жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
д»ҠеӨ©е°Ҹзј–з»ҷеӨ§е®¶еҲҶдә«дёҖдёӢNamespaceжңәеҲ¶жҖҺд№ҲзҗҶи§Јзҡ„зӣёе…ізҹҘиҜҶзӮ№пјҢеҶ…е®№иҜҰз»ҶпјҢйҖ»иҫ‘жё…жҷ°пјҢзӣёдҝЎеӨ§йғЁеҲҶдәәйғҪиҝҳеӨӘдәҶи§Јиҝҷж–№йқўзҡ„зҹҘиҜҶпјҢжүҖд»ҘеҲҶдә«иҝҷзҜҮж–Үз« з»ҷеӨ§е®¶еҸӮиҖғдёҖдёӢпјҢеёҢжңӣеӨ§е®¶йҳ…иҜ»е®ҢиҝҷзҜҮж–Үз« еҗҺжңүжүҖ收иҺ·пјҢдёӢйқўжҲ‘们дёҖиө·жқҘдәҶи§ЈдёҖдёӢеҗ§гҖӮ
Namespace
Linux Namespace жҳҜ Linux жҸҗдҫӣзҡ„дёҖз§ҚеҶ…ж ёзә§еҲ«зҺҜеўғйҡ”зҰ»зҡ„ж–№жі•гҖӮиҝҷз§Қйҡ”зҰ»жңәеҲ¶е’Ң chroot еҫҲзұ»дјјпјҢchroot жҳҜжҠҠжҹҗдёӘзӣ®еҪ•дҝ®ж”№дёәж №зӣ®еҪ•пјҢд»ҺиҖҢж— жі•и®ҝй—®еӨ–йғЁзҡ„еҶ…е®№гҖӮLinux Namesapce еңЁжӯӨеҹәзЎҖд№ӢдёҠпјҢжҸҗдҫӣдәҶеҜ№ UTSгҖҒIPCгҖҒMountгҖҒPIDгҖҒNetworkгҖҒUser зӯүзҡ„йҡ”зҰ»жңәеҲ¶пјҢеҰӮдёӢжүҖзӨәгҖӮ
| еҲҶзұ» | зі»з»ҹи°ғз”ЁеҸӮж•° | зӣёе…іеҶ…ж ёзүҲжң¬ |
|---|---|---|
| Mount Namespaces | CLONE_NEWNS | Linux 2.4.19 |
| UTS Namespaces | CLONE_NEWUTS | Linux 2.6.19 |
| IPC Namespaces | CLONE_NEWIPC | Linux 2.6.19 |
| PID Namespaces | CLONE_NEWPID | Linux 2.6.19 |
| Network Namespaces | CLONE_NEWNET | е§ӢдәҺLinux 2.6.24 е®ҢжҲҗдәҺ Linux 2.6.29 |
| User Namespaces | CLONE_NEWUSER | е§ӢдәҺ Linux 2.6.23 е®ҢжҲҗдәҺ Linux 3.8) |
вҳ… Linux Namespace е®ҳж–№ж–ҮжЎЈпјҡNamespaces in operationвҖқ
namespace жңүдёүдёӘзі»з»ҹи°ғз”ЁеҸҜд»ҘдҪҝз”Ёпјҡ
clone() --- е®һзҺ°зәҝзЁӢзҡ„зі»з»ҹи°ғз”ЁпјҢз”ЁжқҘеҲӣе»әдёҖдёӘж–°зҡ„иҝӣзЁӢпјҢ并еҸҜд»ҘйҖҡиҝҮи®ҫи®ЎдёҠиҝ°еҸӮж•°иҫҫеҲ°йҡ”зҰ»гҖӮ
unshare() --- дҪҝжҹҗдёӘиҝӣзЁӢи„ұзҰ»жҹҗдёӘ namespace
setns(int fd, int nstype) --- жҠҠжҹҗиҝӣзЁӢеҠ е…ҘеҲ°жҹҗдёӘ namespace
дёӢйқўдҪҝз”ЁиҝҷеҮ дёӘзі»з»ҹи°ғз”ЁжқҘжј”зӨә Namespace зҡ„ж•ҲжһңпјҢжӣҙеҠ иҜҰз»Ҷең°еҸҜд»ҘзңӢ DOCKERеҹәзЎҖжҠҖжңҜпјҡLINUX NAMESPACE(дёҠ)гҖҒ DOCKERеҹәзЎҖжҠҖжңҜпјҡLINUX NAMESPACE(дёӢ)гҖӮ
UTS Namespace
UTS Namespace дё»иҰҒжҳҜз”ЁжқҘйҡ”зҰ»дё»жңәеҗҚзҡ„пјҢд№ҹе°ұжҳҜжҜҸдёӘе®№еҷЁйғҪжңүиҮӘе·ұзҡ„дё»жңәеҗҚгҖӮжҲ‘们дҪҝз”ЁеҰӮдёӢзҡ„д»Јз ҒжқҘиҝӣиЎҢжј”зӨәгҖӮжіЁж„ҸпјҡеҒҮеҰӮеңЁе®№еҷЁеҶ…йғЁжІЎжңүи®ҫзҪ®дё»жңәеҗҚзҡ„иҜқдјҡдҪҝз”Ёдё»жңәзҡ„дё»жңәеҗҚзҡ„;еҒҮеҰӮеңЁе®№еҷЁеҶ…йғЁи®ҫзҪ®дәҶдё»жңәеҗҚдҪҶжҳҜжІЎжңүдҪҝз”Ё CLONE_NEWUTS зҡ„иҜқйӮЈд№Ҳж”№еҸҳзҡ„е…¶е®һжҳҜдё»жңәзҡ„дё»жңәеҗҚгҖӮ
#define _GNU_SOURCE #include <sys/types.h> #include <sys/wait.h> #include <sys/mount.h> #include <stdio.h> #include <sched.h> #include <signal.h> #include <unistd.h> #define STACK_SIZE (1024 * 1024) static char container_stack[STACK_SIZE]; char* const container_args[] = { "/bin/bash", NULL }; int container_main(void* arg) { printf("Container [%5d] - inside the container!\n", getpid()); sethostname("container_dawn", 15); execv(container_args[0], container_args); printf("Something's wrong!\n"); return 1; } int main() { printf("Parent [%5d] - start a container!\n", getpid()); int container_id = clone(container_main, container_stack + STACK_SIZE, CLONE_NEWUTS | SIGCHLD, NULL); waitpid(container_id, NULL, 0); printf("Parent - container stopped!\n"); return 0; }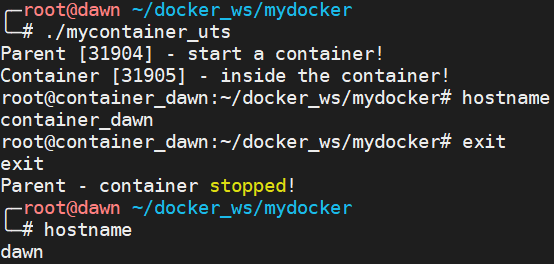
PID Namespace
жҜҸдёӘе®№еҷЁйғҪжңүиҮӘе·ұзҡ„иҝӣзЁӢзҺҜеўғдёӯпјҢд№ҹе°ұжҳҜзӣёеҪ“дәҺе®№еҷЁеҶ…иҝӣзЁӢзҡ„ PID д»Һ 1 ејҖе§Ӣе‘ҪеҗҚпјҢжӯӨж—¶дё»жңәдёҠзҡ„ PID е…¶е®һд№ҹиҝҳжҳҜд»Һ 1 ејҖе§Ӣе‘ҪеҗҚзҡ„пјҢе°ұзӣёеҪ“дәҺжңүдёӨдёӘиҝӣзЁӢзҺҜеўғпјҡдёҖдёӘдё»жңәдёҠзҡ„д»Һ 1 ејҖе§ӢпјҢеҸҰдёҖдёӘе®№еҷЁйҮҢзҡ„д»Һ 1 ејҖе§ӢгҖӮ
