жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
иҝҷзҜҮж–Үз« дё»иҰҒд»Ӣз»ҚStampedLockжҖҺд№Ҳз”ЁпјҢж–Үдёӯд»Ӣз»Қзҡ„йқһеёёиҜҰз»ҶпјҢе…·жңүдёҖе®ҡзҡ„еҸӮиҖғд»·еҖјпјҢж„ҹе…ҙи¶Јзҡ„е°Ҹдјҷдјҙ们дёҖе®ҡиҰҒзңӢе®ҢпјҒ
йқўеҜ№дёҙз•ҢеҢәиө„жәҗз®ЎзҗҶзҡ„й—®йўҳпјҢеӨ§дҪ“дёҠжңү2еҘ—жҖқи·Ҝпјҡ
第дёҖе°ұжҳҜдҪҝз”ЁжӮІи§Ӯзҡ„зӯ–з•ҘпјҢжӮІи§ӮиҖ…иҝҷж ·и®ӨдёәпјҡеңЁжҜҸдёҖж¬Ўи®ҝй—®дёҙз•ҢеҢәзҡ„е…ұдә«еҸҳйҮҸпјҢжҖ»жҳҜжңүдәәдјҡе’ҢжҲ‘еҶІзӘҒпјҢеӣ жӯӨпјҢжҜҸж¬Ўи®ҝй—®жҲ‘еҝ…йЎ»е…Ҳй”ҒдҪҸж•ҙдёӘеҜ№иұЎпјҢе®ҢжҲҗи®ҝй—®еҗҺеҶҚи§Јй”ҒгҖӮ
иҖҢдёҺд№ӢзӣёеҸҚзҡ„д№җеӨ©жҙҫеҚҙи®ӨдёәпјҢиҷҪ然дёҙз•ҢеҢәзҡ„е…ұдә«еҸҳйҮҸдјҡеҶІзӘҒпјҢдҪҶжҳҜеҶІзӘҒеә”иҜҘжҳҜе°ҸжҰӮзҺҮдәӢ件пјҢеӨ§йғЁеҲҶжғ…еҶөдёӢпјҢеә”иҜҘдёҚдјҡеҸ‘з”ҹпјҢжүҖд»ҘпјҢжҲ‘еҸҜд»Ҙе…Ҳи®ҝй—®дәҶеҶҚиҜҙпјҢеҰӮжһңзӯүжҲ‘з”Ёе®ҢдәҶж•°жҚ®иҝҳжІЎдәәеҶІзӘҒпјҢйӮЈд№ҲжҲ‘зҡ„ж“ҚдҪңе°ұжҳҜжҲҗеҠҹ;еҰӮжһңжҲ‘дҪҝз”Ёе®ҢжҲҗеҗҺпјҢеҸ‘зҺ°жңүдәәеҶІзӘҒпјҢйӮЈд№ҲжҲ‘иҰҒд№ҲеҶҚйҮҚиҜ•дёҖж¬ЎпјҢиҰҒд№ҲеҲҮжҚўдёәжӮІи§Ӯзҡ„зӯ–з•ҘгҖӮ

д»ҺиҝҷйҮҢдёҚйҡҫзңӢеҲ°пјҢйҮҚе…Ҙй”Ғд»ҘеҸҠsynchronized жҳҜдёҖз§Қе…ёеһӢзҡ„жӮІи§Ӯзӯ–з•ҘгҖӮиҒӘжҳҺзҡ„дҪ дёҖе®ҡд№ҹзҢңеҲ°дәҶпјҢStampedLockе°ұжҳҜжҸҗдҫӣдәҶдёҖз§Қд№җи§Ӯй”Ғзҡ„е·Ҙе…·пјҢеӣ жӯӨпјҢе®ғжҳҜеҜ№йҮҚе…Ҙй”Ғзҡ„дёҖдёӘйҮҚиҰҒзҡ„иЎҘе……гҖӮ
еңЁStampedLockзҡ„ж–ҮжЎЈдёӯе°ұжҸҗдҫӣдәҶдёҖдёӘйқһеёёеҘҪзҡ„дҫӢеӯҗпјҢи®©жҲ‘们еҸҜд»ҘеҫҲеҝ«зҡ„зҗҶи§ЈStampedLockзҡ„дҪҝз”ЁгҖӮдёӢйқўи®©жҲ‘зңӢдёҖдёӢиҝҷдёӘдҫӢеӯҗпјҢжңүе…іе®ғзҡ„иҜҙжҳҺпјҢйғҪеҶҷеңЁжіЁйҮҠдёӯдәҶгҖӮ
