您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
初因是给宝宝制作拼音卡点读包时,要下载卖家提供给的MP3,大概有2百多个。作为一个会码代码的非专业人士,怎么可能取一个一个下载?所以就决定用python 的 scrapy 框架写个爬虫,去下载这些MP3。一开始以为简单,直到完成下载,竟然花了我一下午的时间。最大的难题就是页面的数据是通过javascript 脚本动态渲染的。百度上大部分方法都是通过splash 做中转实现的方法,而我只是想简单的写个代码实现而已,看splash还要挂docker,巴啦巴啦一大堆的操作,顿时就心塞了。通过百度和自己实践,终于找到了一个最简单的方法解决了问题,特此记录下来,同大家分享一下。
先开始分析目标html
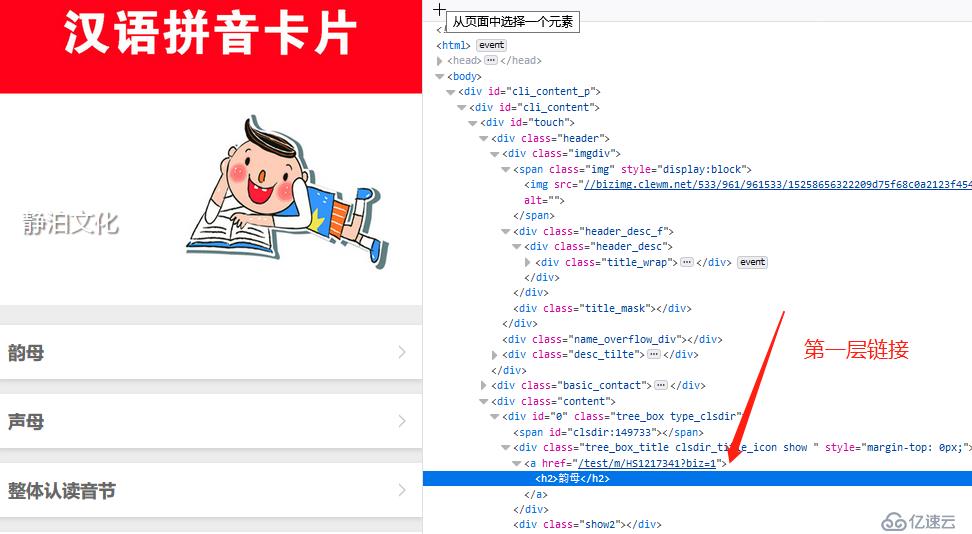
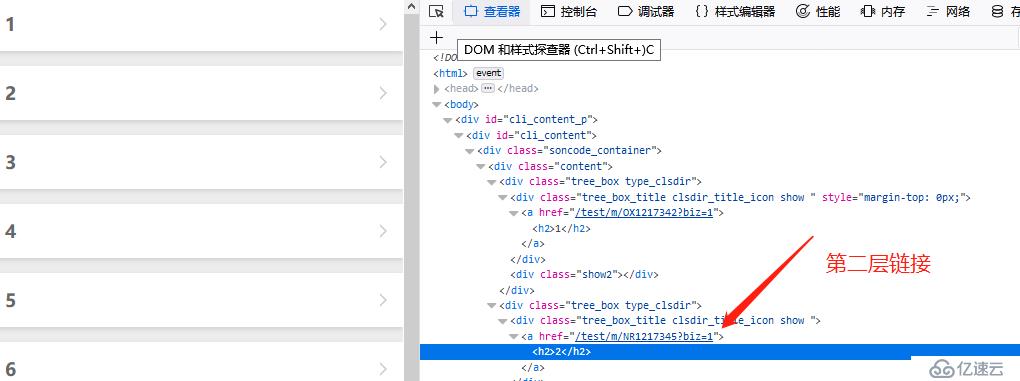
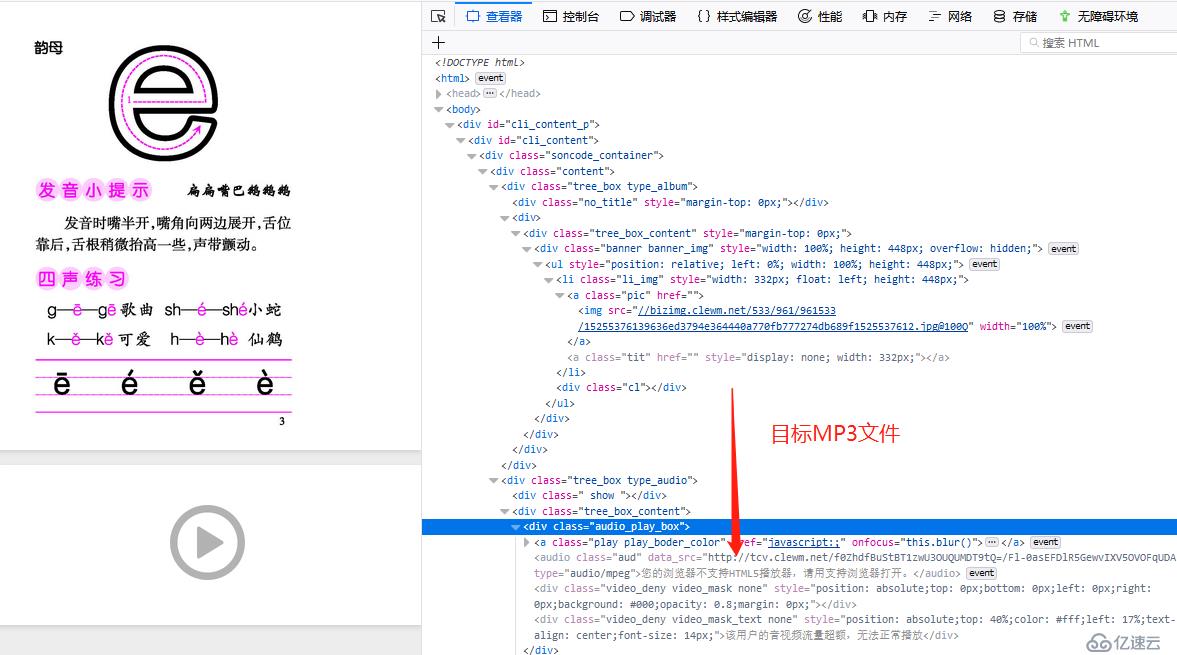
看着简单吧,可一爬取,问题立马就出现了,curl下静态页看看。
curl -s https://biz.cli.im/test/CI525711?stime=2 >111.html
首页竟是这样的,页面的列表数据,是通过javascript 动态渲染的。

是个json 数据,再格式化后分析下,页面link 都在data 这个json数据里了。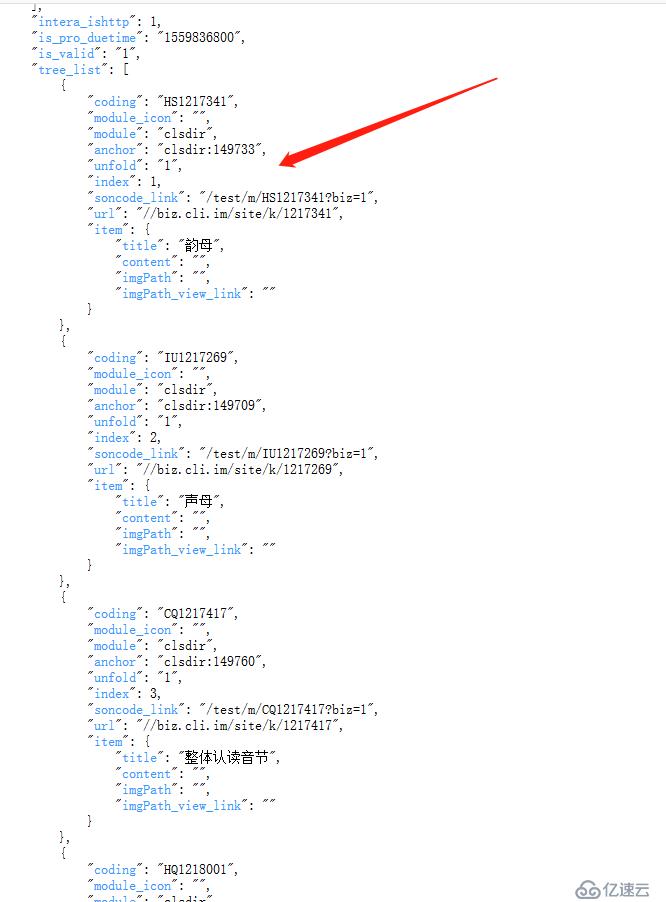
最基础的response.xpath 方式是不能用了,我的思路是把scripts 获取出来,然后用获取soncode_link 的值。
经过研究决定用 BeautifulSoup + js2xml
class JingboSpider(scrapy.Spider):
name = 'jingbo'
allowed_domains = ['biz.cli.im']
all_urls= "https://biz.cli.im"
start_urls = ['test/CI525711?stime=2']
def start_requests(self):
#自定义headers
for url in self.start_urls:
yield scrapy.Request(self.all_urls+"/"+url, headers={"User-Agent": USER_AGENT})
def parse(self, response):
resp = response.text
# 用lxml作为解析器 ,解析返回数据
soup = BeautifulSoup(resp,'lxml')
