жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ
еҜҶз Ғзҷ»еҪ•
зҷ»еҪ•жіЁеҶҢ
зӮ№еҮ» зҷ»еҪ•жіЁеҶҢ еҚіиЎЁзӨәеҗҢж„ҸгҖҠдәҝйҖҹдә‘з”ЁжҲ·жңҚеҠЎжқЎж¬ҫгҖӢ
иҝҷзҜҮж–Үз« дё»иҰҒд»Ӣз»ҚвҖңJDKдёӯUUIDзҡ„еә•еұӮе®һзҺ°ж–№ејҸвҖқпјҢеңЁж—Ҙеёёж“ҚдҪңдёӯпјҢзӣёдҝЎеҫҲеӨҡдәәеңЁJDKдёӯUUIDзҡ„еә•еұӮе®һзҺ°ж–№ејҸй—®йўҳдёҠеӯҳеңЁз–‘жғ‘пјҢе°Ҹзј–жҹҘйҳ…дәҶеҗ„ејҸиө„ж–ҷпјҢж•ҙзҗҶеҮәз®ҖеҚ•еҘҪз”Ёзҡ„ж“ҚдҪңж–№жі•пјҢеёҢжңӣеҜ№еӨ§е®¶и§Јзӯ”вҖқJDKдёӯUUIDзҡ„еә•еұӮе®һзҺ°ж–№ејҸвҖқзҡ„з–‘жғ‘жңүжүҖеё®еҠ©пјҒжҺҘдёӢжқҘпјҢиҜ·и·ҹзқҖе°Ҹзј–дёҖиө·жқҘеӯҰд№ еҗ§пјҒ
еүҚжҸҗ
UUIDжҳҜUniversally Unique IDentifierзҡ„зј©еҶҷпјҢзҝ»иҜ‘дёәйҖҡз”Ёе”ҜдёҖж ҮиҜҶз¬ҰжҲ–иҖ…е…ЁеұҖе”ҜдёҖж ҮиҜҶз¬ҰгҖӮеҜ№дәҺUUIDзҡ„жҸҸиҝ°пјҢдёӢйқўж‘ҳеҪ•дёҖдёӢ规иҢғж–Ү件A Universally Unique IDentifier (UUID) URN Namespaceдёӯзҡ„дёҖдәӣжҸҸиҝ°пјҡ
UUID(д№ҹз§°дёәGUID)е®ҡд№үдәҶз»ҹдёҖиө„жәҗеҗҚз§°е‘ҪеҗҚз©әй—ҙгҖӮUUIDзҡ„й•ҝеәҰдёә128жҜ”зү№пјҢеҸҜд»ҘдҝқиҜҒеңЁз©әй—ҙе’Ңж—¶й—ҙдёҠзҡ„е”ҜдёҖжҖ§гҖӮ
гҖҢеҠЁжңәпјҡгҖҚ
дҪҝз”ЁUUIDзҡ„дё»иҰҒеҺҹеӣ д№ӢдёҖжҳҜдёҚйңҖиҰҒйӣҶдёӯејҸз®ЎзҗҶпјҢе…¶дёӯдёҖз§Қж јејҸйҷҗе®ҡдәҶIEEE 802иҠӮзӮ№ж ҮиҜҶз¬ҰпјҢе…¶д»–ж јејҸж— жӯӨйҷҗеҲ¶гҖӮеҸҜд»ҘиҮӘеҠЁеҢ–жҢүйңҖз”ҹжҲҗUUIDпјҢеә”з”ЁдәҺеӨҡйҮҚдёҚеҗҢзҡ„еңәжҷҜгҖӮUUIDз®—жі•ж”ҜжҢҒжһҒй«ҳзҡ„еҲҶй…ҚйҖҹзҺҮпјҢжҜҸеҸ°жңәеҷЁжҜҸз§’й’ҹеҸҜд»Ҙз”ҹжҲҗи¶…иҝҮ1000дёҮдёӘUUIDпјҢеӣ жӯӨе®ғ们еҸҜд»ҘдҪңдёәдәӢеҠЎIDдҪҝз”ЁгҖӮUUIDе…·жңүеӣәе®ҡеӨ§е°Ҹ128жҜ”зү№пјҢдёҺе…¶д»–жӣҝд»Јж–№жЎҲзӣёжҜ”пјҢе®ғе…·жңүдҪ“з§Ҝе°Ҹзҡ„дјҳеҠҝпјҢйқһеёёйҖӮз”ЁдәҺеҗ„з§ҚжҺ’еәҸгҖҒж•ЈеҲ—е’ҢеӯҳеӮЁеңЁж•°жҚ®еә“дёӯпјҢе…·жңүзј–зЁӢжҳ“з”ЁжҖ§зҡ„зү№зӮ№гҖӮ
иҝҷйҮҢеҸӘйңҖиҰҒи®°дҪҸUUIDеҮ дёӘж ёеҝғзү№е®ҡпјҡ
е…ЁеұҖж—¶з©әе”ҜдёҖжҖ§
еӣәе®ҡй•ҝеәҰ128жҜ”зү№пјҢд№ҹе°ұжҳҜ16еӯ—иҠӮ(1 byte = 8 bit)
еҲҶй…ҚйҖҹзҺҮжһҒй«ҳпјҢеҚ•жңәжҜҸз§’еҸҜд»Ҙз”ҹжҲҗи¶…иҝҮ1000дёҮдёӘUUID(е®һйҷ…дёҠжӣҙй«ҳ)
дёӢйқўе°ұJDKдёӯзҡ„UUIDе®һзҺ°иҜҰз»ҶеҲҶжһҗдёҖдёӢUUIDз”ҹжҲҗз®—жі•гҖӮзј–еҶҷжң¬ж–Үзҡ„ж—¶еҖҷйҖүз”Ёзҡ„JDKдёәJDK11гҖӮ
еҶҚиҒҠUUID
еүҚйқўдёәдәҶзј–еҶҷз®ҖеҚ•зҡ„ж‘ҳиҰҒпјҢжүҖд»ҘеҸӘзІ—з•Ҙж‘ҳеҪ•дәҶ规иҢғж–Ү件йҮҢйқўзҡ„дёҖдәӣз« иҠӮпјҢиҝҷйҮҢеҶҚиҜҰз»ҶиҒҠиҒҠUUIDзҡ„дёҖдәӣе®ҡд№үгҖҒзў°ж’һжҰӮзҺҮзӯүзӯүгҖӮ
UUIDе®ҡд№ү
UUIDжҳҜдёҖз§ҚиҪҜ件жһ„е»әзҡ„ж ҮеҮҶпјҢд№ҹжҳҜејҖж”ҫиҪҜ件еҹәйҮ‘дјҡз»„з»ҮеңЁеҲҶеёғејҸи®Ўз®—зҺҜеўғйўҶеҹҹзҡ„дёҖйғЁеҲҶгҖӮжҸҗеҮәжӯӨж ҮеҮҶзҡ„зӣ®зҡ„жҳҜпјҡи®©еҲҶеёғејҸзі»з»ҹдёӯзҡ„жүҖжңүе…ғзҙ жҲ–иҖ…组件йғҪжңүе”ҜдёҖзҡ„еҸҜиҫЁеҲ«зҡ„дҝЎжҒҜпјҢеӣ дёәжһҒдҪҺеҶІзӘҒйў‘зҺҮе’Ңй«ҳж•Ҳз®—жі•зҡ„еҹәзЎҖпјҢе®ғдёҚйңҖиҰҒйӣҶдёӯејҸжҺ§еҲ¶е’Ңз®ЎзҗҶе”ҜдёҖеҸҜиҫЁеҲ«дҝЎжҒҜзҡ„з”ҹжҲҗпјҢз”ұжӯӨпјҢжҜҸдёӘдҪҝз”ЁиҖ…йғҪеҸҜд»ҘиҮӘз”ұең°еҲӣе»әдёҺе…¶д»–дәәдёҚеҶІзӘҒзҡ„UUIDгҖӮ
гҖҢUUIDжң¬иҙЁжҳҜдёҖдёӘ128жҜ”зү№зҡ„ж•°еӯ—гҖҚпјҢиҝҷжҳҜдёҖдёӘдҪҚй•ҝе·ЁеӨ§зҡ„ж•°еҖјпјҢзҗҶи®әдёҠжқҘиҜҙпјҢUUIDзҡ„жҖ»ж•°йҮҸдёә2^128дёӘгҖӮиҝҷдёӘж•°еӯ—еӨ§жҰӮеҸҜд»Ҙиҝҷж ·дј°з®—пјҡеҰӮжһңгҖҢжҜҸзәіз§’гҖҚдә§з”ҹгҖҢ1е…ҶгҖҚдёӘдёҚзӣёеҗҢзҡ„UUIDпјҢйңҖиҰҒиҠұиҙ№и¶…иҝҮ100дәҝе№ҙжүҚдјҡз”Ёе®ҢжүҖжңүзҡ„UUIDгҖӮ
UUIDзҡ„еҸҳдҪ“дёҺзүҲжң¬
