жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
жң¬зҜҮеҶ…е®№д»Ӣз»ҚдәҶвҖңPythonж–Үжң¬йў„еӨ„зҗҶзҡ„ж–№жі•жҳҜд»Җд№ҲвҖқзҡ„жңүе…ізҹҘиҜҶпјҢеңЁе®һйҷ…жЎҲдҫӢзҡ„ж“ҚдҪңиҝҮзЁӢдёӯпјҢдёҚе°‘дәәйғҪдјҡйҒҮеҲ°иҝҷж ·зҡ„еӣ°еўғпјҢжҺҘдёӢжқҘе°ұи®©е°Ҹзј–еёҰйўҶеӨ§е®¶еӯҰд№ дёҖдёӢеҰӮдҪ•еӨ„зҗҶиҝҷдәӣжғ…еҶөеҗ§пјҒеёҢжңӣеӨ§е®¶д»”з»Ҷйҳ…иҜ»пјҢиғҪеӨҹеӯҰжңүжүҖжҲҗпјҒ
е°Ҷж–Үжң¬дёӯеҮәзҺ°зҡ„еӯ—жҜҚиҪ¬еҢ–дёәе°ҸеҶҷ
зӨәдҫӢ1пјҡе°Ҷеӯ—жҜҚиҪ¬еҢ–дёәе°ҸеҶҷ
Python е®һзҺ°д»Јз Ғпјҡ
input_str = вҖқThe 5 biggest countries by population in 2017 are China, India, United States, Indonesia, and Brazil.вҖқ input_strinput_str = input_str.lower() print(input_str)
иҫ“еҮәпјҡ
the 5 biggest countries by population in 2017 are china, india, united states, indonesia, and brazil.
еҲ йҷӨж–Үжң¬дёӯеҮәзҺ°зҡ„ж•°еӯ—
еҰӮжһңж–Үжң¬дёӯзҡ„ж•°еӯ—дёҺж–Үжң¬еҲҶжһҗж— е…ізҡ„иҜқпјҢйӮЈе°ұеҲ йҷӨиҝҷдәӣж•°еӯ—гҖӮйҖҡеёёпјҢжӯЈеҲҷеҢ–иЎЁиҫҫејҸеҸҜд»Ҙеё®еҠ©дҪ е®һзҺ°иҝҷдёҖиҝҮзЁӢгҖӮ
зӨәдҫӢ2пјҡеҲ йҷӨж•°еӯ—
Python е®һзҺ°д»Јз Ғпјҡ
import re input_str = ’Box A contains 3 red and 5 white balls, while Box B contains 4 red and 2 blue balls.’ reresult = re.sub(r’\d+’, ‘’, input_str) print(result)
иҫ“еҮәпјҡ
Box A contains red and white balls, while Box B contains red and blue balls.
