жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
иҝҷзҜҮж–Үз« дё»иҰҒи®Іи§ЈдәҶвҖңJava+LinuxеҶ…ж ёжәҗз Ғд№ӢеҰӮдҪ•зҗҶи§ЈеӨҡзәҝзЁӢд№ӢиҝӣзЁӢвҖқпјҢж–Үдёӯзҡ„и®Іи§ЈеҶ…е®№з®ҖеҚ•жё…жҷ°пјҢжҳ“дәҺеӯҰд№ дёҺзҗҶи§ЈпјҢдёӢйқўиҜ·еӨ§е®¶и·ҹзқҖе°Ҹзј–зҡ„жҖқи·Ҝж…ўж…ўж·ұе…ҘпјҢдёҖиө·жқҘз ”з©¶е’ҢеӯҰд№ вҖңJava+LinuxеҶ…ж ёжәҗз Ғд№ӢеҰӮдҪ•зҗҶи§ЈеӨҡзәҝзЁӢд№ӢиҝӣзЁӢвҖқеҗ§пјҒ
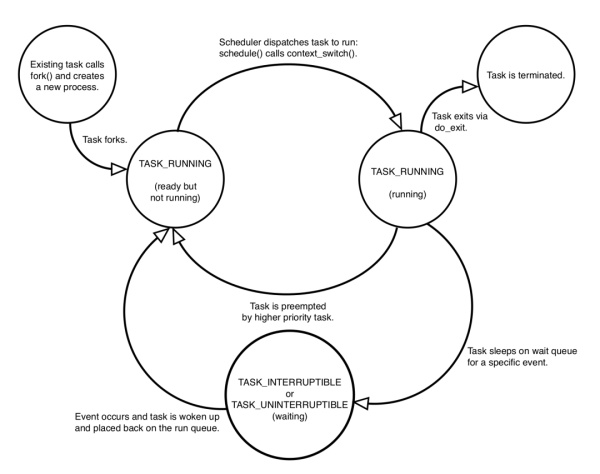
Linux еҶ…ж ёеҰӮдҪ•жҸҸиҝ°дёҖдёӘиҝӣзЁӢ?
1. Linux зҡ„иҝӣзЁӢ
иҝӣзЁӢзҡ„жңҜиҜӯжҳҜ processпјҢжҳҜ Linux жңҖеҹәзЎҖзҡ„жҠҪиұЎпјҢеҸҰдёҖдёӘеҹәзЎҖжҠҪиұЎжҳҜж–Ү件гҖӮ
жңҖз®ҖеҚ•зҡ„зҗҶи§ЈпјҢиҝӣзЁӢе°ұжҳҜжү§иЎҢдёӯ (executing, дёҚзӯүдәҺrunning) зҡ„зЁӢеәҸгҖӮ
жӣҙеҮҶзЎ®дёҖзӮ№зҡ„зҗҶи§ЈпјҢиҝӣзЁӢеҢ…жӢ¬жү§иЎҢдёӯзҡ„зЁӢеәҸд»ҘеҸҠзӣёе…ізҡ„иө„жәҗ (еҢ…жӢ¬cpuзҠ¶жҖҒгҖҒжү“ејҖзҡ„ж–Ү件гҖҒжҢӮиө·зҡ„дҝЎеҸ·гҖҒttyгҖҒеҶ…еӯҳең°еқҖз©әй—ҙзӯү)гҖӮ
дёҖз§Қз®ҖжҙҒзҡ„иҜҙжі•пјҡиҝӣзЁӢ = n*жү§иЎҢжөҒ + иө„жәҗпјҢn>=1гҖӮ
Linux иҝӣзЁӢзҡ„зү№зӮ№пјҡ
йёҝи’ҷе®ҳж–№жҲҳз•ҘеҗҲдҪңе…ұе»әвҖ”вҖ”HarmonyOSжҠҖжңҜзӨҫеҢә
йҖҡиҝҮзі»з»ҹи°ғз”Ё fork() еҲӣе»әиҝӣзЁӢпјҢfork() дјҡеӨҚеҲ¶зҺ°жңүиҝӣзЁӢжқҘеҲӣе»әдёҖдёӘе…Ёж–°зҡ„иҝӣзЁӢгҖӮ
еҶ…ж ёйҮҢпјҢ并дёҚдёҘж јеҢәеҲҶиҝӣзЁӢе’ҢзәҝзЁӢгҖӮ
д»ҺеҶ…ж ёзҡ„и§’еәҰзңӢпјҢи°ғеәҰеҚ•дҪҚжҳҜзәҝзЁӢ (еҚіжү§иЎҢжөҒ)гҖӮеҸҜд»ҘжҠҠзәҝзЁӢзңӢеҒҡжҳҜиҝӣзЁӢйҮҢзҡ„дёҖжқЎжү§иЎҢжөҒпјҢ1дёӘиҝӣзЁӢйҮҢеҸҜд»Ҙжңү1дёӘжҲ–иҖ…еӨҡдёӘзәҝзЁӢгҖӮ
еҶ…ж ёйҮҢпјҢеёёжҠҠиҝӣзЁӢз§°дёә task жҲ–иҖ… threadпјҢиҝҷж ·жҸҸиҝ°жӣҙеҮҶзЎ®пјҢеӣ дёәи®ёеӨҡиҝӣзЁӢе°ұеҸӘжңү1жқЎжү§иЎҢжөҒгҖӮ
еҶ…ж ёйҖҡиҝҮиҪ»йҮҸзә§иҝӣзЁӢ (lightweight process) жқҘж”ҜжҢҒеӨҡзәҝзЁӢгҖӮ1дёӘиҪ»йҮҸзә§иҝӣзЁӢе°ұеҜ№еә”1дёӘзәҝзЁӢпјҢиҪ»йҮҸзә§иҝӣзЁӢд№Ӣй—ҙеҸҜд»Ҙе…ұдә«жү“ејҖзҡ„ж–Ү件гҖҒең°еқҖз©әй—ҙзӯүиө„жәҗгҖӮ
2. Linux зҡ„иҝӣзЁӢжҸҸиҝ°з¬Ұ
2.1 task_struct
еҶ…ж ёйҮҢпјҢйҖҡиҝҮ task_struct з»“жһ„дҪ“жқҘжҸҸиҝ°дёҖдёӘиҝӣзЁӢпјҢз§°дёәиҝӣзЁӢжҸҸиҝ°з¬Ұ (process descriptor)пјҢе®ғдҝқеӯҳзқҖж”Ҝж’‘дёҖдёӘиҝӣзЁӢжӯЈеёёиҝҗиЎҢзҡ„жүҖжңүдҝЎжҒҜгҖӮ
жҜҸдёҖдёӘиҝӣзЁӢпјҢеҚідҫҝжҳҜиҪ»йҮҸзә§иҝӣзЁӢ(еҚізәҝзЁӢ)пјҢйғҪжңү1дёӘ task_structгҖӮ
sched.h (include\linux) struct task_struct { struct thread_info thread_info; volatile long state; void *stack; [...] struct mm_struct *mm; [...] pid_t pid; [...] struct task_struct *parent; [...] char comm[TASK_COMM_LEN]; [...] struct files_struct *files; [...] struct signal_struct *signal; }иҝҷжҳҜдёҖдёӘеәһеӨ§зҡ„з»“жһ„дҪ“пјҢдёҚд»…жңүи®ёеӨҡиҝӣзЁӢзӣёе…ізҡ„еҹәзЎҖеӯ—ж®өпјҢиҝҳжңүи®ёеӨҡжҢҮеҗ‘е…¶д»–ж•°жҚ®з»“жһ„зҡ„жҢҮй’ҲгҖӮ
е®ғеҢ…еҗ«зҡ„еӯ—ж®өиғҪе®Ңж•ҙең°жҸҸиҝ°дёҖдёӘжӯЈеңЁжү§иЎҢзҡ„зЁӢеәҸпјҢеҢ…жӢ¬ cpu зҠ¶жҖҒгҖҒжү“ејҖзҡ„ж–Ү件гҖҒең°еқҖз©әй—ҙгҖҒжҢӮиө·зҡ„дҝЎеҸ·гҖҒиҝӣзЁӢзҠ¶жҖҒзӯүгҖӮ
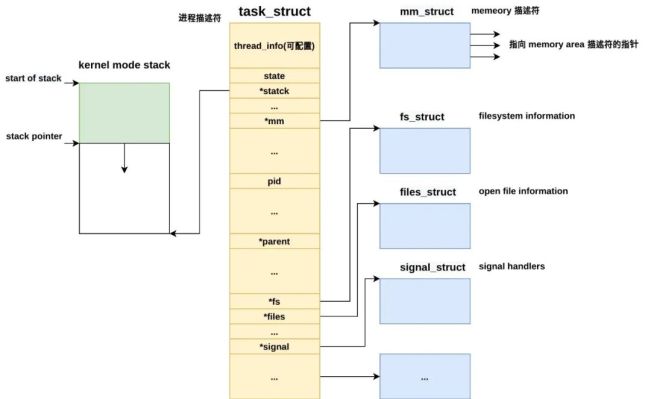
дҪңдёәеҲқеӯҰиҖ…пјҢе…Ҳз®ҖеҚ•ең°дәҶи§ЈйғЁеҲҶеӯ—ж®өе°ұеҘҪпјҡпјҡ
struct thread_info thread_info: иҝӣзЁӢеә•еұӮдҝЎжҒҜпјҢе№іеҸ°зӣёе…іпјҢдёӢйқўдјҡиҜҰз»ҶжҸҸиҝ°гҖӮ
long state: иҝӣзЁӢеҪ“еүҚзҡ„зҠ¶жҖҒпјҢдёӢйқўжҳҜеҮ дёӘжҜ”иҫғйҮҚиҰҒзҡ„иҝӣзЁӢзҠ¶жҖҒд»ҘеҸҠе®ғ们д№Ӣй—ҙзҡ„иҪ¬жҚўжөҒзЁӢгҖӮ
