您好,登录后才能下订单哦!
密码登录
登录注册
点击 登录注册 即表示同意《亿速云用户服务条款》
这篇文章主要介绍“怎么用Python讲解偏度和峰度”,在日常操作中,相信很多人在怎么用Python讲解偏度和峰度问题上存在疑惑,小编查阅了各式资料,整理出简单好用的操作方法,希望对大家解答”怎么用Python讲解偏度和峰度”的疑惑有所帮助!接下来,请跟着小编一起来学习吧!
首先还是介绍一下偏度和峰度的概念。
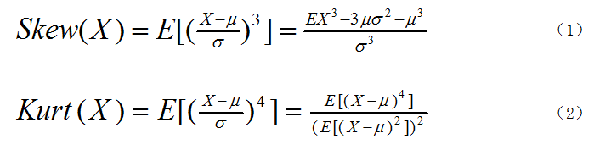
图1. 偏度和峰度公式
偏度(skewness)又称偏态、偏态系数,是描述数据分布偏斜方向和程度的度量,其是衡量数据分布非对称程度的数字特征。对于随机变量X,其偏度是样本的三阶标准化矩,计算公式如图1中的式(1)所示。
偏度的衡量是相对于正态分布来说,正态分布的偏度为0。因此我们说,若数据分布是对称的,偏度为0;若偏度>0,则可认为分布为右偏,也叫正偏,即分布有一条长尾在右;若偏度<0,则可认为分布为左偏,也叫负偏,即分布有一条长尾在左。正偏和负偏如图2所示,在图2中,左边的就是正偏,右边的是负偏。
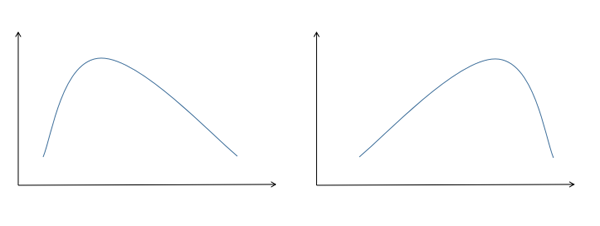
图2. 偏度的示意图
而峰度(Kurtosis)则是描述数据分布陡峭或平滑的统计量,通过对峰度的计算,我们能够判定数据分布相对于正态分布而言是更陡峭还是平缓。对于随机变量X,其峰度为样本的四阶标准中心矩,计算公式如图1中的式2所示。
当峰度系数>0,从形态上看,它相比于正态分布要更陡峭或尾部更厚;而峰度系数<0,从形态上看,则它相比于正态分布更平缓或尾部更薄。在实际环境当中,如果一个分部是厚尾的,这个分布往往比正态分布的尾部具有更大的“质量”,即含又更多的极端值。我们常用的几个分布中,正态分布的峰度为0,均匀分布的峰度为-1.2,指数分布的峰度为6。
峰度的示意图如图3所示,其中第一个子图就是峰度为0的情况,第二个子图是峰度大于0的情况,第三个则是峰度小于0。
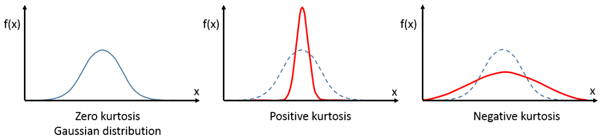
图3. 峰度的示意图
在说完基本概念之后,我们就再讲一下怎么基于偏度和峰度进行正态性检验。这里主要有两种方法,一是Omnibus检验,二是Jarque - Bera检验。
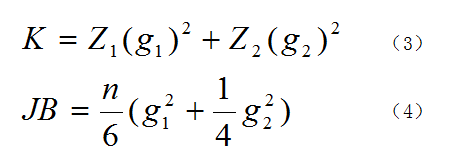
图4. Omnibus和JB检验的公式
Omnibus检验的公式如图4中公式(3)所示,式中Z1和Z2是两个正态化函数,g1和g2则分别是偏度和峰度,在Z1和Z2的作用下,K的结果就接近于卡方分布,我们就能用卡方分布来检验了。这个公式的原理比较复杂,大家如想了解可自行查找相关资料。
Jarque - Bera检验的公式如图4中公式(4)所示,式中n是样本量,这个结果也是接近于卡方分布,其原理也不在这里赘述。这两个检验都是基于所用数据是正态分布的,即有如下假设。
原假设H0:数据是正态分布的。
备择假设H1:数据不是正态分布。
下面我们用代码来说明一下偏度和峰度。
首先看一下数据,这个数据很简单,只有15行2列。数据描述的是火灾事故的损失以及火灾发生地与最近消防站的距离,前者单位是千元,后者单位是千米,数据如图5所示。其中distance指火灾发生地与最近消防站的距离,loss指火灾事故的损失。
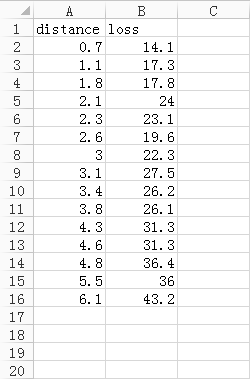
图5. 数据示例
下面是代码,首先导入需要的库。
import pandas as pd import matplotlib.pyplot as plt import statsmodels.stats.api as sms import statsmodels.formula.api as smf from statsmodels.compat import lzip from statsmodels.graphics.tsaplots import plot_acf
接下来是读取数据并作图,这些代码都非常简单,笔者不做过多的解释。
file = r'C:\Users\data.xlsx' df = pd.read_excel(file) fig, ax = plt.subplots(figsize=(8,6)) plt.ylabel('Loss') plt.xlabel('Distance') plt.plot(df['distance'], df['loss'], 'bo-', label='loss') plt.legend() plt.show()结果如图6所示,从结果中我们可以看到这些点大致在一条直线上,那么我们就用一元线性回归来拟合这些数据。
