жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
жң¬зҜҮеҶ…е®№дё»иҰҒи®Іи§ЈвҖңеҰӮдҪ•д»Һеә•еұӮиҒҠдёӢIOеӨҡи·ҜеӨҚз”ЁжЁЎеһӢвҖқпјҢж„ҹе…ҙи¶Јзҡ„жңӢеҸӢдёҚеҰЁжқҘзңӢзңӢгҖӮжң¬ж–Үд»Ӣз»Қзҡ„ж–№жі•ж“ҚдҪңз®ҖеҚ•еҝ«жҚ·пјҢе®һз”ЁжҖ§ејәгҖӮдёӢйқўе°ұи®©е°Ҹзј–жқҘеёҰеӨ§е®¶еӯҰд№ вҖңеҰӮдҪ•д»Һеә•еұӮиҒҠдёӢIOеӨҡи·ҜеӨҚз”ЁжЁЎеһӢвҖқеҗ§!
еҪ“жҲ‘们еҺ»йқўиҜ•зҡ„ж—¶еҖҷпјҢй—®еҲ°дәҶ redisпјҢnginxпјҢnetty他们зҡ„еә•еұӮжЁЎеһӢеҲҶеҲ«жҳҜд»Җд№Ҳ?
redis -> epoll
nginx-> epoll
netty-> epoll?
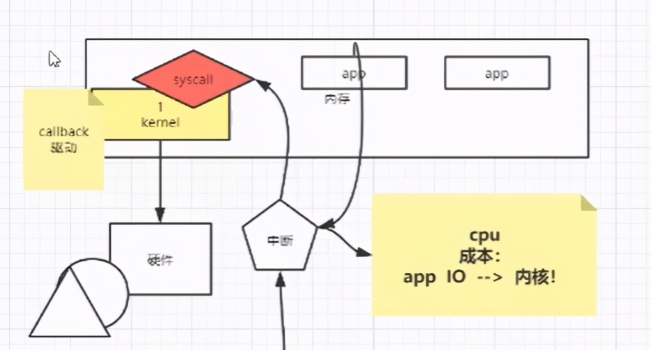
йңҖиҰҒд»Һж“ҚдҪңзі»з»ҹзҡ„еұӮйқўдёҠжқҘи°Ҳ
еҪ“жҲ‘们ејҖжңәзҡ„ж—¶еҖҷпјҢйҰ–е…Ҳиў«еҠ иҪҪиҝӣеҶ…еӯҳзҡ„жҳҜжҲ‘们зҡ„Kernel(еҶ…ж ё)пјҢеҶ…ж ёжҳҜз”ЁдәҺз®ЎзҗҶжҲ‘们зҡ„硬件зҡ„пјҢеҗҢж—¶еҶ…ж ёиҝҳдјҡеҲӣе»әдёҖдёӘGDTиЎЁпјҢ然еҗҺеҲ’еҲҶдёӨдёӘз©әй—ҙ(з”ЁжҲ·з©әй—ҙе’ҢеҶ…ж ёз©әй—ҙ)пјҢеҗҢж—¶з©әй—ҙдёӯзҡ„еҶ…е®№жҳҜејҖеҗҜдәҶдҝқжҠӨжЁЎејҸпјҢж— жі•иў«дҝ®ж”№зҡ„гҖӮ
еҗҢж—¶иҝҳжңүдёҖдёӘCPUзҡ„жҰӮеҝөпјҢCPUжңүиҮӘе·ұзҡ„жҢҮд»ӨйӣҶпјҢ并且жҢҮд»ӨйӣҶжҳҜеҲҶдәҶеҮ дёӘзә§еҲ«зҡ„пјҢеҲҶеҲ«жҳҜд»Һ0~3зҡ„пјҢKernelеұһдәҺ0зә§еҲ«гҖӮAPPеҸӘиғҪз”Ёзә§еҲ«дёә3зҡ„жҢҮд»ӨйӣҶгҖӮ
д»ҺдёҠйқўжҲ‘们еҸҜд»ҘзҹҘйҒ“пјҢжҲ‘们зҡ„еә”з”ЁзЁӢеәҸжҳҜж— жі•зӣҙжҺҘи®ҝй—®жҲ‘们зҡ„Kernelзҡ„пјҢд№ҹе°ұжҳҜзЁӢеәҸдёҚиғҪзӣҙжҺҘи®ҝй—®жҲ‘们зҡ„зЈҒзӣҳпјҢеЈ°еҚЎпјҢзҪ‘еҚЎзӯүи®ҫеӨҮпјҢеҸӘжңүеҶ…ж ёжүҚеҸҜд»Ҙи®ҝй—®пјҢйӮЈжҲ‘们жҖҺд№ҲеҠһ?