void *stack: жҢҮеҗ‘иҝӣзЁӢеҶ…ж ёж ҲпјҢдёӢйқўдјҡи§ЈйҮҠгҖӮ
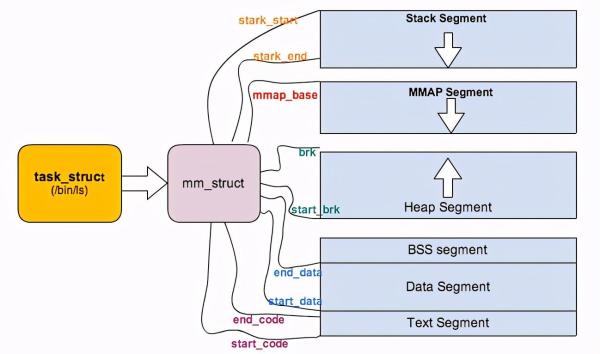
struct mm_struct *mm: дёҺиҝӣзЁӢең°еқҖз©әй—ҙзӣёе…ізҡ„дҝЎжҒҜйғҪдҝқеӯҳеңЁдёҖдёӘеҸ«еҶ…еӯҳжҸҸиҝ°з¬Ұ (memory descriptor) зҡ„з»“жһ„дҪ“ (mm_struct) дёӯгҖӮ
pid_t pid: иҝӣзЁӢж ҮиҜҶз¬ҰпјҢжң¬иҙЁе°ұжҳҜдёҖдёӘж•°еӯ—пјҢжҳҜз”ЁжҲ·з©әй—ҙеј•з”ЁиҝӣзЁӢзҡ„е”ҜдёҖж ҮиҜҶгҖӮ
struct task_struct *parent: зҲ¶иҝӣзЁӢзҡ„ task_structгҖӮ char comm[TASK_COMM_LEN]: иҝӣзЁӢзҡ„еҗҚз§°гҖӮ struct files_structгҖҖ*files: жү“ејҖзҡ„ж–Ү件表гҖӮ struct signal_struct *signal: дҝЎеҸ·еӨ„зҗҶзӣёе…ігҖӮ
е…¶д»–еӯ—ж®өпјҢзӯүеҲ°жңүйңҖиҰҒзҡ„ж—¶еҖҷеҶҚеӣһиҝҮеӨҙжқҘеӯҰд№ гҖӮ
2.2 еҪ“еҸ‘з”ҹзі»з»ҹи°ғз”ЁжҲ–иҖ…иҝӣзЁӢеҲҮжҚўж—¶пјҢеҶ…ж ёеҰӮдҪ•жүҫеҲ° task_struct ?
еҜ№дәҺ ARM жһ¶жһ„пјҢзӯ”жЎҲжҳҜпјҡйҖҡиҝҮеҶ…ж ёж Ҳ (kernel mode stack)гҖӮ
дёәд»Җд№ҲиҰҒжңүеҶ…ж ёж Ҳ?
еӣ дёәеҶ…ж ёжҳҜеҸҜйҮҚе…Ҙзҡ„пјҢеңЁеҶ…ж ёдёӯдјҡжңүеӨҡжқЎдёҺдёҚеҗҢиҝӣзЁӢзӣёе…іиҒ”зҡ„жү§иЎҢи·Ҝеҫ„гҖӮеӣ жӯӨдёҚеҗҢзҡ„иҝӣзЁӢеӨ„дәҺеҶ…ж ёжҖҒж—¶пјҢйғҪйңҖиҰҒжңүиҮӘе·ұз§Ғжңүзҡ„иҝӣзЁӢеҶ…ж ёж Ҳ (process kernel stack)гҖӮ
еҪ“иҝӣзЁӢд»Һз”ЁжҲ·жҖҒеҲҮжҚўеҲ°еҶ…ж ёжҖҒж—¶пјҢжүҖдҪҝз”Ёзҡ„ж Ҳдјҡд»Һз”ЁжҲ·ж ҲеҲҮжҚўеҲ°еҶ…ж ёж ҲгҖӮ
иҮідәҺжҳҜеҰӮдҪ•еҲҮжҚўзҡ„пјҢе…ій”®иҜҚжҳҜзі»з»ҹи°ғз”ЁпјҢиҝҷдёҚжҳҜжң¬ж–Үе…іжіЁзҡ„йҮҚзӮ№пјҢе…Ҳж”ҫдёҖиҫ№пјҢеӯҰд№ еҶ…ж ёиҰҒжҮӮеҫ—жҒ°еҪ“зҡ„ж—¶еҖҷеҝҪз•Ҙз»ҶиҠӮгҖӮ
еҪ“еҸ‘з”ҹиҝӣзЁӢеҲҮжҚўж—¶пјҢд№ҹдјҡеҲҮжҚўеҲ°зӣ®ж ҮиҝӣзЁӢзҡ„еҶ…ж ёж ҲгҖӮ
еҗҢдёҠпјҢе…ій”®иҜҚжҳҜ硬件дёҠдёӢж–ҮеҲҮжҚў (hardware context switch)пјҢеҝҪз•Ҙе…·дҪ“е®һзҺ°гҖӮ
ж— и®әдҪ•ж—¶пјҢеҸӘиҰҒиҝӣзЁӢеӨ„дәҺеҶ…ж ёжҖҒпјҢе°ұдјҡжңүеҶ…ж ёж ҲеҸҜд»ҘдҪҝз”ЁпјҢеҗҰеҲҷзі»з»ҹе°ұзҰ»еҙ©жәғдёҚиҝңдәҶгҖӮ
ARM жһ¶жһ„зҡ„еҶ…ж ёж Ҳе’Ң task_struct зҡ„е…ізі»еҰӮдёӢпјҡ
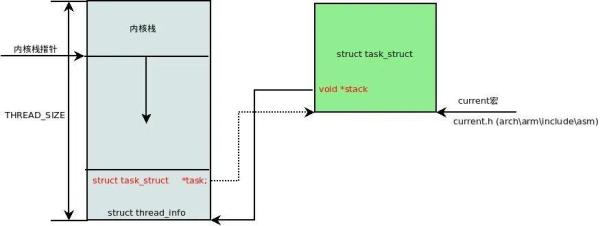
еҶ…ж ёж Ҳзҡ„й•ҝеәҰжҳҜ THREAD_SIZEпјҢеҜ№дәҺ ARM жһ¶жһ„пјҢдёҖиҲ¬жҳҜ 2 дёӘйЎөжЎҶзҡ„еӨ§е°ҸпјҢеҚі 8KBгҖӮ
еҶ…ж ёе°ҶдёҖдёӘиҫғе°Ҹзҡ„ж•°жҚ®з»“жһ„ thread_info ж”ҫеңЁеҶ…ж ёж Ҳзҡ„еә•йғЁпјҢе®ғиҙҹиҙЈе°ҶеҶ…ж ёж Ҳе’Ң task_struct дёІиҒ”иө·жқҘгҖӮthread_info жҳҜе№іеҸ°зӣёе…ізҡ„пјҢеңЁ ARM жһ¶жһ„дёӯзҡ„е®ҡд№үеҰӮдёӢпјҡ
// thread_info.h (arch\arm\include\asm) struct thread_info { unsigned long flags; /* low level flags */ int preempt_count; /* 0 => preemptable, <0 => bug */ mm_segment_t addr_limit; /* address limit */ struct task_struct *task; /* main task structure */ [...] struct cpu_context_save cpu_context; /* cpu context */ [...] };thread_info дҝқеӯҳдәҶдёҖдёӘиҝӣзЁӢиғҪиў«и°ғеәҰжү§иЎҢзҡ„жңҖеә•еұӮдҝЎжҒҜ(low level task data)пјҢдҫӢеҰӮstruct cpu_context_save cpu_context дјҡеңЁиҝӣзЁӢеҲҮжҚўж—¶з”ЁжқҘдҝқеӯҳ/жҒўеӨҚеҜ„еӯҳеҷЁдёҠдёӢж–ҮгҖӮ
еҶ…ж ёйҖҡиҝҮеҶ…ж ёж Ҳзҡ„ж ҲжҢҮй’ҲеҸҜд»Ҙеҝ«йҖҹең°жӢҝеҲ° thread_infoпјҡ