UUIDж ҮеҮҶе’Ңз®—жі•е®ҡд№үзҡ„ж—¶еҖҷпјҢдёәдәҶиҖғиҷ‘еҺҶеҸІе…је®№жҖ§е’ҢжңӘжқҘзҡ„жү©еұ•пјҢжҸҗдҫӣдәҶеӨҡз§ҚеҸҳдҪ“е’ҢзүҲжң¬гҖӮжҺҘдёӢжқҘзҡ„еҸҳдҪ“е’ҢзүҲжң¬жҸҸиҝ°жқҘжәҗдәҺз»ҙеҹәзҷҫ科дёӯзҡ„Versionsз« иҠӮе’ҢRFC 4122дёӯзҡ„Variantз« иҠӮгҖӮ
зӣ®еүҚе·ІзҹҘзҡ„еҸҳдҪ“еҰӮдёӢпјҡ
еҸҳдҪ“0xxпјҡReserved, NCS backward compatibilityпјҢдёәеҗ‘еҗҺе…је®№еҒҡйў„з•ҷзҡ„еҸҳдҪ“
еҸҳдҪ“10xпјҡThe IETF aka Leach-Salz variant (used by this class)пјҢз§°дёәLeach–Salz UUIDжҲ–иҖ…IETF UUIDпјҢJDKдёӯUUIDзӣ®еүҚжӯЈеңЁдҪҝз”Ёзҡ„еҸҳдҪ“
еҸҳдҪ“110пјҡReserved, Microsoft Corporation backward compatibilityпјҢеҫ®иҪҜж—©жңҹGUIDйў„з•ҷеҸҳдҪ“
еҸҳдҪ“111пјҡReserved for future definitionпјҢе°ҶжқҘжү©еұ•йў„з•ҷпјҢзӣ®еүҚиҝҳжІЎиў«дҪҝз”Ёзҡ„еҸҳдҪ“
зӣ®еүҚе·ІзҹҘзҡ„зүҲжң¬еҰӮдёӢпјҡ
з©әUUID(зү№ж®ҠзүҲжң¬0)пјҢз”Ё00000000-0000-0000-0000-000000000000иЎЁзӨәпјҢд№ҹе°ұжҳҜжүҖжңүзҡ„жҜ”зү№йғҪжҳҜ0
date-time and MAC address(зүҲжң¬1)пјҡеҹәдәҺж—¶й—ҙе’ҢMACең°еқҖзҡ„зүҲжң¬пјҢйҖҡиҝҮи®Ўз®—еҪ“еүҚж—¶й—ҙжҲігҖҒйҡҸжңәж•°е’ҢжңәеҷЁMACең°еқҖеҫ—еҲ°гҖӮз”ұдәҺжңүMACең°еқҖпјҢиҝҷдёӘеҸҜд»ҘдҝқиҜҒе…¶еңЁе…Ёзҗғзҡ„е”ҜдёҖжҖ§гҖӮдҪҶжҳҜдҪҝз”ЁдәҶMACең°еқҖпјҢе°ұдјҡжңүMACең°еқҖжҡҙйңІй—®йўҳгҖӮиӢҘжҳҜеұҖеҹҹзҪ‘пјҢеҸҜд»Ҙз”ЁIPең°еқҖд»Јжӣҝ
date-time and MAC address, DCE security version(зүҲжң¬2)пјҡеҲҶеёғејҸи®Ўз®—зҺҜеўғе®үе…Ёзҡ„UUIDпјҢз®—жі•е’ҢзүҲжң¬1еҹәжң¬дёҖиҮҙпјҢдҪҶдјҡжҠҠж—¶й—ҙжҲізҡ„еүҚ4дҪҚзҪ®жҚўдёәPOSIXзҡ„UIDжҲ–GID
namespace name-based MD5(зүҲжң¬3)пјҡйҖҡиҝҮи®Ўз®—еҗҚеӯ—е’Ңе‘ҪеҗҚз©әй—ҙзҡ„MD5ж•ЈеҲ—еҖјеҫ—еҲ°гҖӮиҝҷдёӘзүҲжң¬зҡ„UUIDдҝқиҜҒдәҶпјҡзӣёеҗҢе‘ҪеҗҚз©әй—ҙдёӯдёҚеҗҢеҗҚеӯ—з”ҹжҲҗзҡ„UUIDзҡ„е”ҜдёҖжҖ§;дёҚеҗҢе‘ҪеҗҚз©әй—ҙдёӯзҡ„UUIDзҡ„е”ҜдёҖжҖ§;зӣёеҗҢе‘ҪеҗҚз©әй—ҙдёӯзӣёеҗҢеҗҚеӯ—зҡ„UUIDйҮҚеӨҚз”ҹжҲҗжҳҜзӣёеҗҢзҡ„
random(зүҲжң¬4)пјҡж №жҚ®йҡҸжңәж•°пјҢжҲ–иҖ…дјӘйҡҸжңәж•°з”ҹжҲҗUUIDгҖӮиҝҷз§ҚUUIDдә§з”ҹйҮҚеӨҚзҡ„жҰӮзҺҮжҳҜеҸҜд»Ҙи®Ўз®—еҮәжқҘзҡ„пјҢиҝҳжңүдёҖдёӘзү№зӮ№е°ұжҳҜйў„з•ҷдәҶ6жҜ”зү№еӯҳж”ҫеҸҳдҪ“е’ҢзүҲжң¬еұһжҖ§пјҢжүҖд»ҘйҡҸжңәз”ҹжҲҗзҡ„дҪҚдёҖе…ұжңү122дёӘпјҢжҖ»йҮҸдёә2^122пјҢжҜ”е…¶д»–еҸҳдҪ“зҡ„жҖ»йҮҸиҰҒеҒҸе°‘
namespace name-based SHA-1(зүҲжң¬5)пјҡе’ҢзүҲжң¬3зұ»дјјпјҢж•ЈеҲ—з®—жі•жҚўжҲҗдәҶSHA-1
е…¶дёӯпјҢJDKдёӯеә”з”Ёзҡ„еҸҳдҪ“жҳҜLeach-SalzпјҢжҸҗдҫӣдәҶnamespace name-based MD5(зүҲжң¬3)е’Ңrandom(зүҲжң¬4)дёӨдёӘзүҲжң¬зҡ„UUIDз”ҹжҲҗе®һзҺ°гҖӮ
UUIDзҡ„ж јејҸ
еңЁи§„иҢғж–Ү件жҸҸиҝ°дёӯпјҢUUIDжҳҜз”ұ16дёӘ8жҜ”зү№ж•°еӯ—пјҢжҲ–иҖ…иҜҙ32дёӘ16иҝӣеҲ¶иЎЁзӨәеҪўејҸдёӢзҡ„еӯ—з¬Ұз»„жҲҗпјҢдёҖиҲ¬иЎЁзӨәеҪўејҸдёә8-4-4-4-12пјҢеҠ дёҠиҝһжҺҘеӯ—з¬Ұ-дёҖе…ұжңү36дёӘеӯ—з¬ҰпјҢдҫӢеҰӮпјҡ
## дҫӢеӯҗ 123e4567-e89b-12d3-a456-426614174000 ## йҖҡз”Ёж јејҸ xxxxxxxx-xxxx-Mxxx-Nxxx-xxxxxxxxxxxx
е…¶дёӯ4жҜ”зү№й•ҝеәҰзҡ„Mе’Ң1еҲ°3жҜ”зү№й•ҝеәҰзҡ„NеҲҶеҲ«д»ЈиЎЁзүҲжң¬еҸ·е’ҢеҸҳдҪ“ж ҮиҜҶгҖӮUUIDзҡ„е…·дҪ“еёғеұҖеҰӮдёӢпјҡ
| еұһжҖ§ | еұһжҖ§еҗҚ | й•ҝеәҰпјҲbytesпјү | й•ҝеәҰпјҲ16иҝӣеҲ¶еӯ—з¬Ұпјү | еҶ…е®№ |
|---|---|---|---|---|