еҲ йҷӨж–Үжң¬дёӯеҮәзҺ°зҡ„ж ҮзӮ№
д»ҘдёӢзӨәдҫӢд»Јз Ғжј”зӨәеҰӮдҪ•еҲ йҷӨж–Үжң¬дёӯзҡ„ж ҮзӮ№з¬ҰеҸ·пјҢеҰӮ [!вҖқ#$%&’()*+,-./:;<=>?@[\]^_`{|}~] зӯүз¬ҰеҸ·гҖӮ
зӨәдҫӢ3пјҡеҲ йҷӨж ҮзӮ№
Python е®һзҺ°д»Јз Ғпјҡ
import string input_str = вҖңThis &is [an] example? {of} string. with.? punctuation!!!!вҖқ # Sample string result = input_str.translate(string.maketrans(вҖңвҖқ,вҖқвҖқ), string.punctuation) print(result)иҫ“еҮәпјҡ
This is an example of string with punctuation
еҲ йҷӨж–Үжң¬дёӯеҮәзҺ°зҡ„з©әж ј
еҸҜд»ҘйҖҡиҝҮ strip()еҮҪ数移йҷӨж–Үжң¬еүҚеҗҺеҮәзҺ°зҡ„з©әж јгҖӮ
зӨәдҫӢ4пјҡеҲ йҷӨз©әж ј
Python е®һзҺ°д»Јз Ғпјҡ
input_str = вҖң \t a string example\t вҖң input_strinput_str = input_str.strip() input_str
иҫ“еҮәпјҡ
‘a string example’
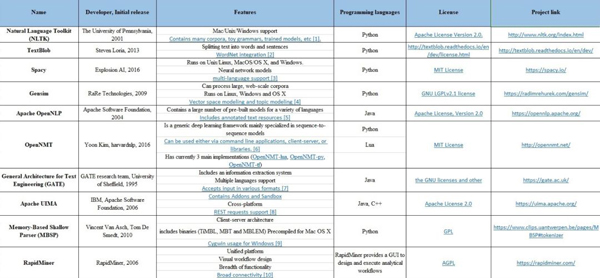
з¬ҰеҸ·еҢ–пјҲTokenizationпјү
з¬ҰеҸ·еҢ–жҳҜе°Ҷз»ҷе®ҡзҡ„ж–Үжң¬жӢҶеҲҶжҲҗжҜҸдёӘеёҰж Үи®°зҡ„е°ҸжЁЎеқ—зҡ„иҝҮзЁӢпјҢе…¶дёӯеҚ•иҜҚгҖҒж•°еӯ—гҖҒж ҮзӮ№еҸҠе…¶д»–з¬ҰеҸ·зӯүйғҪеҸҜи§ҶдёәжҳҜдёҖз§Қж Үи®°гҖӮеңЁдёӢиЎЁдёӯпјҲTokenization sheetпјүпјҢзҪ—еҲ—еҮәз”ЁдәҺе®һзҺ°з¬ҰеҸ·еҢ–иҝҮзЁӢзҡ„дёҖдәӣеёёз”Ёе·Ҙе…·гҖӮ
еҲ йҷӨж–Үжң¬дёӯеҮәзҺ°зҡ„з»ҲжӯўиҜҚ
з»ҲжӯўиҜҚпјҲStop wordsпјү жҢҮзҡ„жҳҜвҖңaвҖқпјҢвҖңaвҖқпјҢвҖңonвҖқпјҢвҖңisвҖқпјҢвҖңallвҖқзӯүиҜӯиЁҖдёӯжңҖеёёи§Ғзҡ„иҜҚгҖӮиҝҷдәӣиҜҚиҜӯжІЎд»Җд№Ҳзү№еҲ«жҲ–йҮҚиҰҒж„Ҹд№үпјҢйҖҡеёёеҸҜд»Ҙд»Һж–Үжң¬дёӯеҲ йҷӨгҖӮдёҖиҲ¬дҪҝз”Ё Natural Language ToolkitпјҲNLTKпјү жқҘеҲ йҷӨиҝҷдәӣз»ҲжӯўиҜҚпјҢиҝҷжҳҜдёҖеҘ—дё“й—Ёз”ЁдәҺз¬ҰеҸ·е’ҢиҮӘ然иҜӯиЁҖеӨ„зҗҶз»ҹи®Ўзҡ„ејҖжәҗеә“гҖӮ
зӨәдҫӢ7пјҡеҲ йҷӨз»ҲжӯўиҜҚ
е®һзҺ°д»Јз Ғпјҡ
input_str = вҖңNLTK is a leading platform for building Python programs to work with human language data.вҖқ stop_words = set(stopwords.words(‘english’)) from nltk.tokenize import word_tokenize tokens = word_tokenize(input_str) result = [i for i in tokens if not i in stop_words] print (result)
иҫ“еҮәпјҡ
[‘NLTK’, ‘leading’, ‘platform’, ‘building’, ‘Python’, ‘programs’, ‘work’, ‘human’, ‘language’, ‘data’, ‘.’]