дёәе•Ҙ PID д»Һ 1 ејҖе§Ӣе°ұзӣёеҪ“дәҺиҝӣзЁӢзҺҜеўғзҡ„йҡ”зҰ»дәҶе‘ў?еӣ жӯӨеңЁдј з»ҹзҡ„ UNIX зі»з»ҹдёӯпјҢPID дёә 1 зҡ„иҝӣзЁӢжҳҜ initпјҢең°дҪҚзү№ж®ҠгҖӮе®ғдҪңдёәжүҖжңүиҝӣзЁӢзҡ„зҲ¶иҝӣзЁӢпјҢжңүеҫҲеӨҡзү№жқғгҖӮеҸҰеӨ–пјҢе…¶иҝҳдјҡжЈҖжҹҘжүҖжңүиҝӣзЁӢзҡ„зҠ¶жҖҒпјҢжҲ‘们зҹҘйҒ“еҰӮжһңжҹҗдёӘиҝӣзЁӢи„ұзҰ»дәҶзҲ¶иҝӣзЁӢ(зҲ¶иҝӣзЁӢжІЎжңү wait е®ғ)пјҢйӮЈд№Ҳ init е°ұдјҡиҙҹиҙЈеӣһ收иө„жәҗ并结жқҹиҝҷдёӘеӯҗиҝӣзЁӢгҖӮжүҖд»ҘиҰҒжғіеҒҡеҲ°иҝӣзЁӢзҡ„йҡ”зҰ»пјҢйҰ–е…ҲйңҖиҰҒеҲӣе»әеҮә PID дёә 1 зҡ„иҝӣзЁӢгҖӮ
дҪҶжҳҜпјҢгҖҗkubernetes йҮҢйқўзҡ„иҜқгҖ‘
int container_main(void* arg) { printf("Container [%5d] - inside the container!\n", getpid()); sethostname("container_dawn", 15); execv(container_args[0], container_args); printf("Something's wrong!\n"); return 1; } int main() { printf("Parent [%5d] - start a container!\n", getpid()); int container_id = clone(container_main, container_stack + STACK_SIZE, CLONE_NEWUTS | CLONE_NEWPID | SIGCHLD, NULL); waitpid(container_id, NULL, 0); printf("Parent - container stopped!\n"); return 0; }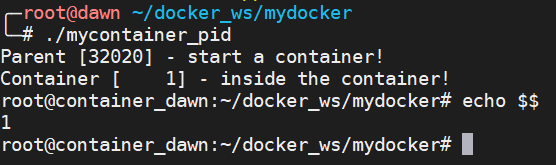
еҰӮжһңжӯӨж—¶дҪ еңЁеӯҗиҝӣзЁӢзҡ„ shell дёӯиҫ“е…Ҙ psгҖҒtop зӯүе‘Ҫд»ӨпјҢжҲ‘们иҝҳжҳҜеҸҜд»ҘзңӢеҲ°жүҖжңүиҝӣзЁӢгҖӮиҝҷжҳҜеӣ дёәпјҢpsгҖҒtop иҝҷдәӣе‘Ҫд»ӨжҳҜеҺ»иҜ» /proc ж–Ү件系з»ҹпјҢз”ұдәҺжӯӨж—¶ж–Ү件系з»ҹ并没жңүйҡ”зҰ»пјҢжүҖд»ҘзҲ¶иҝӣзЁӢе’ҢеӯҗиҝӣзЁӢйҖҡиҝҮе‘Ҫд»ӨзңӢеҲ°зҡ„жғ…еҶөйғҪжҳҜдёҖж ·зҡ„гҖӮ
IPC Namespace
еёёи§Ғзҡ„ IPC жңүе…ұдә«еҶ…еӯҳгҖҒдҝЎеҸ·йҮҸгҖҒж¶ҲжҒҜйҳҹеҲ—зӯүгҖӮеҪ“дҪҝз”Ё IPC Namespace жҠҠ IPC йҡ”зҰ»иө·жқҘд№ӢеҗҺпјҢеҸӘжңүеҗҢдёҖдёӘ Namespace дёӢзҡ„иҝӣзЁӢжүҚиғҪзӣёдә’йҖҡдҝЎпјҢеӣ дёәдё»жңәзҡ„ IPC е’Ңе…¶д»– Namespace дёӯзҡ„ IPC йғҪжҳҜзңӢдёҚеҲ°дәҶзҡ„гҖӮиҖҢиҝҷдёӘзҡ„йҡ”зҰ»дё»иҰҒжҳҜеӣ дёәеҲӣе»әеҮәжқҘзҡ„ IPC йғҪдјҡжңүдёҖдёӘе”ҜдёҖзҡ„ IDпјҢйӮЈд№Ҳдё»иҰҒеҜ№иҝҷдёӘ ID иҝӣиЎҢйҡ”зҰ»е°ұеҘҪдәҶгҖӮ
жғіиҰҒеҗҜеҠЁ IPC йҡ”зҰ»пјҢеҸӘйңҖиҰҒеңЁи°ғз”Ё clone зҡ„ж—¶еҖҷеҠ дёҠ CLONE_NEWIPC еҸӮж•°е°ұеҸҜд»ҘдәҶгҖӮ
int container_main(void* arg) { printf("Container [%5d] - inside the container!\n", getpid()); sethostname("container_dawn", 15); execv(container_args[0], container_args); printf("Something's wrong!\n"); return 1; } int main() { printf("Parent [%5d] - start a container!\n", getpid()); int container_id = clone(container_main, container_stack + STACK_SIZE, CLONE_NEWUTS | CLONE_NEWPID | CLONE_NEWIPC | SIGCHLD, NULL); waitpid(container_id, NULL, 0); printf("Parent - container stopped!\n"); return 0; }Mount Namespace еҸҜд»Ҙи®©е®№еҷЁжңүиҮӘе·ұзҡ„ root ж–Ү件系з»ҹгҖӮйңҖиҰҒжіЁж„Ҹзҡ„жҳҜпјҢеңЁйҖҡиҝҮ CLONE_NEWNS еҲӣе»ә mount namespace д№ӢеҗҺпјҢзҲ¶иҝӣзЁӢдјҡжҠҠиҮӘе·ұзҡ„ж–Ү件结жһ„еӨҚеҲ¶з»ҷеӯҗиҝӣзЁӢдёӯгҖӮжүҖд»ҘеҪ“еӯҗиҝӣзЁӢдёӯдёҚйҮҚж–° mount зҡ„иҜқпјҢеӯҗиҝӣзЁӢе’ҢзҲ¶иҝӣзЁӢзҡ„ж–Ү件系з»ҹи§ҶеӣҫжҳҜдёҖж ·зҡ„пјҢеҒҮеҰӮжғіиҰҒж”№еҸҳе®№еҷЁиҝӣзЁӢзҡ„и§ҶеӣҫпјҢдёҖе®ҡйңҖиҰҒйҮҚж–° mount(иҝҷдёӘжҳҜ mount namespace е’Ңе…¶д»– namespace дёҚеҗҢзҡ„ең°ж–№)гҖӮ
еҸҰеӨ–пјҢеӯҗиҝӣзЁӢдёӯж–°зҡ„ namespace дёӯзҡ„жүҖжңү mount ж“ҚдҪңйғҪеҸӘеҪұе“ҚиҮӘиә«зҡ„ж–Ү件系з»ҹ(жіЁж„Ҹиҝҷиҫ№жҳҜ mount ж“ҚдҪңпјҢиҖҢеҲӣе»әж–Ү件зӯүж“ҚдҪңйғҪжҳҜдјҡжңүжүҖеҪұе“Қзҡ„)пјҢиҖҢдёҚеҜ№еӨ–з•Ңдә§з”ҹд»»дҪ•еҪұе“ҚпјҢиҝҷж ·еҸҜд»ҘеҒҡеҲ°жҜ”иҫғдёҘж јең°йҡ”зҰ»(еҪ“然иҝҷиҫ№жҳҜйҷӨ share mount д№ӢеӨ–зҡ„)гҖӮ