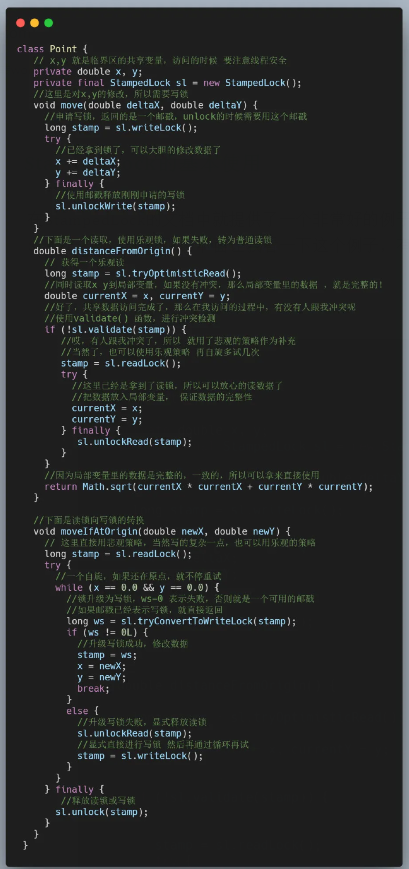
иҝҷйҮҢеҶҚиҜҙжҳҺдёҖдёӢvalidate()ж–№жі•зҡ„еҗ«д№үпјҢеҮҪж•°зӯҫеҗҚй•ҝиҝҷж ·пјҡ
public boolean validate(long stamp)
е®ғзҡ„жҺҘеҸ—еҸӮж•°жҳҜдёҠж¬Ўй”Ғж“ҚдҪңиҝ”еӣһзҡ„йӮ®жҲіпјҢеҰӮжһңеңЁи°ғз”Ёvalidate()д№ӢеүҚпјҢиҝҷдёӘй”ҒжІЎжңүеҶҷй”Ғз”іиҜ·иҝҮпјҢйӮЈе°ұиҝ”еӣһtrueпјҢиҝҷд№ҹиЎЁзӨәй”ҒдҝқжҠӨзҡ„е…ұдә«ж•°жҚ®е№¶жІЎжңүиў«дҝ®ж”№пјҢеӣ жӯӨд№ӢеүҚзҡ„иҜ»еҸ–ж“ҚдҪңжҳҜиӮҜе®ҡиғҪдҝқиҜҒж•°жҚ®е®Ңж•ҙжҖ§е’ҢдёҖиҮҙжҖ§зҡ„гҖӮ
еҸҚд№ӢпјҢеҰӮжһңй”ҒеңЁvalidate()д№ӢеүҚжңүеҶҷй”Ғз”іиҜ·жҲҗеҠҹиҝҮпјҢйӮЈе°ұиЎЁзӨәпјҢд№ӢеүҚзҡ„ж•°жҚ®иҜ»еҸ–е’ҢеҶҷж“ҚдҪңеҶІзӘҒдәҶпјҢзЁӢеәҸйңҖиҰҒиҝӣиЎҢйҮҚиҜ•пјҢжҲ–иҖ…еҚҮзә§дёәжӮІи§Ӯй”ҒгҖӮ
д»ҺдёҠйқўзҡ„дҫӢеӯҗе…¶е®һдёҚйҡҫзңӢеҲ°пјҢе°ұзј–зЁӢеӨҚжқӮеәҰжқҘиҜҙпјҢStampedLockе…¶е®һжҳҜиҰҒжҜ”йҮҚе…Ҙй”ҒеӨҚжқӮзҡ„еӨҡпјҢд»Јз Ғд№ҹжІЎжңүд»ҘеүҚйӮЈд№Ҳз®ҖжҙҒдәҶгҖӮ
жңҖжң¬иҙЁзҡ„еҺҹеӣ пјҢе°ұжҳҜдёәдәҶжҸҗеҚҮжҖ§иғҪ!дёҖиҲ¬жқҘиҜҙпјҢиҝҷз§Қд№җи§Ӯй”Ғзҡ„жҖ§иғҪиҰҒжҜ”жҷ®йҖҡзҡ„йҮҚе…Ҙй”Ғеҝ«еҮ еҖҚпјҢиҖҢдё”йҡҸзқҖзәҝзЁӢж•°йҮҸзҡ„дёҚж–ӯеўһеҠ пјҢжҖ§иғҪзҡ„е·®и·қдјҡи¶ҠжқҘи¶ҠеӨ§гҖӮ
з®ҖиҖҢиЁҖд№ӢпјҢеңЁеӨ§йҮҸ并еҸ‘зҡ„еңәжҷҜдёӯStampedLockзҡ„жҖ§иғҪжҳҜзўҫеҺӢйҮҚе…Ҙй”Ғе’ҢиҜ»еҶҷй”Ғзҡ„гҖӮ
дҪҶжҜ•з«ҹпјҢдё–з•ҢдёҠжІЎжңүеҚҒе…ЁеҚҒзҫҺзҡ„дёңиҘҝпјҢStampedLockд№ҹ并йқһе…ЁиғҪпјҢе®ғзҡ„зјәзӮ№еҰӮдёӢпјҡ
зј–з ҒжҜ”иҫғйә»зғҰпјҢеҰӮжһңдҪҝз”Ёд№җи§ӮиҜ»пјҢйӮЈд№ҲеҶІзӘҒзҡ„еңәжҷҜиҰҒеә”з”ЁиҮӘе·ұеӨ„зҗҶ
е®ғжҳҜдёҚеҸҜйҮҚе…Ҙзҡ„пјҢеҰӮжһңдёҖдёҚе°ҸеҝғеңЁеҗҢдёҖдёӘзәҝзЁӢдёӯи°ғз”ЁдәҶдёӨж¬ЎпјҢйӮЈд№ҲдҪ зҡ„дё–з•Ңе°ұжё…еҮҖдәҶгҖӮгҖӮгҖӮгҖӮгҖӮ