жӯӨеӨ–пјҢscikit-learn д№ҹжҸҗдҫӣдәҶдёҖдёӘз”ЁдәҺеӨ„зҗҶз»ҲжӯўиҜҚзҡ„е·Ҙе…·пјҡ
from sklearn.feature_extraction.stop_words import ENGLISH_STOP_WORDS
еҗҢж ·пјҢspaCy д№ҹжңүдёҖдёӘзұ»дјјзҡ„еӨ„зҗҶе·Ҙе…·пјҡ
from spacy.lang.en.stop_words import STOP_WORDS
еҲ йҷӨж–Үжң¬дёӯеҮәзҺ°зҡ„зЁҖз–ҸиҜҚе’Ңзү№е®ҡиҜҚ
еңЁжҹҗдәӣжғ…еҶөдёӢпјҢжңүеҝ…иҰҒеҲ йҷӨж–Үжң¬дёӯеҮәзҺ°зҡ„дёҖдәӣзЁҖз–ҸжңҜиҜӯжҲ–зү№е®ҡиҜҚгҖӮиҖғиҷ‘еҲ°д»»дҪ•еҚ•иҜҚйғҪеҸҜд»Ҙиў«и®ӨдёәжҳҜдёҖз»„з»ҲжӯўиҜҚпјҢеӣ жӯӨеҸҜд»ҘйҖҡиҝҮз»ҲжӯўиҜҚеҲ йҷӨе·Ҙе…·жқҘе®һзҺ°иҝҷдёҖзӣ®ж ҮгҖӮ
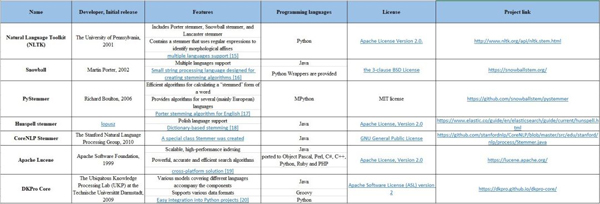
иҜҚе№ІжҸҗеҸ–пјҲStemmingпјү
иҜҚе№ІжҸҗеҸ–жҳҜдёҖдёӘе°ҶиҜҚиҜӯз®ҖеҢ–дёәиҜҚе№ІгҖҒиҜҚж №жҲ–иҜҚеҪўзҡ„иҝҮзЁӢпјҲеҰӮ books-bookпјҢlooked-lookпјүгҖӮеҪ“еүҚдё»жөҒзҡ„дёӨз§Қз®—жі•жҳҜ Porter stemming з®—жі•пјҲеҲ йҷӨеҚ•иҜҚдёӯеҲ йҷӨеёёи§Ғзҡ„еҪўжҖҒе’ҢжӢҗзӮ№з»“е°ҫпјү е’Ң Lancaster stemming з®—жі•гҖӮ
зӨәдҫӢ 8пјҡдҪҝз”Ё NLYK е®һзҺ°иҜҚе№ІжҸҗеҸ–
е®һзҺ°д»Јз Ғпјҡ
from nltk.stem import PorterStemmer from nltk.tokenize import word_tokenize stemmer= PorterStemmer() input_str=вҖқThere are several types of stemming algorithms.вҖқ input_str=word_tokenize(input_str) for word in input_str: print(stemmer.stem(word))
иҫ“еҮәпјҡ
There are sever type of stem algorithm.
