жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
жң¬зҜҮеҶ…е®№д»Ӣз»ҚдәҶвҖңжҖҺд№Ҳз”ЁPythonеҝ«йҖҹжҸӯзӨәж•°жҚ®д№Ӣй—ҙзҡ„еҗ„з§Қе…ізі»вҖқзҡ„жңүе…ізҹҘиҜҶпјҢеңЁе®һйҷ…жЎҲдҫӢзҡ„ж“ҚдҪңиҝҮзЁӢдёӯпјҢдёҚе°‘дәәйғҪдјҡйҒҮеҲ°иҝҷж ·зҡ„еӣ°еўғпјҢжҺҘдёӢжқҘе°ұи®©е°Ҹзј–еёҰйўҶеӨ§е®¶еӯҰд№ дёҖдёӢеҰӮдҪ•еӨ„зҗҶиҝҷдәӣжғ…еҶөеҗ§пјҒеёҢжңӣеӨ§е®¶д»”з»Ҷйҳ…иҜ»пјҢиғҪеӨҹеӯҰжңүжүҖжҲҗпјҒ
жҺўзҙўжҖ§ж•°жҚ®еҲҶжһҗ(EDA)ж¶үеҸҠдёӨдёӘеҹәжң¬жӯҘйӘӨпјҡ
ж•°жҚ®еҲҶжһҗ(ж•°жҚ®йў„еӨ„зҗҶгҖҒжё…жҙ—д»ҘеҸҠеӨ„зҗҶ)гҖӮ
ж•°жҚ®еҸҜи§ҶеҢ–(дҪҝз”ЁдёҚеҗҢзұ»еһӢзҡ„еӣҫжқҘеұ•зӨәж•°жҚ®дёӯзҡ„е…ізі»)гҖӮ

Pandas жҳҜ Python дёӯжңҖеёёз”Ёзҡ„ж•°жҚ®еҲҶжһҗеә“гҖӮPython жҸҗдҫӣдәҶеӨ§йҮҸз”ЁдәҺж•°жҚ®еҸҜи§ҶеҢ–зҡ„еә“пјҢMatplotlib жҳҜжңҖеёёз”Ёзҡ„пјҢе®ғжҸҗдҫӣдәҶеҜ№з»ҳеӣҫзҡ„е®Ңе…ЁжҺ§еҲ¶пјҢ并дҪҝеҫ—з»ҳеӣҫиҮӘе®ҡд№үеҸҳеҫ—е®№жҳ“гҖӮ
дҪҶжҳҜпјҢMatplotlib зјәе°‘дәҶеҜ№ Pandas зҡ„ж”ҜжҢҒгҖӮиҖҢ Seaborn ејҘиЎҘдәҶиҝҷдёҖзјәйҷ·пјҢе®ғжҳҜе»әз«ӢеңЁ Matplotlib д№ӢдёҠ并дёҺ Pandas зҙ§еҜҶйӣҶжҲҗзҡ„ж•°жҚ®еҸҜи§ҶеҢ–еә“гҖӮ
然иҖҢпјҢSeaborn иҷҪ然жҙ»е№Іеҫ—жјӮдә®пјҢдҪҶжҳҜеҮҪж•°дј—еӨҡпјҢи®©дәәдёҚзҹҘйҒ“еҲ°еә•иҜҘжҖҺд№ҲдҪҝз”Ёе®ғ们?дёҚиҰҒжҖӮпјҢжң¬ж–Үе°ұжҳҜдёәдәҶзҗҶжё…иҝҷзӮ№пјҢи®©дҪ еҝ«йҖҹжҺҢжҸЎиҝҷж¬ҫеҲ©еҷЁгҖӮ
иҝҷзҜҮж–Үз« дё»иҰҒж¶өзӣ–еҰӮдёӢеҶ…е®№пјҢ
Seaborn дёӯжҸҗдҫӣзҡ„дёҚеҗҢзҡ„з»ҳеӣҫзұ»еһӢгҖӮ
Pandas дёҺ Seaborn зҡ„йӣҶжҲҗеҰӮдҪ•е®һзҺ°д»ҘжңҖе°‘зҡ„д»Јз Ғз»ҳеҲ¶еӨҚжқӮзҡ„еӨҡз»ҙеӣҫ?
еҰӮдҪ•еңЁ Matplotlib зҡ„иҫ…еҠ©дёӢиҮӘе®ҡд№ү Seaborn з»ҳеӣҫи®ҫзҪ®?
дёҖгҖҒMatplotlib
е°Ҫз®Ўд»…дҪҝз”ЁжңҖз®ҖеҚ•зҡ„еҠҹиғҪе°ұеҸҜд»Ҙе®ҢжҲҗи®ёеӨҡд»»еҠЎпјҢдҪҶжҳҜдәҶи§Ј Matplotlib зҡ„еҹәзЎҖйқһеёёйҮҚиҰҒпјҢе…¶еҺҹеӣ жңүдёӨдёӘпјҢ
Seaborn еңЁеә•еұӮдҪҝз”Ё Matplotlib з»ҳеӣҫгҖӮ
дёҖдәӣиҮӘе®ҡд№үйЎ№йңҖиҰҒзӣҙжҺҘдҪҝз”Ё MatplotlibгҖӮ
иҝҷйҮҢеҜ№ Matplotlib зҡ„еҹәзЎҖдҪңдёӘз®ҖеҚ•жҰӮиҝ°гҖӮдёӢеӣҫжҳҫзӨәдәҶ Matplotlib зӘ—еҸЈзҡ„еҗ„дёӘиҰҒзҙ гҖӮ
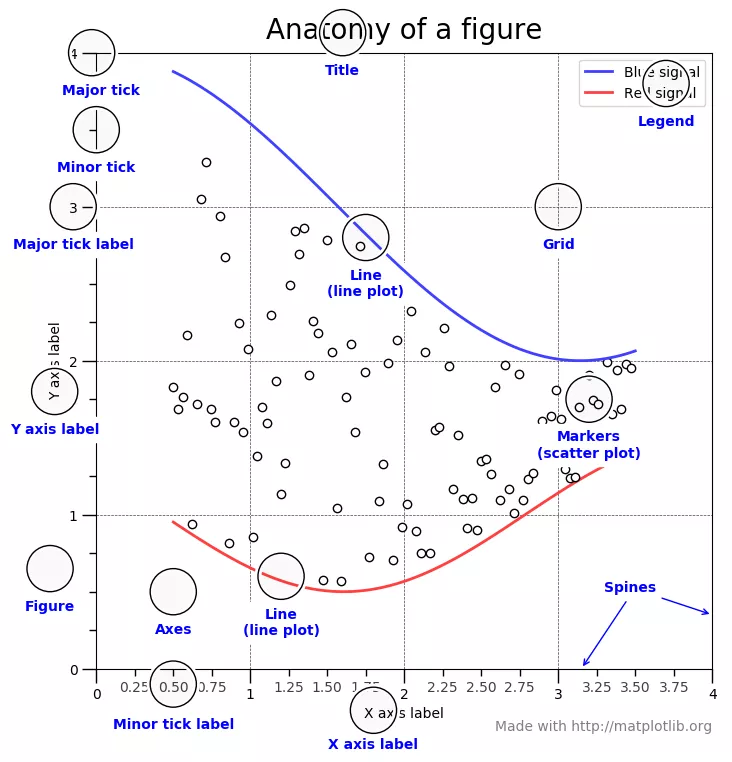
йңҖиҰҒдәҶи§Јзҡ„дёүдёӘдё»иҰҒзҡ„зұ»жҳҜеӣҫеҪў(Figure)пјҢеӣҫиҪҙ(Axes)д»ҘеҸҠеқҗж ҮиҪҙ(Axis)гҖӮ
еӣҫеҪў(Figure)пјҡе®ғжҢҮзҡ„е°ұжҳҜдҪ зңӢеҲ°зҡ„ж•ҙдёӘеӣҫеҪўзӘ—еҸЈгҖӮеҗҢдёҖеӣҫеҪўдёӯеҸҜиғҪжңүеӨҡдёӘеӯҗеӣҫ(еӣҫиҪҙ)гҖӮеңЁдёҠйқўзҡ„зӨәдҫӢдёӯпјҢеңЁдёҖдёӘеӣҫеҪўдёӯжңүеӣӣдёӘеӯҗеӣҫ(еӣҫиҪҙ)гҖӮ
еӣҫиҪҙ(Axes)пјҡеӣҫиҪҙе°ұжҳҜжҢҮеӣҫеҪўдёӯе®һйҷ…з»ҳеҲ¶зҡ„еӣҫгҖӮдёҖдёӘеӣҫеҪўеҸҜд»ҘжңүеӨҡдёӘеӣҫиҪҙпјҢдҪҶжҳҜз»ҷе®ҡзҡ„еӣҫиҪҙеҸӘжҳҜж•ҙдёӘеӣҫеҪўзҡ„дёҖйғЁеҲҶгҖӮеңЁдёҠйқўзҡ„зӨәдҫӢдёӯпјҢжҲ‘们еңЁдёҖдёӘеӣҫеҪўдёӯжңүеӣӣдёӘеӣҫиҪҙгҖӮ
еқҗж ҮиҪҙ(Axis)пјҡеқҗж ҮиҪҙжҳҜжҢҮзү№е®ҡеӣҫиҪҙдёӯзҡ„е®һйҷ…зҡ„ x-иҪҙе’Ң y-иҪҙгҖӮ