е®ғдёҚж”ҜжҢҒwait/notifyжңәеҲ¶
еҰӮжһңд»ҘдёҠ3зӮ№еҜ№дҪ жқҘиҜҙйғҪдёҚжҳҜй—®йўҳпјҢйӮЈд№ҲжҲ‘зӣёдҝЎStampedLockеә”иҜҘжҲҗдёәдҪ зҡ„йҰ–йҖүгҖӮ
дёәдәҶеё®еҠ©еӨ§е®¶жӣҙеҘҪзҡ„зҗҶи§ЈStampedLockпјҢиҝҷйҮҢеҶҚз®ҖеҚ•з»ҷеӨ§е®¶д»Ӣз»ҚдёҖдёӢе®ғзҡ„еҶ…йғЁе®һзҺ°е’Ңж•°жҚ®з»“жһ„гҖӮ
еңЁStampedLockдёӯпјҢжңүдёҖдёӘйҳҹеҲ—пјҢйҮҢйқўеӯҳж”ҫзқҖзӯүеҫ…еңЁй”ҒдёҠзҡ„зәҝзЁӢгҖӮиҜҘйҳҹеҲ—жҳҜдёҖдёӘй“ҫиЎЁпјҢй“ҫиЎЁдёӯзҡ„е…ғзҙ жҳҜдёҖдёӘеҸ«еҒҡWNodeзҡ„еҜ№иұЎпјҡ
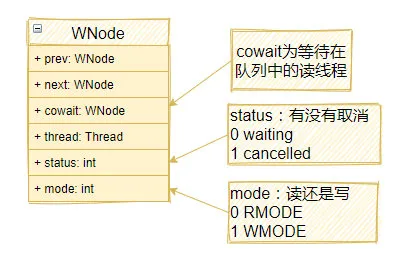
еҪ“йҳҹеҲ—дёӯжңүиӢҘе№ІдёӘзәҝзЁӢзӯүеҫ…ж—¶пјҢж•ҙдёӘйҳҹеҲ—еҸҜиғҪзңӢиө·жқҘеғҸиҝҷж ·зҡ„пјҡ
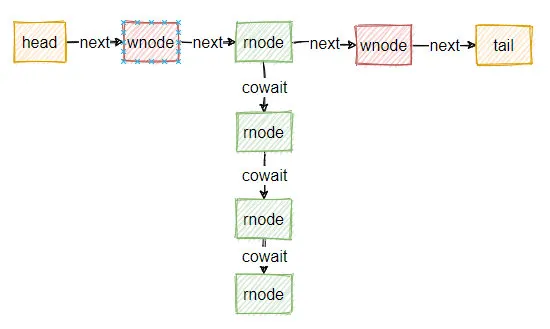
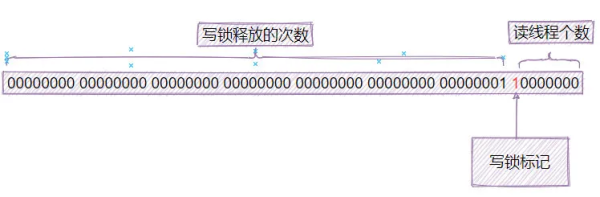
йҷӨдәҶиҝҷдёӘзӯүеҫ…йҳҹеҲ—пјҢStampedLockдёӯеҸҰеӨ–дёҖдёӘзү№еҲ«йҮҚиҰҒзҡ„еӯ—ж®өе°ұжҳҜlong stateпјҢ иҝҷжҳҜдёҖдёӘ64дҪҚзҡ„ж•ҙж•°пјҢStampedLockеҜ№е®ғзҡ„дҪҝз”ЁжҳҜйқһеёёе·§еҰҷзҡ„гҖӮ
state зҡ„еҲқе§ӢеҖјжҳҜ:
private static final int LG_READERS = 7; private static final long WBIT = 1L << LG_READERS; private static final long ORIGIN = WBIT << 1;
д№ҹе°ұжҳҜ ...0001 0000 0000 (еүҚйқўзҡ„0еӨӘеӨҡдәҶпјҢдёҚеҶҷдәҶпјҢеҮ‘и¶і64дёӘеҗ§~)пјҢдёәд»Җд№ҲиҝҷйҮҢдёҚз”Ё0еҒҡеҲқе§ӢеҖје‘ў?еӣ дёә0жңүзү№ж®Ҡзҡ„еҗ«д№үпјҢдёәдәҶйҒҝе…ҚеҶІзӘҒпјҢжүҖд»ҘйҖүжӢ©дәҶдёҖдёӘйқһйӣ¶зҡ„ж•°еӯ—гҖӮ
еҰӮжһңжңүеҶҷй”ҒеҚ з”ЁпјҢйӮЈд№Ҳе°ұ让第7дҪҚи®ҫзҪ®дёә1 ...0001 1000 0000пјҢд№ҹе°ұжҳҜеҠ дёҠWBITгҖӮ
