жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
иҝҷзҜҮж–Үз« дё»иҰҒи®Іи§ЈдәҶвҖңжҖҺд№ҲдҪҝз”ЁPythonе®ҡж—¶жҠ“еҸ–еҫ®еҚҡиҜ„и®әвҖқпјҢж–Үдёӯзҡ„и®Іи§ЈеҶ…е®№з®ҖеҚ•жё…жҷ°пјҢжҳ“дәҺеӯҰд№ дёҺзҗҶи§ЈпјҢдёӢйқўиҜ·еӨ§е®¶и·ҹзқҖе°Ҹзј–зҡ„жҖқи·Ҝж…ўж…ўж·ұе…ҘпјҢдёҖиө·жқҘз ”з©¶е’ҢеӯҰд№ вҖңжҖҺд№ҲдҪҝз”ЁPythonе®ҡж—¶жҠ“еҸ–еҫ®еҚҡиҜ„и®әвҖқеҗ§пјҒ
гҖҗPart1——зҗҶи®әзҜҮгҖ‘
иҜ•жғідёҖдёӘй—®йўҳпјҢеҰӮжһңжҲ‘们иҰҒжҠ“еҸ–жҹҗдёӘеҫ®еҚҡеӨ§Vеҫ®еҚҡзҡ„иҜ„и®әж•°жҚ®пјҢеә”иҜҘжҖҺд№Ҳе®һзҺ°е‘ў?жңҖз®ҖеҚ•зҡ„еҒҡжі•е°ұжҳҜжүҫеҲ°еҫ®еҚҡиҜ„и®әж•°жҚ®жҺҘеҸЈпјҢ然еҗҺйҖҡиҝҮж”№еҸҳеҸӮж•°жқҘиҺ·еҸ–жңҖж–°ж•°жҚ®е№¶дҝқеӯҳгҖӮйҰ–е…Ҳд»Һеҫ®еҚҡapiеҜ»жүҫжҠ“еҸ–иҜ„и®әзҡ„жҺҘеҸЈпјҢеҰӮдёӢеӣҫжүҖзӨәгҖӮ
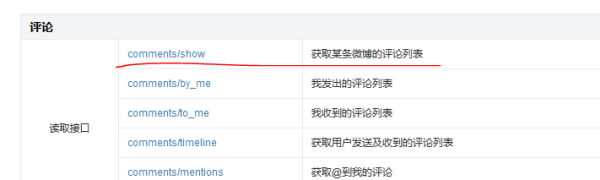
дҪҶжҳҜеҫҲдёҚе№ёпјҢиҜҘжҺҘеҸЈйў‘зҺҮеҸ—йҷҗпјҢжҠ“дёҚдәҶеҮ ж¬Ўе°ұиў«зҰҒдәҶпјҢиҝҳжІЎжңүејҖе§Ӣиө·йЈһпјҢе°ұеҮүеҮүдәҶгҖӮ
жҺҘдёӢжқҘе°Ҹзј–еҸҲйҖүжӢ©еҫ®еҚҡзҡ„移еҠЁз«ҜзҪ‘з«ҷпјҢе…Ҳзҷ»еҪ•пјҢ然еҗҺжүҫеҲ°жҲ‘们жғіиҰҒжҠ“еҸ–иҜ„и®әзҡ„еҫ®еҚҡпјҢжү“ејҖжөҸи§ҲеҷЁиҮӘеёҰжөҒйҮҸеҲҶжһҗе·Ҙе…·пјҢдёҖзӣҙдёӢжӢүиҜ„и®әпјҢжүҫеҲ°иҜ„и®әж•°жҚ®жҺҘеҸЈпјҢеҰӮдёӢеӣҫжүҖзӨәгҖӮ
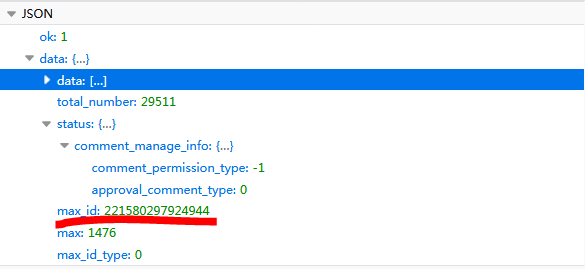
д№ӢеҗҺзӮ№еҮ»вҖңеҸӮж•°вҖқйҖүйЎ№еҚЎпјҢеҸҜд»ҘзңӢеҲ°еҸӮж•°дёәдёӢеӣҫжүҖзӨәзҡ„еҶ…е®№пјҡ
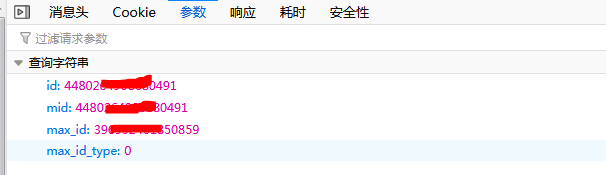
еҸҜд»ҘзңӢеҲ°жҖ»е…ұжңү4дёӘеҸӮж•°пјҢе…¶дёӯ第1гҖҒ2дёӘеҸӮж•°дёәиҜҘжқЎеҫ®еҚҡзҡ„idпјҢе°ұеғҸдәәзҡ„иә«д»ҪиҜҒеҸ·дёҖж ·пјҢиҝҷдёӘзӣёеҪ“дәҺиҜҘжқЎеҫ®еҚҡзҡ„вҖңиә«д»ҪиҜҒеҸ·вҖқпјҢmax_idжҳҜеҸҳжҚўйЎөз Ғзҡ„еҸӮж•°пјҢжҜҸж¬ЎйғҪиҰҒеҸҳеҢ–пјҢдёӢж¬Ўзҡ„max_idеҸӮж•°еҖјеңЁжң¬ж¬ЎиҜ·жұӮзҡ„иҝ”еӣһж•°жҚ®дёӯгҖӮ
гҖҗPart2——е®һжҲҳзҜҮгҖ‘
жңүдәҶдёҠж–Үзҡ„еҹәзЎҖд№ӢеҗҺпјҢдёӢйқўжҲ‘们ејҖе§Ӣж’ёд»Јз ҒпјҢдҪҝз”ЁPythonиҝӣиЎҢе®һзҺ°гҖӮ