иҜҚеҪўиҝҳеҺҹпјҲLemmatizationпјү
иҜҚеҪўиҝҳеҺҹзҡ„зӣ®зҡ„пјҢеҰӮиҜҚе№ІиҝҮзЁӢпјҢжҳҜе°ҶеҚ•иҜҚзҡ„дёҚеҗҢеҪўејҸиҝҳеҺҹеҲ°дёҖдёӘеёёи§Ғзҡ„еҹәзЎҖеҪўејҸгҖӮдёҺиҜҚе№ІжҸҗеҸ–иҝҮзЁӢзӣёеҸҚпјҢиҜҚеҪўиҝҳеҺҹ并дёҚжҳҜз®ҖеҚ•ең°еҜ№еҚ•иҜҚиҝӣиЎҢеҲҮж–ӯжҲ–еҸҳеҪўпјҢиҖҢжҳҜйҖҡиҝҮдҪҝз”ЁиҜҚжұҮзҹҘиҜҶеә“жқҘиҺ·еҫ—жӯЈзЎ®зҡ„еҚ•иҜҚеҪўејҸгҖӮ
еҪ“еүҚеёёз”Ёзҡ„иҜҚеҪўиҝҳеҺҹе·Ҙе…·еә“еҢ…жӢ¬пјҡ NLTKпјҲWordNet LemmatizerпјүпјҢspaCyпјҢTextBlobпјҢPatternпјҢgensimпјҢStanford CoreNLPпјҢеҹәдәҺеҶ…еӯҳзҡ„жө…еұӮи§ЈжһҗеҷЁпјҲMBSPпјүпјҢApache OpenNLPпјҢApache LuceneпјҢж–Үжң¬е·ҘзЁӢйҖҡз”Ёжһ¶жһ„пјҲGATEпјүпјҢIllinois Lemmatizer е’Ң DKPro CoreгҖӮ
зӨәдҫӢ 9пјҡдҪҝз”Ё NLYK е®һзҺ°иҜҚеҪўиҝҳеҺҹ
е®һзҺ°д»Јз Ғпјҡ
from nltk.stem import WordNetLemmatizer from nltk.tokenize import word_tokenize lemmatizer=WordNetLemmatizer() input_str=вҖқbeen had done languages cities miceвҖқ input_str=word_tokenize(input_str) for word in input_str: print(lemmatizer.lemmatize(word))
иҫ“еҮәпјҡ
be have do language city mouse
иҜҚжҖ§ж ҮжіЁпјҲPOSпјү
иҜҚжҖ§ж ҮжіЁж—ЁеңЁеҹәдәҺиҜҚиҜӯзҡ„е®ҡд№үе’ҢдёҠдёӢж–Үж„Ҹд№үпјҢдёәз»ҷе®ҡж–Үжң¬дёӯзҡ„жҜҸдёӘеҚ•иҜҚпјҲеҰӮеҗҚиҜҚгҖҒеҠЁиҜҚгҖҒеҪўе®№иҜҚе’Ңе…¶д»–еҚ•иҜҚпјү еҲҶй…ҚиҜҚжҖ§гҖӮеҪ“еүҚжңүи®ёеӨҡеҢ…еҗ« POS ж Үи®°еҷЁзҡ„е·Ҙе…·пјҢеҢ…жӢ¬ NLTKпјҢspaCyпјҢTextBlobпјҢPatternпјҢStanford CoreNLPпјҢеҹәдәҺеҶ…еӯҳзҡ„жө…еұӮеҲҶжһҗеҷЁпјҲMBSPпјүпјҢApache OpenNLPпјҢApache LuceneпјҢж–Үжң¬е·ҘзЁӢйҖҡз”Ёжһ¶жһ„пјҲGATEпјүпјҢFreeLingпјҢIllinois Part of Speech Tagger е’Ң DKPro CoreгҖӮ
зӨәдҫӢ 10пјҡдҪҝз”Ё TextBlob е®һзҺ°иҜҚжҖ§ж ҮжіЁ
е®һзҺ°д»Јз Ғпјҡ