жң¬её–еӯҗдёӯзҡ„жҜҸдёӘзӨәдҫӢеқҮеҒҮи®ҫе·Із»ҸеҠ иҪҪжүҖйңҖзҡ„жЁЎеқ—д»ҘеҸҠж•°жҚ®йӣҶпјҢеҰӮдёӢжүҖзӨәпјҢ
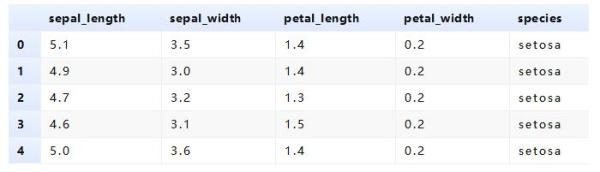
import pandas as pd import numpy as np from matplotlib import pyplot as plt import seaborn as sns tips = sns.load_dataset('tips') iris = sns.load_dataset('iris')import matplotlib matplotlib.style.use('ggplot')tips.head()
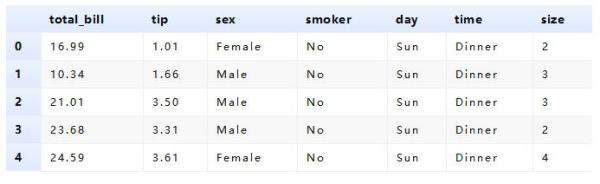
iris.head()
и®©жҲ‘们йҖҡиҝҮдёҖдёӘдҫӢеӯҗжқҘзҗҶи§ЈдёҖдёӢ Figure е’Ң Axes иҝҷдёӨдёӘзұ»гҖӮ
dates = ['1981-01-01', '1981-01-02', '1981-01-03', '1981-01-04', '1981-01-05', '1981-01-06', '1981-01-07', '1981-01-08', '1981-01-09', '1981-01-10'] min_temperature = [20.7, 17.9, 18.8, 14.6, 15.8, 15.8, 15.8, 17.4, 21.8, 20.0] max_temperature = [34.7, 28.9, 31.8, 25.6, 28.8, 21.8, 22.8, 28.4, 30.8, 32.0] fig, axes = plt.subplots(nrows=1, ncols=1, figsize=(10,5)); axes.plot(dates, min_temperature, label='Min Temperature'); axes.plot(dates, max_temperature, label = 'Max Temperature'); axes.legend();
plt.subplots() еҲӣе»әдёҖдёӘ Figure еҜ№иұЎе®һдҫӢпјҢд»ҘеҸҠ nrows x ncols дёӘ Axes е®һдҫӢпјҢ并иҝ”еӣһеҲӣе»әзҡ„ Figure еҜ№иұЎе’Ң Axes е®һдҫӢгҖӮеңЁдёҠйқўзҡ„зӨәдҫӢдёӯпјҢз”ұдәҺжҲ‘д»¬дј йҖ’дәҶ nrows = 1 е’Ң ncols = 1пјҢеӣ жӯӨе®ғд»…еҲӣе»әдёҖдёӘ Axes е®һдҫӢгҖӮеҰӮжһң nrows > 1 жҲ– ncols > 1пјҢеҲҷе°ҶеҲӣе»әдёҖдёӘ Axes зҪ‘ж је№¶е°Ҷе…¶иҝ”еӣһдёә nrows иЎҢ ncols еҲ—зҡ„ numpy ж•°з»„гҖӮ
Axes зұ»жңҖеёёз”Ёзҡ„иҮӘе®ҡд№үж–№жі•жңүпјҢ
Axes.set_xlabel() Axes.set_ylabel() Axes.set_xlim() Axes.set_ylim() Axes.set_xticks() Axes.set_yticks() Axes.set_xticklabels() Axes.set_yticklabels() Axes.set_title() Axes.tick_params()
дёӢйқўжҳҜдёҖдёӘдҪҝз”ЁдёҠиҝ°жҹҗдәӣж–№жі•иҝӣиЎҢиҮӘе®ҡд№үзҡ„дҫӢеӯҗпјҢ
fontsize =20 fig, axes = plt.subplots(nrows=1, ncols=1, figsize=(15,7)) axes.plot(dates, min_temperature, label='Min Temperature') axes.plot(dates, max_temperature, label='Max Temperature') axes.set_xlabel('Date', fontsizefontsize=fontsize) axes.set_ylabel('Temperature', fontsizefontsize=fontsize) axes.set_title('Daily Min and Max Temperature', fontsizefontsize=fontsize) axes.set_xticks(dates) axes.set_xticklabels(dates) axes.tick_params('x', labelsize=fontsize, labelrotation=30, size=15) axes.set_ylim(10,40) axes.set_yticks(np.arange(10,41,2)) axes.tick_params('y',labelsize=fontsize) axes.legend(fontsizefontsize=fontsize,loc='upper left', bbox_to_anchor=(1,1));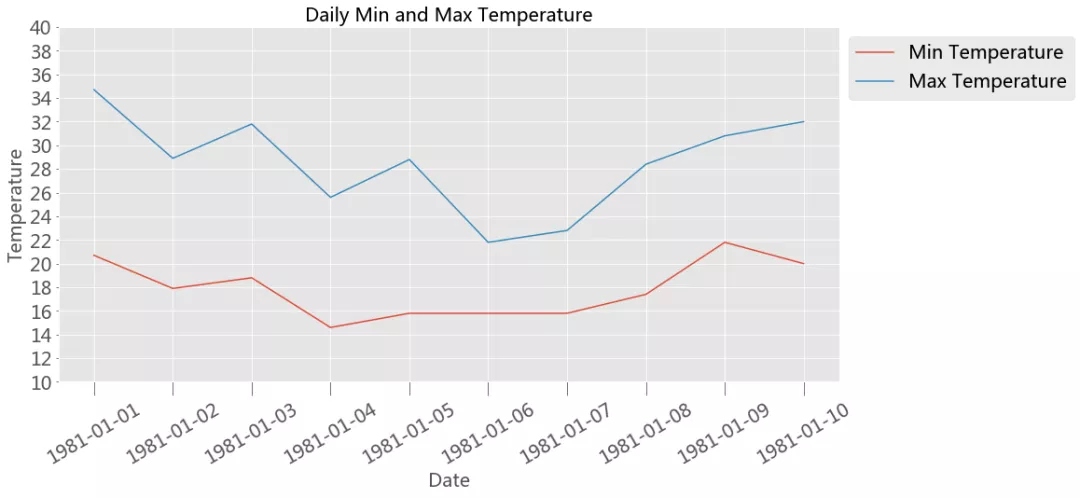
