您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
这篇文章将为大家详细讲解有关Linux下故障分析怎么用,小编觉得挺实用的,因此分享给大家做个参考,希望大家阅读完这篇文章后可以有所收获。
1、背景
有时候会遇到一些疑难杂症,并且监控插件并不能一眼立马发现问题的根源。这时候就需要登录服务器进一步深入分析问题的根源。那么分析问题需要有一定的技术经验积累,并且有些问题涉及到的领域非常广,才能定位到问题。所以,分析问题和踩坑是非常锻炼一个人的成长和提升自我能力。如果我们有一套好的分析工具,那将是事半功倍,能够帮助大家快速定位问题,节省大家很多时间做更深入的事情。
2、说明
本篇文章主要介绍各种问题定位的工具以及会结合案例分析问题。
3、分析问题的方法论
套用5W2H方法,可以提出性能分析的几个问题
What-现象是什么样的
When-什么时候发生
Why-为什么会发生
Where-哪个地方发生的问题
How much-耗费了多少资源
How to do-怎么解决问题
4、cpu
4.1 说明
针对应用程序,我们通常关注的是内核CPU调度器功能和性能。
线程的状态分析主要是分析线程的时间用在什么地方,而线程状态的分类一般分为:
a. on-CPU:执行中,执行中的时间通常又分为用户态时间user和系统态时间sys。
b. off-CPU:等待下一轮上CPU,或者等待I/O、锁、换页等等,其状态可以细分为可执行、匿名换页、睡眠、锁、空闲等状态。
如果大量时间花在CPU上,对CPU的剖析能够迅速解释原因;如果系统时间大量处于off-cpu状态,定位问题就会费时很多。但是仍然需要清楚一些概念:
处理器
核
硬件线程
CPU内存缓存
时钟频率
每指令周期数CPI和每周期指令数IPC
CPU指令
使用率
用户时间/内核时间
调度器
运行队列
抢占
多进程
多线程
字长
4.2 分析工具
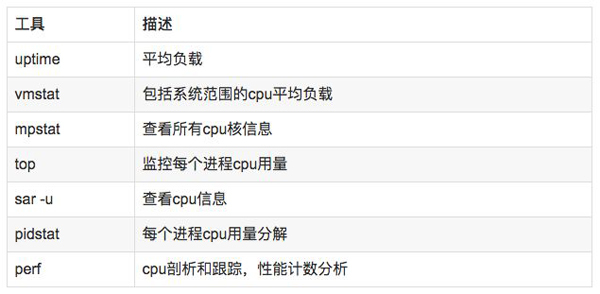
说明:
uptime,vmstat,mpstat,top,pidstat只能查询到cpu及负载的的使用情况。
perf可以跟着到进程内部具体函数耗时情况,并且可以指定内核函数进行统计,指哪打哪。
4.3 使用方式
//查看系统cpu使用情况 top //查看所有cpu核信息 mpstat -P ALL 1 //查看cpu使用情况以及平均负载 vmstat 1 //进程cpu的统计信息 pidstat -u 1 -p pid //跟踪进程内部函数级cpu使用情况 perf top -p pid -e cpu-clock
5、内存
5.1 说明
内存是为提高效率而生,实际分析问题的时候,内存出现问题可能不只是影响性能,而是影响服务或者引起其他问题。同样对于内存有些概念需要清楚:
主存
虚拟内存
常驻内存
地址空间
OOM
页缓存
缺页
换页
交换空间
交换
用户分配器libc、glibc、libmalloc和mtmalloc
LINUX内核级SLUB分配器
5.2 分析工具
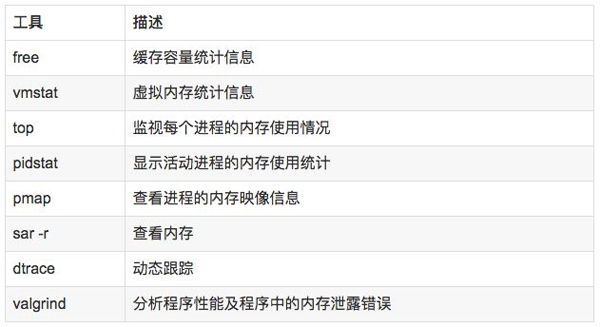
说明:
free,vmstat,top,pidstat,pmap只能统计内存信息以及进程的内存使用情况。
valgrind可以分析内存泄漏问题。
dtrace动态跟踪。需要对内核函数有很深入的了解,通过D语言编写脚本完成跟踪。
5.3 使用方式
//查看系统内存使用情况 free -m //虚拟内存统计信息 vmstat 1 //查看系统内存情况 top //1s采集周期,获取内存的统计信息 pidstat -p pid -r 1 //查看进程的内存映像信息 pmap -d pid //检测程序内存问题 valgrind --tool=memcheck --leak-check=full --log-file=./log.txt ./程序名