input_str=вҖқParts of speech examples: an article, to write, interesting, easily, and, ofвҖқ from textblob import TextBlob result = TextBlob(input_str) print(result.tags)
иҫ“еҮәпјҡ
[(‘Parts’, u’NNS’), (‘of’, u’IN’), (‘speech’, u’NN’), (‘examples’, u’NNS’), (‘an’, u’DT’), (‘article’, u’NN’), (‘to’, u’TO’), (‘write’, u’VB’), (‘interesting’, u’VBG’), (‘easily’, u’RB’), (‘and’, u’CC’), (‘of’, u’IN’)]
иҜҚиҜӯеҲҶеқ—пјҲжө…и§Јжһҗпјү
иҜҚиҜӯеҲҶеқ—жҳҜдёҖз§ҚиҜҶеҲ«еҸҘеӯҗдёӯзҡ„з»„жҲҗйғЁеҲҶпјҲеҰӮеҗҚиҜҚгҖҒеҠЁиҜҚгҖҒеҪўе®№иҜҚзӯүпјүпјҢ并е°Ҷе®ғ们й“ҫжҺҘеҲ°е…·жңүдёҚиҝһз»ӯиҜӯжі•ж„Ҹд№үзҡ„й«ҳйҳ¶еҚ•е…ғпјҲеҰӮеҗҚиҜҚз»„жҲ–зҹӯиҜӯгҖҒеҠЁиҜҚз»„зӯүпјү зҡ„иҮӘ然иҜӯиЁҖиҝҮзЁӢгҖӮеёёз”Ёзҡ„иҜҚиҜӯеҲҶеқ—е·Ҙе…·еҢ…жӢ¬пјҡNLTKпјҢTreeTagger chunkerпјҢApache OpenNLPпјҢж–Үжң¬е·ҘзЁӢйҖҡз”Ёжһ¶жһ„пјҲGATEпјүпјҢFreeLingгҖӮ
зӨәдҫӢ 11пјҡдҪҝз”Ё NLYK е®һзҺ°иҜҚиҜӯеҲҶеқ—
第дёҖжӯҘйңҖиҰҒзЎ®е®ҡжҜҸдёӘеҚ•иҜҚзҡ„иҜҚжҖ§гҖӮ
е®һзҺ°д»Јз Ғпјҡ
input_str=вҖқA black television and a white stove were bought for the new apartment of John.вҖқ from textblob import TextBlob result = TextBlob(input_str) print(result.tags)
иҫ“еҮәпјҡ
[(‘A’, u’DT’), (‘black’, u’JJ’), (‘television’, u’NN’), (‘and’, u’CC’), (‘a’, u’DT’), (‘white’, u’JJ’), (‘stove’, u’NN’), (‘were’, u’VBD’), (‘bought’, u’VBN’), (‘for’, u’IN’), (‘the’, u’DT’), (‘new’, u’JJ’), (‘apartment’, u’NN’), (‘of’, u’IN’), (‘John’, u’NNP’)]
дәҢйғЁе°ұжҳҜиҝӣиЎҢиҜҚиҜӯеҲҶеқ—
е®һзҺ°д»Јз Ғпјҡ
reg_exp = вҖңNP: {<DT>?<JJ>*<NN>}вҖқ rp = nltk.RegexpParser(reg_exp) result = rp.parse(result.tags) print(result)иҫ“еҮәпјҡ