жҜҸж¬ЎйҮҠж”ҫеҶҷй”ҒпјҢе°ұеҠ 1пјҢдҪҶдёҚжҳҜstateзӣҙжҺҘеҠ пјҢиҖҢжҳҜеҺ»жҺүжңҖеҗҺдёҖдёӘеӯ—иҠӮпјҢеҸӘдҪҝз”ЁеүҚйқўзҡ„7дёӘеӯ—иҠӮеҒҡз»ҹи®ЎгҖӮеӣ жӯӨпјҢйҮҠж”ҫеҶҷй”ҒеҗҺпјҢstateе°ұеҸҳжҲҗдәҶпјҡ...0010 0000 0000пјҢ еҶҚеҠ дёҖж¬Ўй”ҒпјҢеҸҲеҸҳжҲҗпјҡ...0010 1000 0000пјҢд»ҘжӯӨзұ»жҺЁгҖӮ
иҝҷжҳҜеӣ дёәж•ҙдёӘstate зҡ„зҠ¶жҖҒеҲӨж–ӯйғҪжҳҜеҹәдәҺCASж“ҚдҪңзҡ„гҖӮиҖҢжҷ®йҖҡзҡ„CASж“ҚдҪңеҸҜиғҪдјҡйҒҮеҲ°ABAзҡ„й—®йўҳпјҢеҰӮжһңдёҚи®°еҪ•ж¬Ўж•°пјҢйӮЈд№ҲеҪ“еҶҷй”ҒйҮҠж”ҫжҺүпјҢз”іиҜ·еҲ°пјҢеҶҚйҮҠж”ҫжҺүж—¶пјҢжҲ‘们е°Ҷж— жі•еҲӨж–ӯж•°жҚ®жҳҜеҗҰиў«еҶҷиҝҮгҖӮиҖҢиҝҷйҮҢи®°еҪ•дәҶйҮҠж”ҫзҡ„ж¬Ўж•°пјҢеӣ жӯӨеҮәзҺ°"йҮҠж”ҫ->з”іиҜ·->йҮҠж”ҫ"зҡ„ж—¶еҖҷпјҢCASж“ҚдҪңе°ұеҸҜд»ҘжЈҖжҹҘеҲ°ж•°жҚ®зҡ„еҸҳеҢ–пјҢд»ҺиҖҢеҲӨж–ӯеҶҷж“ҚдҪңе·Із»ҸжңүеҸ‘з”ҹпјҢдҪңдёәдёҖдёӘд№җи§Ӯй”ҒжқҘиҜҙпјҢе°ұеҸҜд»ҘеҮҶзЎ®еҲӨж–ӯеҶІзӘҒе·Із»Ҹдә§з”ҹпјҢеү©дёӢзҡ„е°ұжҳҜдәӨз»ҷеә”з”ЁжқҘи§ЈеҶіеҶІзӘҒеҚіеҸҜгҖӮеӣ жӯӨпјҢиҝҷйҮҢи®°еҪ•йҮҠж”ҫй”Ғзҡ„ж¬Ўж•°пјҢжҳҜдёәдәҶзІҫзЎ®ең°зӣ‘жҺ§зәҝзЁӢеҶІзӘҒгҖӮ
иҖҢstateеү©дёӢзҡ„йӮЈдёҖдёӘеӯ—иҠӮзҡ„е…¶дёӯ7дҪҚпјҢз”ЁжқҘи®°еҪ•иҜ»й”Ғзҡ„зәҝзЁӢж•°йҮҸпјҢз”ұдәҺеҸӘжңү7дҪҚпјҢеӣ жӯӨеҸӘиғҪи®°еҪ•еҸҜжҖңзҡ„126дёӘ,зңӢдёӢйқўд»Јз Ғдёӯзҡ„RFULLпјҢе°ұжҳҜиҜ»зәҝзЁӢж»ЎиҪҪзҡ„ж•°йҮҸгҖӮи¶…иҝҮдәҶжҖҺд№ҲеҠһе‘ўпјҢеӨҡдҪҷзҡ„йғЁеҲҶе°ұи®°еҪ•еңЁreaderOverflowеӯ—ж®өдёӯгҖӮ
private static final long WBIT = 1L << LG_READERS; private static final long RBITS = WBIT - 1L; private static final long RFULL = RBITS - 1L; private transient int readerOverflow;