6、磁盘IO
6.1 说明
磁盘通常是计算机最慢的子系统,也是最容易出现性能瓶颈的地方,因为磁盘离 CPU 距离最远而且 CPU 访问磁盘要涉及到机械操作,比如转轴、寻轨等。访问硬盘和访问内存之间的速度差别是以数量级来计算的,就像1天和1分钟的差别一样。要监测 IO 性能,有必要了解一下基本原理和 Linux 是如何处理硬盘和内存之间的 IO 的。
在理解磁盘IO之前,同样我们需要理解一些概念,例如:
文件系统
VFS
文件系统缓存
页缓存page cache
缓冲区高速缓存buffer cache
目录缓存
inode
inode缓存
noop调用策略
6.2 分析工具
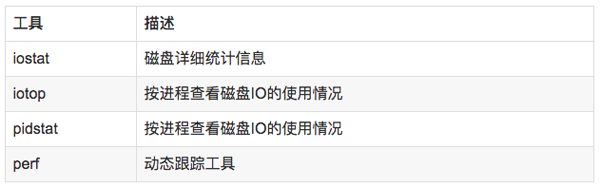
6.3 使用方式
//查看系统io信息 iotop //统计io详细信息 iostat -d -x -k 1 10 //查看进程级io的信息 pidstat -d 1 -p pid //查看系统IO的请求,比如可以在发现系统IO异常时,可以使用该命令进行调查,就能指定到底是什么原因导致的IO异常 perf record -e block:block_rq_issue -ag ^C perf report
7、网络
7.1 说明
网络的监测是所有 Linux 子系统里面最复杂的,有太多的因素在里面,比如:延迟、阻塞、冲突、丢包等,更糟的是与 Linux 主机相连的路由器、交换机、无线信号都会影响到整体网络并且很难判断是因为 Linux 网络子系统的问题还是别的设备的问题,增加了监测和判断的复杂度。现在我们使用的所有网卡都称为自适应网卡,意思是说能根据网络上的不同网络设备导致的不同网络速度和工作模式进行自动调整。
7.2 分析工具

7.3 使用方式
//显示网络统计信息 netstat -s //显示当前UDP连接状况 netstat -nu //显示UDP端口号的使用情况 netstat -apu //统计机器中网络连接各个状态个数 netstat -a | awk '/^tcp/ {++S[$NF]} END {for(a in S) print a, S[a]}' //显示TCP连接 ss -t -a //显示sockets摘要信息 ss -s //显示所有udp sockets ss -u -a //tcp,etcp状态 sar -n TCP,ETCP 1 //查看网络IO sar -n DEV 1 //抓包以包为单位进行输出 tcpdump -i eth2 host 192.168.1.1 and port 80 //抓包以流为单位显示数据内容 tcpflow -cp host 192.168.1.18、系统负载
8.1 说明
Load 就是对计算机干活多少的度量(WikiPedia:the system Load is a measure of the amount of work that a compute system is doing)简单的说是进程队列的长度。Load Average 就是一段时间(1分钟、5分钟、15分钟)内平均Load。
8.2 分析工具
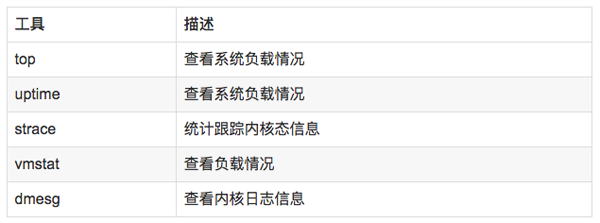
8.3 使用方式
//查看负载情况 uptime top vmstat //统计系统调用耗时情况 strace -c -p pid //跟踪指定的系统操作例如epoll_wait strace -T -e epoll_wait -p pid //查看内核日志信息 dmesg
9、火焰图
9.1 说明
火焰图(Flame Graph是 Bredan Gregg 创建的一种性能分析图表,因为它的样子近似 ?而得名。