дёҠйқўжҲ‘们еҝ«йҖҹдәҶи§ЈдәҶдёӢ Matplotlib зҡ„еҹәзЎҖзҹҘиҜҶпјҢзҺ°еңЁи®©жҲ‘们иҝӣе…Ҙ SeabornгҖӮ
дәҢгҖҒSeaborn
Seaborn дёӯзҡ„жҜҸдёӘз»ҳеӣҫеҮҪж•°ж—ўжҳҜеӣҫеҪўзә§еҮҪж•°еҸҲжҳҜеӣҫиҪҙзә§еҮҪж•°пјҢеӣ жӯӨжңүеҝ…иҰҒдәҶи§ЈиҝҷдёӨиҖ…д№Ӣй—ҙзҡ„еҢәеҲ«гҖӮ
еҰӮеүҚжүҖиҝ°пјҢеӣҫеҪўжҢҮзҡ„жҳҜдҪ зңӢеҲ°зҡ„ж•ҙдёӘз»ҳеӣҫзӘ—еҸЈдёҠзҡ„еӣҫпјҢиҖҢеӣҫиҪҙжҢҮзҡ„жҳҜеӣҫеҪўдёӯзҡ„дёҖдёӘзү№е®ҡеӯҗеӣҫгҖӮ
еӣҫиҪҙзә§еҮҪж•°еҸӘз»ҳеҲ¶еҲ°еҚ•дёӘ Matplotlib еӣҫиҪҙдёҠпјҢ并дёҚеҪұе“ҚеӣҫеҪўзҡ„е…¶дҪҷйғЁеҲҶгҖӮ
иҖҢеӣҫеҪўзә§еҮҪж•°еҲҷеҸҜд»ҘжҺ§еҲ¶ж•ҙдёӘеӣҫеҪўгҖӮ
жҲ‘们еҸҜд»Ҙиҝҷд№ҲжқҘзҗҶи§ЈиҝҷдёҖзӮ№пјҢеӣҫеҪўзә§еҮҪж•°еҸҜд»Ҙи°ғз”ЁдёҚеҗҢзҡ„еӣҫиҪҙзә§еҮҪж•°еңЁдёҚеҗҢзҡ„еӣҫиҪҙдёҠз»ҳеҲ¶дёҚеҗҢзұ»еһӢзҡ„еӯҗеӣҫгҖӮ
sns.set_style('darkgrid')1. еӣҫиҪҙзә§еҮҪж•°
дёӢйқўзҪ—еҲ—зҡ„жҳҜ Seaborn дёӯжүҖжңүеӣҫиҪҙзә§еҮҪж•°зҡ„иҜҰз»ҶеҲ—иЎЁгҖӮ
е…ізі»еӣҫ Relational Plotsпјҡ
scatterplot( )
lineplot( )
зұ»еҲ«еӣҫ Categorical Plotsпјҡ
striplot( )гҖҒswarmplot( )
boxplot( )гҖҒboxenplot( )
violinplot( )гҖҒcountplot( )
pointplot( )гҖҒbarplot( )
еҲҶеёғеӣҫ Distribution Plotsпјҡ
distplot( )
kdeplot( )
rugplot( )
еӣһеҪ’еӣҫ Regression Plotsпјҡ
regplot( )
residplot( )
зҹ©йҳөеӣҫ MatrixPlots( )пјҡ
heatmap( )
дҪҝз”Ёд»»дҪ•еӣҫиҪҙзә§еҮҪж•°йңҖиҰҒдәҶи§Јзҡ„дёӨзӮ№пјҢ
е°Ҷиҫ“е…Ҙж•°жҚ®жҸҗдҫӣз»ҷеӣҫиҪҙзә§еҮҪж•°зҡ„дёҚеҗҢж–№жі•гҖӮ
жҢҮе®ҡз”ЁдәҺз»ҳеӣҫзҡ„еӣҫиҪҙгҖӮ
(1) е°Ҷиҫ“е…Ҙж•°жҚ®жҸҗдҫӣз»ҷеӣҫиҪҙзә§еҮҪж•°зҡ„дёҚеҗҢж–№жі•
a. еҲ—иЎЁгҖҒж•°з»„жҲ–зі»еҲ—
е°Ҷж•°жҚ®дј йҖ’еҲ°еӣҫиҪҙзә§еҮҪж•°зҡ„жңҖеёёз”Ёж–№жі•жҳҜдҪҝз”Ёиҝӯд»ЈеҷЁпјҢдҫӢеҰӮеҲ—иЎЁ listпјҢж•°з»„ array жҲ–еәҸеҲ— series
total_bill = tips['total_bill'].values tip = tips['tip'].values fig = plt.figure(figsize=(10, 5)) sns.scatterplot(total_bill, tip, s=15);
tip = tips['tip'].values day = tips['day'].values fig = plt.figure(figsize=(10, 5)) sns.boxplot(day, tip, palette="Set2");
b. дҪҝз”Ё Pandas зҡ„ Dataframe зұ»еһӢд»ҘеҸҠеҲ—еҗҚгҖӮ
Seaborn еҸ—ж¬ўиҝҺзҡ„дё»иҰҒеҺҹеӣ д№ӢдёҖжҳҜе®ғеҸҜд»ҘзӣҙжҺҘеҸҜд»ҘдёҺ Pandas зҡ„ Dataframes й…ҚеҗҲдҪҝз”ЁгҖӮеңЁиҝҷз§Қж•°жҚ®дј йҖ’ж–№жі•дёӯпјҢеҲ—еҗҚеә”дј йҖ’з»ҷ x е’Ң y еҸӮж•°пјҢиҖҢ Dataframe еә”дј йҖ’з»ҷ data еҸӮж•°гҖӮ
fig = plt.figure(figsize=(10, 5)) sns.scatterplot(x='total_bill', y='tip', data=tips, s=50);