жҖ»з»“дёҖдёӢпјҢstateеҸҳйҮҸзҡ„з»“жһ„еҰӮдёӢпјҡ
еңЁдәҶи§ЈдәҶStampedLockзҡ„еҶ…йғЁж•°жҚ®з»“жһ„д№ӢеҗҺпјҢи®©жҲ‘们еҶҚжқҘзңӢдёҖдёӢжңүе…іеҶҷй”Ғзҡ„з”іиҜ·е’ҢйҮҠж”ҫеҗ§!йҰ–е…ҲжҳҜеҶҷй”Ғзҡ„з”іиҜ·пјҡ
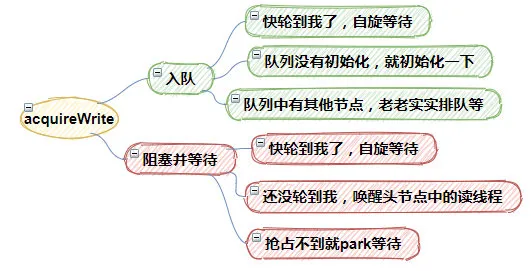
public long writeLock() { long s, next; return ((((s = state) & ABITS) == 0L && //жңүжІЎжңүиҜ»еҶҷй”Ғиў«еҚ з”ЁпјҢеҰӮжһңжІЎжңүпјҢе°ұи®ҫзҪ®дёҠеҶҷй”Ғж Үи®° U.compareAndSwapLong(this, STATE, s, next = s + WBIT)) ? //еҰӮжһңеҶҷй”ҒеҚ з”ЁжҲҗеҠҹиҢғеӣҙnextпјҢеҰӮжһңеӨұиҙҘе°ұиҝӣе…ҘacquireWrite()иҝӣиЎҢй”Ғзҡ„еҚ з”ЁгҖӮ next : acquireWrite(false, 0L)); }еҰӮжһңCASи®ҫзҪ®stateеӨұиҙҘпјҢиЎЁзӨәеҶҷй”Ғз”іиҜ·еӨұиҙҘпјҢиҝҷж—¶пјҢдјҡи°ғз”ЁacquireWrite()иҝӣиЎҢз”іиҜ·жҲ–иҖ…зӯүеҫ…гҖӮacquireWrite()еӨ§дҪ“еҒҡдәҶдёӢйқўеҮ 件дәӢжғ…пјҡ
1.е…Ҙйҳҹ
еҰӮжһңеӨҙз»“зӮ№зӯүдәҺе°ҫз»“зӮ№wtail == wheadпјҢ иЎЁзӨәеҝ«иҪ®еҲ°жҲ‘дәҶпјҢжүҖд»ҘиҝӣиЎҢиҮӘж—Ӣзӯүеҫ…пјҢжҠўеҲ°е°ұз»“жқҹдәҶ
еҰӮжһңwtail==null пјҢиҜҙжҳҺйҳҹеҲ—йғҪжІЎеҲқе§ӢеҢ–пјҢе°ұеҲқе§ӢеҢ–дёҖдёӢйҳҹеҲ—
еҰӮжһңйҳҹеҲ—дёӯжңүе…¶д»–зӯүеҫ…з»“зӮ№пјҢйӮЈд№ҲеҸӘиғҪиҖҒиҖҒе®һе®һе…Ҙйҳҹзӯүеҫ…дәҶ
2.йҳ»еЎһ并зӯүеҫ…
еҰӮжһңеӨҙз»“зӮ№зӯүдәҺеүҚзҪ®з»“зӮ№(h = whead) == p), йӮЈиҜҙжҳҺд№ҹеҝ«иҪ®еҲ°жҲ‘дәҶпјҢдёҚж–ӯиҝӣиЎҢиҮӘж—Ӣзӯүеҫ…дәүжҠў
еҗҰеҲҷе”ӨйҶ’еӨҙз»“зӮ№дёӯзҡ„иҜ»зәҝзЁӢ
еҰӮжһңжҠўеҚ дёҚеҲ°й”ҒпјҢйӮЈд№Ҳе°ұpark()еҪ“еүҚзәҝзЁӢ