time_low | ж—¶й—ҙжҲідҪҺдҪҚ | 4 | 8 | д»ЈиЎЁж—¶й—ҙжҲізҡ„дҪҺ32жҜ”зү№зҡ„ж•ҙж•°иЎЁзӨә |
time_mid | ж—¶й—ҙжҲідёӯдҪҚ | 2 | 4 | д»ЈиЎЁж—¶й—ҙжҲізҡ„дёӯй—ҙ16жҜ”зү№зҡ„ж•ҙж•°иЎЁзӨә |
time_hi_and_version | ж—¶й—ҙжҲій«ҳдҪҚе’ҢзүҲжң¬еҸ· | 2 | 4 | й«ҳдҪҚ4жҜ”зү№жҳҜзүҲжң¬еҸ·иЎЁзӨәпјҢеү©дҪҷжҳҜж—¶й—ҙжҲізҡ„й«ҳ12жҜ”зү№зҡ„ж•ҙж•°иЎЁзӨә |
clock_seq_hi_and_res clock_seq_low | ж—¶й’ҹеәҸеҲ—дёҺеҸҳдҪ“зј–еҸ· | 2 | 4 | жңҖй«ҳдҪҚ1еҲ°3жҜ”зү№иЎЁзӨәеҸҳдҪ“зј–еҸ·пјҢеү©дёӢзҡ„13еҲ°15жҜ”зү№иЎЁзӨәж—¶й’ҹеәҸеҲ— |
node | иҠӮзӮ№ID | 6 | 12 | 48жҜ”зү№иЎЁзӨәзҡ„иҠӮзӮ№ID |
еҹәдәҺиҝҷдёӘиЎЁж јз”»дёҖдёӘеӣҫпјҡ

гҖҢдёҘйҮҚжіЁж„ҸпјҢйҮҚеӨҚдёүж¬ЎгҖҚпјҡ
дёҠйқўжҸҗеҲ°зҡ„UUIDзҡ„е…·дҪ“еёғеұҖеҸӘйҖӮз”ЁдәҺdate-time and MAC address(зүҲжң¬1)е’Ңdate-time and MAC address, DCE security version(зүҲжң¬2)пјҢе…¶д»–зүҲжң¬иҷҪ然йҮҮз”ЁдәҶеҹәжң¬дёҖж ·зҡ„еӯ—ж®өеҲҶеёғпјҢдҪҶжҳҜж— жі•иҺ·еҸ–ж—¶й—ҙжҲігҖҒж—¶й’ҹеәҸеҲ—жҲ–иҖ…иҠӮзӮ№IDзӯүдҝЎжҒҜ
дёҠйқўжҸҗеҲ°зҡ„UUIDзҡ„е…·дҪ“еёғеұҖеҸӘйҖӮз”ЁдәҺdate-time and MAC address(зүҲжң¬1)е’Ңdate-time and MAC address, DCE security version(зүҲжң¬2)пјҢе…¶д»–зүҲжң¬иҷҪ然йҮҮз”ЁдәҶеҹәжң¬дёҖж ·зҡ„еӯ—ж®өеҲҶеёғпјҢдҪҶжҳҜж— жі•иҺ·еҸ–ж—¶й—ҙжҲігҖҒж—¶й’ҹеәҸеҲ—жҲ–иҖ…иҠӮзӮ№IDзӯүдҝЎжҒҜ
дёҠйқўжҸҗеҲ°зҡ„UUIDзҡ„е…·дҪ“еёғеұҖеҸӘйҖӮз”ЁдәҺdate-time and MAC address(зүҲжң¬1)е’Ңdate-time and MAC address, DCE security version(зүҲжң¬2)пјҢе…¶д»–зүҲжң¬иҷҪ然йҮҮз”ЁдәҶеҹәжң¬дёҖж ·зҡ„еӯ—ж®өеҲҶеёғпјҢдҪҶжҳҜж— жі•иҺ·еҸ–ж—¶й—ҙжҲігҖҒж—¶й’ҹеәҸеҲ—жҲ–иҖ…иҠӮзӮ№IDзӯүдҝЎжҒҜ
JDKдёӯеҸӘжҸҗдҫӣдәҶзүҲжң¬3е’ҢзүҲжң¬4зҡ„е®һзҺ°пјҢдҪҶжҳҜjava.util.UUIDзҡ„еёғеұҖйҮҮз”ЁдәҶдёҠйқўиЎЁж јзҡ„еӯ—ж®ө
UUIDзҡ„зў°ж’һеҮ зҺҮи®Ўз®—
UUIDзҡ„жҖ»йҮҸиҷҪ然巨еӨ§пјҢдҪҶжҳҜеҰӮжһңдёҚеҒңең°дҪҝз”ЁпјҢеҒҮи®ҫжҜҸзәіз§’з”ҹжҲҗи¶…иҝҮ1е…ҶдёӘUUID并且дәәзұ»жңүе№ёиғҪеӨҹз№ҒиЎҚеҲ°100дәҝе№ҙд»ҘеҗҺпјҢжҖ»дјҡжңүеҸҜиғҪдә§з”ҹйҮҚеӨҚзҡ„UUIDгҖӮйӮЈд№ҲпјҢжҖҺд№Ҳи®Ўз®—UUIDзҡ„зў°ж’һеҮ зҺҮе‘ў?иҝҷжҳҜдёҖдёӘж•°еӯҰй—®йўҳпјҢеҸҜд»ҘдҪҝз”ЁжҜ”иҫғи‘—еҗҚзҡ„гҖҢз”ҹж—ҘжӮ–и®әгҖҚи§ЈеҶіпјҡ

дёҠеӣҫжқҘжәҗдәҺжҹҗжҗңзҙўеј•ж“Һзҷҫ科гҖӮеҲҡеҘҪз»ҙеҹәзҷҫ科дёҠз»ҷеҮәдәҶзў°ж’һеҮ зҺҮзҡ„и®Ўз®—иҝҮзЁӢпјҢе…¶е®һз”Ёзҡ„д№ҹжҳҜз”ҹж—ҘжӮ–и®әзҡ„и®Ўз®—ж–№жі•пјҢиҝҷйҮҢиҙҙдёҖдёӢпјҡ

дёҠйқўзҡ„зў°ж’һеҮ зҺҮи®Ўз®—жҳҜеҹәдәҺLeach–SalzеҸҳдҪ“е’ҢзүҲжң¬4иҝӣиЎҢпјҢеҫ—еҲ°зҡ„з»“и®әжҳҜпјҡ
103дёҮдәҝдёӘUUIDдёӯжүҫеҲ°йҮҚеӨҚйЎ№зҡ„жҰӮзҺҮжҳҜеҚҒдәҝеҲҶд№ӢдёҖ
иҰҒз”ҹжҲҗдёҖдёӘеҶІзӘҒзҺҮиҫҫеҲ°50%зҡ„UUIDиҮіе°‘йңҖиҰҒз”ҹжҲҗ2.71 * 1_000_000^3дёӘUUID
жңүз”ҹд№Ӣе№ҙдёҚйңҖиҰҒжӢ…еҝғUUIDеҶІзӘҒпјҢеҮәзҺ°зҡ„еҸҜиғҪжҖ§жҜ”еӨ§еһӢйҷЁзҹіж’һең°зҗғиҝҳдҪҺгҖӮ

UUIDзҡ„дҪҝз”ЁеңәжҷҜ
еҹәжң¬жүҖжңүйңҖиҰҒдҪҝз”Ёе…ЁеұҖе”ҜдёҖж ҮиҜҶз¬Ұзҡ„еңәжҷҜйғҪеҸҜд»ҘдҪҝз”ЁUUIDпјҢйҷӨйқһеҜ№й•ҝеәҰжңүжҳҺзЎ®зҡ„йҷҗеҲ¶пјҢеёёз”Ёзҡ„еңәжҷҜеҢ…жӢ¬пјҡ
ж—Ҙеҝ—жЎҶжһ¶жҳ е°„иҜҠж–ӯдёҠдёӢж–Үдёӯзҡ„TRACE_ID
APMе·Ҙе…·жҲ–иҖ…иҜҙOpenTracing规иҢғдёӯзҡ„SPAN_ID
зү№ж®ҠеңәжҷҜдёӢж•°жҚ®еә“дё»й”®жҲ–иҖ…иҷҡжӢҹеӨ–й”®
дәӨжҳ“ID(и®ўеҚ•ID)
зӯүзӯү......