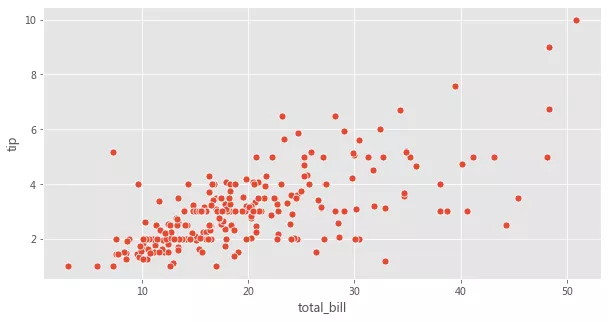
fig = plt.figure(figsize=(10, 5)) sns.boxplot(x='day', y='tip', data=tips);
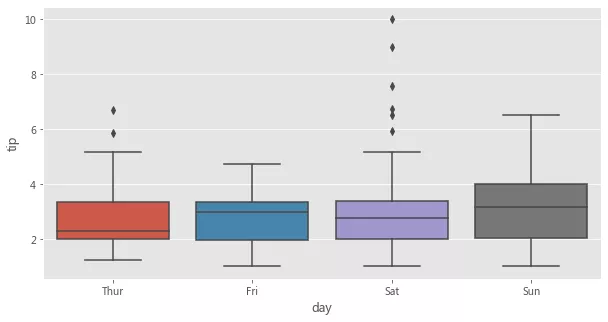
c. д»…дј йҖ’ Dataframe
еңЁиҝҷз§Қж•°жҚ®дј йҖ’ж–№ејҸдёӯпјҢд»…е°Ҷ Dataframe дј йҖ’з»ҷ data еҸӮж•°гҖӮж•°жҚ®йӣҶдёӯзҡ„жҜҸдёӘж•°еӯ—еҲ—йғҪе°ҶдҪҝз”ЁжӯӨж–№жі•з»ҳеҲ¶гҖӮжӯӨж–№жі•еҸӘиғҪдёҺд»ҘдёӢиҪҙзә§еҮҪж•°дёҖиө·дҪҝз”ЁпјҢ
stripplot( )гҖҒswarmplot( )
boxplot( )гҖҒboxenplot( )гҖҒviolinplot( )гҖҒpointplot( )
barplot( )гҖҒcountplot( )
дҪҝз”ЁдёҠиҝ°еӣҫиҪҙзә§еҮҪж•°жқҘеұ•зӨәжҹҗдёӘж•°жҚ®йӣҶдёӯзҡ„еӨҡдёӘж•°еҖјеһӢеҸҳйҮҸзҡ„еҲҶеёғпјҢжҳҜиҝҷз§Қж•°жҚ®дј йҖ’ж–№ејҸзҡ„еёёи§Ғз”ЁдҫӢгҖӮ
fig = plt.figure(figsize=(10, 5)) sns.boxplot(data=iris);
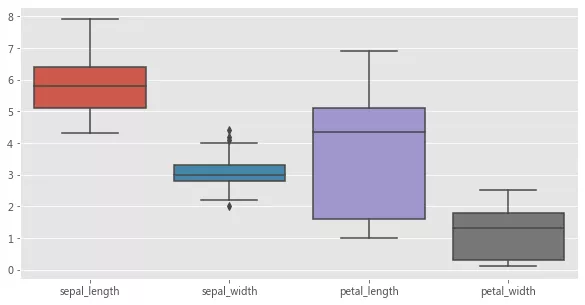
(2) жҢҮе®ҡз”ЁдәҺз»ҳеӣҫзҡ„еӣҫиҪҙ
Seaborn дёӯзҡ„жҜҸдёӘеӣҫиҪҙзә§еҮҪж•°йғҪеёҰжңүдёҖдёӘ ax еҸӮж•°гҖӮдј йҖ’з»ҷ ax еҸӮж•°зҡ„ Axes е°ҶиҙҹиҙЈе…·дҪ“з»ҳеӣҫгҖӮиҝҷдёәжҺ§еҲ¶дҪҝз”Ёе…·дҪ“еӣҫиҪҙиҝӣиЎҢз»ҳеӣҫжҸҗдҫӣдәҶжһҒеӨ§зҡ„зҒөжҙ»жҖ§гҖӮдҫӢеҰӮпјҢеҒҮи®ҫиҰҒжҹҘзңӢжҖ»иҙҰеҚ• bill е’Ңе°Ҹиҙ№ tip д№Ӣй—ҙзҡ„е…ізі»(дҪҝз”Ёж•ЈзӮ№еӣҫ)д»ҘеҸҠе®ғ们зҡ„еҲҶеёғ(дҪҝз”Ёз®ұеҪўеӣҫ)пјҢжҲ‘们еёҢжңӣеңЁеҗҢдёҖдёӘеӣҫеҪўдҪҶеңЁдёҚеҗҢеӣҫиҪҙдёҠеұ•зӨәе®ғ们гҖӮ
fig, axes = plt.subplots(1, 2, figsize=(10, 7)) sns.scatterplot(x='total_bill', y='tip', data=tips, ax=axes[1]); sns.boxplot(data = tips[['total_bill','tip']], ax=axes[0]);
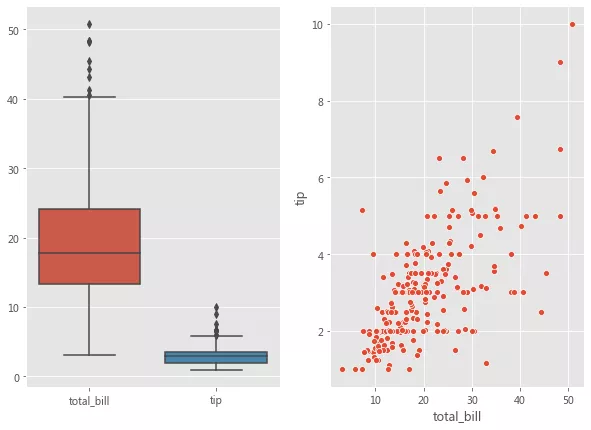
жҜҸдёӘеӣҫиҪҙзә§еҮҪж•°иҝҳдјҡиҝ”еӣһе®һйҷ…еңЁе…¶дёҠиҝӣиЎҢз»ҳеӣҫзҡ„еӣҫиҪҙгҖӮеҰӮжһңе°ҶеӣҫиҪҙдј йҖ’з»ҷдәҶ ax еҸӮж•°пјҢеҲҷе°Ҷиҝ”еӣһиҜҘеӣҫиҪҙеҜ№иұЎгҖӮ然еҗҺеҸҜд»ҘдҪҝз”ЁдёҚеҗҢзҡ„ж–№жі•(еҰӮAxes.set_xlabel( )пјҢAxes.set_ylabel( ) зӯү)еҜ№иҝ”еӣһзҡ„еӣҫиҪҙеҜ№иұЎиҝӣиЎҢиҝӣдёҖжӯҘиҮӘе®ҡд№үи®ҫзҪ®гҖӮ
еҰӮжһңжІЎжңүеӣҫиҪҙдј йҖ’з»ҷ ax еҸӮж•°пјҢеҲҷ Seaborn е°ҶдҪҝз”ЁеҪ“еүҚ(жҙ»еҠЁ)еӣҫиҪҙжқҘиҝӣиЎҢз»ҳеҲ¶гҖӮ
fig, curr_axes = plt.subplots() scatter_plot_axes = sns.scatterplot(x='total_bill', y='tip', data=tips) id(curr_axes) == id(scatter_plot_axes)
True
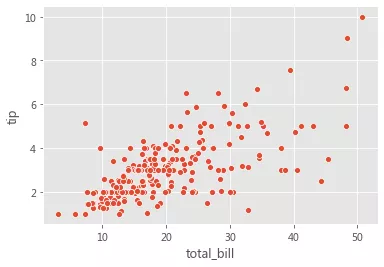
еңЁдёҠйқўзҡ„зӨәдҫӢдёӯпјҢеҚідҪҝжҲ‘们没жңүе°Ҷ curr_axes(еҪ“еүҚжҙ»еҠЁеӣҫиҪҙ)жҳҫејҸдј йҖ’з»ҷ ax еҸӮж•°пјҢдҪҶ Seaborn д»Қ然дҪҝз”Ёе®ғиҝӣиЎҢдәҶз»ҳеҲ¶пјҢеӣ дёәе®ғжҳҜеҪ“еүҚзҡ„жҙ»еҠЁеӣҫиҪҙгҖӮid(curr_axes) == id(scatter_plot_axes) иҝ”еӣһ TrueпјҢиЎЁзӨәе®ғ们жҳҜзӣёеҗҢзҡ„иҪҙгҖӮ
еҰӮжһңжІЎжңүе°ҶеӣҫиҪҙдј йҖ’з»ҷ ax еҸӮ数并且没жңүеҪ“еүҚжҙ»еҠЁеӣҫиҪҙеҜ№иұЎпјҢйӮЈд№Ҳ Seaborn е°ҶеҲӣе»әдёҖдёӘж–°зҡ„еӣҫиҪҙеҜ№иұЎд»ҘиҝӣиЎҢз»ҳеҲ¶пјҢ然еҗҺиҝ”еӣһиҜҘеӣҫиҪҙеҜ№иұЎгҖӮ