з®ҖеҚ•ең°иҜҙпјҢacquireWrite()еҮҪж•°е°ұжҳҜз”ЁжқҘдәүжҠўй”Ғзҡ„пјҢе®ғзҡ„иҝ”еӣһеҖје°ұжҳҜд»ЈиЎЁеҪ“еүҚй”ҒзҠ¶жҖҒзҡ„йӮ®жҲіпјҢеҗҢж—¶пјҢдёәдәҶжҸҗй«ҳй”Ғзҡ„жҖ§иғҪпјҢacquireWrite()дҪҝз”ЁеӨ§йҮҸзҡ„иҮӘж—ӢйҮҚиҜ•пјҢеӣ жӯӨпјҢе®ғзҡ„д»Јз ҒзңӢиө·жқҘжңүзӮ№жҷҰ涩йҡҫжҮӮгҖӮ
еҶҷй”Ғзҡ„йҮҠж”ҫеҰӮдёӢжүҖзӨәпјҢunlockWrite()зҡ„дј е…ҘеҸӮж•°жҳҜз”іиҜ·й”Ғж—¶еҫ—еҲ°зҡ„йӮ®жҲіпјҡ
public void unlockWrite(long stamp) { WNode h; //жЈҖжҹҘй”Ғзҡ„зҠ¶жҖҒжҳҜеҗҰжӯЈеёё if (state != stamp || (stamp & WBIT) == 0L) throw new IllegalMonitorStateException(); // и®ҫзҪ®stateдёӯж Үеҝ—дҪҚдёә0пјҢеҗҢж—¶д№ҹиө·еҲ°дәҶеўһеҠ йҮҠж”ҫй”Ғж¬Ўж•°зҡ„дҪңз”Ё state = (stamp += WBIT) == 0L ? ORIGIN : stamp; // еӨҙз»“зӮ№дёҚдёәз©әпјҢе°қиҜ•е”ӨйҶ’еҗҺз»ӯзҡ„зәҝзЁӢ if ((h = whead) != null && h.status != 0) //е”ӨйҶ’(unpark)еҗҺз»ӯзҡ„дёҖдёӘзәҝзЁӢ release(h); }иҺ·еҸ–иҜ»й”Ғзҡ„д»Јз ҒеҰӮдёӢпјҡ
public long readLock() { long s = state, next; //еҰӮжһңйҳҹеҲ—дёӯжІЎжңүеҶҷй”ҒпјҢ并且иҜ»зәҝзЁӢдёӘж•°жІЎжңүи¶…иҝҮ126пјҢзӣҙжҺҘиҺ·еҫ—й”ҒпјҢ并且иҜ»зәҝзЁӢж•°йҮҸеҠ 1 return ((whead == wtail && (s & ABITS) < RFULL && U.compareAndSwapLong(this, STATE, s, next = s + RUNIT)) ? //еҰӮжһңдәүжҠўеӨұиҙҘпјҢиҝӣе…ҘacquireRead()дәүжҠўжҲ–иҖ…зӯүеҫ… next : acquireRead(false, 0L)); }acquireRead()зҡ„е®һзҺ°зӣёеҪ“еӨҚжқӮпјҢеӨ§дҪ“дёҠеҲҶдёәиҝҷд№ҲеҮ жӯҘпјҡ
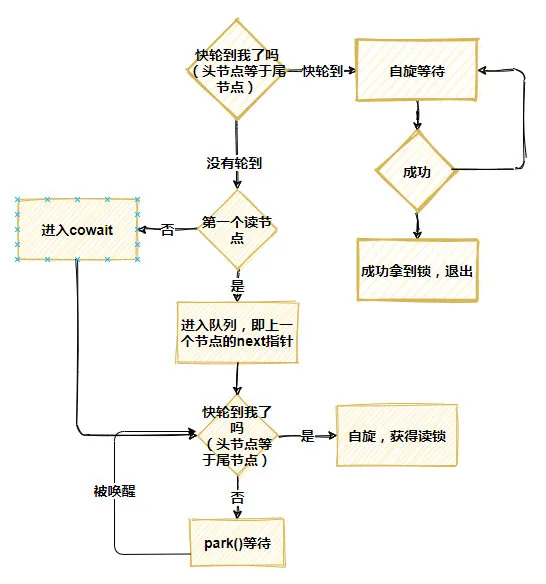