JDKдёӯUUIDиҜҰз»Ҷд»Ӣз»Қе’ҢдҪҝз”Ё
иҝҷйҮҢе…Ҳд»Ӣз»ҚдҪҝз”Ёж–№ејҸгҖӮеүҚйқўжҸҗеҲ°JDKдёӯеә”з”Ёзҡ„еҸҳдҪ“жҳҜLeach-Salz(еҸҳдҪ“2)пјҢжҸҗдҫӣдәҶnamespace name-based MD5(зүҲжң¬3)е’Ңrandom(зүҲжң¬4)дёӨдёӘзүҲжң¬зҡ„UUIDз”ҹжҲҗе®һзҺ°пјҢе®һйҷ…дёҠjava.util.UUIDжҸҗдҫӣдәҶеӣӣз§Қз”ҹжҲҗUUIDе®һдҫӢзҡ„ж–№ејҸпјҡ
жңҖеёёи§Ғзҡ„е°ұжҳҜи°ғз”ЁйқҷжҖҒж–№жі•UUID#randomUUID()пјҢиҝҷе°ұжҳҜзүҲжң¬4зҡ„йқҷжҖҒе·ҘеҺӮж–№жі•
е…¶ж¬ЎжҳҜи°ғз”ЁйқҷжҖҒж–№жі•UUID#nameUUIDFromBytes(byte[] name)пјҢиҝҷе°ұжҳҜзүҲжң¬3зҡ„йқҷжҖҒе·ҘеҺӮж–№жі•
еҸҰеӨ–жңүи°ғз”ЁйқҷжҖҒж–№жі•UUID#fromString(String name)пјҢиҝҷжҳҜи§Јжһҗ8-4-4-4-12ж јејҸеӯ—з¬ҰдёІз”ҹжҲҗUUIDе®һдҫӢзҡ„йқҷжҖҒе·ҘеҺӮж–№жі•
иҝҳжңүдҪҺеұӮж¬Ўзҡ„жһ„йҖ еҮҪж•°UUID(long mostSigBits, long leastSigBits)пјҢиҝҷдёӘеҜ№дәҺдҪҝз”ЁиҖ…жқҘиҜҙ并дёҚеёёи§Ғ
жңҖеёёз”Ёзҡ„ж–№жі•жңүе®һдҫӢж–№жі•toString()пјҢжҠҠUUIDиҪ¬еҢ–дёә16иҝӣеҲ¶еӯ—з¬ҰдёІжӢјжҺҘиҖҢжҲҗзҡ„8-4-4-4-12еҪўејҸиЎЁзӨәпјҢдҫӢеҰӮпјҡ
String uuid = UUID.randomUUID().toString();
е…¶д»–Getterж–№жі•пјҡ
UUID uuid = UUID.randomUUID(); // иҝ”еӣһзүҲжң¬еҸ· int version = uuid.version(); // иҝ”еӣһеҸҳдҪ“еҸ· int variant = uuid.variant(); // иҝ”еӣһж—¶й—ҙжҲі - иҝҷдёӘж–№жі•дјҡжҠҘй”ҷпјҢеҸӘжңүTime-based UUIDд№ҹе°ұжҳҜзүҲжң¬1жҲ–иҖ…2зҡ„UUIDе®һзҺ°жүҚиғҪиҝ”еӣһж—¶й—ҙжҲі long timestamp = uuid.timestamp(); // иҝ”еӣһж—¶й’ҹеәҸеҲ— - иҝҷдёӘж–№жі•дјҡжҠҘй”ҷпјҢеҸӘжңүTime-based UUIDд№ҹе°ұжҳҜзүҲжң¬1жҲ–иҖ…2зҡ„UUIDе®һзҺ°жүҚиғҪиҝ”еӣһж—¶й’ҹеәҸеҲ— long clockSequence = uuid.clockSequence(); // иҝ”еӣһиҠӮзӮ№ID - иҝҷдёӘж–№жі•дјҡжҠҘй”ҷпјҢеҸӘжңүTime-based UUIDд№ҹе°ұжҳҜзүҲжң¬1жҲ–иҖ…2зҡ„UUIDе®һзҺ°жүҚиғҪиҝ”еӣһиҠӮзӮ№ID long nodeId = uuid.node();
еҸҜд»ҘйӘҢиҜҒдёҖдёӢдёҚеҗҢйқҷжҖҒе·ҘеҺӮж–№жі•зҡ„зүҲжң¬е’ҢеҸҳдҪ“еҸ·пјҡ
UUID uuid = UUID.randomUUID(); int version = uuid.version(); int variant = uuid.variant(); System.out.println(String.format("version:%d,variant:%d", version, variant)); uuid = UUID.nameUUIDFromBytes(new byte[0]); version = uuid.version(); variant = uuid.variant(); System.out.println(String.format("version:%d,variant:%d", version, variant)); // иҫ“еҮәз»“жһң version:4,variant:2 version:3,variant:2жҺўз©¶JDKдёӯUUIDжәҗз Ғе®һзҺ°
java.util.UUIDиў«finalдҝ®йҘ°пјҢе®һзҺ°дәҶSerializableе’ҢComparableжҺҘеҸЈпјҢд»ҺдёҖиҲ¬зҗҶи§ЈдёҠзңӢпјҢжңүдёӢйқўзҡ„зү№е®ҡпјҡ
дёҚеҸҜеҸҳпјҢдёҖиҲ¬жқҘиҜҙе·Ҙе…·зұ»йғҪжҳҜиҝҷж ·е®ҡд№үзҡ„
еҸҜеәҸеҲ—еҢ–е’ҢеҸҚеәҸеҲ—еҢ–
дёҚеҗҢзҡ„еҜ№иұЎд№Ӣй—ҙеҸҜд»ҘиҝӣиЎҢжҜ”иҫғпјҢжҜ”иҫғж–№жі•еҗҺйқўдјҡеҲҶжһҗ
дёӢйқўдјҡд»ҺдёҚеҗҢзҡ„ж–№йқўеҲҶжһҗдёҖдёӢjava.util.UUIDзҡ„жәҗз Ғе®һзҺ°пјҡ
еұһжҖ§е’Ңжһ„йҖ еҮҪж•°
йҡҸжңәж•°зүҲжң¬е®һзҺ°
namespace name-based MD5зүҲжң¬е®һзҺ°
е…¶д»–е®һзҺ°
ж јејҸеҢ–иҫ“еҮә
жҜ”иҫғзӣёе…ізҡ„ж–№жі•
еұһжҖ§е’Ңжһ„йҖ еҮҪж•°
еүҚйқўеҸҚеӨҚжҸҗеҲ°JDKдёӯеҸӘжҸҗдҫӣдәҶзүҲжң¬3е’ҢзүҲжң¬4зҡ„е®һзҺ°пјҢдҪҶжҳҜjava.util.UUIDзҡ„еёғеұҖйҮҮз”ЁдәҶUUID规иҢғдёӯзҡ„еӯ—ж®өе®ҡд№үпјҢй•ҝеәҰдёҖе…ұ128жҜ”зү№пјҢеҲҡеҘҪеҸҜд»Ҙеӯҳж”ҫеңЁдёӨдёӘlongзұ»еһӢзҡ„ж•ҙж•°дёӯпјҢжүҖд»ҘзңӢеҲ°дәҶUUIDзұ»дёӯеӯҳеңЁдёӨдёӘlongзұ»еһӢзҡ„ж•ҙеһӢж•°еҖјпјҡ
public final class UUID implements java.io.Serializable, Comparable<UUID> { // жҡӮж—¶зңҒз•Ҙе…¶д»–д»Јз Ғ /* * The most significant 64 bits of this UUID. * UUIDдёӯжңүж•Ҳзҡ„й«ҳ64жҜ”зү№ * * @serial */ private final long mostSigBits; /* * The least significant 64 bits of this UUID. * UUIDдёӯжңүж•Ҳзҡ„дҪҺ64жҜ”зү№ * * @serial */ private final long leastSigBits; // жҡӮж—¶зңҒз•Ҙе…¶д»–д»Јз Ғ }д»ҺUUIDзұ»жіЁйҮҠдёӯеҸҜд»ҘзңӢеҲ°е…·дҪ“зҡ„еӯ—ж®өеёғеұҖеҰӮдёӢпјҡ
гҖҢй«ҳ64жҜ”зү№mostSigBitsзҡ„еёғеұҖгҖҚ
| еӯ—ж®ө | bitй•ҝеәҰ | 16иҝӣеҲ¶еӯ—з¬Ұй•ҝеәҰ |
|---|---|---|
time_low | 32 | 8 |
time_mid | 16 | 4 |
version | 4 | 1 |
time_hi | 12 | 3 |
гҖҢдҪҺ64жҜ”зү№leastSigBitsзҡ„еёғеұҖгҖҚ
| еӯ—ж®ө | bitй•ҝеәҰ | 16иҝӣеҲ¶еӯ—з¬Ұй•ҝеәҰ |
|---|---|---|
variant | 2 | е°ҸдәҺ1 |
clock_seq | 14 | variantе’Ңclock_seqеҠ иө·жқҘзӯүдәҺ4 |
node | 48 | 12 |
жҺҘзқҖзңӢUUIDзҡ„е…¶д»–жҲҗе‘ҳеұһжҖ§е’Ңжһ„йҖ еҮҪж•°пјҡ
