byte[] bytes = new byte[list.size()]; for (int i = 0; i < list.size(); i++) { bytes[i] = list.get(i); } return bytes; } /** * е°ҶдёҖдёӘbyte иҪ¬жҲҗдёҖдёӘдәҢиҝӣеҲ¶зҡ„еӯ—з¬ҰдёІ * * @param flag ж ҮиҜҶжҳҜеҗҰйңҖиҰҒиЎҘй«ҳдҪҚпјҢtrueж ҮиҜҶйңҖиҰҒиЎҘй«ҳдҪҚ,еҰӮжһңжҳҜfalseиЎЁзӨәдёҚиЎҘпјҢеҰӮжһңжҳҜжңҖеҗҺдёҖдёӘеӯ—иҠӮпјҢж— йңҖиЎҘй«ҳдҪҚ * @param b дј е…Ҙзҡ„byte * @return иҜҘbyteеҜ№еә”зҡ„дәҢиҝӣеҲ¶еӯ—з¬ҰдёІпјҢпјҲжіЁж„ҸжҳҜжҢүиЎҘз Ғиҝ”еӣһ) */ public static String byteToBitString(boolean flag, byte b) { //е°Ҷb иҪ¬жҲҗ int int temp = b; //еҰӮжһңtempжҳҜжӯЈж•°иҝҳйңҖиҰҒиЎҘй«ҳдҪҚ if (flag) { // жҢүдҪҚжҲ– еҰӮ 256|1=> 1 0000 0000|0000 0001 => 1 0000 0001 temp |= 256; } //иҝ”еӣһзҡ„жҳҜtempдәҢиҝӣеҲ¶зҡ„иЎҘз Ғ String bitStr = Integer.toBinaryString(temp); if (flag) { //еҸ–еҗҺ8дҪҚ return bitStr.substring(bitStr.length() - 8); } else { return bitStr; } } /** * е°ҒиЈ…еҺҹе§Ӣеӯ—иҠӮж•°з»„иҪ¬иө«еӨ«жӣјеӯ—иҠӮж•°з»„ * * @param bytes * @return */ public static byte[] huffmanZip(byte[] bytes) { List<Node> nodes = getNodes(bytes); //еҲӣе»әиө«еӨ«жӣјж ‘ Node hufffmanTreeRoot = createHufffmanTree(nodes); //з”ҹжҲҗиө«еӨ«жӣјзј–з Ғ getCodes(hufffmanTreeRoot, "", stringBuilder); //иҝ”еӣһеҺӢзј©еҗҺзҡ„иө«еӨ«жӣјзј–з Ғеӯ—иҠӮж•°з»„ return zip(bytes, huffmanCodes); } /** * е°Ҷеӯ—з¬ҰдёІеҜ№еә”зҡ„byte[] ж•°з»„пјҢйҖҡиҝҮиө«еӨ«жӣјзј–з ҒиЎЁпјҢиҝ”еӣһдёҖдёӘиө«еӨ«жӣјзј–з ҒеҺӢзј©еҗҺзҡ„byte[] * * @param bytes еҺҹе§Ӣеӯ—з¬ҰдёІеҜ№еә”зҡ„byte[] * @param huffmanCodes з”ҹжҲҗзҡ„иө«еӨ«жӣјзј–з Ғ * @return иҝ”еӣһиө«еӨ«жӣјзј–з ҒеӨ„зҗҶеҗҺзҡ„byte[] */ public static byte[] zip(byte[] bytes, Map<Byte, String> huffmanCodes) { //еҲ©з”ЁhuffmanCodes е°Ҷ bytes иҪ¬жҲҗиө«еӨ«жӣјзј–з ҒеҜ№еә”зҡ„еӯ—з¬ҰдёІ StringBuilder stringBuilder = new StringBuilder(); for (byte b : bytes) { stringBuilder.append(huffmanCodes.get(b)); } // е°Ҷ"101010001011111111001000101111...." иҪ¬жҲҗbyte[] // з»ҹи®Ўиҝ”еӣһbyte[] huffmanCodeBytes й•ҝеәҰ int len; if (stringBuilder.length() % 8 == 0) { len = stringBuilder.length() / 8; } else { len = stringBuilder.length() / 8 + 1; } //еҲӣе»ә еӯҳеӮЁеҺӢзј©еҗҺзҡ„byte[]ж•°з»„ byte[] huffmanCodeBytes = new byte[len]; int index = 0; for (int i = 0; i < stringBuilder.length(); i += 8) { String strByte; if (i + 8 > stringBuilder.length()) { strByte = stringBuilder.substring(i); } else { strByte = stringBuilder.substring(i, i + 8); } //е°ҶstrByte иҪ¬жҲҗдёҖдёӘbyte ,ж”ҫе…ҘеҲ°huffmanCodeBytes huffmanCodeBytes[index] = (byte) Integer.parseInt(strByte, 2); index++; } return huffmanCodeBytes; } //з”ҹжҲҗиө«еӨ«жӣјж ‘еҜ№еә”зҡ„иө«еӨ«жӣјзј–з ҒиЎЁ //жҖқи·Ҝпјҡ //1. е°Ҷиө«еӨ«жӣјзј–з ҒиЎЁеӯҳж”ҫеңЁMap<Byte,String>,еҪўејҸеҰӮ32->01,97->100... static Map<Byte, String> huffmanCodes = new HashMap<>(); //2. еңЁз”ҹжҲҗиө«еӨ«жӣјзј–з ҒиЎЁж—¶пјҢйңҖиҰҒжӢјжҺҘи·Ҝеҫ„пјҢе®ҡд№үдёҖдёӘStringBuilder еӯҳеӮЁжҹҗдёӘеҸ¶еӯҗиҠӮзӮ№зҡ„и·Ҝеҫ„ static StringBuilder stringBuilder = new StringBuilder(); /** * е°Ҷдј е…Ҙзҡ„node иҠӮзӮ№зҡ„жүҖжңүеҸ¶еӯҗзҡ„иө«еӨ«жӣјзј–з Ғеҫ—еҲ°пјҢ并ж”ҫе…ҘhuffmanCodesйӣҶеҗҲ * * @param node дј е…ҘиҠӮзӮ№ * @param code и·Ҝеҫ„пјҡе·ҰеӯҗиҠӮзӮ№жҳҜ0пјҢеҸіеӯҗиҠӮзӮ№жҳҜ1 * @param stringBuilder з”ЁдәҺжӢјжҺҘи·Ҝеҫ„ */ public static void getCodes(Node node, String code, StringBuilder stringBuilder) { StringBuilder stringBuilder2 = new StringBuilder(stringBuilder); stringBuilder2.append(code); if (node != null) { //еҲӨж–ӯеҪ“еүҚnode жҳҜеҸ¶еӯҗиҠӮзӮ№иҝҳжҳҜйқһеҸ¶еӯҗиҠӮзӮ№ if (node.data == null) {//йқһеҸ¶еӯҗиҠӮзӮ№ //еҗ‘е·ҰйҖ’еҪ’еӨ„зҗҶ getCodes(node.left, "0", stringBuilder2); //еҗ‘еҸійҖ’еҪ’еӨ„зҗҶ getCodes(node.right, "1", stringBuilder2); } else {//еҸ¶еӯҗиҠӮзӮ№ huffmanCodes.put(node.data, stringBuilder2.toString()); } } } //еүҚеәҸйҒҚеҺҶ public static void preOrder(Node root) { if (root != null) { root.preOrder(); } else { System.out.println("иө«еӨ«жӣјж ‘дёҚиғҪдёәз©ә~~"); } } /** * е°Ҷеӯ—иҠӮж•°з»„иҪ¬жҲҗnodeйӣҶеҗҲ * * @param bytes еӯ—иҠӮж•°з»„ * @return */ public static List<Node> getNodes(byte[] bytes) { ArrayList<Node> nodes = new ArrayList<>(); //еӯҳеӮЁжҜҸдёӘbyteеҮәзҺ°зҡ„ж¬Ўж•° Map<Byte, Integer> counts = new HashMap<>(); for (byte b : bytes) { counts.merge(b, 1, (a, b1) -> a + b1); } //жҠҠжҜҸдёӘй”®еҖјеҜ№иҪ¬жҲҗдёҖдёӘnodeеҜ№иұЎпјҢ并еҠ е…ҘеҲ°nodes