дёӢйқўжҲ‘们йҮҚж–°жҢӮиҪҪеӯҗиҝӣзЁӢзҡ„ /proc зӣ®еҪ•пјҢд»ҺиҖҢеҸҜд»ҘдҪҝз”Ё ps жқҘжҹҘзңӢе®№еҷЁеҶ…йғЁзҡ„жғ…еҶөгҖӮ
int container_main(void* arg) { printf("Container [%5d] - inside the container!\n", getpid()); sethostname("container_dawn", 15); if (mount("proc", "/proc", "proc", 0, NULL) !=0 ) { perror("proc"); } execv(container_args[0], container_args); printf("Something's wrong!\n"); return 1; } int main() { printf("Parent [%5d] - start a container!\n", getpid()); int container_id = clone(container_main, container_stack + STACK_SIZE, CLONE_NEWUTS | CLONE_NEWPID | CLONE_NEWNS | SIGCHLD, NULL); waitpid(container_id, NULL, 0); printf("Parent - container stopped!\n"); return 0; }
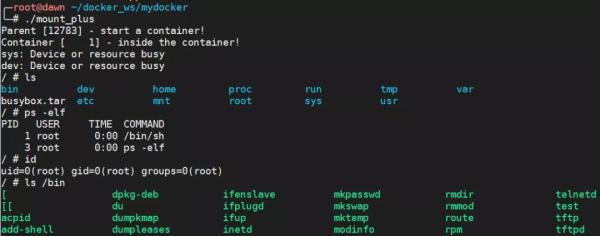
вҳ… иҝҷйҮҢдјҡжңүдёӘй—®йўҳе°ұжҳҜеңЁйҖҖеҮәеӯҗиҝӣзЁӢд№ӢеҗҺпјҢеҪ“еҶҚж¬ЎдҪҝз”Ё ps -elf зҡ„ж—¶еҖҷдјҡжҠҘй”ҷпјҢеҰӮдёӢжүҖзӨә
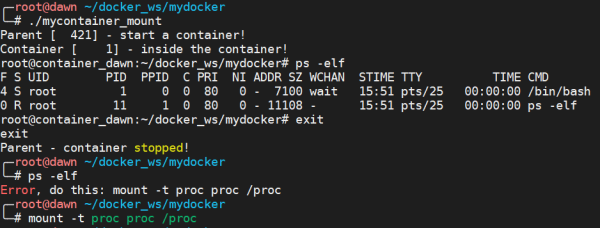
иҝҷжҳҜеӣ дёә /proc жҳҜ share mountпјҢеҜ№е®ғзҡ„ж“ҚдҪңдјҡеҪұе“ҚжүҖжңүзҡ„ mount namespaceпјҢеҸҜд»ҘзңӢиҝҷйҮҢпјҡhttp://unix.stackexchange.com/questions/281844/why-does-child-with-mount-namespace-affect-parent-mountsвҖқ
дёҠйқўд»…д»…йҮҚж–° mount дәҶ /proc иҝҷдёӘзӣ®еҪ•пјҢе…¶д»–зҡ„зӣ®еҪ•иҝҳжҳҜи·ҹзҲ¶иҝӣзЁӢдёҖж ·и§Ҷеӣҫзҡ„гҖӮдёҖиҲ¬жқҘиҜҙпјҢе®№еҷЁеҲӣе»әд№ӢеҗҺпјҢе®№еҷЁиҝӣзЁӢйңҖиҰҒзңӢеҲ°зҡ„жҳҜдёҖдёӘзӢ¬з«Ӣзҡ„йҡ”зҰ»зҺҜеўғпјҢиҖҢдёҚжҳҜ继жүҝе®ҝдё»жңәзҡ„ж–Ү件系з»ҹгҖӮжҺҘдёӢжқҘжј”зӨәдёҖдёӘеұұеҜЁй•ңеғҸпјҢжқҘжЁЎд»ҝ Docker зҡ„ Mount NamespaceгҖӮд№ҹе°ұжҳҜз»ҷеӯҗиҝӣзЁӢе®һзҺ°дёҖдёӘиҫғдёәе®Ңж•ҙзҡ„зӢ¬з«Ӣзҡ„ root ж–Ү件系з»ҹпјҢи®©иҝҷдёӘиҝӣзЁӢеҸӘиғҪи®ҝй—®иҮӘе·ұжһ„жҲҗзҡ„ж–Ү件系з»ҹдёӯзҡ„еҶ…е®№(жғіжғіжҲ‘们平常дҪҝз”Ё Docker е®№еҷЁзҡ„ж ·еӯҗ)гҖӮ
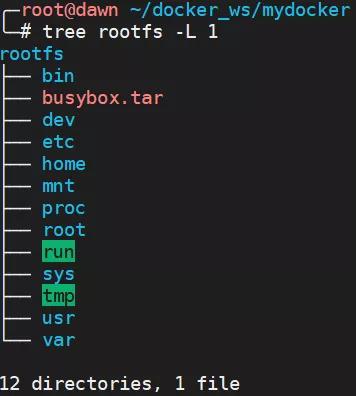
йҰ–е…ҲжҲ‘们дҪҝз”Ё docker export е°Ҷ busybox й•ңеғҸеҜјеҮәжҲҗдёҖдёӘ rootfs зӣ®еҪ•пјҢиҝҷдёӘ rootfs зӣ®еҪ•зҡ„жғ…еҶөеҰӮеӣҫжүҖзӨәпјҢе·Із»ҸеҢ…еҗ«дәҶ /procгҖҒ/sys зӯүзү№ж®Ҡзҡ„зӣ®еҪ•гҖӮ
д№ӢеҗҺжҲ‘们еңЁд»Јз Ғдёӯе°ҶдёҖдәӣзү№ж®Ҡзӣ®еҪ•йҮҚж–°жҢӮиҪҪпјҢ并дҪҝз”Ё chroot() зі»з»ҹи°ғз”Ёе°ҶиҝӣзЁӢзҡ„ж №зӣ®еҪ•ж”№жҲҗдёҠж–Үзҡ„ rootfs зӣ®еҪ•гҖӮ
char* const container_args[] = { "/bin/sh", NULL }; int container_main(void* arg) { printf("Container [%5d] - inside the container!\n", getpid()); sethostname("container_dawn", 15); if (mount("proc", "rootfs/proc", "proc", 0, NULL) != 0) { perror("proc"); } if (mount("sysfs", "rootfs/sys", "sysfs", 0, NULL)!=0) { perror("sys"); } if (mount("none", "rootfs/tmp", "tmpfs", 0, NULL)!=0) { perror("tmp"); } if (mount("udev", "rootfs/dev", "devtmpfs", 0, NULL)!=0) { perror("dev"); } if (mount("devpts", "rootfs/dev/pts", "devpts", 0, NULL)!=0) { perror("dev/pts"); } if (mount("shm", "rootfs/dev/shm", "tmpfs", 0, NULL)!=0) { perror("dev/shm"); } if (mount("tmpfs", "rootfs/run", "tmpfs", 0, NULL)!=0) { perror("run"); } if ( chdir("./rootfs") || chroot("./") != 0 ){ perror("chdir/chroot"); } // ж”№еҸҳж №зӣ®еҪ•д№ӢеҗҺпјҢйӮЈд№Ҳ /bin/bash жҳҜд»Һж”№еҸҳд№ӢеҗҺзҡ„ж №зӣ®еҪ•дёӯжҗңзҙўдәҶ execv(container_args[0], container_args); perror("exec"); printf("Something's wrong!\n"); return 1; } int main() { printf("Parent [%5d] - start a container!\n", getpid()); int container_id = clone(container_main, container_stack + STACK_SIZE, CLONE_NEWUTS | CLONE_NEWPID | CLONE_NEWNS | SIGCHLD, NULL); waitpid(container_id, NULL, 0); printf("Parent - container stopped!\n"); return 0; }жңҖеҗҺпјҢжҹҘзңӢе®һзҺ°ж•ҲжһңеҰӮдёӢеӣҫжүҖзӨәгҖӮ