public final class UUID implements java.io.Serializable, Comparable<UUID> { // жҡӮж—¶зңҒз•Ҙе…¶д»–д»Јз Ғ // JavaиҜӯиЁҖи®ҝй—®зұ»пјҢйҮҢйқўеӯҳж”ҫдәҶеҫҲеӨҡеә•еұӮзӣёе…ізҡ„и®ҝй—®жҲ–иҖ…иҪ¬жҚўж–№жі•пјҢеңЁUUIDдёӯдё»иҰҒжҳҜtoString()е®һдҫӢж–№жі•з”ЁжқҘж јејҸеҢ–жҲҗ8-4-4-4-12зҡ„еҪўејҸпјҢ委жүҳеҲ°Long.fastUUID()ж–№жі• private static final JavaLangAccess jla = SharedSecrets.getJavaLangAccess(); // йқҷжҖҒеҶ…йғЁзұ»зЎ®дҝқSecureRandomеҲқе§ӢеҢ–пјҢз”ЁдәҺзүҲжң¬4зҡ„йҡҸжңәж•°UUIDзүҲжң¬з”ҹжҲҗе®үе…ЁйҡҸжңәж•° private static class Holder { static final SecureRandom numberGenerator = new SecureRandom(); } // йҖҡиҝҮй•ҝеәҰдёә16зҡ„еӯ—иҠӮж•°з»„пјҢи®Ўз®—mostSigBitsе’ҢleastSigBitsзҡ„еҖјеҲқе§ӢеҢ–UUIDе®һдҫӢ private UUID(byte[] data) { long msb = 0; long lsb = 0; assert data.length == 16 : "data must be 16 bytes in length"; for (int i=0; i<8; i++) msb = (msb << 8) | (data[i] & 0xff); for (int i=8; i<16; i++) lsb = (lsb << 8) | (data[i] & 0xff); this.mostSigBits = msb; this.leastSigBits = lsb; } // зӣҙжҺҘжҢҮе®ҡmostSigBitsе’ҢleastSigBitsжһ„йҖ UUIDе®һдҫӢ public UUID(long mostSigBits, long leastSigBits) { this.mostSigBits = mostSigBits; this.leastSigBits = leastSigBits; } // жҡӮж—¶зңҒз•Ҙе…¶д»–д»Јз Ғ }з§Ғжңүжһ„йҖ private UUID(byte[] data)дёӯжңүдёҖдәӣдҪҚиҝҗз®—жҠҖе·§пјҡ
long msb = 0; long lsb = 0; assert data.length == 16 : "data must be 16 bytes in length"; for (int i=0; i<8; i++) msb = (msb << 8) | (data[i] & 0xff); for (int i=8; i<16; i++) lsb = (lsb << 8) | (data[i] & 0xff); this.mostSigBits = msb; this.leastSigBits = lsb;
иҫ“е…Ҙзҡ„еӯ—иҠӮж•°з»„й•ҝеәҰдёә16пјҢmostSigBitsз”ұеӯ—иҠӮж•°з»„зҡ„еүҚ8дёӘеӯ—иҠӮиҪ¬жҚўиҖҢжқҘпјҢиҖҢleastSigBitsз”ұеӯ—иҠӮж•°з»„зҡ„еҗҺ8дёӘеӯ—иҠӮиҪ¬жҚўиҖҢжқҘгҖӮдёӯй—ҙеҸҳйҮҸmsbжҲ–иҖ…lsbеңЁжҸҗеҸ–еӯ—иҠӮдҪҚиҝӣиЎҢи®Ўз®—зҡ„ж—¶еҖҷпјҡ
е…ҲиҝӣиЎҢе·Ұ移8дҪҚзЎ®дҝқйңҖиҰҒи®Ўз®—зҡ„дҪҚдёә0пјҢе·Із»Ҹи®Ўз®—еҘҪзҡ„дҪҚ移еҠЁеҲ°е·Ұиҫ№
然еҗҺеҸіиҫ№йңҖиҰҒжҸҗеҸ–зҡ„еӯ—иҠӮdata[i]зҡ„8дҪҚдјҡе…Ҳе’Ң0xff(иЎҘз Ғ1111 1111)иҝӣиЎҢжҲ–иҝҗз®—пјҢзЎ®дҝқдёҚи¶і8дҪҚзҡ„й«ҳдҪҚиў«иЎҘе……дёә0пјҢи¶…иҝҮ8дҪҚзҡ„й«ҳдҪҚдјҡиў«жҲӘж–ӯдёәдҪҺ8дҪҚпјҢд№ҹе°ұжҳҜdata[i] & 0xffзЎ®дҝқеҫ—еҲ°зҡ„иЎҘз Ғдёә8дҪҚ
еүҚйқўдёӨжӯҘзҡ„з»“жһңеҶҚиҝӣиЎҢжҲ–иҝҗз®—
дёҖдёӘжЁЎжӢҹиҝҮзЁӢеҰӮдёӢпјҡ
пјҲдёәдәҶеҢәеҲҶжҳҺжҳҫпјҢ笔иҖ…жҜҸ4дҪҚеҠ дәҶдёҖдёӘдёӢеҲ’зәҝпјү пјҲдёәдәҶз®Җзӯ”пјҢеҸӘзңӢеӯ—иҠӮж•°з»„зҡ„еүҚ4дёӘеӯ—иҠӮпјҢеҗҢж—¶еҸӘзңӢlongзұ»еһӢзҡ„еүҚ4дёӘеӯ—иҠӮпјү 0xff === 1111_1111 long msb = 0 => 0000_0000 0000_0000 0000_0000 0000_0000 byte[] data 0000_0001 0000_0010 0000_0100 0000_1000 i = 0пјҲ第дёҖиҪ®пјү msb << 8 = 0000_0000 0000_0000 0000_0000 0000_0000 data[i] & 0xff = 0000_0001 & 1111_1111 = 0000_0001 (msb << 8) | (data[i] & 0xff) = 0000_0000 0000_0000 0000_0000 0000_0001 пјҲ第дёҖиҪ® msb = 0000_0000 0000_0000 0000_0000 0000_0001пјү i = 1пјҲ第дәҢиҪ®пјү msb << 8 = 0000_0000 0000_0000 0000_0001 0000_0000 data[i] & 0xff = 0000_0010 & 1111_1111 = 0000_0010 (msb << 8) | (data[i] & 0xff) = 0000_0000 0000_0000 0000_0001 0000_0010 пјҲ第дәҢиҪ® msb = 0000_0000 0000_0000 0000_0001 0000_0010пјү i = 2пјҲ第дёүиҪ®пјү msb << 8 = 0000_0000 0000_0001 0000_0010 0000_0000 data[i] & 0xff = 0000_0100 & 1111_1111 = 0000_0100 (msb << 8) | (data[i] & 0xff) = 0000_0000 0000_0001 0000_0010 0000_0100 пјҲ第дёүиҪ® msb = 0000_0000 0000_0001 0000_0010 0000_0100пјү i = 3пјҲ第еӣӣиҪ®пјү msb << 8 = 0000_0001 0000_0010 0000_0100 0000000 data[i] & 0xff = 0000_1000 & 1111_1111 = 0000_1000 (msb << 8) | (data[i] & 0xff) = 0000_0001 0000_0010 0000_0100 0000_1000 пјҲ第еӣӣиҪ® msb = 0000_0001 0000_0010 0000_0100 0000_1000пјү
д»ҘжӯӨзұ»жҺЁпјҢиҝҷдёӘз§Ғжңүжһ„йҖ еҮҪж•°жү§иЎҢе®ҢжҜ•еҗҺпјҢй•ҝеәҰдёә16зҡ„еӯ—иҠӮж•°з»„зҡ„жүҖжңүдҪҚе°ұдјҡиҪ¬з§»еҲ°mostSigBitsе’ҢleastSigBitsдёӯгҖӮ
йҡҸжңәж•°зүҲжң¬е®һзҺ°
жһ„йҖ еҮҪж•°еҲҶжһҗе®ҢпјҢжҺҘзқҖеҲҶжһҗйҮҚзЈ…зҡ„йқҷжҖҒе·ҘеҺӮж–№жі•UUID#randomUUID()пјҢиҝҷжҳҜдҪҝз”Ёйў‘зҺҮжңҖй«ҳзҡ„дёҖдёӘж–№жі•пјҡ