# 获取所有script 标签数据,并遍历查找
scripts = soup.find_all('script')
for script in scripts:
if type(script.string) is type(None):
continue
if script.string.find("loadtemp();") > 0:
src=script
break
title="title"
link="soncode_link"
# 将js 数据转化为 xml 标签树格式
src_text = js2xml.parse(src.string, encoding='utf-8',debug=False)
src_tree = js2xml.pretty_print(src_text)
# print(src_tree)
selector = etree.HTML(src_tree)
links = selector.xpath("//property[@name = '"+link+"']/string/text()")
playurl = selector.xpath("//property[@name = 'play_url']/string/text()")
titles = selector.xpath("//property[@name = '"+title+"']/string/text()")
#剩下就是循环获取页面,下载MP3文件了。
wget https://www.lfd.uci.edu/~gohlke/pythonlibs/Twisted‑18.9.0‑cp37‑cp37m‑win_amd64.whl
wget https://www.lfd.uci.edu/~gohlke/pythonlibs/beautifulsoup4‑4.7.1‑py3‑none‑any.whl
pip install Twisted‑18.9.0‑cp37‑cp37m‑win_amd64.whl
pip install pypiwin32 js2xml urllib2 Scrapy
scrapy startproject pinyin
scrapy genspider jingbo https://biz.cli.im/test/CI525711?stime=2
scrapy crawl jingbo

https://scrapy-chs.readthedocs.io/zh_CN/latest/intro/overview.html
https://www.cnblogs.com/zhaof/p/6930955.html
https://blog.csdn.net/qq_34246164/article/details/80700399
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。