е®һйҷ…дёҠпјҢMount Namespace жҳҜеҹәдәҺ chroot зҡ„дёҚж–ӯж”№иүҜжүҚиў«еҸ‘жҳҺеҮәжқҘ
зҡ„пјҢchroot еҸҜд»Ҙз®—жҳҜ Linux дёӯ第дёҖдёӘ NamespaceгҖӮйӮЈд№ҲдёҠйқўиў«жҢӮиҪҪеңЁе®№еҷЁж №зӣ®еҪ•дёҠгҖҒз”ЁжқҘдёәе®№еҷЁй•ңеғҸжҸҗдҫӣйҡ”зҰ»еҗҺжү§иЎҢзҺҜеўғзҡ„ж–Ү件系з»ҹпјҢе°ұжҳҜжүҖи°“зҡ„е®№еҷЁй•ңеғҸпјҢд№ҹиў«еҸ«еҒҡ rootfs(ж №ж–Ү件系з»ҹ)гҖӮйңҖиҰҒжҳҺзЎ®зҡ„жҳҜпјҢrootfs еҸӘжҳҜдёҖдёӘж“ҚдҪңзі»з»ҹжүҖеҢ…еҗ«зҡ„ж–Ү件гҖҒй…ҚзҪ®е’Ңзӣ®еҪ•пјҢ并дёҚеҢ…жӢ¬ж“ҚдҪңзі»з»ҹеҶ…ж ёгҖӮ
User Namespace
е®№еҷЁеҶ…йғЁзңӢеҲ°зҡ„ UID е’Ң GID е’ҢеӨ–йғЁжҳҜдёҚеҗҢзҡ„дәҶпјҢжҜ”еҰӮе®№еҷЁеҶ…йғЁй’ҲеҜ№ dawn иҝҷдёӘз”ЁжҲ·жҳҫзӨәзҡ„жҳҜ 0пјҢдҪҶжҳҜе®һйҷ…дёҠиҝҷдёӘз”ЁжҲ·еңЁдё»жңәдёҠеә”иҜҘжҳҜ 1000гҖӮиҰҒе®һзҺ°иҝҷж ·зҡ„ж•ҲжһңпјҢйңҖиҰҒжҠҠе®№еҷЁеҶ…йғЁзҡ„ UID е’Ңдё»жңәзҡ„ UID иҝӣиЎҢжҳ е°„пјҢйңҖиҰҒдҝ®ж”№зҡ„ж–Ү件жҳҜ /proc/
ID-INSIDE-NS ID-OUTSIDE-NS LENGTH
ID-INSIDE-NS пјҡиЎЁзӨәеңЁе®№еҷЁеҶ…йғЁжҳҫзӨәзҡ„ UID жҲ– GID
ID-OUTSIDE-NSпјҡиЎЁзӨәе®№еҷЁеӨ–жҳ е°„зҡ„зңҹе®һзҡ„ UID е’Ң GID
LENGTHпјҡиЎЁзӨәжҳ е°„зҡ„иҢғеӣҙпјҢдёҖиҲ¬дёә 1пјҢиЎЁзӨәдёҖдёҖеҜ№еә”
жҜ”еҰӮпјҢдёӢйқўе°ұжҳҜе°Ҷзңҹе®һзҡ„ uid=1000 зҡ„жҳ е°„дёәе®№еҷЁеҶ…зҡ„ uid =0пјҡ
$ cat /proc/8353/uid_map 0 1000 1
еҶҚжҜ”еҰӮпјҢдёӢйқўеҲҷиЎЁзӨәжҠҠ namesapce еҶ…йғЁд»Һ 0 ејҖе§Ӣзҡ„ uid жҳ е°„еҲ°еӨ–йғЁд»Һ 0 ејҖе§Ӣзҡ„ uidпјҢе…¶жңҖеӨ§иҢғеӣҙжҳҜж— з¬ҰеҸ· 32 дҪҚж•ҙеһӢ(дёӢйқўиҝҷжқЎе‘Ҫд»ӨжҳҜеңЁдё»жңәзҺҜеўғдёӯиҫ“е…Ҙзҡ„)гҖӮ
$ cat /proc/$$/uid_map 0 0 4294967295
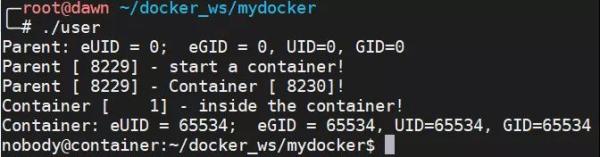
й»ҳи®Өжғ…еҶөпјҢи®ҫзҪ®дәҶ CLONE_NEWUSER еҸӮж•°дҪҶжҳҜжІЎжңүдҝ®ж”№дёҠиҝ°дёӨдёӘж–Ү件зҡ„иҜқпјҢе®№еҷЁдёӯй»ҳи®Өжғ…еҶөдёӢжҳҫзӨәдёә 65534пјҢиҝҷжҳҜеӣ дёәе®№еҷЁжүҫдёҚеҲ°зңҹжӯЈзҡ„ UIDпјҢжүҖд»Ҙе°ұи®ҫзҪ®дәҶжңҖеӨ§зҡ„ UIDгҖӮеҰӮдёӢйқўзҡ„д»Јз ҒжүҖзӨәпјҡ
#define _GNU_SOURCE #include <stdio.h> #include <stdlib.h> #include <sys/types.h> #include <sys/wait.h> #include <sys/mount.h> #include <sys/capability.h> #include <stdio.h> #include <sched.h> #include <signal.h> #include <unistd.h> #define STACK_SIZE (1024 * 1024) static char container_stack[STACK_SIZE]; char* const container_args[] = { "/bin/bash", NULL }; int container_main(void* arg) { printf("Container [%5d] - inside the container!\n", getpid()); printf("Container: eUID = %ld; eGID = %ld, UID=%ld, GID=%ld\n", (long) geteuid(), (long) getegid(), (long) getuid(), (long) getgid()); printf("Container [%5d] - setup hostname!\n", getpid()); //set hostname sethostname("container",10); execv(container_args[0], container_args); printf("Something's wrong!\n"); return 1; } int main() { const int gid=getgid(), uid=getuid(); printf("Parent: eUID = %ld; eGID = %ld, UID=%ld, GID=%ld\n", (long) geteuid(), (long) getegid(), (long) getuid(), (long) getgid()); printf("Parent [%5d] - start a container!\n", getpid()); int container_pid = clone(container_main, container_stack+STACK_SIZE, CLONE_NEWUTS | CLONE_NEWPID | CLONE_NEWUSER | SIGCHLD, NULL); printf("Parent [%5d] - Container [%5d]!\n", getpid(), container_pid); printf("Parent [%5d] - user/group mapping done!\n", getpid()); waitpid(container_pid, NULL, 0); printf("Parent - container stopped!\n"); return 0; }еҪ“жҲ‘д»Ҙ dawn иҝҷдёӘз”ЁжҲ·жү§иЎҢзҡ„иҜҘзЁӢеәҸзҡ„ж—¶еҖҷпјҢйӮЈд№ҲдјҡжҳҫзӨәеҰӮдёӢеӣҫжүҖзӨәзҡ„ж•ҲжһңгҖӮдҪҝз”Ё root з”ЁжҲ·зҡ„ж—¶еҖҷжҳҜеҗҢж ·зҡ„пјҡ