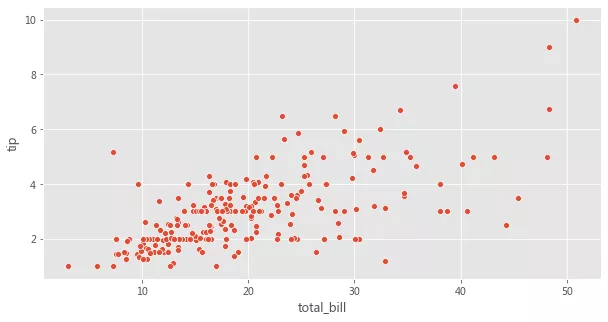
Seaborn дёӯзҡ„еӣҫиҪҙзә§еҮҪ数并没жңүеҸӮж•°з”ЁжқҘжҺ§еҲ¶еӣҫеҪўзҡ„е°әеҜёгҖӮдҪҶжҳҜпјҢз”ұдәҺжҲ‘们еҸҜд»ҘжҢҮе®ҡиҰҒдҪҝз”Ёе“ӘдёӘеӣҫиҪҙиҝӣиЎҢз»ҳеӣҫпјҢеӣ жӯӨеҸҜд»ҘйҖҡиҝҮдёә ax еҸӮж•°дј йҖ’еӣҫиҪҙжқҘжҺ§еҲ¶еӣҫеҪўе°әеҜёпјҢеҰӮдёӢжүҖзӨәгҖӮ
fig, axes = plt.subplots(1, 1, figsize=(10, 5)) sns.scatterplot(x='total_bill', y='tip', data=tips, ax=axes);
2. еӣҫеҪўзә§еҮҪж•°
еңЁжөҸи§ҲеӨҡз»ҙж•°жҚ®йӣҶж—¶пјҢж•°жҚ®еҸҜи§ҶеҢ–зҡ„жңҖеёёи§Ғз”ЁдҫӢд№ӢдёҖе°ұжҳҜй’ҲеҜ№еҗ„дёӘж•°жҚ®еӯҗйӣҶз»ҳеҲ¶еҗҢдёҖзұ»еӣҫзҡ„еӨҡдёӘе®һдҫӢгҖӮ
Seaborn дёӯзҡ„еӣҫеҪўзә§еҮҪж•°е°ұжҳҜдёәиҝҷз§Қжғ…еҪўйҮҸиә«е®ҡеҲ¶зҡ„гҖӮ
еӣҫеҪўзә§еҮҪж•°еҸҜд»Ҙе®Ңе…ЁжҺ§еҲ¶ж•ҙдёӘеӣҫеҪўпјҢ并且жҜҸж¬Ўи°ғз”ЁеӣҫеҪўзә§еҮҪж•°ж—¶пјҢе®ғйғҪдјҡеҲӣе»әдёҖдёӘеҢ…еҗ«еӨҡдёӘеӣҫиҪҙзҡ„ж–°еӣҫеҪўгҖӮ
Seaborn дёӯдёүдёӘжңҖйҖҡз”Ёзҡ„еӣҫеҪўзә§еҮҪж•°жҳҜ FacetGridгҖҒPairGrid д»ҘеҸҠ JointGridгҖӮ
(1) FacetGrid
иҖғиҷ‘дёӢйқўзҡ„з”ЁдҫӢпјҢжҲ‘们жғіеҸҜи§ҶеҢ–дёҚеҗҢж•°жҚ®еӯҗйӣҶдёҠзҡ„жҖ»иҙҰеҚ•е’Ңе°Ҹиҙ№д№Ӣй—ҙзҡ„е…ізі»(йҖҡиҝҮж•ЈзӮ№еӣҫ)гҖӮж•°жҚ®зҡ„жҜҸдёӘеӯҗйӣҶеқҮжҢүд»ҘдёӢеҸҳйҮҸзҡ„еҖјзҡ„е”ҜдёҖз»„еҗҲиҝӣиЎҢеҲҶзұ»пјҢ
жҳҹжңҹеҮ (жҳҹжңҹеӣӣгҖҒдә”гҖҒе…ӯгҖҒж—Ҙ)
жҳҜеҗҰеҗёзғҹ(жҳҜжҲ–еҗҰ)
жҖ§еҲ«(з”·жҖ§жҲ–еҘіжҖ§)
еҰӮдёӢжүҖзӨәпјҢжҲ‘们еҸҜд»Ҙз”Ё Matplotlib е’Ң Seaborn иҪ»жқҫе®ҢжҲҗиҝҷдёӘж“ҚдҪңпјҢ
row_variable = 'day' col_variable = 'smoker' hue_variable = 'sex' row_variables = tips[row_variable].unique() col_variables = tips[col_variable].unique() num_rows = row_variables.shape[0] num_cols = col_variables.shape[0] fig,axes = plt.subplots(num_rows, num_cols, sharex=True, sharey=True, figsize=(15,10)) subset = tips.groupby([row_variable,col_variable]) for row in range(num_rows): for col in range(num_cols): ax = axes[row][col] row_id = row_variables[row] col_id = col_variables[col] ax_data = subset.get_group((row_id, col_id)) sns.scatterplot(x='total_bill', y='tip', data=ax_data, hue=hue_variable,axax=ax); title = row_variable + ' : ' + row_id + ' | ' + col_variable + ' : ' + col_id ax.set_title(title);
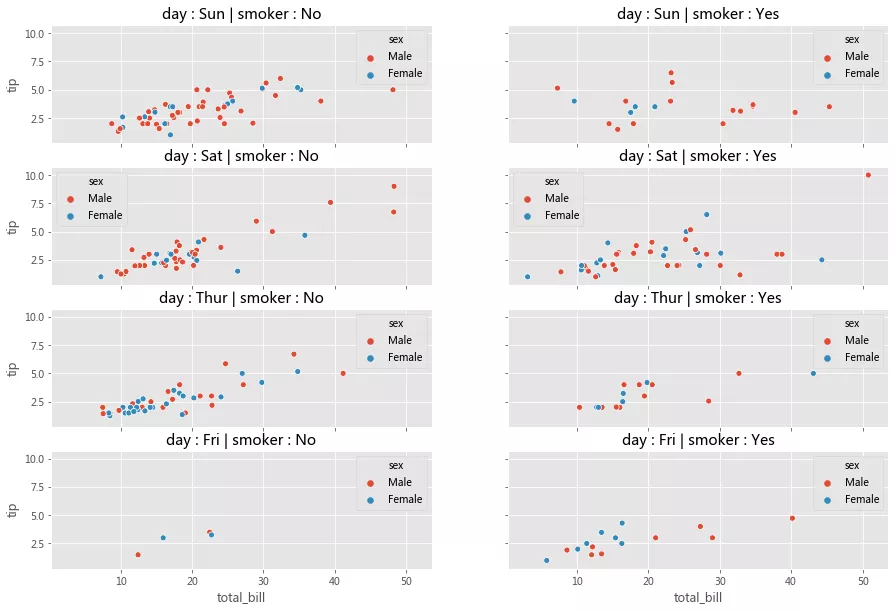
еҲҶжһҗдёҖдёӢпјҢдёҠйқўзҡ„д»Јз ҒеҸҜд»ҘеҲҶдёәдёүдёӘжӯҘйӘӨпјҢ
дёәжҜҸдёӘж•°жҚ®еӯҗйӣҶеҲӣе»әдёҖдёӘеӣҫиҪҙ(еӯҗеӣҫ)
е°Ҷж•°жҚ®йӣҶеҲ’еҲҶдёәеӯҗйӣҶ
еңЁжҜҸдёӘеӣҫиҪҙдёҠпјҢдҪҝз”ЁеҜ№еә”дәҺиҜҘеӣҫиҪҙзҡ„ж•°жҚ®еӯҗйӣҶжқҘз»ҳеҲ¶ж•ЈзӮ№еӣҫ