еҸӘжңүAPPйҖҡиҝҮи°ғз”ЁKernelжҸҗдҫӣзҡ„ syscall(зі»з»ҹиҪҜдёӯж–ӯе’ҢзЎ¬дёӯж–ӯ)жқҘиҺ·еҸ–硬件дёӯзҡ„еҶ…е®№гҖӮ
зЎ¬дёӯж–ӯпјҡзЎ¬дёӯж–ӯжҢҮзҡ„жҳҜжҲ‘们зҡ„й”®зӣҳпјҢжҢүдёӢдёҖдёӘжҢүй”®зҡ„ж—¶еҖҷпјҢе°ұдјҡи§ҰеҸ‘жҲ‘们зҡ„зЎ¬дёӯж–ӯпјҢд№ҹе°ұжҳҜеҶ…ж ёдјҡжңүдёҖдёӘдёӯж–ӯеҸ·пјҢ然еҗҺеҫ—еҲ°дёҖдёӘcallbackзҡ„еӣһи°ғеҮҪж•°
иҜҙеҲ°иҝҷйҮҢпјҢе…¶е®һе°ұжҳҜдёәдәҶеј•еҮәдёҖдёӘ жҰӮеҝөпјҢе°ұжҳҜ IO е’Ң еҶ…ж ёд№Ӣй—ҙзҡ„жҲҗжң¬й—®йўҳ
/** * жңҚеҠЎеҷЁиҜ»еҸ–ж–Ү件 * @author: йҷҢжәӘ * @create: 2020-07-01-20:40 */ public class TestSocket { public static void main(String[] args) throws IOException { ServerSocket server = new ServerSocket(8090); System.out.println("step1: new ServerSocket(8090)"); while(true) { Socket client = server.accept(); System.out.println("step2: client " + client.getPort()); new Thread(() -> { try { InputStream in = client.getInputStream(); BufferedReader reader = new BufferedReader(new InputStreamReader(in)); while(true) { System.out.println(reader.readLine()); } } catch (IOException e) { e.printStackTrace(); } }, "t1").start(); } } }