жҺҘдёӢеҺ»пјҢжҲ‘们иҰҒејҖе§ӢжқҘе®һзҺ°жҳ е°„зҡ„ж•ҲжһңдәҶпјҢд№ҹе°ұжҳҜи®© dawn иҝҷдёӘз”ЁжҲ·еңЁе®№еҷЁдёӯжҳҫзӨәдёә 0гҖӮд»Јз ҒжҳҜеҮ д№Һе®Ңе…ЁжӢҝиҖ—еӯҗеҸ”зҡ„еҚҡе®ўдёҠзҡ„пјҢй“ҫжҺҘеҸҜи§Ғж–Үжң«пјҡ
int pipefd[2]; void set_map(char* file, int inside_id, int outside_id, int len) { FILE* mapfd = fopen(file, "w"); if (NULL == mapfd) { perror("open file error"); return; } fprintf(mapfd, "%d %d %d", inside_id, outside_id, len); fclose(mapfd); } void set_uid_map(pid_t pid, int inside_id, int outside_id, int len) { char file[256]; sprintf(file, "/proc/%d/uid_map", pid); set_map(file, inside_id, outside_id, len); } int container_main(void* arg) { printf("Container [%5d] - inside the container!\n", getpid()); printf("Container: eUID = %ld; eGID = %ld, UID=%ld, GID=%ld\n", (long) geteuid(), (long) getegid(), (long) getuid(), (long) getgid()); /* зӯүеҫ…зҲ¶иҝӣзЁӢйҖҡзҹҘеҗҺеҶҚеҫҖдёӢжү§иЎҢпјҲиҝӣзЁӢй—ҙзҡ„еҗҢжӯҘпјү */ char ch; close(pipefd[1]); read(pipefd[0], &ch, 1); printf("Container [%5d] - setup hostname!\n", getpid()); //set hostname sethostname("container",10); //remount "/proc" to make sure the "top" and "ps" show container's information mount("proc", "/proc", "proc", 0, NULL); execv(container_args[0], container_args); printf("Something's wrong!\n"); return 1; } int main() { const int gid=getgid(), uid=getuid(); printf("Parent: eUID = %ld; eGID = %ld, UID=%ld, GID=%ld\n", (long) geteuid(), (long) getegid(), (long) getuid(), (long) getgid()); pipe(pipefd); printf("Parent [%5d] - start a container!\n", getpid()); int container_pid = clone(container_main, container_stack+STACK_SIZE, CLONE_NEWUTS | CLONE_NEWPID | CLONE_NEWNS | CLONE_NEWUSER | SIGCHLD, NULL); printf("Parent [%5d] - Container [%5d]!\n", getpid(), container_pid); //To map the uid/gid, // we need edit the /proc/PID/uid_map (or /proc/PID/gid_map) in parent set_uid_map(container_pid, 0, uid, 1); printf("Parent [%5d] - user/group mapping done!\n", getpid()); /* йҖҡзҹҘеӯҗиҝӣзЁӢ */ close(pipefd[1]); waitpid(container_pid, NULL, 0); printf("Parent - container stopped!\n"); return 0; }е®һзҺ°зҡ„жңҖз»Ҳж•ҲжһңеҰӮеӣҫжүҖзӨәпјҢеҸҜд»ҘзңӢеҲ°еңЁе®№еҷЁеҶ…йғЁе°Ҷ dawn иҝҷдёӘз”ЁжҲ· UID жҳҫзӨәдёәдәҶ 0(root)пјҢдҪҶе…¶е®һиҝҷдёӘе®№еҷЁдёӯзҡ„ /bin/bash иҝӣзЁӢиҝҳжҳҜд»ҘдёҖдёӘжҷ®йҖҡз”ЁжҲ·пјҢд№ҹе°ұжҳҜ dawn жқҘиҝҗиЎҢзҡ„пјҢеҸӘжҳҜжҳҫзӨәеҮәжқҘзҡ„ UID жҳҜ 0пјҢжүҖд»ҘеҪ“жҹҘзңӢ /root зӣ®еҪ•зҡ„ж—¶еҖҷиҝҳжҳҜжІЎжңүжқғйҷҗгҖӮ
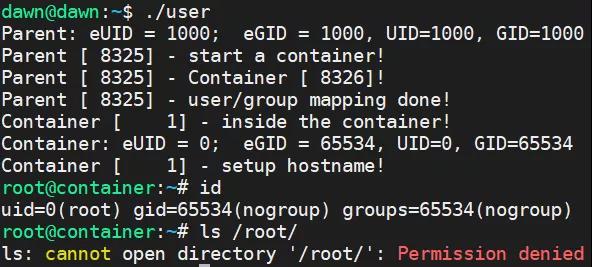
User Namespace жҳҜд»Ҙжҷ®йҖҡз”ЁжҲ·иҝҗиЎҢзҡ„пјҢдҪҶжҳҜеҲ«зҡ„ Namespace йңҖиҰҒ root жқғйҷҗпјҢйӮЈд№ҲеҪ“дҪҝз”ЁеӨҡдёӘ Namespace иҜҘжҖҺд№ҲеҠһе‘ў?жҲ‘们еҸҜд»Ҙе…Ҳз”ЁдёҖиҲ¬з”ЁжҲ·еҲӣе»ә User NamespaceпјҢ然еҗҺжҠҠиҝҷдёӘдёҖиҲ¬з”ЁжҲ·жҳ е°„жҲҗ rootпјҢйӮЈд№ҲеңЁе®№еҷЁеҶ…з”Ё root жқҘеҲӣе»әе…¶д»–зҡ„ NamespaceгҖӮ