(S (NP A/DT black/JJ television/NN) and/CC (NP a/DT white/JJ stove/NN) were/VBD bought/VBN for/IN (NP the/DT new/JJ apartment/NN) of/IN John/NNP)
д№ҹеҸҜд»ҘйҖҡиҝҮ result.draw(пјү еҮҪж•°з»ҳеҲ¶еҸҘеӯҗж ‘з»“жһ„еӣҫпјҢеҰӮдёӢеӣҫжүҖзӨәгҖӮ

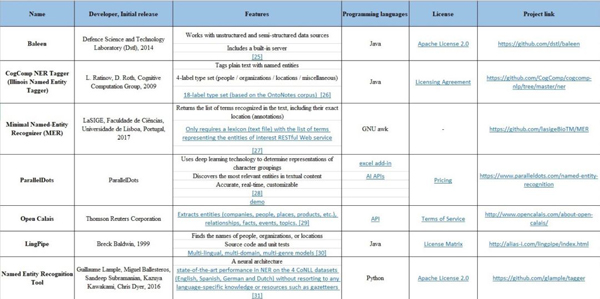
е‘ҪеҗҚе®һдҪ“иҜҶеҲ«пјҲNamed Entity Recognitionпјү
е‘ҪеҗҚе®һдҪ“иҜҶеҲ«пјҲNERпјү ж—ЁеңЁд»Һж–Үжң¬дёӯжүҫеҲ°е‘ҪеҗҚе®һдҪ“пјҢ并е°Ҷе®ғ们еҲ’еҲҶеҲ°дәӢе…Ҳйў„е®ҡд№үзҡ„зұ»еҲ«пјҲдәәе‘ҳгҖҒең°зӮ№гҖҒз»„з»ҮгҖҒж—¶й—ҙзӯүпјүгҖӮ
еёёи§Ғзҡ„е‘ҪеҗҚе®һдҪ“иҜҶеҲ«е·Ҙе…·еҰӮдёӢиЎЁжүҖзӨәпјҢеҢ…жӢ¬пјҡNLTKпјҢspaCyпјҢж–Үжң¬е·ҘзЁӢйҖҡз”Ёжһ¶жһ„пјҲGATEпјү -- ANNIEпјҢApache OpenNLPпјҢStanford CoreNLPпјҢDKProж ёеҝғпјҢMITIEпјҢWatson NLPпјҢTextRazorпјҢFreeLing зӯүгҖӮ
зӨәдҫӢ 12пјҡдҪҝз”Ё TextBlob е®һзҺ°иҜҚжҖ§ж ҮжіЁ
е®һзҺ°д»Јз Ғпјҡ
from nltk import word_tokenize, pos_tag, ne_chunk input_str = вҖңBill works for Apple so he went to Boston for a conference.вҖқ print ne_chunk(pos_tag(word_tokenize(input_str)))
иҫ“еҮәпјҡ
(S (PERSON Bill/NNP) works/VBZ for/IN Apple/NNP so/IN he/PRP went/VBD to/TO (GPE Boston/NNP) for/IN a/DT conference/NN ./.)
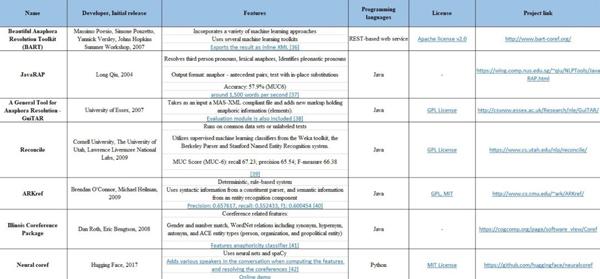
е…ұжҢҮи§Јжһҗ Coreference resolutionпјҲеӣһжҢҮеҲҶиҫЁзҺҮ anaphora resolutionпјү
д»ЈиҜҚе’Ңе…¶д»–еј•з”ЁиЎЁиҫҫеә”иҜҘдёҺжӯЈзЎ®зҡ„дёӘдҪ“иҒ”зі»иө·жқҘгҖӮCoreference resolution еңЁж–Үжң¬дёӯжҢҮзҡ„жҳҜеј•з”Ёзңҹе®һдё–з•Ңдёӯзҡ„еҗҢдёҖдёӘе®һдҪ“гҖӮеҰӮеңЁеҸҘеӯҗ вҖңе®үеҫ·йІҒиҜҙд»–дјҡд№°иҪҰвҖқдёӯпјҢд»ЈиҜҚвҖңд»–вҖқжҢҮзҡ„жҳҜеҗҢдёҖдёӘдәәпјҢеҚівҖңе®үеҫ·йІҒвҖқгҖӮеёёз”Ёзҡ„ Coreference resolution е·Ҙе…·еҰӮдёӢиЎЁжүҖзӨәпјҢеҢ…жӢ¬ Stanford CoreNLPпјҢspaCyпјҢOpen CalaisпјҢApache OpenNLP зӯүгҖӮ