жҠ“еҸ–зЁӢеәҸеҜ№еҶ…ж ёжңүжІЎжңүзі»з»ҹи°ғз”ЁпјҢ然еҗҺиҫ“еҮә
strace -ff -o ./ooxx java TestSocket
然еҗҺжҲ‘们жү§иЎҢдёҠйқўзҡ„зЁӢеәҸпјҢеҫ—еҲ°жҲ‘们зҡ„з»“жһң
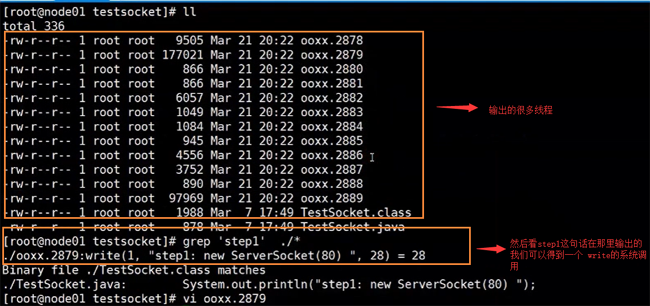
然еҗҺжҲ‘们еңЁйҖҡиҝҮjpsе‘Ҫд»ӨпјҢжҹҘзңӢеҪ“еүҚTestSocketзҡ„иҝӣзЁӢеҸ·
jps 2912 Jps 2878 TestSocket
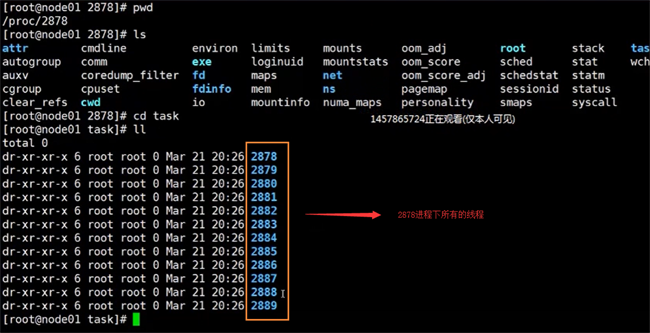
然еҗҺжҲ‘们еңЁиҝӣе…ҘдёӢйқўзҡ„иҝҷдёӘзӣ®еҪ•дёӢпјҢеҗҜеҠЁ2878жҳҜзәҝзЁӢзҡ„idеҸ·пјҢиҝҷдёӘзӣ®еҪ•е°ұжҳҜеӯҳж”ҫиҜҘзәҝзЁӢзҡ„дёҖдәӣдҝЎжҒҜ
cd /proc/2878
жҲ‘们еҸҜд»ҘзңӢеҲ°2878иҝӣзЁӢдёӢзҡ„пјҢйҖҡиҝҮжҹҘзңӢtaskзӣ®еҪ•пјҢеҸҜд»ҘзңӢеҲ°жүҖжңүзәҝзЁӢж•°
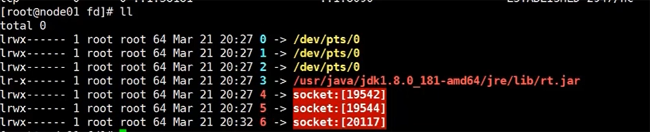
иҝҳжңүдёҖдёӘзӣ®еҪ•пјҢе°ұжҳҜ fdзӣ®еҪ•пјҢеңЁиҜҘзӣ®еҪ•дёӢпјҢе°ұжҳҜжҲ‘们зҡ„дёҖдәӣIOжөҒ
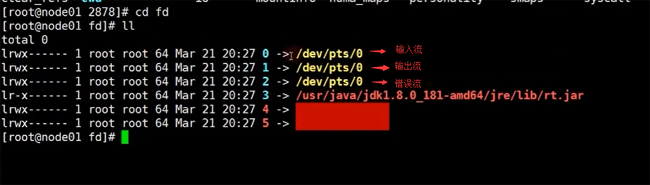
дёҠйқўзҡ„0,1,2пјҢеҲҶеҲ«еҜ№еә”зқҖ иҫ“е…ҘжөҒпјҢиҫ“еҮәжөҒе’Ңй”ҷиҜҜжөҒгҖӮеңЁjavaйҮҢйқўжҲ‘们жөҒе°ұжҳҜеҜ№иұЎпјҢиҖҢеңЁlinuxзі»з»ҹдёӯпјҢжөҒе°ұжҳҜдёҖдёӘдёӘзҡ„ж–Ү件гҖӮеҗҺйқўзҡ„4,5 е°ұеҜ№еә”зқҖжҲ‘们зҡ„socketйҖҡдҝЎпјҢеҲҶеҲ«еҜ№еә”зқҖipv4 е’Ң ipv6

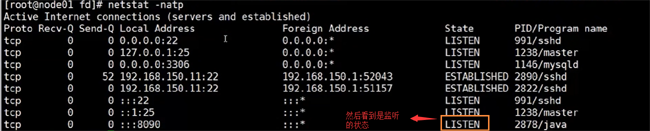
йҖҡиҝҮnetstatе‘Ҫд»ӨжҹҘзңӢ
然еҗҺжҲ‘们дҪҝз”ЁncиҝһжҺҘ 8090з«ҜеҸЈ
nc localhost 8090