еңЁ Seaborn дёӯпјҢеҸҜд»Ҙе°ҶдёҠйқўдёүйғЁжӣІиҝӣдёҖжӯҘз®ҖеҢ–дёәдёӨйғЁжӣІгҖӮ
жӯҘйӘӨ 1 еҸҜд»ҘеңЁ Seaborn дёӯеҸҜд»ҘдҪҝз”Ё FacetGrid( ) е®ҢжҲҗ
жӯҘйӘӨ 2 е’ҢжӯҘйӘӨ 3 еҸҜд»ҘдҪҝз”Ё FacetGrid.map( ) е®ҢжҲҗ
дҪҝз”Ё FacetGridпјҢжҲ‘们еҸҜд»ҘеҲӣе»әеӣҫиҪҙ并结еҗҲ rowпјҢcol е’Ң hue еҸӮж•°е°Ҷж•°жҚ®йӣҶеҲ’еҲҶдёәдёүдёӘз»ҙеәҰгҖӮдёҖж—ҰеҲӣе»әеҘҪ FacetGrid еҗҺпјҢеҸҜд»Ҙе°Ҷе…·дҪ“зҡ„з»ҳеӣҫеҮҪж•°дҪңдёәеҸӮж•°дј йҖ’з»ҷ FacetGrid.map( ) д»ҘеңЁжүҖжңүеӣҫиҪҙдёҠз»ҳеҲ¶зӣёеҗҢзұ»еһӢзҡ„еӣҫгҖӮеңЁз»ҳеӣҫж—¶пјҢжҲ‘们иҝҳйңҖиҰҒдј йҖ’з”ЁдәҺз»ҳеӣҫзҡ„ Dataframe дёӯзҡ„е…·дҪ“еҲ—еҗҚгҖӮ
facet_grid = sns.FacetGrid(row='day', col='smoker', hue='sex', data=tips, height=2, aspect=2.5) facet_grid.map(sns.scatterplot, 'total_bill', 'tip') facet_grid.add_legend();
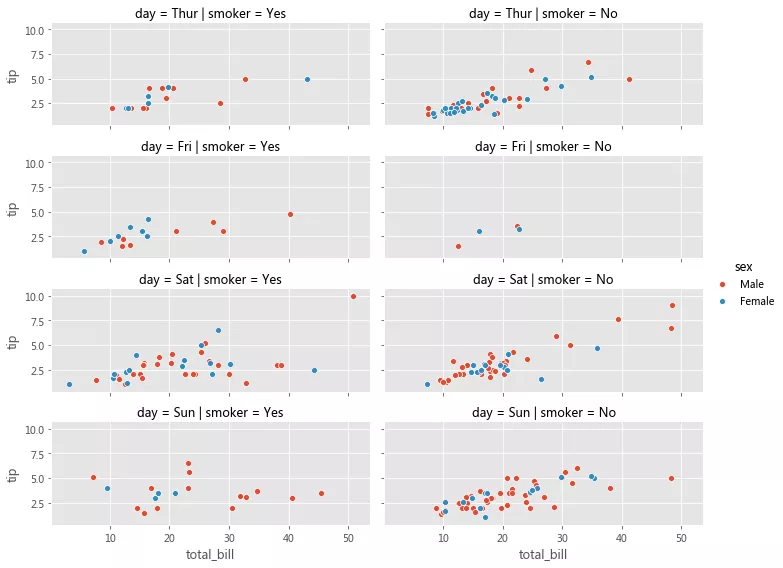
Matplotlib дёәдҪҝз”ЁеӨҡдёӘеӣҫиҪҙз»ҳеӣҫжҸҗдҫӣдәҶиүҜеҘҪзҡ„ж”ҜжҢҒпјҢиҖҢ Seaborn еңЁе®ғеҹәзЎҖдёҠе°Ҷеӣҫзҡ„з»“жһ„дёҺж•°жҚ®йӣҶзҡ„з»“жһ„зӣҙжҺҘиҝһжҺҘиө·жқҘдәҶгҖӮ
дҪҝз”Ё FacetGridпјҢжҲ‘们既дёҚеҝ…дёәжҜҸдёӘж•°жҚ®еӯҗйӣҶжҳҫејҸең°еҲӣе»әеӣҫиҪҙпјҢд№ҹдёҚеҝ…жҳҫејҸең°е°Ҷж•°жҚ®еҲ’еҲҶдёәеӯҗйӣҶгҖӮиҝҷдәӣд»»еҠЎз”ұ FacetGrid( ) е’Ң FacetGrid.map( ) еҲҶеҲ«еңЁеҶ…йғЁе®ҢжҲҗдәҶгҖӮ
жҲ‘们еҸҜд»Ҙе°ҶдёҚеҗҢзҡ„еӣҫиҪҙзә§еҮҪж•°дј йҖ’з»ҷ FacetGrid.map( )гҖӮ
еҸҰеӨ–пјҢSeaborn жҸҗдҫӣдәҶдёүдёӘеӣҫеҪўзә§еҮҪж•°(й«ҳзә§жҺҘеҸЈ)пјҢиҝҷдәӣеҮҪж•°еңЁеә•еұӮдҪҝз”Ё FacetGrid( ) е’Ң FacetGrid.map( )гҖӮ
relplot( )
catplot( )
lmplot( )
дёҠйқўзҡ„еӣҫеҪўзә§еҮҪж•°йғҪдҪҝз”Ё FacetGrid( ) еҲӣе»әеӨҡдёӘеӣҫиҪҙ AxesпјҢ并用еҸӮж•° kind и®°еҪ•дёҖдёӘеӣҫиҪҙзә§еҮҪж•°пјҢ然еҗҺеңЁеҶ…йғЁе°ҶиҜҘеҸӮж•°дј йҖ’з»ҷ FacetGrid.map( )гҖӮдёҠиҝ°дёүдёӘеҮҪж•°еҲҶеҲ«дҪҝз”ЁдёҚеҗҢзҡ„еӣҫиҪҙзә§еҮҪж•°жқҘе®һзҺ°дёҚеҗҢзҡ„з»ҳеҲ¶гҖӮ
relplot() - FacetGrid() + lineplot() / scatterplot() catplot() - FacetGrid() + stripplot() / swarmplot() / boxplot() boxenplot() / violinplot() / pointplot() barplot() / countplot() lmplot() - FacetGrid() + regplot()
дёҺзӣҙжҺҘдҪҝз”ЁиҜёеҰӮ relplot( )гҖҒcatplot( ) жҲ– lmplot( ) д№Ӣзұ»зҡ„й«ҳзә§жҺҘеҸЈзӣёжҜ”пјҢжҳҫејҸең°дҪҝз”Ё FacetGrid жҸҗдҫӣдәҶжӣҙеӨ§зҡ„зҒөжҙ»жҖ§гҖӮдҫӢеҰӮпјҢдҪҝз”Ё FacetGrid( )пјҢжҲ‘们иҝҳеҸҜд»Ҙе°ҶиҮӘе®ҡд№үеҮҪж•°дј йҖ’з»ҷ FacetGrid.map( )пјҢдҪҶжҳҜеҜ№дәҺй«ҳзә§жҺҘеҸЈпјҢжҲ‘们еҸӘиғҪдҪҝз”ЁеҶ…зҪ®зҡ„еӣҫиҪҙзә§еҮҪж•°жҢҮе®ҡз»ҷеҸӮж•° kindгҖӮеҰӮжһңдҪ дёҚйңҖиҰҒиҝҷз§ҚзҒөжҙ»жҖ§пјҢеҲҷеҸҜд»ҘзӣҙжҺҘдҪҝз”Ёиҝҷдәӣй«ҳзә§жҺҘеҸЈеҮҪж•°гҖӮ
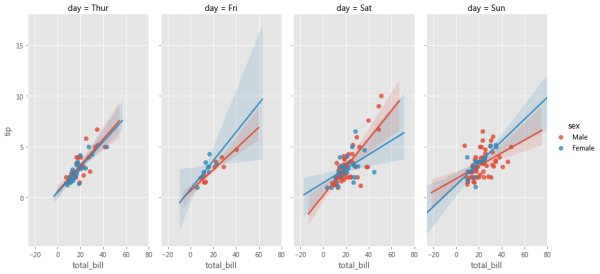