// thread_info.h (include\linux) static inline struct thread_info *current_thread_info(void) { // current_stack_pointer жҳҜеҪ“еүҚиҝӣзЁӢеҶ…ж ёж Ҳзҡ„ж ҲжҢҮй’Ҳ return (struct thread_info *) (current_stack_pointer & ~(THREAD_SIZE - 1)); } 然еҗҺйҖҡиҝҮ thread_info жүҫеҲ° task_struct: // current.h (include\asm-generic) #define current (current_thread_info()->task)еҶ…ж ёйҮҢйҖҡиҝҮ current е®ҸеҸҜд»ҘиҺ·еҫ—еҪ“еүҚиҝӣзЁӢзҡ„ task_structгҖӮ
2.3 task_struct зҡ„еҲҶй…Қе’ҢеҲқе§ӢеҢ–
еҪ“дёҠеұӮеә”з”ЁдҪҝз”Ё fork() еҲӣе»әиҝӣзЁӢж—¶пјҢеҶ…ж ёдјҡж–°е»әдёҖдёӘ task_structгҖӮ
иҝӣзЁӢзҡ„еҲӣе»әжҳҜдёӘеӨҚжқӮзҡ„е·ҘдҪңпјҢеҸҜд»Ҙ延伸еҮәж— ж•°зҡ„з»ҶиҠӮгҖӮиҝҷйҮҢжҲ‘们еҸӘжҳҜз®ҖеҚ•ең°дәҶи§ЈдёҖдёӢ task_struct зҡ„еҲҶй…Қе’ҢйғЁеҲҶеҲқе§ӢеҢ–зҡ„жөҒзЁӢгҖӮ
fork() еңЁеҶ…ж ёйҮҢзҡ„ж ёеҝғжөҒзЁӢпјҡ
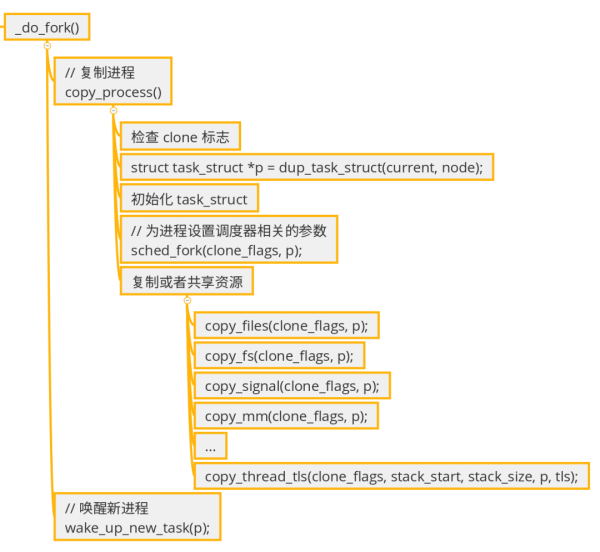
dup_task_struct() еҒҡдәҶд»Җд№Ҳ?

иҮідәҺи®ҫзҪ®еҶ…ж ёж ҲйҮҢеҒҡдәҶд»Җд№ҲпјҢж¶үеҸҠеҲ°дәҶиҝӣзЁӢзҡ„еҲӣе»әдёҺеҲҮжҚўпјҢдёҚеңЁжң¬ж–Үзҡ„е…іжіЁиҢғеӣҙеҶ…пјҢд»ҘеҗҺеҶҚз ”з©¶дәҶгҖӮ
3. е®һйӘҢпјҡжү“еҚ° task_struct / thread_info / kernel mode stack
е®һйӘҢзӣ®зҡ„пјҡ
жўізҗҶ task_struct / thread_info / kernel mode stack зҡ„е…ізі»гҖӮ
е®һйӘҢд»Јз Ғпјҡ
е®һйӘҢд»Јз Ғпјҡ #include <linux/init.h> #include <linux/module.h> #include <linux/sched.h> static void print_task_info(struct task_struct *task) { printk(KERN_NOTICE "%10s %5d task_struct (%p) / stack(%p~%p) / thread_info->task (%p)", task->comm, task->pid, task, task->stack, ((unsigned long *)task->stack) + THREAD_SIZE, task_thread_info(task)->task); } static int __init task_init(void) { struct task_struct *task = current; printk(KERN_INFO "task module init\n"); print_task_info(task); do { task = task->parent; print_task_info(task); } while (task->pid != 0); return 0; } module_init(task_init); static void __exit task_exit(void) { printk(KERN_INFO "task module exit\n "); } module_exit(task_exit);иҝҗиЎҢж•Ҳжһңпјҡ
task module init insmod 3123 task_struct (edb42580) / stack(ed46c000~ed474000) / thread_info->task (edb42580) bash 2393 task_struct (eda13e80) / stack(c9dda000~c9de2000) / thread_info->task (eda13e80) sshd 2255 task_struct (ee5c9f40) / stack(c9d2e000~c9d36000) / thread_info->task (ee5c9f40) sshd 543 task_struct (ef15f080) / stack(ee554000~ee55c000) / thread_info->task (ef15f080) systemd 1 task_struct (ef058000) / stack(ef04c000~ef054000) / thread_info->task (ef058000)
еңЁзЁӢеәҸйҮҢпјҢжҲ‘们йҖҡиҝҮ task_struct жүҫеҲ° stackпјҢ然еҗҺйҖҡиҝҮ stack жүҫеҲ° thread_infoпјҢжңҖеҗҺеҸҲйҖҡиҝҮ thread_info->task жүҫеҲ° task_structгҖӮ
еҲ°иҝҷйҮҢпјҢдёҚзҹҘйҒ“дҪ еҜ№иҝӣзЁӢзҡ„жҰӮеҝөжҳҜдёҚжҳҜжңүдәҶдёҖдёӘжё…жҷ°зҡ„зҗҶи§Ј
дҪҶжҳҜдёҠйқўжҳҜйҖҡиҝҮLinuxиҝӣиЎҢдәҶзәҝзЁӢзҡ„еұ•зӨәпјҢеңЁж—Ҙеёёзҡ„е·ҘдҪңдёӯпјҢд»Јз Ғзҡ„е®һзҺ°е’Ңзј–еҶҷжҲ‘们иҝҳжҳҜд»ҘJavaдёәдё»пјҢйӮЈжҲ‘们жқҘзңӢдёҖдёӢJavaиҝӣзЁӢ
1.JavaиҝӣзЁӢзҡ„еҲӣе»ә
JavaжҸҗдҫӣдәҶдёӨз§Қж–№жі•з”ЁжқҘеҗҜеҠЁиҝӣзЁӢжҲ–е…¶е®ғзЁӢеәҸпјҡ
дҪҝз”ЁRuntimeзҡ„exec()ж–№жі•