1гҖҒйҰ–е…ҲеҢәеҲҶurlпјҢ第дёҖж¬ЎдёҚйңҖиҰҒmax_id,第дәҢж¬ЎйңҖиҰҒ用第дёҖж¬Ўиҝ”еӣһзҡ„max_idгҖӮ

2гҖҒиҜ·жұӮзҡ„ж—¶еҖҷйңҖиҰҒеёҰдёҠcookieж•°жҚ®пјҢеҫ®еҚҡcookieзҡ„жңүж•ҲжңҹжҜ”иҫғй•ҝпјҢи¶іеӨҹжҠ“дёҖжқЎеҫ®еҚҡзҡ„иҜ„и®әж•°жҚ®дәҶпјҢcookieж•°жҚ®еҸҜд»Ҙд»ҺжөҸи§ҲеҷЁеҲҶжһҗе·Ҙе…·дёӯжүҫеҲ°гҖӮ
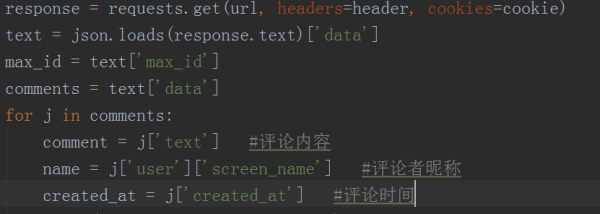
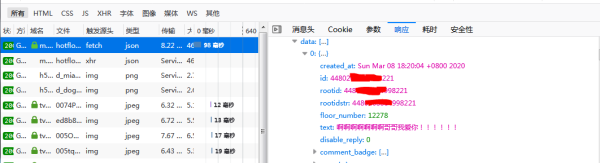
3гҖҒ然еҗҺе°Ҷиҝ”еӣһж•°жҚ®иҪ¬жҚўжҲҗjsonж јејҸпјҢеҸ–еҮәиҜ„и®әеҶ…е®№гҖҒиҜ„и®әиҖ…жҳөз§°е’ҢиҜ„и®әж—¶й—ҙзӯүж•°жҚ®пјҢиҫ“еҮәз»“жһңеҰӮдёӢеӣҫжүҖзӨәгҖӮ

4гҖҒдёәдәҶдҝқеӯҳиҜ„и®әеҶ…е®№пјҢжҲ‘们иҰҒе°ҶиҜ„и®әдёӯзҡ„иЎЁжғ…еҺ»жҺүпјҢдҪҝз”ЁжӯЈеҲҷиЎЁиҫҫејҸиҝӣиЎҢеӨ„зҗҶпјҢеҰӮдёӢеӣҫжүҖзӨәгҖӮ