grid = sns.relplot(x='total_bill', y='tip', row='day', col='smoker', hue='sex', data=tips, kind='scatter', height=3, aspect=2.0)
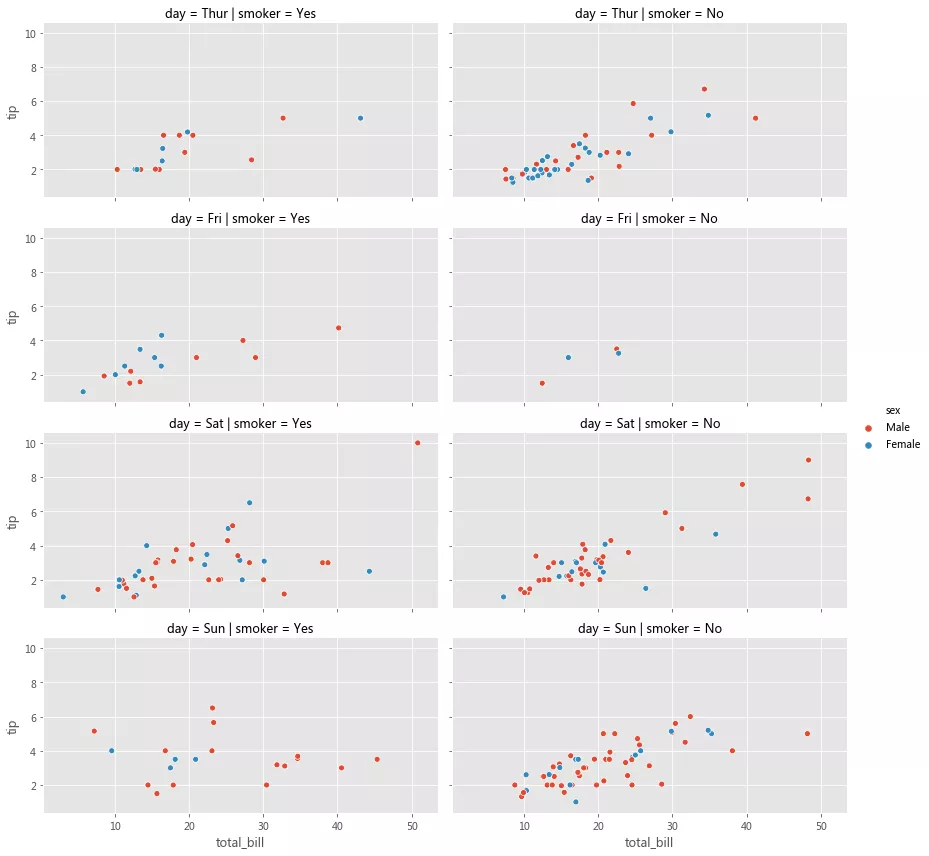
sns.catplot(col='day', kind='box', data=tips, x='sex', y='total_bill', hue='smoker', height=6, aspect=0.5)
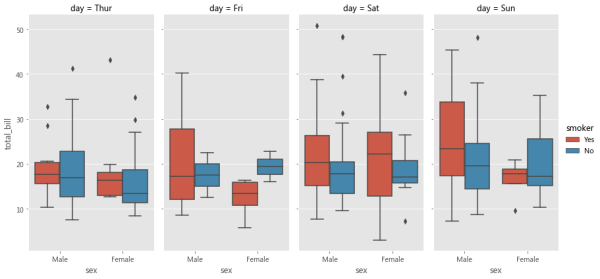
sns.lmplot(col='day', data=tips, x='total_bill', y='tip', hue='sex', height=6, aspect=0.5)
(2) PairGrid
PairGrid з”ЁдәҺз»ҳеҲ¶ж•°жҚ®йӣҶдёӯеҸҳйҮҸд№Ӣй—ҙзҡ„жҲҗеҜ№е…ізі»гҖӮжҜҸдёӘеӯҗеӣҫжҳҫзӨәдёҖеҜ№еҸҳйҮҸд№Ӣй—ҙзҡ„е…ізі»гҖӮиҖғиҷ‘д»ҘдёӢз”ЁдҫӢпјҢжҲ‘们еёҢжңӣеҸҜи§ҶеҢ–жҜҸеҜ№еҸҳйҮҸд№Ӣй—ҙзҡ„е…ізі»(йҖҡиҝҮж•ЈзӮ№еӣҫ)гҖӮиҷҪ然еҸҜд»ҘеңЁ Matplotlib дёӯд№ҹиғҪе®ҢжҲҗжӯӨж“ҚдҪңпјҢдҪҶеҰӮжһңз”Ё Seaborn е°ұдјҡеҸҳеҫ—жӣҙеҠ дҫҝжҚ·гҖӮ
iris = sns.load_dataset('iris') g = sns.PairGrid(iris)
жӯӨеӨ„зҡ„е®һзҺ°дё»иҰҒеҲҶдёәдёӨжӯҘпјҢ
дёәжҜҸеҜ№еҸҳйҮҸеҲӣе»әдёҖдёӘеӣҫиҪҙ
еңЁжҜҸдёӘеӣҫиҪҙдёҠпјҢдҪҝз”ЁдёҺиҜҘеҜ№еҸҳйҮҸеҜ№еә”зҡ„ж•°жҚ®з»ҳеҲ¶ж•ЈзӮ№еӣҫ
第 1 жӯҘеҸҜд»ҘдҪҝз”Ё PairGrid( ) жқҘе®ҢжҲҗгҖӮ第 2 жӯҘеҸҜд»ҘдҪҝз”Ё PairGrid.map( )жқҘе®ҢжҲҗгҖӮ
еӣ жӯӨпјҢPairGrid( ) дёәжҜҸеҜ№еҸҳйҮҸеҲӣе»әеӣҫиҪҙпјҢиҖҢ PairGrid.map( ) дҪҝз”ЁдёҺиҜҘеҜ№еҸҳйҮҸзӣёеҜ№еә”зҡ„ж•°жҚ®еңЁжҜҸдёӘеӣҫиҪҙдёҠз»ҳеҲ¶жӣІзәҝгҖӮжҲ‘们еҸҜд»Ҙе°ҶдёҚеҗҢзҡ„еӣҫиҪҙзә§еҮҪж•°дј йҖ’з»ҷ PairGrid.map( )гҖӮ
grid = sns.PairGrid(iris) grid.map(sns.scatterplot)
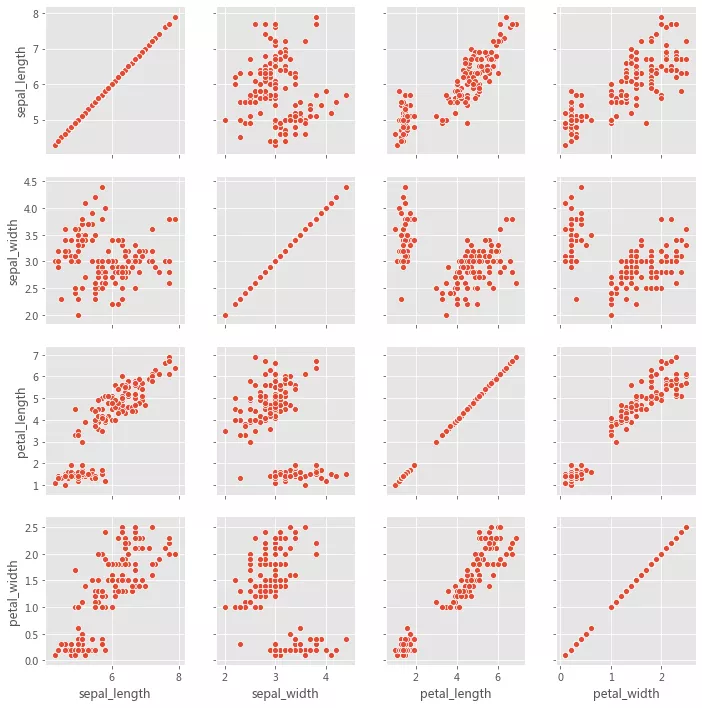
grid = sns.PairGrid(iris, diag_sharey=True, despine=False) grid.map_lower(sns.scatterplot) grid.map_diag(sns.kdeplot)
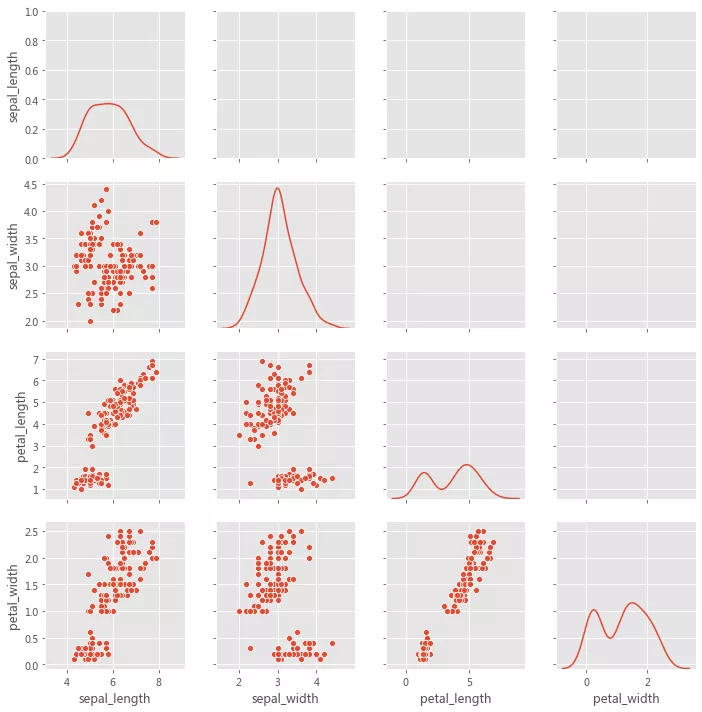
grid = sns.PairGrid(iris, hue='species') grid.map_diag(sns.distplot) grid.map_offdiag(sns.scatterplot)
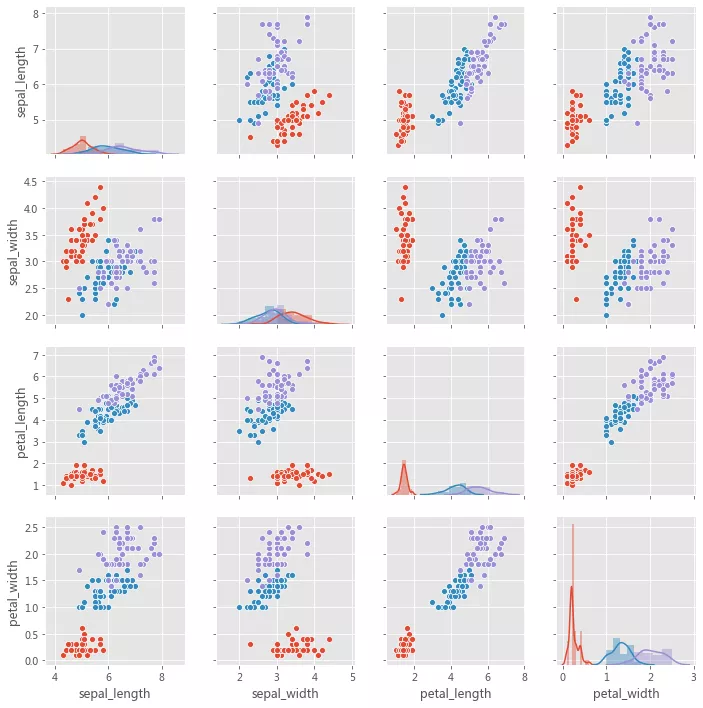
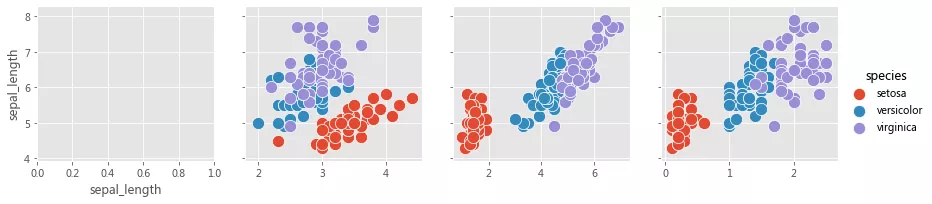
иҜҘеӣҫдёҚеҝ…жҳҜжӯЈж–№еҪўзҡ„пјҡеҸҜд»ҘдҪҝз”ЁеҚ•зӢ¬зҡ„еҸҳйҮҸжқҘе®ҡд№үиЎҢе’ҢеҲ—пјҢ
x_vars = ['sepal_length', 'sepal_width', 'petal_length', 'petal_width'] y_vars = ['sepal_length'] grid = sns.PairGrid(iris, hue='species', x_varsx_vars=x_vars, y_varsy_vars=y_vars, height=3) grid.map_offdiag(sns.scatterplot, s=150) # grid.map_diag(sns.kdeplot) grid.add_legend()
(3) JointGrid
еҪ“жҲ‘们иҰҒеңЁеҗҢдёҖеӣҫдёӯз»ҳеҲ¶еҸҢеҸҳйҮҸиҒ”еҗҲеҲҶеёғе’Ңиҫ№йҷ…еҲҶеёғж—¶пјҢдҪҝз”Ё JointGridгҖӮеҸҜд»ҘдҪҝз”Ё scatter plotгҖҒregplot жҲ– kdeplot еҸҜи§ҶеҢ–дёӨдёӘеҸҳйҮҸзҡ„иҒ”еҗҲеҲҶеёғгҖӮеҸҳйҮҸзҡ„иҫ№йҷ…еҲҶеёғеҸҜд»ҘйҖҡиҝҮзӣҙж–№еӣҫе’Ң/жҲ– kde еӣҫеҸҜи§ҶеҢ–гҖӮ