йӣҶеҗҲ counts.forEach((k, v) -> nodes.add(new Node(k, v))); return nodes; } /** * з”ҹжҲҗиө«еӨ«жӣјж ‘ * @param nodes дј е…Ҙзҡ„иҠӮзӮ№ * @return */ public static Node createHufffmanTree(List<Node> nodes) { while (nodes.size() > 1) { //жҺ’еәҸпјҢд»Һе°ҸеҲ°еӨ§ Collections.sort(nodes); //(1)еҸ–еҮәжқғеҖјжңҖе°Ҹзҡ„иҠӮзӮ№(дәҢеҸүж ‘) Node leftNode = nodes.get(0); //(2) еҸ–еҮәжқғеҖјз¬¬дәҢе°Ҹзҡ„иҠӮзӮ№(дәҢеҸүж ‘) Node rightNode = nodes.get(1); //(3) жһ„е»әдёҖйў—ж–°зҡ„дәҢеҸүж ‘ Node parent = new Node(null, leftNode.weight + rightNode.weight); parent.left = leftNode; parent.right = rightNode; //(4) д»ҺArrayListдёӯеҲ йҷӨеӨ„зҗҶиҝҮзҡ„дәҢеҸүж ‘ nodes.remove(leftNode); nodes.remove(rightNode); //(5) е°ҶparentеҠ е…Ҙnodes nodes.add(parent); } //nodes зҡ„жңҖеҗҺдёҖдёӘе°ұжҳҜиө«еӨ«жӣјж ‘зҡ„rootиҠӮзӮ№ return nodes.get(0); } } //еҲӣе»әNodeпјҢеёҰж•°жҚ®е’ҢжқғеҖј class Node implements Comparable<Node> { //еӯҳж”ҫж•°жҚ®жң¬иә«,жҜ”еҰӮ'a'=>'97'пјҢ' ' =>'32' Byte data; //жқғеҖјпјҢиЎЁзӨәеӯ—з¬ҰеҮәзҺ°зҡ„ж¬Ўж•° int weight; Node left; Node right; public Node(Byte data, int weight) { this.data = data; this.weight = weight; } public void preOrder() { System.out.println(this); if (this.left != null) { this.left.preOrder(); } if (this.right != null) { this.right.preOrder(); } } @Override public int compareTo(Node o) { //д»Һе°ҸеҲ°еӨ§жҺ’еәҸ return this.weight - o.weight; } @Override public String toString() { return "Node{" + "data=" + data + ", weight=" + weight + '}'; } }еҰӮжһңж–Ү件жң¬иә«е°ұз»ҸиҝҮеҺӢзј©еӨ„зҗҶзҡ„пјҢйӮЈд№ҲдҪҝз”Ёиө«еӨ«жӣјзј–з ҒеҶҚеҺӢзј©ж•ҲзҺҮдёҚдјҡжңүжҳҺжҳҫзҡ„еҸҳеҢ–пјҢжҜ”еҰӮи§Ҷйў‘пјҢpptзӯүж–Ү件гҖӮ
иө«еӨ«жӣјзј–з ҒжҳҜжҢүеӯ—иҠӮжқҘеӨ„зҗҶзҡ„пјҢеӣ жӯӨеҸҜд»ҘеӨ„зҗҶжүҖжңүзҡ„ж–Ү件(дәҢиҝӣеҲ¶ж–Ү件пјҢж–Үжң¬ж–Ү件)
еҰӮжһңдёҖдёӘж–Ү件дёӯзҡ„еҶ…е®№пјҢйҮҚеӨҚзҡ„ж•°жҚ®дёҚеӨҡпјҢеҺӢзј©ж•Ҳжһңд№ҹдёҚдјҡжҳҺжҳҫгҖӮ
вҖңд»Җд№ҲжҳҜиө«еӨ«жӣјзј–з ҒвҖқзҡ„еҶ…е®№е°ұд»Ӣз»ҚеҲ°иҝҷйҮҢдәҶпјҢж„ҹи°ўеӨ§е®¶зҡ„йҳ…иҜ»гҖӮеҰӮжһңжғідәҶи§ЈжӣҙеӨҡиЎҢдёҡзӣёе…ізҡ„зҹҘиҜҶеҸҜд»Ҙе…іжіЁдәҝйҖҹдә‘зҪ‘з«ҷпјҢе°Ҹзј–е°ҶдёәеӨ§е®¶иҫ“еҮәжӣҙеӨҡй«ҳиҙЁйҮҸзҡ„е®һз”Ёж–Үз« пјҒ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