дҪҝз”ЁProcessBuilderзҡ„start()ж–№жі•
1.1 ProcessBuilder
ProcessBuilderзұ»жҳҜJ2SE 1.5еңЁjava.langдёӯж–°ж·»еҠ зҡ„дёҖдёӘж–°зұ»пјҢжӯӨзұ»з”ЁдәҺеҲӣе»әж“ҚдҪңзі»з»ҹиҝӣзЁӢпјҢе®ғжҸҗдҫӣдёҖз§ҚеҗҜеҠЁе’Ңз®ЎзҗҶиҝӣзЁӢ(д№ҹе°ұжҳҜеә”з”ЁзЁӢеәҸ)зҡ„ж–№жі•гҖӮеңЁJ2SE 1.5д№ӢеүҚпјҢйғҪжҳҜз”ұProcessзұ»еӨ„жқҘе®һзҺ°иҝӣзЁӢзҡ„жҺ§еҲ¶з®ЎзҗҶгҖӮ
жҜҸдёӘ ProcessBuilder е®һдҫӢз®ЎзҗҶдёҖдёӘиҝӣзЁӢеұһжҖ§йӣҶгҖӮstart() ж–№жі•еҲ©з”ЁиҝҷдәӣеұһжҖ§еҲӣе»әдёҖдёӘж–°зҡ„ Process е®һдҫӢгҖӮstart() ж–№жі•еҸҜд»Ҙд»ҺеҗҢдёҖе®һдҫӢйҮҚеӨҚи°ғз”ЁпјҢд»ҘеҲ©з”ЁзӣёеҗҢзҡ„жҲ–зӣёе…ізҡ„еұһжҖ§еҲӣе»әж–°зҡ„еӯҗиҝӣзЁӢгҖӮ
жҜҸдёӘиҝӣзЁӢз”ҹжҲҗеҷЁз®ЎзҗҶиҝҷдәӣиҝӣзЁӢеұһжҖ§пјҡ
е‘Ҫд»Ө жҳҜдёҖдёӘеӯ—з¬ҰдёІеҲ—иЎЁпјҢе®ғиЎЁзӨәиҰҒи°ғз”Ёзҡ„еӨ–йғЁзЁӢеәҸж–Ү件еҸҠе…¶еҸӮж•°(еҰӮжһңжңү)гҖӮеңЁжӯӨпјҢиЎЁзӨәжңүж•Ҳзҡ„ж“ҚдҪңзі»з»ҹе‘Ҫд»Өзҡ„еӯ—з¬ҰдёІеҲ—иЎЁжҳҜдҫқиө–дәҺзі»з»ҹзҡ„гҖӮдҫӢеҰӮпјҢжҜҸдёҖдёӘжҖ»дҪ“еҸҳйҮҸпјҢйҖҡеёёйғҪиҰҒжҲҗдёәжӯӨеҲ—иЎЁдёӯзҡ„е…ғзҙ пјҢдҪҶжңүдёҖдәӣж“ҚдҪңзі»з»ҹпјҢеёҢжңӣзЁӢеәҸиғҪиҮӘе·ұж Үи®°е‘Ҫд»ӨиЎҢеӯ—з¬ҰдёІ——еңЁиҝҷз§Қзі»з»ҹдёӯпјҢJava е®һзҺ°еҸҜиғҪйңҖиҰҒе‘Ҫд»ӨзЎ®еҲҮең°еҢ…еҗ«иҝҷдёӨдёӘе…ғзҙ гҖӮ
зҺҜеўғ жҳҜд»ҺеҸҳйҮҸ еҲ°еҖј зҡ„дҫқиө–дәҺзі»з»ҹзҡ„жҳ е°„гҖӮеҲқе§ӢеҖјжҳҜеҪ“еүҚиҝӣзЁӢзҺҜеўғзҡ„дёҖдёӘеүҜжң¬(иҜ·еҸӮйҳ… System.getenv())гҖӮ
е·ҘдҪңзӣ®еҪ•гҖӮй»ҳи®ӨеҖјжҳҜеҪ“еүҚиҝӣзЁӢзҡ„еҪ“еүҚе·ҘдҪңзӣ®еҪ•пјҢйҖҡеёёж №жҚ®зі»з»ҹеұһжҖ§ user.dir жқҘе‘ҪеҗҚгҖӮ
redirectErrorStream еұһжҖ§гҖӮжңҖеҲқпјҢжӯӨеұһжҖ§дёә falseпјҢж„ҸжҖқжҳҜеӯҗиҝӣзЁӢзҡ„ж ҮеҮҶиҫ“еҮәе’Ңй”ҷиҜҜиҫ“еҮәиў«еҸ‘йҖҒз»ҷдёӨдёӘзӢ¬з«Ӣзҡ„жөҒпјҢиҝҷдәӣжөҒеҸҜд»ҘйҖҡиҝҮ Process.getInputStream() е’Ң Process.getErrorStream() ж–№жі•жқҘи®ҝй—®гҖӮеҰӮжһңе°ҶеҖји®ҫзҪ®дёә trueпјҢж ҮеҮҶй”ҷиҜҜе°ҶдёҺж ҮеҮҶиҫ“еҮәеҗҲ并гҖӮиҝҷдҪҝеҫ—е…іиҒ”й”ҷиҜҜж¶ҲжҒҜе’Ңзӣёеә”зҡ„иҫ“еҮәеҸҳеҫ—жӣҙе®№жҳ“гҖӮеңЁжӯӨжғ…еҶөдёӢпјҢеҗҲ并зҡ„ж•°жҚ®еҸҜд»Һ Process.getInputStream() иҝ”еӣһзҡ„жөҒиҜ»еҸ–пјҢиҖҢд»Һ Process.getErrorStream() иҝ”еӣһзҡ„жөҒиҜ»еҸ–е°ҶзӣҙжҺҘеҲ°иҫҫж–Ү件е°ҫгҖӮ
дҝ®ж”№иҝӣзЁӢжһ„е»әеҷЁзҡ„еұһжҖ§е°ҶеҪұе“ҚеҗҺз»ӯз”ұиҜҘеҜ№иұЎзҡ„ start() ж–№жі•еҗҜеҠЁзҡ„иҝӣзЁӢпјҢдҪҶд»ҺдёҚдјҡеҪұе“Қд»ҘеүҚеҗҜеҠЁзҡ„иҝӣзЁӢжҲ– Java иҮӘиә«зҡ„иҝӣзЁӢгҖӮеӨ§еӨҡж•°й”ҷиҜҜжЈҖжҹҘз”ұ start() ж–№жі•жү§иЎҢгҖӮеҸҜд»Ҙдҝ®ж”№еҜ№иұЎзҡ„зҠ¶жҖҒпјҢдҪҶиҝҷж · start() е°ҶдјҡеӨұиҙҘгҖӮдҫӢеҰӮпјҢе°Ҷе‘Ҫд»ӨеұһжҖ§и®ҫзҪ®дёәдёҖдёӘз©әеҲ—иЎЁе°ҶдёҚдјҡжҠӣеҮәејӮеёёпјҢйҷӨйқһеҢ…еҗ«дәҶ start()гҖӮ
жіЁж„ҸпјҢжӯӨзұ»дёҚжҳҜеҗҢжӯҘзҡ„гҖӮеҰӮжһңеӨҡдёӘзәҝзЁӢеҗҢж—¶и®ҝй—®дёҖдёӘ ProcessBuilderпјҢиҖҢе…¶дёӯиҮіе°‘дёҖдёӘзәҝзЁӢд»Һз»“жһ„дёҠдҝ®ж”№дәҶе…¶дёӯдёҖдёӘеұһжҖ§пјҢе®ғеҝ…йЎ» дҝқжҢҒеӨ–йғЁеҗҢжӯҘгҖӮ
жһ„йҖ ж–№жі•ж‘ҳиҰҒ
ProcessBuilder(List command) еҲ©з”ЁжҢҮе®ҡзҡ„ж“ҚдҪңзі»з»ҹзЁӢеәҸе’ҢеҸӮж•°жһ„йҖ дёҖдёӘиҝӣзЁӢз”ҹжҲҗеҷЁгҖӮ ProcessBuilder(String... command) еҲ©з”ЁжҢҮе®ҡзҡ„ж“ҚдҪңзі»з»ҹзЁӢеәҸе’ҢеҸӮж•°жһ„йҖ дёҖдёӘиҝӣзЁӢз”ҹжҲҗеҷЁгҖӮ
ж–№жі•ж‘ҳиҰҒ