з”ЁдәҺиҒ”еҗҲеҲҶеёғзҡ„еӣҫиҪҙзә§еҮҪж•°еҝ…йЎ»дј йҖ’з»ҷ JointGrid.plot_joint( )гҖӮ
з”ЁдәҺиҫ№йҷ…еҲҶеёғзҡ„иҪҙзә§еҮҪж•°еҝ…йЎ»дј йҖ’з»ҷ JointGrid.plot_marginals( )гҖӮ
grid = sns.JointGrid(x="total_bill", y="tip", data=tips, height=8) grid.plot(sns.regplot, sns.distplot);
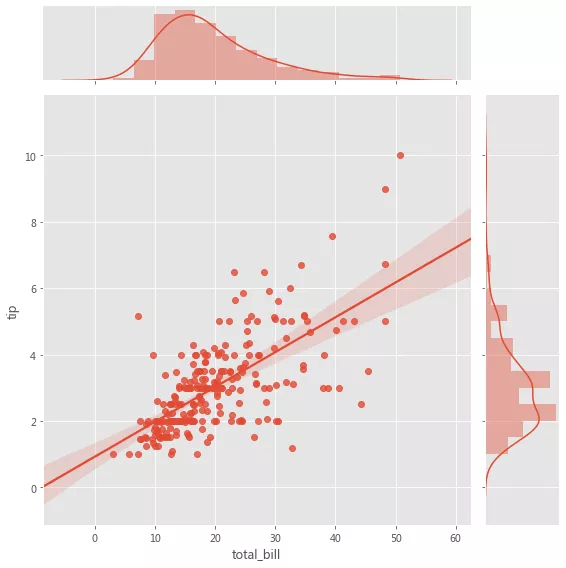
grid = sns.JointGrid(x="total_bill", y="tip", data=tips, height=8) gridgrid = grid.plot_joint(plt.scatter, color=".5", edgecolor="white") gridgrid = grid.plot_marginals(sns.distplot, kde=True, color=".5")
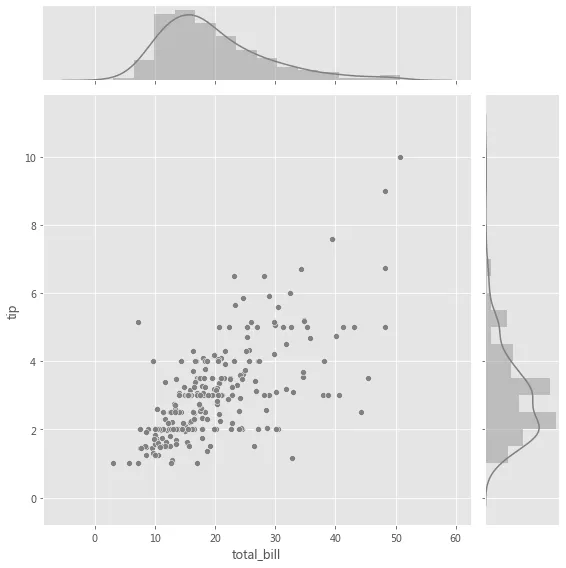
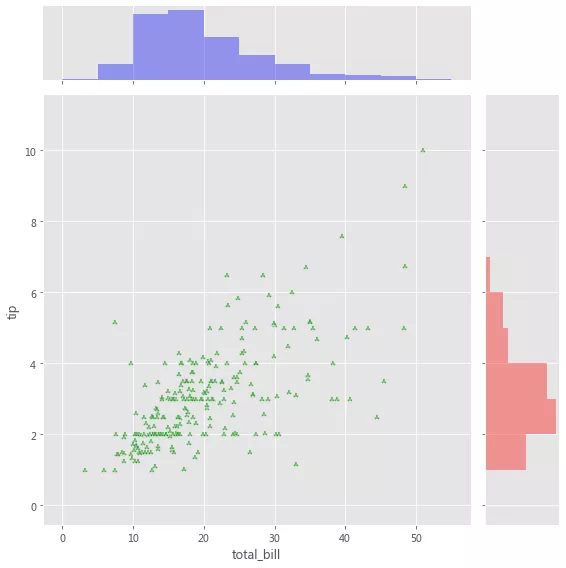
g = sns.JointGrid(x="total_bill", y="tip", data=tips, height=8) gg = g.plot_joint(plt.scatter, color="g", marker='$\clubsuit$', edgecolor="white", alpha=.6) _ = g.ax_marg_x.hist(tips["total_bill"], color="b", alpha=.36, bins=np.arange(0, 60, 5)) _ = g.ax_marg_y.hist(tips["tip"], color="r", alpha=.36, orientation="horizontal", bins=np.arange(0, 12, 1))
ж·»еҠ еёҰжңүз»ҹи®ЎдҝЎжҒҜзҡ„жіЁйҮҠ(Annotation)пјҢиҜҘжіЁйҮҠжұҮжҖ»дәҶеҸҢеҸҳйҮҸе…ізі»пјҢ
from scipy import stats g = sns.JointGrid(x="total_bill", y="tip", data=tips, height=8) gg = g.plot_joint(plt.scatter, color="b", alpha=0.36, s=40, edgecolor="white") gg = g.plot_marginals(sns.distplot, kde=False, color="g") rsquare = lambda a, b: stats.pearsonr(a, b)[0] ** 2 gg = g.annotate(rsquare, template="{stat}: {val:.2f}", stat="$R^2$", loc="upper left", fontsize=12)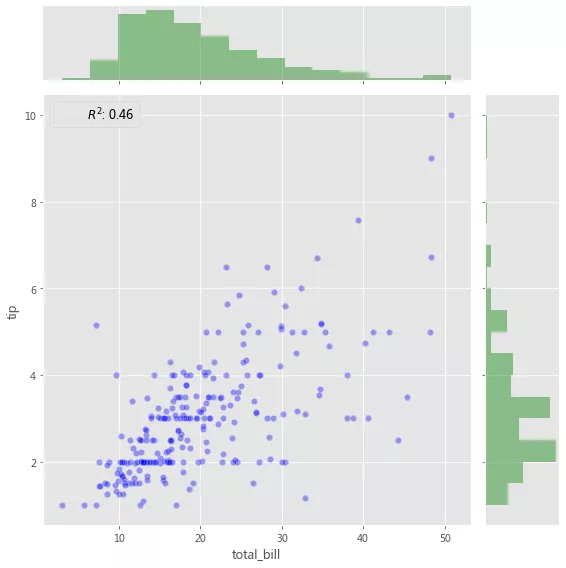
3. е°Ҹз»“
жҺўзҙўжҖ§ж•°жҚ®еҲҶжһҗ(EDA)ж¶үеҸҠдёӨдёӘеҹәжң¬жӯҘйӘӨпјҢ
ж•°жҚ®еҲҶжһҗ(ж•°жҚ®йў„еӨ„зҗҶгҖҒжё…жҙ—д»ҘеҸҠеӨ„зҗҶ)гҖӮ
ж•°жҚ®еҸҜи§ҶеҢ–(дҪҝз”ЁдёҚеҗҢзұ»еһӢзҡ„еӣҫжқҘеұ•зӨәж•°жҚ®дёӯзҡ„е…ізі»)гҖӮ
Seaborn дёҺ Pandas зҡ„йӣҶжҲҗжңүеҠ©дәҺд»ҘжңҖе°‘зҡ„д»Јз ҒеҲ¶дҪңеӨҚжқӮзҡ„еӨҡз»ҙеӣҫпјҢ
Seaborn дёӯзҡ„жҜҸдёӘз»ҳеӣҫеҮҪж•°йғҪжҳҜеӣҫиҪҙзә§еҮҪж•°жҲ–еӣҫеҪўзә§еҮҪж•°гҖӮ
еӣҫиҪҙзә§еҮҪж•°з»ҳеҲ¶еҲ°еҚ•дёӘ Matplotlib еӣҫиҪҙдёҠпјҢ并且дёҚеҪұе“ҚеӣҫеҪўзҡ„е…¶дҪҷйғЁеҲҶгҖӮ
еӣҫеҪўзә§еҮҪж•°жҺ§еҲ¶ж•ҙдёӘеӣҫеҪўгҖӮ
вҖңжҖҺд№Ҳз”ЁPythonеҝ«йҖҹжҸӯзӨәж•°жҚ®д№Ӣй—ҙзҡ„еҗ„з§Қе…ізі»вҖқзҡ„еҶ…е®№е°ұд»Ӣз»ҚеҲ°иҝҷйҮҢдәҶпјҢж„ҹи°ўеӨ§е®¶зҡ„йҳ…иҜ»гҖӮеҰӮжһңжғідәҶи§ЈжӣҙеӨҡиЎҢдёҡзӣёе…ізҡ„зҹҘиҜҶеҸҜд»Ҙе…іжіЁдәҝйҖҹдә‘зҪ‘з«ҷпјҢе°Ҹзј–е°ҶдёәеӨ§е®¶иҫ“еҮәжӣҙеӨҡй«ҳиҙЁйҮҸзҡ„е®һз”Ёж–Үз« пјҒ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