жҲ‘们жү§иЎҢе®ҢеҗҺпјҢйҖҡиҝҮnetstatе‘Ҫд»ӨжҹҘзңӢ пјҢеҸ‘зҺ°еӨҡдәҶдёӘиҝһжҺҘзҡ„зҠ¶жҖҒ
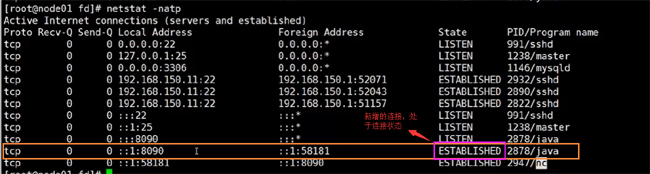
然еҗҺеңЁзңӢж–Ү件йҮҢйқўпјҢд№ҹеӨҡдәҶдёҖдёӘsocket
жҲ‘们жҹҘзңӢзі»з»ҹи°ғз”ЁпјҢеҸ‘зҺ°йҖҡиҝҮзі»з»ҹи°ғз”ЁжҺҘ收дәҶдёҖдёӘ58181з«ҜеҸЈеҸ·зҡ„иҜ·жұӮпјҢеңЁеүҚйқўжҲ‘们иҝҳиғҪеӨҹзңӢеҲ°5пјҢиҝҷдёӘ5е…¶е®һе°ұжҳҜеҜ№еә”зҡ„дёҠеӣҫйҮҢйқўзҡ„socketпјҢиө°зҡ„жҳҜipv4гҖӮ
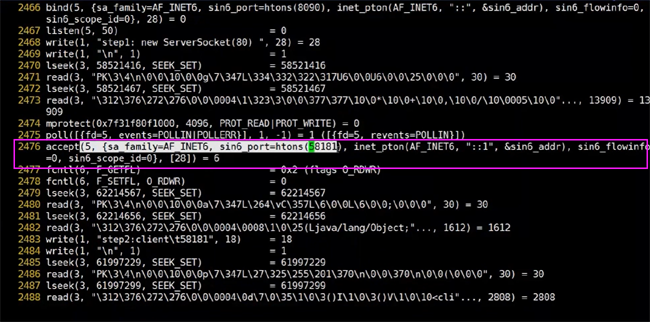
д»ҺиҝҷйҮҢе…¶е®һжҲ‘们е°ұеҸҜд»ҘзҹҘйҒ“дәҶпјҢжҲ‘们еҺҹжқҘи°ғз”ЁдёӯеҶҷзҡ„д»Јз Ғ
Socket client = server.accept();
еҜ№еә”еҲ°зі»з»ҹеұӮйқўпјҢд№ҹжҳҜи°ғз”ЁдәҶзі»з»ҹзҡ„ж–№жі•гҖӮ
еҗҢж—¶е…ідәҺзі»з»ҹи°ғз”ЁпјҢжңүд»ҘдёӢеҮ з§Қж–№ејҸ
bind
connect
listen
select
socket
йҰ–е…ҲжҲ‘们йңҖиҰҒзҹҘйҒ“пјҢjavaе…¶е®һжҳҜдёҖз§Қи§ЈйҮҠеһӢиҜӯиЁҖпјҢйҖҡиҝҮJVM иҷҡжӢҹжңәе°ҶжҲ‘们зҡ„.javaж–Ү件иҪ¬жҚўдёәеӯ—иҠӮз Ғж–Ү件пјҢ然еҗҺи°ғз”ЁжҲ‘们osдёӯзҡ„syscallж–№жі•пјҢжҲ‘们еҝ…йЎ»жҳҺзЎ®зҡ„жҳҜпјҢж— и®әжҖҺд№Ҳи°ғз”ЁпјҢдёҖе®ҡжңҖеҗҺиҰҒйҖҡиҝҮи°ғз”ЁеҶ…ж ёзҡ„ж–№жі•пјҢ然еҗҺи°ғз”ЁжҲ‘们зҡ„硬件гҖӮ
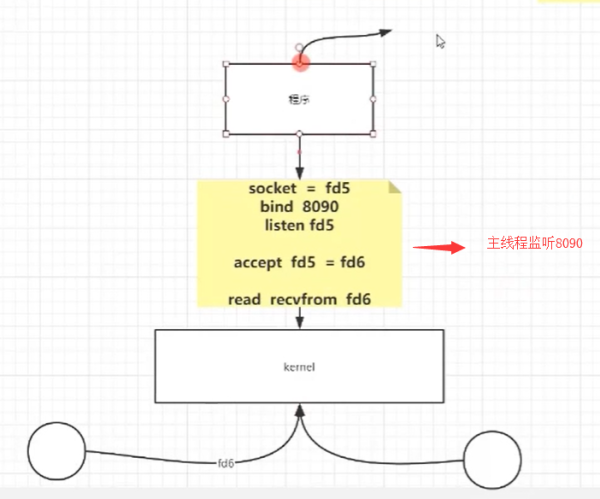