List command() иҝ”еӣһжӯӨиҝӣзЁӢз”ҹжҲҗеҷЁзҡ„ж“ҚдҪңзі»з»ҹзЁӢеәҸе’ҢеҸӮж•°гҖӮ ProcessBuilder command(List command) и®ҫзҪ®жӯӨиҝӣзЁӢз”ҹжҲҗеҷЁзҡ„ж“ҚдҪңзі»з»ҹзЁӢеәҸе’ҢеҸӮж•°гҖӮ ProcessBuilder command(String... command) и®ҫзҪ®жӯӨиҝӣзЁӢз”ҹжҲҗеҷЁзҡ„ж“ҚдҪңзі»з»ҹзЁӢеәҸе’ҢеҸӮж•°гҖӮ File directory() иҝ”еӣһжӯӨиҝӣзЁӢз”ҹжҲҗеҷЁзҡ„е·ҘдҪңзӣ®еҪ•гҖӮ ProcessBuilder directory(File directory) и®ҫзҪ®жӯӨиҝӣзЁӢз”ҹжҲҗеҷЁзҡ„е·ҘдҪңзӣ®еҪ•гҖӮ Map environment() иҝ”еӣһжӯӨиҝӣзЁӢз”ҹжҲҗеҷЁзҺҜеўғзҡ„еӯ—з¬ҰдёІжҳ е°„и§ҶеӣҫгҖӮ boolean redirectErrorStream() йҖҡзҹҘиҝӣзЁӢз”ҹжҲҗеҷЁжҳҜеҗҰеҗҲ并ж ҮеҮҶй”ҷиҜҜе’Ңж ҮеҮҶиҫ“еҮәгҖӮ ProcessBuilder redirectErrorStream(boolean redirectErrorStream) и®ҫзҪ®жӯӨиҝӣзЁӢз”ҹжҲҗеҷЁзҡ„ redirectErrorStream еұһжҖ§гҖӮ Process start() дҪҝз”ЁжӯӨиҝӣзЁӢз”ҹжҲҗеҷЁзҡ„еұһжҖ§еҗҜеҠЁдёҖдёӘж–°иҝӣзЁӢгҖӮ
1.2 Runtime
жҜҸдёӘ Java еә”з”ЁзЁӢеәҸйғҪжңүдёҖдёӘ Runtime зұ»е®һдҫӢпјҢдҪҝеә”з”ЁзЁӢеәҸиғҪеӨҹдёҺе…¶иҝҗиЎҢзҡ„зҺҜеўғзӣёиҝһжҺҘгҖӮеҸҜд»ҘйҖҡиҝҮ getRuntime ж–№жі•иҺ·еҸ–еҪ“еүҚиҝҗиЎҢж—¶гҖӮ
еә”з”ЁзЁӢеәҸдёҚиғҪеҲӣе»әиҮӘе·ұзҡ„ Runtime зұ»е®һдҫӢгҖӮдҪҶеҸҜд»ҘйҖҡиҝҮ getRuntime ж–№жі•иҺ·еҸ–еҪ“еүҚRuntimeиҝҗиЎҢж—¶еҜ№иұЎзҡ„еј•з”ЁгҖӮдёҖж—Ұеҫ—еҲ°дәҶдёҖдёӘеҪ“еүҚзҡ„RuntimeеҜ№иұЎзҡ„еј•з”ЁпјҢе°ұеҸҜд»Ҙи°ғз”ЁRuntimeеҜ№иұЎзҡ„ж–№жі•еҺ»жҺ§еҲ¶JavaиҷҡжӢҹжңәзҡ„зҠ¶жҖҒе’ҢиЎҢдёәгҖӮ
Javaд»Јз Ғ 收и—Ҹд»Јз Ғ
void addShutdownHook(Thread hook) жіЁеҶҢж–°зҡ„иҷҡжӢҹжңәжқҘе…ій—ӯжҢӮй’©гҖӮ int availableProcessors() еҗ‘ Java иҷҡжӢҹжңәиҝ”еӣһеҸҜз”ЁеӨ„зҗҶеҷЁзҡ„ж•°зӣ®гҖӮ Process exec(String command) еңЁеҚ•зӢ¬зҡ„иҝӣзЁӢдёӯжү§иЎҢжҢҮе®ҡзҡ„еӯ—з¬ҰдёІе‘Ҫд»ӨгҖӮ Process exec(String[] cmdarray) еңЁеҚ•зӢ¬зҡ„иҝӣзЁӢдёӯжү§иЎҢжҢҮе®ҡе‘Ҫд»Өе’ҢеҸҳйҮҸгҖӮ Process exec(String[] cmdarray, String[] envp) еңЁжҢҮе®ҡзҺҜеўғзҡ„зӢ¬з«ӢиҝӣзЁӢдёӯжү§иЎҢжҢҮе®ҡе‘Ҫд»Өе’ҢеҸҳйҮҸгҖӮ Process exec(String[] cmdarray, String[] envp, File dir) еңЁжҢҮе®ҡзҺҜеўғе’Ңе·ҘдҪңзӣ®еҪ•зҡ„зӢ¬з«ӢиҝӣзЁӢдёӯжү§иЎҢжҢҮе®ҡзҡ„е‘Ҫд»Өе’ҢеҸҳйҮҸгҖӮ Process exec(String command, String[] envp) еңЁжҢҮе®ҡзҺҜеўғзҡ„еҚ•зӢ¬иҝӣзЁӢдёӯжү§иЎҢжҢҮе®ҡзҡ„еӯ—з¬ҰдёІе‘Ҫд»ӨгҖӮ Process exec(String command, String[] envp, File dir) еңЁжңүжҢҮе®ҡзҺҜеўғе’Ңе·ҘдҪңзӣ®еҪ•зҡ„зӢ¬з«ӢиҝӣзЁӢдёӯжү§иЎҢжҢҮе®ҡзҡ„еӯ—з¬ҰдёІе‘Ҫд»ӨгҖӮ void exit(int status) йҖҡиҝҮеҗҜеҠЁиҷҡжӢҹжңәзҡ„е…ій—ӯеәҸеҲ—пјҢз»ҲжӯўеҪ“еүҚжӯЈеңЁиҝҗиЎҢзҡ„ Java иҷҡжӢҹжңәгҖӮ long freeMemory() иҝ”еӣһ Java иҷҡжӢҹжңәдёӯзҡ„з©әй—ІеҶ…еӯҳйҮҸгҖӮ void gc() иҝҗиЎҢеһғеңҫеӣһ收еҷЁгҖӮ InputStream getLocalizedInputStream(InputStream in) е·ІиҝҮж—¶гҖӮ д»Һ JDK 1.1 ејҖе§ӢпјҢе°Ҷжң¬ең°зј–з Ғеӯ—иҠӮжөҒиҪ¬жҚўдёә Unicode еӯ—з¬ҰжөҒзҡ„йҰ–йҖүж–№жі•жҳҜдҪҝз”Ё InputStreamReader е’Ң BufferedReader зұ»гҖӮ OutputStream getLocalizedOutputStream(OutputStream out) е·ІиҝҮж—¶гҖӮ д»Һ JDK 1.1 ејҖе§ӢпјҢе°Ҷ Unicode еӯ—з¬ҰжөҒиҪ¬жҚўдёәжң¬ең°зј–з Ғеӯ—иҠӮжөҒзҡ„йҰ–йҖүж–№жі•жҳҜдҪҝз”Ё OutputStreamWriterгҖҒBufferedWriter е’Ң PrintWriter зұ»гҖӮ static Runtime getRuntime() иҝ”еӣһдёҺеҪ“еүҚ Java еә”з”ЁзЁӢеәҸзӣёе…ізҡ„иҝҗиЎҢж—¶еҜ№иұЎгҖӮ void halt(int