public static UUID randomUUID() { // йқҷжҖҒеҶ…йғЁзұ»HolderжҢҒжңүзҡ„SecureRandomе®һдҫӢпјҢзЎ®дҝқжҸҗеүҚеҲқе§ӢеҢ– SecureRandom ng = Holder.numberGenerator; // з”ҹжҲҗдёҖдёӘ16еӯ—иҠӮзҡ„е®үе…ЁйҡҸжңәж•°пјҢж”ҫеңЁй•ҝеәҰдёә16зҡ„еӯ—иҠӮж•°з»„дёӯ byte[] randomBytes = new byte[16]; ng.nextBytes(randomBytes); // жё…з©әзүҲжң¬еҸ·жүҖеңЁзҡ„дҪҚпјҢйҮҚж–°и®ҫзҪ®дёә4 randomBytes[6] &= 0x0f; /* clear version */ randomBytes[6] |= 0x40; /* set to version 4 */ // жё…з©әеҸҳдҪ“еҸ·жүҖеңЁзҡ„дҪҚпјҢйҮҚж–°и®ҫзҪ®дёә randomBytes[8] &= 0x3f; /* clear variant */ randomBytes[8] |= 0x80; /* set to IETF variant */ return new UUID(randomBytes); }е…ідәҺдёҠйқўзҡ„дҪҚиҝҗз®—пјҢиҝҷйҮҢеҸҜд»ҘдҪҝз”ЁжһҒз«Ҝзҡ„дҫӢеӯҗиҝӣиЎҢжҺЁжј”пјҡ
еҒҮи®ҫrandomBytes[6] = 1111_1111 // жё…з©әversionдҪҚ randomBytes[6] &= 0x0f => 1111_1111 & 0000_1111 = 0000_1111 еҫ—еҲ°randomBytes[6] = 0000_1111 пјҲиҝҷйҮҢеҸҜи§Ғй«ҳ4жҜ”зү№иў«жё…з©әдёә0пјү // и®ҫзҪ®versionдҪҚдёәж•ҙж•°4 => еҚҒе…ӯиҝӣеҲ¶0x40 => дәҢзә§еҲ¶иЎҘз Ғ0100_0000 randomBytes[6] |= 0x40 => 0000_1111 | 0100_0000 = 0100_1111 еҫ—еҲ°randomBytes[6] = 0100_1111 з»“жһңпјҡversionдҪҚ => 0100пјҲ4 bitпјү=> еҜ№еә”еҚҒиҝӣеҲ¶ж•°4 еҗҢзҗҶ еҒҮи®ҫrandomBytes[8] = 1111_1111 // жё…з©әvariantдҪҚ randomBytes[8] &= 0x3f => 1111_1111 & 0011_1111 = 0011_1111 // и®ҫзҪ®variantдҪҚдёәж•ҙж•°128 => еҚҒе…ӯиҝӣеҲ¶0x80 => дәҢзә§еҲ¶иЎҘз Ғ1000_0000 пјҲиҝҷйҮҢеҸ–е·Ұиҫ№й«ҳдҪҚ2дҪҚпјү randomBytes[8] |= 0x80 => 0011_1111 | 1000_0000 = 1011_1111 з»“жһңпјҡvariantдҪҚ => 10пјҲ2 bitпјү=> еҜ№еә”еҚҒиҝӣеҲ¶ж•°2
е…ідәҺUUIDйҮҢйқўзҡ„Getterж–№жі•дҫӢеҰӮversion()гҖҒvariant()е…¶е®һе°ұжҳҜжүҫеҲ°еҜ№еә”зҡ„дҪҚпјҢ并且иҪ¬жҚўдёәеҚҒиҝӣеҲ¶ж•ҙж•°иҝ”еӣһпјҢеҰӮжһңзҶҹз»ғдҪҝз”ЁдҪҚиҝҗз®—пјҢеә”иҜҘдёҚйҡҫзҗҶи§ЈпјҢеҗҺйқўдёҚдјҡеҲҶжһҗиҝҷзұ»зҡ„Getterж–№жі•гҖӮ
гҖҢйҡҸжңәж•°зүҲжң¬е®һзҺ°ејәдҫқиө–дәҺSecureRandomз”ҹжҲҗзҡ„йҡҸжңәж•°(еӯ—иҠӮж•°з»„)гҖҚгҖӮSecureRandomзҡ„еј•ж“ҺжҸҗдҫӣиҖ…еҸҜд»Ҙд»Һsun.security.provider.SunEntriesдёӯжҹҘзңӢпјҢеҜ№дәҺдёҚеҗҢзі»з»ҹзүҲжң¬зҡ„JDKе®һзҺ°дјҡйҖүз”ЁдёҚеҗҢзҡ„еј•ж“ҺпјҢеёёи§Ғзҡ„еҰӮNativePRNGгҖӮJDK11й…ҚзҪ®ж–Ү件$JAVA_HOME/conf/security/java.securityдёӯзҡ„securerandom.sourceеұһжҖ§з”ЁдәҺжҢҮе®ҡзі»з»ҹй»ҳи®Өзҡ„йҡҸжңәжәҗпјҡ
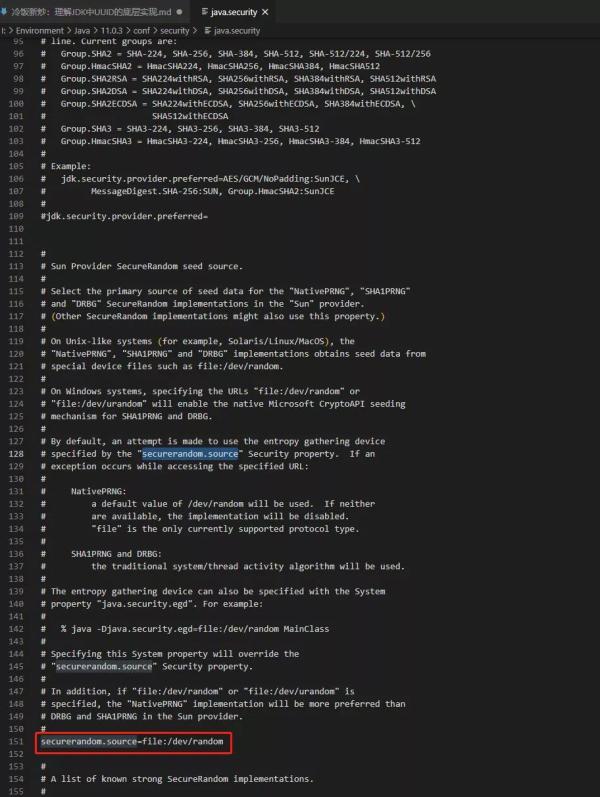
иҝҷйҮҢиҰҒжҸҗдёҖдёӘе°ҸзҹҘиҜҶзӮ№пјҢжғіиҰҒеҫ—еҲ°еҜҶз ҒеӯҰж„Ҹд№үдёҠзҡ„е®үе…ЁйҡҸжңәж•°пјҢеҸҜд»ҘзӣҙжҺҘдҪҝз”ЁзңҹйҡҸжңәж•°дә§з”ҹеҷЁдә§з”ҹзҡ„йҡҸжңәж•°пјҢжҲ–иҖ…дҪҝз”ЁзңҹйҡҸжңәж•°дә§з”ҹеҷЁдә§з”ҹзҡ„йҡҸжңәж•°еҒҡз§ҚеӯҗгҖӮйҖҡиҝҮжҹҘжүҫдёҖдәӣиө„ж–ҷеҫ—зҹҘгҖҢйқһзү©зҗҶзңҹйҡҸжңәж•°дә§з”ҹеҷЁгҖҚжңүпјҡ
Linuxж“ҚдҪңзі»з»ҹзҡ„/dev/randomи®ҫеӨҮжҺҘеҸЈ
Windowsж“ҚдҪңзі»з»ҹзҡ„CryptGenRandomжҺҘеҸЈ
еҰӮжһңдёҚдҝ®ж”№java.securityй…ҚзҪ®ж–Ү件пјҢй»ҳи®ӨйҡҸжңәж•°жҸҗдҫӣеј•ж“Һдјҡж №жҚ®дёҚеҗҢзҡ„ж“ҚдҪңзі»з»ҹйҖүз”ЁдёҚеҗҢзҡ„е®һзҺ°пјҢиҝҷйҮҢдёҚиҝӣиЎҢж·ұ究гҖӮеңЁLinuxзҺҜеўғдёӢпјҢSecureRandomе®һдҫӢеҢ–еҗҺпјҢдёҚйҖҡиҝҮsetSeed()ж–№жі•и®ҫзҪ®йҡҸжңәж•°дҪңдёәз§ҚеӯҗпјҢй»ҳи®Өе°ұжҳҜдҪҝз”Ё/dev/randomжҸҗдҫӣзҡ„е®үе…ЁйҡҸжңәж•°жҺҘеҸЈиҺ·еҸ–з§ҚеӯҗпјҢдә§з”ҹзҡ„йҡҸжңәж•°жҳҜеҜҶз ҒеӯҰж„Ҹд№үдёҠзҡ„е®үе…ЁйҡҸжңәж•°гҖӮгҖҢдёҖеҸҘиҜқжҰӮжӢ¬пјҢUUIDдёӯзҡ„з§ҒжңүйқҷжҖҒеҶ…йғЁзұ»Holderдёӯзҡ„SecureRandomе®һдҫӢеҸҜд»Ҙдә§з”ҹе®үе…ЁйҡҸжңәж•°пјҢиҝҷдёӘжҳҜJDKе®һзҺ°UUIDзүҲжң¬4зҡ„дёҖдёӘйҮҚиҰҒеүҚжҸҗгҖҚгҖӮиҝҷйҮҢжҖ»з»“дёҖдёӢйҡҸжңәж•°зүҲжң¬UUIDзҡ„е®һзҺ°жӯҘйӘӨпјҡ
йҖҡиҝҮSecureRandomдҫқиө–жҸҗдҫӣзҡ„е®үе…ЁйҡҸжңәж•°жҺҘеҸЈиҺ·еҸ–з§ҚеӯҗпјҢз”ҹжҲҗдёҖдёӘ16еӯ—иҠӮзҡ„йҡҸжңәж•°(еӯ—иҠӮж•°з»„)
еҜ№дәҺз”ҹжҲҗзҡ„йҡҸжңәж•°пјҢжё…з©әе’ҢйҮҚж–°и®ҫзҪ®versionе’ҢvariantеҜ№еә”зҡ„дҪҚ
жҠҠйҮҚзҪ®е®Ңversionе’Ңvariantзҡ„йҡҸжңәж•°зҡ„жүҖжңүдҪҚиҪ¬з§»еҲ°mostSigBitsе’ҢleastSigBitsдёӯ
namespace name-based MD5зүҲжң¬е®һзҺ°
жҺҘзқҖеҲҶжһҗзүҲжң¬3д№ҹе°ұжҳҜnamespace name-based MD5зүҲжң¬зҡ„е®һзҺ°пјҢеҜ№еә”дәҺйқҷжҖҒе·ҘеҺӮж–№жі•UUID#nameUUIDFromBytes()пјҡ
public static UUID nameUUIDFromBytes(byte[] name) { MessageDigest md; try { md = MessageDigest.getInstance("MD5"); } catch (NoSuchAlgorithmException nsae) { throw new InternalError("MD5 not supported", nsae); } byte[] md5Bytes = md.digest(name); md5Bytes[6] &= 0x0f; /* clear version */ md5Bytes[6] |= 0x30; /* set to version 3 */ md5Bytes[8] &= 0x3f; /* clear variant */ md5Bytes[8] |= 0x80; /* set to IETF variant */ return new UUID(md5Bytes); }е®ғзҡ„еҗҺз»ӯеҹәжң¬еӨ„зҗҶе’ҢйҡҸжңәж•°зүҲжң¬еҹәжң¬дёҖиҮҙ(жё…з©әзүҲжң¬дҪҚзҡ„ж—¶еҖҷпјҢйҮҚж–°и®ҫзҪ®дёә3)пјҢе”ҜдёҖжҳҺжҳҫдёҚеҗҢзҡ„ең°ж–№е°ұжҳҜз”ҹжҲҗеҺҹе§ӢйҡҸжңәж•°зҡ„ж—¶еҖҷпјҢйҮҮз”Ёзҡ„ж–№ејҸжҳҜпјҡеҹәдәҺиҫ“е…Ҙзҡ„nameеӯ—иҠӮж•°з»„пјҢйҖҡиҝҮMD5ж‘ҳиҰҒз®—жі•з”ҹжҲҗдёҖдёӘMD5ж‘ҳиҰҒеӯ—иҠӮж•°з»„дҪңдёәеҺҹе§Ӣе®үе…ЁйҡҸжңәж•°пјҢиҝ”еӣһзҡ„иҝҷдёӘйҡҸжңәж•°еҲҡеҘҪд№ҹжҳҜ16еӯ—иҠӮй•ҝеәҰзҡ„гҖӮдҪҝз”Ёж–№ејҸеҫҲз®ҖеҚ•пјҡ