жҖ»д№ӢпјҢе°ұжҳҜиҮӘж—ӢпјҢиҮӘж—ӢеҶҚиҮӘж—ӢпјҢйҖҡиҝҮдёҚж–ӯзҡ„иҮӘж—ӢжқҘе°ҪеҸҜиғҪйҒҝе…ҚзәҝзЁӢиў«зңҹзҡ„жҢӮиө·пјҢеҸӘжңүеҪ“иҮӘж—Ӣе……еҲҶеӨұиҙҘеҗҺпјҢжүҚдјҡзңҹжӯЈи®©зәҝзЁӢеҺ»зӯүеҫ…гҖӮ
дёӢйқўжҳҜйҮҠж”ҫиҜ»й”Ғзҡ„иҝҮзЁӢпјҡ

StampedLockеӣә然жҳҜдёӘеҘҪдёңиҘҝпјҢдҪҶжҳҜз”ұдәҺе®ғзү№еҲ«еӨҚжқӮпјҢйҡҫе…Қд№ҹдјҡеҮәзҺ°дёҖдәӣе°Ҹй—®йўҳгҖӮдёӢйқўиҝҷдёӘдҫӢеӯҗпјҢе°ұжј”зӨәдәҶStampedLockжӮІи§Ӯй”Ғз–ҜзӢӮеҚ з”ЁCPUзҡ„й—®йўҳпјҡ
public class StampedLockTest { public static void main(String[] args) throws InterruptedException { final StampedLock lock = new StampedLock(); Thread t1 = new Thread(() -> { // иҺ·еҸ–еҶҷй”Ғ lock.writeLock(); // жЁЎжӢҹзЁӢеәҸйҳ»еЎһзӯүеҫ…е…¶д»–иө„жәҗ LockSupport.park(); }); t1.start(); // дҝқиҜҒt1иҺ·еҸ–еҶҷй”Ғ Thread.sleep(100); Thread t2 = new Thread(() -> { // йҳ»еЎһеңЁжӮІи§ӮиҜ»й”Ғ lock.readLock(); }); t2.start(); // дҝқиҜҒt2йҳ»еЎһеңЁиҜ»й”Ғ Thread.sleep(100); // дёӯж–ӯзәҝзЁӢt2,дјҡеҜјиҮҙзәҝзЁӢt2жүҖеңЁCPUйЈҷеҚҮ t2.interrupt(); t2.join(); } }дёҠиҝ°д»Јз ҒдёӯпјҢеңЁдёӯж–ӯt2еҗҺпјҢt2зҡ„CPUеҚ з”ЁзҺҮе°ұдјҡжІҫж»Ў100%гҖӮиҖҢиҝҷж—¶еҖҷпјҢt2жӯЈйҳ»еЎһеңЁreadLock()еҮҪж•°дёҠпјҢжҚўиЁҖд№ӢпјҢеңЁеҸ—еҲ°дёӯж–ӯеҗҺпјҢStampedLockзҡ„иҜ»й”ҒжңүеҸҜиғҪдјҡеҚ ж»ЎCPUгҖӮиҝҷжҳҜд»Җд№ҲеҺҹеӣ е‘ў?жңәеҲ¶зҡ„е°ҸеӮ»з“ңдёҖе®ҡжғіеҲ°дәҶпјҢиҝҷжҳҜеӣ дёәStampedLockеҶ…еӨӘеӨҡзҡ„иҮӘж—Ӣеј•иө·зҡ„!жІЎй”ҷпјҢдҪ зҡ„зҢңжөӢжҳҜжӯЈзЎ®зҡ„гҖӮ