дёҠиҝ°зҡ„жЁЎеһӢпјҢе°ұжҳҜBIOзҡ„йҖҡдҝЎпјҢжҳҜиҝҷйҮҢйқўжңүеҫҲеӨҡйҳ»еЎһпјҢжҲ‘们еҸӘиғҪеӨҹйҖҡиҝҮеӨҡдёӘзәҝзЁӢжқҘйҒҝе…Қдё»зәҝзЁӢзҡ„йҳ»еЎһгҖӮдҪҶжҳҜд»ҺдёҠйқўжҲ‘们еҸҜд»ҘзҹҘйҒ“пјҢеҰӮжһңжңүеӨ§йҮҸең°иҝһжҺҘиҝҮжқҘпјҢйӮЈжңҚеҠЎеҷЁйңҖиҰҒеҲӣе»әеҫҲеӨҡдёӘзәҝзЁӢдёҺд№ӢеҜ№еә”пјҢ并且зәҝзЁӢзҡ„еҲӣе»әд№ҹжҳҜйңҖиҰҒж¶ҲиҖ—иө„жәҗзҡ„пјҢеӣ дёәзәҝзЁӢдҪҝз”Ёзҡ„ж ҲжҳҜзӢ¬еҚ зҡ„(ж ҲеӨ§е°Ҹй»ҳи®Ө1MB)пјҢеҗҢж—¶CPUзҡ„иө„жәҗи°ғеәҰд№ҹжҳҜйңҖиҰҒжөӘиҙ№гҖӮ
жңҖж №жң¬зҡ„еҺҹеӣ е°ұжҳҜеӣ дёә BIOжҳҜйҳ»еЎһзҡ„пјҢжүҚдјҡйҖ жҲҗдёҠйқўзҡ„й—®йўҳгҖӮ
еӣ дёәBIOеӯҳеңЁзәҝзЁӢйҳ»еЎһзҡ„й—®йўҳпјҢеҗҺйқўе°ұжҸҗеҮәдәҶNIOзҡ„жҰӮеҝөпјҢеңЁNIOдёӯпјҢжңүC10Kзҡ„й—®йўҳпјҢC10K = 10000дёӘе®ўжҲ·з«ҜгҖӮдҪҶжҳҜеңЁе’ҢдҪ иҝһжҺҘзҡ„жңҚеҠЎеҷЁдёӯпјҢе…¶е®һжІЎжңүеӨҡе°‘з»ҷдҪ еҸ‘йҖҒж•°жҚ®дәҶпјҢжүҖд»ҘжҲ‘们йңҖиҰҒеҒҡзҡ„е°ұжҳҜпјҢжҜҸеҪ“жңүдәәеҸ‘йҖҒж¶ҲжҒҜзҡ„ж—¶еҖҷпјҢжҲ‘жүҚе’Ңе®ғиҝӣиЎҢиҝһжҺҘгҖӮ
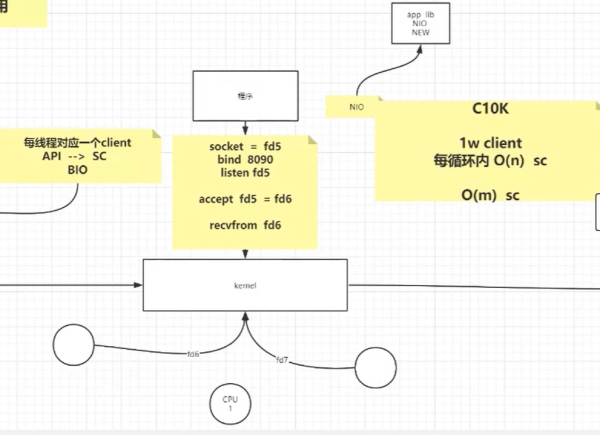
д№ҹе°ұжҳҜжҜҸж¬ЎйғҪйңҖиҰҒйҒҚеҺҶ10000дёӘе®ўжҲ·з«ҜпјҢжҳҜйқһеёёиҖ—иҙ№ж—¶й—ҙе‘ўпјҢеӣ дёәеҫҲеӨҡе®ўжҲ·з«ҜеҸҜиғҪе°ұжІЎжңүиҜ·жұӮзҡ„еҸ‘йҖҒгҖӮ