UUID uuid = UUID.nameUUIDFromBytes("throwable".getBytes());namespace name-based MD5зүҲжң¬UUIDзҡ„е®һзҺ°жӯҘйӘӨеҰӮдёӢпјҡ
йҖҡиҝҮиҫ“е…Ҙзҡ„е‘ҪеҗҚеӯ—иҠӮж•°з»„еҹәдәҺMD5з®—жі•з”ҹжҲҗдёҖдёӘ16еӯ—иҠӮй•ҝеәҰзҡ„йҡҸжңәж•°
еҜ№дәҺз”ҹжҲҗзҡ„йҡҸжңәж•°пјҢжё…з©әе’ҢйҮҚж–°и®ҫзҪ®versionе’ҢvariantеҜ№еә”зҡ„дҪҚ
жҠҠйҮҚзҪ®е®Ңversionе’Ңvariantзҡ„йҡҸжңәж•°зҡ„жүҖжңүдҪҚиҪ¬з§»еҲ°mostSigBitsе’ҢleastSigBitsдёӯ
namespace name-based MD5зүҲжң¬зҡ„UUIDејәдҫқиө–дәҺMD5з®—жі•пјҢжңүдёӘжҳҺжҳҫзҡ„зү№еҫҒжҳҜеҰӮжһңиҫ“е…Ҙзҡ„byte[] nameдёҖиҮҙзҡ„жғ…еҶөдёӢпјҢдјҡдә§з”ҹе®Ңе…ЁзӣёеҗҢзҡ„UUIDе®һдҫӢгҖӮ
е…¶д»–е®һзҺ°
е…¶д»–е®һзҺ°дё»иҰҒеҢ…жӢ¬пјҡ
// е®Ңе…Ёе®ҡеҲ¶mostSigBitsе’ҢleastSigBitsпјҢеҸҜд»ҘеҸӮиҖғUUIDж ҮеҮҶеӯ—ж®өеёғеұҖиҝӣиЎҢи®ҫзҪ®пјҢд№ҹеҸҜд»ҘжҢүз…§иҮӘиЎҢеҲ¶е®ҡзҡ„ж ҮеҮҶ public UUID(long mostSigBits, long leastSigBits) { this.mostSigBits = mostSigBits; this.leastSigBits = leastSigBits; } // еҹәдәҺеӯ—з¬ҰдёІж јејҸ8-4-4-4-12зҡ„UUIDиҫ“е…ҘпјҢйҮҚж–°и§ЈжһҗеҮәmostSigBitsе’ҢleastSigBitsпјҢиҝҷдёӘйқҷжҖҒе·ҘеҺӮж–№жі•д№ҹдёҚеёёз”ЁпјҢйҮҢйқўзҡ„дҪҚиҝҗз®—д№ҹдёҚиҝӣиЎҢиҜҰз»ҶжҺўз©¶ public static UUID fromString(String name) { int len = name.length(); if (len > 36) { throw new IllegalArgumentException("UUID string too large"); } int dash2 = name.indexOf('-', 0); int dash3 = name.indexOf('-', dash2 + 1); int dash4 = name.indexOf('-', dash3 + 1); int dash5 = name.indexOf('-', dash4 + 1); int dash6 = name.indexOf('-', dash5 + 1); if (dash5 < 0 || dash6 >= 0) { throw new IllegalArgumentException("Invalid UUID string: " + name); } long mostSigBits = Long.parseLong(name, 0, dash2, 16) & 0xffffffffL; mostSigBits <<= 16; mostSigBits |= Long.parseLong(name, dash2 + 1, dash3, 16) & 0xffffL; mostSigBits <<= 16; mostSigBits |= Long.parseLong(name, dash3 + 1, dash4, 16) & 0xffffL; long leastSigBits = Long.parseLong(name, dash4 + 1, dash5, 16) & 0xffffL; leastSigBits <<= 48; leastSigBits |= Long.parseLong(name, dash5 + 1, len, 16) & 0xffffffffffffL; return new UUID(mostSigBits, leastSigBits); }ж јејҸеҢ–иҫ“еҮә
ж јејҸеҢ–иҫ“еҮәдҪ“зҺ°еңЁUUID#toString()ж–№жі•пјҢиҝҷдёӘж–№жі•дјҡжҠҠmostSigBitsе’ҢleastSigBitsж јејҸеҢ–дёә8-4-4-4-12зҡ„еҪўејҸпјҢиҝҷйҮҢиҜҰз»ҶеҲҶжһҗдёҖдёӢж јејҸеҢ–зҡ„иҝҮзЁӢгҖӮйҰ–е…Ҳд»ҺжіЁйҮҠдёҠзңӢж јејҸжҳҜпјҡ
<time_low>-<time_mid>-<time_high_and_version>-<variant_and_sequence>-<node> time_low = 4 * <hexOctet> => 4дёӘ16иҝӣеҲ¶8дҪҚеӯ—з¬Ұ time_mid = 2 * <hexOctet> => 2дёӘ16иҝӣеҲ¶8дҪҚеӯ—з¬Ұ time_high_and_version = 4 * <hexOctet> => 2дёӘ16иҝӣеҲ¶8дҪҚеӯ—з¬Ұ variant_and_sequence = 4 * <hexOctet> => 2дёӘ16иҝӣеҲ¶8дҪҚеӯ—з¬Ұ node = 4 * <hexOctet> => 6дёӘ16иҝӣеҲ¶8дҪҚеӯ—з¬Ұ hexOctet = <hexDigit><hexDigit>пјҲ2дёӘhexDigitпјү hexDigit = 0-9a-FпјҲе…¶е®һе°ұжҳҜ16иҝӣеҲ¶зҡ„еӯ—з¬Ұпјү
е’ҢеүҚж–ҮеёғеұҖеҲҶжһҗж—¶еҖҷзҡ„жҸҗеҲ°зҡ„еҶ…е®№дёҖиҮҙгҖӮUUID#toString()ж–№жі•жәҗз ҒеҰӮдёӢпјҡ
private static final JavaLangAccess jla = SharedSecrets.getJavaLangAccess(); public String toString() { return jla.fastUUID(leastSigBits, mostSigBits); } ↓↓↓↓↓↓↓↓↓↓↓↓ // java.lang.System private static void setJavaLangAccess() { SharedSecrets.setJavaLangAccess(new JavaLangAccess() { public String fastUUID(long lsb, long msb) { return Long.fastUUID(lsb, msb); } } ↓↓↓↓↓↓↓↓↓↓↓↓ // java.lang.Long static String fastUUID(long lsb, long msb) { // COMPACT_STRINGSеңЁStringзұ»дёӯй»ҳи®ӨдёәtrueпјҢжүҖд»Ҙдјҡе‘ҪдёӯifеҲҶж”Ҝ if (COMPACT_STRINGS) { // еҲқе§ӢеҢ–36й•ҝеәҰзҡ„еӯ—иҠӮж•°з»„ byte[] buf = new byte[36]; // lsbзҡ„дҪҺ48дҪҚиҪ¬жҚўдёә16иҝӣеҲ¶ж јејҸеҶҷе…ҘеҲ°bufдёӯ - node => дҪҚзҪ®[24,35] formatUnsignedLong0(lsb, 4, buf, 24, 12); // lsbзҡ„й«ҳ16дҪҚиҪ¬жҚўдёә16иҝӣеҲ¶ж јејҸеҶҷе…ҘеҲ°bufдёӯ - variant_and_sequence => дҪҚзҪ®[19,22] formatUnsignedLong0(lsb >>> 48, 4, buf, 19, 4); // msbзҡ„дҪҺ16дҪҚиҪ¬жҚўдёә16иҝӣеҲ¶ж јејҸеҶҷе…ҘеҲ°bufдёӯ - time_high_and_version => дҪҚзҪ®[14,17] formatUnsignedLong0(msb, 4, buf, 14, 4); // msbзҡ„дёӯ16дҪҚиҪ¬жҚўдёә16иҝӣеҲ¶ж јејҸеҶҷе…ҘеҲ°bufдёӯ - time_mid => дҪҚзҪ®[9,12] formatUnsignedLong0(msb >>> 16, 4, buf, 9, 4); // msbзҡ„й«ҳ32дҪҚиҪ¬жҚўдёә16иҝӣеҲ¶ж јејҸеҶҷе…ҘеҲ°bufдёӯ - time_low => дҪҚзҪ®[0,7] formatUnsignedLong0(msb >>> 32, 4, buf, 0, 8); // з©әдҪҷзҡ„еӯ—иҠӮж§ҪдҪҚжҸ’е…Ҙ'-'пјҢеҲҡеҘҪеҚ з”ЁдәҶ4дёӘеӯ—иҠӮ buf[23] = '-'; buf[18] = '-'; buf[13] = '-'; buf[8] = '-'; // еҹәдәҺеӨ„зҗҶеҘҪзҡ„еӯ—иҠӮж•°з»„пјҢе®һдҫӢеҢ–StringпјҢ并且编з ҒжҢҮе®ҡдёәLATIN1 return new String(buf, LATIN1); } else { byte[] buf = new byte[72]; formatUnsignedLong0UTF16(lsb, 4, buf, 24, 12); formatUnsignedLong0UTF16(lsb >>> 48, 4, buf, 19, 4); formatUnsignedLong0UTF16(msb, 4, buf, 14, 4); formatUnsignedLong0UTF16(msb >>> 16, 4, buf, 9, 4); formatUnsignedLong0UTF16(msb >>> 32, 4, buf, 0, 8); StringUTF16.putChar(buf, 23, '-'); StringUTF16.putChar(buf, 18, '-'); StringUTF16.putChar(buf, 13, '-'); StringUTF16.putChar(buf, 8, '-'); return new String(buf, UTF16); } } /** * ж јејҸеҢ–ж— з¬ҰеҸ·зҡ„й•ҝж•ҙеһӢпјҢеЎ«е……еҲ°еӯ—иҠӮзј“еҶІеҢәbufдёӯпјҢеҰӮжһңй•ҝеәҰlenи¶…иҝҮдәҶиҫ“е…ҘеҖјзҡ„ASCIIж јејҸиЎЁзӨәпјҢеҲҷдјҡдҪҝз”Ё0иҝӣиЎҢеЎ«е…… * иҝҷдёӘж–№жі•е°ұжҳҜжҠҠиҫ“е…Ҙй•ҝж•ҙеһӢеҖјvalпјҢеҜ№еә”дёҖж®өй•ҝеәҰзҡ„дҪҚпјҢеЎ«е……еҲ°еӯ—иҠӮж•°з»„bufдёӯпјҢlenжҺ§еҲ¶еҶҷе…Ҙеӯ—з¬Ұзҡ„й•ҝеәҰпјҢoffsetжҺ§еҲ¶еҶҷе…Ҙbufзҡ„иө·е§ӢдҪҚзҪ® * иҖҢshiftеҸӮж•°еҶіе®ҡеҹәзЎҖж јејҸпјҢ4жҳҜ16иҝӣеҲ¶пјҢ1жҳҜ2иҝӣеҲ¶пјҢ3жҳҜ8дҪҚ */ static void formatUnsignedLong0(long val, int shift, byte[] buf, int offset, int len) { int charPos = offset + len; int radix = 1 << shift; int mask = radix - 1; do { buf[--charPos] = (byte)Integer.digits[((int) val) & mask]; val >>>= shift; } while (charPos > offset); }жҜ”иҫғзӣёе…ізҡ„ж–№жі•
жҜ”иҫғзӣёе…іж–№жі•еҰӮдёӢпјҡ
// hashCodeж–№жі•еҹәдәҺmostSigBitsе’ҢleastSigBitsеҒҡејӮжҲ–еҫ—еҮәдёҖдёӘдёӯй—ҙеҸҳйҮҸhiloпјҢеҶҚд»Ҙ32дёәеӣ еӯҗиҝӣиЎҢи®Ўз®— public int hashCode() { long hilo = mostSigBits ^ leastSigBits; return ((int)(hilo >> 32)) ^ (int) hilo; } // equalsдёәе®һдҫӢеҜ№жҜ”ж–№жі•пјҢзӣҙжҺҘеҜ№жҜ”дёӨдёӘUUIDзҡ„mostSigBitsе’ҢleastSigBitsеҖјпјҢе®Ңе…Ёзӣёзӯүзҡ„ж—¶еҖҷиҝ”еӣһtrue public boolean equals(Object obj) { if ((null == obj) || (obj.getClass() != UUID.class)) return false; UUID id = (UUID)obj; return (mostSigBits == id.mostSigBits && leastSigBits == id.leastSigBits); } // жҜ”иҫғ规еҲҷжҳҜmostSigBitsй«ҳдҪҚеӨ§иҖ…дёәеӨ§пјҢй«ҳдҪҚзӣёзӯүзҡ„жғ…еҶөдёӢпјҢleastSigBitsеӨ§иҖ…дёәеӨ§ public int compareTo(UUID val) { // The ordering is intentionally set up so that the UUIDs // can simply be numerically compared as two numbers return (this.mostSigBits < val.mostSigBits ? -1 : (this.mostSigBits > val.mostSigBits ? 1 : (this.leastSigBits < val.leastSigBits ? -1 : (this.leastSigBits > val.leastSigBits ? 1 : 0)))); }жүҖжңүжҜ”иҫғж–№жі•д»…д»…е’ҢmostSigBitsе’ҢleastSigBitsжңүе…іпјҢжҜ•з«ҹиҝҷдёӨдёӘй•ҝж•ҙеһӢе°ұеӯҳеӮЁдәҶUUIDе®һдҫӢзҡ„жүҖжңүдҝЎжҒҜгҖӮ
еҲ°жӯӨпјҢе…ідәҺвҖңJDKдёӯUUIDзҡ„еә•еұӮе®һзҺ°ж–№ејҸвҖқзҡ„еӯҰд№ е°ұз»“жқҹдәҶпјҢеёҢжңӣиғҪеӨҹи§ЈеҶіеӨ§е®¶зҡ„з–‘жғ‘гҖӮзҗҶи®әдёҺе®һи·өзҡ„жҗӯй…ҚиғҪжӣҙеҘҪзҡ„её®еҠ©еӨ§е®¶еӯҰд№ пјҢеҝ«еҺ»иҜ•иҜ•еҗ§пјҒиӢҘжғіз»§з»ӯеӯҰд№ жӣҙеӨҡзӣёе…ізҹҘиҜҶпјҢиҜ·з»§з»ӯе…іжіЁдәҝйҖҹдә‘зҪ‘з«ҷпјҢе°Ҹзј–дјҡ继з»ӯеҠӘеҠӣдёәеӨ§е®¶еёҰжқҘжӣҙеӨҡе®һз”Ёзҡ„ж–Үз« пјҒ
е…ҚиҙЈеЈ°жҳҺпјҡжң¬з«ҷеҸ‘еёғзҡ„еҶ…е®№пјҲеӣҫзүҮгҖҒи§Ҷйў‘е’Ңж–Үеӯ—пјүд»ҘеҺҹеҲӣгҖҒиҪ¬иҪҪе’ҢеҲҶдә«дёәдё»пјҢж–Үз« и§ӮзӮ№дёҚд»ЈиЎЁжң¬зҪ‘з«ҷз«ӢеңәпјҢеҰӮжһңж¶үеҸҠдҫөжқғиҜ·иҒ”зі»з«ҷй•ҝйӮ®з®ұпјҡis@yisu.comиҝӣиЎҢдёҫжҠҘпјҢ并жҸҗдҫӣзӣёе…іиҜҒжҚ®пјҢдёҖз»ҸжҹҘе®һпјҢе°Ҷз«ӢеҲ»еҲ йҷӨж¶үе«ҢдҫөжқғеҶ…е®№гҖӮ
жӮЁеҘҪпјҢзҷ»еҪ•еҗҺжүҚиғҪдёӢи®ўеҚ•е“ҰпјҒ