status) ејәиЎҢз»Ҳжӯўзӣ®еүҚжӯЈеңЁиҝҗиЎҢзҡ„ Java иҷҡжӢҹжңәгҖӮ void load(String filename) еҠ иҪҪдҪңдёәеҠЁжҖҒеә“зҡ„жҢҮе®ҡж–Ү件еҗҚгҖӮ void loadLibrary(String libname) еҠ иҪҪе…·жңүжҢҮе®ҡеә“еҗҚзҡ„еҠЁжҖҒеә“гҖӮ long maxMemory() иҝ”еӣһ Java иҷҡжӢҹжңәиҜ•еӣҫдҪҝз”Ёзҡ„жңҖеӨ§еҶ…еӯҳйҮҸгҖӮ boolean removeShutdownHook(Thread hook) еҸ–ж¶ҲжіЁеҶҢжҹҗдёӘе…ҲеүҚе·ІжіЁеҶҢзҡ„иҷҡжӢҹжңәе…ій—ӯжҢӮй’©гҖӮ void runFinalization() иҝҗиЎҢжҢӮиө· finalization зҡ„жүҖжңүеҜ№иұЎзҡ„з»Ҳжӯўж–№жі•гҖӮ static void runFinalizersOnExit(boolean value) е·ІиҝҮж—¶гҖӮ жӯӨж–№жі•жң¬иә«е…·жңүдёҚе®үе…ЁжҖ§гҖӮе®ғеҸҜиғҪеҜ№жӯЈеңЁдҪҝз”Ёзҡ„еҜ№иұЎи°ғз”Ёз»Ҳз»“ж–№жі•пјҢиҖҢе…¶д»–зәҝзЁӢжӯЈеңЁж“ҚдҪңиҝҷдәӣеҜ№иұЎпјҢд»ҺиҖҢеҜјиҮҙдёҚжӯЈзЎ®зҡ„иЎҢдёәжҲ–жӯ»й”ҒгҖӮ long totalMemory() иҝ”еӣһ Java иҷҡжӢҹжңәдёӯзҡ„еҶ…еӯҳжҖ»йҮҸгҖӮ void traceInstructions(boolean on) еҗҜз”Ё/зҰҒз”ЁжҢҮд»Өи·ҹиёӘгҖӮ void traceMethodCalls(boolean on) еҗҜз”Ё/зҰҒз”Ёж–№жі•и°ғз”Ёи·ҹиёӘгҖӮ
1.3 Process
дёҚз®ЎйҖҡиҝҮе“Әз§Қж–№жі•еҗҜеҠЁиҝӣзЁӢеҗҺпјҢйғҪдјҡиҝ”еӣһдёҖдёӘProcessзұ»зҡ„е®һдҫӢд»ЈиЎЁеҗҜеҠЁзҡ„иҝӣзЁӢпјҢиҜҘе®һдҫӢеҸҜз”ЁжқҘжҺ§еҲ¶иҝӣзЁӢ并иҺ·еҫ—зӣёе…ідҝЎжҒҜгҖӮProcess зұ»жҸҗдҫӣдәҶжү§иЎҢд»ҺиҝӣзЁӢиҫ“е…ҘгҖҒжү§иЎҢиҫ“еҮәеҲ°иҝӣзЁӢгҖҒзӯүеҫ…иҝӣзЁӢе®ҢжҲҗгҖҒжЈҖжҹҘиҝӣзЁӢзҡ„йҖҖеҮәзҠ¶жҖҒд»ҘеҸҠй”ҖжҜҒ(жқҖжҺү)иҝӣзЁӢзҡ„ж–№жі•пјҡ
void destroy() жқҖжҺүеӯҗиҝӣзЁӢгҖӮ дёҖиҲ¬жғ…еҶөдёӢпјҢиҜҘ方法并дёҚиғҪжқҖжҺүе·Із»ҸеҗҜеҠЁзҡ„иҝӣзЁӢпјҢдёҚз”ЁдёәеҘҪгҖӮ int exitValue() иҝ”еӣһеӯҗиҝӣзЁӢзҡ„еҮәеҸЈеҖјгҖӮ еҸӘжңүеҗҜеҠЁзҡ„иҝӣзЁӢжү§иЎҢе®ҢжҲҗгҖҒжҲ–иҖ…з”ұдәҺејӮеёёйҖҖеҮәеҗҺпјҢexitValue()ж–№жі•жүҚдјҡжңүжӯЈеёёзҡ„иҝ”еӣһеҖјпјҢеҗҰеҲҷжҠӣеҮәејӮеёёгҖӮ InputStream getErrorStream() иҺ·еҸ–еӯҗиҝӣзЁӢзҡ„й”ҷиҜҜжөҒгҖӮ еҰӮжһңй”ҷиҜҜиҫ“еҮәиў«йҮҚе®ҡеҗ‘пјҢеҲҷдёҚиғҪд»ҺиҜҘжөҒдёӯиҜ»еҸ–й”ҷиҜҜиҫ“еҮәгҖӮ InputStream getInputStream() иҺ·еҸ–еӯҗиҝӣзЁӢзҡ„иҫ“е…ҘжөҒгҖӮ еҸҜд»Ҙд»ҺиҜҘжөҒдёӯиҜ»еҸ–иҝӣзЁӢзҡ„ж ҮеҮҶиҫ“еҮәгҖӮ OutputStream getOutputStream() иҺ·еҸ–еӯҗиҝӣзЁӢзҡ„иҫ“еҮәжөҒгҖӮ еҶҷе…ҘеҲ°иҜҘжөҒдёӯзҡ„ж•°жҚ®дҪңдёәиҝӣзЁӢзҡ„ж ҮеҮҶиҫ“е…ҘгҖӮ int waitFor() еҜјиҮҙеҪ“еүҚзәҝзЁӢзӯүеҫ…пјҢеҰӮжңүеҝ…иҰҒпјҢдёҖзӣҙиҰҒзӯүеҲ°з”ұиҜҘ Process еҜ№иұЎиЎЁзӨәзҡ„иҝӣзЁӢе·Із»Ҹз»ҲжӯўгҖӮ
2.еӨҡиҝӣзЁӢзј–зЁӢе®һдҫӢ
дёҖиҲ¬жҲ‘们еңЁjavaдёӯиҝҗиЎҢе…¶е®ғзұ»дёӯзҡ„ж–№жі•ж—¶пјҢж— и®әжҳҜйқҷжҖҒи°ғз”ЁпјҢиҝҳжҳҜеҠЁжҖҒи°ғз”ЁпјҢйғҪжҳҜеңЁеҪ“еүҚзҡ„иҝӣзЁӢдёӯжү§иЎҢзҡ„пјҢд№ҹе°ұжҳҜиҜҙпјҢеҸӘжңүдёҖдёӘjavaиҷҡжӢҹжңәе®һдҫӢеңЁиҝҗиЎҢгҖӮиҖҢжңүзҡ„ж—¶еҖҷпјҢжҲ‘们йңҖиҰҒйҖҡиҝҮjavaд»Јз ҒеҗҜеҠЁеӨҡдёӘjavaеӯҗиҝӣзЁӢгҖӮиҝҷж ·еҒҡиҷҪ然еҚ з”ЁдәҶдёҖдәӣзі»з»ҹиө„жәҗпјҢдҪҶдјҡдҪҝзЁӢеәҸжӣҙеҠ зЁіе®ҡпјҢеӣ дёәж–°еҗҜеҠЁзҡ„зЁӢеәҸжҳҜеңЁдёҚеҗҢзҡ„иҷҡжӢҹжңәиҝӣзЁӢдёӯиҝҗиЎҢзҡ„пјҢеҰӮжһңжңүдёҖдёӘиҝӣзЁӢеҸ‘з”ҹејӮеёёпјҢ并дёҚеҪұе“Қе…¶е®ғзҡ„еӯҗиҝӣзЁӢгҖӮ
еңЁJavaдёӯжҲ‘们еҸҜд»ҘдҪҝз”ЁдёӨз§Қж–№жі•жқҘе®һзҺ°иҝҷз§ҚиҰҒжұӮгҖӮжңҖз®ҖеҚ•зҡ„ж–№жі•е°ұжҳҜйҖҡиҝҮRuntimeдёӯзҡ„execж–№жі•жү§иЎҢjava classnameгҖӮеҰӮжһңжү§иЎҢжҲҗеҠҹпјҢиҝҷдёӘж–№жі•иҝ”еӣһдёҖдёӘProcessеҜ№иұЎпјҢеҰӮжһңжү§иЎҢеӨұиҙҘпјҢе°ҶжҠӣеҮәдёҖдёӘIOExceptionй”ҷиҜҜгҖӮдёӢйқўи®©жҲ‘们жқҘзңӢдёҖдёӘз®ҖеҚ•зҡ„дҫӢеӯҗгҖӮ