иҝҷдёӘж—¶еҖҷпјҢжҲ‘们е°ұдёҚйңҖиҰҒйҒҚеҺҶ10KдёӘе®ўжҲ·з«ҜдәҶпјҢиҖҢжҳҜжҠҠжҲ‘们зҡ„fdsж–Ү件еҸ‘йҖҒз»ҷеҶ…ж ёпјҢ然еҗҺеҶ…ж ёеҺ»еҲӨж–ӯжңҖеҗҺйңҖиҰҒиҝһжҺҘиҜ¶зҡ„е®ўжҲ·з«ҜпјҢиҝҷж ·е°ұдёҚз”ЁйҒҚеҺҶе…ЁйғЁзҡ„дәҶгҖӮжүҖд»ҘиҝҷйҮҢзҡ„Selectе°ұжҳҜеӨҡи·ҜеӨҚз”ЁеҷЁпјҢйҖҡиҝҮеӨҡи·ҜеӨҚз”Ёиҝ”еӣһзҡ„жҳҜзҠ¶жҖҒпјҢ然еҗҺжҲ‘们йңҖиҰҒзЁӢеәҸеҺ»еҲӨж–ӯиҝҷдәӣзҠ¶жҖҒгҖӮ
иҜҙзҷҪдәҶпјҢе°ұжҳҜйҖҡиҝҮдёҖдёӘеӨҡи·ҜеӨҚз”ЁеҷЁпјҢжқҘеҲӨж–ӯе“Әдәӣи·ҜеҸҜд»Ҙиө°йҖҡпјҢ然еҗҺдёҚйңҖиҰҒиҪ®иҜўе…ЁйғЁзҡ„гҖӮ
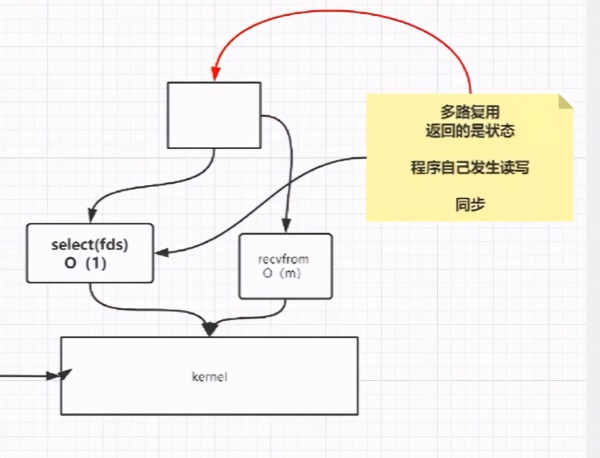
иҝҷдёӘжЁЎеһӢпјҢжҳҜйҖҡиҝҮselectпјҢе°Ҷfdsж–Ү件дәӨз»ҷеҶ…ж ёжқҘеҒҡдәҶпјҢд№ҹе°ұжҳҜеҶ…ж ёйңҖиҰҒе®ҢжҲҗ10KдёӘж–Ү件зҡ„дё»еҠЁйҒҚеҺҶпјҢиҝҷдёӘ10KдёӘи°ғз”ЁпјҢеҜ№жҜ”д№ӢеүҚзҡ„10Kж¬Ўзі»з»ҹи°ғз”ЁжқҘиҜҙпјҢжҳҜжӣҙзңҒж—¶й—ҙзҡ„пјҢеӯҳеңЁд»ҘдёӢзҡ„й—®йўҳ
жҜҸж¬Ўдј йҖ’еҫҲеӨҡж•°жҚ®(йҮҚеӨҚеҠіеҠЁ)
然еҗҺеҶ…ж ёйңҖиҰҒдё»еҠЁеҺ»йҒҚеҺҶ( еӨҚжқӮеәҰO(N) )
и§ЈеҶіж–№жі•пјҢйҖҡиҝҮеңЁеҶ…ж ёдёӯпјҢејҖиҫҹдёҖдёӘз©әй—ҙпјҢеҪ“жҜҸж¬ЎжқҘдёҖдёӘе®ўжҲ·з«ҜпјҢе°ұжҠҠиҝҷдёӘж–Ү件丢еҲ°еҶ…ж ёдёӯпјҢиҝҷж ·дёҚйңҖиҰҒжҜҸж¬ЎжҠҠ10KдёӘж–Үд»¶дј йҖ’еҲ°еҶ…ж ёдәҶгҖӮ然еҗҺеңЁдҪҝз”ЁдёҖдёӘеҹәдәҺдәӢ件й©ұеҠЁзҡ„жЁЎеһӢпјҢеҰӮдёӢеӣҫжүҖзӨәе°ұжҳҜдёҖдёӘејӮжӯҘдәӢ件й©ұеҠЁзҡ„жөҒзЁӢ
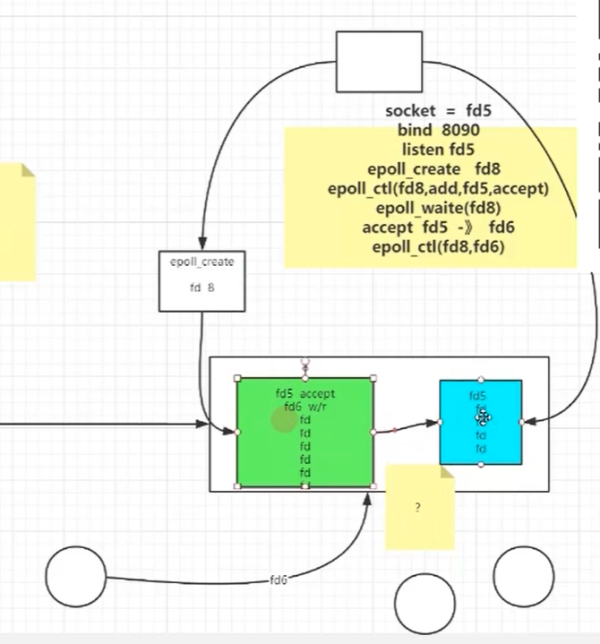
жҲ‘们йҖҡиҝҮstraceе‘Ҫд»ӨпјҢжҹҘзңӢnginx е’Ң redisзҡ„иҝҗиЎҢжөҒзЁӢпјҢиғҪеӨҹеҸ‘зҺ° еҗҢж ·жҳҜдҪҝз”ЁдәҶ epollпјҢдҪҶжҳҜnginxжҳҜйҳ»еЎһзҡ„пјҢиҖҢredisе®ғжҳҜиҪ®иҜў(йқһйҳ»еЎһ)зҡ„гҖӮ