火焰图主要是用来展示 CPU的调用栈。
y 轴表示调用栈,每一层都是一个函数。调用栈越深,火焰就越高,顶部就是正在执行的函数,下方都是它的父函数。
x 轴表示抽样数,如果一个函数在 x 轴占据的宽度越宽,就表示它被抽到的次数多,即执行的时间长。注意,x 轴不代表时间,而是所有的调用栈合并后,按字母顺序排列的。
火焰图就是看顶层的哪个函数占据的宽度最大。只要有”平顶”(plateaus),就表示该函数可能存在性能问题。颜色没有特殊含义,因为火焰图表示的是 CPU 的繁忙程度,所以一般选择暖色调。
常见的火焰图类型有On-CPU、Off-CPU、Memory、Hot/Cold、Differential等等。
9.2 安装依赖库
//安装systemtap,默认系统已安装 yum install systemtap systemtap-runtime //内核调试库必须跟内核版本对应,例如:uname -r 2.6.18-308.el5 kernel-debuginfo-2.6.18-308.el5.x86_64.rpm kernel-devel-2.6.18-308.el5.x86_64.rpm kernel-debuginfo-common-2.6.18-308.el5.x86_64.rpm //安装内核调试库 debuginfo-install --enablerepo=debuginfo search kernel debuginfo-install --enablerepo=debuginfo search glibc
9.3 安装
git clone https://github.com/lidaohang/quick_location.git cd quick_location
9.4 CPU级别火焰图
cpu占用过高,或者使用率提不上来,你能快速定位到代码的哪块有问题吗?
一般的做法可能就是通过日志等方式去确定问题。现在我们有了火焰图,能够非常清晰的发现哪个函数占用cpu过高,或者过低导致的问题。
9.4.1 on-CPU
cpu占用过高,执行中的时间通常又分为用户态时间user和系统态时间sys。
使用方式:
//on-CPU user sh ngx_on_cpu_u.sh pid //进入结果目录 cd ngx_on_cpu_u //on-CPU kernel sh ngx_on_cpu_k.sh pid //进入结果目录 cd ngx_on_cpu_k //开一个临时端口8088 python -m SimpleHTTPServer 8088 //打开浏览器输入地址 127.0.0.1:8088/pid.svg
DEMO:
#include <stdio.h> #include <stdlib.h> void foo3() { } void foo2() { int i; for(i=0 ; i < 10; i++) foo3(); } void foo1() { int i; for(i = 0; i< 1000; i++) foo3(); } int main(void) { int i; for( i =0; i< 1000000000; i++) { foo1(); foo2(); } }DEMO火焰图:

9.4.2 off-CPU
cpu过低,利用率不高。等待下一轮CPU,或者等待I/O、锁、换页等等,其状态可以细分为可执行、匿名换页、睡眠、锁、空闲等状态。
使用方式:
// off-CPU user sh ngx_off_cpu_u.sh pid //进入结果目录 cd ngx_off_cpu_u //off-CPU kernel sh ngx_off_cpu_k.sh pid //进入结果目录 cd ngx_off_cpu_k //开一个临时端口8088 python -m SimpleHTTPServer 8088 //打开浏览器输入地址 127.0.0.1:8088/pid.svg