еҰӮжһңжІЎжңүдёӯж–ӯпјҢйӮЈд№Ҳйҳ»еЎһеңЁreadLock()дёҠзҡ„зәҝзЁӢеңЁз»ҸиҝҮеҮ ж¬ЎиҮӘж—ӢеҗҺпјҢдјҡиҝӣе…Ҙpark()зӯүеҫ…пјҢдёҖж—Ұиҝӣе…Ҙpark()зӯүеҫ…пјҢе°ұдёҚдјҡеҚ з”ЁCPUдәҶгҖӮдҪҶжҳҜpark()иҝҷдёӘеҮҪж•°жңүдёҖдёӘзү№зӮ№пјҢе°ұжҳҜдёҖж—ҰзәҝзЁӢиў«дёӯж–ӯпјҢpark()е°ұдјҡз«ӢеҚіиҝ”еӣһпјҢиҝ”еӣһиҝҳдёҚз®—пјҢе®ғд№ҹдёҚз»ҷдҪ жҠӣзӮ№ејӮеёёе•Ҙзҡ„пјҢйӮЈиҝҷе°ұе°ҙе°¬дәҶгҖӮжң¬жқҘе‘ўпјҢдҪ жҳҜжғіеңЁй”ҒеҮҶеӨҮеҘҪзҡ„ж—¶еҖҷпјҢunpark()зҡ„зәҝзЁӢзҡ„пјҢдҪҶжҳҜзҺ°еңЁй”ҒжІЎеҘҪпјҢдҪ зӣҙжҺҘдёӯж–ӯдәҶпјҢpark()д№ҹиҝ”еӣһдәҶпјҢдҪҶжҳҜпјҢжҜ•з«ҹй”ҒжІЎеҘҪпјҢжүҖд»Ҙе°ұеҸҲеҺ»иҮӘж—ӢдәҶгҖӮ
иҪ¬зқҖиҪ¬зқҖпјҢеҸҲиҪ¬еҲ°дәҶpark()еҮҪж•°пјҢдҪҶжӮІеӮ¬зҡ„жҳҜпјҢзәҝзЁӢзҡ„дёӯж–ӯж Үи®°дёҖзӣҙжү“ејҖзқҖпјҢpark()е°ұйҳ»еЎһдёҚдҪҸдәҶпјҢдәҺжҳҜд№ҺпјҢдёӢдёҖдёӘиҮӘж—ӢеҸҲејҖе§ӢдәҶпјҢжІЎе®ҢжІЎдәҶзҡ„иҮӘж—ӢеҒңдёҚдёӢжқҘдәҶпјҢжүҖд»ҘCPUе°ұзҲҶж»ЎдәҶгҖӮ
иҰҒи§ЈеҶіиҝҷдёӘй—®йўҳпјҢжң¬иҙЁдёҠйңҖиҰҒеңЁStampedLockеҶ…йғЁпјҢеңЁpark()иҝ”еӣһж—¶пјҢйңҖиҰҒеҲӨж–ӯдёӯж–ӯж Үи®°дёәпјҢ并дҪңеҮәжӯЈзЎ®зҡ„еӨ„зҗҶпјҢжҜ”еҰӮпјҢйҖҖеҮәпјҢжҠӣејӮеёёпјҢжҲ–иҖ…жҠҠдёӯж–ӯдҪҚз»ҷжё…зҗҶдёҖдёӢпјҢйғҪеҸҜд»Ҙи§ЈеҶій—®йўҳгҖӮ
дҪҶеҫҲдёҚе№ёпјҢиҮіе°‘еңЁJDK8йҮҢпјҢиҝҳжІЎжңүиҝҷж ·зҡ„еӨ„зҗҶгҖӮеӣ жӯӨе°ұеҮәзҺ°дәҶдёҠйқўзҡ„пјҢдёӯж–ӯreadLock()еҗҺпјҢCPUзҲҶж»Ўзҡ„й—®йўҳгҖӮиҜ·еӨ§е®¶дёҖе®ҡиҰҒжіЁж„ҸгҖӮ
д»ҘдёҠжҳҜвҖңStampedLockжҖҺд№Ҳз”ЁвҖқиҝҷзҜҮж–Үз« зҡ„жүҖжңүеҶ…е®№пјҢж„ҹи°ўеҗ„дҪҚзҡ„йҳ…иҜ»пјҒеёҢжңӣеҲҶдә«зҡ„еҶ…е®№еҜ№еӨ§е®¶жңүеё®еҠ©пјҢжӣҙеӨҡзӣёе…ізҹҘиҜҶпјҢж¬ўиҝҺе…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“пјҒ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