йҰ–е…ҲйӮЈжҳҜеӣ дёәRedisеҸӘжңүдёҖдёӘзәҝзЁӢпјҢиҖҢиҝҷдёӘзәҝзЁӢиҰҒеҒҡеҫҲеӨҡдәӢжғ…пјҢдҫӢеҰӮ жҺҘ收客жҲ·з«ҜпјҢLRUпјҢLFU(ж·ҳжұ°иҝҮж»Ө)гҖҒRDB/AOF(forkзәҝзЁӢиҝӣиЎҢж•°жҚ®еӨҮд»Ҫ)гҖӮ
д№ҹе°ұжҳҜиҜҙеҜ№дәҺRedisдёӯзҡ„C10Kй—®йўҳпјҢredisд№ҹжҳҜйҖҡиҝҮepollзҡ„дәӢ件й©ұеҠЁжқҘиҝӣиЎҢеӨ„зҗҶзҡ„пјҢд№ҹе°ұжҳҜйҖҡиҝҮepollе°ҶжҜҸдёӘйңҖиҰҒиҜ»еҸ–зҡ„е®ўжҲ·з«Ҝзҡ„ж“ҚдҪңж”ҫеңЁдёҖдёӘеҺҹеӯҗдёІиЎҢеҢ–зҡ„йҳҹеҲ—дёӯпјҢ并且дёҖдёӘе®ўжҲ·з«ҜеҢ…еҗ«д»ҘдёӢзҡ„еҮ дёӘж“ҚдҪңпјҡreadгҖҒи®Ўз®—гҖҒwriteзӯү
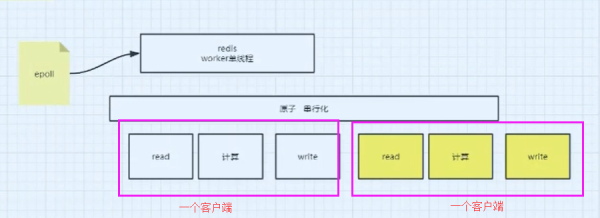
еңЁredis 6.XзүҲжң¬дёӯпјҢиҝҳжңүдёҖдёӘIO threadsзҡ„жҰӮеҝөпјҢйҰ–е…Ҳе®ғдёәдәҶз•ҷдҪҸдёІиЎҢеҢ–еҺҹеӯҗжҖ§зҡ„зү№зӮ№пјҢд№ҹе°ұжҳҜи®Ўз®—зҡ„ж—¶еҖҷиҝҳжҳҜдёІиЎҢеҢ–зҡ„еӨ„зҗҶпјҢдҪҶжҳҜеңЁиҜ»еҸ–ж•°жҚ®зҡ„ж—¶еҖҷпјҢдҪҝз”Ёзҡ„жҳҜеӨҡзәҝзЁӢиҝӣиЎҢ并еҸ‘IOиҜ»еҸ–гҖӮдёәд»Җд№ҲиҰҒеӨҡзәҝзЁӢиҜ»е‘ў?йҰ–е…Ҳеӣ дёәиҜ»ж“ҚдҪңйңҖиҰҒеҸ‘з”ҹCPUзҡ„зі»з»ҹи°ғз”ЁпјҢеҰӮжһңйҖҡиҝҮеӨҡдёӘзәҝзЁӢиҜ»еҸ–пјҢиғҪеӨҹе……еҲҶеҸ‘жҢҘCPUзҡ„еӨҡж ёдҪңз”Ё
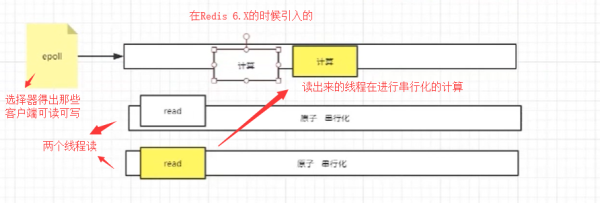