Network Namespace
йҡ”зҰ»е®№еҷЁдёӯзҡ„зҪ‘з»ңпјҢжҜҸдёӘе®№еҷЁйғҪжңүиҮӘе·ұзҡ„иҷҡжӢҹзҪ‘з»ңжҺҘеҸЈе’Ң IP ең°еқҖгҖӮеңЁ Linux дёӯпјҢеҸҜд»ҘдҪҝз”Ё ip е‘Ҫд»ӨеҲӣе»ә Network Namespace(Docker зҡ„жәҗз ҒдёӯпјҢе®ғжІЎжңүдҪҝз”Ё ip е‘Ҫд»ӨпјҢиҖҢжҳҜиҮӘе·ұе®һзҺ°дәҶ ip е‘Ҫд»ӨеҶ…зҡ„дёҖдәӣеҠҹиғҪ)гҖӮ
дёӢйқўе°ұдҪҝз”Ё ip е‘Ҫд»ӨжқҘи®Іи§ЈдёҖдёӢ Network Namespace зҡ„жһ„е»әпјҢд»Ҙ bridge зҪ‘з»ңдёәдҫӢгҖӮbridge зҪ‘з»ңзҡ„жӢ“жү‘еӣҫдёҖиҲ¬еҰӮдёӢеӣҫжүҖзӨәпјҢе…¶дёӯ br0 жҳҜ Linux зҪ‘жЎҘгҖӮ
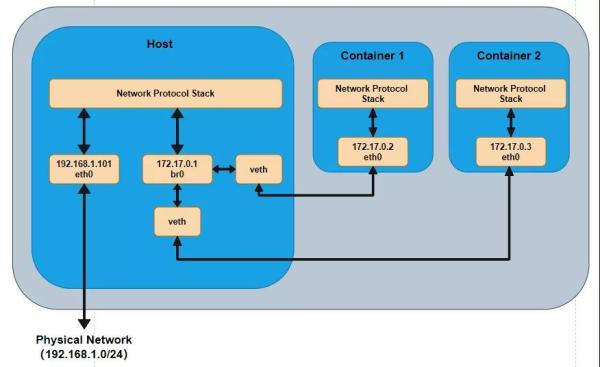
еңЁдҪҝз”Ё Docker зҡ„ж—¶еҖҷпјҢеҰӮжһңеҗҜеҠЁдёҖдёӘ Docker е®№еҷЁпјҢ并дҪҝз”Ё ip link show жҹҘзңӢеҪ“еүҚе®ҝдё»жңәдёҠзҡ„зҪ‘з»ңжғ…еҶөпјҢйӮЈд№ҲдҪ дјҡзңӢеҲ°жңүдёҖдёӘ docker0 иҝҳжңүдёҖдёӘ veth**** зҡ„иҷҡжӢҹзҪ‘еҚЎпјҢиҝҷдёӘ veth зҡ„иҷҡжӢҹзҪ‘еҚЎе°ұжҳҜдёҠеӣҫдёӯ vethпјҢиҖҢ docker0 е°ұзӣёеҪ“дәҺдёҠеӣҫдёӯзҡ„ br0гҖӮ
йӮЈд№ҲпјҢжҲ‘们еҸҜд»ҘдҪҝз”ЁдёӢйқўиҝҷдәӣе‘Ҫд»ӨеҚіеҸҜеҲӣе»әи·ҹ docker зұ»дјјзҡ„ж•Ҳжһң(еҸӮиҖғиҮӘиҖ—еӯҗеҸ”зҡ„еҚҡе®ўпјҢй“ҫжҺҘи§Ғж–Үжң«еҸӮиҖғпјҢз»“еҗҲдёҠеӣҫеҠ дәҶдёҖдәӣж–Үеӯ—)гҖӮ
## 1. йҰ–е…ҲпјҢжҲ‘们е…ҲеўһеҠ дёҖдёӘзҪ‘жЎҘ lxcbr0пјҢжЁЎд»ҝ docker0 brctl addbr lxcbr0 brctl stp lxcbr0 off ifconfig lxcbr0 192.168.10.1/24 up #дёәзҪ‘жЎҘи®ҫзҪ®IPең°еқҖ ## 2. жҺҘдёӢжқҘпјҢжҲ‘们иҰҒеҲӣе»әдёҖдёӘ network namespace пјҢе‘ҪеҗҚдёә ns1 # еўһеҠ дёҖдёӘ namesapce е‘Ҫд»Өдёә ns1 пјҲдҪҝз”Ё ip netns add е‘Ҫд»Өпјү ip netns add ns1 # жҝҖжҙ» namespace дёӯзҡ„ loopbackпјҢеҚі127.0.0.1пјҲдҪҝз”Ё ip netns exec ns1 зӣёеҪ“дәҺиҝӣе…ҘдәҶ ns1 иҝҷдёӘ namespaceпјҢйӮЈд№Ҳ ip link set dev lo up зӣёеҪ“дәҺеңЁ ns1 дёӯжү§иЎҢзҡ„пјү ip netns exec ns1 ip link set dev lo up ## 3. 然еҗҺпјҢжҲ‘们йңҖиҰҒеўһеҠ дёҖеҜ№иҷҡжӢҹзҪ‘еҚЎ # еўһеҠ дёҖеҜ№иҷҡжӢҹзҪ‘еҚЎпјҢжіЁж„Ҹе…¶дёӯзҡ„ veth зұ»еһӢгҖӮиҝҷйҮҢжңүдёӨдёӘиҷҡжӢҹзҪ‘еҚЎпјҡveth-ns1 е’Ң lxcbr0.1пјҢveth-ns1 зҪ‘еҚЎжҳҜиҰҒиў«е®үеҲ°е®№еҷЁдёӯзҡ„пјҢиҖҢ lxcbr0.1 еҲҷжҳҜиҰҒиў«е®үеҲ°зҪ‘жЎҘ lxcbr0 дёӯзҡ„пјҢд№ҹе°ұжҳҜдёҠеӣҫдёӯзҡ„ vethгҖӮ ip link add veth-ns1 type veth peer name lxcbr0.1 # жҠҠ veth-ns1 жҢүеҲ° namespace ns1 дёӯпјҢиҝҷж ·е®№еҷЁдёӯе°ұдјҡжңүдёҖдёӘж–°зҡ„зҪ‘еҚЎдәҶ ip link set veth-ns1 netns ns1 # жҠҠе®№еҷЁйҮҢзҡ„ veth-ns1 ж”№еҗҚдёә eth0 пјҲе®№еҷЁеӨ–дјҡеҶІзӘҒпјҢе®№еҷЁеҶ…е°ұдёҚдјҡдәҶпјү ip netns exec ns1 ip link set dev veth-ns1 name eth0 # дёәе®№еҷЁдёӯзҡ„зҪ‘еҚЎеҲҶй…ҚдёҖдёӘ IP ең°еқҖпјҢ并жҝҖжҙ»е®ғ ip netns exec ns1 ifconfig eth0 192.168.10.11/24 up # дёҠйқўжҲ‘们жҠҠ veth-ns1 иҝҷдёӘзҪ‘еҚЎжҢүеҲ°дәҶе®№еҷЁдёӯпјҢ然еҗҺжҲ‘们иҰҒжҠҠ lxcbr0.1 ж·»еҠ дёҠзҪ‘жЎҘдёҠ brctl addif lxcbr0 lxcbr0.1 # дёәе®№еҷЁеўһеҠ дёҖдёӘи·Ҝз”ұ规еҲҷпјҢи®©е®№еҷЁеҸҜд»Ҙи®ҝй—®еӨ–йқўзҡ„зҪ‘з»ң ip netns exec ns1 ip route add default via 192.168.10.1 ## 4. дёәиҝҷдёӘ namespace и®ҫзҪ® resolv.confпјҢиҝҷж ·пјҢе®№еҷЁеҶ…е°ұеҸҜд»Ҙи®ҝй—®еҹҹеҗҚдәҶ echo "nameserver 8.8.8.8" > conf/resolv.conf
дёҠйқўеҹәжң¬дёҠе°ұзӣёеҪ“дәҺ docker зҪ‘з»ңзҡ„еҺҹзҗҶпјҢеҸӘдёҚиҝҮпјҡ
Docker дёҚдҪҝз”Ё ip е‘Ҫд»ӨиҖҢжҳҜпјҢиҮӘе·ұе®һзҺ°дәҶ ip е‘Ҫд»ӨеҶ…зҡ„дёҖдәӣеҠҹиғҪгҖӮ
Docker зҡ„ resolv.conf жІЎжңүдҪҝз”Ёиҝҷж ·зҡ„ж–№ејҸпјҢиҖҢжҳҜе°Ҷе…¶еҶҷеҲ°жҢҮе®ҡзҡ„ resolv.conf дёӯпјҢд№ӢеҗҺеңЁеҗҜеҠЁе®№еҷЁзҡ„ж—¶еҖҷе°Ҷе…¶е’Ң hostnameгҖҒhost дёҖиө·д»ҘеҸӘиҜ»зҡ„ж–№ејҸеҠ иҪҪеҲ°е®№еҷЁзҡ„ж–Ү件系з»ҹдёӯгҖӮ
docker дҪҝз”ЁиҝӣзЁӢзҡ„ PID жқҘеҒҡ network namespace зҡ„еҗҚз§°гҖӮ