жҗӯй…ҚжҸҗеҸ–пјҲCollocation extractionпјү
жҗӯй…ҚжҸҗеҸ–иҝҮзЁӢ并дёҚжҳҜеҚ•зӢ¬гҖҒеҒ¶з„¶еҸ‘з”ҹзҡ„пјҢе®ғжҳҜдёҺеҚ•иҜҚз»„еҗҲдёҖеҗҢеҸ‘з”ҹзҡ„иҝҮзЁӢгҖӮиҜҘиҝҮзЁӢзҡ„зӨәдҫӢеҢ…жӢ¬вҖңжү“з ҙ规еҲҷ break the rulesвҖқпјҢвҖңз©әй—Іж—¶й—ҙ free timeвҖқпјҢвҖңеҫ—еҮәз»“и®ә draw a conclusionвҖқпјҢвҖңи®°дҪҸ keep in mindвҖқпјҢвҖңеҮҶеӨҮеҘҪ get readyвҖқзӯүгҖӮ
зӨәдҫӢ 13пјҡдҪҝз”Ё ICE е®һзҺ°жҗӯй…ҚжҸҗеҸ–
е®һзҺ°д»Јз Ғпјҡ
input=[вҖңhe and Chazz duel with all keys on the line.вҖқ] from ICE import CollocationExtractor extractor = CollocationExtractor.with_collocation_pipeline(вҖңT1вҖқ , bing_key = вҖңTempвҖқ,pos_check = False) print(extractor.get_collocations_of_length(input, length = 3))
иҫ“еҮәпјҡ
[вҖңon the lineвҖқ]
е…ізі»жҸҗеҸ–пјҲRelationship extractionпјү
е…ізі»жҸҗеҸ–иҝҮзЁӢжҳҜжҢҮд»Һйқһз»“жһ„еҢ–зҡ„ж•°жҚ®жәҗ пјҲеҰӮеҺҹе§Ӣж–Үжң¬пјүиҺ·еҸ–з»“жһ„еҢ–зҡ„ж–Үжң¬дҝЎжҒҜгҖӮдёҘж јжқҘиҜҙпјҢе®ғзЎ®е®ҡдәҶе‘ҪеҗҚе®һдҪ“пјҲеҰӮдәәгҖҒз»„з»ҮгҖҒең°зӮ№зҡ„е®һдҪ“пјү д№Ӣй—ҙзҡ„е…ізі»пјҲеҰӮй…ҚеҒ¶гҖҒе°ұдёҡзӯүе…ізі»пјүгҖӮдҫӢеҰӮпјҢд»ҺвҖңжҳЁеӨ©дёҺ Mark е’Ң Emily з»“е©ҡвҖқиҝҷеҸҘиҜқдёӯпјҢжҲ‘们еҸҜд»ҘжҸҗеҸ–еҲ°зҡ„дҝЎжҒҜжҳҜ Mark жҳҜ Emily зҡ„дёҲеӨ«гҖӮ
вҖңPythonж–Үжң¬йў„еӨ„зҗҶзҡ„ж–№жі•жҳҜд»Җд№ҲвҖқзҡ„еҶ…е®№е°ұд»Ӣз»ҚеҲ°иҝҷйҮҢдәҶпјҢж„ҹи°ўеӨ§е®¶зҡ„йҳ…иҜ»гҖӮеҰӮжһңжғідәҶи§ЈжӣҙеӨҡиЎҢдёҡзӣёе…ізҡ„зҹҘиҜҶеҸҜд»Ҙе…іжіЁдәҝйҖҹдә‘зҪ‘з«ҷпјҢе°Ҹзј–е°ҶдёәеӨ§е®¶иҫ“еҮәжӣҙеӨҡй«ҳиҙЁйҮҸзҡ„е®һз”Ёж–Үз« пјҒ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