иҖҢnginxеҸӘйңҖиҰҒеҒҡдёҖ件дәӢпјҢе°ұжҳҜзӯүзқҖе®ўжҲ·з«ҜиҝҮжқҘпјҢдёҚйңҖиҰҒеҒҡе…¶д»–зҡ„дәӢжғ…пјҢжүҖд»Ҙд№ҹе°ұи®ҫзҪ®жҲҗйҳ»еЎһгҖӮ
з”ЁkafkaжқҘи®ІпјҢйҰ–е…ҲиҝҷйҮҢйқўжңүдёӨдёӘи§’иүІпјҢдёҖдёӘжҳҜж¶ҲжҒҜз”ҹдә§иҖ…пјҢдёҖдёӘжҳҜж¶ҲжҒҜж¶Ҳиҙ№иҖ…
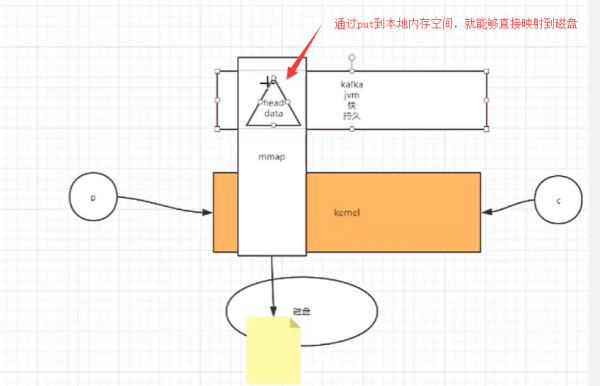
д№ҹе°ұжҳҜиҜҙпјҢжҲ‘们йҖҡиҝҮејҖиҫҹдәҶдёҖдёӘеҶ…еӯҳз©әй—ҙпјҢиғҪеӨҹзӣҙжҺҘжҠөиҫҫзЈҒзӣҳпјҢиғҪеӨҹеҮҸе°‘kernelзҡ„зі»з»ҹи°ғз”ЁгҖӮеңЁиҜ»еҸ–зҡ„ж—¶еҖҷпјҢеҰӮжһңжҳҜеҺҹжқҘзҡ„еҒҡжі•пјҢе°ұйңҖиҰҒйҰ–е…ҲиҜ·жұӮkernelпјҢ然еҗҺkernelеҸ‘иө·дёҖдёӘreadиҜ·жұӮпјҢиҜ»еҸ–зЈҒзӣҳзҡ„ж–Ү件еҲ°еҶ…ж ёдёӯпјҢ然еҗҺkafkaеңЁиҜ»еҸ–kernelдёӯзҡ„дҝЎжҒҜгҖӮ
йӮЈд№Ҳд»Җд№ҲжҳҜйӣ¶жӢ·иҙқе‘ў?
йӣ¶жӢ·иҙқе°ұжҳҜдёҚеҸ‘з”ҹжӢ·иҙқзҡ„жғ…еҶөпјҢйӣ¶жӢ·иҙқзҡ„еүҚжҸҗе°ұжҳҜж•°жҚ®дёҚйңҖиҰҒеҠ е·ҘпјҢеңЁJVMдёӯжңүдёҖдёӘRandomAccessFileпјҢе®ғиғҪеӨҹзӣҙжҺҘејҖиҫҹдёҖдёӘе ҶеҶ…з©әй—ҙпјҢжҲ–иҖ…е ҶеӨ–з©әй—ҙгҖӮ
еҲ°жӯӨпјҢзӣёдҝЎеӨ§е®¶еҜ№вҖңеҰӮдҪ•д»Һеә•еұӮиҒҠдёӢIOеӨҡи·ҜеӨҚз”ЁжЁЎеһӢвҖқжңүдәҶжӣҙж·ұзҡ„дәҶи§ЈпјҢдёҚеҰЁжқҘе®һйҷ…ж“ҚдҪңдёҖз•Әеҗ§пјҒиҝҷйҮҢжҳҜдәҝйҖҹдә‘зҪ‘з«ҷпјҢжӣҙеӨҡзӣёе…іеҶ…е®№еҸҜд»Ҙиҝӣе…Ҙзӣёе…ійў‘йҒ“иҝӣиЎҢжҹҘиҜўпјҢе…іжіЁжҲ‘们пјҢ继з»ӯеӯҰд№ пјҒ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