еҗҢзҗҶпјҢжҲ‘们иҝҳеҸҜд»ҘдҪҝз”ЁеҰӮдёӢзҡ„ж–№ејҸдёәжӯЈеңЁиҝҗиЎҢзҡ„ docker е®№еҷЁеўһеҠ дёҖдёӘж–°зҡ„зҪ‘еҚЎ
ip link add peerA type veth peer name peerB brctl addif docker0 peerA ip link set peerA up ip link set peerB netns ${container-pid} ip netns exec ${container-pid} ip link set dev peerB name eth2 ip netns exec ${container-pid} ip link set eth2 up ip netns exec ${container-pid} ip addr add ${ROUTEABLE_IP} dev eth2Namespace жғ…еҶөжҹҘзңӢ
Cgroup зҡ„ж“ҚдҪңжҺҘеҸЈжҳҜж–Ү件系з»ҹпјҢдҪҚдәҺ /sys/fs/cgroup дёӯгҖӮеҒҮеҰӮжғіжҹҘзңӢ namespace зҡ„жғ…еҶөеҗҢж ·еҸҜд»ҘжҹҘзңӢж–Ү件系з»ҹпјҢnamespace дё»иҰҒжҹҘзңӢ /proc/
жҲ‘们д»ҘдёҠйқўзҡ„ [PID Namespace зЁӢеәҸ](#PID Namespace) дёәдҫӢпјҢеҪ“иҝҷдёӘзЁӢеәҸиҝҗиЎҢиө·жқҘд№ӢеҗҺпјҢжҲ‘们еҸҜд»ҘзңӢеҲ°е…¶ PID дёә 11702гҖӮ
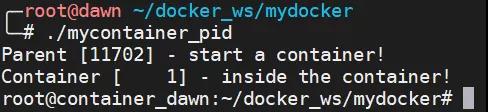
д№ӢеҗҺпјҢжҲ‘们дҝқжҢҒиҝҷдёӘеӯҗиҝӣзЁӢиҝҗиЎҢпјҢ然еҗҺжү“ејҖеҸҰдёҖдёӘ shellпјҢжҹҘзңӢиҝҷдёӘзЁӢеәҸеҲӣе»әзҡ„еӯҗиҝӣзЁӢзҡ„ PIDпјҢд№ҹе°ұжҳҜе®№еҷЁдёӯиҝҗиЎҢзҡ„иҝӣзЁӢеңЁдё»жңәдёӯзҡ„ PIDгҖӮ
жңҖеҗҺпјҢжҲ‘们еҲҶеҲ«жҹҘзңӢ /proc/11702/ns е’Ң /proc/11703/ns иҝҷдёӨдёӘзӣ®еҪ•зҡ„жғ…еҶөпјҢд№ҹе°ұжҳҜжҹҘзңӢиҝҷдёӨдёӘиҝӣзЁӢзҡ„ namespace жғ…еҶөгҖӮеҸҜд»ҘзңӢеҲ°е…¶дёӯ cgroupгҖҒipcгҖҒmntгҖҒnetгҖҒuser йғҪжҳҜеҗҢдёҖдёӘ IDпјҢиҖҢ pidгҖҒuts жҳҜдёҚеҗҢзҡ„ IDгҖӮеҰӮжһңдёӨдёӘиҝӣзЁӢзҡ„ namespace зј–еҸ·зӣёеҗҢпјҢйӮЈд№ҲиЎЁзӨәиҝҷдёӨдёӘиҝӣзЁӢдҪҚдәҺеҗҢдёҖдёӘ namespace дёӯпјҢеҗҰеҲҷдҪҚдәҺдёҚеҗҢ namespace дёӯгҖӮ
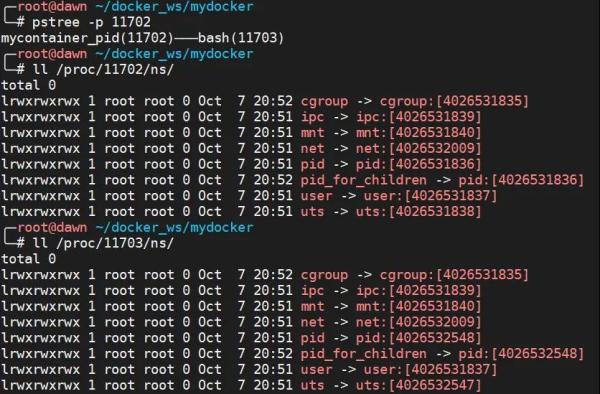
еҰӮжһңеҸҜд»ҘжҹҘзңӢ ns зҡ„жғ…еҶөд№ӢеӨ–пјҢиҝҷдәӣж–Ү件дёҖж—Ұиў«жү“ејҖпјҢеҸӘиҰҒ fd иў«еҚ з”ЁзқҖпјҢеҚідҪҝ namespace дёӯжүҖжңүиҝӣзЁӢйғҪе·Із»Ҹз»“жқҹдәҶпјҢйӮЈд№ҲеҲӣе»әзҡ„ namespace д№ҹдјҡдёҖзӣҙеӯҳеңЁгҖӮжҜ”еҰӮеҸҜд»ҘдҪҝз”Ё mount --bind /proc/11703/ns/uts ~/utsпјҢи®© 11703 иҝҷдёӘиҝӣзЁӢзҡ„ UTS Namespace дёҖзӣҙеӯҳеңЁгҖӮ
жҖ»з»“
Namespace жҠҖжңҜе®һйҷ…дёҠдҝ®ж”№дәҶеә”з”ЁиҝӣзЁӢзңӢеҫ…ж•ҙдёӘи®Ўз®—жңәвҖңи§ҶеӣҫвҖқпјҢеҚіе®ғзҡ„вҖқи§ҶеӣҫвҖңе·Із»Ҹиў«ж“ҚдҪңзі»з»ҹеҒҡдәҶйҷҗеҲ¶пјҢеҸӘиғҪвҖқзңӢеҲ°вҖңжҹҗдәӣжҢҮе®ҡзҡ„еҶ…е®№пјҢиҝҷд»…д»…еҜ№еә”з”ЁиҝӣзЁӢдә§з”ҹдәҶеҪұе“ҚгҖӮдҪҶжҳҜеҜ№е®ҝдё»жңәжқҘиҜҙпјҢиҝҷдәӣиў«йҡ”зҰ»дәҶзҡ„иҝӣзЁӢпјҢе…¶е®һиҝҳжҳҜиҝӣзЁӢпјҢи·ҹе®ҝдё»жңәдёҠе…¶д»–иҝӣзЁӢе№¶ж— еӨӘеӨ§еҢәеҲ«пјҢйғҪз”ұе®ҝдё»жңәз»ҹдёҖз®ЎзҗҶгҖӮеҸӘдёҚиҝҮиҝҷдәӣиў«йҡ”зҰ»зҡ„иҝӣзЁӢжӢҘжңүйўқеӨ–и®ҫзҪ®иҝҮзҡ„ Namespace еҸӮж•°гҖӮйӮЈд№Ҳ Docker йЎ№зӣ®еңЁиҝҷйҮҢжү®жј”зҡ„пјҢжӣҙеӨҡжҳҜж—Ғи·ҜејҸзҡ„иҫ…еҠ©е’Ңз®ЎзҗҶе·ҘдҪңгҖӮеҰӮдёӢе·ҰеӣҫжүҖзӨә
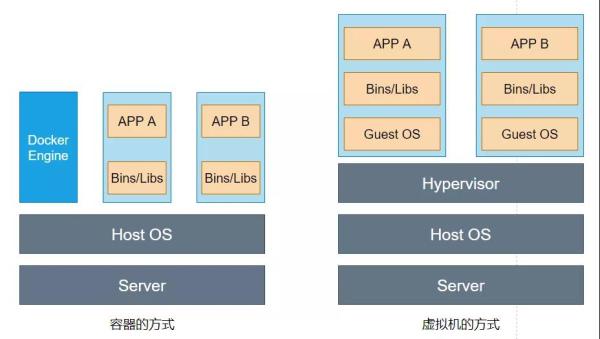
еӣ жӯӨпјҢзӣёжҜ”иҷҡжӢҹжңәзҡ„ж–№ејҸпјҢе®№еҷЁдјҡжӣҙеҸ—ж¬ўиҝҺгҖӮиҝҷжҳҜеҒҮеҰӮдҪҝз”ЁиҷҡжӢҹжңәзҡ„ж–№ејҸдҪңдёәеә”з”ЁжІҷзӣ’пјҢйӮЈд№Ҳеҝ…йЎ»иҰҒз”ұ Hypervisor жқҘиҙҹиҙЈеҲӣе»әиҷҡжӢҹжңәпјҢиҝҷдёӘиҷҡжӢҹжңәжҳҜзңҹе®һеӯҳеңЁзҡ„пјҢ并且йҮҢйқўеҝ…йЎ»иҰҒиҝҗиЎҢдёҖдёӘе®Ңж•ҙзҡ„ Guest OS жүҚиғҪжү§иЎҢз”ЁжҲ·зҡ„еә”з”ЁиҝӣзЁӢгҖӮиҝҷж ·е°ұеҜјиҮҙдәҶйҮҮз”ЁиҷҡжӢҹжңәзҡ„ж–№ејҸд№ӢеҗҺпјҢдёҚеҸҜйҒҝе…Қең°еёҰжқҘйўқеӨ–зҡ„иө„жәҗж¶ҲиҖ—е’ҢеҚ з”ЁгҖӮж №жҚ®е®һйӘҢпјҢдёҖдёӘиҝҗиЎҢзқҖ CentOS зҡ„ KVM иҷҡжӢҹжңәеҗҜеҠЁеҗҺпјҢеңЁдёҚеҒҡдјҳеҢ–зҡ„жғ…еҶөдёӢпјҢиҷҡжӢҹжңәе°ұйңҖиҰҒеҚ з”Ё 100-200 MB еҶ…еӯҳгҖӮжӯӨеӨ–пјҢз”ЁжҲ·еә”з”ЁиҝҗиЎҢеңЁиҷҡжӢҹжңәдёӯпјҢе®ғеҜ№е®ҝдё»жңәж“ҚдҪңзі»з»ҹзҡ„и°ғз”Ёе°ұдёҚеҸҜйҒҝе…Қең°иҰҒз»ҸиҝҮиҷҡжӢҹжңәиҪҜ件зҡ„жӢҰжҲӘе’ҢеӨ„зҗҶпјҢиҝҷжң¬иә«е°ұжҳҜдёҖеұӮж¶ҲиҖ—пјҢе°Өе…¶еҜ№иө„жәҗгҖҒзҪ‘з»ңе’ҢзЈҒзӣҳ IO зҡ„жҚҹиҖ—йқһеёёеӨ§гҖӮ