// Test1.javaж–Ү件 import java.io.*; public class Test { гҖҖpublic static void main(String[] args) гҖҖ{ FileOutputStream fOut = new FileOutputStream("c:\\Test1.txt"); fOut.close(); System.out.println("иў«и°ғз”ЁжҲҗеҠҹ!"); гҖҖ} } // Test_Exec.java public class Test_Exec { гҖҖpublic static void main(String[] args) гҖҖ{ Runtime run = Runtime.getRuntime(); Process p = run.exec("java test1"); гҖҖ} }йҖҡиҝҮjava Test_ExecиҝҗиЎҢзЁӢеәҸеҗҺпјҢеҸ‘зҺ°еңЁCзӣҳеӨҡдәҶдёӘTest1.txtж–Ү件пјҢдҪҶеңЁжҺ§еҲ¶еҸ°дёӯ并жңӘеҮәзҺ°"иў«и°ғз”ЁжҲҗеҠҹ!"зҡ„иҫ“еҮәдҝЎжҒҜгҖӮеӣ жӯӨеҸҜд»Ҙж–ӯе®ҡпјҢTestе·Із»Ҹиў«жү§иЎҢжҲҗеҠҹпјҢдҪҶеӣ дёәжҹҗз§ҚеҺҹеӣ пјҢTestзҡ„иҫ“еҮәдҝЎжҒҜжңӘеңЁTest_Execзҡ„жҺ§еҲ¶еҸ°дёӯиҫ“еҮәгҖӮиҝҷдёӘеҺҹеӣ д№ҹеҫҲз®ҖеҚ•пјҢеӣ дёәдҪҝз”Ёexecе»әз«Ӣзҡ„жҳҜTest_Execзҡ„еӯҗиҝӣзЁӢпјҢиҝҷдёӘеӯҗиҝӣзЁӢ并没жңүиҮӘе·ұзҡ„жҺ§еҲ¶еҸ°пјҢеӣ жӯӨпјҢе®ғ并дёҚдјҡиҫ“еҮәд»»дҪ•дҝЎжҒҜгҖӮ
еҰӮжһңиҰҒиҫ“еҮәеӯҗиҝӣзЁӢзҡ„иҫ“еҮәдҝЎжҒҜпјҢеҸҜд»ҘйҖҡиҝҮProcessдёӯзҡ„getInputStreamеҫ—еҲ°еӯҗиҝӣзЁӢзҡ„иҫ“еҮәжөҒ(еңЁеӯҗиҝӣзЁӢдёӯиҫ“еҮәпјҢеңЁзҲ¶иҝӣзЁӢдёӯе°ұжҳҜиҫ“е…Ҙ)пјҢ然еҗҺе°ҶеӯҗиҝӣзЁӢдёӯзҡ„иҫ“еҮәжөҒд»ҺзҲ¶иҝӣзЁӢзҡ„жҺ§еҲ¶еҸ°иҫ“еҮәгҖӮе…·дҪ“зҡ„е®һзҺ°д»Јз ҒеҰӮдёӢеҰӮзӨәпјҡ
// Test_Exec_Out.java import java.io.*; public class Test_Exec_Out { гҖҖpublic static void main(String[] args) гҖҖ{ Runtime run = Runtime.getRuntime(); Process p = run.exec("java test1"); BufferedInputStream in = new BufferedInputStream(p.getInputStream()); BufferedReader br = new BufferedReader(new InputStreamReader(in)); String s; while ((s = br.readLine()) != null) гҖҖSystem.out.println(s); гҖҖ} }д»ҺдёҠйқўзҡ„д»Јз ҒеҸҜд»ҘзңӢеҮәпјҢеңЁTest_Exec_Out.javaдёӯйҖҡиҝҮжҢүиЎҢиҜ»еҸ–еӯҗиҝӣзЁӢзҡ„иҫ“еҮәдҝЎжҒҜпјҢ然еҗҺеңЁTest_Exec_OutдёӯжҢүжҜҸиЎҢиҝӣиЎҢиҫ“еҮәгҖӮ дёҠйқўи®Ёи®әзҡ„жҳҜеҰӮдҪ•еҫ—еҲ°еӯҗиҝӣзЁӢзҡ„иҫ“еҮәдҝЎжҒҜгҖӮйӮЈд№ҲпјҢйҷӨдәҶиҫ“еҮәдҝЎжҒҜпјҢиҝҳжңүиҫ“е…ҘдҝЎжҒҜгҖӮ既然еӯҗиҝӣзЁӢжІЎжңүиҮӘе·ұзҡ„жҺ§еҲ¶еҸ°пјҢйӮЈд№Ҳиҫ“е…ҘдҝЎжҒҜд№ҹеҫ—з”ұзҲ¶иҝӣзЁӢжҸҗдҫӣгҖӮжҲ‘们еҸҜд»ҘйҖҡиҝҮProcessзҡ„getOutputStreamж–№жі•жқҘдёәеӯҗиҝӣзЁӢжҸҗдҫӣиҫ“е…ҘдҝЎжҒҜ(еҚіз”ұзҲ¶иҝӣзЁӢеҗ‘еӯҗиҝӣзЁӢиҫ“е…ҘдҝЎжҒҜпјҢиҖҢдёҚжҳҜз”ұжҺ§еҲ¶еҸ°иҫ“е…ҘдҝЎжҒҜ)гҖӮжҲ‘们еҸҜд»ҘзңӢзңӢеҰӮдёӢзҡ„д»Јз Ғпјҡ
// Test2.javaж–Ү件 import java.io.*; public class Test { гҖҖpublic static void main(String[] args) гҖҖ{ BufferedReader br = new BufferedReader(new InputStreamReader(System.in)); System.out.println("з”ұзҲ¶иҝӣзЁӢиҫ“е…Ҙзҡ„дҝЎжҒҜпјҡ" + br.readLine()); гҖҖ} } // Test_Exec_In.java import java.io.