官网DEMO:
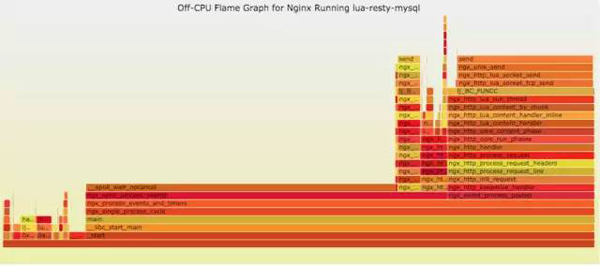
9.5 内存级别火焰图
如果线上程序出现了内存泄漏,并且只在特定的场景才会出现。这个时候我们怎么办呢?有什么好的方式和工具能快速的发现代码的问题呢?同样内存级别火焰图帮你快速分析问题的根源。
使用方式:
sh ngx_on_memory.sh pid //进入结果目录 cd ngx_on_memory //开一个临时端口8088 python -m SimpleHTTPServer 8088 //打开浏览器输入地址 127.0.0.1:8088/pid.svg
官网DEMO:
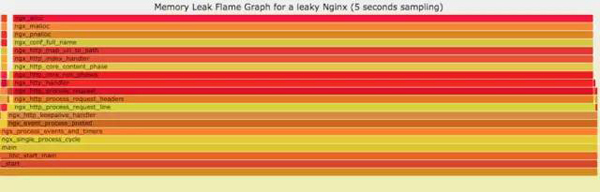
9.6 性能回退-红蓝差分火焰图
你能快速定位CPU性能回退的问题么?如果你的工作环境非常复杂且变化快速,那么使用现有的工具是来定位这类问题是很具有挑战性的。当你花掉数周时间把根因找到时,代码已经又变更了好几轮,新的性能问题又冒了出来。主要可以用到每次构建中,每次上线做对比看,如果损失严重可以立马解决修复。
通过抓取了两张普通的火焰图,然后进行对比,并对差异部分进行标色:红色表示上升,蓝色表示下降。差分火焰图是以当前(“修改后”)的profile文件作为基准,形状和大小都保持不变。因此你通过色彩的差异就能够很直观的找到差异部分,且可以看出为什么会有这样的差异。
使用方式:
cd quick_location //抓取代码修改前的profile 1文件 perf record -F 99 -p pid -g -- sleep 30 perf script > out.stacks1 //抓取代码修改后的profile 2文件 perf record -F 99 -p pid -g -- sleep 30 perf script > out.stacks2 //生成差分火焰图: ./FlameGraph/stackcollapse-perf.pl ../out.stacks1 > out.folded1 ./FlameGraph/stackcollapse-perf.pl ../out.stacks2 > out.folded2 ./FlameGraph/difffolded.pl out.folded1 out.folded2 | ./FlameGraph/flamegraph.pl > diff2.svg
DEMO:
//test.c #include <stdio.h> #include <stdlib.h> void foo3() { } void foo2() { int i; for(i=0 ; i < 10; i++) foo3(); } void foo1() { int i; for(i = 0; i< 1000; i++) foo3(); } int main(void) { int i; for( i =0; i< 1000000000; i++) { foo1(); foo2(); } } //test1.c #include <stdio.h> #include <stdlib.h> void foo3() { } void foo2() { int i; for(i=0 ; i < 10; i++) foo3(); } void foo1() { int i; for(i = 0; i< 1000; i++) foo3(); } void add() { int i; for(i = 0; i< 10000; i++) foo3(); } int main(void) { int i; for( i =0; i< 1000000000; i++) { foo1(); foo2(); add(); } }DEMO红蓝差分火焰图:

10、案例分析
10.1 接入层nginx集群异常现象
通过监控插件发现在2017.09.25 19点nginx集群请求流量出现大量的499,5xx状态码。并且发现机器cpu使用率升高,目前一直持续中。
10.2 分析nginx相关指标
a) **分析nginx请求流量:
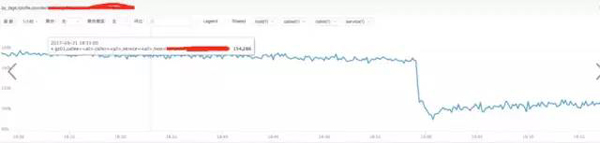
结论:
通过上图发现流量并没有突增,反而下降了,跟请求流量突增没关系。
b) **分析nginx响应时间
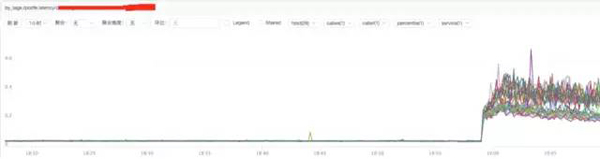
结论:
通过上图发现nginx的响应时间有增加可能跟nginx自身有关系或者跟后端upstream响应时间有关系。
c) **分析nginx upstream响应时间
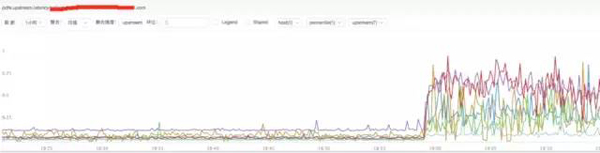
结论:
通过上图发现nginx upstream 响应时间有增加,目前猜测可能后端upstream响应时间拖住nginx,导致nginx出现请求流量异常。
10.3 分析系统cpu情况
a) **通过top观察系统指标
top
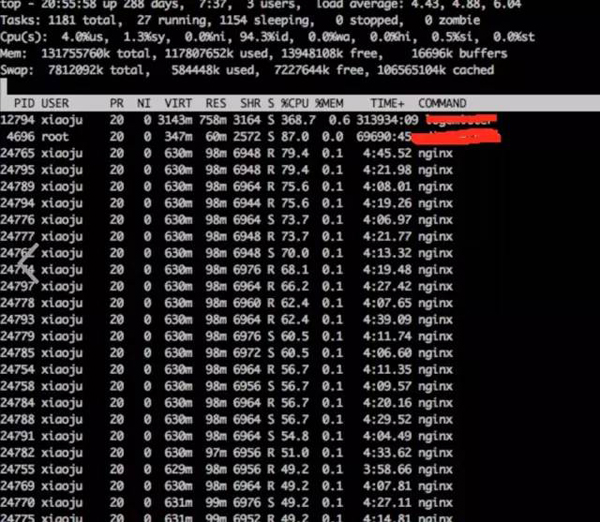
结论:
发现nginx worker cpu比较高
b) **分析nginx进程内部cpu情况
perf top -p pid
结论:
发现主要开销在free,malloc,json解析上面
10.4 火焰图分析cpu
a) **生成用户态cpu火焰图
//test.c #include <stdio.h> #include <stdlib.h> //on-CPU user sh ngx_on_cpu_u.sh pid //进入结果目录 cd ngx_on_cpu_u //开一个临时端口8088 python -m SimpleHTTPServer 8088 //打开浏览器输入地址 127.0.0.1:8088/pid.svg
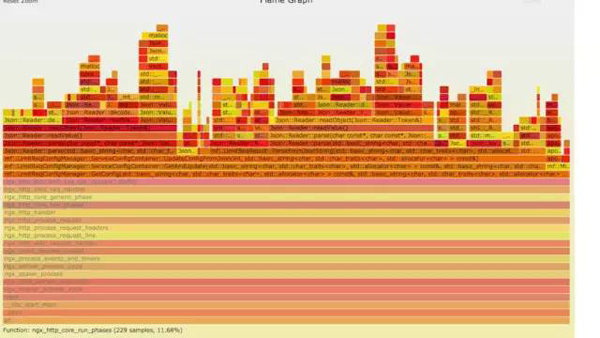
结论:
发现代码里面有频繁的解析json操作,并且发现这个json库性能不高,占用cpu挺高。
10.5 案例总结
a) 分析请求流量异常,得出nginx upstream后端机器响应时间拉长
b) 分析nginx进程cpu高,得出nginx内部模块代码有耗时的json解析以及内存分配回收操作
10.5.1 深入分析
根据以上两点问题分析的结论,我们进一步深入分析。
后端upstream响应拉长,最多可能影响nginx的处理能力。但是不可能会影响nginx内部模块占用过多的cpu操作。并且当时占用cpu高的模块,是在请求的时候才会走的逻辑。不太可能是upstram后端拖住nginx,从而触发这个cpu的耗时操作。
10.5.2 解决方式
遇到这种问题,我们优先解决已知的,并且非常明确的问题。那就是cpu高的问题。解决方式先降级关闭占用cpu过高的模块,然后进行观察。经过降级关闭该模块cpu降下来了,并且nginx请求流量也正常了。之所以会影响upstream时间拉长,因为upstream后端的服务调用的接口可能是个环路再次走回到nginx。
关于“Linux下故障分析怎么用”这篇文章就分享到这里了,希望以上内容可以对大家有一定的帮助,使各位可以学到更多知识,如果觉得文章不错,请把它分享出去让更多的人看到。
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。