иҖҢеҒҮеҰӮдҪҝз”Ёе®№еҷЁзҡ„ж–№ејҸпјҢе®№еҷЁеҢ–д№ӢеҗҺеә”з”Ёжң¬иҙЁиҝҳжҳҜе®ҝдё»жңәдёҠзҡ„дёҖдёӘиҝӣзЁӢпјҢиҝҷд№ҹе°ұж„Ҹе‘ізқҖеӣ дёәиҷҡжӢҹжңәеҢ–еёҰжқҘзҡ„жҖ§иғҪжҚҹиҖ—жҳҜдёҚеӯҳеңЁзҡ„;иҖҢеҸҰдёҖж–№йқўдҪҝз”Ё Namespace дҪңдёәйҡ”зҰ»жүӢж®өзҡ„е®№еҷЁе№¶дёҚйңҖиҰҒеҚ•зӢ¬зҡ„ Guest OSпјҢиҝҷе°ұдҪҝеҫ—е®№еҷЁйўқеӨ–зҡ„иө„жәҗеҚ з”ЁеҮ д№ҺеҸҜд»ҘеҝҪз•ҘдёҚи®ЎгҖӮ
жҖ»еҫ—жқҘиҜҙпјҢвҖңж•ҸжҚ·вҖқе’ҢвҖңй«ҳжҖ§иғҪвҖқжҳҜе®№еҷЁзӣёеҜ№дәҺиҷҡжӢҹжңәжңҖеӨ§зҡ„дјҳеҠҝпјҢд№ҹе°ұжҳҜе®№еҷЁиғҪеңЁ PaaS иҝҷз§ҚжӣҙеҠ з»ҶзІ’еәҰзҡ„иө„жәҗз®ЎзҗҶе№іеҸ°дёҠеӨ§иЎҢе…¶йҒ“зҡ„йҮҚиҰҒеҺҹеӣ гҖӮ
дҪҶжҳҜ!еҹәдәҺ Linux Namespace зҡ„йҡ”зҰ»жңәеҲ¶зӣёжҜ”дәҺиҷҡжӢҹеҢ–жҠҖжңҜд№ҹжңүеҫҲеӨҡдёҚи¶ід№ӢеӨ„пјҢе…¶дёӯжңҖдё»иҰҒзҡ„й—®йўҳе°ұжҳҜйҡ”зҰ»дёҚеҪ»еә•гҖӮ
йҰ–е…ҲпјҢе®№еҷЁеҸӘжҳҜиҝҗиЎҢеңЁе®ҝдё»жңәдёҠзҡ„дёҖз§Қзү№ж®ҠиҝӣзЁӢпјҢйӮЈд№Ҳе®№еҷЁд№Ӣй—ҙдҪҝз”Ёзҡ„иҝҳжҳҜеҗҢдёҖдёӘе®ҝдё»жңәдёҠзҡ„ж“ҚдҪңзі»з»ҹгҖӮе°Ҫз®ЎеҸҜд»ҘеңЁе®№еҷЁйҮҢйқўйҖҡиҝҮ mount namesapce еҚ•зӢ¬жҢӮиҪҪе…¶д»–дёҚеҗҢзүҲжң¬зҡ„ж“ҚдҪңзі»з»ҹж–Ү件пјҢжҜ”еҰӮ centosгҖҒubuntuпјҢдҪҶжҳҜиҝҷ并дёҚиғҪж”№еҸҳе…ұдә«е®ҝдё»жңәеҶ…ж ёзҡ„дәӢе®һгҖӮиҝҷе°ұж„Ҹе‘ізқҖдҪ иҰҒеңЁ windows дёҠиҝҗиЎҢ Linux е®№еҷЁпјҢжҲ–иҖ…еңЁдҪҺзүҲжң¬зҡ„ Linux е®ҝдё»жңәдёҠиҝҗиЎҢй«ҳзүҲжң¬зҡ„ Linux е®№еҷЁйғҪжҳҜиЎҢдёҚйҖҡзҡ„гҖӮ
иҖҢжӢҘжңүиҷҡжӢҹжңәжҠҖжңҜе’ҢзӢ¬з«Ӣ Guest OS зҡ„иҷҡжӢҹжңәе°ұиҰҒж–№дҫҝеӨҡдәҶгҖӮ
е…¶ж¬ЎпјҢеңЁ Linux еҶ…ж ёдёӯпјҢжңүеҫҲеӨҡиө„жәҗе’ҢеҜ№иұЎйғҪжҳҜдёҚиғҪиў« namespace еҢ–зҡ„пјҢжҜ”еҰӮж—¶й—ҙгҖӮеҒҮеҰӮдҪ зҡ„е®№еҷЁдёӯзҡ„зЁӢеәҸдҪҝз”Ё settimeofday(2) зі»з»ҹи°ғз”Ёдҝ®ж”№дәҶж—¶й—ҙпјҢж•ҙдёӘе®ҝдё»жңәзҡ„ж—¶й—ҙйғҪдјҡиў«йҡҸд№Ӣдҝ®ж”№гҖӮ
зӣёжҜ”иҷҡжӢҹжңәйҮҢйқўеҸҜд»ҘйҡҸж„ҸжҠҳи…ҫзҡ„иҮӘз”ұеәҰпјҢеңЁе®№еҷЁйҮҢйғЁзҪІеә”з”Ёзҡ„ж—¶еҖҷпјҢвҖңд»Җд№ҲиғҪеҒҡпјҢд»Җд№ҲдёҚиғҪеҒҡвҖқ жҳҜз”ЁжҲ·еҝ…йЎ»иҖғиҷ‘зҡ„дёҖдёӘй—®йўҳгҖӮд№ӢеӨ–пјҢе®№еҷЁз»ҷеә”з”ЁжҡҙйңІеҮәжқҘзҡ„ж”»еҮ»йқўжҳҜзӣёеҪ“еӨ§зҡ„пјҢеә”з”ЁвҖңи¶ҠзӢұвҖқзҡ„йҡҫеәҰд№ҹжҜ”иҷҡжӢҹжңәдҪҺеҫҲеӨҡгҖӮиҷҪ然пјҢе®һи·өдёӯеҸҜд»ҘдҪҝз”Ё Seccomp зӯүжҠҖжңҜеҜ№е®№еҷЁеҶ…йғЁеҸ‘иө·зҡ„жүҖжңүзі»з»ҹи°ғз”ЁиҝӣиЎҢиҝҮж»Өе’Ңз”„еҲ«жқҘиҝӣиЎҢе®үе…ЁеҠ еӣәпјҢдҪҶиҝҷз§Қж–№ејҸеӣ дёәеӨҡдәҶдёҖеұӮеҜ№зі»з»ҹи°ғз”Ёзҡ„иҝҮж»ӨпјҢд№ҹдјҡеҜ№е®№еҷЁзҡ„жҖ§иғҪдә§з”ҹеҪұе“ҚгҖӮеӣ жӯӨпјҢеңЁз”ҹдә§зҺҜеўғдёӯжІЎжңүдәәж•ўжҠҠиҝҗиЎҢеңЁзү©зҗҶжңәдёҠзҡ„ Linux е®№еҷЁзӣҙжҺҘжҡҙйңІеҲ°е…¬зҪ‘дёҠгҖӮ
еҸҰеӨ–пјҢе®№еҷЁжҳҜдёҖдёӘвҖңеҚ•иҝӣзЁӢвҖқжЁЎеһӢгҖӮе®№еҷЁзҡ„жң¬иҙЁжҳҜдёҖдёӘиҝӣзЁӢпјҢз”ЁжҲ·зҡ„еә”з”ЁиҝӣзЁӢе®һйҷ…дёҠе°ұжҳҜе®№еҷЁйҮҢ PID=1 зҡ„иҝӣзЁӢпјҢиҖҢиҝҷдёӘиҝӣзЁӢд№ҹжҳҜеҗҺз»ӯеҲӣе»әзҡ„жүҖжңүиҝӣзЁӢзҡ„зҲ¶иҝӣзЁӢгҖӮиҝҷд№ҹе°ұж„Ҹе‘ізқҖпјҢеңЁдёҖдёӘе®№еҷЁдёӯпјҢдҪ жІЎеҠһжі•еҗҢж—¶иҝҗиЎҢдёӨдёӘдёҚеҗҢзҡ„еә”з”ЁпјҢйҷӨйқһиғҪдәӢе…ҲжүҫеҲ°дёҖдёӘе…¬е…ұзҡ„ PID=1 зҡ„зЁӢеәҸжқҘе……еҪ“дёӨиҖ…зҡ„зҲ¶иҝӣзЁӢпјҢжҜ”еҰӮдҪҝз”Ё systemd жҲ–иҖ… supervisordгҖӮе®№еҷЁзҡ„и®ҫи®ЎжӣҙеӨҡжҳҜеёҢжңӣе®№еҷЁе’Ңеә”з”ЁеҗҢз”ҹе‘Ҫе‘Ёжңҹзҡ„пјҢиҖҢдёҚжҳҜе®№еҷЁиҝҳеңЁиҝҗиЎҢпјҢиҖҢйҮҢйқўзҡ„еә”з”Ёж—©е·Із»ҸжҢӮдәҶгҖӮ
д»ҘдёҠе°ұжҳҜвҖңNamespaceжңәеҲ¶жҖҺд№ҲзҗҶи§ЈвҖқиҝҷзҜҮж–Үз« зҡ„жүҖжңүеҶ…е®№пјҢж„ҹи°ўеҗ„дҪҚзҡ„йҳ…иҜ»пјҒзӣёдҝЎеӨ§е®¶йҳ…иҜ»е®ҢиҝҷзҜҮж–Үз« йғҪжңүеҫҲеӨ§зҡ„收иҺ·пјҢе°Ҹзј–жҜҸеӨ©йғҪдјҡдёәеӨ§е®¶жӣҙж–°дёҚеҗҢзҡ„зҹҘиҜҶпјҢеҰӮжһңиҝҳжғіеӯҰд№ жӣҙеӨҡзҡ„зҹҘиҜҶпјҢиҜ·е…іжіЁдәҝйҖҹдә‘иЎҢдёҡиө„и®Ҝйў‘йҒ“гҖӮ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