*; public class Test_Exec_In { гҖҖpublic static void main(String[] args) гҖҖ{ Runtime run = Runtime.getRuntime(); Process p = run.exec("java test2"); BufferedWriter bw = new BufferedWriter(new OutputStreamWriter(p.getOutputStream())); bw.write("еҗ‘еӯҗиҝӣзЁӢиҫ“еҮәдҝЎжҒҜ"); bw.flush(); bw.close(); // еҝ…йЎ»еҫ—е…ій—ӯжөҒпјҢеҗҰеҲҷж— жі•еҗ‘еӯҗиҝӣзЁӢдёӯиҫ“е…ҘдҝЎжҒҜ // System.in.read(); гҖҖ} }д»Һд»ҘдёҠд»Јз ҒеҸҜд»ҘзңӢеҮәпјҢTest1еҫ—еҲ°з”ұTest_Exec_InеҸ‘иҝҮжқҘзҡ„дҝЎжҒҜпјҢ并е°Ҷе…¶иҫ“еҮәгҖӮеҪ“дҪ дёҚеҠ bw.flash()е’Ңbw.close()ж—¶пјҢдҝЎжҒҜе°Ҷж— жі•еҲ°иҫҫеӯҗиҝӣзЁӢпјҢд№ҹе°ұжҳҜиҜҙеӯҗиҝӣзЁӢиҝӣе…Ҙйҳ»еЎһзҠ¶жҖҒпјҢдҪҶз”ұдәҺзҲ¶иҝӣзЁӢе·Із»ҸйҖҖеҮәдәҶпјҢеӣ жӯӨпјҢеӯҗиҝӣзЁӢд№ҹи·ҹзқҖйҖҖеҮәдәҶгҖӮеҰӮжһңиҰҒиҜҒжҳҺиҝҷдёҖзӮ№пјҢеҸҜд»ҘеңЁжңҖеҗҺеҠ дёҠSystem.in.read()пјҢ然еҗҺйҖҡиҝҮд»»еҠЎз®ЎзҗҶеҷЁ(еңЁwindowsдёӢ)жҹҘзңӢjavaиҝӣзЁӢпјҢдҪ дјҡеҸ‘зҺ°еҰӮжһңеҠ дёҠbw.flush()е’Ңbw.close()пјҢеҸӘжңүдёҖдёӘjavaиҝӣзЁӢеӯҳеңЁпјҢеҰӮжһңеҺ»жҺүе®ғ们пјҢе°ұжңүдёӨдёӘjavaиҝӣзЁӢеӯҳеңЁгҖӮиҝҷжҳҜеӣ дёәпјҢеҰӮжһңе°ҶдҝЎжҒҜдј з»ҷTest2пјҢеңЁеҫ—еҲ°дҝЎжҒҜеҗҺпјҢTest2е°ұйҖҖеҮәдәҶгҖӮеңЁиҝҷйҮҢжңүдёҖзӮ№йңҖиҰҒиҜҙжҳҺдёҖдёӢпјҢexecзҡ„жү§иЎҢжҳҜејӮжӯҘзҡ„пјҢ并дёҚдјҡеӣ дёәжү§иЎҢзҡ„жҹҗдёӘзЁӢеәҸйҳ»еЎһиҖҢеҒңжӯўжү§иЎҢдёӢйқўзҡ„д»Јз ҒгҖӮеӣ жӯӨпјҢеҸҜд»ҘеңЁиҝҗиЎҢtest2еҗҺпјҢд»ҚеҸҜд»Ҙжү§иЎҢдёӢйқўзҡ„д»Јз ҒгҖӮ
execж–№жі•з»ҸиҝҮдәҶеӨҡж¬Ўзҡ„йҮҚиҪҪгҖӮдёҠйқўдҪҝз”Ёзҡ„еҸӘжҳҜе®ғзҡ„дёҖз§ҚйҮҚиҪҪгҖӮе®ғиҝҳеҸҜд»Ҙе°Ҷе‘Ҫд»Өе’ҢеҸӮж•°еҲҶејҖпјҢеҰӮexec("java.test2")еҸҜд»ҘеҶҷжҲҗexec("java", "test2")гҖӮexecиҝҳеҸҜд»ҘйҖҡиҝҮжҢҮе®ҡзҡ„зҺҜеўғеҸҳйҮҸиҝҗиЎҢдёҚеҗҢй…ҚзҪ®зҡ„javaиҷҡжӢҹжңәгҖӮ
йҷӨдәҶдҪҝз”ЁRuntimeзҡ„execж–№жі•е»әз«ӢеӯҗиҝӣзЁӢеӨ–пјҢиҝҳеҸҜд»ҘйҖҡиҝҮProcessBuilderе»әз«ӢеӯҗиҝӣзЁӢгҖӮProcessBuilderзҡ„дҪҝз”Ёж–№жі•еҰӮдёӢпјҡ
// Test_Exec_Out.java import java.io.*; public class Test_Exec_Out { гҖҖpublic static void main(String[] args) гҖҖ{ ProcessBuilder pb = new ProcessBuilder("java", "test1"); Process p = pb.start(); … … гҖҖ} }еңЁе»әз«ӢеӯҗиҝӣзЁӢдёҠпјҢProcessBuilderе’ҢRuntimeзұ»дјјпјҢдёҚеҗҢзҡ„ProcessBuilderдҪҝз”Ёstart()ж–№жі•еҗҜеҠЁеӯҗиҝӣзЁӢпјҢиҖҢRuntimeдҪҝз”Ёexecж–№жі•еҗҜеҠЁеӯҗиҝӣзЁӢгҖӮеҫ—еҲ°ProcessеҗҺпјҢе®ғ们зҡ„ж“ҚдҪңе°ұе®Ңе…ЁдёҖж ·зҡ„гҖӮ
ProcessBuilderе’ҢRuntimeдёҖж ·пјҢд№ҹеҸҜи®ҫзҪ®еҸҜжү§иЎҢж–Ү件зҡ„зҺҜеўғдҝЎжҒҜгҖҒе·ҘдҪңзӣ®еҪ•зӯүгҖӮдёӢйқўзҡ„дҫӢеӯҗжҸҸиҝ°дәҶеҰӮдҪ•дҪҝз”ЁProcessBuilderи®ҫзҪ®иҝҷдәӣдҝЎжҒҜгҖӮ
ProcessBuilder pb = new ProcessBuilder("Command", "arg2", "arg2", '''); // и®ҫзҪ®зҺҜеўғеҸҳйҮҸ Map<String, String> env = pb.environment(); env.put("key1", "value1"); env.remove("key2"); env.put("key2", env.get("key1") + "_test"); pb.directory("..\abcd"); // и®ҫзҪ®е·ҘдҪңзӣ®еҪ• Process p = pb.start(); // е»әз«ӢеӯҗиҝӣзЁӢж„ҹи°ўеҗ„дҪҚзҡ„йҳ…иҜ»пјҢд»ҘдёҠе°ұжҳҜвҖңJava+LinuxеҶ…ж ёжәҗз Ғд№ӢеҰӮдҪ•зҗҶи§ЈеӨҡзәҝзЁӢд№ӢиҝӣзЁӢвҖқзҡ„еҶ…е®№дәҶпјҢз»ҸиҝҮжң¬ж–Үзҡ„еӯҰд№ еҗҺпјҢзӣёдҝЎеӨ§е®¶еҜ№Java+LinuxеҶ…ж ёжәҗз Ғд№ӢеҰӮдҪ•зҗҶи§ЈеӨҡзәҝзЁӢд№ӢиҝӣзЁӢиҝҷдёҖй—®йўҳжңүдәҶжӣҙж·ұеҲ»зҡ„дҪ“дјҡпјҢе…·дҪ“дҪҝз”Ёжғ…еҶөиҝҳйңҖиҰҒеӨ§е®¶е®һи·өйӘҢиҜҒгҖӮиҝҷйҮҢжҳҜдәҝйҖҹдә‘пјҢе°Ҹзј–е°ҶдёәеӨ§е®¶жҺЁйҖҒжӣҙеӨҡзӣёе…ізҹҘиҜҶзӮ№зҡ„ж–Үз« пјҢж¬ўиҝҺе…іжіЁпјҒ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