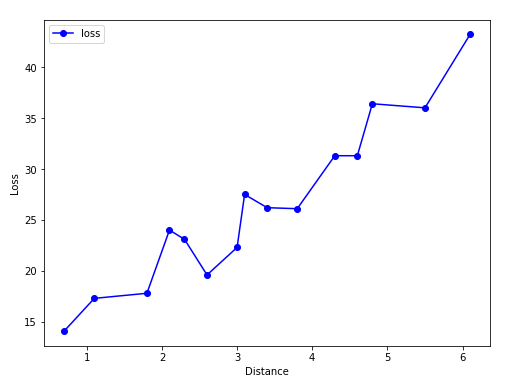
图6. 数据连线图
下面是生成模型,并输出模型的结果。
expr = 'loss ~ distance' results = smf.ols(expr, df).fit() #生成回归模型 print(results.summary())
结果如图7所示。从图中我们可以看到,Prob (F-statistic)的值为1.25e-08,这个值非常小,说明我们的一元线性回归模型是正确的,也就是loss和distance的线性关系是显著的。而图中还可以看到Skew=-0.003,说明这部分数据非常接近正态分布,而Kurtosis=1.706,说明我们的数据比正态分布更陡峭,是一个尖峰。此外,从图中还可以看到Omnibus=2.551,Prob(Omnibus)=0.279,Jarque-Bera (JB)=1.047,Prob(JB)=0.592,这里我们很难直接从Omnibus和Jarque-Bera的数值来判断是否支持前面的备择假设,但我们可以从Prob(Omnibus)和Prob(JB)这两个数值来判断,因为这两个数值都比较大,那么我们就无法拒绝前面的原假设,即H0是正确的,说明我们的数据是服从正态分布的。
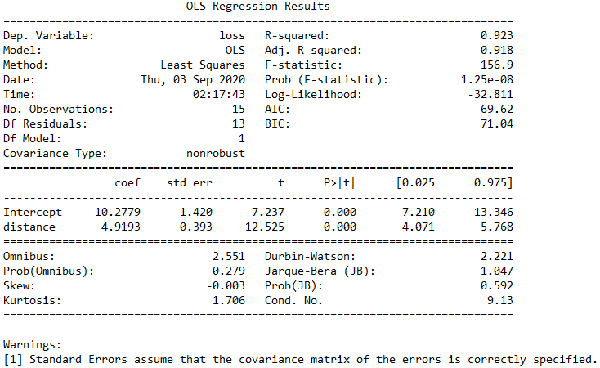
图7. 模型结果说明
接下来我们再验证一下Skew、Kurtosis、Omnibus和Jarque-Bera (JB)这些数值,用的是statsmodels自带的方法。代码如下。
omnibus_label = ['Omnibus K-squared test', 'Chi-squared(2) p-value'] omnibus_test = sms.omni_normtest(results.resid) #omnibus检验 omnibus_results = lzip(omnibus_label, omnibus_test) jb_label = ['Jarque-Bera test', 'Chi-squared(2) p-value', 'Skewness', 'Kurtosis'] jb_test = sms.jarque_bera(results.resid) #jarque_bera检验 jb_results = lzip(jb_label, jb_test) print(omnibus_results) print(jb_results)
这里omnibus_label和jb_label是两个list,里面包含了我们所要检验的项目名称,sms.omni_normtest就是statsmodels自带的omnibus检验方法,sms.jarque_bera就是statsmodels自带的jarque_bera检验方法。results.resid是残差值,一共有15个值,我们的数据本身就只有15个点,这里的每个残差值就对应前面的每个数据点,sms.omni_normtest和sms.jarque_bera就是通过残差值来进行检验的。而lzip这个方法很少见,其用法和python中原生函数zip差不多,笔者在这里更多地是想让大家了解statsmodels,所以用了lzip,这里直接用zip也是可以的,至于lzip和zip的区别,留给大家自行去学习。而上面得到的结果如图8所示。从图8中可以看到,我们得到的结果和前面图7中的结果一模一样。这里用sms.omni_normtest和sms.jarque_bera来进行验证,主要是对前面图7中的结果的一个解释,帮助大家更好地学习statsmodels。
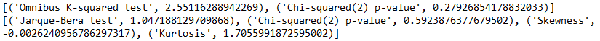
到此,关于“怎么用Python讲解偏度和峰度”的学习就结束了,希望能够解决大家的疑惑。理论与实践的搭配能更好的帮助大家学习,快去试试吧!若想继续学习更多相关知识,请继续关注亿速云网站,小编会继续努力为大家带来更多实用的文章!
免责声明:本站发布的内容(图片、视频和文字)以原创、转载和分享为主,文章观点不代表本网站立场,如果涉及侵权请联系站长邮箱:is@yisu.com进行举报,并提供相关证据,一经查实,将立刻删除涉嫌侵权内容。