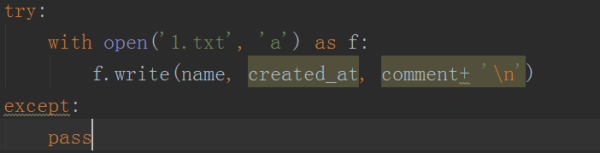
5гҖҒд№ӢеҗҺжҺҘзқҖжҠҠеҶ…е®№дҝқеӯҳеҲ°txtж–Ү件дёӯпјҢдҪҝз”Ёз®ҖеҚ•зҡ„openеҮҪж•°иҝӣиЎҢе®һзҺ°пјҢеҰӮдёӢеӣҫжүҖзӨәгҖӮ
6гҖҒйҮҚзӮ№жқҘдәҶпјҢйҖҡиҝҮжӯӨжҺҘеҸЈжңҖеӨҡеҸӘиғҪиҝ”еӣһ16йЎөзҡ„ж•°жҚ®(жҜҸйЎө20жқЎ)пјҢзҪ‘дёҠд№ҹжңүиҜҙиҝ”еӣһ50йЎөзҡ„пјҢдҪҶжҳҜжҺҘеҸЈдёҚеҗҢгҖҒиҝ”еӣһзҡ„ж•°жҚ®жқЎж•°д№ҹдёҚеҗҢпјҢжүҖд»ҘжҲ‘еҠ дәҶдёӘforеҫӘзҺҜпјҢдёҖжӯҘеҲ°дҪҚпјҢйҒҚеҺҶиҝҳжҳҜеҫҲз»ҷеҠӣзҡ„пјҢеҰӮдёӢеӣҫжүҖзӨәгҖӮ

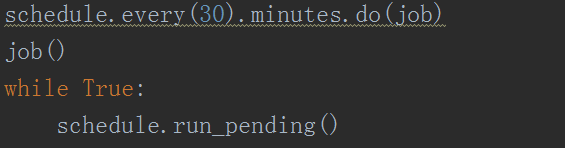
7гҖҒиҝҷйҮҢжҠҠеҮҪж•°е‘ҪеҗҚдёәjobгҖӮдёәдәҶиғҪеӨҹдёҖзӣҙеҸ–еҮәжңҖж–°зҡ„ж•°жҚ®пјҢжҲ‘们еҸҜд»Ҙз”Ёscheduleз»ҷзЁӢеәҸеҠ дёӘе®ҡж—¶еҠҹиғҪпјҢжҜҸйҡ”10еҲҶй’ҹжҲ–иҖ…еҚҠдёӘе°Ҹж—¶жҠ“1ж¬ЎпјҢеҰӮдёӢеӣҫжүҖзӨәгҖӮ
8гҖҒеҜ№иҺ·еҸ–еҲ°зҡ„ж•°жҚ®пјҢеҒҡеҺ»йҮҚеӨ„зҗҶпјҢеҰӮдёӢеӣҫжүҖзӨәгҖӮеҰӮжһңиҜ„и®әе·Із»ҸеңЁйҮҢиҫ№зҡ„иҜқпјҢе°ұзӣҙжҺҘpassжҺүпјҢеҰӮжһңжІЎжңүзҡ„иҜқпјҢ继з»ӯиҝҪеҠ еҚіеҸҜгҖӮ
иҝҷйЎ№е·ҘдҪңеҲ°жӯӨе°ұеҹәжң¬е®ҢжҲҗдәҶгҖӮ
ж„ҹи°ўеҗ„дҪҚзҡ„йҳ…иҜ»пјҢд»ҘдёҠе°ұжҳҜвҖңжҖҺд№ҲдҪҝз”ЁPythonе®ҡж—¶жҠ“еҸ–еҫ®еҚҡиҜ„и®әвҖқзҡ„еҶ…е®№дәҶпјҢз»ҸиҝҮжң¬ж–Үзҡ„еӯҰд№ еҗҺпјҢзӣёдҝЎеӨ§е®¶еҜ№жҖҺд№ҲдҪҝз”ЁPythonе®ҡж—¶жҠ“еҸ–еҫ®еҚҡиҜ„и®әиҝҷдёҖй—®йўҳжңүдәҶжӣҙж·ұеҲ»зҡ„дҪ“дјҡпјҢе…·дҪ“дҪҝз”Ёжғ…еҶөиҝҳйңҖиҰҒеӨ§е®¶е®һи·өйӘҢиҜҒгҖӮиҝҷйҮҢжҳҜдәҝйҖҹдә‘пјҢе°Ҹзј–е°ҶдёәеӨ§е®¶жҺЁйҖҒжӣҙеӨҡзӣёе…ізҹҘиҜҶзӮ№зҡ„ж–Үз« пјҢж¬ўиҝҺе…іжіЁпјҒ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